프로젝션
소개
ClickHouse는 대량의 데이터에 대한 실시간 분석 쿼리를 가속화하기 위한 다양한 메커니즘을 제공합니다. 이러한 쿼리를 빠르게 하는 메커니즘 중 하나가 바로 _프로젝션_입니다. 프로젝션은 관심 있는 속성 기준으로 데이터를 재정렬하여 쿼리를 최적화합니다. 이 재정렬 방식은 다음과 같을 수 있습니다.
- 전체 데이터에 대한 완전한 재정렬
- 원본 테이블의 부분 집합을 다른 순서로 정렬
- 미리 계산된 집계(materialized view와 유사)이며, 집계에 맞춰 정렬이 구성된 경우
Projections는 어떻게 동작합니까?
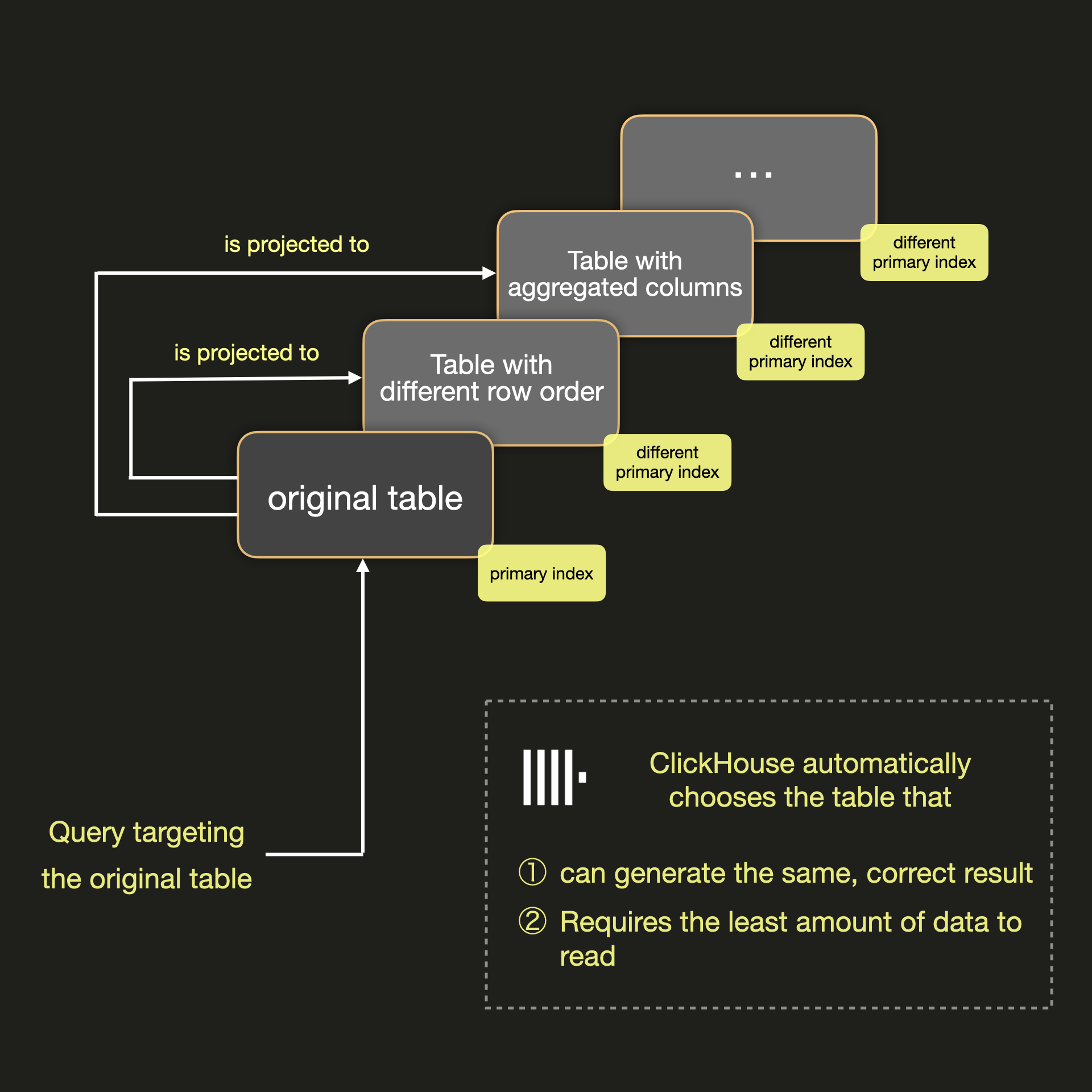
실제로 Projection은 원본 테이블에 추가된 숨겨진 보조 테이블로 볼 수 있습니다. Projection은 원본 테이블과 다른 행(row) 순서를 가질 수 있으며, 따라서 원본 테이블과는 다른 기본 인덱스(primary index)를 가질 수 있고, 집계 값을 자동으로 점진적으로 미리 계산합니다. 그 결과 Projections를 사용하면 쿼리 실행 속도를 높이기 위한 두 가지 주요 「튜닝 수단」을 제공하게 됩니다:
- 기본 인덱스를 적절히 활용하기
- 집계를 미리 계산하기
Projections는 여러 행(row) 순서를 허용하고 삽입 시점에 집계를 미리 계산한다는 점에서 Materialized Views와 어느 정도 유사합니다. Projections는 자동으로 업데이트되고 원본 테이블과 동기화 상태로 유지되지만, Materialized Views는 명시적으로 업데이트해야 합니다. 쿼리가 원본 테이블을 대상으로 할 때 ClickHouse는 기본 키를 자동으로 샘플링하고, 동일한 올바른 결과를 생성할 수 있으면서도 읽어야 하는 데이터 양이 가장 적은 테이블을 아래 그림과 같이 선택합니다:
_part_offset를 활용한 더 스마트한 스토리지
버전 25.5부터 ClickHouse는 프로젝션에서 가상 컬럼 _part_offset을 지원하며, 이를 통해 프로젝션을 정의하는 새로운 방식을 제공합니다.
이제 프로젝션을 정의하는 방식에는 두 가지가 있습니다:
-
전체 컬럼 저장(기존 동작): 프로젝션에 전체 데이터가 저장되며, 프로젝션의 정렬 순서와 일치하는 필터가 있을 때 프로젝션에서 직접 읽어 더 빠른 성능을 제공합니다.
-
정렬 키(sorting key)와
_part_offset만 저장: 프로젝션이 인덱스처럼 동작합니다.
ClickHouse는 프로젝션의 프라이머리 인덱스를 사용하여 일치하는 행을 찾고, 실제 데이터는 기본 테이블에서 읽습니다. 이 방식은 쿼리 시 I/O가 약간 증가하는 대신 스토리지 오버헤드를 줄여 줍니다.
위 두 가지 접근 방식은 혼용할 수도 있으며, 일부 컬럼은 프로젝션에 직접 저장하고
다른 컬럼은 _part_offset을 통해 간접적으로 저장할 수 있습니다.
프로젝션을 언제 사용해야 하나요?
프로젝션은 데이터가 삽입될 때 자동으로 유지 관리되므로 신규 사용자에게 매력적인 기능입니다. 또한 쿼리는 단일 테이블로만 전송하면 되며, 가능한 경우 프로젝션을 활용해 응답 시간을 단축합니다.
이는 materialized view와 대조적입니다. materialized view에서는 필터에 따라 사용자가 적절한 최적화 대상 테이블을 선택하거나 쿼리를 다시 작성해야 합니다. 이로 인해 사용자 애플리케이션의 부담이 커지고 클라이언트 측 복잡성이 증가합니다.
이러한 이점에도 불구하고 프로젝션에는 본질적인 제한 사항이 있으므로 이를 이해한 뒤 신중하게 사용하는 것이 좋습니다.
- 프로젝션은 소스 테이블과 (숨겨진) 대상 테이블에 서로 다른 TTL을 설정할 수 없지만, materialized view는 서로 다른 TTL을 사용할 수 있습니다.
- 프로젝션이 있는 테이블은 경량 업데이트 및 삭제를 지원하지 않습니다.
- materialized view는 체이닝이 가능합니다. 하나의 materialized view 대상 테이블을 다른 materialized view의 소스 테이블로 사용할 수 있습니다. 프로젝션에서는 이것이 불가능합니다.
- 프로젝션 정의는 조인을 지원하지 않지만 materialized view는 지원합니다. 다만 프로젝션이 있는 테이블에 대한 쿼리에서는 조인을 자유롭게 사용할 수 있습니다.
- 프로젝션 정의는 필터(
WHERE절)를 지원하지 않지만 materialized view는 지원합니다. 다만 프로젝션이 있는 테이블에 대한 쿼리에서는 자유롭게 필터링할 수 있습니다.
다음과 같은 경우 프로젝션 사용을 권장합니다.
- 데이터의 완전한 재정렬이 필요한 경우입니다. 이론적으로 프로젝션의 표현식에서
GROUP BY를 사용할 수 있지만, 집계를 유지 관리하는 데에는 materialized view가 더 효과적입니다. 또한 쿼리 옵티마이저는 일반적으로SELECT * ORDER BY x와 같이 단순 재정렬을 사용하는 프로젝션을 더 잘 활용합니다. 스토리지 사용량을 줄이기 위해 이 표현식에서 컬럼의 일부만 선택할 수 있습니다. - 스토리지 사용량 증가 가능성과 데이터를 두 번 기록하는 데 따른 오버헤드를 수용할 수 있는 경우입니다. 삽입 속도에 미치는 영향을 테스트하고 스토리지 오버헤드를 평가하십시오.
예제
기본 키에 포함되지 않은 컬럼을 기준으로 필터링하기
이 예제에서는 테이블에 프로젝션(Projection)을 추가하는 방법을 보여줍니다. 또한 이 프로젝션을 사용하여 테이블의 기본 키에 포함되지 않은 컬럼을 기준으로 필터링하는 쿼리를 더 빠르게 만드는 방법도 살펴봅니다.
이 예제에서는 pickup_datetime 순서로 정렬된
sql.clickhouse.com에서 제공하는 New York Taxi Data
데이터 세트를 사용합니다.
먼저 승객이 운전 기사에게 200달러를 초과하여 팁을 지급한 모든 운행 ID를 찾는 간단한 쿼리를 작성해 보겠습니다:
ORDER BY에 포함되지 않은 tip_amount에 대해 필터링하고 있으므로 ClickHouse가 전체 테이블 스캔을 수행해야 했습니다. 이제 이 쿼리를 더 빠르게 만들어 보겠습니다.
원래 테이블과 결과를 보존하기 위해 새 테이블을 생성하고 INSERT INTO SELECT를 사용하여 데이터를 복사하겠습니다.
PROJECTION을 추가하려면 ALTER TABLE 문과 ADD PROJECTION 문을 함께 사용합니다:
프로젝션을 추가한 후에는 위에서 지정한 쿼리에 따라 그 안의 데이터가 실제로 정렬되고 재작성되도록 MATERIALIZE PROJECTION
문을 실행해야 합니다.
이제 PROJECTION을 추가했으니 쿼리를 다시 한 번 실행해 보겠습니다:
쿼리 수행 시간을 상당히 줄일 수 있었고, 스캔해야 하는 행 수도 더 적어졌습니다.
위의 쿼리가 앞에서 생성한 프로젝션을 실제로 사용했는지는 system.query_log 테이블을 조회하여 확인할 수 있습니다.
프로젝션을 사용하여 영국 부동산 실거래가 쿼리 속도 향상하기
프로젝션을 사용하여 쿼리 성능을 향상시키는 방법을 시연하기 위해 실제 데이터셋을 사용한 예제를 살펴보겠습니다. 이 예제에서는 3,003만 개의 행이 포함된 UK Property Price Paid 튜토리얼의 테이블을 사용합니다. 이 데이터셋은 sql.clickhouse.com 환경에서도 사용 가능합니다.
테이블이 생성되고 데이터가 삽입된 방법을 확인하려면 "영국 부동산 가격 데이터셋" 페이지를 참조하세요.
이 데이터셋에 대해 두 가지 간단한 쿼리를 실행할 수 있습니다. 첫 번째 쿼리는 런던에서 가장 높은 가격이 지불된 카운티 목록을 표시하며, 두 번째 쿼리는 카운티별 평균 가격을 계산합니다:
두 쿼리 모두 매우 빠르게 실행되었지만, 테이블 생성 시 ORDER BY 절에 town과 price가 포함되지 않았기 때문에 전체 3,003만 행에 대한 풀 테이블 스캔이 발생했다는 점에 유의하십시오:
프로젝션을 사용하여 이 쿼리 속도를 높일 수 있는지 확인해 보겠습니다.
원본 테이블과 결과를 보존하기 위해 새 테이블을 생성하고 INSERT INTO SELECT를 사용하여 데이터를 복사하겠습니다:
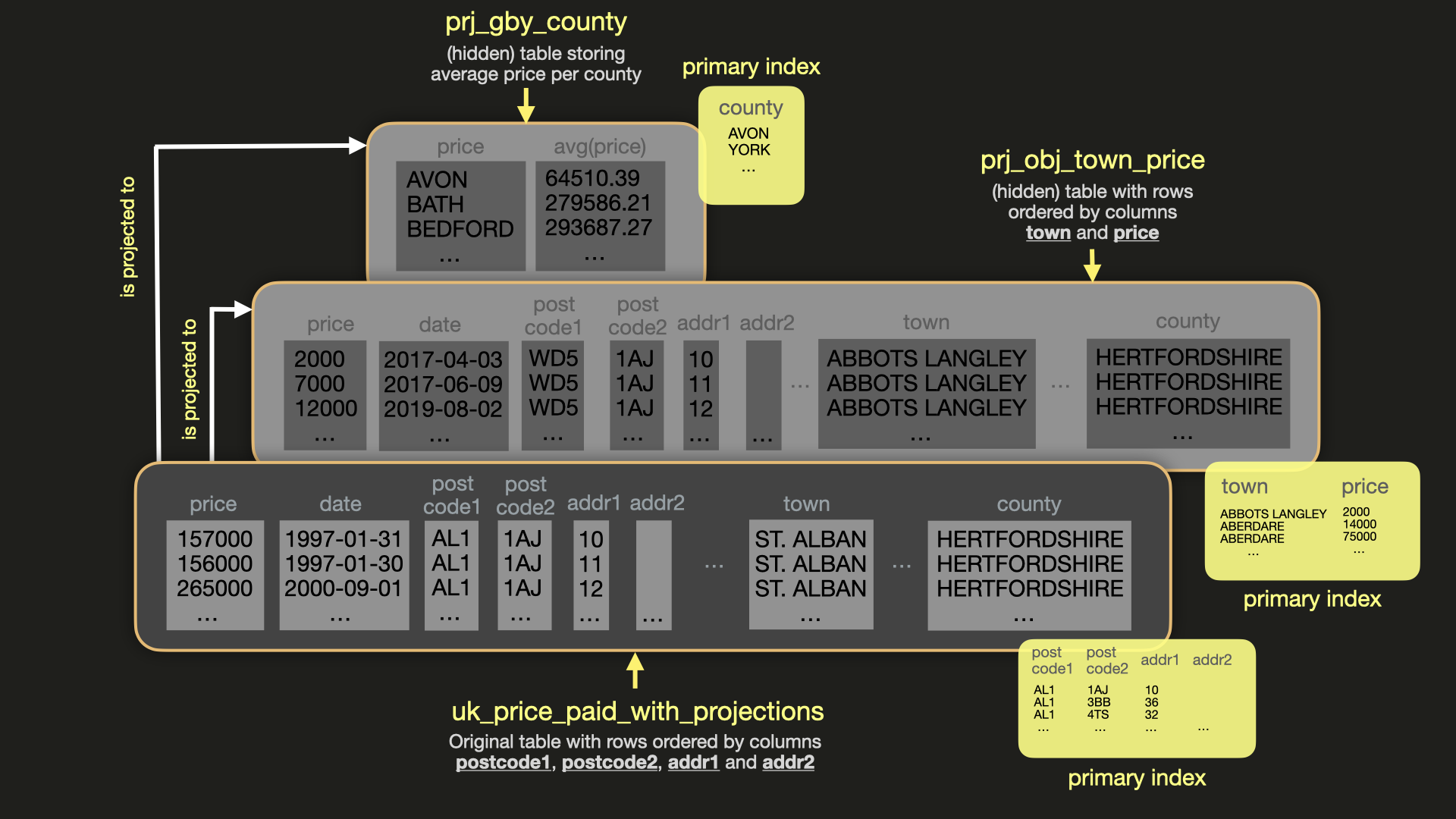
프로젝션 prj_oby_town_price를 생성하고 데이터를 채워 town과 price로 정렬된 기본 인덱스를 가진
추가 (숨겨진) 테이블을 생성합니다. 이를 통해 특정 town에서 가장 높은 가격으로
지불된 county 목록을 조회하는 쿼리를 최적화합니다:
mutations_sync 설정을 사용하여
동기 실행을 강제할 수 있습니다.
PROJECTION prj_gby_county를 생성하고 데이터를 채웁니다. 이는 기존 130개 영국 카운티 전체에 대한 avg(price) 집계 값을 점진적으로 사전 계산하는 추가(숨겨진) 테이블입니다:
위의 prj_gby_county 프로젝션처럼 프로젝션에서 GROUP BY 절을 사용하는 경우, (숨겨진) 테이블의 기본 스토리지 엔진은 AggregatingMergeTree가 되며, 모든 집계 함수는 AggregateFunction으로 변환됩니다. 이는 적절한 증분 데이터 집계를 보장합니다.
아래 그림은 메인 테이블 uk_price_paid_with_projections와
두 개의 프로젝션을 시각화한 것입니다:
이제 런던에서 가장 높은 거래 가격 상위 3개에 해당하는 카운티를 나열하는 쿼리를 다시 실행하면 쿼리 성능이 개선된 것을 확인할 수 있습니다:
마찬가지로, 평균 지불 가격이 가장 높은 상위 3개의 영국 카운티를 나열하는 쿼리는 다음과 같습니다:
두 쿼리 모두 원본 테이블을 대상으로 하며, 두 개의 프로젝션을 생성하기 전에는 전체 테이블 스캔(디스크에서 3,003만 개의 행이 모두 스트리밍됨)이 발생했습니다.
또한, 런던의 카운티에서 가장 높은 가격 상위 3개를 나열하는 쿼리는 약 217만 개의 행을 스트리밍한다는 점에 유의해야 합니다. 이 쿼리에 최적화된 두 번째 테이블을 직접 사용했을 때는 디스크에서 스트리밍된 행이 약 8만 1,920개에 불과했습니다.
차이가 발생하는 이유는 위에서 언급한 optimize_read_in_order
최적화가 현재 프로젝션에는 지원되지 않기 때문입니다.
system.query_log 테이블을 확인하면, ClickHouse가 위의 두 쿼리에 대해
자동으로 두 개의 프로젝션을 사용했다는 것을 확인할 수 있습니다(아래의
projections 컬럼 참조):
추가 예시
다음 예시들은 동일한 영국(UK) 가격 데이터셋을 사용하여, 프로젝션을 사용하는 쿼리와 사용하지 않는 쿼리를 비교합니다.
원본 테이블과 그 성능을 보존하기 위해, 이번에도 CREATE AS 및 INSERT INTO SELECT를 사용해 테이블의 복사본을 생성합니다.
프로젝션 생성
toYear(date), district, town 차원을 기준으로 집계 프로젝션을 생성해 보겠습니다:
기존 데이터에 대해 프로젝션을 구체화합니다. (구체화를 수행하지 않으면 프로젝션은 새로 삽입되는 데이터에 대해서만 생성됩니다):
다음 쿼리는 프로젝션을 사용한 경우와 사용하지 않은 경우의 성능을 비교합니다. 프로젝션 사용을 비활성화하기 위해 기본적으로 활성화되어 있는 설정 optimize_use_projections을(를) 사용합니다.
쿼리 1. 연도별 평균 가격
결과는 동일하지만, 후자 예제에서는 성능이 더 좋습니다!
쿼리 2. 런던의 연도별 평균 가격
쿼리 3. 가장 비싼 지역
조건식 (date >= '2020-01-01')은 PROJECTION의 차원(`toYear(date) >= 2020)과 일치하도록 수정해야 합니다:
결과는 동일하지만, 두 번째 쿼리의 성능 향상에 주목하십시오.
하나의 쿼리에서 여러 프로젝션 결합하기
버전 25.6부터, 이전 버전에서 도입된 _part_offset 지원을 기반으로
ClickHouse는 이제 여러 프로젝션을 활용하여 여러 필터가 있는 단일 쿼리를
가속할 수 있습니다.
중요한 점은 ClickHouse가 여전히 하나의 프로젝션(또는 기본 테이블)에서만 데이터를 읽지만, 다른 프로젝션의 기본 인덱스를 사용해 읽기 전에 불필요한 파트를 미리 걸러낼 수 있다는 점입니다. 이는 여러 컬럼에 대해 필터링하는 쿼리에서 특히 유용하며, 각 컬럼이 서로 다른 프로젝션과 잠재적으로 매칭될 수 있습니다.
현재 이 메커니즘은 전체 파트만 제거합니다. 그라뉼(granule) 수준의 제거는 아직 지원하지 않습니다.
이를 보여주기 위해 _part_offset 컬럼을 사용하는 프로젝션이 포함된
테이블을 정의하고, 위 다이어그램과 일치하는 예제 행 5개를 삽입합니다.
그런 다음 테이블에 데이터를 삽입합니다:
참고: 이 테이블은 설명을 위해 단일 행 그래뉼과 파트 병합 비활성화와 같은 사용자 정의 설정을 사용하며, 프로덕션 환경에서는 권장되지 않습니다.
이 구성의 결과는 다음과 같습니다.
- 서로 다른 5개의 파트(삽입된 행당 1개)
- 기본 테이블과 각 프로젝션에서 행당 1개의 기본 인덱스 항목
- 각 파트에는 정확히 1개의 행이 포함됩니다
이 구성을 사용하여 region과 user_id 모두에 대해 필터링하는 쿼리를 실행합니다.
기본 테이블의 기본 인덱스가 event_date와 id로 구성되어 있으므로
여기서는 도움이 되지 않으며, 따라서 ClickHouse는 다음을 사용합니다.
region_proj를 사용해 region별로 파트를 프루닝(pruning)user_id_proj를 사용해user_id로 한 번 더 프루닝(pruning)
이 동작은 EXPLAIN projections = 1을 사용하면 확인할 수 있으며, 이 명령은
ClickHouse가 프로젝션을 선택하고 적용하는 방식을 보여 줍니다.
위에 표시된 EXPLAIN 출력은 논리적 쿼리 계획을 위에서 아래로 보여 줍니다.
| 행 번호 | 설명 |
|---|---|
| 3 | page_views 기본 테이블에서 읽을 계획입니다 |
| 5-13 | region_proj를 사용하여 region = 'us_west'인 3개의 파트를 식별하고, 5개의 파트 중 2개를 건너뜁니다(pruning) |
| 14-22 | user_id_proj를 사용하여 user_id = 107인 1개의 파트를 식별하고, 남은 3개의 파트 중 2개를 추가로 건너뜁니다 |
결과적으로 기본 테이블에서는 5개의 파트 중 단 1개만 읽습니다. 여러 프로젝션의 인덱스 분석을 결합하여 ClickHouse는 스캔해야 하는 데이터 양을 크게 줄이고, 스토리지 오버헤드를 낮게 유지하면서 성능을 향상합니다.
