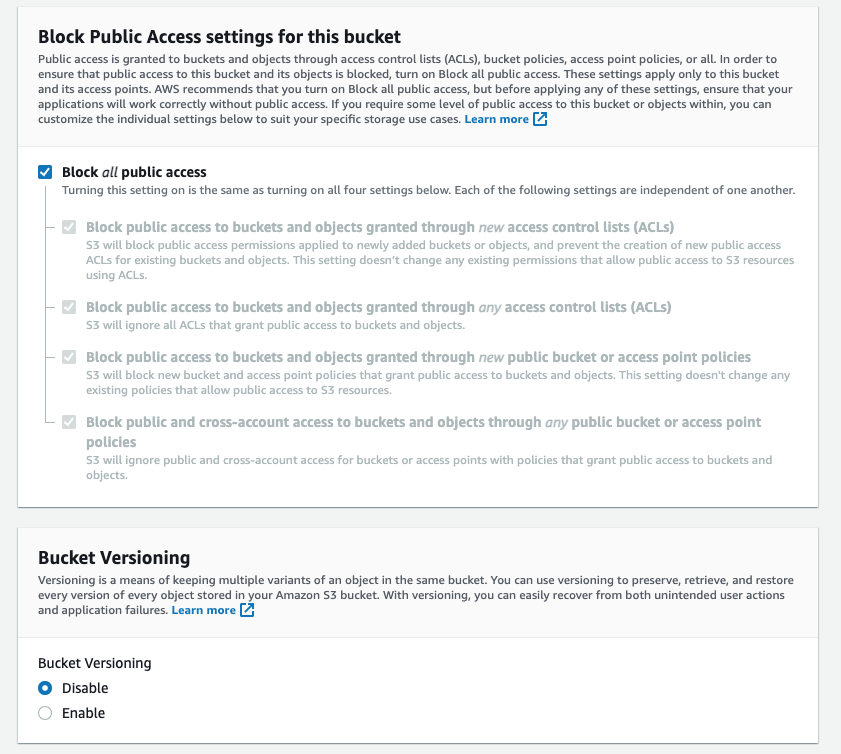
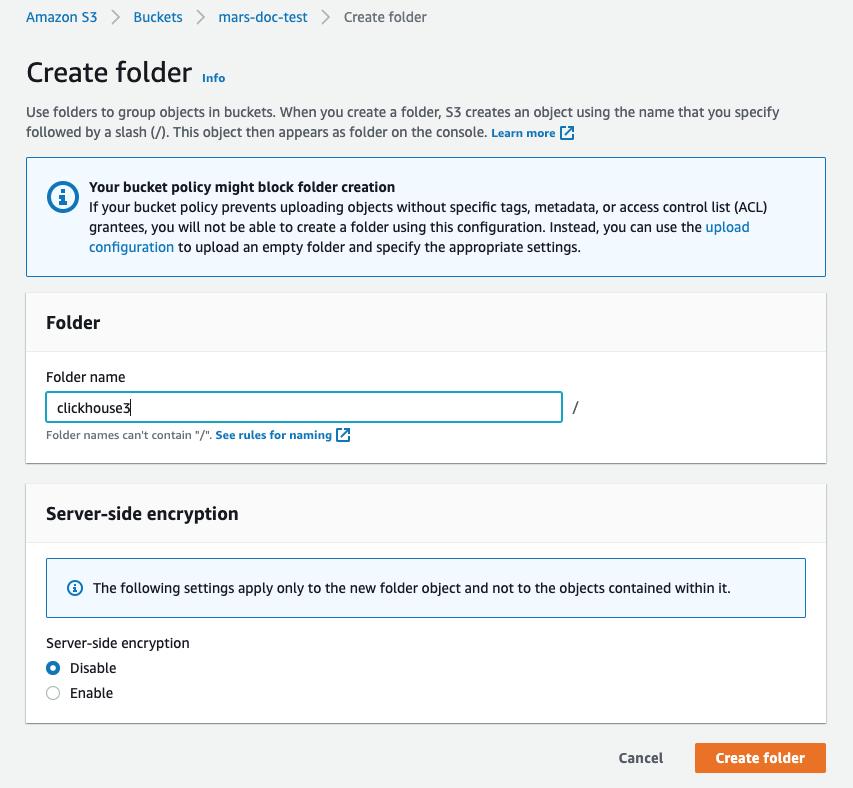
S3에서 ClickHouse로 데이터를 삽입할 수 있으며, S3를 내보내기 대상(export destination)으로도 사용할 수 있어 「데이터 레이크(data lake)」 아키텍처와 상호 작용할 수 있습니다. 또한 S3는 「콜드(cold)」 스토리지 계층을 제공하고 스토리지와 컴퓨팅을 분리하는 데 도움을 줄 수 있습니다. 아래 섹션에서는 뉴욕시 택시 데이터 세트를 사용하여 S3와 ClickHouse 간에 데이터를 이동하는 과정을 보여 주고, 주요 설정 파라미터를 제시하며 성능 최적화에 대한 팁을 제공합니다.
S3 테이블 함수
s3 테이블 함수는 S3 호환 스토리지에서 파일을 읽고 쓸 수 있게 해줍니다. 해당 구문의 형식은 다음과 같습니다:
s3(path, [aws_access_key_id, aws_secret_access_key,] [format, [structure, [compression]]])
where:
- path — 파일 경로를 포함하는 버킷 URL입니다. 읽기 전용 모드에서 다음 와일드카드를 지원합니다:
*, ?, {abc,def}, {N..M}. 여기서 N, M은 숫자이고, 'abc', 'def'는 문자열입니다. 자세한 내용은 경로에서 와일드카드 사용에 대한 문서를 참조하십시오.
- format — 파일의 format입니다.
- structure — 테이블 구조입니다. 형식:
'column1_name column1_type, column2_name column2_type, ...'.
- compression — 선택적 매개변수입니다. 지원되는 값:
none, gzip/gz, brotli/br, xz/LZMA, zstd/zst. 기본적으로 파일 확장자를 기준으로 압축 방식을 자동으로 감지합니다.
경로 표현식에서 와일드카드를 사용하면 여러 파일을 참조할 수 있어 병렬 처리가 가능해집니다.
ClickHouse에서 테이블을 생성하기 전에 먼저 S3 버킷에 있는 데이터를 한 번 자세히 확인하는 것이 좋습니다. 이는 ClickHouse에서 DESCRIBE 문을 사용하여 직접 수행할 수 있습니다:
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames');
DESCRIBE TABLE 구문의 출력 결과를 보면 S3 버킷에 있는 데이터를 기준으로 ClickHouse가 이 데이터를 어떻게 자동으로 추론하는지 알 수 있습니다. 또한 gzip 압축 형식을 자동으로 인식하여 압축을 해제한다는 점에 유의하십시오:`
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') SETTINGS describe_compact_output=1
┌─name──────────────────┬─type───────────────┐
│ trip_id │ Nullable(Int64) │
│ vendor_id │ Nullable(Int64) │
│ pickup_date │ Nullable(Date) │
│ pickup_datetime │ Nullable(DateTime) │
│ dropoff_date │ Nullable(Date) │
│ dropoff_datetime │ Nullable(DateTime) │
│ store_and_fwd_flag │ Nullable(Int64) │
│ rate_code_id │ Nullable(Int64) │
│ pickup_longitude │ Nullable(Float64) │
│ pickup_latitude │ Nullable(Float64) │
│ dropoff_longitude │ Nullable(Float64) │
│ dropoff_latitude │ Nullable(Float64) │
│ passenger_count │ Nullable(Int64) │
│ trip_distance │ Nullable(String) │
│ fare_amount │ Nullable(String) │
│ extra │ Nullable(String) │
│ mta_tax │ Nullable(String) │
│ tip_amount │ Nullable(String) │
│ tolls_amount │ Nullable(Float64) │
│ ehail_fee │ Nullable(Int64) │
│ improvement_surcharge │ Nullable(String) │
│ total_amount │ Nullable(String) │
│ payment_type │ Nullable(String) │
│ trip_type │ Nullable(Int64) │
│ pickup │ Nullable(String) │
│ dropoff │ Nullable(String) │
│ cab_type │ Nullable(String) │
│ pickup_nyct2010_gid │ Nullable(Int64) │
│ pickup_ctlabel │ Nullable(Float64) │
│ pickup_borocode │ Nullable(Int64) │
│ pickup_ct2010 │ Nullable(String) │
│ pickup_boroct2010 │ Nullable(String) │
│ pickup_cdeligibil │ Nullable(String) │
│ pickup_ntacode │ Nullable(String) │
│ pickup_ntaname │ Nullable(String) │
│ pickup_puma │ Nullable(Int64) │
│ dropoff_nyct2010_gid │ Nullable(Int64) │
│ dropoff_ctlabel │ Nullable(Float64) │
│ dropoff_borocode │ Nullable(Int64) │
│ dropoff_ct2010 │ Nullable(String) │
│ dropoff_boroct2010 │ Nullable(String) │
│ dropoff_cdeligibil │ Nullable(String) │
│ dropoff_ntacode │ Nullable(String) │
│ dropoff_ntaname │ Nullable(String) │
│ dropoff_puma │ Nullable(Int64) │
└───────────────────────┴────────────────────┘
S3 기반 데이터셋과 상호 작용하기 위해 대상이 될 표준 MergeTree 테이블을 준비합니다. 아래 구문은 기본 데이터베이스에 trips라는 이름의 테이블을 생성합니다. 위에서 유추한 대로, 특히 Nullable() 데이터 타입 수정자를 사용하지 않기 위해 일부 데이터 타입을 변경하기로 했다는 점에 유의하십시오. Nullable()을 사용하면 불필요한 추가 저장 공간이 사용되고 성능 오버헤드가 발생할 수 있습니다:
CREATE TABLE trips
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime
pickup_date 필드에 대한 partitioning 사용에 주목하십시오. 일반적으로 파티션 키는 데이터 관리 목적이지만, 이후 이 키를 사용하여 S3로의 쓰기를 병렬화하는 데 사용할 것입니다.
택시 데이터셋의 각 항목은 하나의 택시 운행(trip)을 나타냅니다. 이 익명화된 데이터는 https://datasets-documentation.s3.eu-west-3.amazonaws.com/ S3 버킷의 nyc-taxi 폴더 아래에 압축된 상태로 저장된 2,000만 개의 레코드로 구성됩니다. 데이터는 TSV 형식이며, 파일당 약 100만 행이 있습니다.
S3에서 데이터 읽기
S3 데이터를 ClickHouse에 영구적으로 저장하지 않고도 데이터 소스로 쿼리할 수 있습니다. 다음 쿼리에서는 10개의 행을 샘플링합니다. 버킷이 공개되어 있어 누구나 접근할 수 있으므로 여기에는 인증 정보가 포함되어 있지 않습니다.
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames')
LIMIT 10;
TabSeparatedWithNames 포맷은 첫 번째 행에 컬럼 이름을 인코딩하기 때문에 컬럼을 나열할 필요가 없습니다. CSV 또는 TSV와 같은 다른 포맷은 이 쿼리에 대해 c1, c2, c3 등과 같이 자동 생성된 컬럼을 반환합니다.
쿼리는 또한 _path, _file과 같이 버킷 경로와 파일 이름에 대한 정보를 제공하는 가상 컬럼도 지원합니다. 예를 들어:
SELECT _path, _file, trip_id
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_0.gz', 'TabSeparatedWithNames')
LIMIT 5;
┌─_path──────────────────────────────────────┬─_file──────┬────trip_id─┐
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999902 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999919 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999944 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999969 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999990 │
└────────────────────────────────────────────┴────────────┴────────────┘
이 샘플 데이터 세트의 행 개수를 확인하십시오. 파일 확장을 위해 와일드카드를 사용하므로 20개 모든 파일을 대상으로 합니다. 이 쿼리는 ClickHouse 인스턴스의 코어 수에 따라 약 10초 정도 소요됩니다:
SELECT count() AS count
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames');
┌────count─┐
│ 20000000 │
└──────────┘
데이터 샘플링이나 애드 혹(ad-hoc) 탐색형 쿼리를 실행하는 데는 유용하지만, S3에서 데이터를 직접 읽는 방식은 정기적으로 사용하기에 적합하지 않습니다. 본격적으로 작업을 진행할 때에는 데이터를 ClickHouse의 MergeTree 테이블로 가져와 적재하십시오.
clickhouse-local 사용하기
clickhouse-local 프로그램을 사용하면 ClickHouse 서버를 배포하거나 구성하지 않고도 로컬 파일을 빠르게 처리할 수 있습니다. s3 table function(테이블 함수)을 사용하는 모든 쿼리는 이 유틸리티로 실행할 수 있습니다. 예를 들어 다음과 같습니다.
clickhouse-local --query "SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') LIMIT 10"
S3에서 데이터 삽입하기
ClickHouse의 모든 기능을 활용하기 위해 이제 데이터를 읽어서 인스턴스로 삽입합니다.
s3 함수를 간단한 INSERT 문과 결합하여 이를 수행합니다. 대상 테이블이 필요한 구조를 제공하므로 컬럼을 나열할 필요는 없습니다. 이때 컬럼은 테이블 DDL 문에서 지정한 순서대로 나타나야 합니다. 컬럼은 SELECT 절에서의 위치에 따라 매핑됩니다. 전체 1,000만 행을 삽입하는 데에는 ClickHouse 인스턴스에 따라 몇 분 정도 소요될 수 있습니다. 아래 예시에서는 빠른 응답을 위해 100만 행만 삽입합니다. 필요한 경우 LIMIT 절이나 컬럼 선택을 조정하여 부분 집합만 임포트할 수 있습니다:
INSERT INTO trips
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames')
LIMIT 1000000;
ClickHouse Local을 사용한 원격 INSERT
네트워크 보안 정책으로 인해 ClickHouse 클러스터에서 아웃바운드 연결이 허용되지 않는 경우, clickhouse-local을 사용하여 S3 데이터를 INSERT할 수 있습니다. 아래 예시에서는 S3 버킷에서 데이터를 읽어 remote 함수를 사용해 ClickHouse에 INSERT합니다:
clickhouse-local --query "INSERT INTO TABLE FUNCTION remote('localhost:9000', 'default.trips', 'username', 'password') (*) SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') LIMIT 10"
참고
SSL 보안 연결을 통해 이를 실행하려면 remoteSecure 함수를 사용하십시오.
데이터 내보내기
s3 테이블 함수(table function)를 사용하여 S3의 파일에 데이터를 쓸 수 있습니다. 이를 위해서는 적절한 권한이 필요합니다. 필요한 자격 증명은 요청과 함께 전달하지만, 더 많은 옵션은 자격 증명 관리 페이지를 참고하십시오.
아래의 간단한 예제에서는 테이블 함수를 소스가 아닌 대상(destination)으로 사용합니다. 여기서는 trips 테이블에서 10,000개의 행을 버킷으로 스트리밍하고, lz4 압축과 출력 형식은 CSV로 지정합니다:
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
SELECT *
FROM trips
LIMIT 10000;
여기에서는 파일 형식이 확장자로부터 자동으로 유추된다는 점에 주목하십시오. 또한 s3 함수에서 컬럼을 명시할 필요가 없습니다. 이는 SELECT에서 추론할 수 있습니다.
대용량 파일 분할
데이터를 하나의 파일로 내보내는 경우는 많지 않습니다. ClickHouse를 포함한 대부분의 도구는 병렬 처리를 활용할 수 있으므로, 여러 파일에 동시에 읽고 쓰는 방식에서 더 높은 처리량을 달성합니다. INSERT 명령을 여러 번 실행하여 데이터의 부분 집합을 대상으로 할 수도 있습니다. ClickHouse는 PARTITION 키를 사용하여 파일을 자동으로 분할하는 기능을 제공합니다.
아래 예제에서는 rand() 함수의 나머지 연산 결과를 사용하여 10개의 파일을 생성합니다. 생성된 파티션 ID가 파일 이름에서 어떻게 참조되는지에 주목하십시오. 이를 통해 trips_0.csv.lz4, trips_1.csv.lz4 등과 같이 숫자 접미사가 붙은 10개의 파일이 생성됩니다.
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips_{_partition_id}.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
PARTITION BY rand() % 10
SELECT *
FROM trips
LIMIT 100000;
또는 데이터에 포함된 필드를 파티셔닝 기준으로 사용할 수도 있습니다. 이 데이터셋에서는 payment_type 필드가 카디널리티가 5인 자연스러운 파티셔닝 키 역할을 합니다.
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips_{_partition_id}.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
PARTITION BY payment_type
SELECT *
FROM trips
LIMIT 100000;
클러스터 활용
위에서 설명한 함수들은 모두 단일 노드에서만 실행됩니다. 네트워크와 같은 다른 리소스가 포화 상태가 될 때까지 읽기 속도는 CPU 코어 수에 비례하여 선형적으로 확장되며, 이를 통해 사용자는 수직 확장을 할 수 있습니다. 그러나 이러한 접근 방식에는 한계가 있습니다. INSERT INTO SELECT 쿼리를 수행할 때 분산 테이블에 데이터를 삽입하여 일부 리소스 부담을 완화할 수는 있지만, 여전히 단일 노드가 데이터를 읽고, 파싱하고, 처리하는 역할을 담당하게 됩니다. 이러한 문제를 해결하고 읽기를 수평으로 확장할 수 있도록 s3Cluster 함수를 사용할 수 있습니다.
쿼리를 수신하는 노드는 이니시에이터(initiator)라고 하며, 클러스터의 모든 노드에 대한 연결을 생성합니다. 어떤 파일을 읽어야 하는지 결정하는 글롭(glob) 패턴은 파일 집합으로 해석됩니다. 이니시에이터는 이 파일들을 클러스터의 노드(워커 역할을 하는 노드)들에게 분배합니다. 워커들은 읽기를 완료할 때마다 처리할 파일을 요청합니다. 이 과정 덕분에 읽기를 수평 확장할 수 있습니다.
s3Cluster 함수는 단일 노드용 함수들과 동일한 형식을 사용하되, 워커 노드를 나타내는 대상 클러스터를 필수 인자로 지정해야 합니다:
s3Cluster(cluster_name, source, [access_key_id, secret_access_key,] format, structure)
cluster_name — 원격 및 로컬 서버에 대한 주소 집합과 연결 파라미터를 구성하는 데 사용되는 클러스터 이름입니다.source — 하나의 파일 또는 여러 파일에 대한 URL입니다. 읽기 전용 모드에서 다음 와일드카드를 지원합니다: *, ?, {'abc','def'} 및 {N..M}(여기서 N, M — 숫자, abc, def — 문자열). 자세한 내용은 경로의 와일드카드를 참조하십시오.access_key_id 및 secret_access_key — 지정된 엔드포인트에서 사용할 자격 증명을 나타내는 키입니다. 선택 사항입니다.format — 파일의 포맷입니다.structure — 테이블 구조입니다. 포맷: 'column1_name column1_type, column2_name column2_type, ...'.
s3 함수와 마찬가지로, 버킷이 보안 설정 없이 열려 있거나 환경(IAM 역할 등)을 통해 보안을 정의하는 경우 자격 증명은 필수가 아닙니다. 그러나 s3 함수와 달리, 22.3.1 기준으로는 요청에서 반드시 structure를 지정해야 하며 스키마는 자동으로 유추되지 않습니다.
이 함수는 대부분의 경우 INSERT INTO SELECT의 일부로 사용됩니다. 이 경우 자주 분산 테이블에 데이터를 삽입하게 됩니다. 아래에서는 trips_all이 분산 테이블인 간단한 예를 보여 줍니다. 이 테이블은 events 클러스터를 사용하지만, 읽기 및 쓰기에 사용되는 노드 간 일관성은 필수 요건이 아닙니다:
INSERT INTO default.trips_all
SELECT *
FROM s3Cluster(
'events',
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz',
'TabSeparatedWithNames'
)
INSERT 작업은 이니시에이터 노드에서 수행됩니다. 이는 읽기 작업은 각 노드에서 수행되지만, 생성된 행은 분산을 위해 이니시에이터 노드로 라우팅된다는 뜻입니다. 처리량이 매우 높은 상황에서는 병목 현상이 발생할 수 있습니다. 이를 해결하기 위해 s3cluster 함수에 대해 parallel_distributed_insert_select 파라미터를 설정하십시오.
S3 테이블 엔진
s3 함수는 S3에 저장된 데이터에 대해 애드혹(ad-hoc) 쿼리를 실행할 수 있지만, 구문이 장황합니다. S3 테이블 엔진을 사용하면 버킷 URL과 인증 정보를 매번 다시 지정하지 않아도 됩니다. 이를 위해 ClickHouse는 S3 테이블 엔진을 제공합니다.
CREATE TABLE s3_engine_table (name String, value UInt32)
ENGINE = S3(path, [aws_access_key_id, aws_secret_access_key,] format, [compression])
[SETTINGS ...]
path — 파일 경로가 포함된 버킷 URL입니다. 읽기 전용 모드에서 다음 와일드카드를 지원합니다: *, ?, {abc,def}, {N..M}. 여기서 N, M은 숫자이고, 'abc', 'def'는 문자열입니다. 자세한 내용은 여기를 참고하십시오.format — 파일의 형식입니다.aws_access_key_id, aws_secret_access_key - AWS 계정 사용자에 대한 장기 자격 증명입니다. 요청을 인증하는 데 사용할 수 있습니다. 이 매개변수는 선택 사항입니다. 자격 증명이 지정되지 않은 경우 구성 파일의 값이 사용됩니다. 자세한 내용은 자격 증명 관리를 참고하십시오.compression — 압축 유형입니다. 지원되는 값: none, gzip/gz, brotli/br, xz/LZMA, zstd/zst. 이 매개변수는 선택 사항입니다. 기본적으로 파일 확장자를 기준으로 압축 유형을 자동으로 감지합니다.
데이터 읽기
다음 예에서는 https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/ 버킷에 위치한 처음 10개의 TSV 파일을 사용하여 trips_raw라는 이름의 테이블을 생성합니다. 각 파일에는 각각 100만 행이 포함되어 있습니다.
CREATE TABLE trips_raw
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type_` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` FixedString(7),
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` FixedString(7),
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
) ENGINE = S3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{0..9}.gz', 'TabSeparatedWithNames', 'gzip');
처음 10개 파일만 대상으로 하기 위해 {0..9} 패턴을 사용한 점에 유의하십시오. 생성이 완료되면 이 테이블은 다른 테이블과 마찬가지로 쿼리할 수 있습니다.
SELECT DISTINCT(pickup_ntaname)
FROM trips_raw
LIMIT 10;
┌─pickup_ntaname───────────────────────────────────┐
│ Lenox Hill-Roosevelt Island │
│ Airport │
│ SoHo-TriBeCa-Civic Center-Little Italy │
│ West Village │
│ Chinatown │
│ Hudson Yards-Chelsea-Flatiron-Union Square │
│ Turtle Bay-East Midtown │
│ Upper West Side │
│ Murray Hill-Kips Bay │
│ DUMBO-Vinegar Hill-Downtown Brooklyn-Boerum Hill │
└──────────────────────────────────────────────────┘
데이터 삽입
S3 테이블 엔진은 병렬 읽기(reads)를 지원합니다. 테이블 정의에 glob 패턴이 포함되지 않은 경우에만 쓰기가 지원됩니다. 따라서 위의 테이블은 쓰기가 차단됩니다.
쓰기를 시연하기 위해, 쓰기가 가능한 S3 버킷을 가리키는 테이블을 생성합니다:
CREATE TABLE trips_dest
(
`trip_id` UInt32,
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`tip_amount` Float32,
`total_amount` Float32
) ENGINE = S3('<bucket path>/trips.bin', 'Native');
INSERT INTO trips_dest
SELECT
trip_id,
pickup_date,
pickup_datetime,
dropoff_datetime,
tip_amount,
total_amount
FROM trips
LIMIT 10;
SELECT * FROM trips_dest LIMIT 5;
┌────trip_id─┬─pickup_date─┬─────pickup_datetime─┬────dropoff_datetime─┬─tip_amount─┬─total_amount─┐
│ 1200018648 │ 2015-07-01 │ 2015-07-01 00:00:16 │ 2015-07-01 00:02:57 │ 0 │ 7.3 │
│ 1201452450 │ 2015-07-01 │ 2015-07-01 00:00:20 │ 2015-07-01 00:11:07 │ 1.96 │ 11.76 │
│ 1202368372 │ 2015-07-01 │ 2015-07-01 00:00:40 │ 2015-07-01 00:05:46 │ 0 │ 7.3 │
│ 1200831168 │ 2015-07-01 │ 2015-07-01 00:01:06 │ 2015-07-01 00:09:23 │ 2 │ 12.3 │
│ 1201362116 │ 2015-07-01 │ 2015-07-01 00:01:07 │ 2015-07-01 00:03:31 │ 0 │ 5.3 │
└────────────┴─────────────┴─────────────────────┴─────────────────────┴────────────┴──────────────┘
행은 새 파일에만 삽입할 수 있습니다. 머지 사이클이나 파일 분할 작업은 없습니다. 한 번 파일이 작성되면 이후 삽입은 실패합니다. 사용자에게는 다음 두 가지 옵션이 있습니다:
s3_create_new_file_on_insert=1 SETTING을 지정합니다. 이렇게 하면 각 삽입 시마다 새 파일이 생성됩니다. 각 파일 끝에는 숫자 접미사가 추가되며, 삽입 작업이 수행될 때마다 단조 증가합니다. 위 예제에서 이후 삽입은 trips_1.bin 파일을 생성합니다.s3_truncate_on_insert=1 SETTING을 지정합니다. 이렇게 하면 파일이 잘려(truncate되어) 완료 시점에 새로 삽입된 행만 포함하게 됩니다.
이 두 SETTING의 기본값은 모두 0이므로, 사용자에게 둘 중 하나를 반드시 설정하도록 요구합니다. 둘 다 설정된 경우 s3_truncate_on_insert가 우선합니다.
S3 테이블 엔진에 대한 참고 사항:
- 기존
MergeTree 계열 테이블과 달리, S3 테이블을 DROP해도 기반 데이터는 삭제되지 않습니다.
- 이 테이블 유형에 대한 전체 설정은 여기에서 확인할 수 있습니다.
- 이 엔진을 사용할 때 다음 제약 사항에 유의하십시오:
- ALTER 쿼리는 지원되지 않습니다.
- SAMPLE 연산은 지원되지 않습니다.
- 기본 키나 스킵 인덱스 등 인덱스 개념이 없습니다.
자격 증명 관리
이전 예제에서는 s3 함수 또는 S3 테이블 정의에 자격 증명을 전달했습니다. 이는 가끔 사용하는 경우에는 허용될 수 있지만, 운영 환경에서는 자격 증명을 직접 노출하지 않는 인증 메커니즘을 사용하는 것이 일반적입니다. 이를 위해 ClickHouse는 여러 가지 옵션을 제공합니다:
-
config.xml 또는 conf.d 아래의 유사한 설정 파일에 연결 정보를 지정합니다. 다음은 Debian 패키지를 사용해 설치했다고 가정했을 때의 예시 파일 내용입니다.
ubuntu@single-node-clickhouse:/etc/clickhouse-server/config.d$ cat s3.xml
<clickhouse>
<s3>
<endpoint-name>
<endpoint>https://dalem-files.s3.amazonaws.com/test/</endpoint>
<access_key_id>key</access_key_id>
<secret_access_key>secret</secret_access_key>
<!-- <use_environment_credentials>false</use_environment_credentials> -->
<!-- <header>Authorization: Bearer SOME-TOKEN</header> -->
</endpoint-name>
</s3>
</clickhouse>
위의 endpoint가 요청된 URL의 접두사와 정확히 일치하는 모든 요청에 대해 이 자격 증명이 사용됩니다. 또한 이 예시에서는 access/secret 키의 대안으로 Authorization 헤더를 선언할 수 있다는 점에 유의하십시오. 지원되는 설정의 전체 목록은 여기에서 확인할 수 있습니다.
-
위 예제는 설정 파라미터 use_environment_credentials를 사용할 수 있음을 보여 줍니다. 이 설정 파라미터는 s3 수준에서 전역으로도 설정할 수 있습니다:
<clickhouse>
<s3>
<use_environment_credentials>true</use_environment_credentials>
</s3>
</clickhouse>
이 설정을 사용하면 환경으로부터 S3 자격 증명을 가져오도록 시도하여, IAM 역할을 통한 접근이 가능해집니다. 구체적으로는 다음 순서로 자격 증명을 조회합니다:
- 환경 변수
AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_SESSION_TOKEN 조회
- $HOME/.aws에서 확인
- AWS Security Token Service를 통해 획득한 임시 자격 증명 — 즉
AssumeRole API를 통해 획득
- ECS 환경 변수
AWS_CONTAINER_CREDENTIALS_RELATIVE_URI 또는 AWS_CONTAINER_CREDENTIALS_FULL_URI 및 AWS_ECS_CONTAINER_AUTHORIZATION_TOKEN에서 자격 증명 확인
- AWS_EC2_METADATA_DISABLED가 true로 설정되어 있지 않은 경우, Amazon EC2 인스턴스 메타데이터를 통해 자격 증명 획득
- 동일한 설정을 동일한 접두사 일치 규칙을 사용하여 특정 endpoint에만 적용되도록 설정할 수도 있습니다.
S3 FUNCTION을 사용하여 데이터를 읽고 삽입할 때 성능을 최적화하는 방법은 전용 성능 가이드를 참조하십시오.
S3 스토리지 튜닝
내부적으로 ClickHouse MergeTree는 두 가지 기본 스토리지 형식인 Wide 및 Compact를 사용합니다. 현재 구현은 ClickHouse의 기본 동작(설정 min_bytes_for_wide_part 및 min_rows_for_wide_part로 제어됨)을 따르지만, 향후 릴리스에서는 S3에 대해 동작이 달라질 것으로 예상합니다. 예를 들어 min_bytes_for_wide_part의 기본값을 더 크게 설정하여 보다 Compact 형식을 활용하고, 그에 따라 파일 수를 줄이는 방향이 될 수 있습니다. S3 스토리지만 사용하는 환경에서는 이러한 설정을 조정(튜닝)하는 것이 좋습니다.
S3 기반 MergeTree
s3 함수와 연관된 테이블 엔진을 사용하면 익숙한 ClickHouse 구문으로 S3의 데이터를 쿼리할 수 있습니다. 그러나 데이터 관리 기능과 성능 측면에서는 제약이 있습니다. 기본 인덱스(primary index)를 지원하지 않으며, 캐시도 지원되지 않고, 파일 삽입 작업은 사용자가 직접 관리해야 합니다.
ClickHouse는 특히 "콜드(cold)" 데이터에 대한 쿼리 성능이 크게 중요하지 않고 스토리지와 컴퓨트를 분리하려는 경우에 S3가 매력적인 스토리지 솔루션임을 인식합니다. 이를 위해 S3를 MergeTree 엔진의 스토리지로 사용할 수 있는 기능을 제공합니다. 이를 통해 S3의 확장성과 비용 효율성은 물론 MergeTree 엔진의 삽입 및 쿼리 성능까지 함께 활용할 수 있습니다.
Storage Tiers
ClickHouse 스토리지 볼륨을 사용하면 물리 디스크를 MergeTree 테이블 엔진으로부터 추상화할 수 있습니다. 각 볼륨은 정렬된 디스크 집합으로 구성될 수 있습니다. 이는 주로 여러 블록 디바이스를 데이터 저장에 사용할 수 있게 해줄 뿐만 아니라, S3를 포함한 다른 스토리지 유형도 사용할 수 있게 하는 추상화입니다. ClickHouse 데이터 파트는 스토리지 정책에 따라 볼륨 간에 이동되고 볼륨별 사용률을 조절할 수 있으며, 이를 통해 스토리지 계층(storage tiers)이라는 개념이 만들어집니다.
스토리지 계층은 가장 최근 데이터(일반적으로 쿼리가 가장 많이 발생하는 데이터)를 고성능 스토리지(예: NVMe SSD)에 적은 용량만 할당해 저장하는 핫-콜드(hot-cold) 아키텍처를 가능하게 합니다. 데이터가 오래될수록 쿼리 응답 시간에 대한 SLA 허용 범위가 커지고, 쿼리 빈도도 증가합니다. 이와 같은 롱테일(long tail) 데이터는 HDD와 같은 더 느리고 성능이 낮은 스토리지나 S3와 같은 객체 스토리지에 저장할 수 있습니다.
디스크 생성
S3 버킷을 디스크로 활용하려면 먼저 ClickHouse 설정 파일에 해당 디스크를 선언해야 합니다. config.xml을 수정하거나, 가능하면 conf.d 아래에 새로운 파일을 추가하십시오. 아래는 S3 디스크 선언 예시입니다:
<clickhouse>
<storage_configuration>
...
<disks>
<s3>
<type>s3</type>
<endpoint>https://sample-bucket.s3.us-east-2.amazonaws.com/tables/</endpoint>
<access_key_id>your_access_key_id</access_key_id>
<secret_access_key>your_secret_access_key</secret_access_key>
<region></region>
<metadata_path>/var/lib/clickhouse/disks/s3/</metadata_path>
</s3>
<s3_cache>
<type>cache</type>
<disk>s3</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
...
</storage_configuration>
</clickhouse>
이 디스크 선언과 관련된 설정의 전체 목록은 여기에서 확인할 수 있습니다. 자격 증명은 자격 증명 관리에 설명된 것과 동일한 방식으로 여기에서 관리할 수 있습니다. 즉, 위 설정 블록에서 use_environment_credentials를 true로 설정하여 IAM 역할을 사용할 수 있습니다.
스토리지 정책 생성
구성이 완료되면, 이 "disk"는 정책에 정의된 스토리지 볼륨에서 사용할 수 있습니다. 아래 예시에서는 s3가 유일한 스토리지라고 가정합니다. 이는 TTL과 공간 사용률에 따라 데이터를 재배치하는 보다 복잡한 핫-콜드 아키텍처는 고려하지 않습니다.
<clickhouse>
<storage_configuration>
<disks>
<s3>
...
</s3>
<s3_cache>
...
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
테이블 생성
쓰기 권한이 있는 버킷을 사용하도록 디스크를 구성했다고 가정하면, 아래 예시와 같은 테이블을 생성할 수 있습니다. 간단히 하기 위해 NYC 택시 컬럼의 일부만 사용하고, 데이터를 S3를 백엔드로 사용하는 테이블로 직접 스트리밍합니다:
CREATE TABLE trips_s3
(
`trip_id` UInt32,
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`tip_amount` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime
SETTINGS storage_policy='s3_main'
INSERT INTO trips_s3 SELECT trip_id, pickup_date, pickup_datetime, dropoff_datetime, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, passenger_count, trip_distance, tip_amount, total_amount, payment_type FROM s3('https://ch-nyc-taxi.s3.eu-west-3.amazonaws.com/tsv/trips_{0..9}.tsv.gz', 'TabSeparatedWithNames') LIMIT 1000000;
하드웨어에 따라 두 번째 100만 행 insert 작업의 실행에는 몇 분이 걸릴 수 있습니다. system.processes 테이블을 통해 진행 상황을 확인할 수 있습니다. 행 수를 최대 1,000만까지 조정하여 몇 가지 샘플 쿼리를 실행해 보십시오.
SELECT passenger_count, avg(tip_amount) AS avg_tip, avg(total_amount) AS avg_amount FROM trips_s3 GROUP BY passenger_count;
테이블 수정
때때로 특정 테이블의 스토리지 정책을 수정해야 할 때가 있습니다. 이는 가능하지만 몇 가지 제약이 있습니다. 새로운 대상 정책에는 이전 정책의 모든 디스크와 볼륨이 포함되어야 하며, 즉 정책 변경을 위해 데이터를 마이그레이션하지는 않습니다. 이러한 제약 조건을 검증할 때 볼륨과 디스크는 이름으로 식별되며, 이를 위반하는 경우 오류가 발생합니다. 다만 앞선 예시를 사용했다고 가정하면, 다음과 같은 변경은 유효합니다.
<policies>
<s3_main>
<volumes>
<main>
<disk>s3</disk>
</main>
</volumes>
</s3_main>
<s3_tiered>
<volumes>
<hot>
<disk>default</disk>
</hot>
<main>
<disk>s3</disk>
</main>
</volumes>
<move_factor>0.2</move_factor>
</s3_tiered>
</policies>
ALTER TABLE trips_s3 MODIFY SETTING storage_policy='s3_tiered'
여기서는 새로운 s3_tiered 정책에서 기본 볼륨을 재사용하고, 새로운 hot 볼륨을 도입합니다. 이 설정은 기본 디스크를 사용하며, 기본 디스크는 <path> 파라미터를 통해 설정된 단일 디스크로만 구성됩니다. 볼륨 이름과 디스크는 변경되지 않는다는 점에 유의하십시오. 테이블에 새로 삽입되는 데이터는 기본 디스크에 저장되며, 이 디스크가 move_factor * disk_size에 도달할 때까지는 기본 디스크에 유지되고, 해당 시점에 데이터가 S3로 이동됩니다.
복제 처리
S3 디스크를 사용한 복제는 ReplicatedMergeTree 테이블 엔진으로 구현할 수 있습니다. 자세한 내용은 S3 객체 스토리지를 사용하여 단일 세그먼트를 두 개의 AWS 리전에 걸쳐 복제하는 방법 가이드를 참조하십시오.
읽기 및 쓰기
다음 내용은 ClickHouse와 S3 간 상호 작용의 구현 방식에 대해 설명합니다. 일반적으로 참고용 정보이지만, 성능 최적화에 도움이 될 수 있습니다.
- 기본적으로 쿼리 처리 파이프라인의 각 단계에서 사용할 수 있는 쿼리 처리 스레드의 최대 개수는 코어 수와 같습니다. 일부 단계는 다른 단계보다 병렬화가 더 잘되므로, 이 값은 상한선을 의미합니다. 디스크에서 데이터가 스트리밍되므로 여러 쿼리 단계가 동시에 실행될 수 있습니다. 따라서 실제로 하나의 쿼리에 사용되는 스레드 수는 이 값을 초과할 수 있습니다. max_threads 설정을 통해 수정할 수 있습니다.
- S3에서의 읽기는 기본적으로 비동기 방식입니다. 이 동작은 기본값이
threadpool인 remote_filesystem_read_method 설정에 의해 결정됩니다. 요청을 처리할 때 ClickHouse는 그래뉼을 스트라이프 단위로 읽습니다. 각 스트라이프에는 여러 개의 컬럼이 포함될 수 있습니다. 하나의 스레드는 해당 그래뉼에 대한 컬럼을 하나씩 순차적으로 읽습니다. 이를 동기적으로 처리하는 대신, 데이터를 기다리기 전에 모든 컬럼에 대해 미리 가져오기(prefetch)를 수행합니다. 이는 각 컬럼마다 동기적으로 대기하는 방식에 비해 상당한 성능 향상을 제공합니다. 대부분의 경우 이 설정을 변경할 필요는 없습니다. 자세한 내용은 성능 최적화를 참조하십시오.
- 쓰기는 병렬로 수행되며, 동시에 실행되는 파일 쓰기 스레드의 최대 개수는 100개입니다. 기본값이 1000인
max_insert_delayed_streams_for_parallel_write 설정은 동시에 병렬로 쓰이는 S3 blob의 개수를 제어합니다. 각 파일을 쓰는 데는 약 1MB 크기의 버퍼가 필요하므로, 이는 사실상 INSERT의 메모리 사용량을 제한합니다. 서버 메모리가 적은 환경에서는 이 값을 낮추는 것이 적절할 수 있습니다.
S3 객체 스토리지를 ClickHouse 디스크로 사용하기
버킷과 IAM 역할을 단계별로 생성하는 방법이 필요하면 "AWS IAM 사용자와 S3 버킷을 생성하는 방법"을 참고하십시오.
다음 예시는 Linux Deb 패키지를 서비스로 설치하고 기본 ClickHouse 디렉터리를 사용하는 환경을 기준으로 합니다.
- 스토리지 구성을 저장하기 위해 ClickHouse
config.d 디렉터리에 새 파일을 생성합니다.
vim /etc/clickhouse-server/config.d/storage_config.xml
- 다음 스토리지 구성 항목을 추가하고 앞선 단계에서 사용한 버킷 경로와 access key, secret key로 값을 대체하십시오
<clickhouse>
<storage_configuration>
<disks>
<s3_disk>
<type>s3</type>
<endpoint>https://mars-doc-test.s3.amazonaws.com/clickhouse3/</endpoint>
<access_key_id>ABC123</access_key_id>
<secret_access_key>Abc+123</secret_access_key>
<metadata_path>/var/lib/clickhouse/disks/s3_disk/</metadata_path>
</s3_disk>
<s3_cache>
<type>cache</type>
<disk>s3_disk</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3_disk</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
참고
<disks> 태그 내의 s3_disk 및 s3_cache 태그는 임의로 지정한 레이블입니다. 다른 이름으로 설정해도 되지만, 디스크를 참조하기 위해서는 동일한 레이블을 <policies> 태그 아래의 <disk> 태그에서도 사용해야 합니다.
<S3_main> 태그 역시 임의로 지정한 값이며, ClickHouse에서 리소스를 생성할 때 스토리지 대상 식별자로 사용되는 정책의 이름입니다.
위에 표시된 설정은 ClickHouse 22.8 이상 버전용입니다. 더 낮은 버전을 사용하는 경우 데이터 저장 문서를 참고하십시오.
S3 사용에 대한 자세한 정보:
연동 가이드: S3 Backed MergeTree
- 파일의 소유자를
clickhouse 사용자와 그룹으로 변경합니다.
chown clickhouse:clickhouse /etc/clickhouse-server/config.d/storage_config.xml
- 변경 사항이 적용되도록 ClickHouse 인스턴스를 재시작합니다.
service clickhouse-server restart
테스트
- 다음과 같이 ClickHouse 클라이언트로 로그인합니다.
clickhouse-client --user default --password ClickHouse123!
- 새로운 S3 스토리지 정책을 지정해 테이블을 생성합니다
CREATE TABLE s3_table1
(
`id` UInt64,
`column1` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS storage_policy = 's3_main';
- 테이블이 올바른 정책으로 생성되었는지 확인합니다
SHOW CREATE TABLE s3_table1;
┌─statement────────────────────────────────────────────────────
│ CREATE TABLE default.s3_table1
(
`id` UInt64,
`column1` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS storage_policy = 's3_main', index_granularity = 8192
└──────────────────────────────────────────────────────────────
- 테이블에 테스트용 행을 삽입합니다
INSERT INTO s3_table1
(id, column1)
VALUES
(1, 'abc'),
(2, 'xyz');
INSERT INTO s3_table1 (id, column1) FORMAT Values
Query id: 0265dd92-3890-4d56-9d12-71d4038b85d5
Ok.
2 rows in set. Elapsed: 0.337 sec.
- 행을 확인합니다
┌─id─┬─column1─┐
│ 1 │ abc │
│ 2 │ xyz │
└────┴─────────┘
2 rows in set. Elapsed: 0.284 sec.
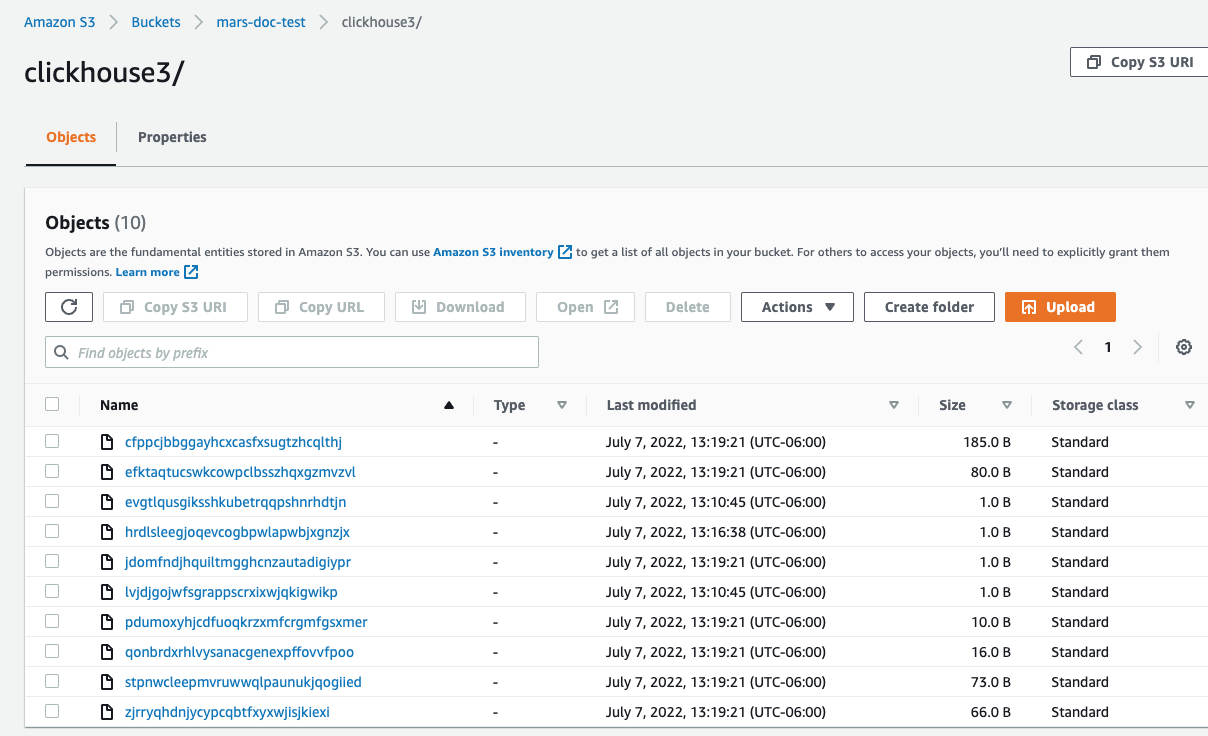
- AWS 콘솔에서 S3 버킷 페이지로 이동한 다음, 새로 만든 버킷과 해당 폴더를 선택합니다.
다음과 비슷한 화면이 표시됩니다.
S3 객체 스토리지를 사용하여 단일 세그먼트를 두 개의 AWS 리전에 걸쳐 복제하기
팁
객체 스토리지는 ClickHouse Cloud에서 기본적으로 사용되므로 ClickHouse Cloud에서 실행 중이라면 이 절차를 따를 필요가 없습니다.
배포 계획 수립
이 튜토리얼은 AWS EC2에 두 개의 ClickHouse Server 노드와 세 개의 ClickHouse Keeper 노드를 배포하는 구성을 기반으로 합니다. ClickHouse 서버의 데이터 저장소는 S3입니다. 재해 복구를 지원하기 위해 두 개의 AWS 리전을 사용하며, 각 리전에 하나의 ClickHouse Server와 하나의 S3 버킷을 둡니다.
ClickHouse 테이블은 두 서버 간, 즉 두 리전 간에 복제되도록 구성됩니다.
소프트웨어 설치
ClickHouse 서버 노드
ClickHouse 서버 노드에서 배포 작업을 수행할 때는 설치 지침을 참조하십시오.
ClickHouse 배포
두 호스트에 ClickHouse를 배포합니다. 예제 구성에서는 이 호스트의 이름을 chnode1, chnode2로 지정합니다.
chnode1은 하나의 AWS 리전에, chnode2는 다른 AWS 리전에 배치합니다.
ClickHouse Keeper 배포
세 개의 호스트에 ClickHouse Keeper를 배포합니다. 예시 구성에서는 이 호스트들의 이름이 keepernode1, keepernode2, keepernode3로 지정됩니다. keepernode1은 chnode1과 동일한 리전에, keepernode2는 chnode2와 동일한 리전에 배포하고, keepernode3는 두 리전 중 어느 쪽이든 배포하되, 해당 리전의 ClickHouse 노드와는 다른 가용 영역(availability zone)에 배포해야 합니다.
ClickHouse Keeper 노드에서 배포 절차를 수행할 때는 설치 안내를 참조하십시오.
S3 버킷 생성
chnode1과 chnode2를 배치한 각 리전에 S3 버킷 2개를 생성합니다.
버킷과 IAM 역할을 단계별로 생성하는 방법이 필요한 경우 Create S3 buckets and an IAM role을 펼쳐서 안내를 따르십시오:
S3 버킷과 IAM 사용자 생성하기
이 문서에서는 AWS IAM 사용자 구성, S3 버킷 생성, 그리고 ClickHouse가 해당 버킷을 S3 디스크로 사용하도록 설정하는 기본 방법을 설명합니다.
보안 팀과 협력하여 사용할 권한을 결정하시고, 본 문서의 내용을 시작점으로 참고하십시오.
AWS IAM 사용자 생성하기
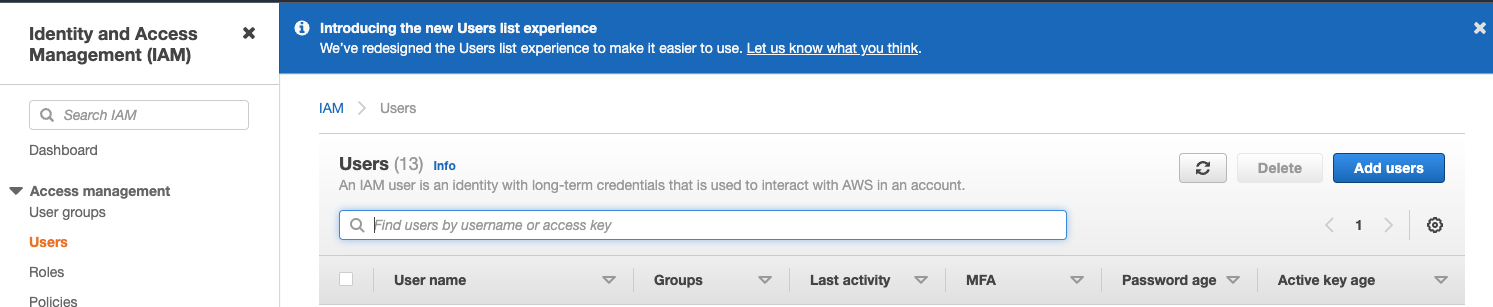
다음 단계에서는 서비스 계정 사용자를 생성합니다(로그인 사용자가 아닙니다).
-
AWS IAM 관리 콘솔에 로그인합니다.
-
Users 메뉴에서 Create user를 선택합니다
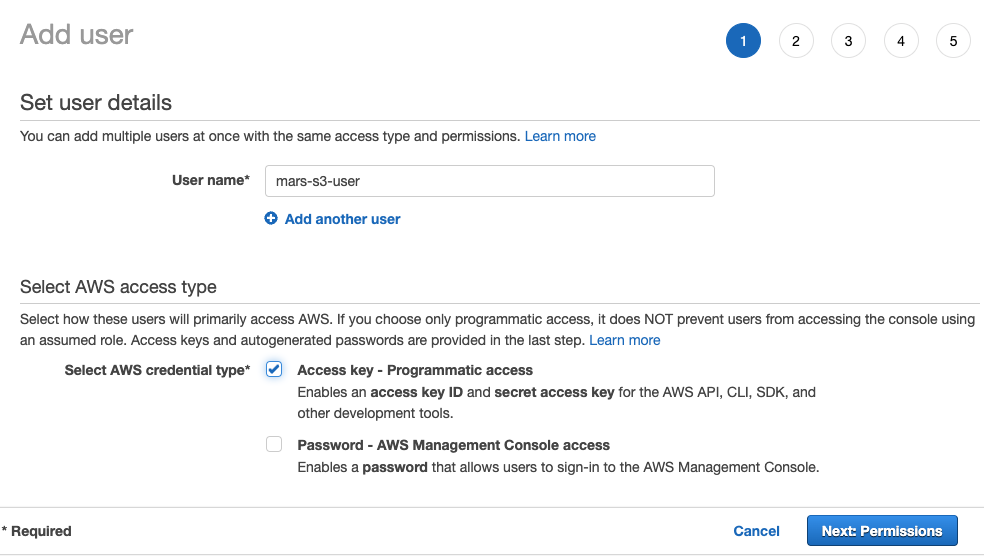
- 사용자 이름을 입력하고 자격 증명 유형을
Access key - Programmatic access로 설정한 다음 Next: Permissions 버튼을 선택합니다.
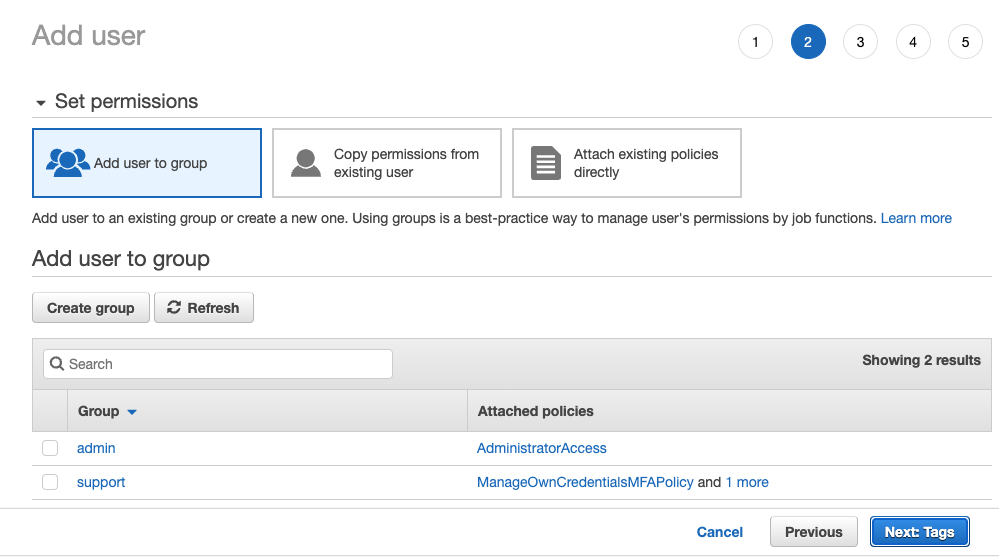
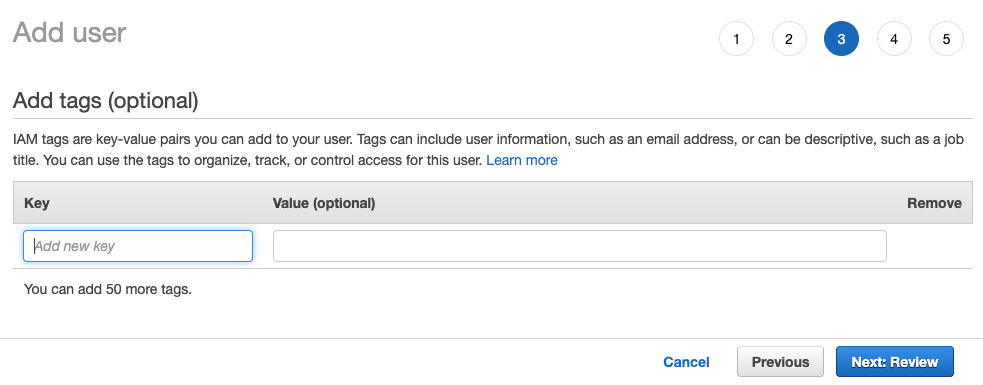
- 사용자를 어떤 그룹에도 추가하지 말고
Next: Tags를 선택하십시오.
- 추가할 태그가 없으면
Next: Review를 선택하십시오
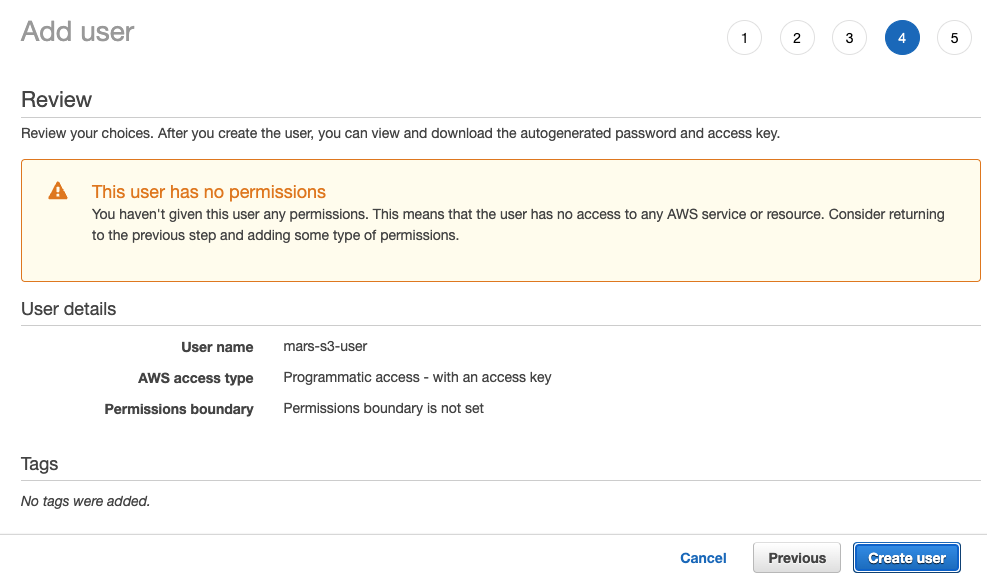
Create User를 선택하십시오
참고
사용자에게 권한이 없다는 경고 메시지는 무시하셔도 됩니다. 다음 섹션에서 버킷에 대한 권한이 부여됩니다
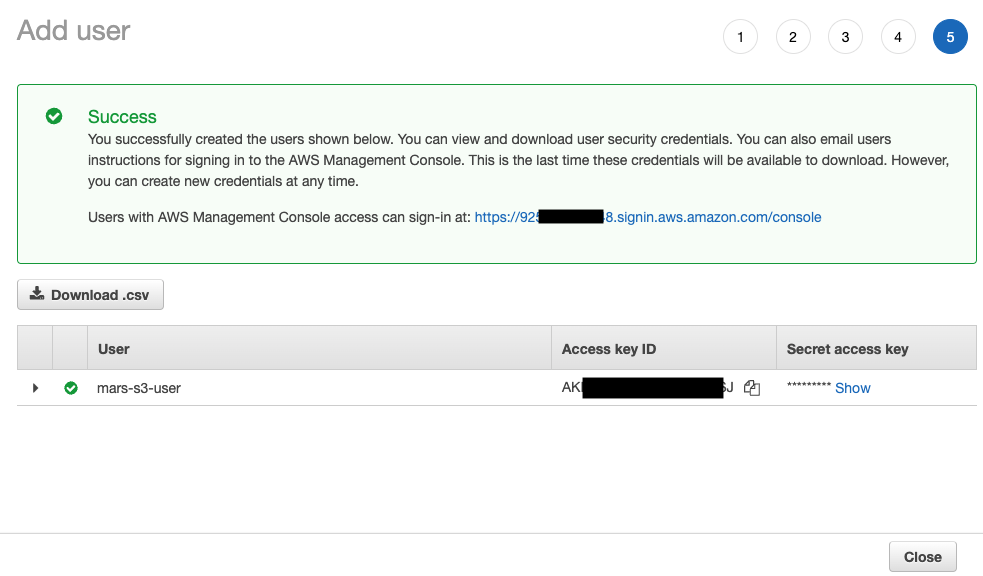
- 이제 사용자가 생성되었습니다.
show를 클릭한 뒤 액세스 키와 시크릿 키를 복사합니다.
참고
키를 다른 곳에 저장하세요. 비밀 액세스 키(secret access key)는 이번에만 확인할 수 있습니다.
- 닫기를 클릭한 다음 Users 화면에서 사용자를 찾습니다.
- ARN(Amazon Resource Name)을 복사하여 버킷의 액세스 정책을 구성할 때 사용하기 위해 저장합니다.
S3 버킷 생성
- S3 버킷 섹션에서
Create bucket을 선택하십시오
- 버킷 이름을 입력하고 나머지 옵션은 기본값으로 두십시오
참고
버킷 이름은 조직 내에서만이 아니라 AWS 전체에서 고유해야 합니다. 그렇지 않으면 오류가 발생합니다.
Block all Public Access는 활성화된 상태로 유지하십시오. 퍼블릭 액세스는 필요하지 않습니다.
- 페이지 하단에서
Create Bucket을 선택하십시오.
-
링크를 선택해 ARN을 복사한 후, 나중에 버킷 액세스 정책을 구성할 때 사용할 수 있도록 저장합니다.
-
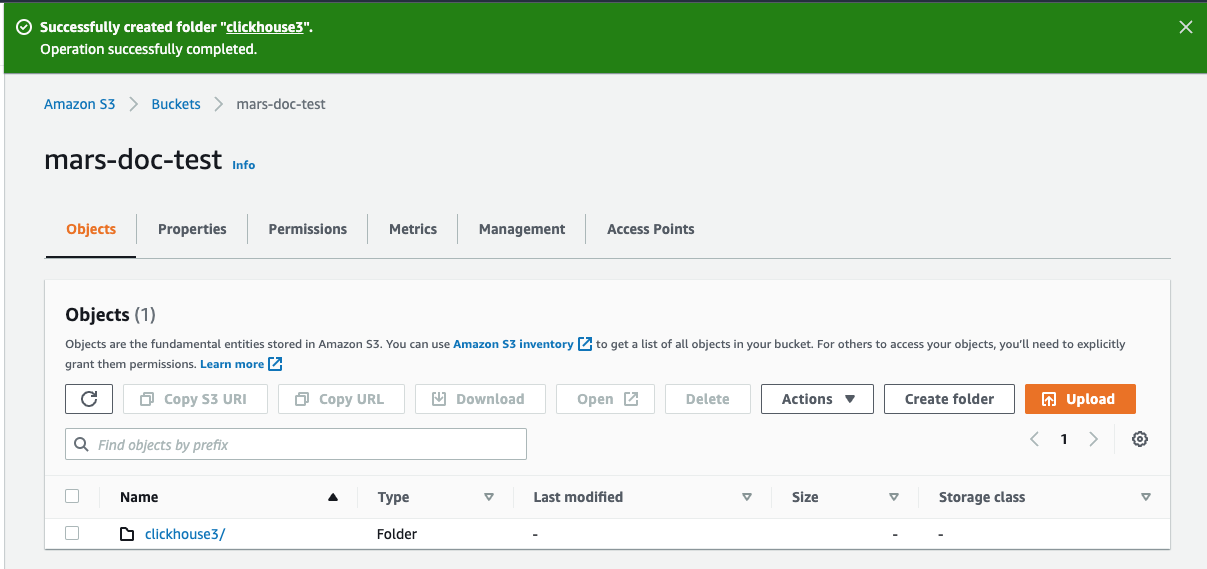
버킷이 생성되면 S3 버킷 목록에서 새 S3 버킷을 찾아 해당 링크를 클릭합니다
Create folder 옵션을 선택하십시오
- ClickHouse S3 디스크의 대상으로 사용할 폴더 이름을 입력한 후
Create folder를 선택합니다
- 이제 해당 폴더가 버킷 목록에 표시되어야 합니다
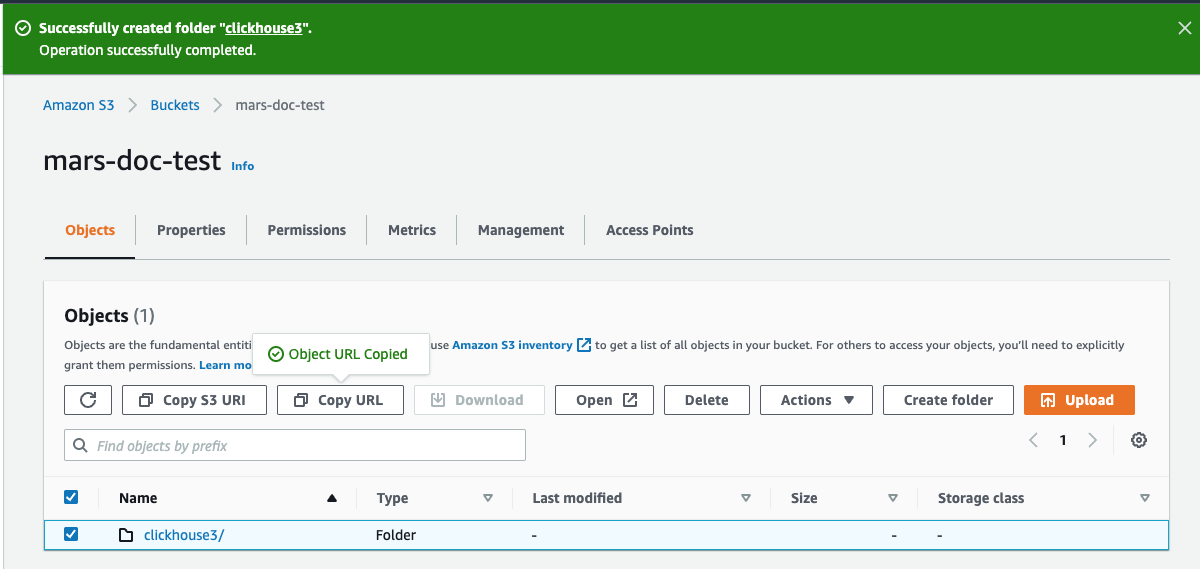
- 새 폴더의 체크박스를 선택한 다음
Copy URL을 클릭하십시오. 복사한 URL은 다음 섹션에서 ClickHouse 스토리지 구성을 위해 사용할 수 있도록 저장해 두십시오.
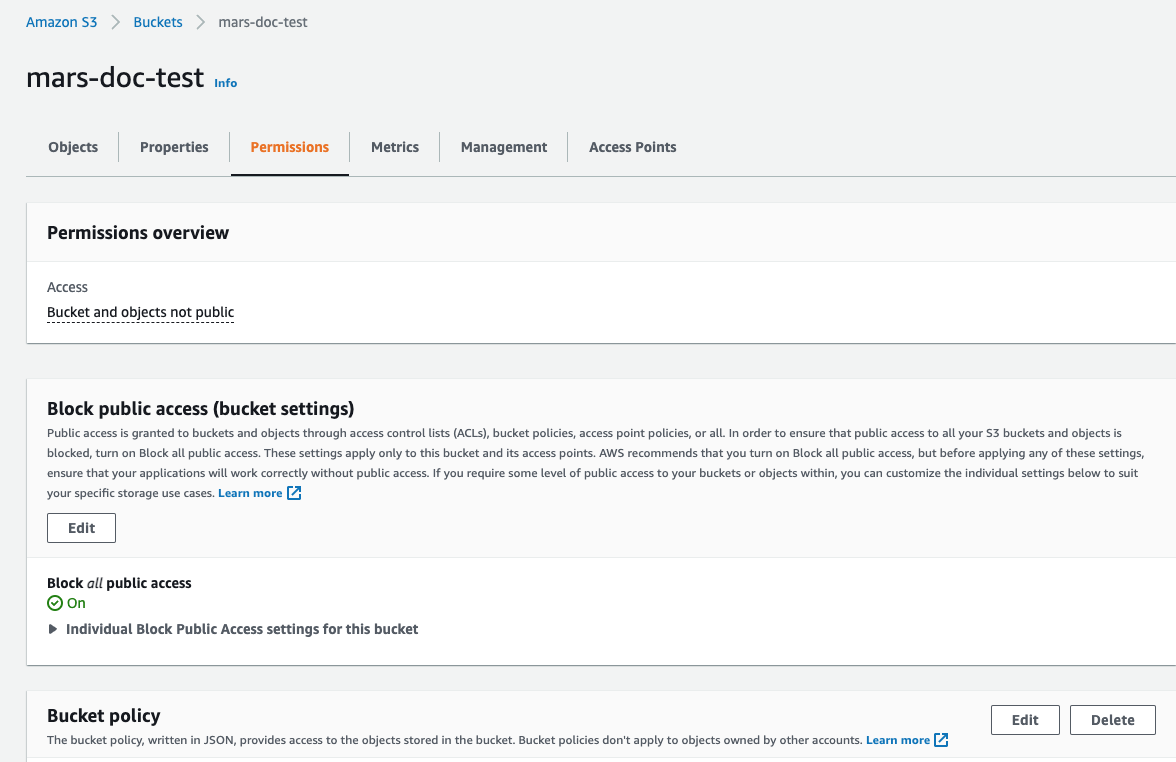
Permissions 탭을 선택한 다음 Bucket Policy 섹션에서 Edit 버튼을 클릭합니다
- 아래 예시와 같이 버킷 정책을 추가합니다:
{
"Version" : "2012-10-17",
"Id" : "Policy123456",
"Statement" : [
{
"Sid" : "abc123",
"Effect" : "Allow",
"Principal" : {
"AWS" : "arn:aws:iam::921234567898:user/mars-s3-user"
},
"Action" : "s3:*",
"Resource" : [
"arn:aws:s3:::mars-doc-test",
"arn:aws:s3:::mars-doc-test/*"
]
}
]
}
|Parameter | Description | Example Value |
|----------|-------------|----------------|
|Version | Version of the policy interpreter, leave as-is | 2012-10-17 |
|Sid | User-defined policy id | abc123 |
|Effect | Whether user requests will be allowed or denied | Allow |
|Principal | The accounts or user that will be allowed | arn:aws:iam::921234567898:user/mars-s3-user |
|Action | What operations are allowed on the bucket| s3:*|
|Resource | Which resources in the bucket will operations be allowed in | "arn:aws:s3:::mars-doc-test", "arn:aws:s3:::mars-doc-test/*" |
- 정책 설정을 저장하십시오.
설정 파일은 /etc/clickhouse-server/config.d/에 배치됩니다. 다음은 하나의 버킷에 대한 예시 설정 파일이며, 다른 하나는 강조된 세 줄만 다르고 나머지는 동일합니다:
<clickhouse>
<storage_configuration>
<disks>
<s3_disk>
<type>s3</type>
<!--highlight-start-->
<endpoint>https://docs-clickhouse-s3.s3.us-east-2.amazonaws.com/clickhouses3/</endpoint>
<access_key_id>ABCDEFGHIJKLMNOPQRST</access_key_id>
<secret_access_key>Tjdm4kf5snfkj303nfljnev79wkjn2l3knr81007</secret_access_key>
<!--highlight-end-->
<metadata_path>/var/lib/clickhouse/disks/s3_disk/</metadata_path>
</s3_disk>
<s3_cache>
<type>cache</type>
<disk>s3_disk</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3_disk</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
참고
이 가이드의 여러 단계에서는 구성 파일을 /etc/clickhouse-server/config.d/에 두도록 요구합니다. 이는 Linux 시스템에서 구성 재정의 파일의 기본 위치입니다. 해당 디렉터리에 이러한 파일을 두면 ClickHouse는 그 내용을 사용해 기본 구성을 재정의합니다. 구성 재정의 디렉터리에 파일을 두면 업그레이드 시 구성 설정이 손실되는 것을 방지할 수 있습니다.
ClickHouse Keeper를 단독으로 실행하는 경우(ClickHouse server와 분리하여 실행하는 경우) 설정은 단일 XML 파일로 구성됩니다. 이 튜토리얼에서 사용하는 파일은 /etc/clickhouse-keeper/keeper_config.xml입니다. 세 개의 Keeper 서버는 모두 동일한 설정을 사용하며, 단 하나의 설정 값만 다릅니다. 바로 <server_id>입니다.
server_id는 해당 설정 파일이 사용되는 호스트에 할당할 ID를 나타냅니다. 아래 예시에서 server_id는 3이며, 파일 아래쪽의 <raft_configuration> 섹션을 보면 서버 3의 호스트명이 keepernode3인 것을 확인할 수 있습니다. ClickHouse Keeper 프로세스는 이를 통해 리더를 선택하고 기타 모든 작업을 수행할 때 어떤 다른 서버에 연결해야 하는지 알게 됩니다.
<clickhouse>
<logger>
<level>trace</level>
<log>/var/log/clickhouse-keeper/clickhouse-keeper.log</log>
<errorlog>/var/log/clickhouse-keeper/clickhouse-keeper.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<listen_host>0.0.0.0</listen_host>
<keeper_server>
<tcp_port>9181</tcp_port>
<!--highlight-next-line-->
<server_id>3</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>warning</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>keepernode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>keepernode2</hostname>
<port>9234</port>
</server>
<!--highlight-start-->
<server>
<id>3</id>
<hostname>keepernode3</hostname>
<port>9234</port>
</server>
<!--highlight-end-->
</raft_configuration>
</keeper_server>
</clickhouse>
ClickHouse Keeper용 설정 파일을 해당 위치로 복사하십시오 (<server_id>를 설정했는지 확인하십시오):
sudo -u clickhouse \
cp keeper.xml /etc/clickhouse-keeper/keeper.xml
클러스터 정의
ClickHouse 클러스터는 구성의 <remote_servers> 섹션에서 정의합니다. 이 예제에서는 cluster_1S_2R라는 하나의 클러스터가 정의되어 있으며, 하나의 세그먼트와 두 개의 레플리카로 구성되어 있습니다. 레플리카는 chnode1 및 chnode2 호스트에 위치해 있습니다.
<clickhouse>
<remote_servers replace="true">
<cluster_1S_2R>
<shard>
<replica>
<host>chnode1</host>
<port>9000</port>
</replica>
<replica>
<host>chnode2</host>
<port>9000</port>
</replica>
</shard>
</cluster_1S_2R>
</remote_servers>
</clickhouse>
클러스터를 사용할 때는 DDL 쿼리에 클러스터, 세그먼트(shard), 레플리카(replica) 설정을 채워 넣는 매크로를 정의해 두면 편리합니다. 이 예제는 shard 및 replica 세부 정보를 명시하지 않고도 복제 테이블 엔진(Replicated Table Engine)을 사용하도록 지정할 수 있게 해줍니다. 테이블을 생성한 후 system.tables를 조회하면 shard와 replica 매크로가 어떻게 사용되는지 확인할 수 있습니다.
<clickhouse>
<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
<macros>
<cluster>cluster_1S_2R</cluster>
<shard>1</shard>
<replica>replica_1</replica>
</macros>
</clickhouse>
참고
위 매크로는 chnode1에 대한 것이며, chnode2에서는 replica를 replica_2로 설정하십시오.
zero-copy 복제를 비활성화합니다
ClickHouse 22.7 및 그 이전 버전에서는 S3 및 HDFS 디스크에 대해 allow_remote_fs_zero_copy_replication 설정이 기본적으로 true로 설정되어 있습니다. 이 재해 복구 시나리오에서는 이 설정을 false로 변경해야 하며, 22.8 및 이후 버전에서는 기본값이 false로 설정됩니다.
이 설정은 두 가지 이유로 false여야 합니다. 1) 이 기능은 아직 프로덕션 환경용으로 성숙하지 않았습니다. 2) 재해 복구 시나리오에서는 데이터와 메타데이터가 모두 여러 리전에 저장되어야 합니다. allow_remote_fs_zero_copy_replication을 false로 설정하십시오.
<clickhouse>
<merge_tree>
<allow_remote_fs_zero_copy_replication>false</allow_remote_fs_zero_copy_replication>
</merge_tree>
</clickhouse>
ClickHouse Keeper는 ClickHouse 노드 간 데이터 복제를 조율하는 역할을 담당합니다. ClickHouse가 ClickHouse Keeper 노드를 인지하도록 각 ClickHouse 노드에 구성 파일을 추가합니다.
<clickhouse>
<zookeeper>
<node index="1">
<host>keepernode1</host>
<port>9181</port>
</node>
<node index="2">
<host>keepernode2</host>
<port>9181</port>
</node>
<node index="3">
<host>keepernode3</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
서버 간 통신 및 서버와 사용자 간 통신이 가능하도록 AWS에서 보안 설정을 구성할 때 network ports 목록을 참고하십시오.
세 대의 서버는 모두 네트워크 연결을 수신 대기하도록 설정되어야 하며, 이를 통해 서로 간과 S3와 통신할 수 있습니다. 기본적으로 ClickHouse는 루프백 주소(로컬호스트)에서만 연결을 수신 대기하므로 이 설정을 변경해야 합니다. 이는 /etc/clickhouse-server/config.d/에서 구성합니다. 아래는 ClickHouse와 ClickHouse Keeper가 모든 IPv4 인터페이스에서 연결을 수신 대기하도록 설정하는 예시입니다. 자세한 내용은 문서 또는 기본 구성 파일 /etc/clickhouse/config.xml을 참고하십시오.
<clickhouse>
<listen_host>0.0.0.0</listen_host>
</clickhouse>
서버 시작하기
ClickHouse Keeper 실행
각 Keeper 서버에서 사용하는 운영 체제에 맞는 명령을 예를 들어 다음과 같이 실행합니다:
sudo systemctl enable clickhouse-keeper
sudo systemctl start clickhouse-keeper
sudo systemctl status clickhouse-keeper
ClickHouse Keeper 상태 확인
netcat을 사용하여 ClickHouse Keeper에 명령을 보냅니다. 예를 들어 mntr 명령은 ClickHouse Keeper 클러스터의 상태를 보여줍니다. 각 Keeper 노드에서 이 명령을 실행하면 하나의 노드는 리더이고 나머지 두 노드는 팔로워임을 확인할 수 있습니다.
echo mntr | nc localhost 9181
zk_version v22.7.2.15-stable-f843089624e8dd3ff7927b8a125cf3a7a769c069
zk_avg_latency 0
zk_max_latency 11
zk_min_latency 0
zk_packets_received 1783
zk_packets_sent 1783
# highlight-start
zk_num_alive_connections 2
zk_outstanding_requests 0
zk_server_state leader
# highlight-end
zk_znode_count 135
zk_watch_count 8
zk_ephemerals_count 3
zk_approximate_data_size 42533
zk_key_arena_size 28672
zk_latest_snapshot_size 0
zk_open_file_descriptor_count 182
zk_max_file_descriptor_count 18446744073709551615
# highlight-start
zk_followers 2
zk_synced_followers 2
# highlight-end
ClickHouse 서버 실행
각 ClickHouse 서버에서 다음 명령을 실행합니다
sudo service clickhouse-server start
ClickHouse 서버 확인
클러스터 구성을 추가할 때 두 개의 ClickHouse 노드에 걸쳐 복제되는 단일 세그먼트가 정의되었습니다. 이 검증 단계에서는 ClickHouse가 시작될 때 클러스터가 정상적으로 구성되었는지 확인하고, 해당 클러스터를 사용하여 복제된 테이블을 생성합니다.
-
클러스터가 존재하는지 확인:
┌─cluster───────┐
│ cluster_1S_2R │
└───────────────┘
1 row in set. Elapsed: 0.009 sec. `
-
ReplicatedMergeTree 테이블 엔진을 사용하여 클러스터에 테이블 생성:
create table trips on cluster 'cluster_1S_2R' (
`trip_id` UInt32,
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`tip_amount` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4))
ENGINE = ReplicatedMergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime
SETTINGS storage_policy='s3_main'
┌─host────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chnode1 │ 9000 │ 0 │ │ 1 │ 0 │
│ chnode2 │ 9000 │ 0 │ │ 0 │ 0 │
└─────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
-
앞에서 정의한 매크로의 사용 방식 이해
매크로 shard와 replica는 앞에서 정의되었으며, 아래의 강조된 줄에서 각 ClickHouse 노드에서 값이 어떻게 치환되는지 확인할 수 있습니다. 추가로 uuid 값도 사용되는데, uuid는 시스템에서 생성되므로 매크로 안에서는 정의되지 않습니다.
SELECT create_table_query
FROM system.tables
WHERE name = 'trips'
FORMAT Vertical
Query id: 4d326b66-0402-4c14-9c2f-212bedd282c0
Row 1:
──────
create_table_query: CREATE TABLE default.trips (`trip_id` UInt32, `pickup_date` Date, `pickup_datetime` DateTime, `dropoff_datetime` DateTime, `pickup_longitude` Float64, `pickup_latitude` Float64, `dropoff_longitude` Float64, `dropoff_latitude` Float64, `passenger_count` UInt8, `trip_distance` Float64, `tip_amount` Float32, `total_amount` Float32, `payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4))
# 다음 줄을 강조
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')
PARTITION BY toYYYYMM(pickup_date) ORDER BY pickup_datetime SETTINGS storage_policy = 's3_main'
1 row in set. Elapsed: 0.012 sec.
참고
위에 표시된 ZooKeeper 경로 'clickhouse/tables/{uuid}/{shard}는 default_replica_path와 default_replica_name을 설정하여 사용자 정의할 수 있습니다. 관련 문서는 여기에 있습니다.
테스트
다음 테스트는 데이터가 두 서버 간에 복제되고 있으며, 로컬 디스크가 아니라 S3 버킷에 저장되고 있음을 검증합니다.
-
New York City 택시 데이터셋에서 데이터를 추가합니다:
INSERT INTO trips
SELECT trip_id,
pickup_date,
pickup_datetime,
dropoff_datetime,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
passenger_count,
trip_distance,
tip_amount,
total_amount,
payment_type
FROM s3('https://ch-nyc-taxi.s3.eu-west-3.amazonaws.com/tsv/trips_{0..9}.tsv.gz', 'TabSeparatedWithNames') LIMIT 1000000;
-
데이터가 S3에 저장되어 있는지 확인합니다.
이 쿼리는 디스크 상의 데이터 크기와, 어떤 디스크가 사용되는지를 결정하는 스토리지 정책을 보여줍니다.
SELECT
engine,
data_paths,
metadata_path,
storage_policy,
formatReadableSize(total_bytes)
FROM system.tables
WHERE name = 'trips'
FORMAT Vertical
Query id: af7a3d1b-7730-49e0-9314-cc51c4cf053c
Row 1:
──────
engine: ReplicatedMergeTree
data_paths: ['/var/lib/clickhouse/disks/s3_disk/store/551/551a859d-ec2d-4512-9554-3a4e60782853/']
metadata_path: /var/lib/clickhouse/store/e18/e18d3538-4c43-43d9-b083-4d8e0f390cf7/trips.sql
storage_policy: s3_main
formatReadableSize(total_bytes): 36.42 MiB
1 row in set. Elapsed: 0.009 sec.
로컬 디스크에서 데이터 크기를 확인합니다. 위 결과에서, 저장된 수백만 개 행의 디스크 상 크기는 36.42 MiB입니다. 이는 로컬 디스크가 아니라 S3에 있어야 합니다. 위 쿼리는 또한 로컬 디스크에서 데이터와 메타데이터가 어디에 저장되어 있는지도 알려 줍니다. 로컬 데이터를 확인합니다:
root@chnode1:~# du -sh /var/lib/clickhouse/disks/s3_disk/store/551
536K /var/lib/clickhouse/disks/s3_disk/store/551
각 S3 버킷에 저장된 S3 데이터를 확인합니다. (합계는 표시되지 않지만, 두 버킷 모두 INSERT 이후 약 36 MiB가 저장되어 있습니다.)
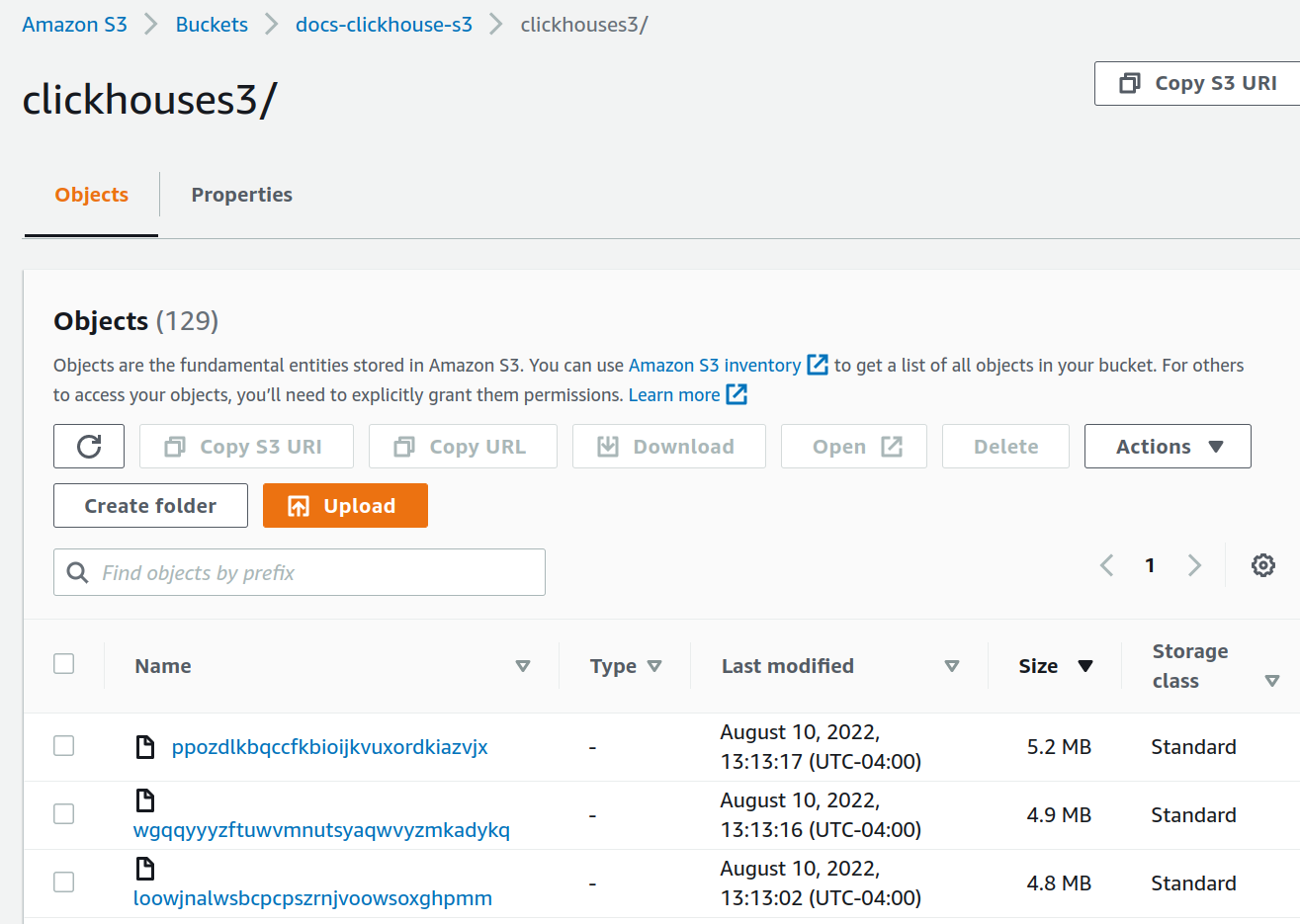
S3Express
S3Express는 Amazon S3에서 제공하는 새로운 고성능 단일 가용 영역(Availability Zone)용 스토리지 클래스입니다.
ClickHouse와 함께 S3Express를 테스트한 경험에 대해 읽어 보려면 이 블로그를 참고하십시오.
참고
S3Express는 단일 AZ 내에 데이터를 저장합니다. 이는 AZ 장애가 발생할 경우 데이터에 액세스할 수 없음을 의미합니다.
S3 디스크
S3Express 버킷을 스토리지로 사용하는 테이블을 생성하려면 다음 단계를 수행합니다:
Directory 유형의 버킷을 생성합니다.- S3 사용자에게 필요한 모든 권한을 부여할 수 있도록 적절한 버킷 정책을 적용합니다(예: 단순히 무제한 액세스를 허용하려면
"Action": "s3express:*").
- 스토리지 정책을 구성할 때
region 파라미터를 지정합니다.
스토리지 구성은 일반 S3와 동일하며, 예를 들어 다음과 같이 설정할 수 있습니다:
<storage_configuration>
<disks>
<s3_express>
<type>s3</type>
<endpoint>https://my-test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com/store/</endpoint>
<region>eu-north-1</region>
<access_key_id>...</access_key_id>
<secret_access_key>...</secret_access_key>
</s3_express>
</disks>
<policies>
<s3_express>
<volumes>
<main>
<disk>s3_express</disk>
</main>
</volumes>
</s3_express>
</policies>
</storage_configuration>
그다음 새 스토리지에 테이블을 생성합니다:
CREATE TABLE t
(
a UInt64,
s String
)
ENGINE = MergeTree
ORDER BY a
SETTINGS storage_policy = 's3_express';
S3 스토리지
S3 스토리지는 Object URL 경로에만 지원됩니다. 예시는 다음과 같습니다.
SELECT * FROM s3('https://test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com/file.csv', ...)
또한 구성에서 버킷 리전을 지정해야 합니다:
<s3>
<perf-bucket-url>
<endpoint>https://test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com</endpoint>
<region>eu-north-1</region>
</perf-bucket-url>
</s3>
위에서 생성한 디스크에 백업을 저장할 수 있습니다.
BACKUP TABLE t TO Disk('s3_express', 't.zip')
┌─id───────────────────────────────────┬─status─────────┐
│ c61f65ac-0d76-4390-8317-504a30ba7595 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
RESTORE TABLE t AS t_restored FROM Disk('s3_express', 't.zip')
┌─id───────────────────────────────────┬─status───┐
│ 4870e829-8d76-4171-ae59-cffaf58dea04 │ RESTORED │
└──────────────────────────────────────┴──────────┘