S3 Insert 및 Read 성능 최적화
이 섹션에서는 s3 table functions를 사용하여 S3에서 데이터를 읽고 삽입할 때의 성능을 최적화하는 방법에 중점을 둡니다.
이 가이드에서 설명하는 내용은 GCS 및 Azure Blob storage처럼 자체 전용 table function을 갖는 다른 객체 스토리지 구현에도 적용할 수 있습니다.
삽입 성능을 향상하기 위해 스레드 수와 블록 크기를 조정하기 전에 S3 삽입 동작 방식을 이해하는 것이 좋습니다. 이미 삽입 메커니즘에 익숙하거나 간단한 팁만 확인하려는 경우 아래 예제로 바로 이동하십시오.
Insert 메커니즘(단일 노드)
하드웨어 규모 외에도 ClickHouse의 데이터 insert 메커니즘(단일 노드)의 성능과 리소스 사용량에는 **insert 블록 크기(insert block size)**와 insert 병렬성(insert parallelism) 두 가지 주요 요인이 영향을 미칩니다.
Insert block size
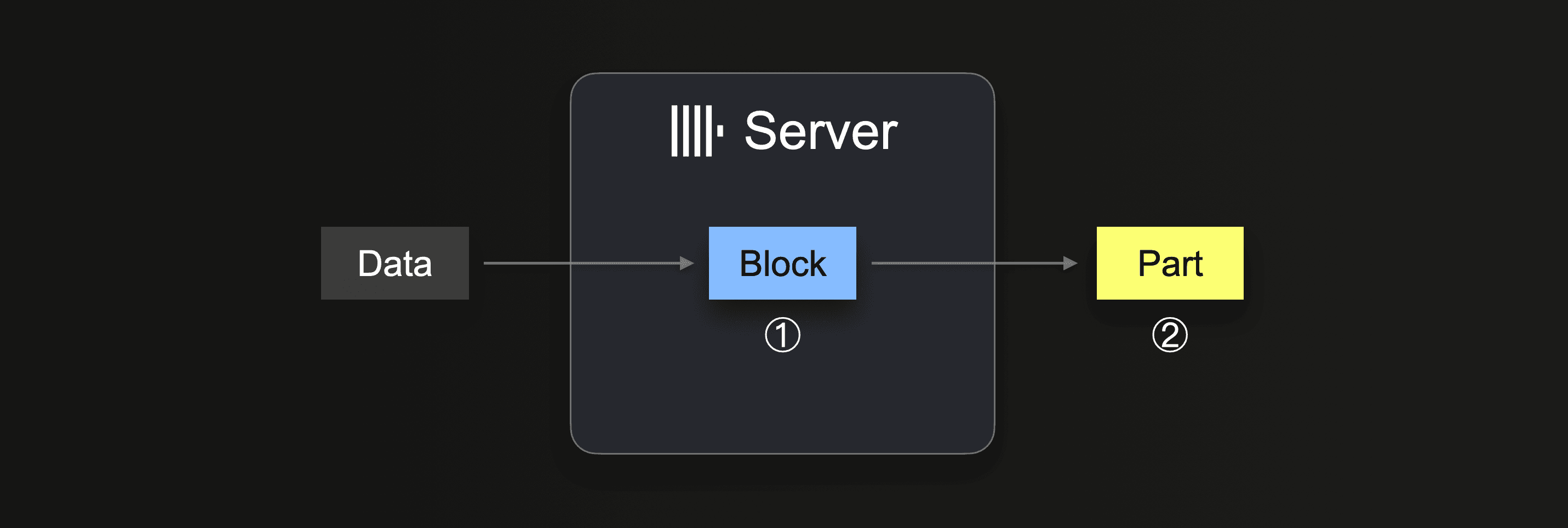
INSERT INTO SELECT를 수행하면, ClickHouse는 일부 데이터를 수신하고, 수신된 데이터로부터 ① (각 파티셔닝 키(partitioning key)마다) 최소 하나의 메모리 상의 insert 블록을 생성합니다. 블록의 데이터는 정렬되며, 테이블 엔진별 최적화가 적용됩니다. 이후 데이터는 압축되어 새로운 데이터 파트 형태로 ② 데이터베이스 스토리지에 기록됩니다.
insert 블록 크기는 ClickHouse 서버의 디스크 파일 I/O 사용량과 메모리 사용량 모두에 영향을 줍니다. 더 큰 insert 블록은 더 많은 메모리를 사용하지만 더 크고 수가 적은 초기 파트를 생성합니다. ClickHouse가 대량의 데이터를 로드하기 위해 생성해야 하는 파트 수가 적을수록, 필요한 디스크 파일 I/O와 자동 백그라운드 머지 작업량도 줄어듭니다.
통합 테이블 엔진 또는 테이블 함수와 함께 INSERT INTO SELECT 쿼리를 사용하는 경우, 데이터는 ClickHouse 서버에서 가져옵니다:
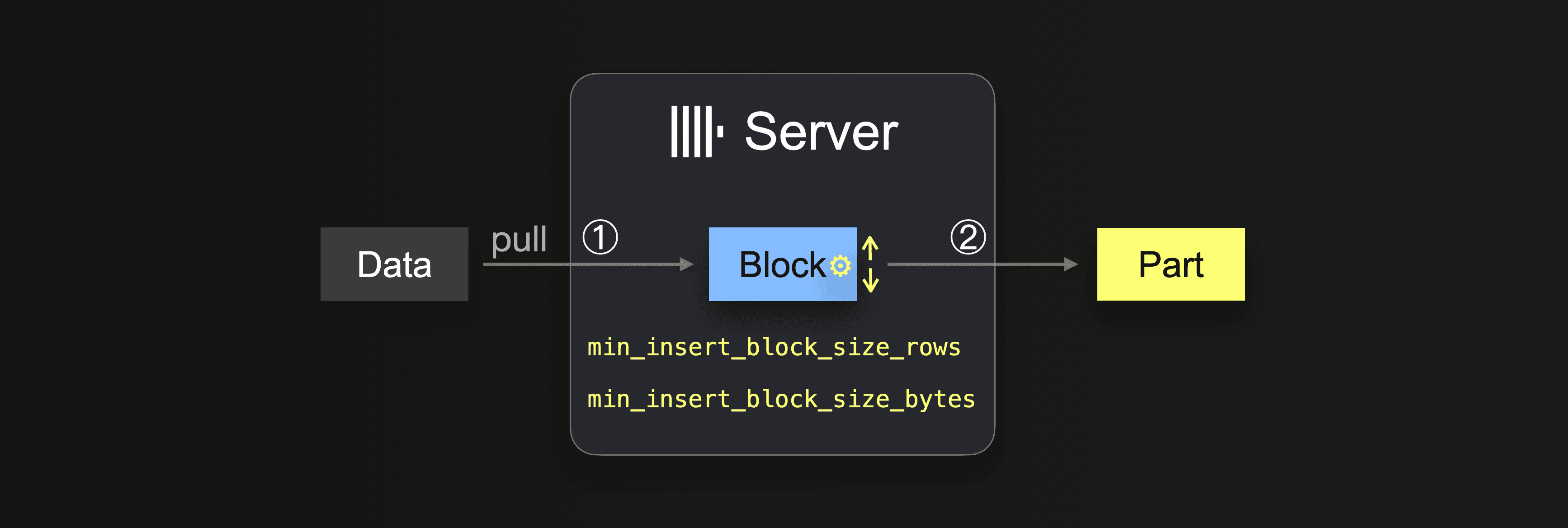
데이터가 완전히 로드될 때까지 서버는 다음과 같은 루프를 반복 실행합니다:
①에서 크기는 삽입 블록 크기에 따라 달라지며, 이는 두 가지 설정으로 제어할 수 있습니다:
min_insert_block_size_rows(기본값:1048545million 행)min_insert_block_size_bytes(기본값:256 MiB)
지정된 행 수가 삽입 블록에 모이거나 구성된 데이터 양에 도달하면(둘 중 먼저 충족되는 조건), 이 블록을 새로운 파트에 기록하는 작업이 트리거됩니다. 이후 삽입 루프는 ①단계로 돌아가 계속 진행됩니다.
min_insert_block_size_bytes 값은 압축되지 않은 메모리 상의 블록 크기를 의미하며(디스크에 저장되는 압축된 파트 크기가 아님), 또한 ClickHouse가 데이터를 행-블록 단위로 스트리밍하고 처리하기 때문에, 생성되는 블록과 파트가 구성된 행 수나 바이트 수와 정확히 일치하는 경우는 드뭅니다. 따라서 이러한 설정은 최소 임계값을 지정하는 역할을 합니다.
병합에 유의하십시오
설정된 INSERT 블록 크기가 작을수록 대용량 데이터 적재 시 초기 파트가 더 많이 생성되고, 데이터 수집과 동시에 백그라운드 파트 병합이 더 많이 실행됩니다. 이로 인해 리소스(CPU와 메모리) 경합이 발생할 수 있고, 수집이 끝난 이후 건전한 상태의 파트 개수(3000개)에 도달하는 데 추가 시간이 필요할 수 있습니다.
파트 개수가 권장 한도를 초과하면 ClickHouse 쿼리 성능이 저하됩니다.
ClickHouse는 파트들을 더 큰 파트로 계속 병합하여, 압축 크기가 약 150 GiB에 도달할 때까지 이를 반복합니다. 다음 다이어그램은 ClickHouse 서버가 파트를 병합하는 방식을 보여줍니다:
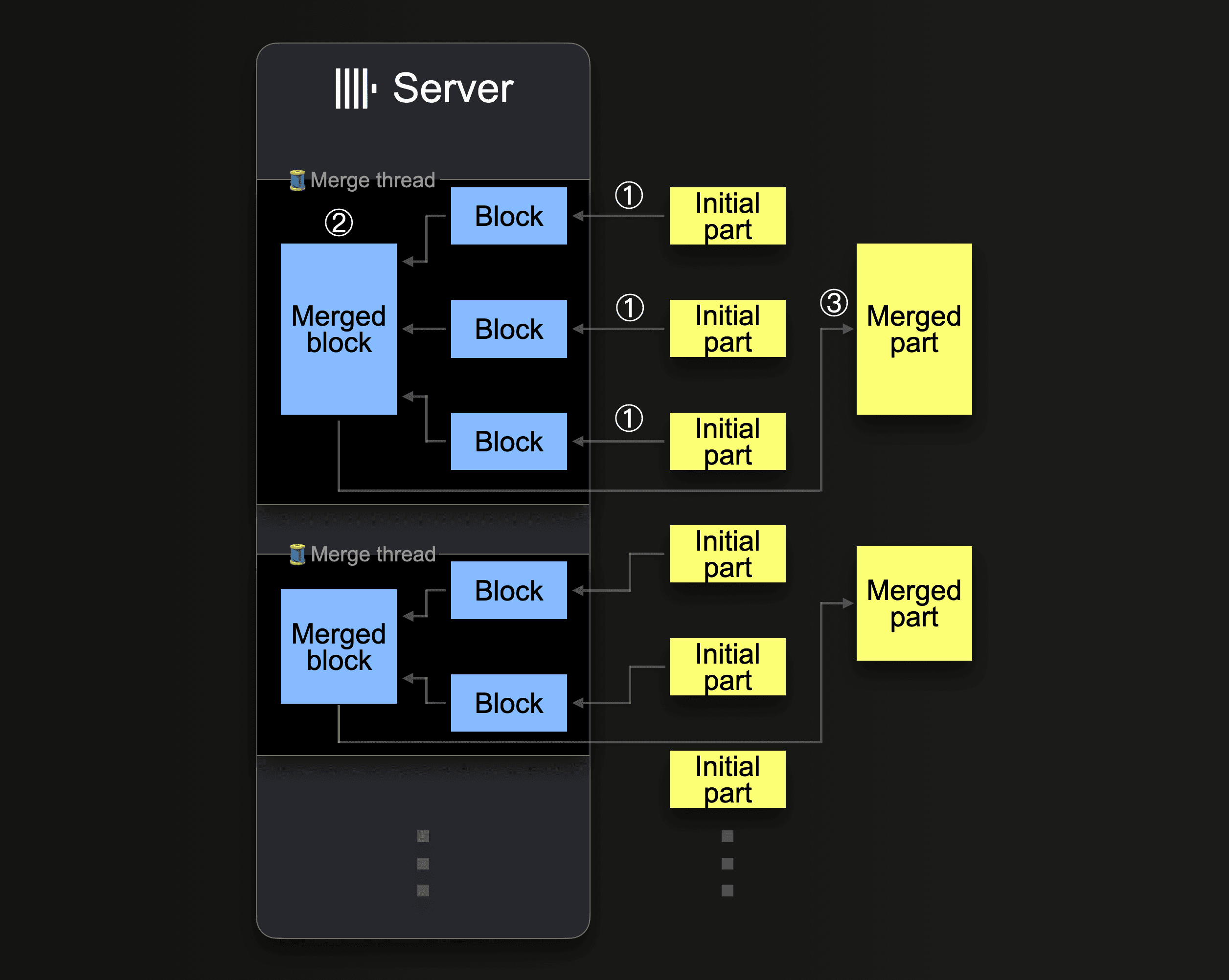
단일 ClickHouse 서버는 여러 백그라운드 병합 스레드를 활용하여 동시에 파트 병합을 실행합니다. 각 스레드는 다음과 같은 루프를 실행합니다:
CPU 코어 수와 RAM 크기를 늘리면 백그라운드 병합 처리량이 증가합니다.
더 큰 파트로 병합된 파트는 비활성 상태로 표시되며, 설정 가능한 분 수가 지난 후 최종적으로 삭제됩니다. 시간이 지나면서 이렇게 병합된 파트들로 이루어진 트리 구조가 생성되며, 이 때문에 MergeTree 테이블이라는 이름이 붙었습니다.
삽입 병렬성
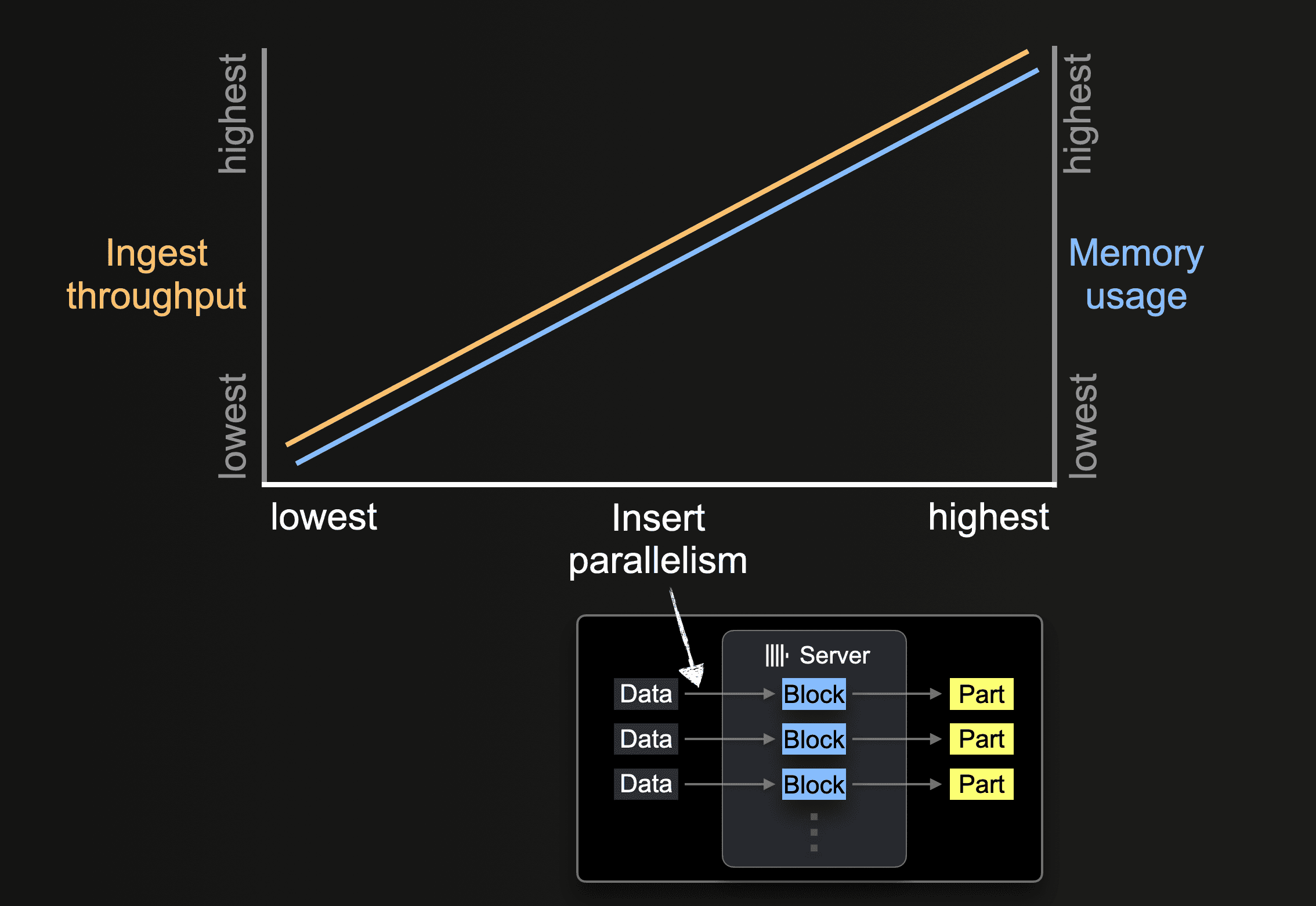
ClickHouse 서버는 데이터를 병렬로 처리하고 삽입할 수 있습니다. 삽입 병렬성 수준은 ClickHouse 서버의 수집 처리량과 메모리 사용량에 영향을 줍니다. 데이터를 병렬로 로드하고 처리하려면 더 많은 주 메모리가 필요하지만, 데이터가 더 빠르게 처리되므로 수집 처리량이 증가합니다.
S3와 같은 테이블 함수는 glob 패턴을 통해 로드할 파일 이름 집합을 지정할 수 있습니다. 하나의 glob 패턴이 여러 기존 파일과 일치하는 경우, ClickHouse는 이러한 파일들 간 및 파일 내부에서 읽기를 병렬화하고, 서버당 병렬로 실행되는 삽입 스레드를 활용하여 테이블에 데이터를 병렬로 삽입할 수 있습니다:
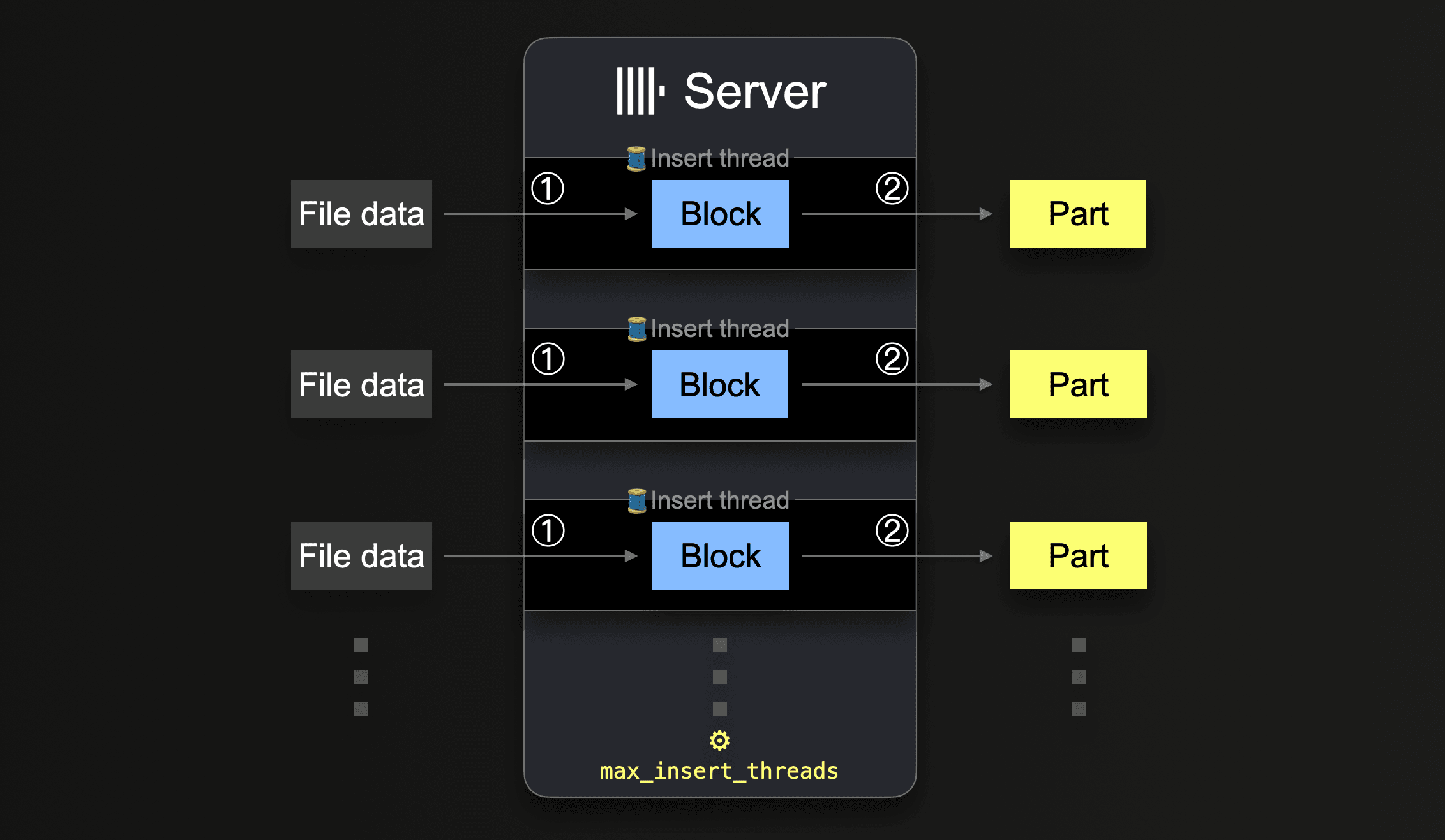
모든 파일의 모든 데이터가 처리될 때까지 각 삽입 스레드는 다음과 같은 루프를 실행합니다:
이러한 병렬 insert 스레드의 개수는 max_insert_threads 설정으로 구성할 수 있습니다. 기본값은 오픈 소스 ClickHouse에서는 1, ClickHouse Cloud에서는 4입니다.
파일 개수가 많은 경우 여러 insert 스레드를 통한 병렬 처리가 효과적으로 동작합니다. 사용 가능한 CPU 코어와 네트워크 대역폭(병렬 파일 다운로드)을 모두 충분히 활용할 수 있습니다. 반대로 소수의 대용량 파일만 테이블에 로드되는 시나리오에서는, ClickHouse가 자동으로 높은 수준의 데이터 처리 병렬성을 확보하고, 각 insert 스레드마다 추가 reader 스레드를 생성하여 대용량 파일 내의 서로 다른 범위를 병렬로 읽기(다운로드)함으로써 네트워크 대역폭 사용을 최적화합니다.
s3 함수와 테이블의 경우, 개별 파일의 병렬 다운로드 여부는 max_download_threads 및 max_download_buffer_size 값에 의해 결정됩니다. 파일 크기가 2 * max_download_buffer_size보다 클 때에만 병렬로 다운로드됩니다. 기본적으로 max_download_buffer_size는 10 MiB로 설정되어 있습니다. 어떤 경우에는 각 파일이 단일 스레드에 의해 다운로드되도록 하기 위해 이 버퍼 크기를 50 MB(max_download_buffer_size=52428800)까지 안전하게 늘릴 수 있습니다. 이렇게 하면 각 스레드가 S3 호출에 소요하는 시간을 줄이고, 그에 따라 S3 대기 시간도 감소시킬 수 있습니다. 또한 병렬 읽기에는 너무 작은 파일의 처리량을 높이기 위해, ClickHouse는 이러한 파일을 비동기적으로 미리 읽어(prefetch) 데이터를 자동으로 가져옵니다.
성능 측정
S3 table function을 사용하는 쿼리 성능 최적화는, 데이터가 S3에 원래 형식 그대로 남아 있고 ClickHouse 컴퓨트만 사용하는 애드혹 쿼리처럼 S3에 있는 데이터를 그대로 대상으로 쿼리를 실행하는 경우와, S3에서 ClickHouse MergeTree 테이블 엔진으로 데이터를 삽입하는 경우 모두에서 필요합니다. 별도로 명시되지 않는 한, 다음 권장 사항은 두 시나리오 모두에 적용됩니다.
하드웨어 규모의 영향
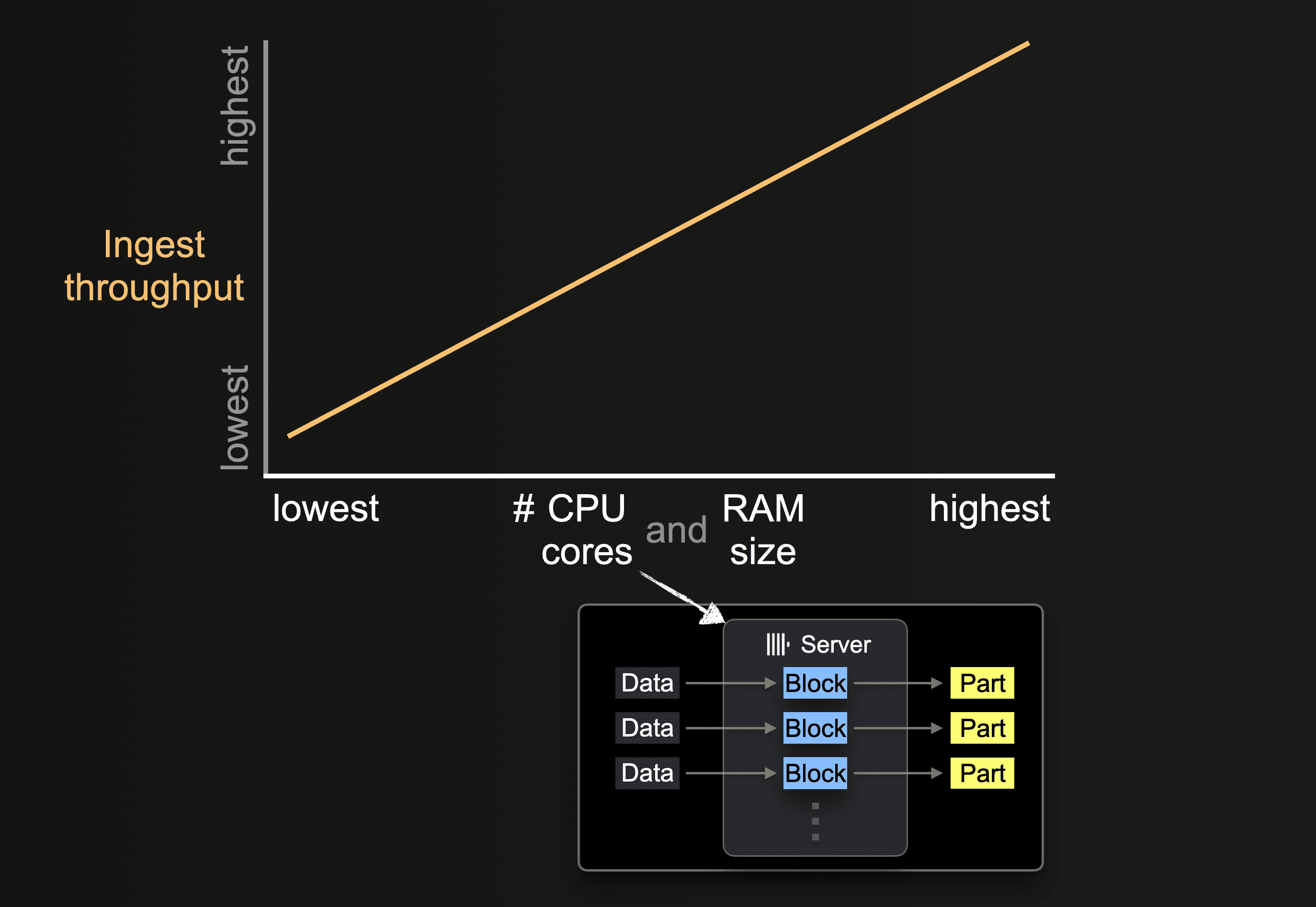
사용 가능한 CPU 코어 수와 RAM 크기는 다음에 영향을 미칩니다:
- 지원되는 초기 파트 크기
- 가능한 insert 병렬성 수준
- 백그라운드 파트 병합의 처리량
따라서 전체 수집 처리량에도 영향을 미칩니다.
리전 로컬리티
버킷이 ClickHouse 인스턴스와 동일한 리전에 위치하도록 구성해야 합니다. 이와 같은 간단한 최적화만으로도 처리량을 크게 향상시킬 수 있으며, 특히 ClickHouse 인스턴스를 AWS 인프라에 배포하는 경우에 효과적입니다.
Formats
ClickHouse는 s3 함수와 S3 엔진을 사용하여 S3 버킷에 저장된 파일을 지원되는 포맷으로 읽을 수 있습니다. 원시 파일을 읽는 경우, 일부 포맷은 다음과 같은 뚜렷한 장점이 있습니다:
- Native, Parquet, CSVWithNames, TabSeparatedWithNames처럼 컬럼 이름이 인코딩된 포맷은
s3함수에서 컬럼 이름을 명시할 필요가 없으므로 쿼리가 더 간결해집니다. 컬럼 이름을 통해 이 정보를 추론할 수 있습니다. - 포맷마다 읽기 및 쓰기 처리량 측면에서 성능이 다릅니다. Native와 Parquet은 이미 컬럼 지향이고 더 컴팩트하게 저장되므로 읽기 성능 측면에서 가장 최적의 포맷입니다. Native 포맷은 추가로 ClickHouse가 메모리에 데이터를 저장하는 방식과 일치하여, 데이터가 ClickHouse로 스트리밍될 때 처리 오버헤드를 줄여 줍니다.
- 블록 크기는 대용량 파일의 읽기 지연 시간에 자주 영향을 미칩니다. 이는 상위 N개의 행만 반환하는 등 데이터를 샘플링하는 경우 특히 두드러집니다. CSV와 TSV 같은 포맷의 경우, 행 집합을 반환하려면 파일 전체를 파싱해야 합니다. Native와 Parquet 같은 포맷은 이러한 이유로 더 빠른 샘플링을 가능하게 합니다.
- 각 압축 포맷은 장단점이 있으며, 일반적으로 압축률과 속도, 그리고 압축 또는 압축 해제 성능 간의 균형을 맞춥니다. CSV나 TSV 같은 원시 파일을 압축하는 경우, lz4는 압축률을 일부 희생하는 대신 가장 빠른 압축 해제 속도를 제공합니다. Gzip은 일반적으로 읽기 속도가 약간 느려지는 대신 더 나은 압축률을 제공합니다. Xz는 이를 한 단계 더 나아가, 보통 가장 좋은 압축률을 제공하지만 가장 느린 압축 및 압축 해제 속도를 보입니다. 내보내기 시에는 Gz와 lz4가 유사한 수준의 압축 속도를 제공합니다. 이는 네트워크 연결 속도와 함께 균형을 맞추어야 합니다. 더 빠른 압축 해제 또는 압축에서 얻는 이점은 S3 버킷으로의 네트워크 연결이 느리면 쉽게 상쇄됩니다.
- Native나 Parquet 같은 포맷은 일반적으로 추가적인 압축 오버헤드를 감수할 만큼의 이점을 제공하지 않습니다. 이러한 포맷은 본질적으로 컴팩트하기 때문에 데이터 크기 절감 효과는 미미한 경우가 많습니다. 특히 S3는 전역적으로 높은 네트워크 대역폭을 제공하므로, 압축 및 압축 해제에 소요되는 시간이 네트워크 전송 시간을 상쇄하는 일은 거의 없습니다.
예제 데이터셋
추가적인 잠재적 최적화와 활용 사례를 설명하기 위해, Stack Overflow 데이터셋의 posts를 사용하여 이 데이터의 쿼리 및 삽입 성능을 모두 최적화하는 방법을 살펴봅니다.
이 데이터셋은 2008년 7월부터 2024년 3월까지 매월 하나씩, 총 189개의 Parquet 파일로 구성되어 있습니다.
위 권장 사항에 따라 성능을 위해 Parquet를 사용하며, 모든 쿼리는 버킷과 동일한 리전에 위치한 ClickHouse Cluster에서 실행합니다. 이 클러스터는 32GiB RAM과 8 vCPU를 가진 노드 3개로 구성됩니다.
튜닝을 전혀 적용하지 않은 상태에서, 이 데이터셋을 MergeTree 테이블 엔진에 삽입하는 성능과 가장 많은 질문을 한 사용자를 계산하는 쿼리 성능을 보여줍니다. 이 두 쿼리는 모두 데이터 전체 스캔이 필요하도록 의도적으로 구성되어 있습니다.
이 예제에서는 몇 개의 행만 반환합니다. 클라이언트로 대량의 데이터를 반환하는 SELECT 쿼리의 성능을 측정할 때에는, 쿼리에서 null format을 사용하거나 결과를 Null engine으로 직접 보내십시오. 이렇게 하면 클라이언트가 과도한 데이터로 인해 과부하되거나 네트워크가 포화 상태가 되는 상황을 피할 수 있습니다.
쿼리에서 데이터를 읽을 때, 동일한 쿼리를 반복 실행하는 경우와 비교하여 초기 쿼리가 더 느리게 보이는 경우가 자주 있습니다. 이는 S3 자체의 캐싱과 ClickHouse Schema Inference Cache 때문일 수 있습니다. 이 캐시는 파일에 대해 추론된 스키마를 저장하며, 이후 접근 시 스키마 추론 단계를 건너뛸 수 있어 쿼리 시간이 단축됩니다.
읽기를 위한 스레드 사용
S3에서의 읽기 성능은 네트워크 대역폭이나 로컬 I/O에 의해 제한되지 않는다면 코어 수에 비례하여 선형적으로 확장됩니다. 스레드 수를 늘리면 메모리 오버헤드가 증가하므로 이를 인지해야 합니다. 다음 항목을 조정하여 읽기 처리량을 향상시킬 수 있습니다.
- 일반적으로
max_threads의 기본값(코어 수)은 충분합니다. 특정 쿼리가 사용하는 메모리 양이 많아 이를 줄여야 하거나, 결과에 대한LIMIT값이 작은 경우 이 값을 더 낮게 설정할 수 있습니다. 메모리가 넉넉한 사용자는 S3에서 더 높은 읽기 처리량을 얻기 위해 이 값을 증가시키는 실험을 해 볼 수 있습니다. 일반적으로 이는 코어 수가 적은 머신(예: 10 미만)에서만 유의미합니다. 추가적인 병렬화의 이점은 다른 리소스(예: 네트워크, CPU 경합)가 병목으로 작용하면서 점차 줄어듭니다. - ClickHouse 22.3.1 이전 버전에서는
s3함수 또는S3테이블 엔진을 사용할 때 여러 파일에 걸친 읽기만 병렬화했습니다. 이로 인해 사용자는 최적의 읽기 성능을 얻기 위해 S3에 업로드할 때 파일을 청크로 분할하고, glob 패턴을 사용해 읽도록 구성해야 했습니다. 이후 버전에서는 이제 단일 파일 내에서도 다운로드가 병렬화됩니다. - 스레드 수가 적은 경우,
remote_filesystem_read_method를 "read"로 설정하여 S3에서 파일을 동기적으로 읽도록 하면 도움이 될 수 있습니다. s3함수 및 테이블에서 개별 파일의 병렬 다운로드 여부는max_download_threads와max_download_buffer_size값에 의해 결정됩니다.max_download_threads는 사용되는 스레드 수를 제어하지만, 파일 크기가 2 *max_download_buffer_size보다 큰 경우에만 병렬로 다운로드됩니다. 기본적으로max_download_buffer_size는 10MiB로 설정됩니다. 일부 경우에는 이 버퍼 크기를 50 MB (max_download_buffer_size=52428800)까지 안전하게 늘려 더 작은 파일은 단일 스레드만 다운로드하도록 할 수 있습니다. 이렇게 하면 각 스레드가 S3 호출에 소요하는 시간을 줄이고 S3 대기 시간도 낮출 수 있습니다. 예시는 이 블로그 게시물을 참고하십시오.
성능을 개선하기 위한 변경을 수행하기 전에 반드시 적절한 측정을 수행해야 합니다. S3 API 호출은 지연 시간에 민감하며 클라이언트 타이밍에 영향을 줄 수 있으므로, 성능 메트릭에는 system.query_log와 같은 쿼리 로그를 사용하십시오.
이전에 사용한 쿼리를 다시 고려해 보면, max_threads를 16으로 두 배로 늘리면(기본값인 max_thread는 노드의 코어 수) 더 많은 메모리를 사용하는 대가로 읽기 쿼리 성능이 2배 향상됩니다. max_threads를 더 증가시키면, 아래에 나타난 것처럼 효과가 점점 감소합니다.
INSERT를 위한 스레드 및 블록 크기 튜닝
최대 수집 성능을 달성하려면 (1) INSERT 블록 크기와 (2) INSERT 병렬 수준을 (3) 사용 가능한 CPU 코어 수와 RAM 용량에 따라 선택해야 합니다. 요약하면 다음과 같습니다.
- INSERT 블록 크기를 크게 설정할수록 ClickHouse가 생성해야 하는 파트 수가 줄어들고, 필요한 디스크 파일 I/O와 백그라운드 머지도 줄어듭니다.
- 병렬 INSERT 스레드 수를 높게 설정할수록 데이터가 더 빠르게 처리됩니다.
이 두 성능 요소 사이에는 (백그라운드 파트 머지와의 트레이드오프를 포함하여) 상충 관계가 있습니다. ClickHouse 서버에서 사용 가능한 메인 메모리 용량에는 한계가 있습니다. 블록이 클수록 더 많은 메인 메모리를 사용하므로 사용할 수 있는 병렬 INSERT 스레드 수가 제한됩니다. 반대로 병렬 INSERT 스레드 수가 많을수록, 메모리 내에서 동시에 생성되는 INSERT 블록 수가 증가하기 때문에 더 많은 메인 메모리가 필요합니다. 이는 가능한 INSERT 블록 크기를 제한합니다. 추가로, INSERT 스레드와 백그라운드 머지 스레드 간에 리소스 경합이 발생할 수 있습니다. 많은 수의 INSERT 스레드를 설정하면 (1) 머지해야 하는 파트가 더 많이 생성되고 (2) 백그라운드 머지 스레드가 사용할 수 있는 CPU 코어와 메모리 공간을 차지하게 됩니다.
이러한 파라미터의 동작이 성능과 리소스에 어떤 영향을 미치는지에 대한 자세한 설명은 이 블로그 글을 읽어 보기를 권장합니다. 해당 블로그에서 설명했듯이, 튜닝에는 이 두 파라미터 간의 신중한 균형 조정이 필요할 수 있습니다. 이와 같은 포괄적인 테스트는 실무에서 비현실적인 경우가 많으므로, 요약하면 다음과 같이 권장합니다.
이 공식을 사용하면 min_insert_block_size_rows를 0으로 설정하여 행 기반 임계값을 비활성화하고, max_insert_threads는 선택한 값으로, min_insert_block_size_bytes는 위 공식에서 계산한 결과 값으로 설정할 수 있습니다.
이 공식을 앞에서 사용한 Stack Overflow 예시에 적용해 보겠습니다.
max_insert_threads=4(노드당 8개 코어)peak_memory_usage_in_bytes- 32 GiB(노드 리소스의 100%) 또는34359738368바이트min_insert_block_size_bytes=34359738368/(3*4) = 2863311530
위에서 보듯이 이러한 설정을 조정하면 INSERT 성능이 33% 이상 향상됩니다. 단일 노드에서의 성능을 더 개선할 수 있는지는 독자에게 맡기겠습니다.
리소스와 노드를 통한 스케일링
리소스와 노드를 통한 스케일링은 읽기 쿼리와 삽입 쿼리 모두에 적용됩니다.
수직 확장(Vertical scaling)
앞서 수행한 모든 튜닝 작업과 쿼리는 ClickHouse Cloud 클러스터의 단일 노드만 사용했습니다. 일반적으로는 둘 이상의 ClickHouse 노드를 사용하게 됩니다. 초기에는 수직 확장을 통해 코어 수에 비례하여 S3 처리량이 선형적으로 증가하도록 하는 방식을 권장합니다. 이전에 수행한 insert 및 read 쿼리를, 리소스를 2배(64GiB, 16 vCPU)로 확장한 더 큰 ClickHouse Cloud 노드에서 적절한 설정과 함께 다시 실행하면, 두 쿼리 모두 수행 속도가 대략 2배 빨라집니다.
개별 노드는 네트워크 및 S3 GET 요청으로 인해 병목이 발생할 수도 있어, 수직으로 자원을 확장하더라도 성능이 선형적으로 증가하지 않을 수 있습니다.
수평 확장
시간이 지나면 하드웨어 가용성과 비용 효율성 때문에 수평 확장이 필요한 경우가 많습니다. ClickHouse Cloud에서 프로덕션 클러스터는 보통 최소 3개의 노드로 구성됩니다. 따라서 insert 시 모든 노드를 활용하고자 할 수 있습니다.
클러스터를 사용하여 S3 읽기를 수행하려면 클러스터 활용에 설명된 대로 s3Cluster 함수를 사용해야 합니다. 이를 통해 읽기가 노드 전체에 분산됩니다.
처음으로 insert 쿼리를 수신한 서버는 먼저 glob 패턴을 해석한 다음, 일치하는 각 파일의 처리를 동적으로 자신과 다른 서버에 분배합니다.
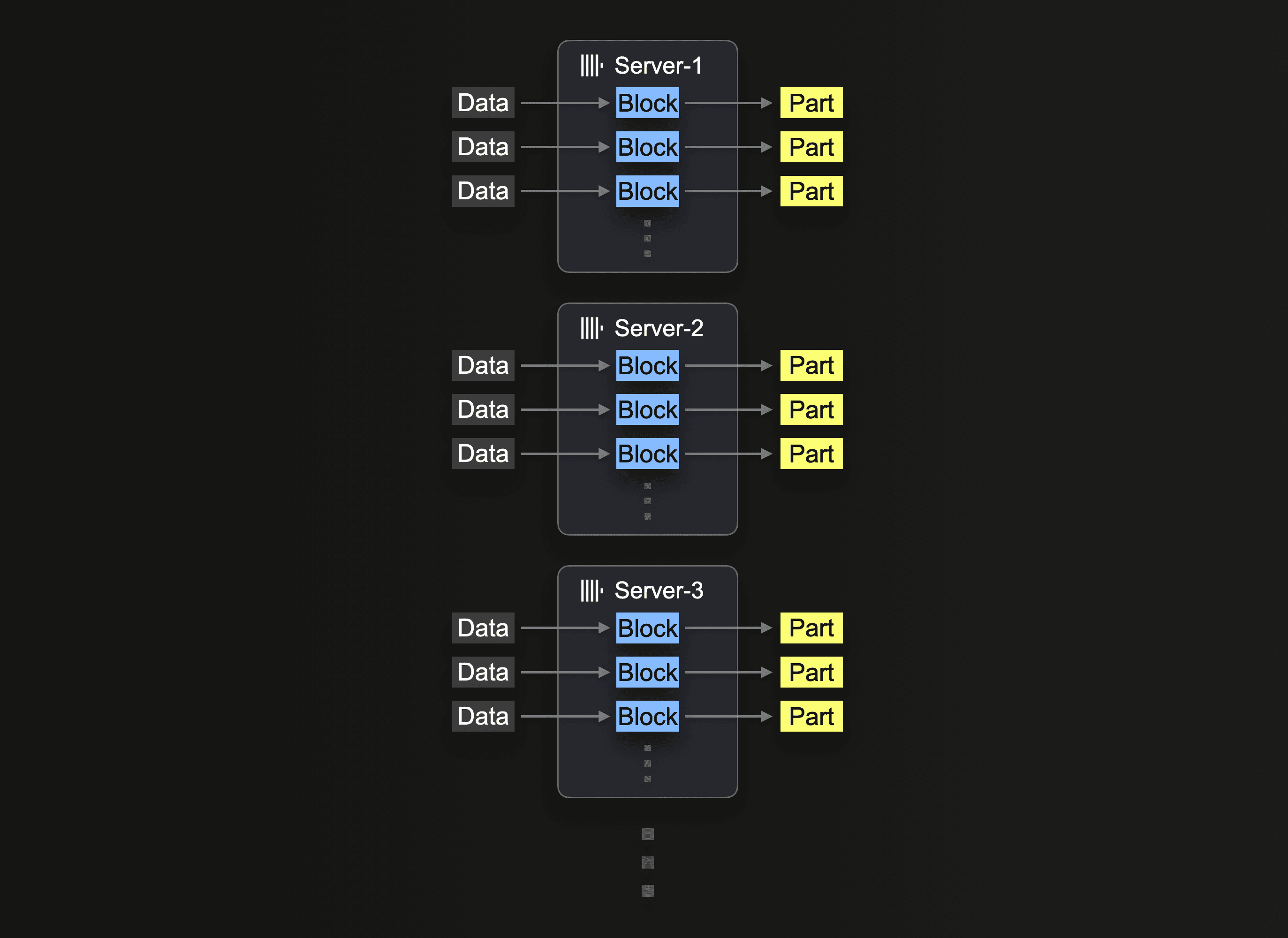
이전에 사용한 읽기 쿼리를, 작업 부하가 3개의 노드에 분산되도록 s3Cluster를 사용하도록 수정하여 다시 실행합니다. ClickHouse Cloud에서는 default 클러스터를 참조함으로써 이 작업이 자동으로 수행됩니다.
클러스터 활용에 언급된 것처럼 이 작업은 파일 단위로 분산됩니다. 이 기능의 이점을 얻으려면 충분한 수의 파일, 즉 노드 수보다 많은 파일이 필요합니다.
마찬가지로 insert 쿼리도 앞에서 단일 노드에 대해 확인한 향상된 설정을 사용하여 분산 실행할 수 있습니다:
독자는 파일 읽기 방식이 쿼리 성능은 개선했지만 insert 성능은 개선하지 못했음을 확인할 수 있습니다. 기본적으로 s3Cluster를 사용하여 읽기는 분산되지만, insert는 요청을 시작한 노드에서 수행됩니다. 이는 읽기는 각 노드에서 수행되지만, 그 결과 행은 분배를 위해 시작 노드로 라우팅된다는 의미입니다. 처리량이 높은 시나리오에서는 이것이 병목이 될 수 있습니다. 이를 해결하기 위해 s3cluster 함수에 대해 parallel_distributed_insert_select 매개변수를 설정합니다.
이를 parallel_distributed_insert_select=2로 설정하면, 각 노드의 Distributed 엔진이 사용하는 기본 테이블로부터/기본 테이블로 SELECT와 INSERT가 각 세그먼트에서 실행되도록 보장합니다.
예상대로 삽입 성능이 3배 감소합니다.
추가 설정
중복 제거 비활성화
INSERT 작업은 때때로 타임아웃과 같은 오류로 인해 실패할 수 있습니다. INSERT가 실패할 경우 데이터가 실제로 성공적으로 삽입되었는지는 확실하지 않을 수 있습니다. 클라이언트에서 INSERT를 안전하게 재시도할 수 있도록, 기본적으로 ClickHouse Cloud와 같은 분산 배포 환경에서는 ClickHouse가 해당 데이터가 이미 성공적으로 삽입되었는지 여부를 확인하려고 시도합니다. 삽입된 데이터가 중복으로 표시되면 ClickHouse는 대상 테이블에 이를 다시 삽입하지 않습니다. 그러나 사용자는 데이터가 정상적으로 삽입된 것과 동일하게 작업이 성공했다는 상태를 받게 됩니다.
이러한 동작은 INSERT 오버헤드가 발생하더라도 클라이언트에서 데이터를 로드하거나 배치로 로드할 때는 유효하지만, 객체 스토리지에서 INSERT INTO SELECT를 수행하는 경우에는 불필요할 수 있습니다. INSERT 시점에 이 기능을 비활성화하면 아래와 같이 성능을 향상할 수 있습니다.
삽입 시 최적화
ClickHouse에서 optimize_on_insert 설정은 삽입 과정에서 데이터 파트를 병합할지 여부를 제어합니다. 이 설정을 활성화하면(기본값 optimize_on_insert = 1) 작은 파트들이 삽입 시 더 큰 파트로 병합되어, 읽어야 하는 파트 수를 줄임으로써 쿼리 성능이 향상됩니다. 그러나 이러한 병합 작업은 삽입 과정에 오버헤드를 추가하여, 고처리량 삽입 작업의 속도를 느리게 만들 수 있습니다.
이 설정을 비활성화하면(optimize_on_insert = 0) 삽입 중 병합을 건너뛰기 때문에, 특히 잦은 소량 삽입을 처리할 때 데이터를 더 빠르게 기록할 수 있습니다. 병합 작업은 백그라운드로 연기되며, 삽입 성능은 향상되지만 작은 파트 수가 일시적으로 증가하여 백그라운드 병합이 완료될 때까지 쿼리가 느려질 수 있습니다. 이 설정은 삽입 성능이 우선이며, 백그라운드 병합 프로세스가 이후에 효율적으로 최적화를 처리할 수 있을 때 적합합니다. 아래에서 보듯이, 이 설정을 비활성화하면 삽입 처리량이 향상될 수 있습니다:
기타 참고 사항
- 메모리가 부족한 상황에서는 S3에 데이터를 삽입할 때
max_insert_delayed_streams_for_parallel_write값을 낮추는 것을 고려하십시오.
