컬럼형 데이터베이스란 무엇인가?
컬럼형 데이터베이스는 각 컬럼의 데이터를 독립적으로 저장합니다. 이를 통해 특정 쿼리에서 사용되는 컬럼의 데이터만 디스크에서 읽을 수 있습니다. 그 대가로, 전체 행에 영향을 미치는 연산의 비용은 그에 비례해 더 커집니다. 컬럼형 데이터베이스는 컬럼 지향 데이터베이스 관리 시스템이라고도 합니다. ClickHouse는 이러한 시스템의 전형적인 예입니다.
컬럼형 데이터베이스의 주요 장점은 다음과 같습니다:
- 많은 컬럼 중 일부 컬럼만 사용하는 쿼리
- 대용량 데이터에 대한 집계 쿼리
- 컬럼 단위 데이터 압축
다음은 보고서를 생성할 때 전통적인 행 지향 시스템과 컬럼형 데이터베이스의 차이를 보여 주는 그림입니다:
전통적인 행 지향
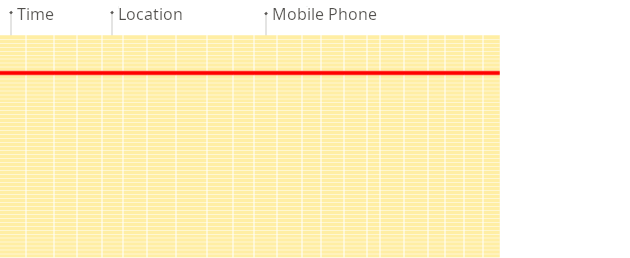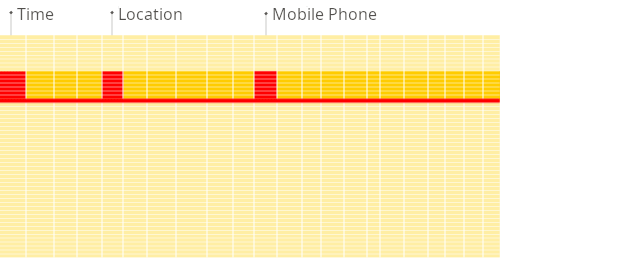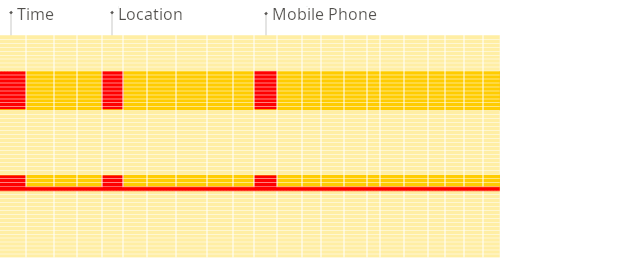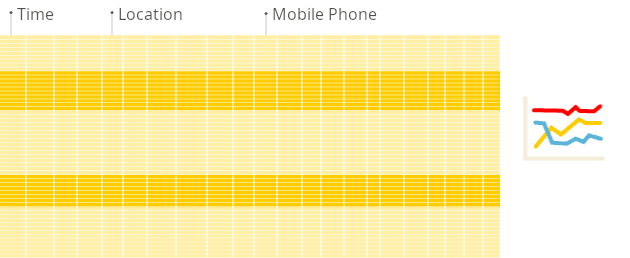
컬럼형
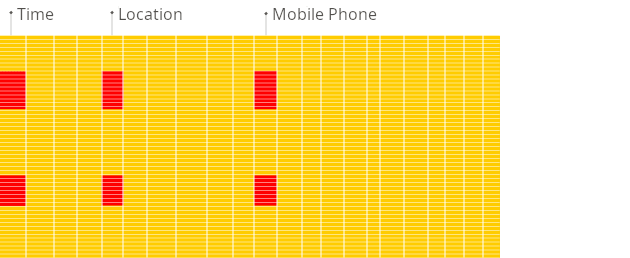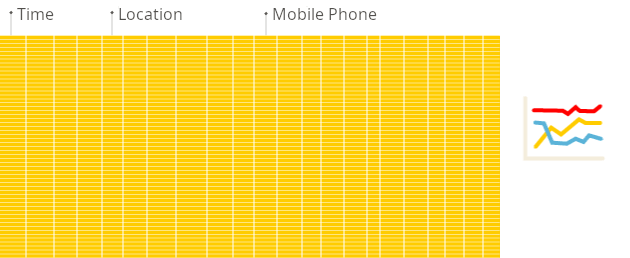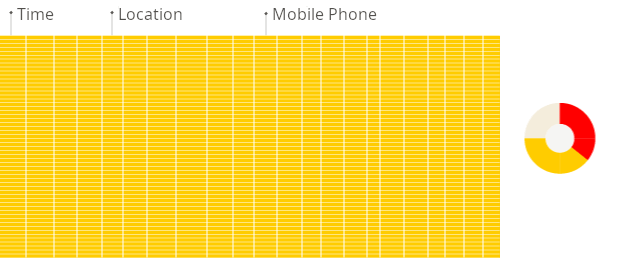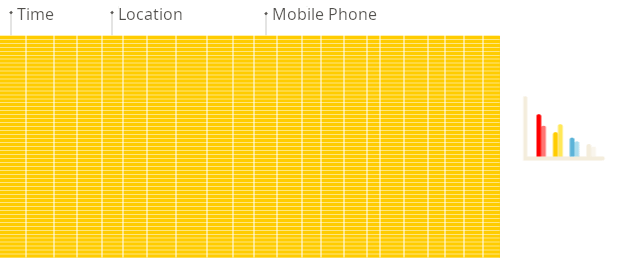
컬럼형 데이터베이스는 분석 애플리케이션에서 우선적으로 선택되는 옵션입니다. 테이블에 많은 컬럼을 「혹시 몰라서」 포함하더라도, 읽기 쿼리를 실행할 때 사용되지 않는 컬럼에 대한 비용을 지불하지 않아도 되기 때문입니다(전통적인 OLTP 데이터베이스는 데이터가 컬럼이 아니라 행 단위로 저장되어 있어 쿼리 시 모든 데이터를 읽습니다). 컬럼 지향 데이터베이스는 빅데이터 처리와 데이터 웨어하우징을 위해 설계되며, 처리량을 높이기 위해 저비용 하드웨어로 구성된 분산 클러스터로 자연스럽게 확장되는 경우가 많습니다. ClickHouse는 distributed 테이블과 replicated 테이블의 조합을 통해 이를 구현합니다.
컬럼형 데이터베이스의 역사, 행 지향 데이터베이스와의 차이, 그리고 컬럼형 데이터베이스의 사용 사례를 자세히 알고 싶다면 컬럼 데이터베이스 가이드를 참고하십시오.
