ClickHouse 데이터 삽입
ClickHouse에 데이터 삽입하기 vs. OLTP 데이터베이스에 삽입하기
OLAP(Online Analytical Processing) 데이터베이스인 ClickHouse는 높은 성능과 확장성을 위해 최적화되어 있어 초당 잠재적으로 수백만 개의 행을 삽입할 수 있습니다. 이는 고도로 병렬화된 아키텍처와 효율적인 컬럼 지향 압축의 조합을 통해 달성되지만, 그 대가로 즉시 일관성(immediate consistency)은 일부 포기합니다. 보다 구체적으로, ClickHouse는 추가 전용(append-only) 작업에 최적화되어 있으며, 최종적 일관성(eventual consistency)만을 보장합니다.
반대로 Postgres와 같은 OLTP 데이터베이스는 트랜잭션 삽입에 특화되어 최적화되어 있으며, 완전한 ACID 준수를 통해 강력한 일관성과 신뢰성을 보장합니다. PostgreSQL은 동시에 발생하는 트랜잭션을 처리하기 위해 MVCC(Multi-Version Concurrency Control)를 사용하며, 이는 데이터의 여러 버전을 유지하는 방식을 의미합니다. 이러한 트랜잭션은 한 번에 소수의 행만을 포함하는 경우가 많고, 신뢰성 보장을 위해 삽입 성능이 제한되면서 상당한 오버헤드가 발생할 수 있습니다.
높은 삽입 성능을 달성하면서도 강력한 일관성 보장을 유지하려면 ClickHouse에 데이터를 삽입할 때 아래에 설명된 간단한 규칙을 따라야 합니다. 이러한 규칙을 따르면 사용자가 처음 ClickHouse를 사용할 때 흔히 겪는 문제를 피하고, OLTP 데이터베이스에서 사용하던 삽입 전략을 그대로 복제하려다 발생하는 문제를 예방하는 데 도움이 됩니다.
INSERT 작업 모범 사례
큰 배치 크기로 Insert 수행
기본적으로 ClickHouse로 전송되는 각 insert는, insert된 데이터와 함께 저장해야 하는 기타 메타데이터를 포함하는 저장소 파트(part)를 ClickHouse가 즉시 생성하도록 합니다. 따라서 한 번에 적은 횟수의 insert에 더 많은 데이터를 담아 보내는 것이, 적은 데이터를 담은 insert를 더 자주 보내는 것보다 필요한 쓰기 횟수를 줄이는 데 도움이 됩니다. 일반적으로 한 번에 최소 1,000개의 행 이상을 포함하는 충분히 큰 배치로 데이터를 insert할 것을 권장하며, 이상적인 배치 크기는 10,000개에서 100,000개 행 사이입니다. (자세한 내용은 여기를 참조하십시오).
큰 배치를 사용하는 것이 불가능한 경우, 아래에 설명된 비동기 insert를 사용하십시오.
멱등 재시도를 위한 일관된 배치 유지
기본적으로 ClickHouse로의 insert는 동기식이며 멱등적입니다(즉, 동일한 insert 작업을 여러 번 수행해도 한 번 수행한 것과 동일한 효과만 발생합니다). MergeTree 엔진 계열 테이블의 경우 ClickHouse는 기본적으로 자동으로 insert 중복 제거(deduplication)를 수행합니다.
이는 다음과 같은 상황에서도 insert가 신뢰성 있게 동작함을 의미합니다:
-
- 데이터를 수신하는 노드에 문제가 있는 경우, insert 쿼리는 타임아웃되거나(또는 더 구체적인 오류를 반환하고) 확인 응답을 받지 못합니다.
-
- 노드가 데이터를 기록했지만 네트워크 단절로 인해 쿼리 전송자에게 확인 응답을 반환할 수 없는 경우, 전송자는 타임아웃 또는 네트워크 오류를 받게 됩니다.
클라이언트 관점에서는 (1)과 (2)를 구분하기 어려울 수 있습니다. 그러나 두 경우 모두 확인되지 않은 insert는 즉시 재시도할 수 있습니다. 재시도된 insert 쿼리에 동일한 순서로 동일한 데이터가 포함되어 있기만 하면, (확인되지 않은) 원래 insert가 성공한 경우 ClickHouse는 재시도된 insert를 자동으로 무시합니다.
MergeTree 테이블 또는 분산 테이블로 Insert 수행
데이터가 샤딩되어 있는 경우 노드 집합에 걸쳐 요청을 분산시키고 internal_replication=true를 설정한 상태에서 MergeTree(또는 복제된 테이블(Replicated table))에 직접 Insert할 것을 권장합니다.
이렇게 하면 ClickHouse가 사용 가능한 레플리카 세그먼트에 데이터를 복제하고, 궁극적으로 데이터의 일관성이 보장되도록 합니다.
클라이언트 측 로드 밸런싱이 불편한 경우 분산 테이블을 통해 Insert를 수행할 수 있으며, 이 경우 쓰기가 노드 전체에 분산됩니다. 이때도 internal_replication=true로 설정하는 것이 좋습니다.
다만 이 방식은 분산 테이블이 존재하는 노드에서 먼저 로컬로 쓰기를 수행한 다음 각 세그먼트로 전송해야 하므로, 성능이 다소 낮을 수 있다는 점을 유의해야 합니다.
소규모 배치에는 비동기 insert를 사용하십시오
클라이언트 측 배치가 불가능한 시나리오가 있습니다. 예를 들어, 수백~수천 개의 단일 용도 에이전트가 로그, 메트릭, 트레이스를 전송하는 관측성 사용 사례입니다. 이러한 시나리오에서는 가능한 한 빠르게 문제와 이상 징후를 탐지하기 위해 해당 데이터를 실시간으로 전송하는 것이 중요합니다. 또한 관측 대상 시스템에서 이벤트 스파이크가 발생할 수 있으며, 이는 클라이언트 측에서 관측성 데이터를 버퍼링하려 할 때 큰 메모리 스파이크와 그에 따른 문제를 야기할 수 있습니다. 대규모 배치를 한 번에 insert할 수 없다면, asynchronous inserts를 사용하여 배치 작업을 ClickHouse에 위임할 수 있습니다.
비동기 insert에서는, 아래 다이어그램에서 보는 것처럼 데이터가 먼저 버퍼에 insert되고 이후 3단계를 거쳐 데이터베이스 스토리지에 기록됩니다:
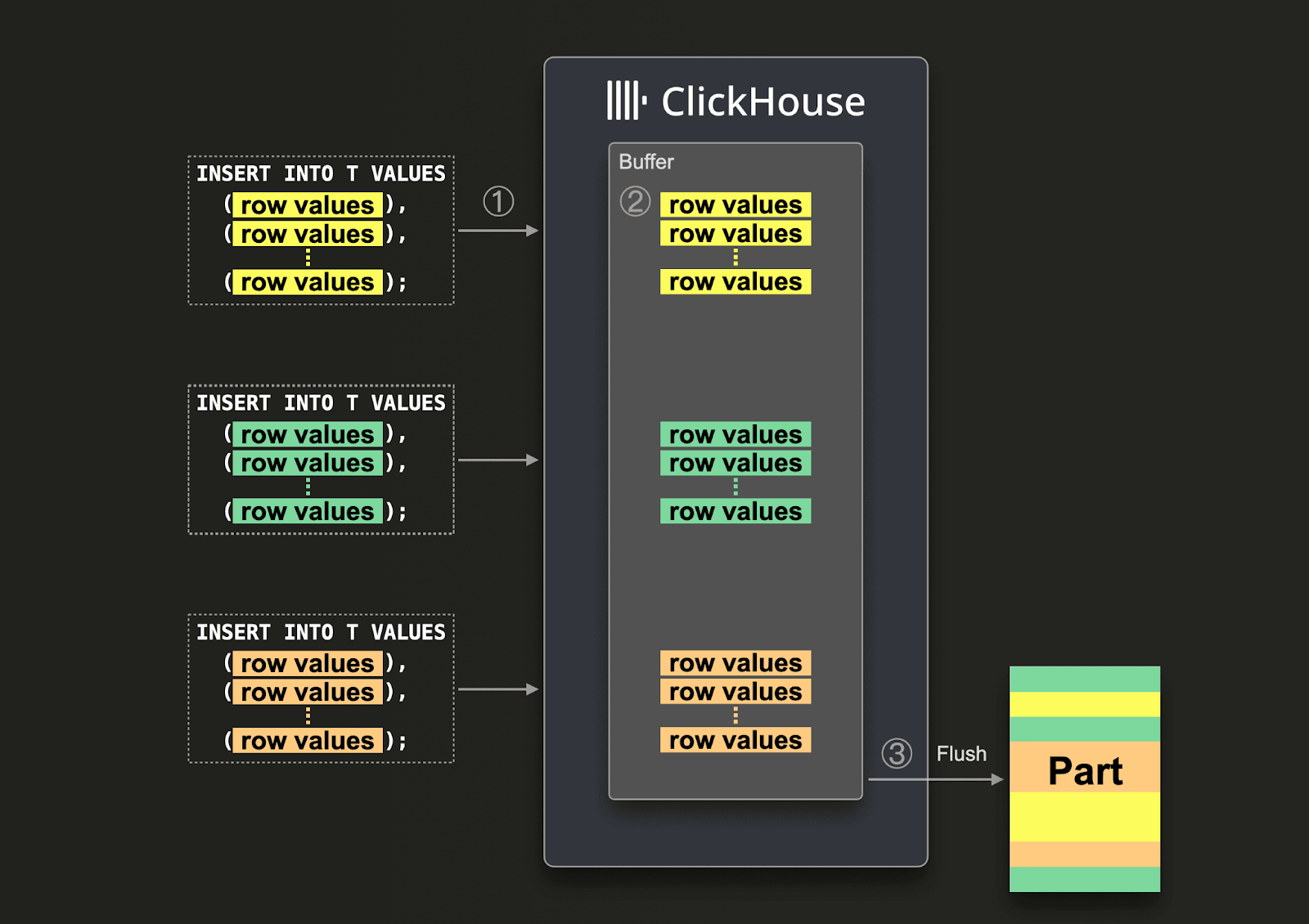
비동기 insert가 활성화된 경우 ClickHouse는 다음과 같이 동작합니다:
(1) insert 쿼리를 비동기적으로 수신합니다. (2) 쿼리의 데이터를 먼저 메모리 내(in-memory) 버퍼에 기록합니다. (3) 다음 버퍼 플러시가 발생할 때에만 데이터를 정렬하고 파트(part)로 데이터베이스 스토리지에 기록합니다.
버퍼가 플러시되기 전까지는, 동일하거나 다른 클라이언트에서 오는 다른 비동기 insert 쿼리의 데이터가 버퍼에 누적될 수 있습니다. 버퍼 플러시로 생성된 파트는 여러 비동기 insert 쿼리에서 온 데이터를 포함할 수 있습니다. 일반적으로 이러한 메커니즘을 통해 데이터 배치가 클라이언트 측에서 서버 측(ClickHouse 인스턴스)으로 이전됩니다.
공식 ClickHouse 클라이언트 사용
ClickHouse는 가장 널리 사용되는 프로그래밍 언어용 클라이언트를 제공합니다. 이 클라이언트들은 INSERT가 올바르게 수행되도록 최적화되어 있으며, 예를 들어 Go 클라이언트처럼 직접적으로 또는 쿼리, USER, 연결 수준 SETTINGS에서 비동기 INSERT를 활성화했을 때 간접적으로 비동기 INSERT를 네이티브로 지원합니다.
사용 가능한 ClickHouse 클라이언트와 드라이버 전체 목록은 Clients and Drivers를 참조하십시오.
네이티브 포맷을 사용하십시오
ClickHouse는 insert(및 쿼리) 시점에 다양한 입력 포맷을 지원합니다. 이는 OLTP 데이터베이스와의 중요한 차이점으로, table functions 및 디스크에 있는 파일에서 데이터를 로드하는 기능과 결합될 때 외부 소스에서 데이터를 훨씬 쉽게 로드할 수 있게 합니다. 이러한 포맷은 애드혹(ad-hoc) 데이터 로딩 및 데이터 엔지니어링 작업에 이상적입니다.
최적의 insert 성능을 달성하려는 애플리케이션은 Native 포맷을 사용해 insert하는 것이 좋습니다. 이는 대부분의 클라이언트(예: Go 및 Python)에서 지원되며, 이미 컬럼 지향 포맷이므로 서버가 수행해야 하는 작업량을 최소화합니다. 이렇게 하면 데이터를 컬럼 지향 포맷으로 변환하는 책임이 클라이언트 측에 있게 되며, 이는 insert를 효율적으로 확장하는 데 중요합니다.
대안으로, row 기반 포맷을 선호하는 경우(예: Java 클라이언트에서 사용) RowBinary 포맷을 사용할 수 있으며, 일반적으로 Native 포맷보다 쓰기가 더 쉽습니다. 이 포맷은 JSON과 같은 다른 row 기반 포맷보다 압축, 네트워크 오버헤드, 서버에서의 처리 측면에서 더 효율적입니다. 더 낮은 쓰기 처리량 환경에서 빠르게 연동하려는 경우 JSONEachRow 포맷을 고려할 수 있습니다. 이 포맷은 ClickHouse에서 파싱을 위해 CPU 오버헤드를 유발한다는 점을 인지해야 합니다.
HTTP 인터페이스 사용
많은 전통적인 데이터베이스와 달리 ClickHouse는 HTTP 인터페이스를 지원합니다. 위에 언급한 형식은 모두 HTTP 인터페이스를 통해 데이터 삽입과 쿼리에 사용할 수 있습니다. 트래픽을 로드 밸런서를 통해 쉽게 전환할 수 있으므로, 이는 ClickHouse의 기본(native) 프로토콜보다 더 선호되는 경우가 많습니다. 기본 프로토콜은 오버헤드가 약간 더 적으므로, 삽입 성능에서 작은 차이가 발생할 것으로 예상합니다. 기존 클라이언트는 이러한 프로토콜 중 하나(일부 경우 둘 다, 예: Go 클라이언트)를 사용합니다. 기본 프로토콜을 사용하면 쿼리 진행 상황을 쉽게 추적할 수 있습니다.
자세한 내용은 HTTP Interface를 참고하십시오.
기본 예제
ClickHouse에서도 익숙한 INSERT INTO TABLE 명령을 사용할 수 있습니다. 시작 가이드 "Creating Tables in ClickHouse"에서 만든 테이블에 데이터를 삽입해 보겠습니다.
정상적으로 동작하는지 확인하기 위해 다음 SELECT 쿼리를 실행합니다:
다음이 반환됩니다:
Postgres에서 데이터 적재
Postgres에서 데이터를 적재하려면 다음 방법을 사용할 수 있습니다:
- PostgreSQL 데이터베이스 복제를 위해 특별히 설계된 ETL 도구인
ClickPipes를 사용할 수 있습니다. 다음 두 가지 방식으로 제공됩니다.- ClickHouse Cloud - ClickPipes의 관리형 수집 서비스를 통해 사용할 수 있습니다.
- 자가 관리형 - PeerDB 오픈소스 프로젝트를 통해 사용할 수 있습니다.
- 이전 예시에서와 같이 데이터를 직접 읽기 위한 PostgreSQL table engine을 사용할 수 있습니다. 일반적으로 알려진 워터마크(예: timestamp)를 기반으로 한 배치 복제가 충분한 경우나 일회성 마이그레이션인 경우에 적합합니다. 이 접근 방식은 수천만 행까지 확장할 수 있습니다. 더 큰 데이터 세트를 마이그레이션하려는 사용자는 요청을 여러 개로 나누어 각 요청이 데이터의 하나의 청크를 처리하도록 하는 것이 좋습니다. 중간 테이블을 사용해 각 청크를 최종 테이블로 파티션을 이동하기 전에 보관할 수 있습니다. 이렇게 하면 실패한 요청을 재시도할 수 있습니다. 이러한 대량 적재 전략에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
- PostgreSQL에서 데이터를 CSV 형식으로 내보낸 후, 로컬 파일에서 직접 또는 table function을 사용해 객체 스토리지를 통해 ClickHouse에 삽입할 수 있습니다.
대용량 데이터 세트를 삽입해야 하거나 ClickHouse Cloud로 데이터를 가져오는 중 오류가 발생하는 경우 support@clickhouse.com 으로 문의하면 도움을 받을 수 있습니다.
커맨드라인에서 데이터 삽입하기
사전 준비사항
- ClickHouse를 설치했음
clickhouse-server가 실행 중임wget,zcat,curl을 사용할 수 있는 터미널에 접근할 수 있음
이 예제에서는 커맨드라인에서 배치 모드의 clickhouse-client를 사용하여 CSV 파일을 ClickHouse에 삽입하는 방법을 보여줍니다. 배치 모드의 clickhouse-client를 사용해 커맨드라인으로 데이터를 삽입하는 추가 정보와 예제는 「Batch mode」를 참고하십시오.
이 예제에서는 2,800만 행의 Hacker News 데이터를 포함한 Hacker News 데이터세트를 사용합니다.
CSV 다운로드
다음 명령을 실행하여 공개 S3 버킷에서 이 데이터세트의 CSV 버전을 다운로드합니다.
이 압축 파일은 크기 4.6GB, 2,800만 행으로, 다운로드에 약 5~10분 정도 소요됩니다.
테이블 생성
clickhouse-server가 실행 중인 상태에서, 다음 스키마를 사용해 배치 모드의 clickhouse-client로 커맨드라인에서 바로 빈 테이블을 생성할 수 있습니다.
오류가 없다면 테이블이 성공적으로 생성된 것입니다. 위 명령에서 heredoc 구분자(_EOF)를 작은따옴표로 감싼 것은 어떠한 치환도 일어나지 않도록 하기 위함입니다. 작은따옴표가 없으면 컬럼 이름을 감싸는 백틱을 이스케이프해야 합니다.
커맨드라인에서 데이터 삽입
다음으로, 이전에 다운로드한 파일에서 데이터를 테이블에 삽입하려면 아래 명령을 실행합니다.
데이터가 압축되어 있으므로, 먼저 gzip, zcat 등의 도구를 사용해 파일 압축을 해제한 후, 적절한 INSERT 문과 FORMAT을 사용하여 압축 해제된 데이터를 clickhouse-client로 파이프해야 합니다.
대화형 모드의 clickhouse-client로 데이터를 삽입할 때는 COMPRESSION 절을 사용해, 삽입 시 ClickHouse가 자동으로 압축 해제를 처리하도록 할 수 있습니다. ClickHouse는 파일 확장자에서 압축 형식을 자동으로 감지할 수 있으며, 명시적으로 지정하는 것도 가능합니다.
삽입 쿼리는 다음과 같은 형태가 됩니다.
데이터 삽입이 완료되면 hackernews 테이블의 행 개수를 확인하기 위해 다음 명령을 실행할 수 있습니다.
curl을 사용한 커맨드라인 데이터 삽입
앞 단계에서는 wget을 사용해 먼저 CSV 파일을 로컬 머신으로 다운로드했습니다. 원격 URL에서 단일 명령으로 데이터를 직접 삽입하는 것도 가능합니다.
로컬 머신으로 다운로드하는 중간 단계를 거치지 않고 다시 삽입할 수 있도록 hackernews 테이블의 데이터를 비우려면 다음 명령을 실행합니다.
이제 다음을 실행합니다.
이제 이전과 동일한 명령을 실행하여 데이터가 다시 삽입되었는지 확인할 수 있습니다.
