ClickHouse란 무엇입니까?
ClickHouse®는 온라인 분석 처리(OLAP)를 위한 고성능 컬럼 지향 SQL 데이터베이스 관리 시스템(DBMS)입니다. 오픈 소스 소프트웨어와 Cloud 서비스로 모두 제공됩니다.
애널리틱스(Analytics)란 무엇입니까?
애널리틱스는 OLAP(Online Analytical Processing)라고도 하며, 방대한 데이터셋에 대해 집계, 문자열 처리, 산술 연산과 같은 복잡한 계산을 수행하는 SQL 쿼리를 의미합니다.
하나의 쿼리에서 소수의 행만 읽고 쓰며 밀리초 단위로 완료되는 트랜잭션 쿼리(또는 OLTP, Online Transaction Processing)와 달리, 애널리틱스 쿼리는 통상적으로 수십억에서 수조 개의 행을 처리합니다.
많은 사용 사례에서는 애널리틱스 쿼리가 「실시간(real-time)」이어야 합니다. 즉, 1초 미만의 시간 안에 결과를 반환해야 합니다.
행 지향 vs. 컬럼 지향 스토리지
이러한 수준의 성능은 데이터의 올바른 「지향 방식」을 선택했을 때만 달성할 수 있습니다.
데이터베이스는 데이터를 행 지향 또는 컬럼 지향 방식으로 저장합니다.
행 지향 데이터베이스에서는 테이블의 연속된 행이 순차적으로 차례대로 저장됩니다. 이 구조에서는 각 행의 컬럼 값이 함께 저장되므로 행을 빠르게 조회할 수 있습니다.
ClickHouse는 컬럼 지향 데이터베이스입니다. 이러한 시스템에서 테이블은 컬럼들의 집합으로 저장되며, 즉 각 컬럼의 값이 차례대로 연속해서 저장됩니다. 이 구조는 단일 행을 다시 재구성하는 작업을 더 어렵게 만들지만(이제 행 값들 사이에 간격이 생기기 때문입니다) 필터링이나 집계와 같은 컬럼 연산은 행 지향 데이터베이스보다 훨씬 더 빠르게 수행됩니다.
이 차이는 실제 익명 웹 분석 데이터 1억 행을 대상으로 실행되는 예제 쿼리로 가장 잘 설명할 수 있습니다.
ClickHouse SQL Playground에서 이 쿼리를 실행하면, 존재하는 100개가 넘는 컬럼 중 극히 일부만 선택 및 필터링하여 밀리초 단위로 결과를 반환하는 예제를 확인할 수 있습니다:
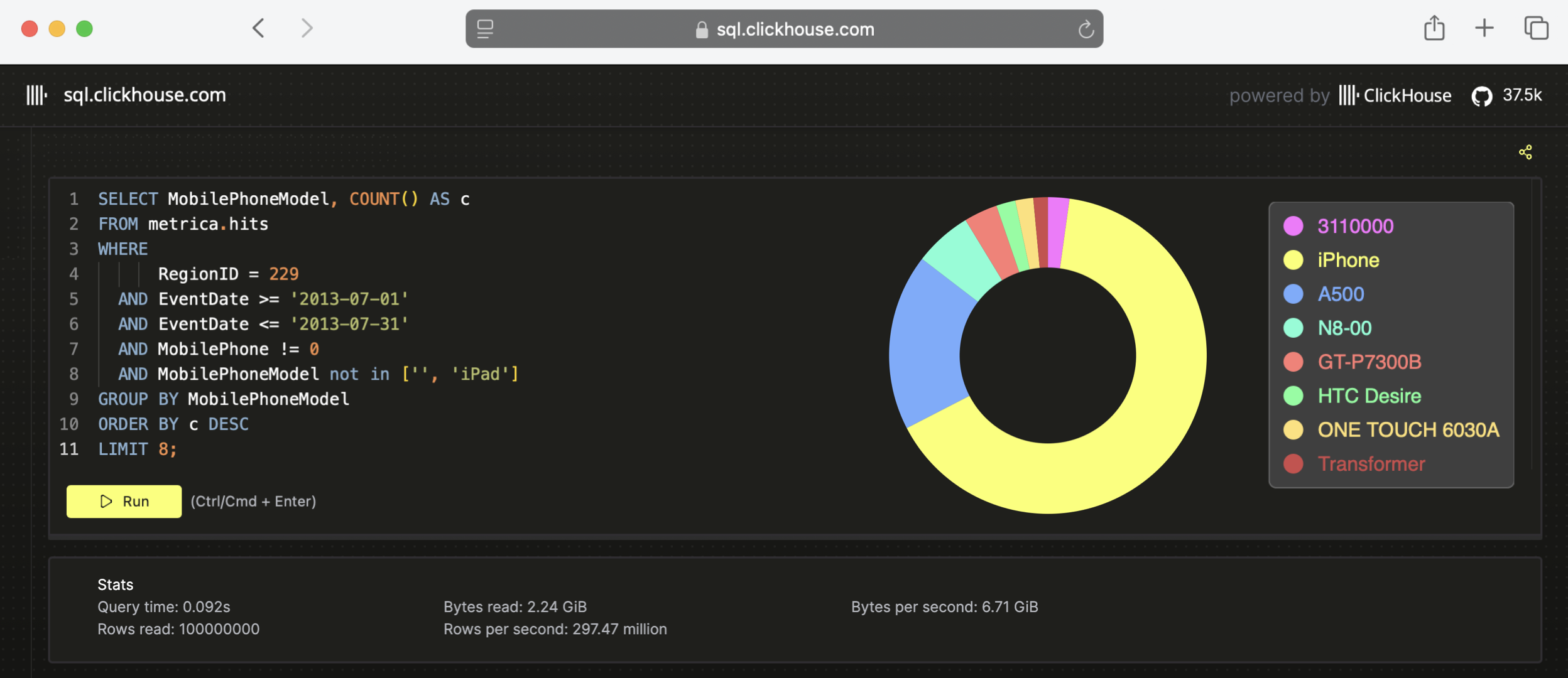
위 다이어그램의 통계 섹션에서 볼 수 있듯이, 이 쿼리는 1억 행을 92밀리초 만에 처리했으며, 이는 초당 약 10억 행 이상, 또는 초당 거의 7GB에 가까운 데이터를 전송한 처리량에 해당합니다.
행 지향 DBMS
행 지향 데이터베이스에서는, 위 쿼리가 기존 컬럼들 중 일부만 처리하더라도, 시스템은 여전히 디스크에서 메모리로 로드하기 위해 다른 기존 컬럼의 데이터도 읽어야 합니다. 그 이유는 데이터가 디스크에 블록이라고 불리는 청크(일반적으로 4KB 또는 8KB 같은 고정 크기) 단위로 저장되기 때문입니다. 블록은 디스크에서 메모리로 읽는 데이터의 최소 단위입니다. 애플리케이션이나 데이터베이스가 데이터를 요청하면, 운영 체제의 디스크 I/O 하위 시스템이 디스크에서 필요한 블록을 읽습니다. 블록의 일부만 필요하더라도, 전체 블록이 메모리로 읽힙니다(이는 디스크 및 파일 시스템 설계 방식에 따른 동작입니다):
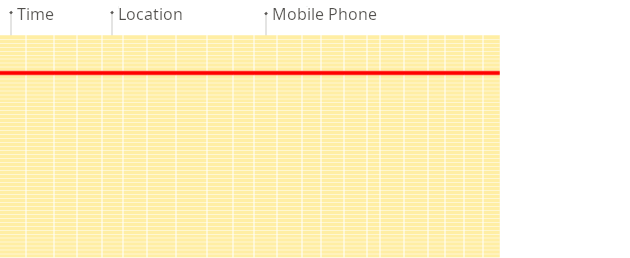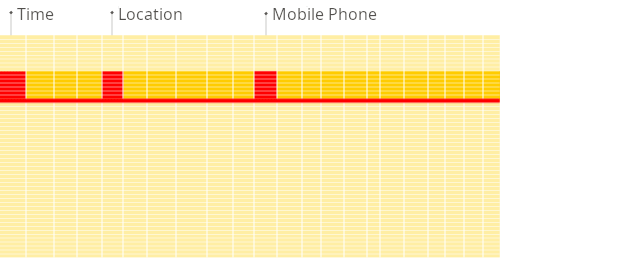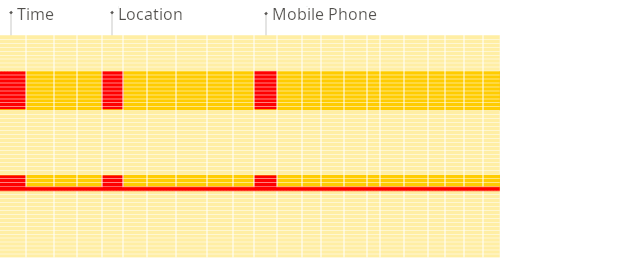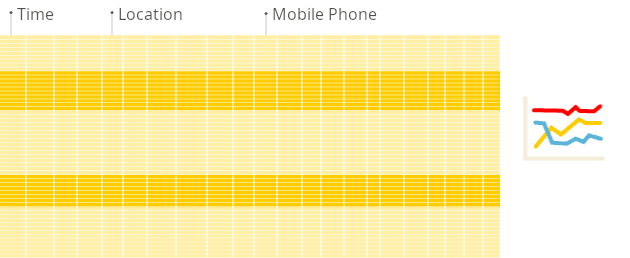
컬럼 지향 DBMS
각 컬럼의 값이 디스크에 서로 연속적으로 저장되므로, 위의 쿼리가 실행될 때 불필요한 데이터는 로드되지 않습니다. 블록 단위 저장 및 디스크에서 메모리로의 전송 방식이 분석용 쿼리의 데이터 접근 패턴과 잘 맞기 때문에, 쿼리에 필요한 컬럼만 디스크에서 읽어 사용되지 않는 데이터에 대한 불필요한 I/O를 피할 수 있습니다. 이는 전체 행(관련 없는 컬럼까지 포함)을 읽는 행 기반 스토리지와 비교했을 때 훨씬 빠릅니다:
데이터 복제와 무결성
ClickHouse는 비동기 멀티 마스터 복제 방식을 사용하여 데이터가 여러 노드에 중복 저장되도록 합니다. 사용 가능한 레플리카 중 어느 하나에 데이터가 기록되면, 나머지 레플리카는 백그라운드에서 해당 사본을 가져옵니다. 시스템은 서로 다른 레플리카 간에 동일한 데이터를 유지합니다. 대부분의 장애에 대해서는 복구가 자동으로 수행되며, 더 복잡한 경우에는 반자동으로 수행됩니다.
역할 기반 접근 제어(Role-Based Access Control)
ClickHouse는 SQL 쿼리를 통해 사용자 계정을 관리하며, ANSI SQL 표준과 널리 사용되는 관계형 데이터베이스 관리 시스템에서 제공하는 것과 유사한 역할 기반 접근 제어 구성을 제공합니다.
SQL 지원
ClickHouse는 대부분의 경우 ANSI SQL 표준과 동일한 SQL 기반 선언형 쿼리 언어를 지원합니다. 지원되는 쿼리 절에는 GROUP BY, ORDER BY, FROM 내 서브쿼리, JOIN 절, IN 연산자, 윈도우 함수, 스칼라 서브쿼리가 포함됩니다.
근사 계산
ClickHouse는 정확성을 성능과 맞바꾸는 여러 방법을 제공합니다. 예를 들어, 일부 집계 함수는 서로 다른 값의 개수, 중앙값(median), 분위수(quantiles)를 근사값으로 계산합니다. 또한, 데이터 샘플에 대해서만 쿼리를 실행하여 근사 결과를 빠르게 계산할 수 있습니다. 마지막으로, 모든 키에 대해 집계를 수행하는 대신, 제한된 수의 키에 대해서만 집계를 수행할 수 있습니다. 키 분포의 편중 정도에 따라, 이는 정확한 계산보다 훨씬 적은 자원을 사용하면서도 충분히 정확한 결과를 제공할 수 있습니다.
적응형 조인 알고리즘
ClickHouse는 상황에 따라 조인 알고리즘을 선택합니다. 먼저 빠른 해시 조인을 사용하고, 큰 테이블이 둘 이상인 경우 머지 조인으로 대체합니다.
뛰어난 쿼리 성능
ClickHouse는 매우 빠른 쿼리 성능으로 널리 알려져 있습니다. ClickHouse가 이렇게 빠른 이유를 알아보려면 Why is ClickHouse fast? 가이드를 참고하십시오.
