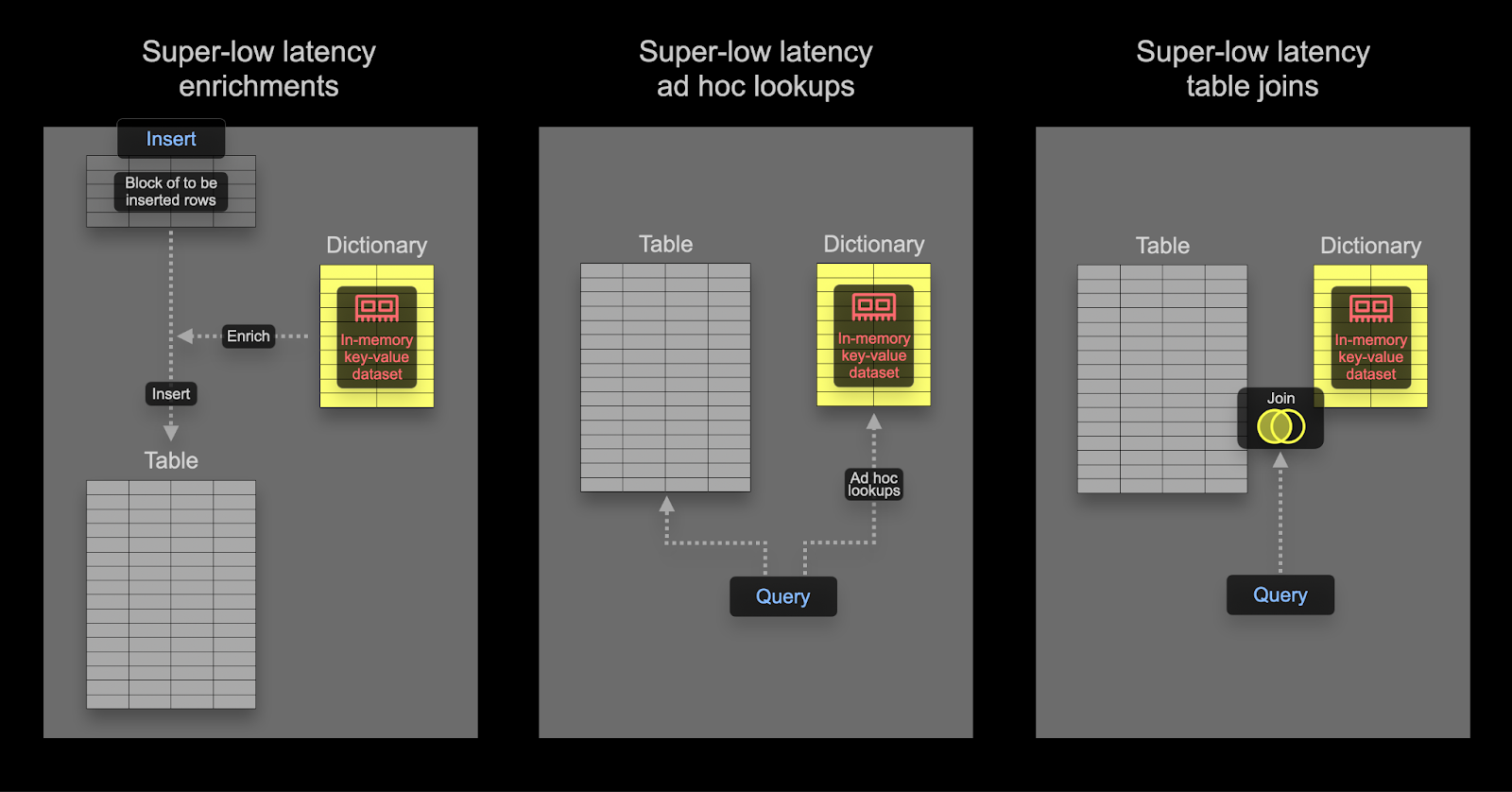
ClickHouse의 딕셔너리는 다양한 내부 및 외부 소스의 데이터를 메모리 내 key-value 형태로 표현하여, 초저지연 조회 쿼리에 최적화합니다.
딕셔너리는 다음과 같은 용도로 유용합니다:
- 특히
JOIN을 사용할 때 쿼리 성능을 향상시키는 경우
- 수집 처리를 지연시키지 않고, 실시간으로 수집된 데이터를 보강하는 경우
딕셔너리를 사용하여 조인 속도 높이기
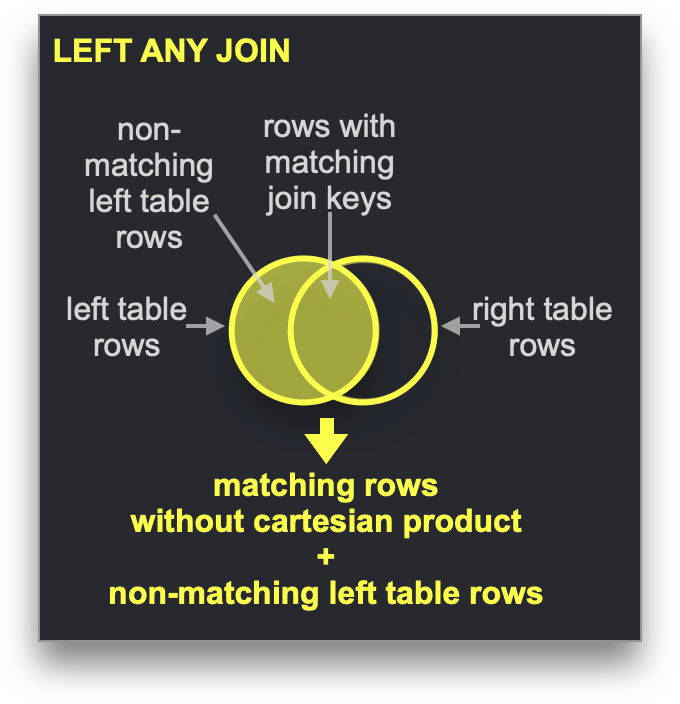
딕셔너리는 특정 유형의 JOIN, 즉 조인 키가 기본 키-값 저장소의 키 속성과 일치해야 하는 LEFT ANY 조인 유형의 속도를 높이는 데 사용할 수 있습니다.
이러한 조건을 만족하는 경우 ClickHouse는 딕셔너리를 활용하여 Direct Join을 수행할 수 있습니다. 이는 ClickHouse에서 가장 빠른 조인 알고리즘이며, 오른쪽 테이블에 사용된 기본 테이블 엔진(table engine)이 저지연 키-값 요청을 지원할 때 적용할 수 있습니다. ClickHouse에는 이를 지원하는 테이블 엔진이 세 가지 있습니다. Join(사실상 미리 계산된 해시 테이블), EmbeddedRocksDB, Dictionary입니다. 여기서는 딕셔너리 기반 접근 방식을 설명하지만, 동작 메커니즘은 세 엔진 모두에서 동일합니다.
Direct Join 알고리즘은 오른쪽 테이블이 딕셔너리를 기반으로 하고, 해당 테이블에서 조인될 데이터가 저지연 키-값 데이터 구조 형태로 이미 메모리에 상주하고 있어야 합니다.
Stack Overflow 데이터셋을 사용하여 다음 질문에 답해 보겠습니다:
Hacker News에서 SQL과 관련된 게시물 중 가장 논쟁적인 게시물은 무엇입니까?
여기서 「논쟁적이다」는 것을, 게시물이 받은 찬성표와 반대표 수가 비슷한 경우로 정의합니다. 이 절대 차이를 계산하며, 값이 0에 가까울수록 더 논쟁적입니다. 또한 게시물은 최소 10개의 찬성표와 10개의 반대표를 받아야 한다고 가정하겠습니다. 사람들이 거의 투표하지 않은 게시물은 그다지 논쟁적이지 않기 때문입니다.
데이터가 정규화되어 있는 상태에서, 현재 이 쿼리는 posts 테이블과 votes 테이블 간의 JOIN이 필요합니다:
WITH PostIds AS
(
SELECT Id
FROM posts
WHERE Title ILIKE '%SQL%'
)
SELECT
Id,
Title,
UpVotes,
DownVotes,
abs(UpVotes - DownVotes) AS Controversial_ratio
FROM posts
INNER JOIN
(
SELECT
PostId,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
WHERE PostId IN (PostIds)
GROUP BY PostId
HAVING (UpVotes > 10) AND (DownVotes > 10)
) AS votes ON posts.Id = votes.PostId
WHERE Id IN (PostIds)
ORDER BY Controversial_ratio ASC
LIMIT 1
Row 1:
──────
Id: 25372161
Title: How to add exception handling to SqlDataSource.UpdateCommand
UpVotes: 13
DownVotes: 13
Controversial_ratio: 0
1 rows in set. Elapsed: 1.283 sec. Processed 418.44 million rows, 7.23 GB (326.07 million rows/s., 5.63 GB/s.)
Peak memory usage: 3.18 GiB.
JOIN의 오른쪽에는 더 작은 데이터 세트를 사용하십시오: 이 쿼리는 외부 쿼리와 서브쿼리 둘 다에서 PostId에 대한 필터링이 발생하기 때문에 필요 이상으로 장황해 보일 수 있습니다. 이는 쿼리 응답 시간을 빠르게 유지하기 위한 성능 최적화입니다. 최적의 성능을 위해서는 항상 JOIN의 오른쪽이 더 작은 집합이며 가능한 한 작도록 유지해야 합니다. JOIN 성능을 최적화하고 사용 가능한 알고리즘을 이해하는 데 도움이 되는 팁은 이 블로그 아티클 시리즈를 참고하십시오.
이 쿼리는 빠르지만, 좋은 성능을 얻기 위해 JOIN을 신중하게 작성해야 한다는 전제에 의존합니다. 이상적으로는 메트릭을 계산하기 위해, 먼저 게시물을 「SQL」을 포함하는 것들로만 필터링한 다음, 해당 블로그 하위 집합에 대한 UpVote 및 DownVote 개수를 확인하면 됩니다.
딕셔너리 적용하기
이 개념들을 보여 주기 위해 투표 데이터에 딕셔너리를 사용합니다. 딕셔너리는 일반적으로 메모리에 상주하므로(ssd_cache는 예외), 데이터 크기에 유의해야 합니다. 먼저 votes 테이블의 크기를 확인합니다:
SELECT table,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE table IN ('votes')
GROUP BY table
┌─table───────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ votes │ 1.25 GiB │ 3.79 GiB │ 3.04 │
└─────────────────┴─────────────────┴───────────────────┴───────┘
데이터는 딕셔너리에 압축되지 않은 상태로 저장되므로, 모든 컬럼을 (실제로는 그렇게 하지 않지만) 딕셔너리에 저장한다고 가정하면 최소 4GB의 메모리가 필요합니다. 딕셔너리는 클러스터 전체에 걸쳐 복제되므로, 이 메모리는 노드별로 예약되어야 합니다.
아래 예제에서는 딕셔너리 데이터가 ClickHouse 테이블에서 생성됩니다. 이는 딕셔너리의 가장 흔한 소스이지만, 파일, http, 그리고 Postgres를 포함한 데이터베이스 등 여러 가지 소스를 지원합니다. 아래에서 설명하듯이, 딕셔너리는 자동으로 갱신될 수 있어, 자주 변경되는 소규모 데이터셋을 직접 조인에 사용할 수 있도록 보장하는 데 이상적인 방법을 제공합니다.
딕셔너리에는 조회가 수행될 기본 키(primary key)가 필요합니다. 이는 개념적으로 트랜잭션 데이터베이스의 기본 키와 동일하며 고유해야 합니다. 위의 쿼리에서는 조인 키 PostId에 대한 조회가 필요합니다. 딕셔너리는 votes 테이블에서 PostId별로 찬성 및 반대 투표 수를 합산한 값으로 채워져야 합니다. 이 딕셔너리 데이터를 얻기 위한 쿼리는 다음과 같습니다:
SELECT PostId,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY PostId
딕셔너리를 생성하려면 다음과 같은 DDL이 필요합니다. 위에서 작성한 쿼리의 사용 방식에 주의하십시오.
CREATE DICTIONARY votes_dict
(
`PostId` UInt64,
`UpVotes` UInt32,
`DownVotes` UInt32
)
PRIMARY KEY PostId
SOURCE(CLICKHOUSE(QUERY 'SELECT PostId, countIf(VoteTypeId = 2) AS UpVotes, countIf(VoteTypeId = 3) AS DownVotes FROM votes GROUP BY PostId'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
0 rows in set. Elapsed: 36.063 sec.
자가 관리형 OSS 환경에서는 위 명령을 모든 노드에서 실행해야 합니다. ClickHouse Cloud에서는 딕셔너리가 자동으로 모든 노드에 복제됩니다. 위 명령은 RAM 64GB가 장착된 ClickHouse Cloud 노드에서 실행되었으며, 로드하는 데 36초가 소요되었습니다.
딕셔너리가 사용한 메모리를 확인하려면 다음을 실행합니다:
SELECT formatReadableSize(bytes_allocated) AS size
FROM system.dictionaries
WHERE name = 'votes_dict'
┌─size─────┐
│ 4.00 GiB │
└──────────┘
이제 간단한 dictGet FUNCTION으로 특정 PostId에 대한 찬반 투표 수를 조회할 수 있습니다. 아래에서는 게시물 11227902에 대한 값을 조회합니다.
SELECT dictGet('votes_dict', ('UpVotes', 'DownVotes'), '11227902') AS votes
┌─votes──────┐
│ (34999,32) │
└────────────┘
Exploiting this in our earlier query, we can remove the JOIN:
WITH PostIds AS
(
SELECT Id
FROM posts
WHERE Title ILIKE '%SQL%'
)
SELECT Id, Title,
dictGet('votes_dict', 'UpVotes', Id) AS UpVotes,
dictGet('votes_dict', 'DownVotes', Id) AS DownVotes,
abs(UpVotes - DownVotes) AS Controversial_ratio
FROM posts
WHERE (Id IN (PostIds)) AND (UpVotes > 10) AND (DownVotes > 10)
ORDER BY Controversial_ratio ASC
LIMIT 3
3 rows in set. Elapsed: 0.551 sec. Processed 119.64 million rows, 3.29 GB (216.96 million rows/s., 5.97 GB/s.)
Peak memory usage: 552.26 MiB.
이 쿼리는 훨씬 더 단순할 뿐만 아니라, 속도도 두 배 이상 빠릅니다! 이를 추가로 최적화하려면 찬성/반대 표가 10개를 초과하는 게시글만 딕셔너리에 로드하고, 미리 계산된 논쟁성 지표 값만 저장하도록 할 수 있습니다.
쿼리 시점 보강
딕셔너리는 쿼리 시점에 값을 조회하는 데 사용할 수 있습니다. 이렇게 조회한 값은 결과에 포함하거나 집계에 활용할 수 있습니다. 예를 들어, 사용자 ID를 위치 정보에 매핑하는 딕셔너리를 생성한다고 가정해 보십시오:
CREATE DICTIONARY users_dict
(
`Id` Int32,
`Location` String
)
PRIMARY KEY Id
SOURCE(CLICKHOUSE(QUERY 'SELECT Id, Location FROM stackoverflow.users'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
이 딕셔너리를 사용하여 포스트 결과를 풍부하게 만들 수 있습니다:
SELECT
Id,
Title,
dictGet('users_dict', 'Location', CAST(OwnerUserId, 'UInt64')) AS location
FROM posts
WHERE Title ILIKE '%clickhouse%'
LIMIT 5
FORMAT PrettyCompactMonoBlock
┌───────Id─┬─Title─────────────────────────────────────────────────────────┬─Location──────────────┐
│ 52296928 │ Comparison between two Strings in ClickHouse │ Spain │
│ 52345137 │ How to use a file to migrate data from mysql to a clickhouse? │ 中国江苏省Nanjing Shi │
│ 61452077 │ How to change PARTITION in clickhouse │ Guangzhou, 广东省中国 │
│ 55608325 │ Clickhouse select last record without max() on all table │ Moscow, Russia │
│ 55758594 │ ClickHouse create temporary table │ Perm', Russia │
└──────────┴───────────────────────────────────────────────────────────────┴───────────────────────┘
5 rows in set. Elapsed: 0.033 sec. Processed 4.25 million rows, 82.84 MB (130.62 million rows/s., 2.55 GB/s.)
Peak memory usage: 249.32 MiB.
위의 조인 예제와 마찬가지로 동일한 딕셔너리를 사용하여 대부분의 게시물이 주로 어디에서 작성되는지 효율적으로 파악할 수 있습니다.
SELECT
dictGet('users_dict', 'Location', CAST(OwnerUserId, 'UInt64')) AS location,
count() AS c
FROM posts
WHERE location != ''
GROUP BY location
ORDER BY c DESC
LIMIT 5
┌─location───────────────┬──────c─┐
│ India │ 787814 │
│ Germany │ 685347 │
│ United States │ 595818 │
│ London, United Kingdom │ 538738 │
│ United Kingdom │ 537699 │
└────────────────────────┴────────┘
5 rows in set. Elapsed: 0.763 sec. Processed 59.82 million rows, 239.28 MB (78.40 million rows/s., 313.60 MB/s.)
Peak memory usage: 248.84 MiB.
인덱싱 시점 보강
위 예제에서는 조인을 제거하기 위해 쿼리 시점에 딕셔너리를 사용했습니다. 딕셔너리는 삽입 시점에 행을 보강하는 데에도 사용할 수 있습니다. 보강 값이 변경되지 않고, 딕셔너리를 채우는 데 사용할 수 있는 외부 소스에 존재하는 경우에 일반적으로 적합합니다. 이 경우 삽입 시점에 행을 보강하면, 쿼리 시점에 딕셔너리를 조회할 필요가 없어집니다.
Stack Overflow에서 사용자의 Location이 절대 변하지 않는다고 가정해 보겠습니다(실제로는 그렇지 않습니다). 구체적으로는 users 테이블의 Location 컬럼입니다. 위치별로 posts 테이블에 대해 분석 쿼리를 수행하려고 한다고 가정합니다. 이 테이블에는 UserId가 포함되어 있습니다.
딕셔너리는 users 테이블을 기반으로 사용자 ID에서 위치로의 매핑을 제공합니다:
CREATE DICTIONARY users_dict
(
`Id` UInt64,
`Location` String
)
PRIMARY KEY Id
SOURCE(CLICKHOUSE(QUERY 'SELECT Id, Location FROM users WHERE Id >= 0'))
LIFETIME(MIN 600 MAX 900)
LAYOUT(HASHED())
Id < 0인 사용자는 제외합니다. 이렇게 하면 Hashed 딕셔너리 타입을 사용할 수 있습니다. Id < 0인 사용자는 시스템 사용자입니다.
posts 테이블에 데이터를 삽입할 때 이 딕셔너리를 활용하려면 스키마를 수정해야 합니다:
CREATE TABLE posts_with_location
(
`Id` UInt32,
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
...
`Location` MATERIALIZED dictGet(users_dict, 'Location', OwnerUserId::'UInt64')
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate), CommentCount)
위 예제에서 Location은 MATERIALIZED 컬럼으로 선언되어 있습니다. 이는 값이 INSERT 쿼리의 일부로 제공될 수도 있으며, 항상 계산된다는 의미입니다.
ClickHouse는 DEFAULT 컬럼도 지원합니다(값을 직접 넣을 수도 있고, 제공되지 않은 경우 계산하여 사용할 수도 있습니다).
테이블에 데이터를 채우기 위해 S3에서 일반적인 INSERT INTO SELECT를 사용할 수 있습니다:
INSERT INTO posts_with_location SELECT Id, PostTypeId::UInt8, AcceptedAnswerId, CreationDate, Score, ViewCount, Body, OwnerUserId, OwnerDisplayName, LastEditorUserId, LastEditorDisplayName, LastEditDate, LastActivityDate, Title, Tags, AnswerCount, CommentCount, FavoriteCount, ContentLicense, ParentId, CommunityOwnedDate, ClosedDate FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
0 rows in set. Elapsed: 36.830 sec. Processed 238.98 million rows, 2.64 GB (6.49 million rows/s., 71.79 MB/s.)
이제 대부분의 게시물이 생성되는 위치 이름을 확인할 수 있습니다.
SELECT Location, count() AS c
FROM posts_with_location
WHERE Location != ''
GROUP BY Location
ORDER BY c DESC
LIMIT 4
┌─Location───────────────┬──────c─┐
│ India │ 787814 │
│ Germany │ 685347 │
│ United States │ 595818 │
│ London, United Kingdom │ 538738 │
└────────────────────────┴────────┘
4 rows in set. Elapsed: 0.142 sec. Processed 59.82 million rows, 1.08 GB (420.73 million rows/s., 7.60 GB/s.)
Peak memory usage: 666.82 MiB.
딕셔너리 고급 주제
딕셔리 LAYOUT 선택
LAYOUT 절은 딕셔리의 내부 데이터 구조를 제어합니다. 여러 가지 옵션이 있으며 여기에 정리되어 있습니다. 적절한 레이아웃을 선택하는 데 도움이 되는 몇 가지 팁은 여기에서 확인할 수 있습니다.
딕셔너리 갱신
딕셔너리에 MIN 600 MAX 900의 LIFETIME을 지정했습니다. LIFETIME은 딕셔너리의 업데이트 주기이며, 여기서 지정한 값에 따라 600초에서 900초 사이의 임의의 간격으로 주기적으로 다시 로드됩니다. 이러한 임의의 간격은 많은 수의 서버에서 업데이트를 수행할 때 딕셔너리 소스에 가해지는 부하를 분산하기 위해 필요합니다. 업데이트 중에도 기존 버전의 딕셔너리는 계속 쿼리할 수 있으며, 최초 로드 시에만 쿼리가 차단됩니다. (LIFETIME(0))으로 설정하면 딕셔너리가 업데이트되지 않음을 유의하십시오.
SYSTEM RELOAD DICTIONARY 명령을 사용하여 딕셔너리를 강제로 다시 로드할 수 있습니다.
ClickHouse와 Postgres 같은 데이터베이스 소스의 경우, 주기적인 간격이 아니라 실제로 변경되었을 때만 딕셔너리를 업데이트하도록 쿼리를 설정할 수 있습니다(해당 쿼리의 응답이 이를 결정합니다). 자세한 내용은 여기를 참조하십시오.
기타 딕셔너리 유형
ClickHouse는 계층형(Hierarchical), 폴리곤(Polygon), 정규 표현식(Regular Expression) 딕셔너리도 지원합니다.
추가 참고 자료