Kafka 테이블 엔진 사용
Kafka 테이블 엔진은 Apache Kafka 및 기타 Kafka API 호환 브로커(예: Redpanda, Amazon MSK)에서 데이터를 읽어오고 기록하는 데 사용할 수 있습니다.
Kafka에서 ClickHouse로
ClickHouse Cloud를 사용 중이라면, 대신 ClickPipes를 사용하는 것을 권장합니다. ClickPipes는 Kafka 데이터를 ClickHouse로 스트리밍하기 위한 사설 네트워크 연결, 데이터 수집과 클러스터 리소스의 독립적인 확장, 포괄적인 모니터링을 기본적으로 지원합니다.
Kafka table engine을 사용하려면 ClickHouse 구체화된 뷰(materialized view)에 대해 전반적인 개념을 이해하고 있어야 합니다.
개요
우선 Kafka 테이블 엔진을 사용해 Kafka에서 ClickHouse로 데이터를 적재하는, 가장 일반적인 사용 사례에 초점을 맞춥니다.
Kafka 테이블 엔진을 사용하면 ClickHouse가 Kafka 토픽에서 직접 데이터를 읽을 수 있습니다. 이는 토픽의 메시지를 조회하는 데 유용하지만, 설계상 한 번만 데이터를 가져올 수 있습니다. 즉, 테이블에 대해 쿼리를 실행하면 큐에서 데이터를 소비하고, 호출자에게 결과를 반환하기 전에 consumer offset을 증가시킵니다. 이러한 offset을 재설정하지 않는 한 데이터를 다시 읽을 수 없습니다.
테이블 엔진에서 읽은 데이터를 영구적으로 저장하려면, 이 데이터를 캡처하여 다른 테이블에 삽입하는 수단이 필요합니다. 트리거 기반 materialized view를 사용하면 이러한 기능을 기본적으로 제공합니다. materialized view는 테이블 엔진에 대한 읽기를 시작하여 문서 배치를 수신합니다. TO 절은 데이터의 목적지를 결정하며, 일반적으로 MergeTree 패밀리의 테이블이 됩니다. 이 과정은 아래와 같이 시각화할 수 있습니다:
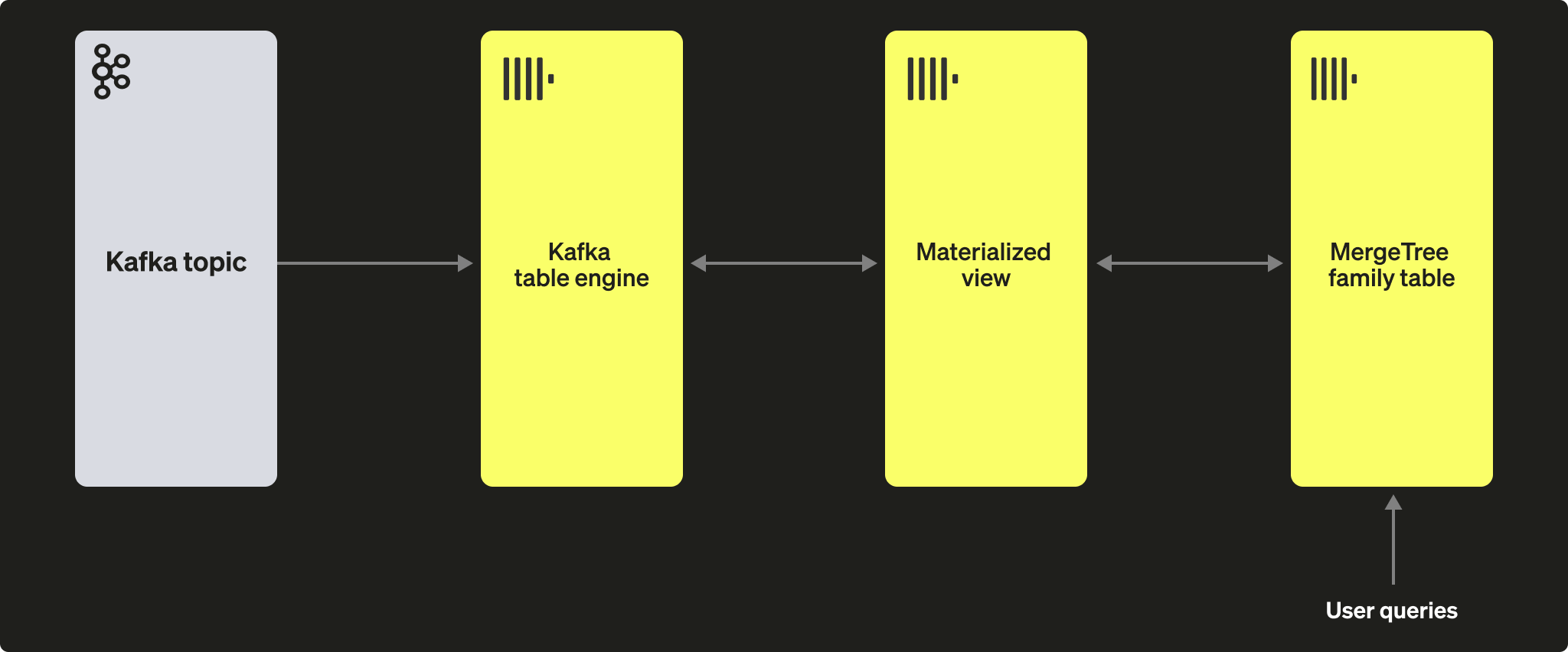
단계
1. 준비
대상 토픽에 이미 데이터가 채워져 있다면, 아래 내용을 현재 데이터셋에 맞게 수정하여 사용할 수 있습니다. 또는 예제용 GitHub 데이터셋이 여기에 제공됩니다. 이 데이터셋은 아래 예제에서 사용되며, 여기에서 제공되는 전체 데이터셋을 간략화한 버전으로, 축약된 스키마와 행(특히 ClickHouse 저장소와 관련된 GitHub 이벤트로 제한된 서브셋)을 사용합니다. 그럼에도 이 서브셋만으로도 해당 데이터셋과 함께 공개된 대부분의 쿼리를 실행하는 데 충분합니다.
2. ClickHouse 구성
보안이 구성된 Kafka에 연결하는 경우 이 단계가 필요합니다. 이러한 설정은 SQL DDL 명령으로 전달할 수 없으며 ClickHouse의 config.xml에서 구성해야 합니다. SASL로 보호되는 인스턴스에 연결한다고 가정합니다. 이는 Confluent Cloud와 연동할 때 사용할 수 있는 가장 단순한 방법입니다.
위 코드 조각을 conf.d/ 디렉터리 아래의 새 파일에 추가하거나, 기존 설정 파일에 병합해서 사용합니다. 설정 가능한 항목은 여기를 참고하십시오.
또한 이 튜토리얼에서 사용할 KafkaEngine이라는 이름의 데이터베이스도 생성합니다:
데이터베이스를 생성했으면 이제 해당 데이터베이스로 전환합니다:
3. 대상 테이블 생성
대상 테이블을 준비합니다. 아래 예제에서는 간결하게 설명하기 위해 축약된 GitHub 스키마를 사용합니다. 이 예제에서는 MergeTree 테이블 엔진을 사용하지만, MergeTree 계열의 어떤 엔진에도 쉽게 적용할 수 있습니다.
4. 토픽 생성 및 데이터 적재
다음으로 토픽을 생성합니다. 이를 위해 사용할 수 있는 도구는 여러 가지가 있습니다. Kafka를 로컬 환경이나 Docker 컨테이너에서 실행하는 경우 RPK를 사용하는 방법이 좋습니다. 다음 명령을 실행하여 github라는 이름의 토픽을 5개의 파티션을 가진 토픽으로 생성할 수 있습니다:
Confluent Cloud에서 Kafka를 사용하는 경우 Confluent CLI를 사용하는 것이 더 편리할 수 있습니다.
이제 이 토픽을 데이터로 채워야 합니다. 이를 위해 kcat을 사용합니다. 인증이 비활성화된 상태에서 Kafka를 로컬로 실행 중이라면 다음과 같은 명령을 실행하면 됩니다:
Kafka 클러스터에서 인증에 SASL을 사용하는 경우 다음 예시를 사용합니다:
데이터셋에는 200,000개의 행이 포함되어 있으므로, 몇 초 안에 수집됩니다. 더 큰 데이터셋으로 작업하려면 GitHub 리포지토리 ClickHouse/kafka-samples의 대규모 데이터셋 섹션을 살펴보십시오.
5. Kafka 테이블 엔진 생성
아래 예시는 MergeTree 테이블과 동일한 스키마를 사용하는 테이블 엔진을 생성합니다. 대상 테이블에 별칭(alias)이나 임시 컬럼을 둘 수 있으므로, 이렇게 할 필요는 없습니다. 그러나 설정은 중요합니다. Kafka 토픽에서 JSON을 소비하기 위한 데이터 타입으로 JSONEachRow를 사용하는 점에 유의하십시오. github과 clickhouse 값은 각각 토픽 이름과 컨슈머 그룹 이름을 나타냅니다. 토픽은 실제로 여러 값을 가지는 리스트로 지정할 수도 있습니다.
엔진 설정과 성능 튜닝에 대해서는 아래에서 다룹니다. 이 시점에서 테이블 github_queue에 대해 간단한 SELECT를 실행하면 몇 개의 행을 읽을 수 있습니다. 이렇게 하면 consumer offset이 앞으로 이동하여, reset을 수행하지 않는 한 해당 행들을 다시 읽을 수 없다는 점에 유의하십시오. LIMIT과 필수 파라미터 stream_like_engine_allow_direct_select에 유의하십시오.
6. materialized view 생성
materialized view는 앞에서 생성한 두 테이블을 연결하여 Kafka 테이블 엔진에서 데이터를 읽고 대상 MergeTree 테이블에 삽입합니다. 다양한 데이터 변환을 수행할 수 있지만, 여기서는 단순히 읽기와 삽입만 수행합니다. * 사용은 컬럼 이름이 동일함(대소문자 구분)을 전제로 합니다.
materialized view가 생성되는 시점에 Kafka 엔진에 연결되어 읽기를 시작하여 대상 테이블에 행을 삽입합니다. 이 과정은 이후 Kafka에 메시지가 계속 삽입되는 대로 이를 계속 소비하면서 무기한 진행됩니다. Kafka에 추가 메시지를 삽입하려면 삽입 스크립트를 다시 실행해도 됩니다.
7. 행이 삽입되었는지 확인
대상 테이블에 데이터가 존재하는지 확인합니다:
200,000개의 행이 표시되어야 합니다:
공통 작업
메시지 소비 중지 및 재시작
메시지 소비를 중지하려면 Kafka 엔진 테이블을 DETACH 하십시오.
이 작업은 consumer group의 오프셋에는 영향을 주지 않습니다. 다시 소비를 시작하여 이전 오프셋부터 계속 처리하려면 테이블을 다시 연결하십시오.
Kafka 메타데이터 추가
원본 Kafka 메시지가 ClickHouse로 수집된 이후에도 해당 메타데이터를 계속 추적할 수 있으면 유용합니다. 예를 들어, 특정 토픽이나 파티션을 얼마나 많이 소비했는지 알고 싶을 수 있습니다. 이를 위해 Kafka 테이블 엔진은 여러 virtual columns을 노출합니다. 스키마와 구체화된 뷰(materialized view)의 SELECT 문을 수정하여 이러한 컬럼을 대상 테이블에 컬럼으로 영구 저장할 수 있습니다.
먼저, 대상 테이블에 컬럼을 추가하기 전에 위에서 설명한 중지 작업을 수행합니다.
아래에서는 각 행이 유입된 소스 토픽과 파티션을 식별할 수 있도록 정보 컬럼을 추가합니다.
다음으로, 가상 컬럼이 요구사항에 맞게 매핑되었는지 확인해야 합니다.
가상 컬럼 이름 앞에는 _ 접두사가 붙습니다.
가상 컬럼의 전체 목록은 여기에서 확인할 수 있습니다.
가상 컬럼을 포함하도록 테이블을 업데이트하려면, materialized view를 삭제하고 Kafka 엔진 테이블을 다시 attach한 다음 materialized view를 다시 생성해야 합니다.
새로 가져온 행에는 메타데이터가 포함되어야 합니다.
결과는 다음과 같습니다:
| actor_login | event_type | created_at | topic | 파티션 |
|---|---|---|---|---|
| IgorMinar | CommitCommentEvent | 2011-02-12 02:22:00 | github | 0 |
| queeup | CommitCommentEvent | 2011-02-12 02:23:23 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:23:24 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:24:50 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:25:20 | github | 0 |
| dapi | CommitCommentEvent | 2011-02-12 06:18:36 | github | 0 |
| sourcerebels | CommitCommentEvent | 2011-02-12 06:34:10 | github | 0 |
| jamierumbelow | CommitCommentEvent | 2011-02-12 12:21:40 | github | 0 |
| jpn | CommitCommentEvent | 2011-02-12 12:24:31 | github | 0 |
| Oxonium | CommitCommentEvent | 2011-02-12 12:31:28 | github | 0 |
Kafka 엔진 설정 수정
Kafka 엔진 테이블을 삭제하고 새 설정으로 다시 생성할 것을 권장합니다. 이 과정에서 materialized view는 수정할 필요가 없으며, Kafka 엔진 테이블이 다시 생성되면 메시지 소비가 재개됩니다.
문제 디버깅
인증 문제와 같은 오류는 Kafka 엔진 DDL에 대한 응답에 포함되어 보고되지 않습니다. 문제를 진단하려면 기본 ClickHouse 로그 파일인 clickhouse-server.err.log를 사용하는 것이 좋습니다. 기본 Kafka 클라이언트 라이브러리인 librdkafka에 대한 추가 trace 로깅은 설정을 통해 활성화할 수 있습니다.
잘못된 형식의 메시지 처리
Kafka는 종종 데이터의 「덤핑 장소」로 사용됩니다. 이로 인해 하나의 토픽에 서로 다른 메시지 형식과 일관되지 않은 필드 이름이 섞여 포함되는 문제가 발생합니다. 이러한 상황을 피하고, Kafka Streams 또는 ksqlDB와 같은 Kafka 기능을 활용하여 Kafka에 삽입되기 전에 메시지가 올바른 형식과 일관된 구조를 갖도록 하는 것이 좋습니다. 이러한 옵션을 사용할 수 없는 경우 ClickHouse에서 도움이 될 수 있는 기능들이 있습니다.
- 메시지 필드를 문자열로 취급합니다. 필요한 경우 materialized view 구문에서 함수를 사용하여 정제 및 형 변환을 수행할 수 있습니다. 이는 운영 환경용 최종 솔루션으로 간주되어서는 안 되지만, 일회성 수집 작업에는 도움이 될 수 있습니다.
- 토픽에서 JSON을
JSONEachRow포맷으로 사용하는 경우input_format_skip_unknown_fields설정을 사용하십시오. 기본적으로 데이터를 쓸 때 입력 데이터에 대상 테이블에 존재하지 않는 컬럼이 포함되어 있으면 ClickHouse는 예외를 발생시킵니다. 그러나 이 옵션을 활성화하면 이러한 초과 컬럼은 무시됩니다. 마찬가지로 이것도 운영 환경 수준의 솔루션은 아니며 다른 사용자를 혼란스럽게 만들 수 있습니다. kafka_skip_broken_messages설정 사용을 고려하십시오. 이 설정은kafka_max_block_size맥락에서 잘못된 형식의 메시지에 대해 블록마다 허용할 오류 허용 수준을 사용자가 지정하도록 요구합니다. 이 허용 한도(절대 메시지 수 기준)를 초과하면 기존의 예외 발생 동작이 다시 적용되고, 다른 메시지들은 건너뛰게 됩니다.
전달 시맨틱과 중복으로 인한 문제
Kafka 테이블 엔진은 최소 1회(at-least-once) 시맨틱을 제공합니다. 몇 가지 알려진 드문 상황에서는 중복이 발생할 수 있습니다. 예를 들어, 메시지를 Kafka에서 읽어 ClickHouse에 성공적으로 삽입했으나, 새 오프셋을 커밋하기 전에 Kafka와의 연결이 끊어질 수 있습니다. 이 경우 해당 블록을 다시 처리해야 합니다. 이 블록은 대상 테이블로 분산 테이블 또는 ReplicatedMergeTree를 사용하여 중복 제거할 수 있습니다. 이는 중복 행 발생 가능성을 줄여주지만, 블록이 동일하다는 가정에 의존합니다. Kafka 리밸런싱과 같은 이벤트는 이 가정을 무효화할 수 있으며, 이로 인해 드문 상황에서 중복이 발생할 수 있습니다.
쿼럼 기반 INSERT
ClickHouse에서 더 강한 전달 보장이 필요한 경우 쿼럼 기반 INSERT가 필요할 수 있습니다. 이는 materialized view나 대상 테이블에는 설정할 수 없습니다. 다만 사용자 프로필에 대해서는 다음과 같이 설정할 수 있습니다.
ClickHouse to Kafka
비교적 드문 사용 사례이지만, ClickHouse 데이터는 Kafka에 영구 저장할 수도 있습니다. 예를 들어, Kafka table engine에 행을 수동으로 삽입해 보겠습니다. 이 데이터는 동일한 Kafka engine에 의해 읽히며, 이에 연결된 materialized view가 데이터를 MergeTree 테이블에 적재합니다. 마지막으로, 기존 소스 테이블에서 데이터를 읽기 위해 Kafka로 데이터를 insert할 때 materialized view를 어떻게 활용하는지 보여 줍니다.
단계
초기 목표는 다음 그림과 같습니다:
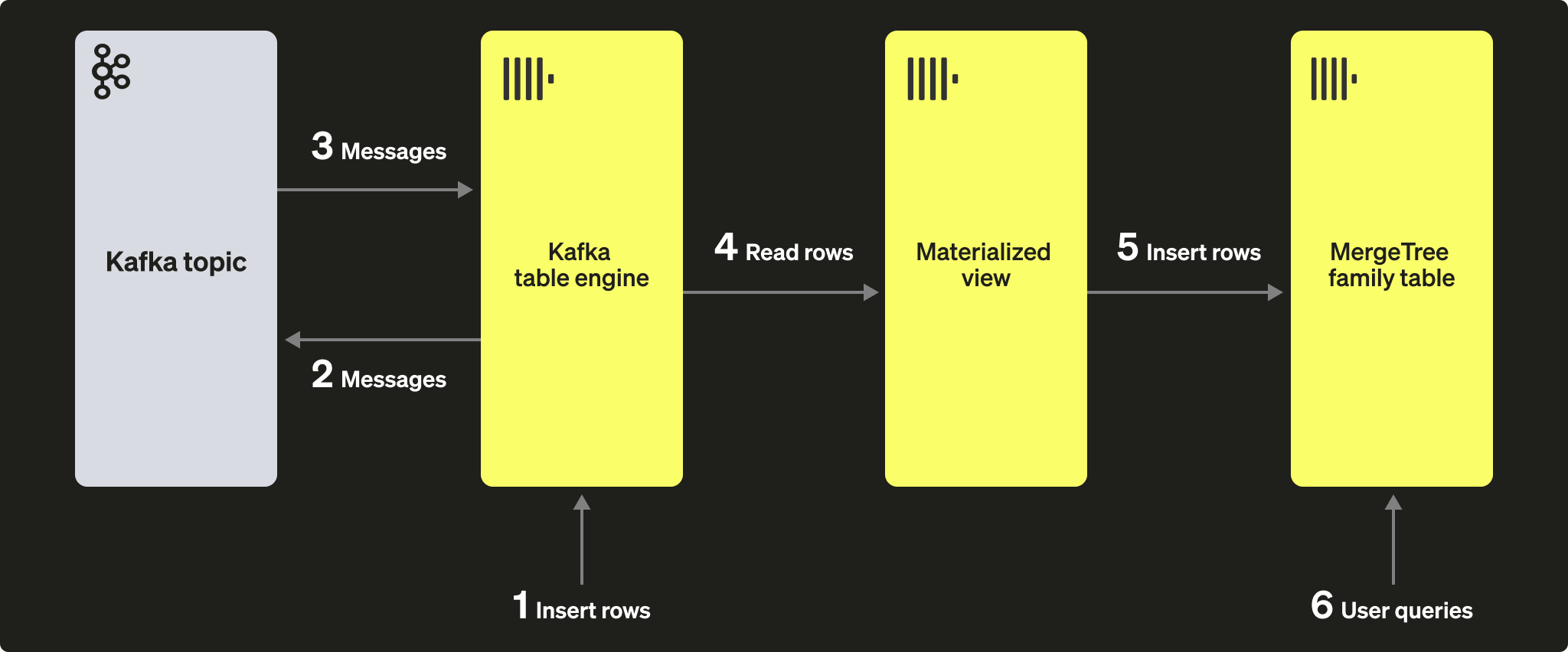
Kafka to ClickHouse 단계에서 테이블과 VIEW가 이미 생성되어 있으며, 해당 토픽의 메시지가 모두 소비된 상태라고 가정합니다.
1. 행을 직접 삽입하기
먼저 대상 테이블의 행 수를 확인합니다.
200,000개의 행이 있어야 합니다:
이제 GitHub 대상 테이블의 행을 Kafka 테이블 엔진 github_queue로 다시 삽입합니다. JSONEachRow 포맷을 사용하고, LIMIT를 통해 SELECT되는 행 수를 100개로 제한하는 방식에 주목하십시오.
GitHub에서 행 수를 다시 세어 100개 증가했는지 확인합니다. 위 다이어그램에서 볼 수 있듯이, 행은 Kafka table engine을 통해 먼저 Kafka에 삽입된 다음, 동일한 엔진에서 다시 읽혀 materialized view를 통해 GitHub 대상 테이블에 삽입되었습니다!
100개의 행이 추가로 표시되어야 합니다:
2. Using materialized views
테이블에 문서가 삽입될 때 Kafka 엔진(및 토픽)으로 메시지를 전달하기 위해 materialized views를 활용할 수 있습니다. GitHub 테이블에 행이 삽입되면 materialized view가 트리거되어, 해당 행이 Kafka 엔진과 새로운 토픽으로 다시 삽입됩니다. 이는 아래 다이어그램이 가장 잘 보여 줍니다:
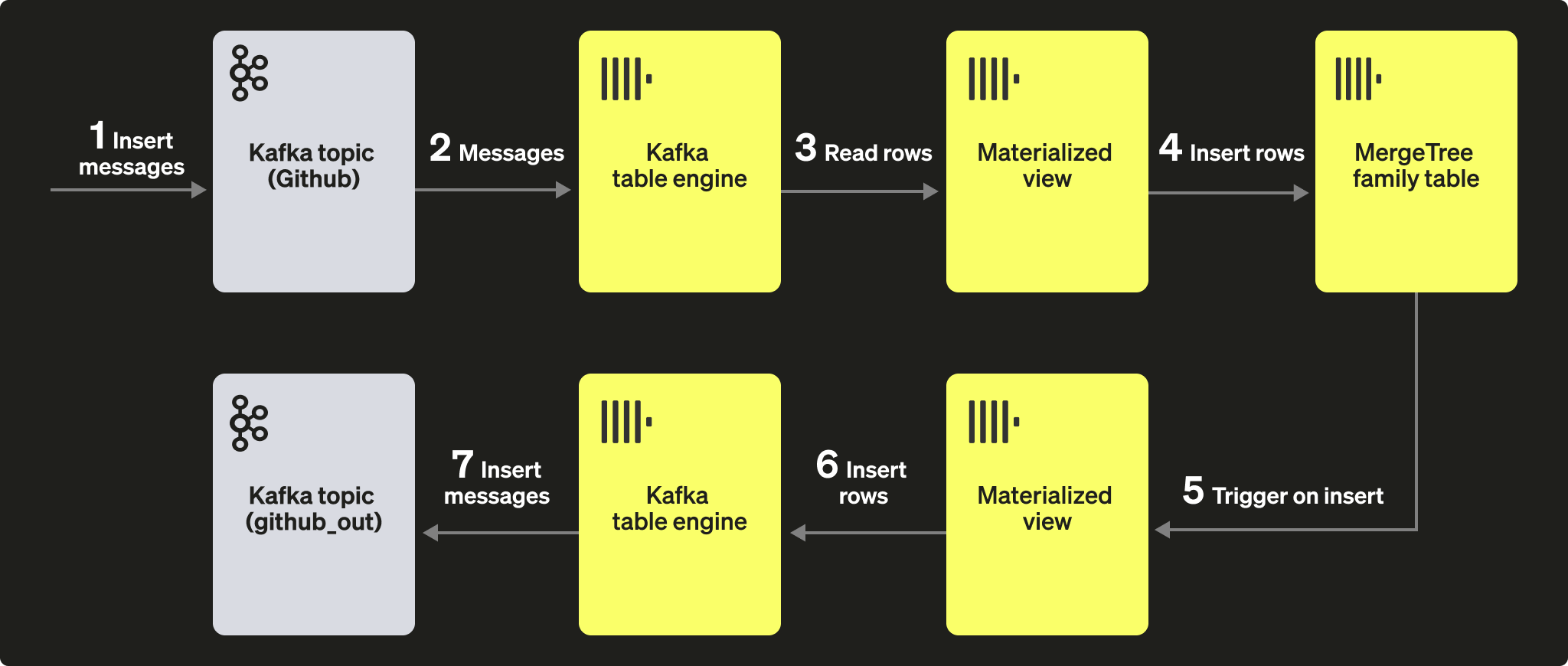
새 Kafka 토픽 github_out 또는 이에 상응하는 토픽을 생성하십시오. Kafka table engine github_out_queue가 이 토픽을 가리키도록 설정하십시오.
이제 GitHub 테이블을 소스로 하여, 트리거될 때 위의 엔진으로 행을 삽입하는 새로운 materialized view github_out_mv를 생성합니다. 이렇게 하면 GitHub 테이블에 행이 추가될 때마다 새 Kafka 토픽으로 전송됩니다.
Kafka to ClickHouse의 일부로 생성된 원래 github 토픽에 데이터를 INSERT하면, 레코드가 마치 마법처럼 「github_clickhouse」 토픽에 나타납니다. 이는 Kafka 기본 도구를 사용하여 확인할 수 있습니다. 예를 들어, 아래 예시에서는 Confluent Cloud에서 호스팅되는 토픽에 대해 kcat을 사용하여 github 토픽에 100개의 행을 삽입합니다:
github_out 토픽에서 읽기를 수행하면 메시지가 정상적으로 전달되었음을 확인할 수 있습니다.
예제가 다소 복잡하긴 하지만, Kafka 엔진과 함께 사용할 때 materialized view의 강력한 기능을 잘 보여 줍니다.
클러스터 및 성능
ClickHouse 클러스터 사용하기
Kafka consumer group을 통해 여러 ClickHouse 인스턴스가 동일한 토픽에서 데이터를 읽을 수 있습니다. 각 consumer는 토픽 파티션에 1:1 매핑으로 할당됩니다. Kafka table engine을 사용해 ClickHouse에서 Kafka 데이터를 소비하는 규모를 확장할 때는, 하나의 클러스터 내 전체 consumer 수가 해당 토픽의 파티션 수를 초과할 수 없다는 점을 고려해야 합니다. 따라서 토픽에 대해 파티션 구성이 사전에 적절히 설정되어 있어야 합니다.
여러 ClickHouse 인스턴스를 동일한 consumer group id(Kafka table engine 생성 시 지정)를 사용하여 하나의 토픽을 읽도록 모두 구성할 수 있습니다. 이때 각 인스턴스는 하나 이상의 파티션에서 데이터를 읽어 로컬 대상 테이블에 데이터 세그먼트를 삽입합니다. 대상 테이블은 데이터 중복을 처리하기 위해 ReplicatedMergeTree를 사용하도록 구성할 수 있습니다. 이 방식은 Kafka 파티션이 충분히 존재하는 경우, Kafka 읽기를 ClickHouse 클러스터와 함께 확장할 수 있도록 해 줍니다.
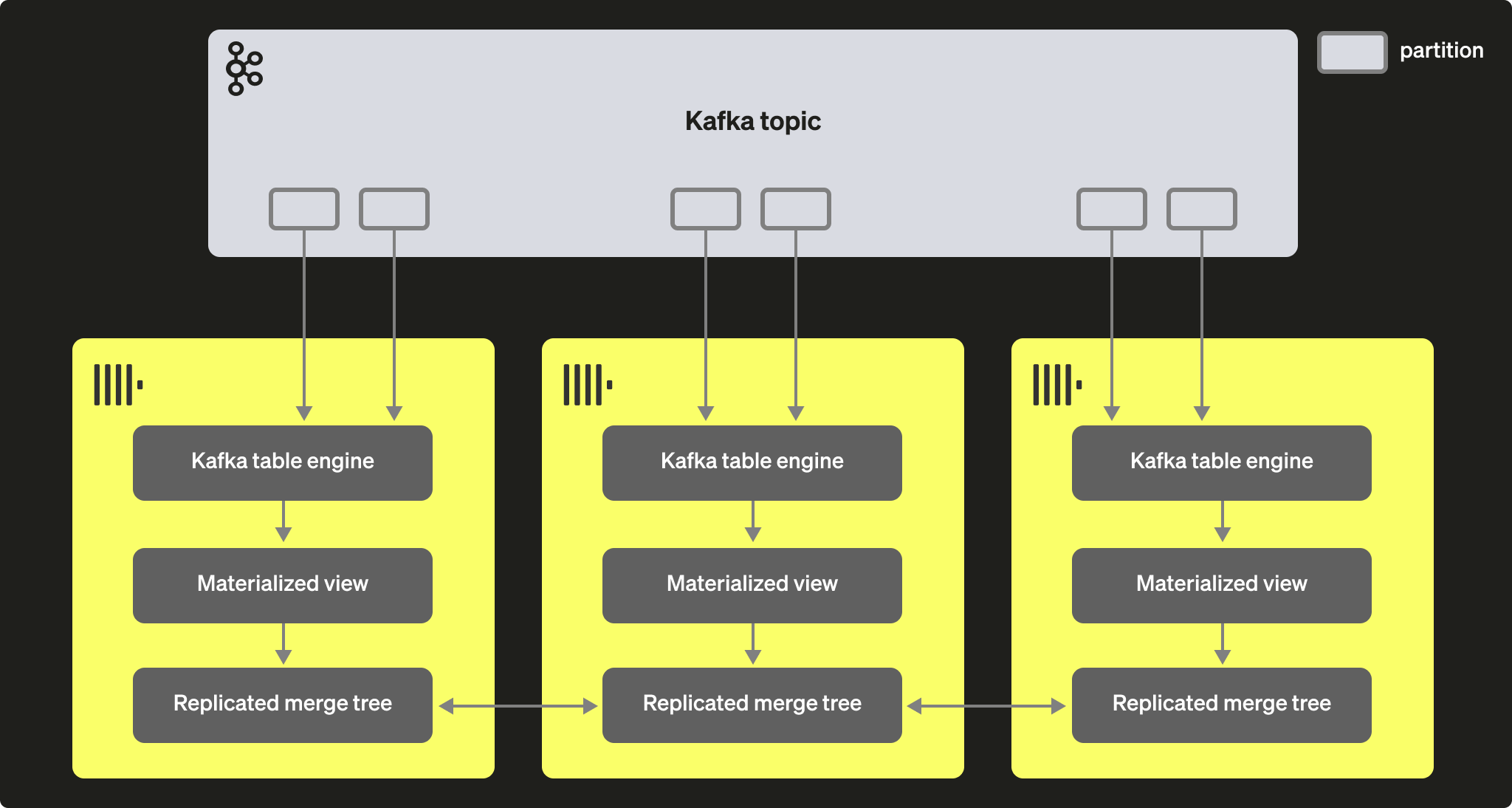
성능 튜닝
Kafka Engine 테이블의 처리량 성능을 높이려면 다음 사항을 고려하십시오:
- 성능은 메시지 크기, 포맷, 대상 테이블 유형에 따라 달라집니다. 단일 테이블 엔진에서 초당 100k 행 정도는 달성 가능한 수준으로 간주할 수 있습니다. 기본적으로 메시지는
kafka_max_block_size파라미터로 제어되는 블록 단위로 읽습니다. 기본값은 max_insert_block_size이며, 기본값은 1,048,576입니다. 메시지가 극도로 크지 않은 한 이 값은 거의 항상 늘려야 합니다. 500k에서 1M 사이의 값도 흔합니다. 테스트를 수행하고 처리량 성능에 미치는 영향을 평가하십시오. - 테이블 엔진의 consumer 수는
kafka_num_consumers를 사용하여 늘릴 수 있습니다. 그러나 기본적으로kafka_thread_per_consumer값이 기본값 1에서 변경되지 않으면 insert는 단일 스레드에서 직렬화됩니다. 플러시가 병렬로 수행되도록 이 값을 1로 설정하십시오.N개의 consumer(및kafka_thread_per_consumer=1)를 사용하는 Kafka 엔진 테이블을 생성하는 것은 논리적으로N개의 Kafka 엔진을 생성하고, 각각에 materialized view와kafka_thread_per_consumer=0을 두는 것과 동일합니다. - consumer를 늘리는 작업은 비용이 없는 작업이 아닙니다. 각 consumer는 자체 버퍼와 스레드를 유지하므로 서버 오버헤드가 증가합니다. consumer 오버헤드를 염두에 두고, 가능하다면 먼저 클러스터 전체에 선형적으로 확장하십시오.
- Kafka 메시지 처리량이 가변적이고 지연이 허용된다면, 더 큰 블록이 플러시되도록
stream_flush_interval_ms를 늘리는 것을 고려하십시오. - background_message_broker_schedule_pool_size는 백그라운드 작업을 수행하는 스레드 수를 설정합니다. 이들 스레드는 Kafka 스트리밍에 사용됩니다. 이 설정은 ClickHouse 서버 시작 시 적용되며, 사용자 세션에서는 변경할 수 없고 기본값은 16입니다. 로그에서 타임아웃이 발생하는 것이 보인다면, 이 값을 늘리는 것이 적절할 수 있습니다.
- Kafka와의 통신에는
librdkafka라이브러리를 사용하며, 이 라이브러리 자체도 스레드를 생성합니다. 많은 수의 Kafka 테이블이나 consumer는 결과적으로 많은 수의 컨텍스트 스위치를 초래할 수 있습니다. 이 부하를 클러스터 전체에 분산하고, 가능하다면 대상 테이블만 복제하거나, 여러 토픽에서 읽는 테이블 엔진 사용을 고려하십시오(값 목록이 지원됩니다). 여러 materialized view가 하나의 테이블에서 읽을 수 있으며, 각 뷰는 특정 토픽의 데이터만 필터링할 수 있습니다.
모든 설정 변경 사항은 반드시 테스트해야 합니다. 적절하게 확장되었는지 확인하기 위해 Kafka consumer lag(지연 시간)을 모니터링할 것을 권장합니다.
추가 설정
위에서 설명한 설정 외에도, 다음 설정이 유용할 수 있습니다:
- Kafka_max_wait_ms - Kafka에서 메시지를 읽은 후 재시도하기 전까지의 대기 시간(밀리초 단위)입니다. 사용자 프로필 수준에서 설정되며 기본값은 5000입니다.
하위 라이브러리인 librdkafka의 모든 설정 은 ClickHouse 설정 파일의 kafka 요소 내부에 지정할 수도 있습니다. 이때 설정 이름은 마침표를 밑줄로 대체한 XML 요소여야 합니다. 예:
이 설정들은 전문가용 설정이므로, 보다 자세한 설명은 Kafka 문서를 참고하시기 바랍니다.
