다음과 같은 이유로, 로그와 트레이스를 위한 별도의 스키마를 항상 정의할 것을 권장합니다:
- 프라이머리 키(primary key) 선택 - 기본 스키마는 특정 액세스 패턴에 최적화된
ORDER BY를 사용합니다. 액세스 패턴이 이에 일치할 가능성은 낮습니다.
- 구조 추출 - 기존 컬럼(예:
Body 컬럼)에서 새로운 컬럼을 추출하고자 할 수 있습니다. 이는 materialized 컬럼(그리고 더 복잡한 경우에는 materialized view)을 사용하여 수행할 수 있습니다. 이를 위해서는 스키마 변경이 필요합니다.
- 맵(Map) 최적화 - 기본 스키마는 속성(attributes)을 저장하기 위해 Map 타입을 사용합니다. 이러한 컬럼은 임의의 메타데이터를 저장할 수 있습니다. 이벤트의 메타데이터가 사전에 정의되지 않는 경우가 많아 ClickHouse와 같은 강한 타입의 데이터베이스에는 다른 방식으로는 저장할 수 없기 때문에 필수적인 기능입니다. 그러나 맵 키와 해당 값을 조회하는 것은 일반 컬럼에 접근하는 것만큼 효율적이지 않습니다. 이 문제는 스키마를 수정하고, 가장 자주 접근하는 맵 키를 최상위 컬럼으로 노출함으로써 해결합니다. 자세한 내용은 「SQL로 구조 추출하기」를 참조하십시오. 이 작업에는 스키마 변경이 필요합니다.
- 맵 키 접근 단순화 - 맵의 키에 접근하려면 더 장황한 문법을 사용해야 합니다. 별칭(alias)을 사용하여 이를 완화할 수 있습니다. 쿼리를 단순화하는 방법은 「별칭 사용하기」를 참조하십시오.
- 세컨더리 인덱스 - 기본 스키마는 맵 접근 속도 및 텍스트 쿼리 성능 향상을 위해 세컨더리 인덱스를 사용합니다. 이는 일반적으로 필수는 아니며 추가 디스크 사용량을 발생시킵니다. 사용할 수는 있지만, 실제로 필요한지 테스트해야 합니다. 자세한 내용은 「세컨더리 / Data Skipping 인덱스」를 참조하십시오.
- 코덱 사용 - 예상되는 데이터를 파악하고, 압축이 향상된다는 근거가 있는 경우 컬럼별로 코덱을 사용자 정의하고자 할 수 있습니다.
위 사용 사례 각각을 아래에서 자세히 설명합니다.
중요: 최적의 압축률과 쿼리 성능을 달성하기 위해 스키마를 확장·수정하는 것은 권장되지만, 가능하면 핵심 컬럼에 대해서는 OTel 스키마 네이밍을 따르는 것이 좋습니다. ClickHouse Grafana 플러그인은 Timestamp, SeverityText와 같은 일부 기본 OTel 컬럼이 존재한다고 가정하고 쿼리 빌딩을 도와줍니다. 로그와 트레이스를 위한 필수 컬럼은 각각 여기 [1][2] 및 여기에 문서화되어 있습니다. 플러그인 설정에서 기본값을 오버라이드하여 이 컬럼 이름을 변경할 수 있습니다.
구조화된 로그이든 비구조화된 로그이든 수집할 때, 사용자에게는 다음과 같은 능력이 필요한 경우가 많습니다.
- 문자열 블롭에서 컬럼 추출. 이렇게 추출된 컬럼을 쿼리하면, 쿼리 시점에 문자열 연산을 사용하는 것보다 더 빠르게 동작합니다.
- 맵에서 키 추출. 기본 스키마는 임의의 속성을 Map 타입의 컬럼에 저장합니다. 이 타입은 스키마리스(schema-less) 기능을 제공하여, 로그와 트레이스를 정의할 때 속성에 대한 컬럼을 미리 정의할 필요가 없다는 장점이 있습니다. Kubernetes에서 로그를 수집하고, 이후 검색을 위해 파드 레이블이 유지되도록 하려는 경우에는 미리 정의하는 것이 불가능한 경우가 많습니다. 맵 키와 그 값에 접근하는 작업은 일반 ClickHouse 컬럼을 쿼리하는 것보다 느립니다. 따라서 맵에서 키를 추출하여 루트 테이블 컬럼으로 만드는 것이 바람직한 경우가 많습니다.
다음 쿼리를 살펴보십시오.
구조화된 로그를 사용하여 어떤 URL 경로가 POST 요청을 가장 많이 받는지 집계하고자 한다고 가정합니다. JSON 블롭은 Body 컬럼에 String으로 저장됩니다. 추가로, 사용자가 수집기에서 json_parser를 활성화한 경우에는 LogAttributes 컬럼에 Map(String, String) 형태로도 저장될 수 있습니다.
SELECT LogAttributes
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
LogAttributes: {'status':'200','log.file.name':'access-structured.log','request_protocol':'HTTP/1.1','run_time':'0','time_local':'2019-01-22 00:26:14.000','size':'30577','user_agent':'Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)','referer':'-','remote_user':'-','request_type':'GET','request_path':'/filter/27|13 ,27| 5 ,p53','remote_addr':'54.36.149.41'}
LogAttributes가 사용 가능하다고 가정하면, 사이트에서 POST 요청을 가장 많이 받는 URL 경로를 집계하는 쿼리는 다음과 같습니다.
SELECT path(LogAttributes['request_path']) AS path, count() AS c
FROM otel_logs
WHERE ((LogAttributes['request_type']) = 'POST')
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productModelImages │ 10866 │
│ /site/productAdditives │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.735 sec. Processed 10.36 million rows, 4.65 GB (14.10 million rows/s., 6.32 GB/s.)
Peak memory usage: 153.71 MiB.
여기에서 예: LogAttributes['request_path']와 같은 맵 문법의 사용 방식과, URL에서 쿼리 매개변수를 제거하기 위한 path 함수에 주목하십시오.
사용자가 수집기에서 JSON 파싱을 활성화하지 않은 경우 LogAttributes는 비어 있게 되며, 이 경우 String Body에서 컬럼을 추출하기 위해 JSON 함수를 사용해야 합니다.
JSON 파싱에는 ClickHouse 사용을 권장
일반적으로 구조화된 로그의 JSON 파싱은 ClickHouse에서 수행하도록 권장합니다. ClickHouse가 가장 빠른 JSON 파싱 구현을 제공한다고 자신합니다. 다만, 로그를 다른 소스로 전송해야 하거나 이 로직을 SQL에 두고 싶지 않을 수도 있음을 이해합니다.
SELECT path(JSONExtractString(Body, 'request_path')) AS path, count() AS c
FROM otel_logs
WHERE JSONExtractString(Body, 'request_type') = 'POST'
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productAdditives │ 10866 │
│ /site/productModelImages │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.668 sec. Processed 10.37 million rows, 5.13 GB (15.52 million rows/s., 7.68 GB/s.)
Peak memory usage: 172.30 MiB.
이제 같은 작업을 비정형 로그에도 적용해 보겠습니다:
SELECT Body, LogAttributes
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: 151.233.185.144 - - [22/Jan/2019:19:08:54 +0330] "GET /image/105/brand HTTP/1.1" 200 2653 "https://www.zanbil.ir/filter/b43,p56" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36" "-"
LogAttributes: {'log.file.name':'access-unstructured.log'}
비정형 로그에 대해 비슷한 쿼리를 실행하려면 정규 표현식을 사용해야 하며, 이를 위해 extractAllGroupsVertical FUNCTION을 사용합니다.
SELECT
path((groups[1])[2]) AS path,
count() AS c
FROM
(
SELECT extractAllGroupsVertical(Body, '(\\w+)\\s([^\\s]+)\\sHTTP/\\d\\.\\d') AS groups
FROM otel_logs
WHERE ((groups[1])[1]) = 'POST'
)
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productModelImages │ 10866 │
│ /site/productAdditives │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 1.953 sec. Processed 10.37 million rows, 3.59 GB (5.31 million rows/s., 1.84 GB/s.)
구조화되지 않은 로그를 파싱하기 위한 쿼리는 복잡성과 비용이 크게 증가합니다(성능 차이를 확인해 보십시오). 이러한 이유로 가능한 경우에는 항상 구조화된 로그를 사용할 것을 권장합니다.
사전(dictionaries) 사용 고려
위 쿼리는 정규 표현식 사전을 활용하도록 최적화할 수 있습니다. 자세한 내용은 Using Dictionaries를 참조하십시오.
위의 쿼리 로직을 데이터 삽입 시점으로 이전하면, 이러한 두 가지 사용 사례 모두를 ClickHouse만으로도 만족할 수 있습니다. 아래에서 여러 가지 접근 방식을 살펴보고, 각 접근 방식이 적합한 상황을 함께 설명합니다.
처리는 OTel과 ClickHouse 중 무엇을 사용할까요?
여기에 설명된 대로 OTel collector의 processor 및 operator를 사용하여 처리 작업을 수행할 수도 있습니다. 대부분의 경우 ClickHouse는 collector의 processor보다 리소스 효율성이 훨씬 높고 훨씬 더 빠릅니다. 모든 이벤트 처리를 SQL에서 수행하는 것의 주요 단점은 솔루션이 ClickHouse에 강하게 결합된다는 점입니다. 예를 들어, OTel collector에서 처리된 로그를 S3와 같은 다른 목적지로도 전송해야 할 수 있습니다.
Materialized 컬럼
Materialized 컬럼은 다른 컬럼에서 구조를 추출하는 가장 단순한 방법을 제공합니다. 이러한 컬럼의 값은 항상 데이터 삽입 시점에 계산되며, INSERT 쿼리에서 직접 지정할 수 없습니다.
오버헤드
Materialized 컬럼은 값이 삽입 시점에 디스크 상의 새로운 컬럼으로 추출되므로 추가적인 스토리지 오버헤드가 발생합니다.
Materialized 컬럼은 모든 ClickHouse 표현식을 지원하며, 문자열 처리(정규식 및 검색 포함), URL 처리, 형 변환, JSON에서 값 추출, 수학 연산 등에 사용되는 분석 함수들을 모두 활용할 수 있습니다.
기본적인 처리에는 materialized 컬럼 사용을 권장합니다. 특히 맵에서 값을 추출해 루트 컬럼으로 승격하거나 형 변환을 수행할 때 유용합니다. 매우 단순한 스키마에서 사용하거나 materialized view와 함께 사용할 때 가장 큰 효과를 발휘하는 경우가 많습니다. 다음은 컬렉터가 JSON을 추출하여 LogAttributes 컬럼에 저장한 로그에 대한 스키마 예시입니다:
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`RequestPage` String MATERIALIZED path(LogAttributes['request_path']),
`RequestType` LowCardinality(String) MATERIALIZED LogAttributes['request_type'],
`RefererDomain` String MATERIALIZED domain(LogAttributes['referer'])
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
String Body에서 JSON 함수를 사용해 추출하기 위한 동일한 스키마는 여기에서 확인할 수 있습니다.
세 개의 materialized 컬럼은 요청 페이지, 요청 유형, 그리고 리퍼러(referrer)의 도메인을 추출합니다. 이 컬럼들은 맵 키를 참조하고 해당 값에 함수를 적용합니다. 이후 쿼리 성능은 크게 향상됩니다:
SELECT RequestPage AS path, count() AS c
FROM otel_logs
WHERE RequestType = 'POST'
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productAdditives │ 10866 │
│ /site/productModelImages │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.173 sec. Processed 10.37 million rows, 418.03 MB (60.07 million rows/s., 2.42 GB/s.)
Peak memory usage: 3.16 MiB.
참고
materialized 컬럼은 기본적으로 SELECT * 결과에 포함되어 반환되지 않습니다. 이는 SELECT * 결과를 항상 INSERT를 사용해 다시 테이블에 삽입할 수 있다는 불변성을 보장하기 위한 것입니다. 이 동작은 asterisk_include_materialized_columns=1을 설정하여 비활성화할 수 있으며, Grafana의 데이터 소스 구성에서 Additional Settings -> Custom Settings를 통해 활성화할 수 있습니다.
Materialized views
Materialized views는 로그와 트레이스에 SQL 필터링과 변환을 적용하는 보다 강력한 방법을 제공합니다.
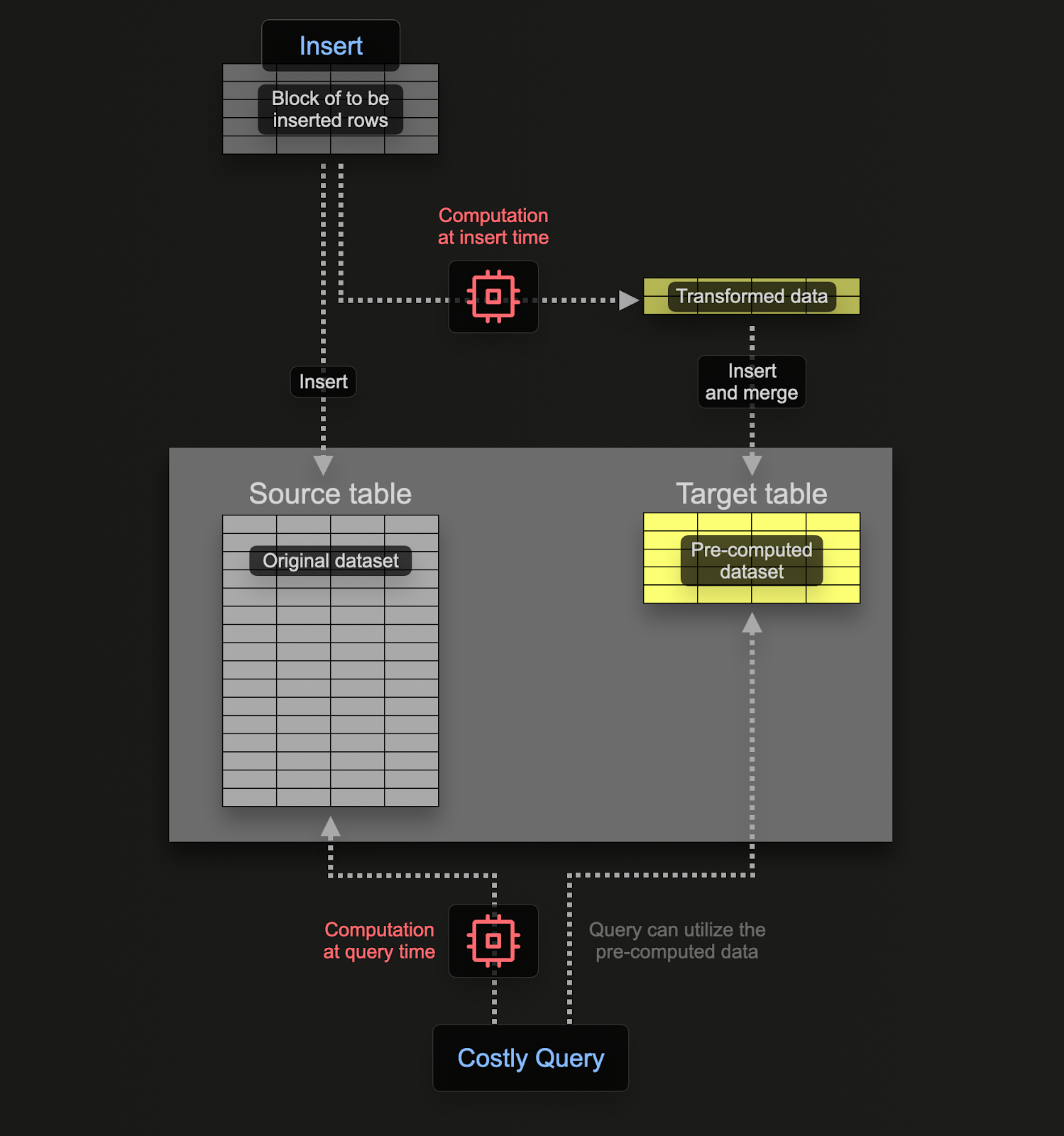
materialized view를 사용하면 계산 비용을 쿼리 시점에서 삽입 시점으로 이전할 수 있습니다. ClickHouse materialized view는 테이블에 데이터 블록이 삽입될 때마다 쿼리를 실행하는 트리거 역할을 합니다. 이 쿼리의 결과는 두 번째 "대상(target)" 테이블에 삽입됩니다.
실시간 업데이트
ClickHouse의 materialized view는 기반이 되는 테이블로 데이터가 유입되는 대로 실시간으로 업데이트되며, 지속적으로 갱신되는 인덱스처럼 동작합니다. 반면 다른 데이터베이스에서 materialized view는 일반적으로 쿼리의 정적인 스냅샷이며, 주기적으로 새로 고쳐야 합니다(ClickHouse의 Refreshable Materialized Views와 유사합니다).
materialized view와 연결된 쿼리는 이론적으로 집계를 포함해 어떤 쿼리든 될 수 있지만, 조인에 대한 제한 사항이 존재합니다. 로그와 트레이스에 필요한 변환 및 필터링 작업의 경우, 어떤 SELECT 문이든 사용 가능하다고 보면 됩니다.
이 쿼리는 테이블(소스 테이블)에 삽입되는 행을 대상으로 실행되는 트리거일 뿐이며, 그 결과가 새 테이블(대상 테이블)로 전송된다는 점을 기억해야 합니다.
소스 테이블과 대상 테이블에 데이터를 두 번 저장하지 않도록 하려면, 소스 테이블의 테이블 엔진을 Null table engine으로 변경하여 원래 스키마를 유지하면 됩니다. OTel collectors는 계속해서 이 테이블로 데이터를 전송합니다. 예를 들어 로그의 경우, otel_logs 테이블은 다음과 같이 변경됩니다:
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1))
) ENGINE = Null
Null 테이블 엔진은 매우 강력한 최적화 기능으로, /dev/null과 유사한 개념입니다. 이 테이블은 데이터를 전혀 저장하지 않지만, 여기에 연결된 모든 구체화된 뷰(materialized view)는 데이터가 폐기되기 전에 삽입된 행에 대해 여전히 실행됩니다.
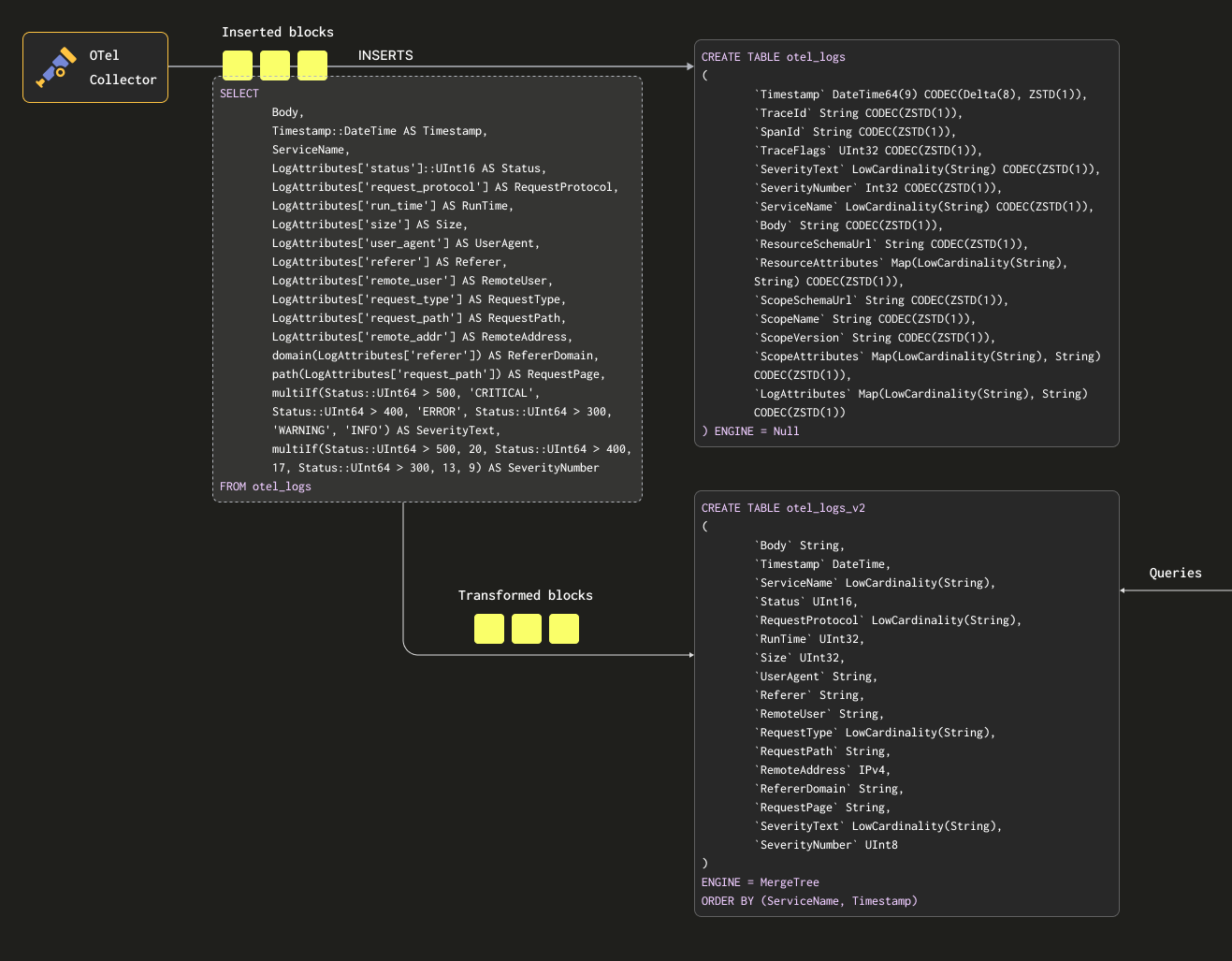
다음 쿼리를 살펴보십시오. 이 쿼리는 행을 유지하려는 형식으로 변환하면서 LogAttributes에서 모든 컬럼을 추출합니다(수집기가 json_parser 연산자를 사용해 이를 설정했다고 가정합니다). 또한 일부 간단한 조건과 해당 컬럼에 대한 정의를 기반으로 SeverityText와 SeverityNumber를 설정합니다. 이 예제에서는 TraceId, SpanId, TraceFlags와 같은 컬럼은 무시하고, 값이 채워질 것이라고 예상되는 컬럼만 선택합니다.
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status'] AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddr,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
Timestamp: 2019-01-22 00:26:14
ServiceName:
Status: 200
RequestProtocol: HTTP/1.1
RunTime: 0
Size: 30577
UserAgent: Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
Referer: -
RemoteUser: -
RequestType: GET
RequestPath: /filter/27|13 ,27| 5 ,p53
RemoteAddr: 54.36.149.41
RefererDomain:
RequestPage: /filter/27|13 ,27| 5 ,p53
SeverityText: INFO
SeverityNumber: 9
1 row in set. Elapsed: 0.027 sec.
위에서 Body 컬럼도 추출합니다. 나중에 SQL에서 추출하지 않는 추가 속성이 여기에 포함될 수 있기 때문입니다. 이 컬럼은 ClickHouse에서 압축 효율이 좋고, 거의 조회되지 않으므로 쿼리 성능에 영향을 주지 않습니다. 마지막으로, Timestamp를 DateTime 타입으로 캐스팅하여 공간을 절약합니다(자세한 내용은 "Optimizing Types"을(를) 참조).
조건문
위에서 SeverityText와 SeverityNumber를 추출할 때 조건문을 사용하는 것에 주목하십시오. 이는 복잡한 조건을 구성하고 맵에 값이 설정되어 있는지 확인하는 데 매우 유용합니다. 여기서는 LogAttributes에 모든 키가 존재한다고 단순하게 가정합니다. null 값을 처리하는 함수와 더불어 로그 파싱에 큰 도움이 되므로, 조건문에 익숙해질 것을 권장합니다.
이 결과를 저장할 테이블이 필요합니다. 아래 대상 테이블은 위 쿼리와 스키마가 일치합니다:
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
여기에서 선택한 타입들은 "타입 최적화"에서 논의한 최적화를 기반으로 합니다.
참고
스키마가 크게 변경된 점에 주목하십시오. 실제 환경에서는 트레이스 컬럼뿐만 아니라 일반적으로 Kubernetes 메타데이터를 포함하는 ResourceAttributes 컬럼도 보존하려 할 가능성이 높습니다. Grafana는 트레이스 컬럼을 활용하여 로그와 트레이스 간의 연결 기능을 제공할 수 있습니다. 자세한 내용은 "Grafana 사용하기"를 참조하십시오.
아래에서는 materialized view otel_logs_mv를 생성합니다. 이 뷰는 otel_logs 테이블에 대해 위의 SELECT를 실행하고, 결과를 otel_logs_v2 테이블로 전송합니다.
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 AS
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status']::UInt16 AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
위에서 설명한 내용은 아래와 같이 시각화됩니다:
이제 "Exporting to ClickHouse"에 사용한 collector 구성을 사용해 collector를 다시 시작하면, otel_logs_v2에 원하는 형식으로 데이터가 나타납니다. 타입이 지정된 JSON 추출 함수를 사용한다는 점에 유의하십시오.
SELECT *
FROM otel_logs_v2
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
Timestamp: 2019-01-22 00:26:14
ServiceName:
Status: 200
RequestProtocol: HTTP/1.1
RunTime: 0
Size: 30577
UserAgent: Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
Referer: -
RemoteUser: -
RequestType: GET
RequestPath: /filter/27|13 ,27| 5 ,p53
RemoteAddress: 54.36.149.41
RefererDomain:
RequestPage: /filter/27|13 ,27| 5 ,p53
SeverityText: INFO
SeverityNumber: 9
1 row in set. Elapsed: 0.010 sec.
Body 컬럼에서 JSON 함수를 사용해 컬럼을 추출하는 방식으로 동작하는 동등한 materialized view 예시는 아래와 같습니다:
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 AS
SELECT Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
JSONExtractUInt(Body, 'status') AS Status,
JSONExtractString(Body, 'request_protocol') AS RequestProtocol,
JSONExtractUInt(Body, 'run_time') AS RunTime,
JSONExtractUInt(Body, 'size') AS Size,
JSONExtractString(Body, 'user_agent') AS UserAgent,
JSONExtractString(Body, 'referer') AS Referer,
JSONExtractString(Body, 'remote_user') AS RemoteUser,
JSONExtractString(Body, 'request_type') AS RequestType,
JSONExtractString(Body, 'request_path') AS RequestPath,
JSONExtractString(Body, 'remote_addr') AS remote_addr,
domain(JSONExtractString(Body, 'referer')) AS RefererDomain,
path(JSONExtractString(Body, 'request_path')) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
타입에 주의하십시오
위의 materialized view는 암시적 캐스팅에 의존합니다. 특히 LogAttributes 맵을 사용할 때 그렇습니다. ClickHouse는 추출된 값을 대상 테이블의 타입으로 종종 자동 캐스팅하여, 필요로 하는 문법을 줄여 줍니다. 그러나 항상 동일한 스키마를 사용하는 대상 테이블에 대해, 해당 뷰의 SELECT 구문과 INSERT INTO 구문을 함께 사용해 뷰를 테스트할 것을 권장합니다. 이렇게 하면 타입이 올바르게 처리되는지 확인할 수 있습니다. 다음과 같은 경우에는 특히 주의를 기울여야 합니다.
- 맵에 키가 존재하지 않으면 빈 문자열이 반환됩니다. 숫자형인 경우에는 이를 적절한 값으로 매핑해야 합니다. 이는 조건 함수를 사용하여 구현할 수 있습니다. 예:
if(LogAttributes['status'] = ", 200, LogAttributes['status']) 또는 기본값이 허용된다면 캐스트 함수를 사용할 수 있습니다. 예: toUInt8OrDefault(LogAttributes['status'] )
- 일부 타입은 항상 캐스팅되지 않습니다. 예를 들어, 숫자형의 문자열 표현은 enum 값으로 캐스팅되지 않습니다.
- JSON 추출 함수는 값이 없을 경우 해당 타입의 기본값을 반환합니다. 이러한 기본값이 논리적으로 의미 있는지 반드시 확인하십시오!
Avoid Nullable
관측성(Observability) 데이터에 대해 ClickHouse에서 Nullable 타입 사용은 피하십시오. 로그와 트레이스에서는 빈 값과 null을 구분해야 할 필요가 거의 없습니다. 이 기능은 추가적인 저장소 오버헤드를 발생시키며 쿼리 성능에 부정적인 영향을 줍니다. 자세한 내용은 여기를 참조하십시오.
기본(정렬) 키 선택하기
원하는 컬럼을 추출했다면, 이제 정렬/기본 키 최적화를 시작할 수 있습니다.
간단한 규칙 몇 가지를 적용하여 정렬 키를 선택할 수 있습니다. 아래 사항들은 서로 충돌할 수 있으므로, 제시된 순서대로 고려하십시오. 이 과정을 통해 여러 개의 키를 도출할 수 있으며, 일반적으로 4–5개면 충분합니다:
- 일반적인 필터 및 액세스 패턴과 잘 부합하는 컬럼을 선택합니다. 관측성(Observability) 분석을 시작할 때 특정 컬럼(예: 파드 이름)으로 필터링하는 경우, 해당 컬럼은
WHERE 절에서 자주 사용됩니다. 사용 빈도가 낮은 컬럼보다 이와 같은 컬럼을 키에 우선적으로 포함하십시오.
- 필터링 시 전체 행 중 큰 비율을 제외하는 데 도움이 되는 컬럼을 우선하여, 읽어야 하는 데이터 양을 줄입니다. 서비스 이름과 상태 코드는 종종 좋은 후보입니다. 다만 상태 코드의 경우, 대부분의 행을 포함하는 값(예: 200대)을 기준으로 필터링하면 대부분의 시스템에서 대부분의 행이 일치하므로 효과가 떨어집니다. 500 오류처럼 소수의 부분집합에만 해당하는 값을 기준으로 필터링할 때 더 유용합니다.
- 테이블의 다른 컬럼과 높은 상관관계를 가질 가능성이 큰 컬럼을 선호합니다. 이렇게 하면 해당 값들이 연속적으로 저장되어 압축 효율이 향상됩니다.
- 정렬 키에 포함된 컬럼에 대해 수행되는
GROUP BY 및 ORDER BY 연산은 메모리를 더 효율적으로 사용할 수 있습니다.
정렬 키에 포함할 컬럼의 부분집합을 식별했다면, 이를 특정 순서로 선언해야 합니다. 이 순서는 쿼리에서 보조 키 컬럼에 대한 필터링 효율과 테이블 데이터 파일의 압축률 모두에 상당한 영향을 줄 수 있습니다. 일반적으로 카디널리티가 낮은 순서(오름차순)로 키를 정렬하는 것이 가장 좋습니다. 단, 정렬 키 튜플에서 뒤쪽에 나타나는 컬럼은 앞쪽 컬럼보다 필터링 효율이 떨어진다는 점과 균형을 맞춰야 합니다. 이러한 동작과 액세스 패턴을 함께 고려하십시오. 무엇보다도 여러 가지 조합을 테스트해야 합니다. 정렬 키에 대한 이해를 높이고 이를 최적화하는 방법을 더 알고 싶다면 이 문서를 참고하기를 권장합니다.
구조가 우선입니다
로그 구조를 먼저 정의한 후 정렬 키를 결정할 것을 권장합니다. 속성 맵(map)의 키나 JSON 추출 표현식을 정렬 키로 사용하지 마십시오. 정렬 키가 테이블의 루트 컬럼이 되도록 해야 합니다.
맵 사용하기
앞의 예제에서는 Map(String, String) 컬럼의 값에 접근하기 위해 맵 문법 map['key']를 사용하는 방법을 보여 주었습니다. 중첩된 키에 접근하기 위해 맵 표기법을 사용할 수 있을 뿐만 아니라, 이러한 컬럼을 필터링하거나 선택하기 위해 특화된 ClickHouse 맵 함수도 사용할 수 있습니다.
예를 들어, 다음 쿼리는 mapKeys 함수에 이어 groupArrayDistinctArray 함수 (콤비네이터)를 사용하여 LogAttributes 컬럼에서 사용 가능한 모든 고유 키를 식별합니다.
SELECT groupArrayDistinctArray(mapKeys(LogAttributes))
FROM otel_logs
FORMAT Vertical
Row 1:
──────
groupArrayDistinctArray(mapKeys(LogAttributes)): ['remote_user','run_time','request_type','log.file.name','referer','request_path','status','user_agent','remote_addr','time_local','size','request_protocol']
1 row in set. Elapsed: 1.139 sec. Processed 5.63 million rows, 2.53 GB (4.94 million rows/s., 2.22 GB/s.)
Peak memory usage: 71.90 MiB.
점 사용을 피하십시오
맵 컬럼 이름에는 점 사용을 권장하지 않으며, 향후 지원이 중단될 수 있습니다. 대신 _를 사용하십시오.
별칭 사용하기
맵 타입에 대한 쿼리는 일반 컬럼에 대한 쿼리보다 느립니다 — "쿼리 가속화"를 참조하십시오. 또한 구문상 더 복잡하여 작성하기 번거로울 수 있습니다. 이 두 번째 문제를 해결하기 위해 Alias 컬럼 사용을 권장합니다.
ALIAS 컬럼은 쿼리 시점에 계산되며 테이블에 저장되지 않습니다. 따라서 이 타입의 컬럼에 값을 INSERT하는 것은 불가능합니다. Alias 컬럼을 사용하면 맵 키를 참조하고 구문을 단순화하여, 맵 항목을 일반 컬럼처럼 투명하게 노출할 수 있습니다. 다음 예제를 참고하십시오:
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`RequestPath` String MATERIALIZED path(LogAttributes['request_path']),
`RequestType` LowCardinality(String) MATERIALIZED LogAttributes['request_type'],
`RefererDomain` String MATERIALIZED domain(LogAttributes['referer']),
`RemoteAddr` IPv4 ALIAS LogAttributes['remote_addr']
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, Timestamp)
여러 개의 materialized 컬럼과 맵 LogAttributes에 접근하는 ALIAS 컬럼 RemoteAddr가 있습니다. 이제 이 컬럼을 통해 LogAttributes['remote_addr'] 값을 조회할 수 있게 되어 쿼리를 단순화할 수 있습니다. 예를 들면 다음과 같습니다.
SELECT RemoteAddr
FROM default.otel_logs
LIMIT 5
┌─RemoteAddr────┐
│ 54.36.149.41 │
│ 31.56.96.51 │
│ 31.56.96.51 │
│ 40.77.167.129 │
│ 91.99.72.15 │
└───────────────┘
5 rows in set. Elapsed: 0.011 sec.
또한 ALTER TABLE 명령을 통해 ALIAS를 추가하는 것은 매우 간단합니다. 이러한 컬럼은 예를 들어 다음과 같이 즉시 사용할 수 있습니다.
ALTER TABLE default.otel_logs
(ADD COLUMN `Size` String ALIAS LogAttributes['size'])
SELECT Size
FROM default.otel_logs_v3
LIMIT 5
┌─Size──┐
│ 30577 │
│ 5667 │
│ 5379 │
│ 1696 │
│ 41483 │
└───────┘
5 rows in set. Elapsed: 0.014 sec.
기본적으로 ALIAS 제외
기본적으로 SELECT *는 ALIAS 컬럼을 제외합니다. 이 동작은 asterisk_include_alias_columns=1로 설정하면 비활성화됩니다.
타입 최적화
타입 최적화에 대한 일반적인 ClickHouse 모범 사례는 여기에서도 그대로 적용됩니다.
코덱 사용하기
데이터 타입 최적화 외에도, ClickHouse Observability 스키마의 압축을 최적화하려 할 때 코덱에 대한 일반적인 모범 사례를 따를 수 있습니다.
일반적으로 ZSTD 코덱은 로그 및 트레이스 데이터셋에 매우 적합합니다. 기본값인 1에서 압축 수준을 높이면 압축률이 향상될 수 있습니다. 다만, 값이 높아질수록 적재 시 CPU 오버헤드가 커지므로 반드시 테스트해야 합니다. 보통은 이 값을 높여도 이득이 거의 없는 것으로 관찰됩니다.
또한, 타임스탬프는 압축 측면에서는 델타 인코딩의 이점을 누리지만, 이 컬럼을 기본 키 또는 정렬 키로 사용할 경우 쿼리 성능 저하를 유발하는 것으로 나타났습니다. 압축 효율과 쿼리 성능 간의 트레이드오프를 평가할 것을 권장합니다.
딕셔너리 사용하기
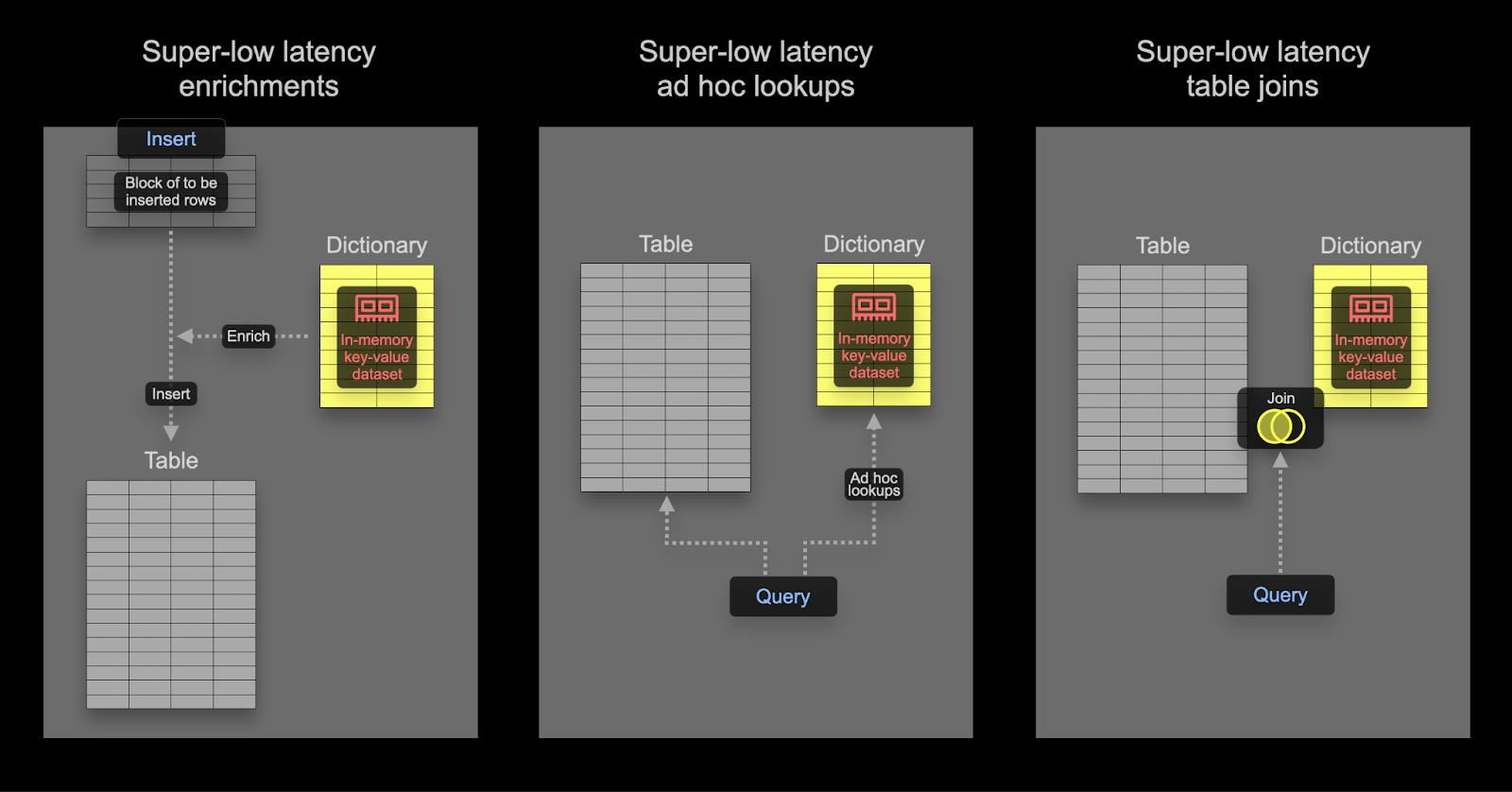
Dictionaries는 ClickHouse의 주요 기능으로, 다양한 내부 및 외부 소스에서 가져온 데이터를 메모리 상의 key-value 형태로 표현하며, 초저지연 조회 쿼리에 최적화되어 있습니다.
이는 수집 프로세스를 지연시키지 않으면서 실시간으로 수집 데이터에 정보를 추가하는 것부터, 전반적인 쿼리 성능을 향상시키는 데까지 다양한 시나리오에서 유용하며, 특히 조인에 큰 이점이 있습니다.
관측성 사용 사례에서는 조인이 자주 필요하지는 않지만, 딕셔너리는 삽입 시점과 쿼리 시점 모두에서 데이터 보강(enrichment) 용도로 여전히 유용하게 사용할 수 있습니다. 아래에 두 가지 모두에 대한 예시를 제공합니다.
조인 가속화
딕셔너리를 사용해 조인을 가속화하는 방법에 대한 자세한 내용은 여기를 참고하십시오.
Insert time vs query time
딕셔너리는 쿼리 시점(query time) 또는 Insert 시점(insert time)에 데이터셋을 보강(enrichment)하는 데 사용할 수 있습니다. 각 접근 방식에는 고유한 장단점이 있습니다. 요약하면 다음과 같습니다:
- Insert time - 보강에 사용할 값이 변경되지 않고, 딕셔너리를 채우는 데 사용할 수 있는 외부 소스에 존재하는 경우에 일반적으로 적합합니다. 이 경우 Insert 시점에 행을 보강하면 쿼리 시점에 딕셔너리를 조회할 필요가 없습니다. 대신 Insert 성능이 저하되고, 보강된 값이 컬럼으로 저장되기 때문에 추가적인 스토리지 오버헤드가 발생합니다.
- Query time - 딕셔너리의 값이 자주 변경되는 경우에는 쿼리 시점 조회가 더 적합한 경우가 많습니다. 이렇게 하면 매핑된 값이 변경될 때 컬럼을 업데이트(및 데이터 재작성)할 필요가 없습니다. 이러한 유연성은 쿼리 시점 조회 비용을 수반합니다. 이 쿼리 시점 비용은 많은 행에 대해 조회가 필요한 경우, 예를 들어 필터 절에서 딕셔너리 조회를 사용할 때 일반적으로 체감될 수 있습니다. 결과 보강, 즉
SELECT에서 사용하는 경우에는 이 오버헤드가 일반적으로 눈에 띄지 않습니다.
딕셔너리의 기본 개념을 먼저 숙지할 것을 권장합니다. 딕셔너리는 전용 함수를 사용하여 값을 조회할 수 있는 인메모리 조회 테이블을 제공합니다.
간단한 보강 예시는 딕셔너리에 대한 가이드 여기를 참고하십시오. 아래에서는 일반적인 관측성 보강 작업에 초점을 맞춥니다.
IP 딕셔너리 사용
IP 주소를 사용해 로그와 트레이스에 위도 및 경도 값을 추가하여 지리 정보를 보강하는 작업은 일반적인 관측성 요구 사항입니다. 이는 구조화된 딕셔너리 유형인 ip_trie를 사용하여 구현할 수 있습니다.
DB-IP.com에서 제공하는 CC BY 4.0 라이선스 조건에 따라 공개된 DB-IP 도시 단위 데이터셋을 사용합니다.
README를 보면, 데이터는 다음과 같이 구조화되어 있음을 알 수 있습니다:
| ip_range_start | ip_range_end | country_code | state1 | state2 | city | postcode | latitude | longitude | timezone |
이 구조를 바탕으로 이제 url() 테이블 함수(table function)를 사용하여 데이터를 간단히 살펴보겠습니다.
SELECT *
FROM url('https://raw.githubusercontent.com/sapics/ip-location-db/master/dbip-city/dbip-city-ipv4.csv.gz', 'CSV', '\n \tip_range_start IPv4, \n \tip_range_end IPv4, \n \tcountry_code Nullable(String), \n \tstate1 Nullable(String), \n \tstate2 Nullable(String), \n \tcity Nullable(String), \n \tpostcode Nullable(String), \n \tlatitude Float64, \n \tlongitude Float64, \n \ttimezone Nullable(String)\n \t')
LIMIT 1
FORMAT Vertical
Row 1:
──────
ip_range_start: 1.0.0.0
ip_range_end: 1.0.0.255
country_code: AU
state1: Queensland
state2: ᴺᵁᴸᴸ
city: South Brisbane
postcode: ᴺᵁᴸᴸ
latitude: -27.4767
longitude: 153.017
timezone: ᴺᵁᴸᴸ
작업을 더 쉽게 하기 위해 URL() 테이블 엔진을 사용하여 필드 이름이 포함된 ClickHouse 테이블 객체를 생성한 다음 전체 행 수를 확인합니다.
CREATE TABLE geoip_url(
ip_range_start IPv4,
ip_range_end IPv4,
country_code Nullable(String),
state1 Nullable(String),
state2 Nullable(String),
city Nullable(String),
postcode Nullable(String),
latitude Float64,
longitude Float64,
timezone Nullable(String)
) ENGINE=URL('https://raw.githubusercontent.com/sapics/ip-location-db/master/dbip-city/dbip-city-ipv4.csv.gz', 'CSV')
select count() from geoip_url;
┌─count()─┐
│ 3261621 │ -- 3.26 million
└─────────┘
ip_trie 딕셔너리는 IP 주소 범위를 CIDR 표기로 표현해야 하므로, ip_range_start와 ip_range_end를 변환해야 합니다.
각 범위에 대한 CIDR은 다음 쿼리로 간단히 계산할 수 있습니다:
WITH
bitXor(ip_range_start, ip_range_end) AS xor,
if(xor != 0, ceil(log2(xor)), 0) AS unmatched,
32 - unmatched AS cidr_suffix,
toIPv4(bitAnd(bitNot(pow(2, unmatched) - 1), ip_range_start)::UInt64) AS cidr_address
SELECT
ip_range_start,
ip_range_end,
concat(toString(cidr_address),'/',toString(cidr_suffix)) AS cidr
FROM
geoip_url
LIMIT 4;
┌─ip_range_start─┬─ip_range_end─┬─cidr───────┐
│ 1.0.0.0 │ 1.0.0.255 │ 1.0.0.0/24 │
│ 1.0.1.0 │ 1.0.3.255 │ 1.0.0.0/22 │
│ 1.0.4.0 │ 1.0.7.255 │ 1.0.4.0/22 │
│ 1.0.8.0 │ 1.0.15.255 │ 1.0.8.0/21 │
└────────────────┴──────────────┴────────────┘
4 rows in set. Elapsed: 0.259 sec.
참고
위 쿼리에서는 여러 단계의 처리가 이루어집니다. 자세한 내용이 궁금하다면 이 훌륭한 설명을 읽으십시오. 그렇지 않다면, 위 쿼리가 IP 범위에 대한 CIDR을 계산한다고 이해하면 됩니다.
이 가이드에서는 IP 범위, 국가 코드, 좌표만 필요하므로 새 테이블을 생성하고 Geo IP 데이터를 삽입하겠습니다:
CREATE TABLE geoip
(
`cidr` String,
`latitude` Float64,
`longitude` Float64,
`country_code` String
)
ENGINE = MergeTree
ORDER BY cidr
INSERT INTO geoip
WITH
bitXor(ip_range_start, ip_range_end) as xor,
if(xor != 0, ceil(log2(xor)), 0) as unmatched,
32 - unmatched as cidr_suffix,
toIPv4(bitAnd(bitNot(pow(2, unmatched) - 1), ip_range_start)::UInt64) as cidr_address
SELECT
concat(toString(cidr_address),'/',toString(cidr_suffix)) as cidr,
latitude,
longitude,
country_code
FROM geoip_url
ClickHouse에서 저지연 IP 조회를 수행하기 위해 Geo IP 데이터를 메모리에 저장하는 딕셔너리를 활용하여 키 -> 속성 매핑을 구성합니다. ClickHouse는 네트워크 프리픽스(CIDR 블록)를 좌표와 국가 코드에 매핑하기 위한 ip_trie 딕셔너리 구조를 제공합니다. 다음 쿼리는 이 구조와 위의 테이블을 소스로 사용하는 딕셔너리를 정의합니다.
CREATE DICTIONARY ip_trie (
cidr String,
latitude Float64,
longitude Float64,
country_code String
)
primary key cidr
source(clickhouse(table 'geoip'))
layout(ip_trie)
lifetime(3600);
딕셔너리에서 행을 선택하여 이 데이터셋을 조회에 사용할 수 있음을 확인합니다:
SELECT * FROM ip_trie LIMIT 3
┌─cidr───────┬─latitude─┬─longitude─┬─country_code─┐
│ 1.0.0.0/22 │ 26.0998 │ 119.297 │ CN │
│ 1.0.0.0/24 │ -27.4767 │ 153.017 │ AU │
│ 1.0.4.0/22 │ -38.0267 │ 145.301 │ AU │
└────────────┴──────────┴───────────┴──────────────┘
3 rows in set. Elapsed: 4.662 sec.
주기적 새로 고침
ClickHouse의 딕셔너리는 기반 테이블 데이터와 위에서 사용한 lifetime 절을 기준으로 주기적으로 갱신됩니다. DB-IP 데이터셋의 최신 변경 사항을 Geo IP 딕셔너리에 반영하려면, geoip_url 원격 테이블에서 변환을 적용한 데이터를 geoip 테이블에 다시 삽입하기만 하면 됩니다.
이제 ip_trie 딕셔너리(편의를 위해 이름도 ip_trie로 지정함)에 Geo IP 데이터를 로드했으므로, 이를 IP 지오로케이션에 사용할 수 있습니다. 이는 다음과 같이 dictGet() function을 사용하여 수행할 수 있습니다:
SELECT dictGet('ip_trie', ('country_code', 'latitude', 'longitude'), CAST('85.242.48.167', 'IPv4')) AS ip_details
┌─ip_details──────────────┐
│ ('PT',38.7944,-9.34284) │
└─────────────────────────┘
1 row in set. Elapsed: 0.003 sec.
여기에서 조회 속도에 주목하십시오. 이를 통해 로그를 보강(enrich)할 수 있습니다. 이 경우 쿼리 시점 보강(query time enrichment)을 수행하는 방식을 선택합니다.
다시 원래 로그 데이터셋으로 돌아가서, 위 내용을 사용해 국가별로 로그를 집계할 수 있습니다. 다음 예시는 앞서 사용한 materialized view에서 생성된 스키마를 사용하며, 여기에는 추출된 RemoteAddress 컬럼이 있다고 가정합니다.
SELECT dictGet('ip_trie', 'country_code', tuple(RemoteAddress)) AS country,
formatReadableQuantity(count()) AS num_requests
FROM default.otel_logs_v2
WHERE country != ''
GROUP BY country
ORDER BY count() DESC
LIMIT 5
┌─country─┬─num_requests────┐
│ IR │ 7.36 million │
│ US │ 1.67 million │
│ AE │ 526.74 thousand │
│ DE │ 159.35 thousand │
│ FR │ 109.82 thousand │
└─────────┴─────────────────┘
5 rows in set. Elapsed: 0.140 sec. Processed 20.73 million rows, 82.92 MB (147.79 million rows/s., 591.16 MB/s.)
Peak memory usage: 1.16 MiB.
IP에서 지리적 위치로의 매핑은 변경될 수 있으므로, 사용자는 동일한 주소에 대한 현재 지리적 위치가 아니라 요청이 발생한 당시 어느 위치에서 요청이 발생했는지 알고자 하는 경우가 많습니다. 이러한 이유로 인덱싱 시점의 enrichment를 사용하는 것이 더 적합합니다. 이는 아래에 나오는 것처럼 materialized 컬럼을 사용하거나 materialized view의 SELECT 절에서 수행할 수 있습니다.
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
`Country` String MATERIALIZED dictGet('ip_trie', 'country_code', tuple(RemoteAddress)),
`Latitude` Float32 MATERIALIZED dictGet('ip_trie', 'latitude', tuple(RemoteAddress)),
`Longitude` Float32 MATERIALIZED dictGet('ip_trie', 'longitude', tuple(RemoteAddress))
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
주기적으로 업데이트
사용자는 새로운 데이터를 기반으로 IP 보강용 딕셔너리를 주기적으로 업데이트하기를 원하는 경우가 많습니다. 이는 딕셔너리의 LIFETIME 절을 사용하여 구현할 수 있으며, 이 절은 딕셔너리가 기반 테이블에서 주기적으로 다시 로드되도록 합니다. 기반 테이블을 업데이트하는 방법은 "갱신 가능 구체화 뷰"를 참조하십시오.
위에서 언급한 국가 및 좌표 데이터는 국가별 그룹화와 필터링을 넘어서는 시각화 기능을 제공합니다. 아이디어가 필요하다면 "Visualizing geo data"를 참고하십시오.
정규식 딕셔너리 사용하기 (user agent 파싱)
User agent 문자열의 파싱은 고전적인 정규 표현식 문제로, 로그 및 트레이스 기반 데이터셋에서 흔히 요구되는 작업입니다. ClickHouse는 Regular Expression Tree 딕셔너리를 사용하여 user agent를 효율적으로 파싱합니다.
정규 표현식 트리 딕셔너리는 ClickHouse 오픈 소스에서 YAMLRegExpTree 딕셔너리 소스 타입을 사용해 정의되며, 정규 표현식 트리가 포함된 YAML 파일의 경로를 지정합니다. 사용자 정의 정규 표현식 딕셔너리를 사용하려는 경우, 필요한 구조에 대한 자세한 내용은 여기에서 확인할 수 있습니다. 아래에서는 uap-core를 사용한 user agent 파싱에 초점을 맞추고, 지원되는 CSV 형식으로 딕셔너리를 로드합니다. 이 접근 방식은 OSS와 ClickHouse Cloud 모두에서 호환됩니다.
참고
아래 예제에서는 2024년 6월 기준 최신 uap-core user agent 파싱용 정규 표현식 스냅샷을 사용합니다. 가끔씩 업데이트되는 최신 파일은 여기에서 확인할 수 있습니다. 아래에서 사용하는 CSV 파일로 로드하려면 여기의 단계를 따르면 됩니다.
다음 Memory 테이블을 생성하십시오. 이 테이블들은 디바이스, 브라우저 및 운영 체제를 파싱하기 위한 정규 표현식을 저장합니다.
CREATE TABLE regexp_os
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
CREATE TABLE regexp_browser
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
CREATE TABLE regexp_device
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
이 테이블들은 url 테이블 함수를 사용하여 아래의 공개적으로 호스팅된 CSV 파일에서 데이터를 채울 수 있습니다.
INSERT INTO regexp_os SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_os.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
INSERT INTO regexp_device SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_device.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
INSERT INTO regexp_browser SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_browser.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
메모리 테이블에 데이터가 채워졌으므로 정규 표현식(Regular Expression) 딕셔너리를 로드할 수 있습니다. 키 값은 컬럼으로 지정해야 합니다. 이 컬럼들이 user agent에서 추출할 수 있는 속성이 됩니다.
CREATE DICTIONARY regexp_os_dict
(
regexp String,
os_replacement String default 'Other',
os_v1_replacement String default '0',
os_v2_replacement String default '0',
os_v3_replacement String default '0',
os_v4_replacement String default '0'
)
PRIMARY KEY regexp
SOURCE(CLICKHOUSE(TABLE 'regexp_os'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(REGEXP_TREE);
CREATE DICTIONARY regexp_device_dict
(
regexp String,
device_replacement String default 'Other',
brand_replacement String,
model_replacement String
)
PRIMARY KEY(regexp)
SOURCE(CLICKHOUSE(TABLE 'regexp_device'))
LIFETIME(0)
LAYOUT(regexp_tree);
CREATE DICTIONARY regexp_browser_dict
(
regexp String,
family_replacement String default 'Other',
v1_replacement String default '0',
v2_replacement String default '0'
)
PRIMARY KEY(regexp)
SOURCE(CLICKHOUSE(TABLE 'regexp_browser'))
LIFETIME(0)
LAYOUT(regexp_tree);
이 딕셔너리들을 로드했으면 예시 user-agent를 사용해 새로운 딕셔너리 추출 기능을 테스트할 수 있습니다:
WITH 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:127.0) Gecko/20100101 Firefox/127.0' AS user_agent
SELECT
dictGet('regexp_device_dict', ('device_replacement', 'brand_replacement', 'model_replacement'), user_agent) AS device,
dictGet('regexp_browser_dict', ('family_replacement', 'v1_replacement', 'v2_replacement'), user_agent) AS browser,
dictGet('regexp_os_dict', ('os_replacement', 'os_v1_replacement', 'os_v2_replacement', 'os_v3_replacement'), user_agent) AS os
┌─device────────────────┬─browser───────────────┬─os─────────────────────────┐
│ ('Mac','Apple','Mac') │ ('Firefox','127','0') │ ('Mac OS X','10','15','0') │
└───────────────────────┴───────────────────────┴────────────────────────────┘
1 row in set. Elapsed: 0.003 sec.
사용자 에이전트에 대한 규칙은 거의 변경되지 않고, 딕셔너리는 새로운 브라우저, 운영 체제, 디바이스가 등장할 때만 업데이트하면 되므로, 이 추출 작업을 삽입 시점에 수행하는 것이 합리적입니다.
이 작업은 materialized 컬럼 또는 materialized view를 사용해 수행할 수 있습니다. 아래에서는 앞에서 사용한 materialized view를 수정합니다.
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2
AS SELECT
Body,
CAST(Timestamp, 'DateTime') AS Timestamp,
ServiceName,
LogAttributes['status'] AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(CAST(Status, 'UInt64') > 500, 'CRITICAL', CAST(Status, 'UInt64') > 400, 'ERROR', CAST(Status, 'UInt64') > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(CAST(Status, 'UInt64') > 500, 20, CAST(Status, 'UInt64') > 400, 17, CAST(Status, 'UInt64') > 300, 13, 9) AS SeverityNumber,
dictGet('regexp_device_dict', ('device_replacement', 'brand_replacement', 'model_replacement'), UserAgent) AS Device,
dictGet('regexp_browser_dict', ('family_replacement', 'v1_replacement', 'v2_replacement'), UserAgent) AS Browser,
dictGet('regexp_os_dict', ('os_replacement', 'os_v1_replacement', 'os_v2_replacement', 'os_v3_replacement'), UserAgent) AS Os
FROM otel_logs
이를 위해 대상 테이블 otel_logs_v2의 스키마를 수정해야 합니다:
CREATE TABLE default.otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt8,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`remote_addr` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
`Device` Tuple(device_replacement LowCardinality(String), brand_replacement LowCardinality(String), model_replacement LowCardinality(String)),
`Browser` Tuple(family_replacement LowCardinality(String), v1_replacement LowCardinality(String), v2_replacement LowCardinality(String)),
`Os` Tuple(os_replacement LowCardinality(String), os_v1_replacement LowCardinality(String), os_v2_replacement LowCardinality(String), os_v3_replacement LowCardinality(String))
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp, Status)
수집기를 다시 시작하고 앞에서 설명한 단계에 따라 구조화된 로그를 수집한 후, 새로 추출된 Device, Browser, Os 컬럼에 대해 쿼리를 실행할 수 있습니다.
SELECT Device, Browser, Os
FROM otel_logs_v2
LIMIT 1
FORMAT Vertical
Row 1:
──────
Device: ('Spider','Spider','Desktop')
Browser: ('AhrefsBot','6','1')
Os: ('Other','0','0','0')
복잡한 구조를 위한 Tuple
이 사용자 에이전트 컬럼들에 Tuple을 사용한다는 점에 유의하십시오. Tuple은 계층 구조가 미리 정의된 복잡한 구조에 사용하는 것이 좋습니다. 하위 컬럼은 이종 타입을 허용하면서도 일반 컬럼과 동일한 성능을 제공하며, Map 키는 그렇지 않습니다.
추가로 읽어볼 자료
딕셔너리에 대한 더 많은 예제와 자세한 설명은 다음 문서를 참고하십시오:
쿼리 가속화
ClickHouse는 쿼리 성능을 가속화하기 위한 여러 기법을 지원합니다. 다음에서 설명하는 기법들은, 가장 일반적인 쿼리/접근 패턴에 최적화하고 압축률을 극대화하기 위해 적절한 기본/정렬 키를 먼저 선택한 이후에만 고려해야 합니다. 대부분의 경우 이러한 키 선택이 가장 적은 노력으로 가장 큰 성능 향상을 제공합니다.
집계에 Materialized View(구체화된 뷰, 증분 방식) 사용하기
앞선 섹션에서 데이터 변환과 필터링을 위해 Materialized View(구체화된 뷰)를 사용하는 방법을 살펴보았습니다. 하지만 Materialized View는 삽입 시점에 집계를 미리 수행하고 그 결과를 저장하는 용도로도 사용할 수 있습니다. 이 결과는 이후에 삽입되는 데이터의 집계 결과로 갱신될 수 있으며, 이를 통해 집계를 삽입 시점에 미리 계산해 둘 수 있습니다.
여기서 핵심 개념은 결과가 종종 원본 데이터보다 더 작은 표현(집계의 경우에는 부분 스케치 형태)이 된다는 점입니다. 대상 테이블에서 결과를 읽기 위한 더 단순한 쿼리와 결합하면, 동일한 연산을 원본 데이터에 수행할 때보다 쿼리 시간이 더 빨라집니다.
다음은 구조화된 로그를 사용하여 시간당 전체 트래픽을 계산하는 쿼리입니다:
SELECT toStartOfHour(Timestamp) AS Hour,
sum(toUInt64OrDefault(LogAttributes['size'])) AS TotalBytes
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.666 sec. Processed 10.37 million rows, 4.73 GB (15.56 million rows/s., 7.10 GB/s.)
Peak memory usage: 1.40 MiB.
Grafana로 사용자들이 자주 그리는 일반적인 선 차트를 떠올릴 수 있습니다. 이 쿼리는 사실 매우 빠릅니다. 데이터셋이 1천만 행에 불과하고 ClickHouse는 빠르기 때문입니다. 그러나 이를 수십억, 수조 행까지 확장하더라도, 이상적으로는 이 쿼리 성능을 계속 유지하고자 합니다.
참고
이 쿼리는 이전에 정의한 materialized view에서 생성된 결과 테이블인 otel_logs_v2 테이블을 사용하면 10배 더 빨라집니다. 이 materialized view는 LogAttributes 맵에서 size 키를 추출합니다. 여기서는 설명을 위한 목적으로 원시 데이터를 사용하며, 이 쿼리가 자주 사용되는 쿼리라면 앞서 만든 materialized view를 사용할 것을 권장합니다.
구체화된 뷰(materialized view)를 사용해 삽입 시점에 이를 계산하려면, 결과를 저장할 테이블이 필요합니다. 이 테이블은 1시간당 1개의 행만 유지해야 합니다. 기존 시간대에 대한 업데이트가 수신되면, 다른 컬럼들은 기존 시간대 행에 병합되어야 합니다. 이러한 증분 상태 병합이 일어나려면, 다른 컬럼들에 대해 부분 상태(partial state)가 저장되어야 합니다.
이를 위해서는 ClickHouse에서 특별한 엔진 타입이 필요합니다. 바로 SummingMergeTree입니다. 이 엔진은 동일한 정렬 키를 가진 모든 행을 하나의 행으로 대체하며, 그 행에는 숫자 컬럼의 합산 값이 저장됩니다. 아래 테이블은 동일한 날짜를 가진 모든 행을 병합하며, 모든 숫자 컬럼을 합산합니다.
CREATE TABLE bytes_per_hour
(
`Hour` DateTime,
`TotalBytes` UInt64
)
ENGINE = SummingMergeTree
ORDER BY Hour
materialized view를 보여 주기 위해, bytes_per_hour 테이블이 비어 있고 아직 어떤 데이터도 수신하지 않은 상태라고 가정합니다. 이 materialized view는 otel_logs에 삽입되는 데이터에 대해 위의 SELECT를 수행하며(이는 설정된 크기의 블록 단위로 수행됩니다), 그 결과를 bytes_per_hour로 전송합니다. 구문은 아래와 같습니다:
CREATE MATERIALIZED VIEW bytes_per_hour_mv TO bytes_per_hour AS
SELECT toStartOfHour(Timestamp) AS Hour,
sum(toUInt64OrDefault(LogAttributes['size'])) AS TotalBytes
FROM otel_logs
GROUP BY Hour
여기에서 TO 절은 결과를 어디로 전송할지 지정하는 핵심 요소로, 이 경우 bytes_per_hour를 의미합니다.
OTel collector를 재시작한 후 로그를 다시 전송하면, 위 쿼리 결과가 bytes_per_hour 테이블에 증분 방식으로 채워집니다. 처리가 완료되면 bytes_per_hour의 크기를 확인할 수 있으며, 매 시간당 1개의 행이 있어야 합니다:
SELECT count()
FROM bytes_per_hour
FINAL
┌─count()─┐
│ 113 │
└─────────┘
1 row in set. Elapsed: 0.039 sec.
otel_logs에서 1천만 개의 행을 사용하던 것을, 쿼리 결과를 저장함으로써 효과적으로 113개로 줄였습니다. 여기서 핵심은 새로운 로그가 otel_logs 테이블에 삽입되면, 해당 로그가 속한 시간대(시간 단위)에 대한 새로운 값이 bytes_per_hour에 기록되고, 백그라운드에서 비동기적으로 자동 병합된다는 점입니다. 이렇게 시간당 하나의 행만 유지함으로써 bytes_per_hour는 항상 작고 최신 상태를 유지합니다.
행 병합이 비동기적으로 이루어지므로, 사용자가 쿼리를 실행할 때 시간당 하나 이상의 행이 존재할 수 있습니다. 쿼리 시점에 아직 병합되지 않은 행들을 병합하려면 두 가지 옵션이 있습니다:
- 테이블 이름에
FINAL 수정자를 사용합니다(위의 count 쿼리에서 사용한 방식).
- 최종 테이블에서 사용한 정렬 키(예: Timestamp)로 집계하고, 메트릭을 합산합니다.
일반적으로 두 번째 옵션이 더 효율적이고 유연합니다(테이블을 다른 용도로도 사용할 수 있음). 하지만 첫 번째 옵션이 일부 쿼리에는 더 단순할 수 있습니다. 아래에서 두 가지 모두를 보여줍니다:
SELECT
Hour,
sum(TotalBytes) AS TotalBytes
FROM bytes_per_hour
GROUP BY Hour
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.008 sec.
SELECT
Hour,
TotalBytes
FROM bytes_per_hour
FINAL
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.005 sec.
이제 쿼리 성능이 0.6초에서 0.008초로 단축되어 75배 이상 빨라졌습니다!
참고
데이터셋이 더 크고 쿼리가 더 복잡할수록 성능 향상 효과는 더욱 커질 수 있습니다. 예제는 여기를 참고하십시오.
더 복잡한 예시
위 예제는 SummingMergeTree를 사용하여 시간당 단순 개수를 집계합니다. 단순 합계를 넘어서는 통계를 계산하려면 다른 대상 테이블 엔진이 필요합니다. 바로 AggregatingMergeTree입니다.
예를 들어 일별로 고유 IP 주소(또는 고유 사용자) 개수를 계산하려고 한다고 가정합니다. 이를 위한 쿼리는 다음과 같습니다.
SELECT toStartOfHour(Timestamp) AS Hour, uniq(LogAttributes['remote_addr']) AS UniqueUsers
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
┌────────────────Hour─┬─UniqueUsers─┐
│ 2019-01-26 16:00:00 │ 4763 │
│ 2019-01-22 00:00:00 │ 536 │
└─────────────────────┴─────────────┘
113 rows in set. Elapsed: 0.667 sec. Processed 10.37 million rows, 4.73 GB (15.53 million rows/s., 7.09 GB/s.)
증분 업데이트 시 카디널리티 카운트 값을 영속적으로 저장하려면 AggregatingMergeTree가 필요합니다.
CREATE TABLE unique_visitors_per_hour
(
`Hour` DateTime,
`UniqueUsers` AggregateFunction(uniq, IPv4)
)
ENGINE = AggregatingMergeTree
ORDER BY Hour
집계 상태가 저장될 것임을 ClickHouse에 알리기 위해 UniqueUsers 컬럼을 타입 AggregateFunction으로 정의하고, 부분 상태의 원본 함수(uniq)와 원본 컬럼의 타입(IPv4)을 지정합니다. SummingMergeTree와 마찬가지로, 동일한 ORDER BY 키 값을 가진 행은 병합됩니다(위 예시에서는 Hour 기준).
연관된 materialized view는 앞에서 사용한 쿼리를 사용합니다:
CREATE MATERIALIZED VIEW unique_visitors_per_hour_mv TO unique_visitors_per_hour AS
SELECT toStartOfHour(Timestamp) AS Hour,
uniqState(LogAttributes['remote_addr']::IPv4) AS UniqueUsers
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
집계 함수 이름 끝에 접미사 State를 추가하는 방식에 주목하십시오. 이렇게 하면 최종 결과 대신 함수의 집계 상태가 반환되도록 보장합니다. 이 상태에는 이 부분 상태가 다른 상태들과 병합될 수 있도록 하는 추가 정보가 포함됩니다.
Collector를 재시작하여 데이터를 다시 로드한 후에는 unique_visitors_per_hour 테이블에 113개의 행이 있음을 확인할 수 있습니다.
SELECT count()
FROM unique_visitors_per_hour
FINAL
┌─count()─┐
│ 113 │
└─────────┘
1 row in set. Elapsed: 0.009 sec.
최종 쿼리에서는 함수에 Merge 접미사를 사용해야 합니다(컬럼에 부분 집계 상태가 저장되기 때문입니다).
SELECT Hour, uniqMerge(UniqueUsers) AS UniqueUsers
FROM unique_visitors_per_hour
GROUP BY Hour
ORDER BY Hour DESC
┌────────────────Hour─┬─UniqueUsers─┐
│ 2019-01-26 16:00:00 │ 4763 │
│ 2019-01-22 00:00:00 │ 536 │
└─────────────────────┴─────────────┘
113 rows in set. Elapsed: 0.027 sec.
여기에서는 FINAL 대신 GROUP BY를 사용한다는 점에 유의하십시오.
빠른 조회를 위한 Materialized view(증분 방식) 사용
ClickHouse 정렬 키를 선택할 때는 필터 및 집계 절에서 자주 사용되는 컬럼과 함께 접근 패턴을 고려해야 합니다. 관측성 사용 사례에서는 단일 컬럼 집합으로는 다양한 접근 패턴을 모두 포괄하기 어렵기 때문에, 이는 제약이 될 수 있습니다. 이는 기본 OTel 스키마에 포함된 예제를 통해 가장 잘 설명할 수 있습니다. traces에 대한 기본 스키마를 살펴보십시오:
CREATE TABLE otel_traces
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`TraceState` String CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`Duration` Int64 CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
`StatusMessage` String CODEC(ZSTD(1)),
`Events.Timestamp` Array(DateTime64(9)) CODEC(ZSTD(1)),
`Events.Name` Array(LowCardinality(String)) CODEC(ZSTD(1)),
`Events.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
`Links.TraceId` Array(String) CODEC(ZSTD(1)),
`Links.SpanId` Array(String) CODEC(ZSTD(1)),
`Links.TraceState` Array(String) CODEC(ZSTD(1)),
`Links.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
이 스키마는 ServiceName, SpanName, Timestamp로 필터링할 때 최적화되어 있습니다. 트레이싱에서는 특정 TraceId로 조회하고, 해당 트레이스에 속한 span들을 조회할 수 있는 기능도 필요합니다. 이는 ordering key에 포함되어 있지만 끝에 위치해 있어 필터링 효율이 떨어지며, 단일 트레이스를 조회할 때 상당한 양의 데이터를 스캔해야 할 가능성이 큽니다.
OTel collector는 이 문제를 해결하기 위해 materialized view와 연관된 테이블도 함께 설치합니다. 해당 테이블과 view는 다음과 같습니다.
CREATE TABLE otel_traces_trace_id_ts
(
`TraceId` String CODEC(ZSTD(1)),
`Start` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`End` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.01) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY (TraceId, toUnixTimestamp(Start))
CREATE MATERIALIZED VIEW otel_traces_trace_id_ts_mv TO otel_traces_trace_id_ts
(
`TraceId` String,
`Start` DateTime64(9),
`End` DateTime64(9)
)
AS SELECT
TraceId,
min(Timestamp) AS Start,
max(Timestamp) AS End
FROM otel_traces
WHERE TraceId != ''
GROUP BY TraceId
이 뷰는 테이블 otel_traces_trace_id_ts가 각 트레이스에 대한 최소 및 최대 타임스탬프를 갖도록 효과적으로 보장합니다. 이 테이블은 TraceId로 정렬되어 있어 이러한 타임스탬프를 효율적으로 조회할 수 있습니다. 이렇게 얻은 타임스탬프 범위는 주요 otel_traces 테이블을 쿼리할 때 활용할 수 있습니다. 보다 구체적으로, 트레이스를 ID로 조회할 때 Grafana는 다음 쿼리를 사용합니다:
WITH 'ae9226c78d1d360601e6383928e4d22d' AS trace_id,
(
SELECT min(Start)
FROM default.otel_traces_trace_id_ts
WHERE TraceId = trace_id
) AS trace_start,
(
SELECT max(End) + 1
FROM default.otel_traces_trace_id_ts
WHERE TraceId = trace_id
) AS trace_end
SELECT
TraceId AS traceID,
SpanId AS spanID,
ParentSpanId AS parentSpanID,
ServiceName AS serviceName,
SpanName AS operationName,
Timestamp AS startTime,
Duration * 0.000001 AS duration,
arrayMap(key -> map('key', key, 'value', SpanAttributes[key]), mapKeys(SpanAttributes)) AS tags,
arrayMap(key -> map('key', key, 'value', ResourceAttributes[key]), mapKeys(ResourceAttributes)) AS serviceTags
FROM otel_traces
WHERE (traceID = trace_id) AND (startTime >= trace_start) AND (startTime <= trace_end)
LIMIT 1000
여기에서 CTE는 trace id ae9226c78d1d360601e6383928e4d22d에 대한 최소/최대 타임스탬프를 먼저 식별한 후, 이를 사용하여 관련 span이 포함된 메인 otel_traces를 필터링합니다.
이와 같은 접근 방식은 유사한 조회 패턴에도 적용할 수 있습니다. Data Modeling 섹션에서 여기와 같이 유사한 예제를 살펴봅니다.
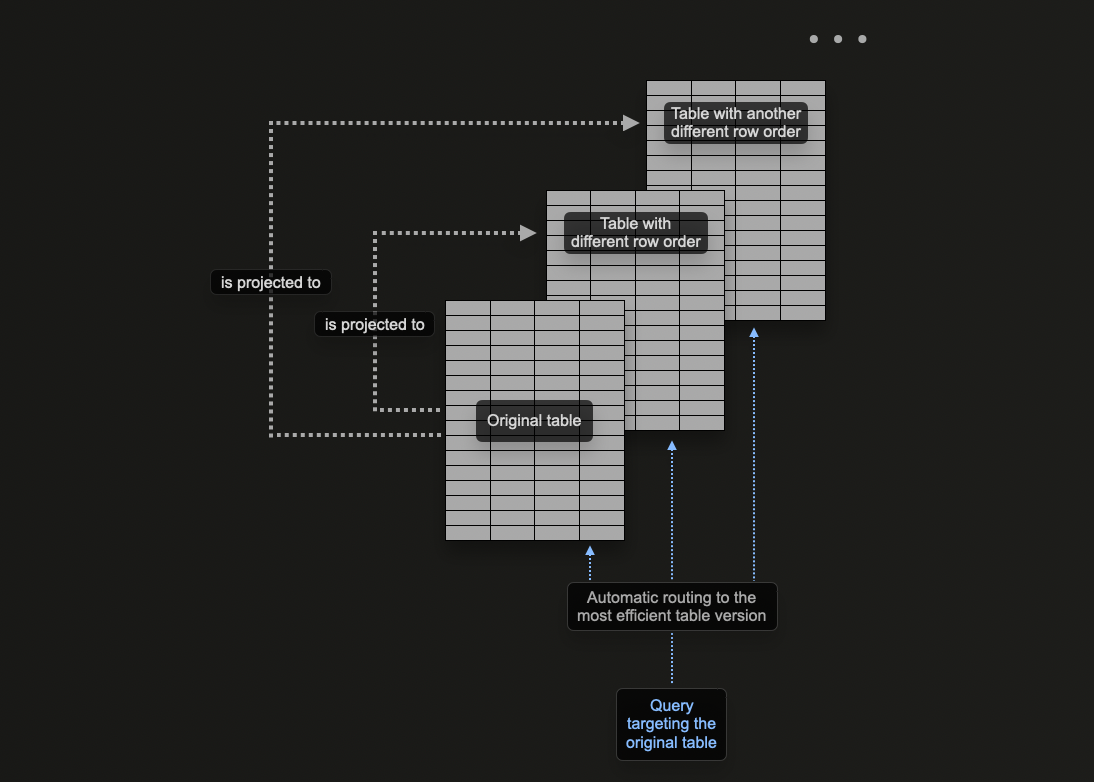
프로젝션 사용
ClickHouse 프로젝션을 사용하면 테이블에 여러 ORDER BY 절을 지정할 수 있습니다.
이전 섹션에서는 ClickHouse에서 materialized view를 사용하여 집계를 사전 계산하고, 행을 변환하며, 다양한 액세스 패턴에 대한 관측성 쿼리를 최적화하는 방법을 살펴보았습니다.
materialized view가 삽입을 받는 원본 테이블과 다른 정렬 키를 가진 대상 테이블로 행을 전송하여 trace id로 조회를 최적화하는 예제를 제공합니다.
프로젝션을 사용하면 동일한 문제를 해결할 수 있으며, 기본 키의 일부가 아닌 컬럼에 대한 쿼리를 최적화할 수 있습니다.
이론적으로 이 기능은 테이블에 여러 정렬 키를 제공하는 데 사용할 수 있지만, 한 가지 명확한 단점이 있습니다: 데이터 중복입니다. 구체적으로, 데이터는 메인 기본 키의 순서로 작성되어야 할 뿐만 아니라 각 PROJECTION에 지정된 순서로도 작성되어야 합니다. 이는 삽입 속도를 저하시키고 더 많은 디스크 공간을 소비하게 됩니다.
프로젝션 vs Materialized View
프로젝션은 materialized view와 유사한 기능을 다수 제공하지만, 제한적으로 사용해야 하며 일반적으로 materialized view가 더 선호됩니다. 각각의 단점과 적절한 사용 시점을 이해하십시오. 예를 들어, 프로젝션을 사전 집계 계산에 사용할 수 있지만, 이러한 용도로는 materialized view를 사용하는 것을 권장합니다.
다음 쿼리를 고려하십시오. 이 쿼리는 otel_logs_v2 테이블을 500 에러 코드로 필터링합니다. 이는 에러 코드로 필터링하고자 하는 로깅의 일반적인 접근 패턴입니다:
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
FROM otel_logs_v2
WHERE Status = 500
FORMAT `Null`
Ok.
0 rows in set. Elapsed: 0.177 sec. Processed 10.37 million rows, 685.32 MB (58.66 million rows/s., 3.88 GB/s.)
Peak memory usage: 56.54 MiB.
성능 측정을 위한 Null 사용
여기서는 FORMAT Null을 사용하여 결과를 출력하지 않습니다. 이를 통해 모든 결과를 읽되 반환하지 않으므로 LIMIT로 인한 쿼리의 조기 종료를 방지합니다. 이는 1,000만 개의 행을 스캔하는 데 걸리는 시간을 보여주기 위한 것입니다.
위 쿼리는 선택한 정렬 키 (ServiceName, Timestamp)를 사용하여 선형 스캔을 수행합니다. 정렬 키 끝에 Status를 추가하면 위 쿼리의 성능을 개선할 수 있지만, PROJECTION을 추가하는 방법도 있습니다.
ALTER TABLE otel_logs_v2 (
ADD PROJECTION status
(
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent ORDER BY Status
)
)
ALTER TABLE otel_logs_v2 MATERIALIZE PROJECTION status
먼저 PROJECTION을 생성한 다음 구체화해야 합니다. 이 후자의 명령은 데이터를 디스크에 두 가지 다른 순서로 두 번 저장합니다. PROJECTION은 아래와 같이 데이터 생성 시 정의할 수도 있으며, 데이터가 삽입될 때 자동으로 유지됩니다.
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
PROJECTION status
(
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
ORDER BY Status
)
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
중요한 점은, ALTER를 통해 프로젝션(PROJECTION)을 생성하는 경우 MATERIALIZE PROJECTION 명령이 실행될 때 생성이 비동기적으로 이루어진다는 것입니다. 다음 쿼리를 사용하여 이 작업의 진행 상황을 확인할 수 있으며, is_done=1이 될 때까지 기다리세요.
SELECT parts_to_do, is_done, latest_fail_reason
FROM system.mutations
WHERE (`table` = 'otel_logs_v2') AND (command LIKE '%MATERIALIZE%')
┌─parts_to_do─┬─is_done─┬─latest_fail_reason─┐
│ 0 │ 1 │ │
└─────────────┴─────────┴────────────────────┘
1 row in set. Elapsed: 0.008 sec.
위의 쿼리를 반복하면 추가 스토리지를 사용하는 대신 성능이 크게 향상된 것을 확인할 수 있습니다(측정 방법은 "테이블 크기 및 압축 측정"을 참조하세요).
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
FROM otel_logs_v2
WHERE Status = 500
FORMAT `Null`
0 rows in set. Elapsed: 0.031 sec. Processed 51.42 thousand rows, 22.85 MB (1.65 million rows/s., 734.63 MB/s.)
Peak memory usage: 27.85 MiB.
위 예시에서는 프로젝션에 앞선 쿼리에서 사용된 컬럼들을 지정합니다. 이렇게 하면 지정된 컬럼들만 프로젝션의 일부로 디스크에 저장되며, Status 기준으로 정렬됩니다. 반대로 여기에서 SELECT *를 사용하면 모든 컬럼이 저장됩니다. 이렇게 하면 더 많은 쿼리(임의의 컬럼 부분집합을 사용하는 쿼리)가 프로젝션의 이점을 얻을 수 있지만, 추가 디스크 공간이 필요합니다. 디스크 사용량과 압축을 측정하려면 "테이블 크기 및 압축 측정"을 참조하십시오.
보조/데이터 스키핑 인덱스
ClickHouse에서 기본 키를 아무리 잘 튜닝해도, 일부 쿼리는 필연적으로 전체 테이블 스캔이 필요합니다. 이는 구체화된 뷰(Materialized View)(및 일부 쿼리에서는 프로젝션)를 사용하여 완화할 수 있지만, 이러한 방법은 추가적인 유지 관리가 필요하며, 이를 활용하려면 사용자가 해당 기능의 존재를 인지하고 있어야 합니다. 전통적인 관계형 데이터베이스에서는 보조 인덱스를 통해 이 문제를 해결하지만, 이러한 방식은 ClickHouse와 같은 컬럼 지향 데이터베이스에서는 효과적이지 않습니다. 대신 ClickHouse는 「Skip 인덱스」를 사용하여 매칭되는 값이 전혀 없는 대용량 데이터 청크를 건너뛰도록 함으로써 쿼리 성능을 크게 향상시킵니다.
기본 OTel 스키마는 맵 접근을 가속화하려는 시도로 보조 인덱스를 사용합니다. 일반적으로 이러한 방식은 효과가 크지 않다고 판단하며, 사용자 정의 스키마에 그대로 복사할 것을 권장하지는 않습니다. 그러나 스키핑 인덱스 자체는 여전히 유용할 수 있습니다.
스키핑 인덱스를 적용하기 전에 보조 인덱스(스키핑 인덱스) 가이드를 반드시 읽고 이해해야 합니다.
일반적으로, 기본 키와 대상이 되는 비기본 컬럼/식 사이에 강한 상관관계가 존재하고, 드문 값(즉, 많은 그래뉼에 나타나지 않는 값)을 조회할 때 효과적입니다.
텍스트 검색을 위한 블룸 필터
관측성(Observability) 쿼리에서 텍스트 검색이 필요할 때는 보조 인덱스를 활용할 수 있습니다. 구체적으로, ngram 및 토큰 기반 블룸 필터 인덱스인 ngrambf_v1와 tokenbf_v1을 사용하면 LIKE, IN, hasToken 연산자를 사용하는 String 컬럼 검색을 가속화할 수 있습니다. 중요한 점은, 토큰 기반 인덱스가 비영숫자(non-alphanumeric) 문자를 구분자로 사용해 토큰을 생성한다는 것입니다. 이는 쿼리 시점에 오직 토큰(또는 전체 단어)만 일치시킬 수 있음을 의미합니다. 더 세밀한 매칭이 필요하면 N-gram 블룸 필터를 사용할 수 있습니다. 이 필터는 문자열을 지정된 크기의 ngram으로 분할하여 단어 일부에 대한 매칭도 가능하게 합니다.
쿼리에서 생성·매칭될 토큰을 확인하려면 tokens 함수를 사용할 수 있습니다:
SELECT tokens('https://www.zanbil.ir/m/filter/b113')
┌─tokens────────────────────────────────────────────┐
│ ['https','www','zanbil','ir','m','filter','b113'] │
└───────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.008 sec.
ngram 함수도 두 번째 파라미터로 ngram 크기를 지정할 수 있어 유사한 기능을 제공합니다:
SELECT ngrams('https://www.zanbil.ir/m/filter/b113', 3)
┌─ngrams('https://www.zanbil.ir/m/filter/b113', 3)────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ ['htt','ttp','tps','ps:','s:/','://','//w','/ww','www','ww.','w.z','.za','zan','anb','nbi','bil','il.','l.i','.ir','ir/','r/m','/m/','m/f','/fi','fil','ilt','lte','ter','er/','r/b','/b1','b11','113'] │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.008 sec.
역 인덱스
ClickHouse에는 보조 인덱스로서 역 인덱스를 실험적으로 지원합니다. 현재로서는 로그 데이터셋에서는 사용을 권장하지 않지만, 프로덕션 환경에서 사용할 준비가 되면 토큰 기반 블룸 필터를 대체할 것으로 예상합니다.
이 예제에서는 구조화된 로그 데이터셋을 사용합니다. Referer 컬럼에 ultra가 포함된 로그의 개수를 세고자 한다고 가정합니다.
SELECT count()
FROM otel_logs_v2
WHERE Referer LIKE '%ultra%'
┌─count()─┐
│ 114514 │
└─────────┘
1 row in set. Elapsed: 0.177 sec. Processed 10.37 million rows, 908.49 MB (58.57 million rows/s., 5.13 GB/s.)
여기서는 ngram 크기를 3으로 맞춰야 합니다. 따라서 ngrambf_v1 인덱스를 생성합니다.
CREATE TABLE otel_logs_bloom
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
INDEX idx_span_attr_value Referer TYPE ngrambf_v1(3, 10000, 3, 7) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY (Timestamp)
여기에서 인덱스 ngrambf_v1(3, 10000, 3, 7)는 네 개의 매개변수를 사용합니다. 이 중 마지막 값(7)은 시드를 의미합니다. 나머지는 n그램 크기(3), 값 m(필터 크기), 해시 함수 개수 k(7)를 나타냅니다. k와 m은 튜닝이 필요하며, 고유 n그램/토큰의 개수와 필터가 참 음성 결과를 반환할 확률, 즉 특정 값이 granule에 존재하지 않음을 확인하는 확률에 따라 결정됩니다. 이러한 값을 설정하는 데는 이 함수들을 사용하는 것을 권장합니다.
적절히 튜닝하면 쿼리 속도 향상이 상당할 수 있습니다.
SELECT count()
FROM otel_logs_bloom
WHERE Referer LIKE '%ultra%'
┌─count()─┐
│ 182 │
└─────────┘
1 row in set. Elapsed: 0.077 sec. Processed 4.22 million rows, 375.29 MB (54.81 million rows/s., 4.87 GB/s.)
Peak memory usage: 129.60 KiB.
예시 전용
위 내용은 설명을 위한 예시일 뿐입니다. 토큰 기반 블룸 필터로 텍스트 검색을 최적화하려 하기보다는, 로그에서 구조를 삽입 시점에 추출하도록 할 것을 권장합니다. 다만, 스택 트레이스나 그 밖의 대용량 String 데이터처럼 구조가 덜 결정적인 경우에는 텍스트 검색이 유용할 수 있습니다.
블룸 필터를 사용할 때의 일반적인 지침은 다음과 같습니다.
블룸 필터의 목적은 그래뉼을 필터링하여, 컬럼의 모든 값을 로드하고 선형 스캔을 수행할 필요를 피하는 것입니다. indexes=1 매개변수와 함께 EXPLAIN 절을 사용하면 건너뛴 그래뉼 수를 파악할 수 있습니다. 아래 결과는 원본 테이블 otel_logs_v2와 ngram 블룸 필터를 사용한 테이블 otel_logs_bloom에 대한 예시입니다.
EXPLAIN indexes = 1
SELECT count()
FROM otel_logs_v2
WHERE Referer LIKE '%ultra%'
┌─explain────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter ((WHERE + Change column names to column identifiers)) │
│ ReadFromMergeTree (default.otel_logs_v2) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 9/9 │
│ Granules: 1278/1278 │
└────────────────────────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.016 sec.
EXPLAIN indexes = 1
SELECT count()
FROM otel_logs_bloom
WHERE Referer LIKE '%ultra%'
┌─explain────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter ((WHERE + Change column names to column identifiers)) │
│ ReadFromMergeTree (default.otel_logs_bloom) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 8/8 │
│ Granules: 1276/1276 │
│ Skip │
│ Name: idx_span_attr_value │
│ Description: ngrambf_v1 GRANULARITY 1 │
│ Parts: 8/8 │
│ Granules: 517/1276 │
└────────────────────────────────────────────────────────────────────┘
블룸 필터는 일반적으로 컬럼 자체보다 더 작을 때 더 빠르게 동작합니다. 더 클 경우에는 성능 이점이 거의 없을 가능성이 큽니다. 다음 쿼리를 사용하여 필터의 크기를 컬럼과 비교하십시오:
SELECT
name,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (`table` = 'otel_logs_bloom') AND (name = 'Referer')
GROUP BY name
ORDER BY sum(data_compressed_bytes) DESC
┌─name────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ Referer │ 56.16 MiB │ 789.21 MiB │ 14.05 │
└─────────┴─────────────────┴───────────────────┴───────┘
1 row in set. Elapsed: 0.018 sec.
SELECT
`table`,
formatReadableSize(data_compressed_bytes) AS compressed_size,
formatReadableSize(data_uncompressed_bytes) AS uncompressed_size
FROM system.data_skipping_indices
WHERE `table` = 'otel_logs_bloom'
┌─table───────────┬─compressed_size─┬─uncompressed_size─┐
│ otel_logs_bloom │ 12.03 MiB │ 12.17 MiB │
└─────────────────┴─────────────────┴───────────────────┘
1 row in set. Elapsed: 0.004 sec.
위 예제에서 알 수 있듯이, 보조 블룸 필터 인덱스는 12MB로, 컬럼 자체의 압축 크기인 56MB보다 거의 5배 작습니다.
블룸 필터는 상당한 튜닝이 필요할 수 있습니다. 최적 설정을 찾는 데 도움이 되는 참고 사항은 여기에 정리되어 있으므로 따르는 것이 좋습니다. 또한 블룸 필터는 insert 및 merge 시점에 비용이 많이 들 수 있습니다. 운영 환경에 블룸 필터를 추가하기 전에 insert 성능에 미치는 영향을 반드시 평가해야 합니다.
보조 스킵 인덱스에 대한 보다 자세한 내용은 여기에서 확인할 수 있습니다.
맵(Map) 타입은 OTel 스키마에서 널리 사용됩니다. 이 타입에서는 값과 키가 동일한 타입이어야 하며, Kubernetes 레이블과 같은 메타데이터를 표현하는 데 충분합니다. 맵 타입의 하위 키를 쿼리할 때에는 상위 컬럼 전체가 로드된다는 점에 유의해야 합니다. 맵에 키가 많이 존재하는 경우, 해당 키가 별도 컬럼으로 존재할 때보다 디스크에서 더 많은 데이터를 읽어야 하므로 상당한 쿼리 성능 저하가 발생할 수 있습니다.
특정 키를 자주 쿼리하는 경우, 해당 키를 루트 수준의 전용 컬럼으로 분리하는 방안을 고려하십시오. 이는 일반적으로 배포 이후 실제 접근 패턴을 파악한 뒤에 수행되는 작업이며, 프로덕션 환경 이전에는 예측하기 어려울 수 있습니다. 배포 이후 스키마를 수정하는 방법은 "Managing schema changes"를 참조하십시오.
테이블 크기 및 압축 측정
ClickHouse가 관측성에 사용되는 주요 이유 중 하나는 압축입니다.
디스크에 저장되는 데이터 양을 크게 줄이면 스토리지 비용이 절감될 뿐만 아니라, 디스크의 데이터가 줄어 I/O가 감소하여 쿼리와 INSERT 속도가 빨라집니다. I/O 감소 효과는 CPU 관점에서 어떤 압축 알고리즘이 추가하는 오버헤드보다 더 큽니다. 따라서 ClickHouse 쿼리 성능을 높이려면 데이터 압축을 개선하는 것에 가장 먼저 집중해야 합니다.
압축 측정에 대한 자세한 내용은 여기를 참고하십시오.