웨어하우스
컴퓨트-컴퓨트 분리란 무엇입니까?
컴퓨트-컴퓨트 분리는 Scale 및 Enterprise 티어에서 사용할 수 있습니다.
각 ClickHouse Cloud 서비스는 다음 구성 요소로 이루어져 있습니다.
- 2개 이상의 ClickHouse 노드(또는 레플리카)로 구성된 그룹이 필요합니다. 단, 자식 서비스는 단일 레플리카일 수 있습니다.
- ClickHouse Cloud UI 콘솔을 통해 생성되는 하나 이상의 엔드포인트로, 서비스에 연결할 때 사용하는 서비스 URL입니다(예:
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443). - 서비스가 모든 데이터와 일부 메타데이터를 저장하는 객체 스토리지 폴더.
단일 부모 서비스와는 달리 단일 자식 서비스는 수직 확장이 가능합니다.
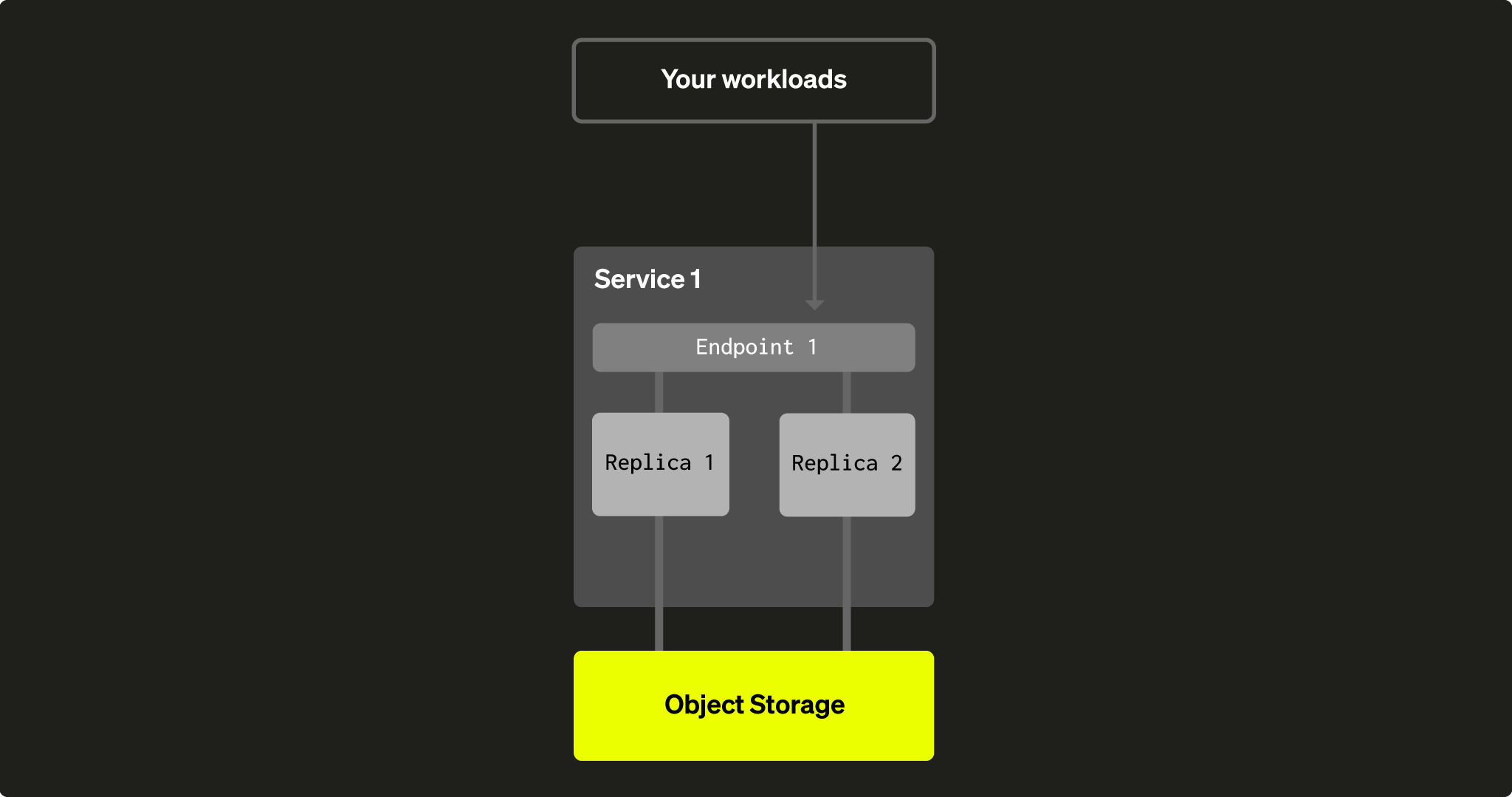
그림 1 - ClickHouse Cloud의 현재 서비스
컴퓨트-컴퓨트 분리를 사용하면 동일한 객체 스토리지 폴더를 사용하는 여러 컴퓨트 노드 그룹을 생성할 수 있으며, 각 그룹은 고유한 엔드포인트를 가지지만 동일한 테이블과 뷰(view) 등을 공유합니다.
각 컴퓨트 노드 그룹은 자체 엔드포인트를 가지므로 워크로드에 사용할 레플리카 집합을 선택할 수 있습니다. 일부 워크로드는 소형 레플리카 1개만으로 충분할 수 있지만, 다른 워크로드는 완전한 고가용성(HA)과 수백 GB에 달하는 메모리가 필요할 수 있습니다. 컴퓨트-컴퓨트 분리를 사용하면 읽기 작업과 쓰기 작업을 서로 간섭하지 않도록 분리할 수도 있습니다:
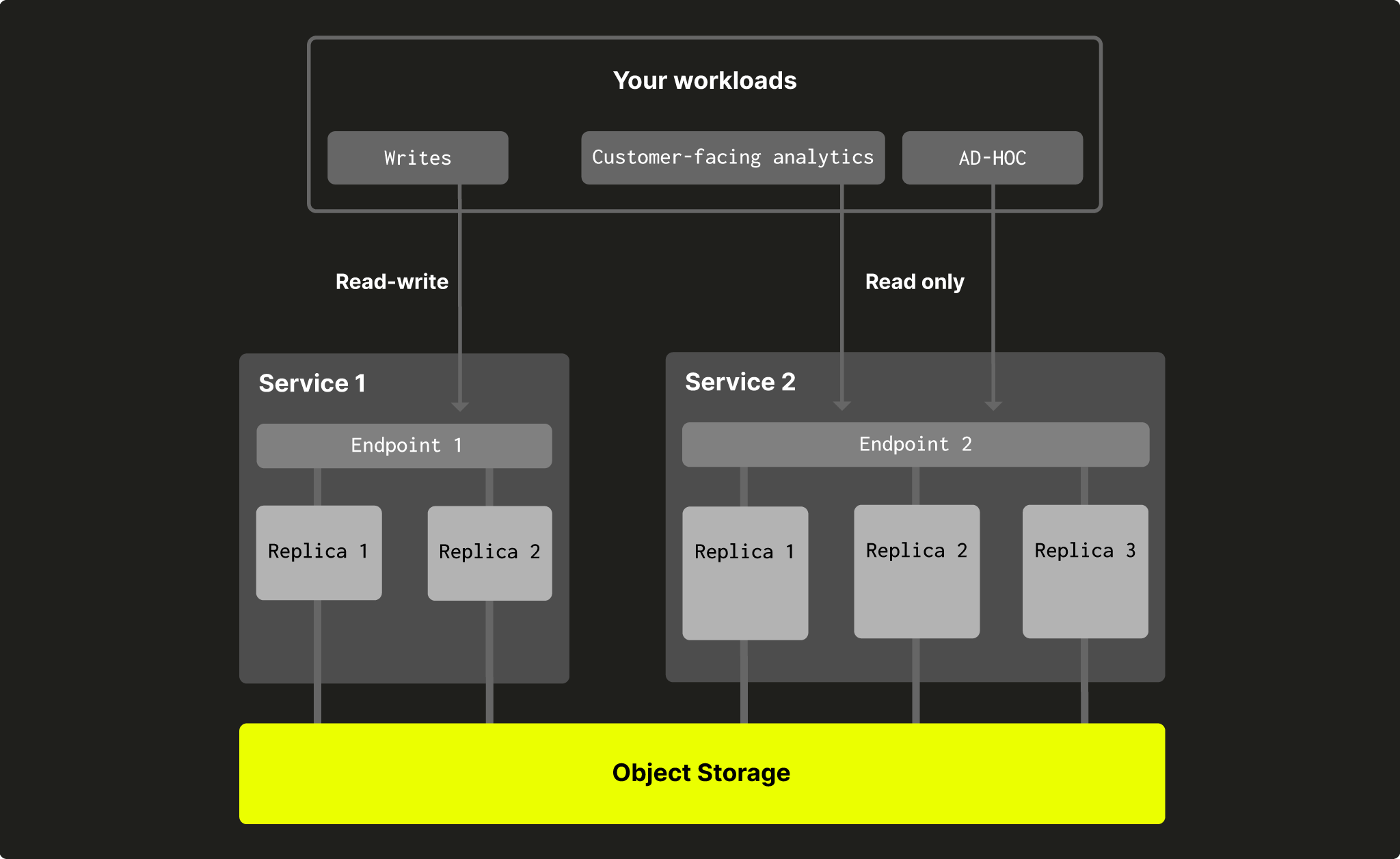
그림 2 - ClickHouse Cloud의 컴퓨트 분리
기존 서비스와 동일한 데이터를 공유하는 추가 서비스를 생성하거나, 여러 서비스가 동일한 데이터를 공유하는 완전히 새로운 구성을 생성하는 것도 가능합니다.
웨어하우스란 무엇입니까?
ClickHouse Cloud에서 _웨어하우스(warehouse)_는 동일한 데이터를 공유하는 서비스 집합입니다. 각 웨어하우스에는 기본 서비스(가장 먼저 생성된 서비스)와 보조 서비스가 있습니다. 예를 들어, 아래 스크린샷에서는 두 개의 서비스를 가진 「DWH Prod」 웨어하우스를 볼 수 있습니다:
- 기본 서비스
DWH Prod - 보조 서비스
DWH Prod Subservice

그림 3 - 웨어하우스 예시
웨어하우스의 모든 서비스는 다음을 공유합니다:
- 리전(예: us-east1)
- Cloud 서비스 공급자(AWS, GCP 또는 Azure)
- ClickHouse 데이터베이스 버전
서비스는 소속된 웨어하우스 기준으로 정렬할 수 있습니다.
액세스 제어
Database credentials
하나의 웨어하우스에 있는 모든 사용자는 동일한 테이블 집합을 공유하므로, 다른 서비스에 대한 접근 제어도 함께 공유합니다. 이는 Service 1에서 생성된 모든 데이터베이스 사용자가 동일한 권한(테이블, 뷰 등에 대한 grant)을 가진 상태로 Service 2도 사용할 수 있으며, 그 반대도 가능함을 의미합니다. 각 서비스마다 다른 엔드포인트를 사용하지만, 동일한 사용자 이름과 비밀번호를 사용합니다. 다시 말해, 동일한 스토리지를 사용하는 서비스 간에는 사용자가 공유됩니다.
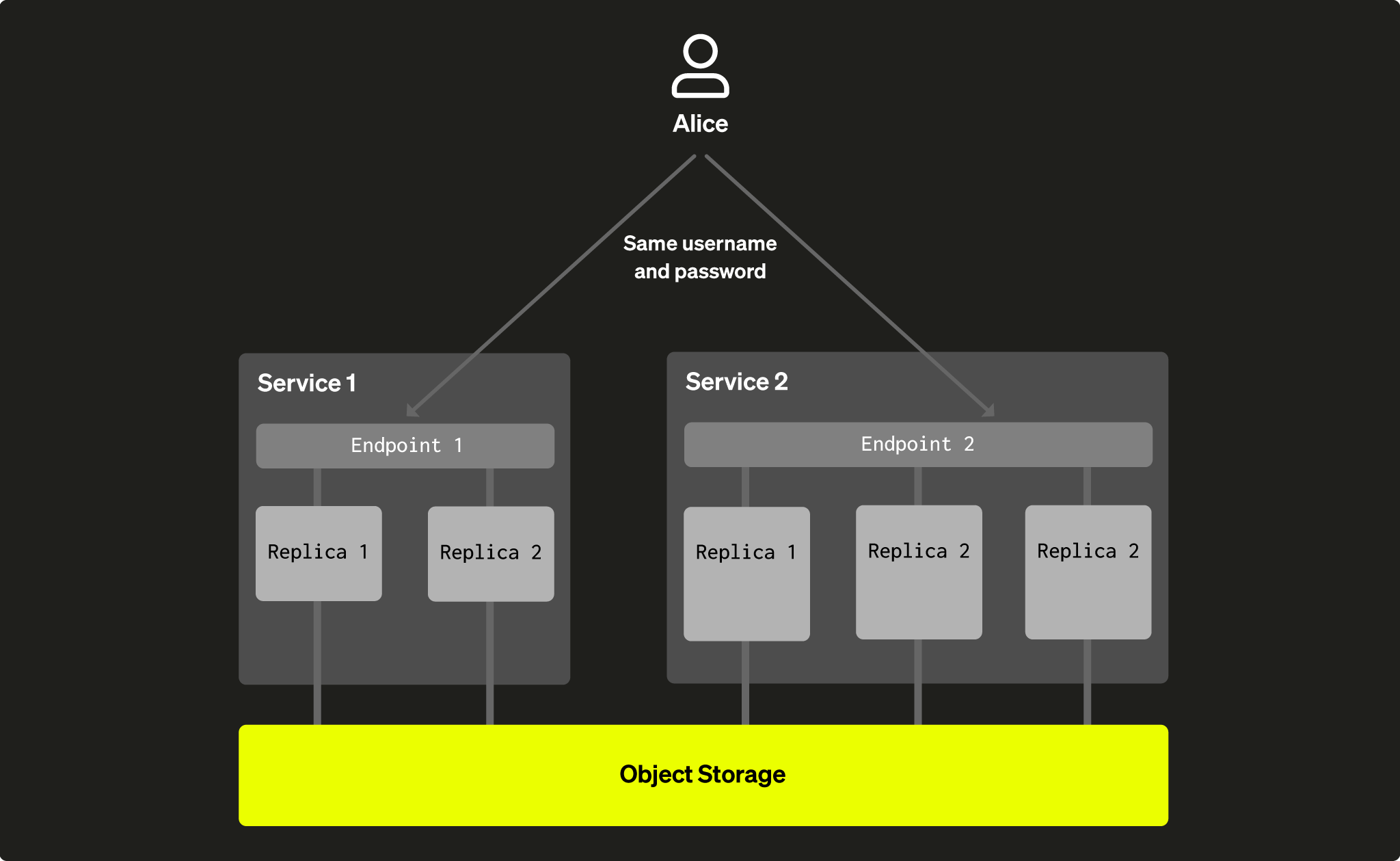
그림 4 - 사용자 Alice는 Service 1에서 생성되었지만, 동일한 자격 증명을 사용해 동일한 데이터를 공유하는 모든 서비스에 접근할 수 있습니다.
네트워크 액세스 제어
특정 서비스를 다른 애플리케이션이나 임시(ad-hoc) 사용자가 사용하지 못하도록 제한하는 것이 유용할 때가 많습니다. 이는 현재 일반 서비스에 대해 구성하는 방식과 유사하게 네트워크 제한을 사용하여 설정할 수 있습니다(ClickHouse Cloud 콘솔에서 해당 서비스의 서비스 탭으로 이동한 후 Settings를 선택).
각 서비스별로 IP 필터링 설정을 적용할 수 있으므로, 어떤 애플리케이션이 어떤 서비스에 접근할 수 있는지 제어할 수 있습니다. 이를 통해 사용자가 특정 서비스를 사용하지 못하도록 제한할 수 있습니다:
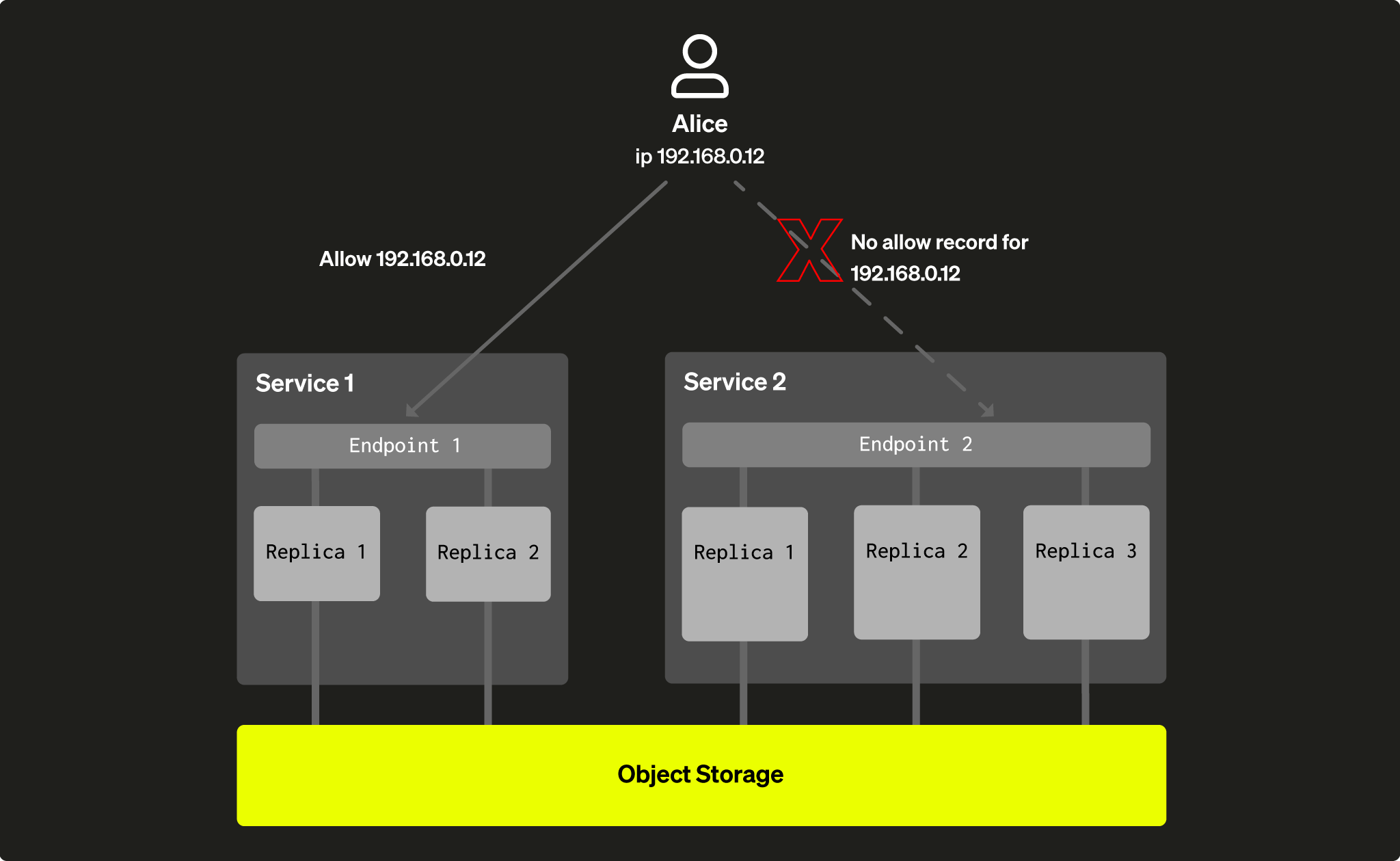
그림 5 - Alice는 네트워크 설정으로 인해 Service 2에 접근하지 못합니다
읽기 vs 읽기-쓰기
때로는 특정 서비스로만 쓰기 권한을 제한하여, 웨어하우스 내 일부 서비스에서만 쓰기를 허용하도록 설정하는 것이 유용한 경우가 있습니다. 이는 두 번째 이후에 생성하는 서비스에서 설정할 수 있습니다(첫 번째 서비스는 항상 읽기-쓰기여야 합니다).
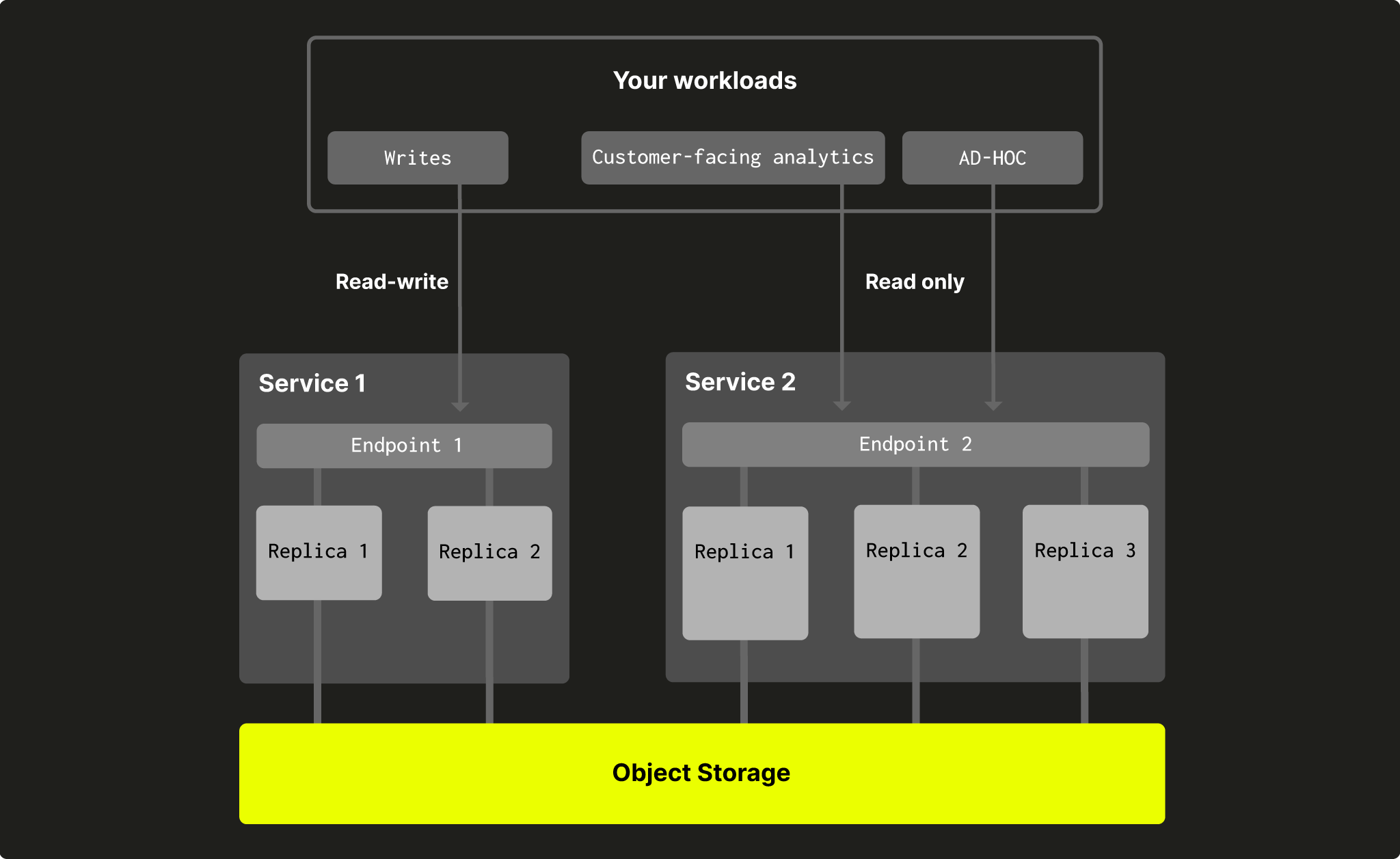
그림 6 - 웨어하우스의 읽기-쓰기 서비스와 읽기 전용 서비스
- 읽기 전용 서비스에서도 현재는 사용자 관리 작업(create, drop 등)이 허용됩니다. 이 동작은 향후 변경될 수 있습니다.
- 갱신 가능 구체화 뷰는 웨어하우스의 읽기-쓰기(RW) 서비스에서만 실행됩니다. 읽기 전용(RO) 서비스에서는 실행되지 않습니다.
스케일링
웨어하우스의 각 서비스는 다음과 같은 측면에서 워크로드에 맞게 조정할 수 있습니다:
- 노드(레플리카) 수. 기본 서비스(해당 웨어하우스에서 가장 먼저 생성된 서비스)는 노드를 2개 이상으로 구성해야 합니다. 각 보조 서비스는 노드를 1개 이상 가질 수 있습니다.
- 노드(레플리카) 크기
- 서비스가 자동으로 스케일링되도록 할지 여부
- 서비스가 비활성 상태일 때 유휴 상태로 전환되도록 할지 여부(그룹의 첫 번째 서비스에는 적용할 수 없습니다. 제한 사항 섹션을 참조하십시오)
동작 변경 사항
서비스에 compute-compute가 활성화되면(최소 하나의 보조 서비스가 생성된 경우), default 클러스터 이름을 사용하는 clusterAllReplicas() 함수 호출은 해당 함수가 호출된 서비스의 레플리카만 사용하게 됩니다. 즉, 동일한 데이터셋에 연결된 2개의 서비스가 있고, 서비스 1에서 clusterAllReplicas(default, system, processes)를 호출하면 서비스 1에서 실행 중인 프로세스만 표시됩니다. 모든 레플리카를 대상으로 해야 하는 경우, 예를 들어 clusterAllReplicas('all_groups.default', system, processes)를 호출할 수 있습니다.
제한 사항
-
기본 서비스는 항상 실행 중이어야 하며 유휴(idle) 상태가 되면 안 됩니다(이 제한은 GA 이후 일정 시점에 제거될 예정입니다). 프라이빗 프리뷰 기간과 GA 이후 일정 기간 동안에는 기본 서비스(일반적으로 다른 서비스를 추가해 확장하려는 기존 서비스)가 항상 실행 상태를 유지하며 유휴 설정이 비활성화됩니다. 하나 이상의 보조 서비스가 있는 동안에는 기본 서비스를 중지하거나 유휴 상태로 전환할 수 없습니다. 모든 보조 서비스를 제거한 이후에는 원래 서비스를 다시 중지하거나 유휴 상태로 전환할 수 있습니다.
-
때때로 워크로드를 완전히 분리하지 못할 수 있습니다. 목표는 서로 다른 데이터베이스 워크로드를 서로 분리할 수 있는 옵션을 제공하는 것이지만, 같은 데이터를 공유하는 서비스 간에 한 서비스의 워크로드가 다른 서비스에 영향을 미치는 예외적인 경우가 있을 수 있습니다. 이러한 상황은 상당히 드물며, 대부분 OLTP와 유사한 워크로드와 관련되어 있습니다.
-
모든 읽기-쓰기 서비스는 백그라운드 병합(merge) 작업을 수행합니다. ClickHouse에 데이터를
INSERT할 때 데이터베이스는 먼저 데이터를 일부 스테이징 파티션에 삽입한 후, 백그라운드에서 병합을 수행합니다. 이 병합 작업은 메모리와 CPU 리소스를 소비할 수 있습니다. 두 개의 읽기-쓰기 서비스가 동일한 스토리지를 공유하는 경우 두 서비스 모두 백그라운드 작업을 수행합니다. 이는 Service 1에서INSERT쿼리가 실행되었지만, 실제 병합 작업은 Service 2에서 완료되는 상황이 발생할 수 있음을 의미합니다. 읽기 전용 서비스는 백그라운드 병합을 수행하지 않으므로, 이 작업에 리소스를 사용하지 않는다는 점에 유의하십시오. -
모든 읽기-쓰기 서비스는 S3Queue 테이블 엔진 삽입 작업을 수행합니다. RW 서비스에서 S3Queue 테이블을 생성하면, 동일 WH에 있는 다른 모든 RW 서비스도 S3에서 데이터를 읽어 데이터베이스에 쓰기를 수행할 수 있습니다.
-
한 읽기-쓰기 서비스에서의 삽입 작업이, 유휴 기능이 활성화된 경우 다른 읽기-쓰기 서비스의 유휴 상태 전환을 방해할 수 있습니다. 그 결과, 두 번째 서비스가 첫 번째 서비스를 위한 백그라운드 병합 작업을 수행하게 됩니다. 이러한 백그라운드 작업은 두 번째 서비스가 유휴 상태로 전환되는 것을 막을 수 있습니다. 백그라운드 작업이 모두 완료되면 서비스는 유휴 상태가 됩니다. 읽기 전용 서비스는 영향을 받지 않으며, 지연 없이 유휴 상태로 전환됩니다.
-
기본적으로 CREATE/RENAME/DROP DATABASE 쿼리는 유휴/중지된 서비스에 의해 차단될 수 있습니다. 이러한 쿼리는 멈춰 있는 것처럼 보일 수 있습니다. 이를 피하려면 세션 단위 또는 쿼리 단위로
settings distributed_ddl_task_timeout=0을 설정해 데이터베이스 관리 쿼리를 실행하면 됩니다. 예를 들면 다음과 같습니다.
- 현재는 웨어하우스당 서비스 수에 대한 소프트 제한이 5개입니다. 하나의 웨어하우스에 5개를 초과하는 서비스를 구성해야 하는 경우 지원 팀에 문의하십시오.
요금제
컴퓨트 요금은 웨어하우스의 모든 서비스(기본 및 보조)에 동일하게 적용됩니다. 스토리지는 한 번만 청구되며, 최초(원본) 서비스에 포함됩니다.
워크로드 규모와 선택한 티어에 따라 비용을 추정하는 데 도움이 되는 요금 계산기는 요금제 페이지를 참조하십시오.
백업
- 단일 웨어하우스의 모든 서비스는 동일한 스토리지를 공유하므로, 백업은 기본(초기) 서비스에서만 수행합니다. 이에 따라 해당 웨어하우스의 모든 서비스 데이터가 백업됩니다.
- 웨어하우스의 기본 서비스에서 생성한 백업을 복원하면, 기존 웨어하우스와 연결되지 않은 완전히 새로운 서비스로 복원됩니다. 그런 다음 복원이 완료되는 대로 새 서비스에 다른 서비스를 바로 추가할 수 있습니다.
웨어하우스 사용
웨어하우스 생성
웨어하우스를 생성하려면 기존 서비스와 데이터를 공유할 두 번째 서비스를 생성해야 합니다. 이는 기존 서비스 중 하나에서 플러스 아이콘을 클릭하여 수행할 수 있습니다:
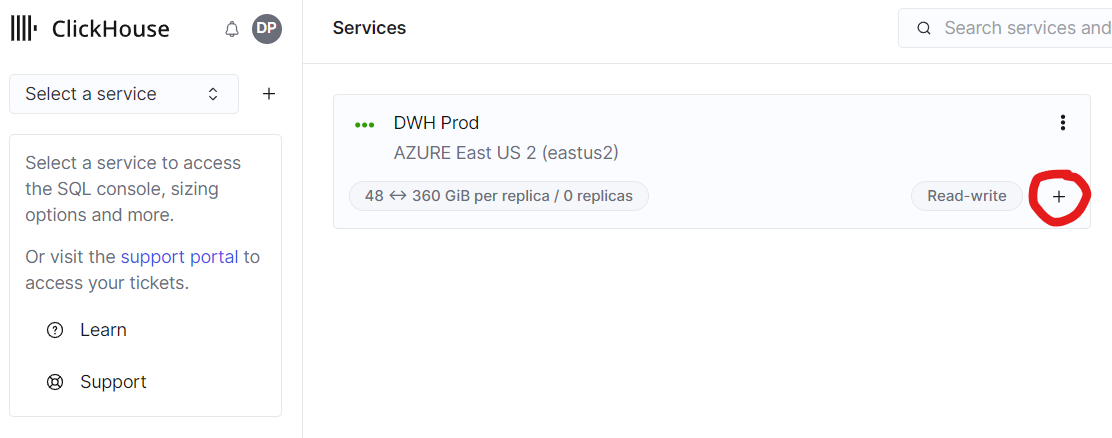
그림 7 - 웨어하우스에서 새 서비스를 생성하려면 플러스 아이콘을 클릭합니다
서비스 생성 화면에서는 새 서비스의 데이터 소스로 드롭다운에서 원래 서비스가 선택되어 있습니다. 생성이 완료되면 이 두 서비스가 하나의 웨어하우스를 구성합니다.
웨어하우스 이름 변경
웨어하우스 이름을 변경하는 방법은 두 가지입니다.
- 서비스 페이지 오른쪽 상단에서 「Sort by warehouse」를 선택한 다음, 웨어하우스 이름 옆의 연필 아이콘을 클릭합니다.
- 어떤 서비스에서든 웨어하우스 이름을 클릭한 후, 해당 화면에서 웨어하우스 이름을 변경합니다.
웨어하우스 삭제
웨어하우스를 삭제하면 모든 컴퓨트 서비스와 데이터(테이블, 뷰, 사용자 등)가 삭제됩니다. 이 작업은 되돌릴 수 없습니다. 웨어하우스는 처음 생성된 서비스를 삭제해야만 삭제할 수 있습니다. 다음 순서대로 진행하십시오:
- 처음 생성된 서비스를 제외하고 추가로 생성된 모든 서비스를 삭제합니다.
- 처음 생성된 서비스를 삭제합니다(경고: 이 단계에서 웨어하우스의 모든 데이터가 삭제됩니다).
