스키마 추론을 사용하면 JSON 데이터에 대한 초기 스키마를 정의하고, 예를 들어 S3에 있는 JSON 데이터 파일에 그대로 쿼리를 실행할 수 있습니다. 그러나 데이터에는 최적화된 버전 관리 스키마를 마련하는 것이 좋습니다. 아래에서 JSON 구조를 모델링하기 위한 권장 접근 방식을 설명합니다.
정적 JSON과 동적 JSON
JSON에 대한 스키마를 정의할 때의 핵심 작업은 각 키의 값에 대한 적절한 타입을 결정하는 것입니다. JSON 계층 구조의 각 키에 다음 규칙을 재귀적으로 적용하여 각 키의 적절한 타입을 결정하는 것이 좋습니다.
- 원시 타입(primitive types) - 키의 값이 하위 객체의 일부인지, 루트에 위치하는지와 상관없이 원시 타입인 경우, 일반적인 스키마 설계 모범 사례와 타입 최적화 규칙에 따라 타입을 선택해야 합니다. 아래
phone_numbers와 같은 원시 타입의 배열은 Array(<type>), 예를 들어 Array(String)으로 모델링할 수 있습니다.
- 정적 vs 동적 - 키의 값이 복합 객체, 즉 객체이거나 객체 배열인 경우 해당 값의 구조가 변경될 가능성이 있는지 판단해야 합니다. 새로운 키가 거의 추가되지 않고, 새로운 키의 추가를 예측할 수 있으며
ALTER TABLE ADD COLUMN을 통한 스키마 변경으로 처리할 수 있는 객체는 정적(static) 으로 간주할 수 있습니다. 여기에는 일부 JSON 문서에서만 키의 부분 집합이 제공되는 객체도 포함됩니다. 새로운 키가 자주 추가되거나 예측할 수 없는 객체는 동적(dynamic) 으로 간주해야 합니다. 예외적으로, 수백 개 또는 수천 개의 하위 키를 가진 구조는 편의상 동적인 것으로 간주할 수 있습니다.
값이 정적(static) 인지 동적(dynamic) 인지 판별하려면 아래의 관련 섹션인 정적 객체 처리 및 동적 객체 처리를 참조하십시오.
중요: 위의 규칙은 재귀적으로 적용해야 합니다. 키의 값이 동적인 것으로 판단되면 더 이상의 평가가 필요 없으며 동적 객체 처리의 지침을 따르면 됩니다. 객체가 정적인 경우, 키 값이 원시 타입이 되거나 동적 키가 발견될 때까지 하위 키를 계속 평가해야 합니다.
이 규칙들을 설명하기 위해 사람을 표현하는 다음 JSON 예제를 사용합니다:
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics",
"labels": {
"type": "database systems",
"founded": "2021"
}
},
"dob": "2007-03-31",
"tags": {
"hobby": "Databases",
"holidays": [
{
"year": 2024,
"location": "Azores, Portugal"
}
],
"car": {
"model": "Tesla",
"year": 2023
}
}
}
이 규칙을 적용하면 다음과 같습니다:
- 루트 키
name, username, email, website는 String 타입으로 표현할 수 있습니다. 컬럼 phone_numbers는 Array(String) 타입의 Array 기본 타입이며, dob와 id는 각각 Date와 UInt32 타입입니다.
- 새로운 키는
address 객체에 추가되지 않고(새로운 address 객체만 추가되므로) 이 객체는 정적이라고 볼 수 있습니다. 재귀적으로 탐색하면, geo를 제외한 모든 하위 컬럼은 기본 타입(그리고 String 타입)으로 간주할 수 있습니다. geo 또한 lat과 lon 두 개의 Float32 컬럼을 가진 정적 구조입니다.
tags 컬럼은 동적입니다. 이 객체에는 임의의 타입과 구조를 가진 새로운 태그가 추가될 수 있다고 가정합니다.company 객체는 정적이며, 항상 최대 3개의 지정된 키만 포함합니다. 하위 키 name과 catchPhrase는 String 타입입니다. 키 labels는 동적입니다. 이 객체에 임의의 새로운 태그가 추가될 수 있다고 가정합니다. 값은 항상 문자열 타입의 key-value 쌍입니다.
참고
수백 또는 수천 개의 정적 키를 가진 구조체는, 이러한 키들에 대해 컬럼을 정적으로 선언하는 것이 현실적이지 않은 경우가 많기 때문에 동적 구조로 간주할 수 있습니다. 다만 가능하다면 저장 공간과 추론 오버헤드를 모두 줄이기 위해 필요하지 않은 skip paths는 생략하십시오.
정적 구조 처리
정적 구조는 명시적인 튜플 타입인 Tuple을 사용해 처리할 것을 권장합니다. 객체 배열은 Array(Tuple)과 같이 튜플의 배열로 저장할 수 있습니다. 튜플 내부에서도 컬럼과 해당 타입은 동일한 규칙으로 정의해야 합니다. 이렇게 하면 아래와 같이 중첩 객체를 표현하기 위해 중첩된 Tuple을 사용할 수 있습니다.
이를 설명하기 위해, 이전에 사용한 JSON person 예시에서 동적 객체를 제외한 형태를 사용합니다.
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics"
},
"dob": "2007-03-31"
}
이 테이블의 스키마는 다음과 같습니다.
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String),
`dob` Date
)
ENGINE = MergeTree
ORDER BY username
company 컬럼이 Tuple(catchPhrase String, name String)으로 정의되어 있다는 점에 주목하십시오. address 키는 Array(Tuple)을 사용하며, 중첩된 Tuple로 geo 컬럼을 나타냅니다.
현재 구조 그대로 이 테이블에 JSON 데이터를 삽입할 수 있습니다:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
위의 예시에서는 데이터가 매우 적지만, 아래와 같이 마침표로 구분된 이름을 사용해 튜플 컬럼을 쿼리할 수 있습니다.
SELECT
address.street,
company.name
FROM people
┌─address.street────┬─company.name─┐
│ ['Victor Plains'] │ ClickHouse │
└───────────────────┴──────────────┘
address.street 컬럼이 Array로 반환되는 점에 유의하십시오. 배열 안의 특정 요소를 위치로 쿼리하려면 배열 오프셋을 컬럼 이름 뒤에 지정해야 합니다. 예를 들어 첫 번째 주소의 street에 접근하려면 다음과 같이 합니다.
SELECT address.street[1] AS street
FROM people
┌─street────────┐
│ Victor Plains │
└───────────────┘
1 row in set. Elapsed: 0.001 sec.
서브 컬럼은 24.12부터 정렬 키에서도 사용할 수 있습니다:
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String),
`dob` Date
)
ENGINE = MergeTree
ORDER BY company.name
기본값 처리
JSON 객체의 구조가 정해져 있더라도, 실제로는 알려진 키의 일부만 포함된 희소한 형태인 경우가 자주 있습니다. 다행히 Tuple 타입은 JSON 페이로드에 모든 컬럼이 포함될 필요는 없습니다. 값이 제공되지 않으면 기본값이 사용됩니다.
앞에서 살펴본 people 테이블과, suite, geo, phone_numbers, catchPhrase 키가 누락된 다음의 희소한 JSON을 생각해 보십시오.
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"city": "Wisokyburgh",
"zipcode": "90566-7771"
}
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse"
},
"dob": "2007-03-31"
}
아래와 같이 이 행이 성공적으로 삽입된 것을 확인할 수 있습니다:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","city":"Wisokyburgh","zipcode":"90566-7771"}],"website":"clickhouse.com","company":{"name":"ClickHouse"},"dob":"2007-03-31"}
Ok.
1 row in set. Elapsed: 0.002 sec.
이 단일 행을 조회하면, 생략된 컬럼(하위 객체 포함)에 기본값이 사용된 것을 확인할 수 있습니다:
SELECT *
FROM people
FORMAT PrettyJSONEachRow
{
"id": "1",
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"city": "Wisokyburgh",
"geo": {
"lat": 0,
"lng": 0
},
"street": "Victor Plains",
"suite": "",
"zipcode": "90566-7771"
}
],
"phone_numbers": [],
"website": "clickhouse.com",
"company": {
"catchPhrase": "",
"name": "ClickHouse"
},
"dob": "2007-03-31"
}
1 row in set. Elapsed: 0.001 sec.
빈 값과 null 구분하기
값이 비어 있는 경우와 아예 제공되지 않은 경우를 구분해야 한다면 널 허용(Nullable) 타입을 사용할 수 있습니다. 그러나 이 타입은 해당 컬럼의 저장 및 쿼리 성능에 부정적인 영향을 주므로, 반드시 필요한 경우가 아니라면 사용을 피해야 합니다.
새로운 컬럼 처리
JSON 키가 고정되어 있을 때는 구조화된 접근 방식이 가장 간단하지만, 스키마 변경을 미리 계획할 수 있다면(예: 새로운 키를 사전에 알고 있고 그에 따라 스키마를 수정할 수 있는 경우) 이 접근 방식을 계속 사용할 수 있습니다.
기본적으로 ClickHouse는 페이로드에 포함되어 있으나 스키마에 존재하지 않는 JSON 키를 무시한다는 점에 유의하십시오. nickname 키가 추가된 다음 수정된 JSON 페이로드를 살펴보십시오:
{
"id": 1,
"name": "Clicky McCliickHouse",
"nickname": "Clicky",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics"
},
"dob": "2007-03-31"
}
이 JSON은 nickname 키를 무시한 채로도 성공적으로 삽입됩니다:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
Ok.
1 row in set. Elapsed: 0.002 sec.
ALTER TABLE ADD COLUMN 명령을 사용하여 스키마에 컬럼을 추가할 수 있습니다. DEFAULT 절을 통해 기본값을 지정할 수 있으며, 이후 INSERT 시 해당 컬럼 값이 지정되지 않으면 이 기본값이 사용됩니다. 해당 값이 존재하지 않는 행(컬럼이 생성되기 이전에 삽입된 행)도 이 기본값을 반환합니다. DEFAULT 값이 지정되지 않으면 해당 타입의 기본값이 사용됩니다.
예를 들어:
-- insert initial row (nickname will be ignored)
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
-- add column
ALTER TABLE people
(ADD COLUMN `nickname` String DEFAULT 'no_nickname')
-- insert new row (same data different id)
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
-- select 2 rows
SELECT id, nickname FROM people
┌─id─┬─nickname────┐
│ 2 │ Clicky │
│ 1 │ no_nickname │
└────┴─────────────┘
2 rows in set. Elapsed: 0.001 sec.
반정형/동적 구조 처리
키가 동적으로 추가되거나 여러 타입을 가질 수 있는 반정형 JSON 데이터인 경우 JSON 타입을 사용하는 것을 권장합니다.
보다 구체적으로, 데이터가 다음과 같은 경우 JSON 타입을 사용합니다:
- 시간이 지나면서 변경될 수 있는 예측 불가능한 키를 가집니다.
- 다양한 타입의 값을 포함합니다(예: 어떤 경로에는 때로는 문자열, 때로는 숫자가 들어갈 수 있음).
- 엄격한 타입 지정을 적용하기 어려워 스키마의 유연성이 필요합니다.
- 정적이긴 하지만 현실적으로 일일이 명시적으로 선언하기 어려운 수백 개 또는 수천 개의 경로를 가지고 있습니다. 이러한 경우는 드문 편입니다.
company.labels 객체가 동적인 것으로 판단되었던 앞에서 사용한 person JSON을 다시 고려해 보겠습니다.
company.labels에 임의의 키가 포함된다고 가정해 보겠습니다. 또한, 이 구조 내의 어떤 키에 대해서도 행(row)마다 타입이 일관되지 않을 수 있습니다. 예를 들어:
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics",
"labels": {
"type": "database systems",
"founded": "2021",
"employees": 250
}
},
"dob": "2007-03-31",
"tags": {
"hobby": "Databases",
"holidays": [
{
"year": 2024,
"location": "Azores, Portugal"
}
],
"car": {
"model": "Tesla",
"year": 2023
}
}
}
{
"id": 2,
"name": "Analytica Rowe",
"username": "Analytica",
"address": [
{
"street": "Maple Avenue",
"suite": "Apt. 402",
"city": "Dataford",
"zipcode": "11223-4567",
"geo": {
"lat": 40.7128,
"lng": -74.006
}
}
],
"phone_numbers": [
"123-456-7890",
"555-867-5309"
],
"website": "fastdata.io",
"company": {
"name": "FastData Inc.",
"catchPhrase": "Streamlined analytics at scale",
"labels": {
"type": [
"real-time processing"
],
"founded": 2019,
"dissolved": 2023,
"employees": 10
}
},
"dob": "1992-07-15",
"tags": {
"hobby": "Running simulations",
"holidays": [
{
"year": 2023,
"location": "Kyoto, Japan"
}
],
"car": {
"model": "Audi e-tron",
"year": 2022
}
}
}
객체 간 company.labels 컬럼의 키와 타입이 동적으로 변하는 특성을 고려하면, 이 데이터를 모델링하는 데에는 여러 가지 방법이 있습니다:
- 단일 JSON 컬럼 - 전체 스키마를 하나의
JSON 컬럼으로 표현하여, 그 아래의 모든 구조를 동적으로 유지합니다.
- 타깃 JSON 컬럼 -
company.labels 컬럼에만 JSON 타입을 사용하고, 나머지 모든 컬럼에는 위에서 사용한 구조화된 스키마를 그대로 유지합니다.
첫 번째 접근 방식은 이전 방법론과는 일치하지 않지만, 단일 JSON 컬럼 방식은 프로토타이핑 및 데이터 엔지니어링 작업에 유용합니다.
대규모 프로덕션 환경에서 ClickHouse를 배포하는 경우, 가능한 한 구조를 구체적으로 정의하고, 필요한 동적 하위 구조에만 JSON 타입을 사용하는 것을 권장합니다.
엄격한 스키마를 사용하면 다음과 같은 여러 이점이 있습니다:
- 데이터 검증 – 엄격한 스키마를 적용하면 특정 구조를 제외한 대부분의 경우 컬럼 폭발 위험을 피할 수 있습니다.
- 컬럼 폭발 위험 회피 - JSON 타입은 서브컬럼이 개별 컬럼으로 저장되므로 잠재적으로 수천 개의 컬럼까지 확장될 수 있지만, 이로 인해 과도한 수의 컬럼 파일이 생성되어 성능에 영향을 주는 컬럼 파일 폭발이 발생할 수 있습니다. 이를 완화하기 위해 JSON에서 사용하는 내부 Dynamic type은 별도 컬럼 파일로 저장되는 고유 경로 수를 제한하는
max_dynamic_paths 파라미터를 제공합니다. 임계값에 도달하면 추가 경로는 압축된 인코딩 형식을 사용하여 공유 컬럼 파일에 저장되어, 유연한 데이터 수집을 지원하면서도 성능과 저장 효율성을 유지합니다. 다만, 이 공유 컬럼 파일에 접근하는 것은 전용 컬럼 파일을 직접 읽는 것만큼 성능이 좋지는 않습니다. 또한 JSON 컬럼은 type hints와 함께 사용할 수 있으며, "힌트"가 적용된 컬럼은 전용 컬럼과 동일한 성능을 제공합니다.
- 경로 및 타입의 단순한 파악 - JSON 타입은 추론된 타입과 경로를 확인하기 위한 introspection functions을 지원하지만,
DESCRIBE와 같은 기능으로 탐색할 때는 정적 구조가 더 단순할 수 있습니다.
단일 JSON 컬럼
이 접근 방식은 프로토타이핑 및 데이터 엔지니어링 작업에 유용합니다. 프로덕션 환경에서는 필요한 경우에만 동적 하위 구조에 JSON을 사용하십시오.
성능 고려사항
단일 JSON 컬럼은 필요하지 않은 JSON 경로를 건너뛰어(저장하지 않고) 최적화할 수 있고, type hints를 사용해 추가로 최적화할 수 있습니다. Type hint를 사용하면 서브 컬럼의 타입을 사용자가 명시적으로 정의할 수 있어, 쿼리 시점에 추론 및 간접 참조(indirection) 처리를 생략합니다. 이를 통해 명시적인 스키마를 사용했을 때와 동일한 성능을 확보할 수 있습니다. 자세한 내용은 「Using type hints and skipping paths」를 참조하십시오.
여기에서 단일 JSON 컬럼에 대한 스키마는 다음과 같이 단순합니다:
SET enable_json_type = 1;
CREATE TABLE people
(
`json` JSON(username String)
)
ENGINE = MergeTree
ORDER BY json.username;
참고
username 컬럼을 정렬/기본 키에 사용하므로 JSON 정의에서 type hint를 제공합니다. 이는 ClickHouse가 이 컬럼이 NULL 값이 아님을 인지하도록 돕고, 어떤 username 서브컬럼을 사용해야 하는지 알 수 있게 합니다(각 타입마다 여러 개가 존재할 수 있어, 그렇지 않으면 모호해집니다).
위 테이블에 행을 삽입하려면 JSONAsObject 포맷을 사용하면 됩니다:
INSERT INTO people FORMAT JSONAsObject
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.028 sec.
INSERT INTO people FORMAT JSONAsObject
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.004 sec.
SELECT *
FROM people
FORMAT Vertical
Row 1:
──────
json: {"address":[{"city":"Dataford","geo":{"lat":40.7128,"lng":-74.006},"street":"Maple Avenue","suite":"Apt. 402","zipcode":"11223-4567"}],"company":{"catchPhrase":"Streamlined analytics at scale","labels":{"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]},"name":"FastData Inc."},"dob":"1992-07-15","id":"2","name":"Analytica Rowe","phone_numbers":["123-456-7890","555-867-5309"],"tags":{"car":{"model":"Audi e-tron","year":"2022"},"hobby":"Running simulations","holidays":[{"location":"Kyoto, Japan","year":"2023"}]},"username":"Analytica","website":"fastdata.io"}
Row 2:
──────
json: {"address":[{"city":"Wisokyburgh","geo":{"lat":-43.9509,"lng":-34.4618},"street":"Victor Plains","suite":"Suite 879","zipcode":"90566-7771"}],"company":{"catchPhrase":"The real-time data warehouse for analytics","labels":{"employees":"250","founded":"2021","type":"database systems"},"name":"ClickHouse"},"dob":"2007-03-31","email":"clicky@clickhouse.com","id":"1","name":"Clicky McCliickHouse","phone_numbers":["010-692-6593","020-192-3333"],"tags":{"car":{"model":"Tesla","year":"2023"},"hobby":"Databases","holidays":[{"location":"Azores, Portugal","year":"2024"}]},"username":"Clicky","website":"clickhouse.com"}
2 rows in set. Elapsed: 0.005 sec.
내부 점검 함수(introspection functions)를 사용하여 추론된 하위 컬럼과 해당 타입을 확인할 수 있습니다. 예를 들어:
SELECT JSONDynamicPathsWithTypes(json) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"address": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"company.catchPhrase": "String",
"company.labels.employees": "Int64",
"company.labels.founded": "String",
"company.labels.type": "String",
"company.name": "String",
"dob": "Date",
"email": "String",
"id": "Int64",
"name": "String",
"phone_numbers": "Array(Nullable(String))",
"tags.car.model": "String",
"tags.car.year": "Int64",
"tags.hobby": "String",
"tags.holidays": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"website": "String"
}
}
{
"paths": {
"address": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"company.catchPhrase": "String",
"company.labels.dissolved": "Int64",
"company.labels.employees": "Int64",
"company.labels.founded": "Int64",
"company.labels.type": "Array(Nullable(String))",
"company.name": "String",
"dob": "Date",
"id": "Int64",
"name": "String",
"phone_numbers": "Array(Nullable(String))",
"tags.car.model": "String",
"tags.car.year": "Int64",
"tags.hobby": "String",
"tags.holidays": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"website": "String"
}
}
2 rows in set. Elapsed: 0.009 sec.
인트로스펙션 함수 전체 목록은 "Introspection functions"를 참조하십시오.
. 표기법을 사용하면 하위 경로에 접근할 수 있습니다, 예:
SELECT json.name, json.email FROM people
┌─json.name────────────┬─json.email────────────┐
│ Analytica Rowe │ ᴺᵁᴸᴸ │
│ Clicky McCliickHouse │ clicky@clickhouse.com │
└──────────────────────┴───────────────────────┘
2 rows in set. Elapsed: 0.006 sec.
행에 존재하지 않는 컬럼은 NULL로 반환됩니다.
또한 동일한 타입을 가진 경로마다 별도의 하위 컬럼이 생성됩니다. 예를 들어 String 타입과 Array(Nullable(String)) 타입 각각에 대해 company.labels.type 하위 컬럼이 존재합니다. 두 하위 컬럼을 모두 반환할 수 있는 경우에는 둘 다 반환되지만, .: 구문을 사용하여 특정 하위 컬럼만 대상으로 지정할 수 있습니다.
SELECT json.company.labels.type
FROM people
┌─json.company.labels.type─┐
│ database systems │
│ ['real-time processing'] │
└──────────────────────────┘
2 rows in set. Elapsed: 0.007 sec.
SELECT json.company.labels.type.:String
FROM people
┌─json.company⋯e.:`String`─┐
│ ᴺᵁᴸᴸ │
│ database systems │
└──────────────────────────┘
2 rows in set. Elapsed: 0.009 sec.
중첩된 하위 객체를 반환하려면 ^가 필요합니다. 이는 명시적으로 요청된 경우가 아니면 다수의 컬럼을 읽지 않도록 하기 위한 설계상의 결정입니다. 아래에 표시된 것처럼 ^ 없이 접근한 객체는 NULL을 반환합니다:
-- sub objects will not be returned by default
SELECT json.company.labels
FROM people
┌─json.company.labels─┐
│ ᴺᵁᴸᴸ │
│ ᴺᵁᴸᴸ │
└─────────────────────┘
2 rows in set. Elapsed: 0.002 sec.
-- return sub objects using ^ notation
SELECT json.^company.labels
FROM people
┌─json.^`company`.labels─────────────────────────────────────────────────────────────────┐
│ {"employees":"250","founded":"2021","type":"database systems"} │
│ {"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]} │
└────────────────────────────────────────────────────────────────────────────────────────┘
2 rows in set. Elapsed: 0.004 sec.
대상 JSON 컬럼
프로토타이핑 및 데이터 엔지니어링 작업에는 유용하지만, 운영 환경에서는 가급적 명시적인 스키마를 사용하는 것을 권장합니다.
이전 예제는 company.labels 컬럼에 대해 하나의 JSON 컬럼을 사용하여 모델링할 수 있습니다.
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String, labels JSON),
`dob` Date,
`tags` String
)
ENGINE = MergeTree
ORDER BY username
JSONEachRow 형식을 사용하여 이 테이블에 데이터를 삽입할 수 있습니다:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
SELECT *
FROM people
FORMAT Vertical
Row 1:
──────
id: 2
name: Analytica Rowe
username: Analytica
email:
address: [('Dataford',(40.7128,-74.006),'Maple Avenue','Apt. 402','11223-4567')]
phone_numbers: ['123-456-7890','555-867-5309']
website: fastdata.io
company: ('Streamlined analytics at scale','FastData Inc.','{"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]}')
dob: 1992-07-15
tags: {"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}
Row 2:
──────
id: 1
name: Clicky McCliickHouse
username: Clicky
email: clicky@clickhouse.com
address: [('Wisokyburgh',(-43.9509,-34.4618),'Victor Plains','Suite 879','90566-7771')]
phone_numbers: ['010-692-6593','020-192-3333']
website: clickhouse.com
company: ('The real-time data warehouse for analytics','ClickHouse','{"employees":"250","founded":"2021","type":"database systems"}')
dob: 2007-03-31
tags: {"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}
2 rows in set. Elapsed: 0.005 sec.
Introspection functions를 사용하여 company.labels 컬럼에 대해 유추된 경로와 데이터 타입을 확인할 수 있습니다.
SELECT JSONDynamicPathsWithTypes(company.labels) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"dissolved": "Int64",
"employees": "Int64",
"founded": "Int64",
"type": "Array(Nullable(String))"
}
}
{
"paths": {
"employees": "Int64",
"founded": "String",
"type": "String"
}
}
2 rows in set. Elapsed: 0.003 sec.
타입 힌트 사용과 경로 건너뛰기
타입 힌트를 사용하면 경로와 해당 하위 컬럼의 타입을 명시적으로 지정하여 불필요한 타입 추론을 방지할 수 있습니다. 다음 예시는 JSON 컬럼 company.labels 내의 JSON 키 dissolved, employees, founded에 대해 타입을 지정하는 경우를 보여줍니다.
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(
city String,
geo Tuple(
lat Float32,
lng Float32),
street String,
suite String,
zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(
catchPhrase String,
name String,
labels JSON(dissolved UInt16, employees UInt16, founded UInt16)),
`dob` Date,
`tags` String
)
ENGINE = MergeTree
ORDER BY username
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
이제 이 컬럼들에 명시적으로 지정한 타입이 적용된 것을 확인할 수 있습니다:
SELECT JSONAllPathsWithTypes(company.labels) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"dissolved": "UInt16",
"employees": "UInt16",
"founded": "UInt16",
"type": "String"
}
}
{
"paths": {
"dissolved": "UInt16",
"employees": "UInt16",
"founded": "UInt16",
"type": "Array(Nullable(String))"
}
}
2 rows in set. Elapsed: 0.003 sec.
추가로, 저장할 필요가 없는 JSON 경로는 SKIP 및 SKIP REGEXP 매개변수를 사용하여 건너뛸 수 있습니다. 이렇게 하면 저장 공간을 최소화하고 사용하지 않는 경로에 대한 불필요한 추론을 피할 수 있습니다. 예를 들어, 위 데이터에 단일 JSON 컬럼을 사용하는 경우 address 및 company 경로를 건너뛸 수 있습니다:
CREATE TABLE people
(
`json` JSON(username String, SKIP address, SKIP company)
)
ENGINE = MergeTree
ORDER BY json.username
INSERT INTO people FORMAT JSONAsObject
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONAsObject
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
컬럼들이 데이터에서 어떻게 제외되었는지 확인하십시오:
SELECT *
FROM people
FORMAT PrettyJSONEachRow
{
"json": {
"dob" : "1992-07-15",
"id" : "2",
"name" : "Analytica Rowe",
"phone_numbers" : [
"123-456-7890",
"555-867-5309"
],
"tags" : {
"car" : {
"model" : "Audi e-tron",
"year" : "2022"
},
"hobby" : "Running simulations",
"holidays" : [
{
"location" : "Kyoto, Japan",
"year" : "2023"
}
]
},
"username" : "Analytica",
"website" : "fastdata.io"
}
}
{
"json": {
"dob" : "2007-03-31",
"email" : "clicky@clickhouse.com",
"id" : "1",
"name" : "Clicky McCliickHouse",
"phone_numbers" : [
"010-692-6593",
"020-192-3333"
],
"tags" : {
"car" : {
"model" : "Tesla",
"year" : "2023"
},
"hobby" : "Databases",
"holidays" : [
{
"location" : "Azores, Portugal",
"year" : "2024"
}
]
},
"username" : "Clicky",
"website" : "clickhouse.com"
}
}
2 rows in set. Elapsed: 0.004 sec.
타입 힌트는 불필요한 타입 추론을 피하는 것 이상의 기능을 제공합니다. 저장 및 처리 과정에서의 간접 참조를 완전히 제거하고, 최적의 프리미티브 타입을 명시할 수 있게 합니다. 타입 힌트가 포함된 JSON 경로는 항상 기존 컬럼과 동일한 방식으로 저장되므로, discriminator 컬럼이나 쿼리 시점의 동적 해석이 필요하지 않습니다.
이는 잘 정의된 타입 힌트를 사용하면, 중첩된 JSON 키가 처음부터 최상위 컬럼으로 모델링된 것과 동일한 수준의 성능과 효율을 얻는다는 의미입니다.
따라서 대부분의 구조는 일관적이지만 여전히 JSON의 유연성이 필요한 데이터셋의 경우, 타입 힌트는 스키마나 수집 파이프라인을 재구성하지 않고도 성능을 유지할 수 있는 편리한 방법을 제공합니다.
동적 경로 구성하기
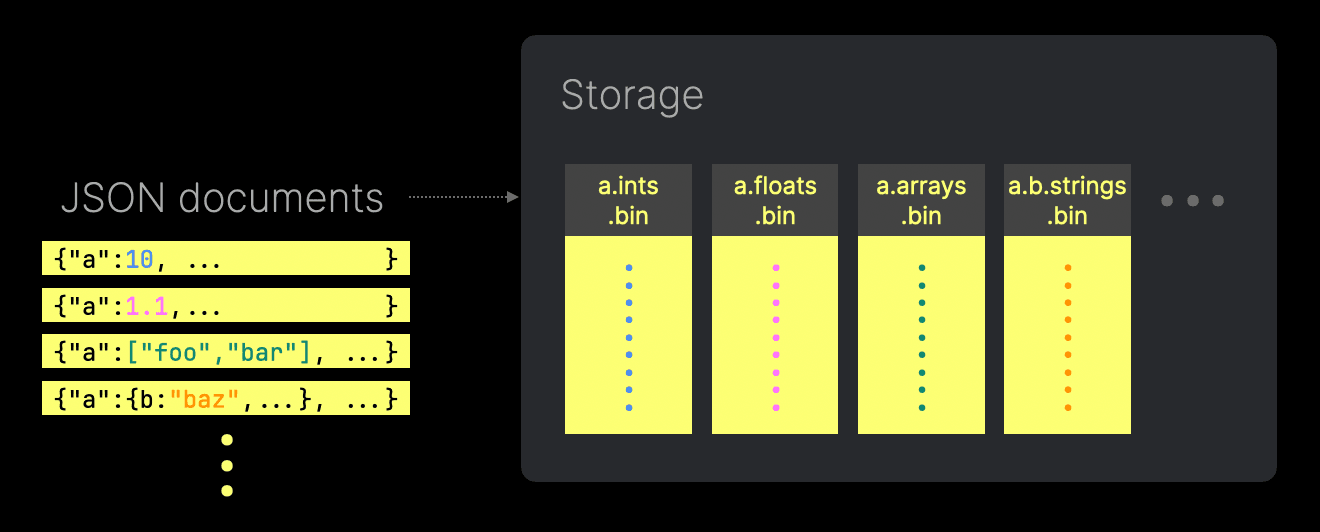
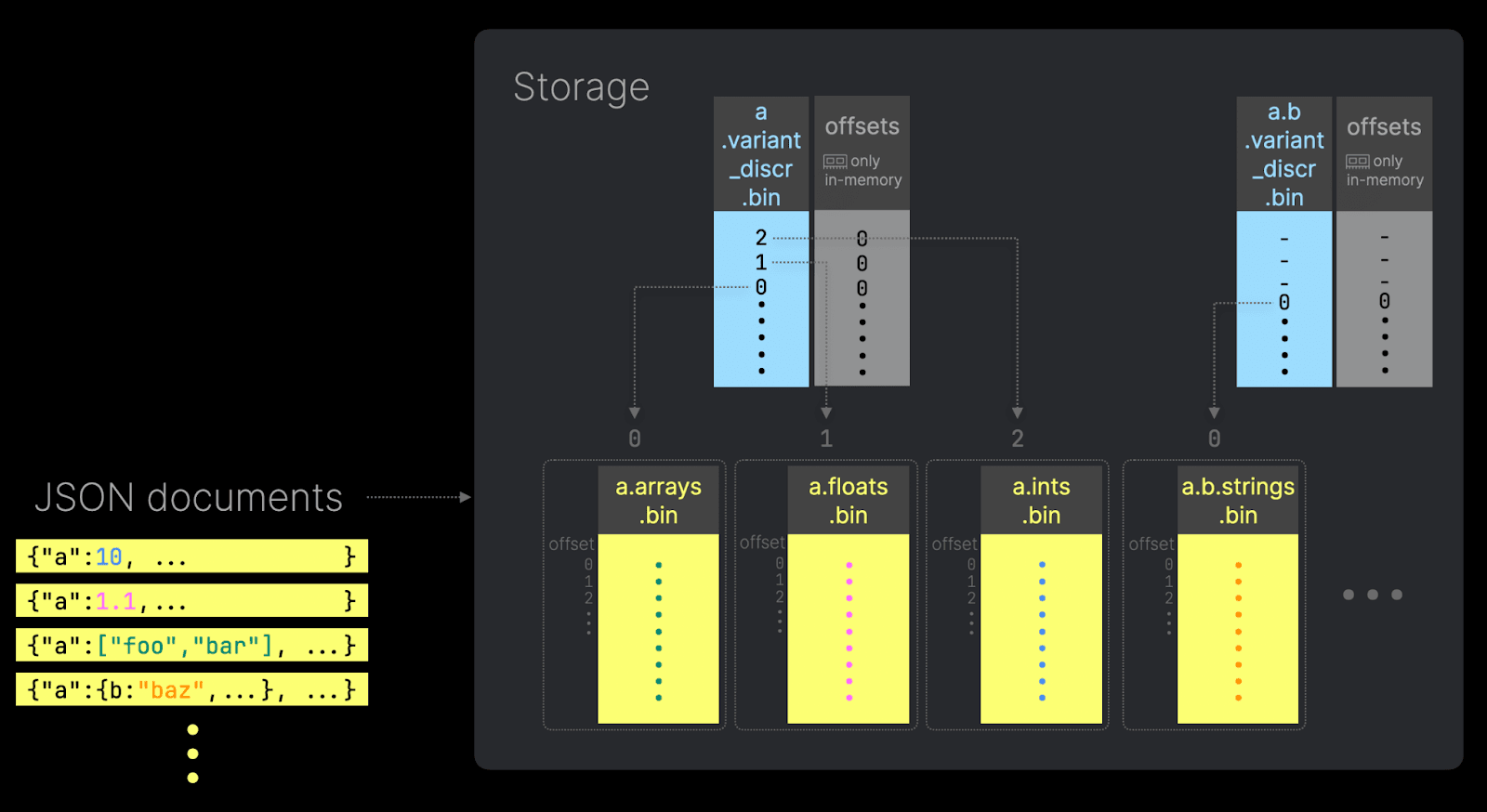
ClickHouse는 각 JSON 경로를 실제 열 지향 레이아웃의 서브컬럼으로 저장하여, 압축, SIMD 가속 처리, 최소 디스크 I/O와 같은 기존 컬럼에서의 동일한 성능 이점을 제공합니다. JSON 데이터에서 각 고유한 경로와 타입 조합은 디스크 상에서 개별 컬럼 파일이 될 수 있습니다.
예를 들어, 두 개의 JSON 경로가 서로 다른 타입으로 삽입되면 ClickHouse는 각 구체적인 타입을 서로 다른 서브컬럼에 저장합니다. 이러한 서브컬럼은 독립적으로 접근할 수 있어 불필요한 I/O를 최소화합니다. 여러 타입을 가진 컬럼을 쿼리하더라도 해당 값들은 여전히 단일 열 지향 응답으로 반환된다는 점에 유의하십시오.
또한, 오프셋을 활용하여 ClickHouse는 이러한 서브컬럼이 조밀하게 유지되도록 하고, 존재하지 않는 JSON 경로에 대해서는 기본값을 저장하지 않습니다. 이 방식은 압축 효율을 극대화하고 I/O를 추가로 줄여 줍니다.
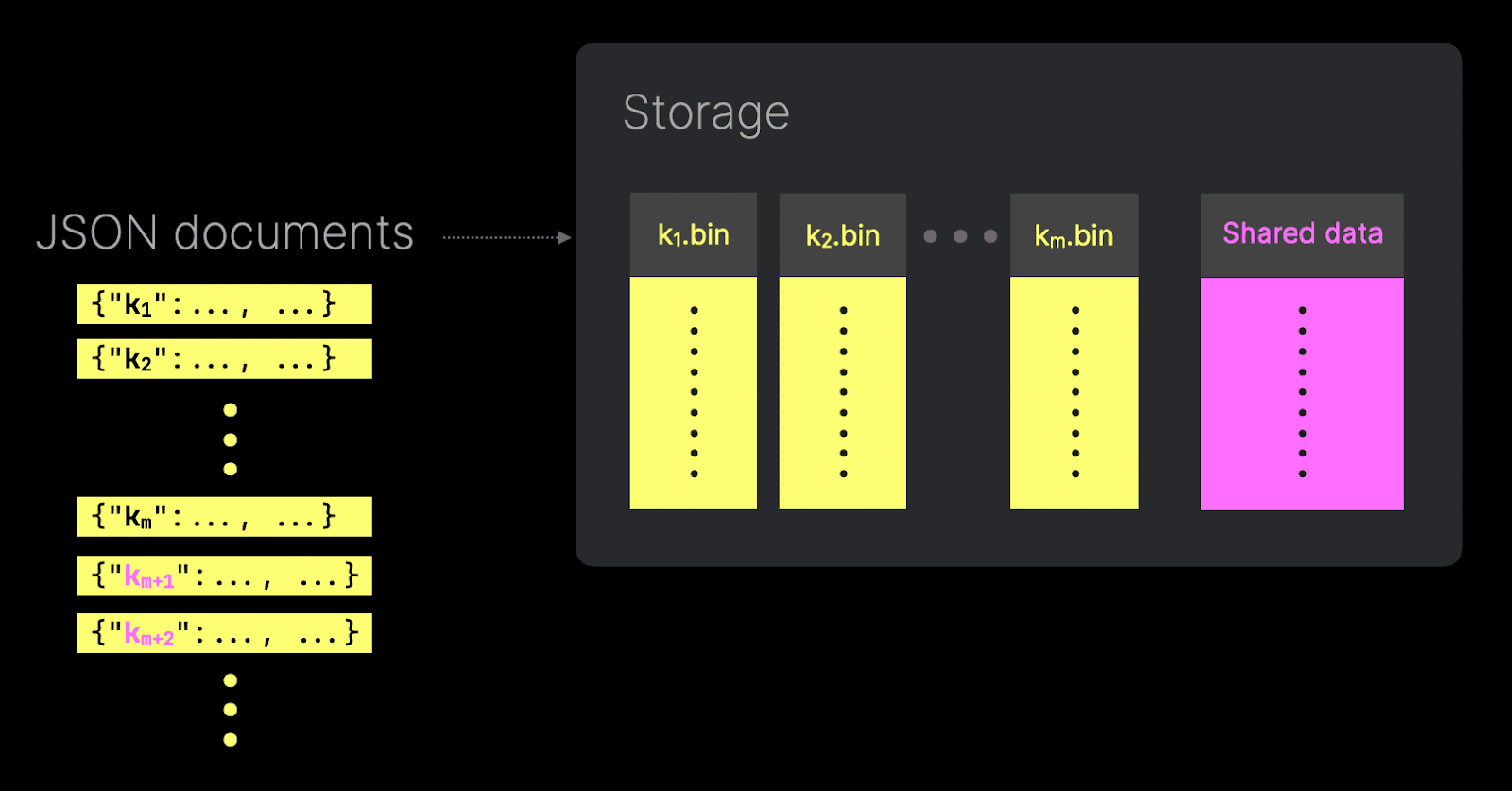
그러나 텔레메트리 파이프라인, 로그, 머신러닝 피처 스토어와 같이 고유 값 개수(cardinality)가 매우 크거나 구조가 매우 가변적인 JSON 구조에서는, 이 동작으로 인해 컬럼 파일 수가 폭발적으로 늘어날 수 있습니다. 새로운 고유 JSON 경로마다 새로운 컬럼 파일이 생성되고, 해당 경로 아래의 각 타입 변형마다 추가 컬럼 파일이 생성됩니다. 이는 읽기 성능 측면에서는 최적이지만, 파일 디스크립터 고갈, 메모리 사용량 증가, 작은 파일이 많아짐에 따른 머지 속도 저하 등 운영상의 어려움을 초래합니다.
이를 완화하기 위해 ClickHouse는 오버플로 서브컬럼(overflow subcolumn) 개념을 도입했습니다. 서로 다른 JSON 경로의 개수가 임계값을 초과하면, 추가 경로들은 하나의 공유 파일에 컴팩트한 인코딩 형식으로 저장됩니다. 이 파일도 여전히 쿼리할 수 있지만, 전용 서브컬럼과 동일한 성능 특성을 제공하지는 않습니다.
이 임계값은 JSON 타입 선언에서 max_dynamic_paths 파라미터로 제어합니다.
CREATE TABLE logs
(
payload JSON(max_dynamic_paths = 500)
)
ENGINE = MergeTree
ORDER BY tuple();
이 파라미터를 너무 크게 설정하지 마십시오 - 값이 커질수록 리소스 소비가 증가하고 효율성이 떨어집니다. 일반적인 기준으로 10,000 미만으로 유지하십시오. 구조가 매우 동적인 워크로드의 경우, 타입 힌트(type hint)와 SKIP 파라미터를 사용하여 저장되는 항목을 제한하십시오.
이 새로운 컬럼 타입의 구현 방식이 궁금한 사용자는 자세한 블로그 게시글인 "A New Powerful JSON Data Type for ClickHouse"를 참고할 것을 권장합니다.