ClickHouse Cloud 빠른 시작
ClickHouse를 가장 빠르고 손쉽게 도입하는 방법은 ClickHouse Cloud에서 새 서비스를 생성하는 것입니다. 이 빠른 시작 가이드에서는 3단계로 환경을 설정하는 방법을 안내합니다.
ClickHouse 서비스 생성하기
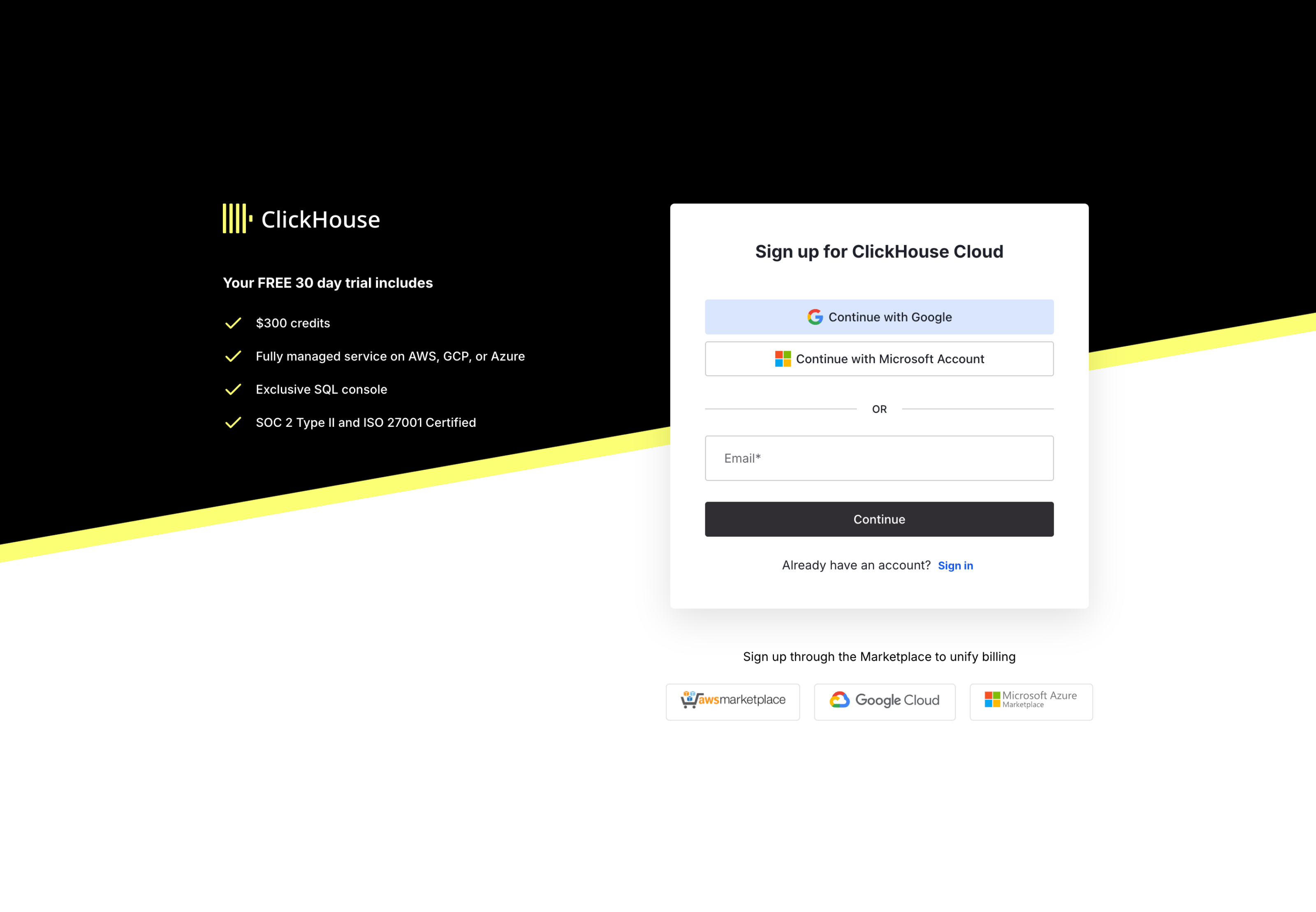
ClickHouse Cloud에서 무료 ClickHouse 서비스를 생성하려면 다음 단계를 완료하여 가입하세요:
- 가입 페이지에서 계정을 생성하십시오
- 이메일로 가입하거나 Google SSO, Microsoft SSO, AWS Marketplace, Google Cloud, Microsoft Azure를 통해 가입할 수 있습니다
- 이메일과 비밀번호로 가입하는 경우, 가입 후 24시간 이내에 수신한 이메일에 포함된 링크를 통해 이메일 주소를 반드시 인증해야 합니다
- 방금 만든 사용자 이름과 비밀번호로 로그인하십시오
로그인하면 ClickHouse Cloud가 온보딩 마법사를 시작하여 새로운 ClickHouse 서비스 생성 과정을 안내합니다. 서비스를 배포할 리전을 선택하고 새 서비스의 이름을 지정하세요:
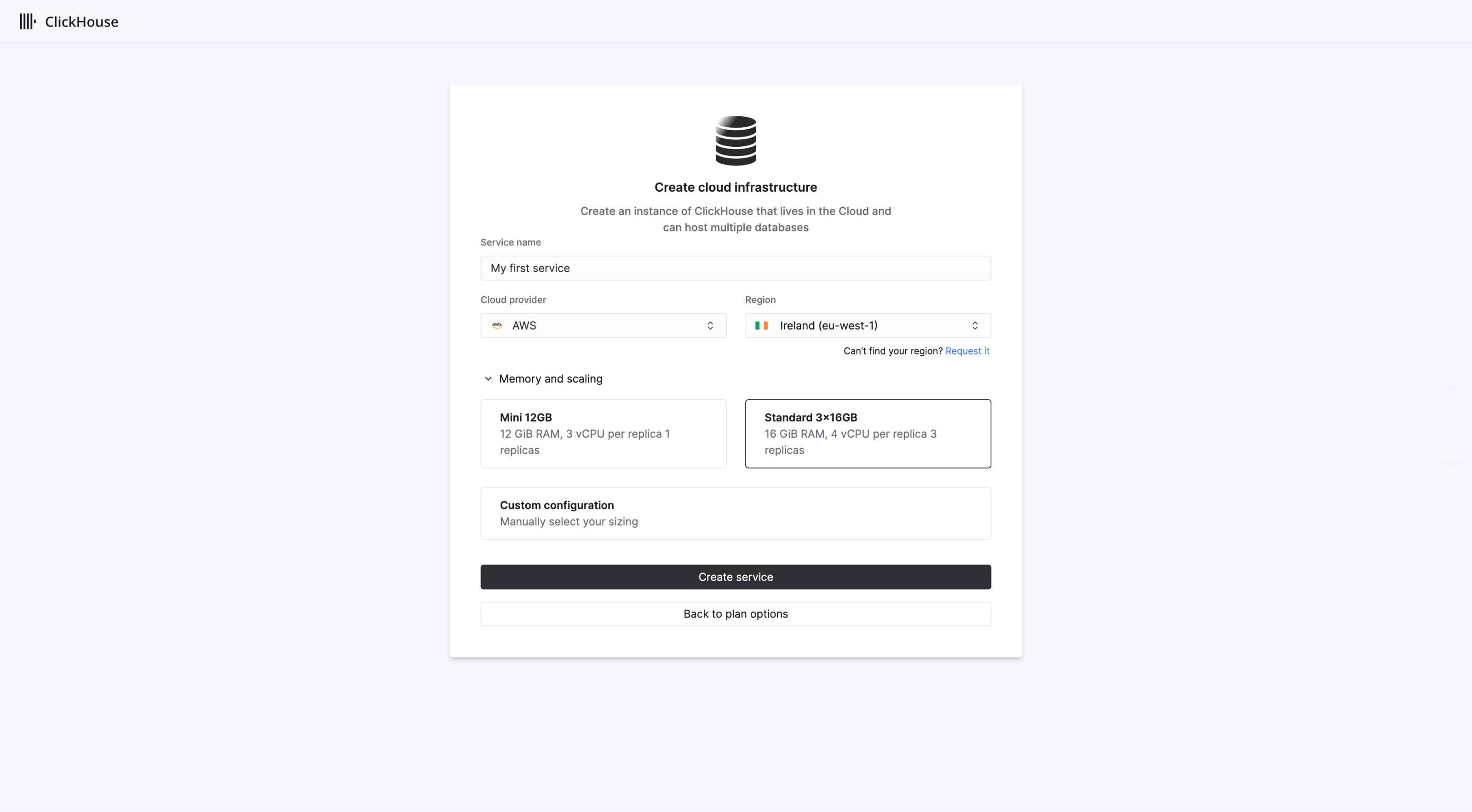
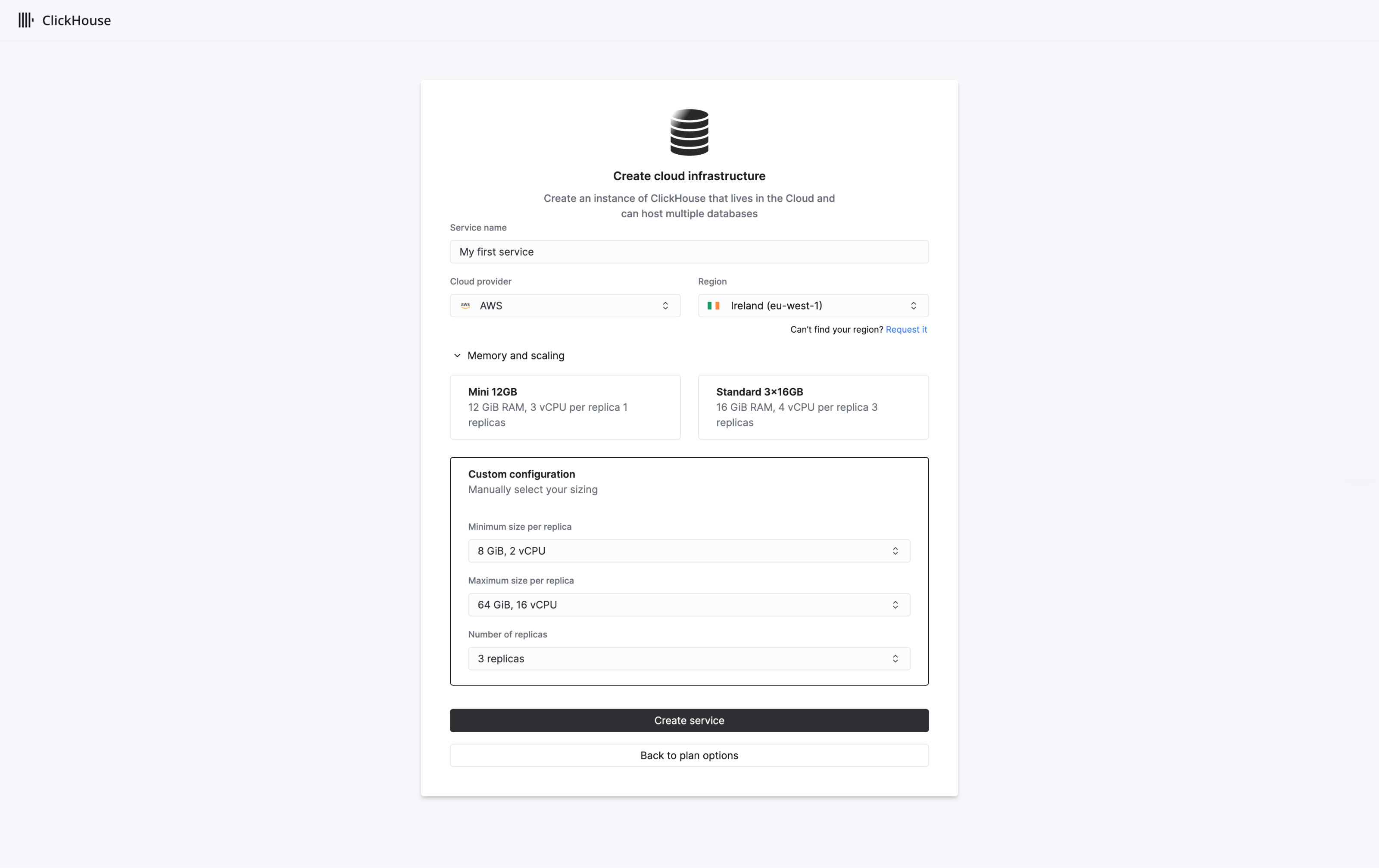
기본적으로 새 조직은 Scale 티어에 배치되며, 각각 4개의 vCPU와 16 GiB RAM을 가진 3개의 ^^레플리카^^가 생성됩니다. Scale 티어에서는 수직 자동 확장이 기본적으로 활성화됩니다. 조직 티어는 나중에 'Plans' 페이지에서 변경하실 수 있습니다.
필요한 경우 레플리카가 확장될 최소 및 최대 크기를 지정하여 서비스 리소스를 사용자 정의하세요. 준비가 완료되면 Create service를 선택하십시오.
축하합니다! ClickHouse Cloud 서비스가 실행 중이며 온보딩이 완료되었습니다. 데이터 수집 및 쿼리를 시작하는 방법에 대한 자세한 내용을 계속 확인하십시오.
ClickHouse에 연결하기
ClickHouse에 연결하는 방법은 두 가지입니다:
- 웹 기반 SQL 콘솔을 사용해 연결하십시오
- 애플리케이션과 연동하기
SQL 콘솔을 사용하여 연결하기
빠른 시작을 위해 ClickHouse는 웹 기반 SQL 콘솔을 제공하며, 온보딩을 완료하면 해당 콘솔로 자동으로 이동합니다.
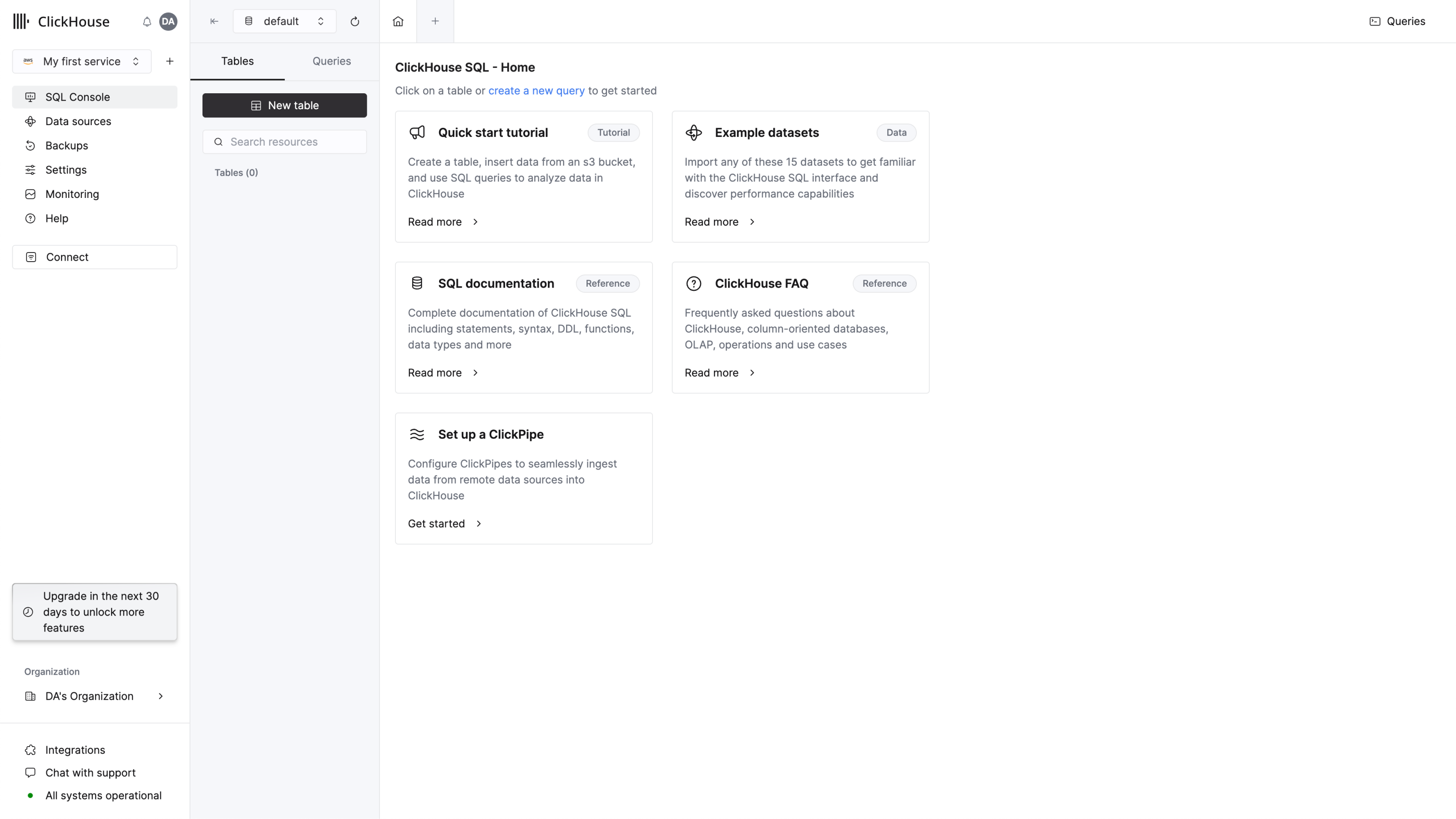
쿼리 탭을 생성하고 간단한 쿼리를 입력하여 연결이 정상적으로 작동하는지 확인하세요:
목록에 4개의 데이터베이스와 사용자가 추가한 데이터베이스가 표시됩니다.
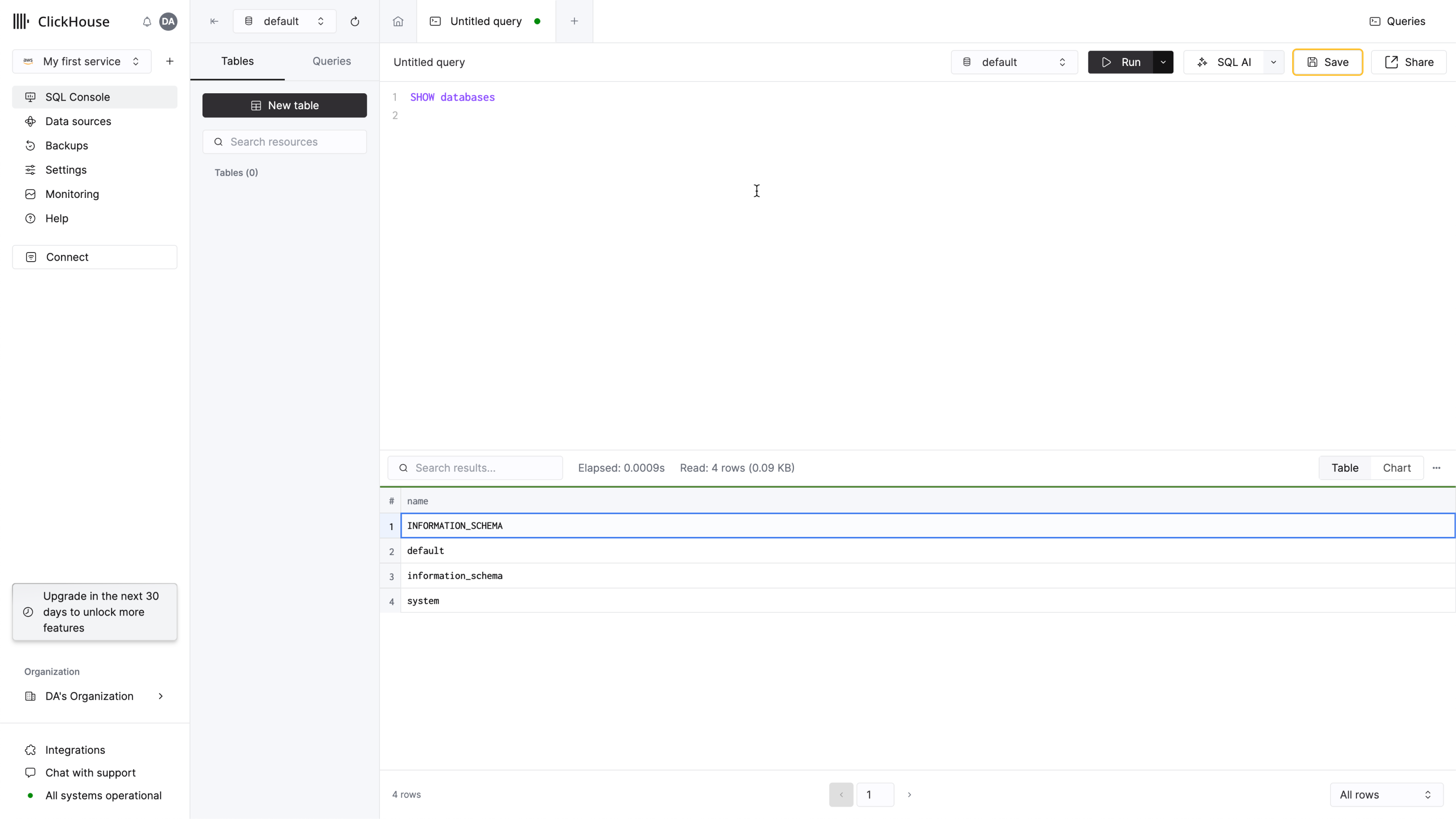
이제 완료되었습니다. 새로운 ClickHouse 서비스를 사용할 준비가 되었습니다!
애플리케이션 연결
내비게이션 메뉴에서 연결 버튼을 클릭하십시오. 모달 창이 열리며 서비스 자격 증명과 인터페이스 또는 언어 클라이언트로 연결하는 방법에 대한 지침이 표시됩니다.
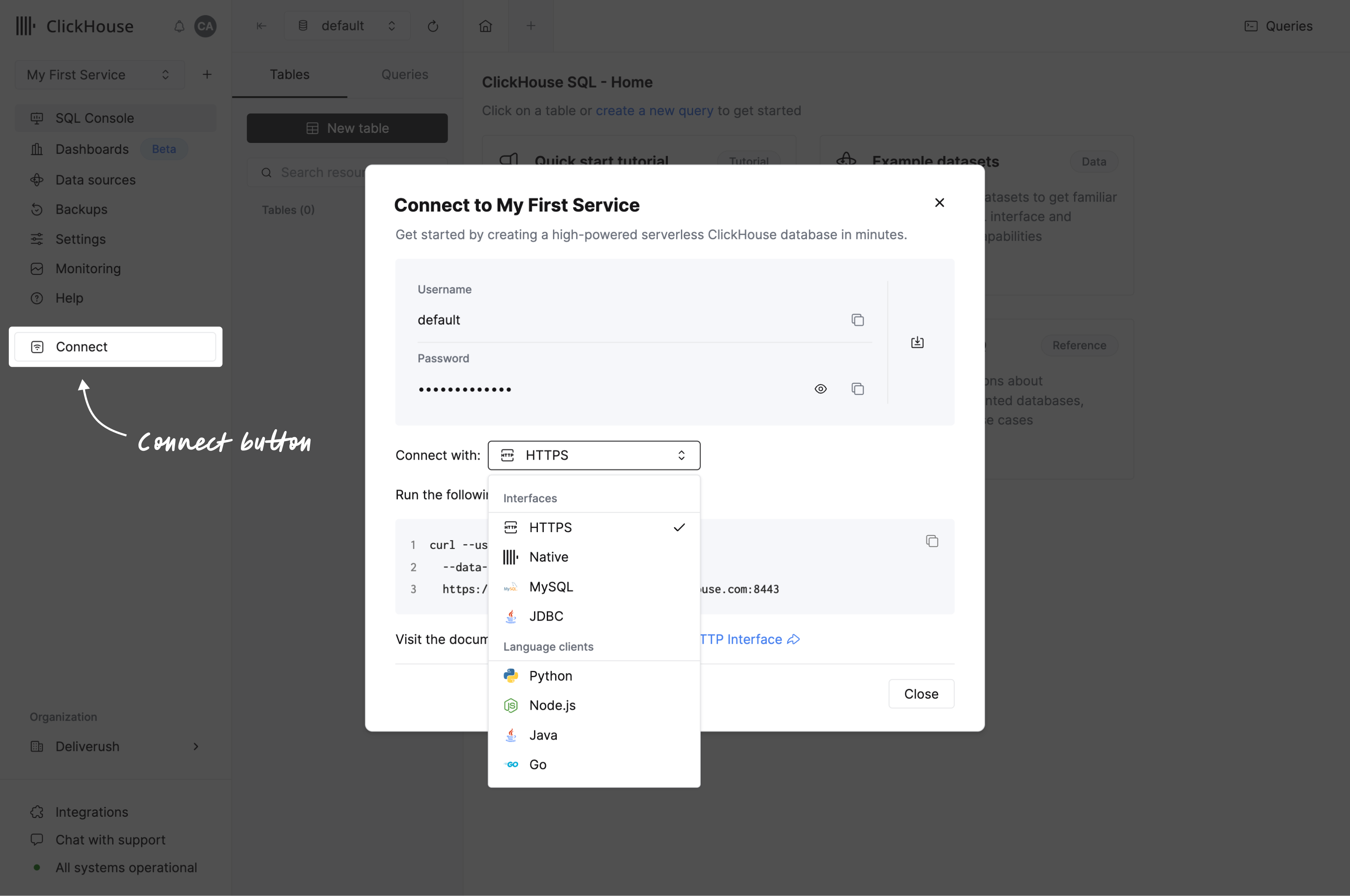
사용하시는 언어 클라이언트가 목록에 없다면 통합 목록을 확인하십시오.
데이터 추가하기
ClickHouse는 데이터와 함께할 때 더욱 강력합니다! 데이터를 추가하는 방법은 여러 가지가 있으며, 대부분의 방법은 탐색 메뉴에서 접근할 수 있는 Data Sources 페이지에서 이용하실 수 있습니다.
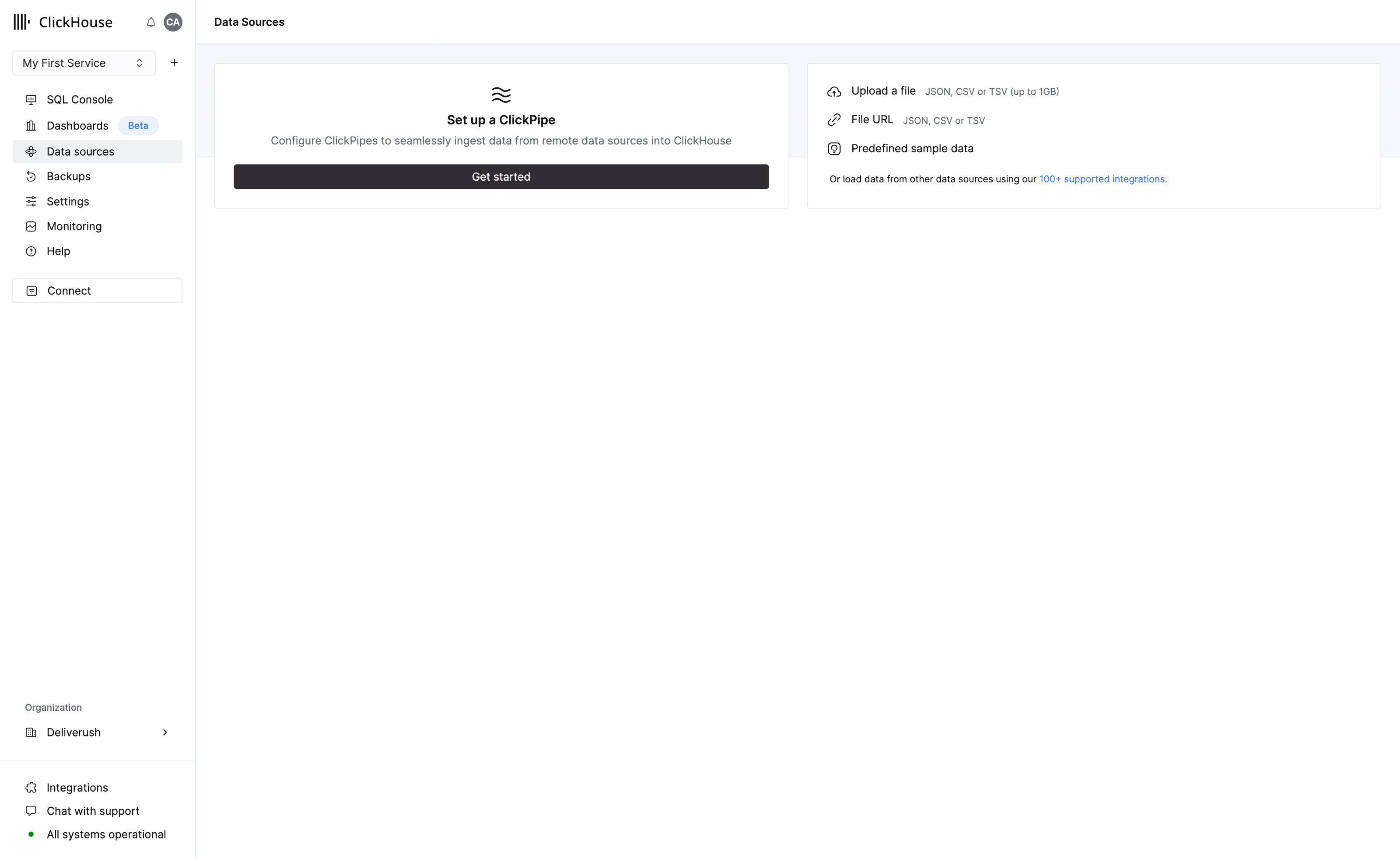
다음 방법을 사용하여 데이터를 업로드하실 수 있습니다:
- S3, Postgres, Kafka, GCS 등의 데이터 소스에서 데이터 수집을 시작할 수 있도록 ClickPipe를 설정합니다
- SQL 콘솔 사용하기
- ClickHouse 클라이언트 사용하기
- 파일 업로드 - 지원되는 형식: JSON, CSV, TSV
- 파일 URL에서 데이터 업로드하기
ClickPipes
ClickPipes는 다양한 소스에서 데이터를 수집하는 작업을 몇 번의 클릭만으로 간편하게 처리할 수 있는 관리형 통합 플랫폼입니다. 가장 까다로운 워크로드를 위해 설계된 ClickPipes의 견고하고 확장 가능한 아키텍처는 일관된 성능과 안정성을 보장합니다. ClickPipes는 장기 스트리밍 요구 사항이나 일회성 데이터 로딩 작업에 모두 사용할 수 있습니다.
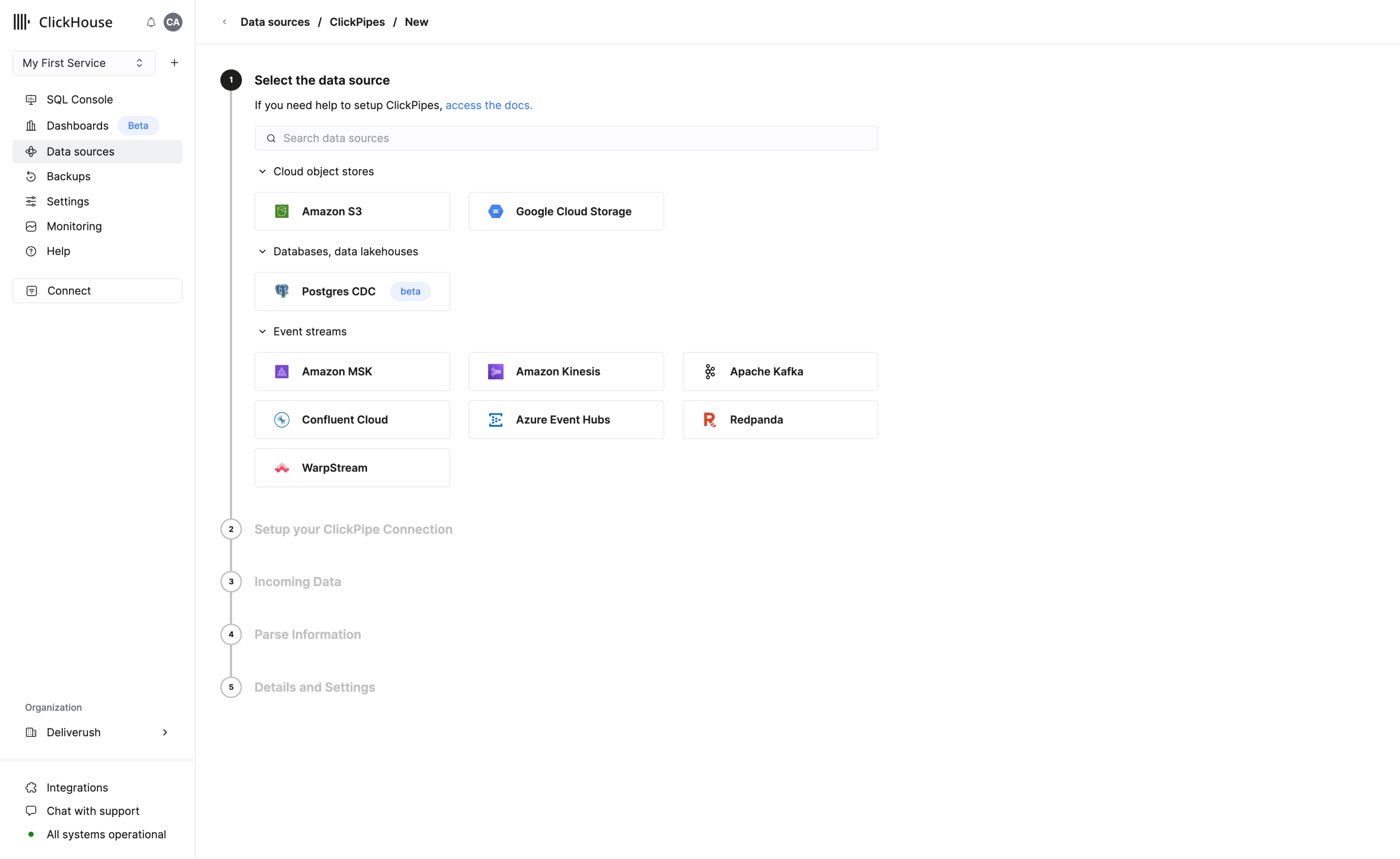
SQL Console을 사용하여 데이터 추가
대부분의 데이터베이스 관리 시스템과 마찬가지로 ClickHouse는 테이블을 논리적으로 데이터베이스로 그룹화합니다. ClickHouse에서 새 데이터베이스를 생성하려면 CREATE DATABASE 명령을 사용하세요:
다음 명령을 실행하여 helloworld 데이터베이스에 my_first_table이라는 이름의 테이블을 생성하세요:
위 예시에서 my_first_table은 4개의 컬럼을 가진 MergeTree 테이블입니다:
user_id: 32비트 부호 없는 정수형 (UInt32)message: 다른 데이터베이스 시스템에서 사용하는VARCHAR,BLOB,CLOB등의 타입을 대체하는 String 데이터 타입timestamp: 특정 시점을 나타내는 DateTime 값입니다metric: 32비트 부동소수점 수 (Float32)
테이블 엔진은 다음 사항을 결정합니다:
- 데이터 저장 방식과 위치
- 지원되는 쿼리 유형
- 데이터가 복제되는지 여부
선택할 수 있는 테이블 엔진이 많지만, 단일 노드 ClickHouse 서버에서 간단한 테이블을 사용하는 경우 MergeTree를 선택하는 것이 적합합니다.
기본 키에 대한 간단한 소개
더 진행하기 전에 ClickHouse에서 기본 키(Primary Key)가 작동하는 방식을 이해하는 것이 중요합니다(기본 키의 구현 방식이 예상과 다를 수 있습니다):
- ClickHouse의 primary key는 테이블의 각 행마다 고유할 필요는 없습니다
ClickHouse 테이블의 ^^기본 키(primary key)^^는 데이터가 디스크에 기록될 때 정렬되는 방식을 결정합니다. 8,192개의 행 또는 10MB의
데이터(**인덱스 그래뉼리티(index granularity)**라고 함)마다 ^^기본 키^^ 인덱스 파일에 항목이 생성됩니다. 이러한 그래뉼리티 개념은
메모리에 쉽게 적재할 수 있는 **^^희소 인덱스(sparse index)^^**를 생성하며, 그래뉼은 SELECT 쿼리 처리 시 가장 작은 단위의
컬럼 데이터 스트라이프를 나타냅니다.
^^기본 키(primary key)^^는 PRIMARY KEY 매개변수를 사용하여 정의할 수 있습니다. PRIMARY KEY를 지정하지 않고 테이블을 정의하면,
키는 ORDER BY 절에 지정된 튜플이 됩니다. PRIMARY KEY와 ORDER BY를 모두 지정하는 경우, ^^기본 키(primary key)^^는 정렬 순서의 하위 집합이어야 합니다.
^^기본 키(primary key)^^는 동시에 ^^정렬 키(sorting key)^^이며, (user_id, timestamp)의 튜플로 구성됩니다. 따라서 각 컬럼 파일에 저장된 데이터는 user_id, 그 다음 timestamp 순으로 정렬됩니다.
ClickHouse의 핵심 개념에 대한 자세한 내용은 "핵심 개념"을 참조하세요.
테이블에 데이터 삽입
ClickHouse에서 익숙한 INSERT INTO TABLE 명령을 사용할 수 있지만, MergeTree 테이블에 삽입할 때마다 스토리지에 파트가 생성된다는 점을 이해하는 것이 중요합니다.
배치당 수만 개 또는 수백만 개의 행을 한 번에 삽입하세요. ClickHouse는 이러한 대용량 데이터를 쉽게 처리할 수 있으며, 서비스에 전송하는 쓰기 요청 수를 줄여 비용을 절감합니다.
간단한 예제이지만 한 번에 여러 행을 삽입해 보겠습니다:
timestamp 컬럼은 다양한 Date 및 DateTime 함수를 사용하여 채워집니다. ClickHouse는 수백 개의 유용한 함수를 제공하며, Functions 섹션에서 확인할 수 있습니다.
정상적으로 작동하는지 확인해 보겠습니다:
ClickHouse Client를 사용하여 데이터 추가
clickhouse client라는 명령줄 도구를 사용하여 ClickHouse Cloud 서비스에 연결할 수도 있습니다. 왼쪽 메뉴에서 Connect를 클릭하여 연결 정보에 접근하세요. 대화 상자의 드롭다운에서 Native를 선택하세요:
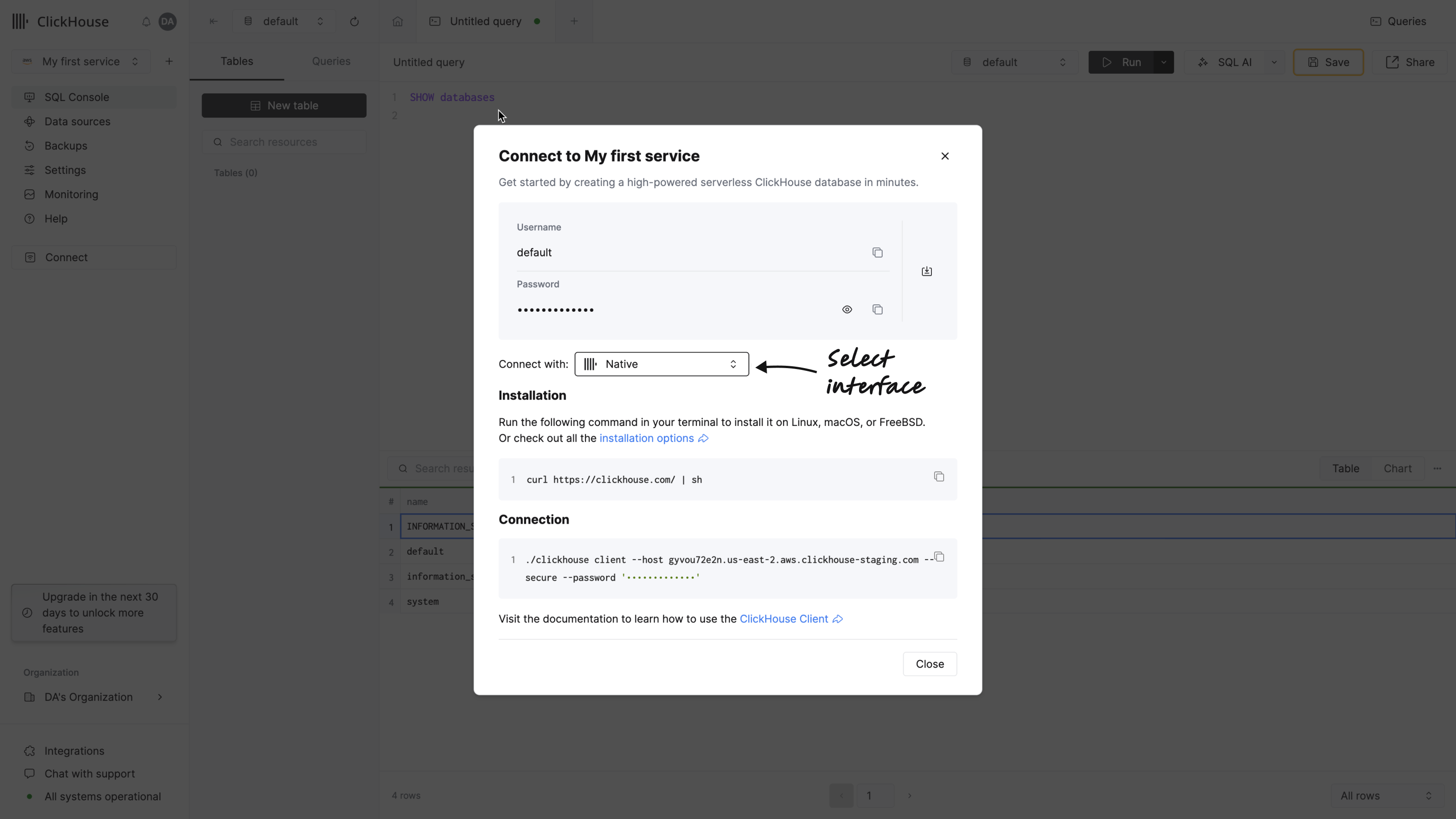
-
ClickHouse를 설치합니다.
-
호스트 이름, 사용자 이름, 비밀번호를 해당 값으로 바꿔서 다음 명령을 실행하십시오:
스마일 이모티콘 프롬프트가 표시되면 쿼리를 실행할 준비가 된 것입니다!
- 다음 쿼리를 실행해 보십시오.
응답이 깔끔한 테이블 형식으로 반환됩니다:
FORMAT절을 추가해 ClickHouse에서 지원하는 다양한 출력 형식 중 하나를 지정하십시오:
위 쿼리의 출력은 탭으로 구분되어 반환됩니다:
clickhouse client에서 나오려면 exit 명령을 입력하십시오:
파일 업로드하기
데이터베이스를 시작할 때 일반적인 작업은 파일에 보유하고 있는 데이터를 삽입하는 것입니다. 클릭스트림 데이터를 나타내는 샘플 데이터를 온라인에서 제공하고 있으며, 이 데이터에는 사용자 ID, 방문한 URL, 이벤트의 타임스탬프가 포함되어 있습니다.
data.csv라는 이름의 CSV 파일에 다음 텍스트가 있다고 가정하겠습니다:
- 다음 명령으로
my_first_table에 데이터를 삽입합니다.
- 이제 SQL 콘솔에서 쿼리를 실행하면 테이블에 새 행이 나타나는 것을 확인할 수 있습니다:
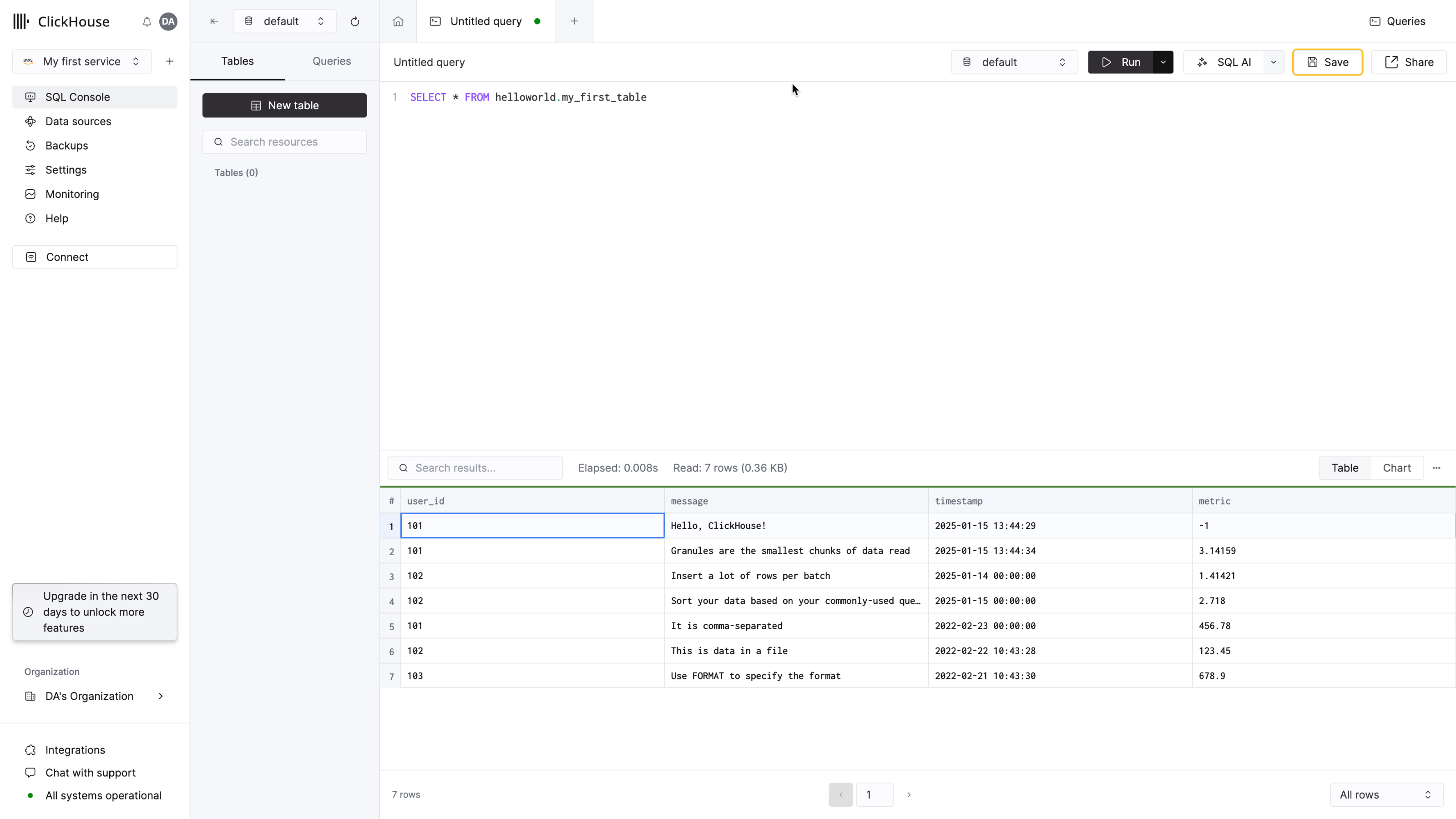
다음 단계로 진행하기 전에 IP 액세스 목록 필터링을 설정하는 것이 좋습니다. 자세한 내용은 "IP 필터 설정" 문서를 참조하십시오.
다음 단계
- Tutorial에서는 테이블에 200만 행을 삽입하고 몇 가지 분석 쿼리를 작성해 봅니다
- 예제 데이터셋 목록과 이를 삽입하는 방법에 대한 안내가 준비되어 있습니다
- 25분 분량의 Getting Started with ClickHouse 동영상을 확인하십시오
- 데이터가 외부 소스에서 유입되는 경우, 메시지 큐, 데이터베이스, 파이프라인 등과 연결하는 방법을 설명한 통합 가이드 모음을 참고하십시오
- UI/BI 시각화 도구를 사용하는 경우, UI를 ClickHouse에 연결하는 방법을 설명한 가이드를 참고하십시오
- 기본 키(Primary Key)에 대한 사용자 가이드는 기본 키와 그 정의 방법에 대해 알아야 할 모든 내용을 다루고 있습니다
