아키텍처 개요
본 문서는 VLDB 2024 학술 논문의 웹 버전입니다. 또한 그 배경과 연구 과정에 대해 블로그 글을 작성했으며, ClickHouse CTO이자 창시자인 Alexey Milovidov의 VLDB 2024 발표 영상을 시청하시기를 권장합니다:
ABSTRACT
지난 수십 년 동안 저장되고 분석되는 데이터의 양은 기하급수적으로 증가했습니다. 업종과 분야를 막론하고 기업들은 이 데이터를 활용해 제품을 개선하고, 성과를 평가하며, 비즈니스에 중대한 의사결정을 내리기 시작했습니다. 그러나 데이터 양이 인터넷 규모로 증가함에 따라, 기업은 과거 데이터와 신규 데이터를 비용 효율적이고 확장 가능한 방식으로 관리하는 동시에, 매우 많은 동시 쿼리와 사용 사례에 따라 1초 미만 수준의 실시간 지연 시간에 대한 기대를 충족하며 데이터를 분석할 수 있어야 합니다.
이 문서는 높은 수집 속도와 페타바이트 규모 데이터 세트에 대한 고성능 분석을 위해 설계된 인기 있는 오픈 소스 OLAP 데이터베이스인 ClickHouse에 대한 개요를 제공합니다. ClickHouse의 스토리지 계층은 전통적인 로그 구조 병합(LSM) 트리를 기반으로 한 데이터 형식과, 백그라운드에서 과거 데이터를 지속적으로 변환(예: 집계, 아카이빙)하기 위한 새로운 기법을 결합합니다. 쿼리는 편리한 SQL 방언으로 작성되며, 선택적 코드 컴파일 기능을 갖춘 최첨단 벡터화된 쿼리 실행 엔진에 의해 처리됩니다. ClickHouse는 쿼리에서 관련 없는 데이터를 스캔하지 않기 위해 적극적으로 프루닝(pruning) 기법을 활용합니다. 다른 데이터 관리 시스템은 table function, ^^table engine^^ 또는 database engine 수준에서 통합할 수 있습니다. 실제 환경 벤치마크는 ClickHouse가 시장에서 가장 빠른 분석용 데이터베이스 중 하나임을 보여줍니다.
1 INTRODUCTION
이 문서는 수조 개의 행과 수백 개의 컬럼을 가진 테이블에 대해 고성능 분석 쿼리를 수행하도록 설계된 열 지향 OLAP 데이터베이스인 ClickHouse를 설명합니다. ClickHouse는 2009년에 웹 규모 로그 파일 데이터를 위한 필터 및 집계 연산자로 시작되었으며, 2016년에 오픈 소스로 공개되었습니다. 이 문서에서 설명하는 주요 기능들이 ClickHouse에 도입된 시점을 그림 1에 나타냅니다.
ClickHouse는 현대 분석 데이터 관리의 다음과 같은 다섯 가지 핵심 과제를 해결하도록 설계되었습니다.
-
높은 수집률을 가진 거대한 데이터 세트. 웹 분석, 금융, 전자상거래와 같은 산업의 많은 데이터 기반 애플리케이션은 거대하고 지속적으로 증가하는 데이터량이라는 특징을 가집니다. 거대한 데이터 세트를 처리하려면 분석 데이터베이스는 효율적인 인덱싱 및 압축 전략을 제공할 뿐만 아니라, 단일 서버가 수십 테라바이트의 스토리지로 제한되므로 데이터를 여러 노드에 분산(스케일 아웃)할 수 있어야 합니다. 또한 실시간 인사이트를 위해서는 최근 데이터가 과거 데이터보다 더 중요한 경우가 많습니다. 그 결과, 분석 데이터베이스는 새로운 데이터를 지속적으로 높은 속도 또는 버스트 형태로 수집할 수 있어야 하며, 동시에 병렬 보고 쿼리를 느려지게 하지 않으면서 과거 데이터를 지속적으로 「우선순위를 낮추어」(예: 집계, 아카이브) 처리할 수 있어야 합니다.
-
낮은 지연 시간이 요구되는 다수의 동시 쿼리. 쿼리는 일반적으로 임시(ad-hoc, 예: 탐색적 데이터 분석) 또는 반복 실행(예: 주기적인 대시보드 쿼리)으로 분류할 수 있습니다. 사용 사례의 상호작용성이 높을수록 더 낮은 쿼리 지연 시간이 요구되며, 이는 쿼리 최적화 및 실행 측면에서 도전 과제가 됩니다. 반복 실행되는 쿼리는 추가로 물리적 데이터베이스 레이아웃을 워크로드에 맞게 조정할 수 있는 기회를 제공합니다. 따라서 데이터베이스는 빈번한 쿼리를 최적화할 수 있는 프루닝(pruning) 기법을 제공해야 합니다. 쿼리 우선순위에 따라, 많은 수의 쿼리가 동시에 실행되더라도 CPU, 메모리, 디스크 및 네트워크 I/O와 같은 공유 시스템 자원에 대해 공정하거나 우선적인 접근을 보장해야 합니다.
-
다양한 데이터 저장소, 스토리지 위치 및 포맷의 조합. 기존 데이터 아키텍처와 통합하기 위해서는 현대 분석 데이터베이스가 어떤 시스템, 위치, 포맷이든 외부 데이터를 읽고 쓸 수 있도록 높은 수준의 개방성을 가져야 합니다.
-
성능 관찰을 지원하는 편리한 쿼리 언어. 실제 OLAP 데이터베이스 사용에는 추가적인 「소프트」 요구사항이 존재합니다. 예를 들어, 특수한 프로그래밍 언어 대신, 사용자는 중첩 데이터 타입과 다양한 일반 함수, 집계 함수, 윈도우 함수를 지원하는 표현력 있는 SQL 방언으로 데이터베이스와 상호작용하기를 선호합니다. 분석 데이터베이스는 또한 시스템 전체 또는 개별 쿼리의 성능을 관찰(introspect)할 수 있는 정교한 도구를 제공해야 합니다.
-
산업 수준의 견고함과 다양한 배포 방식. 범용 하드웨어는 신뢰성이 낮기 때문에, 데이터베이스는 노드 장애에 대비한 견고성을 위해 데이터 복제를 제공해야 합니다. 또한 데이터베이스는 오래된 노트북부터 고성능 서버까지 어떤 하드웨어에서도 동작해야 합니다. 마지막으로, JVM 기반 프로그램의 가비지 컬렉션 오버헤드를 피하고 베어메탈 수준의 성능(예: SIMD)을 제공하기 위해, 데이터베이스는 이상적으로 대상 플랫폼용 네이티브 바이너리로 배포되는 것이 좋습니다.

그림 1: ClickHouse 타임라인.
2 ARCHITECTURE
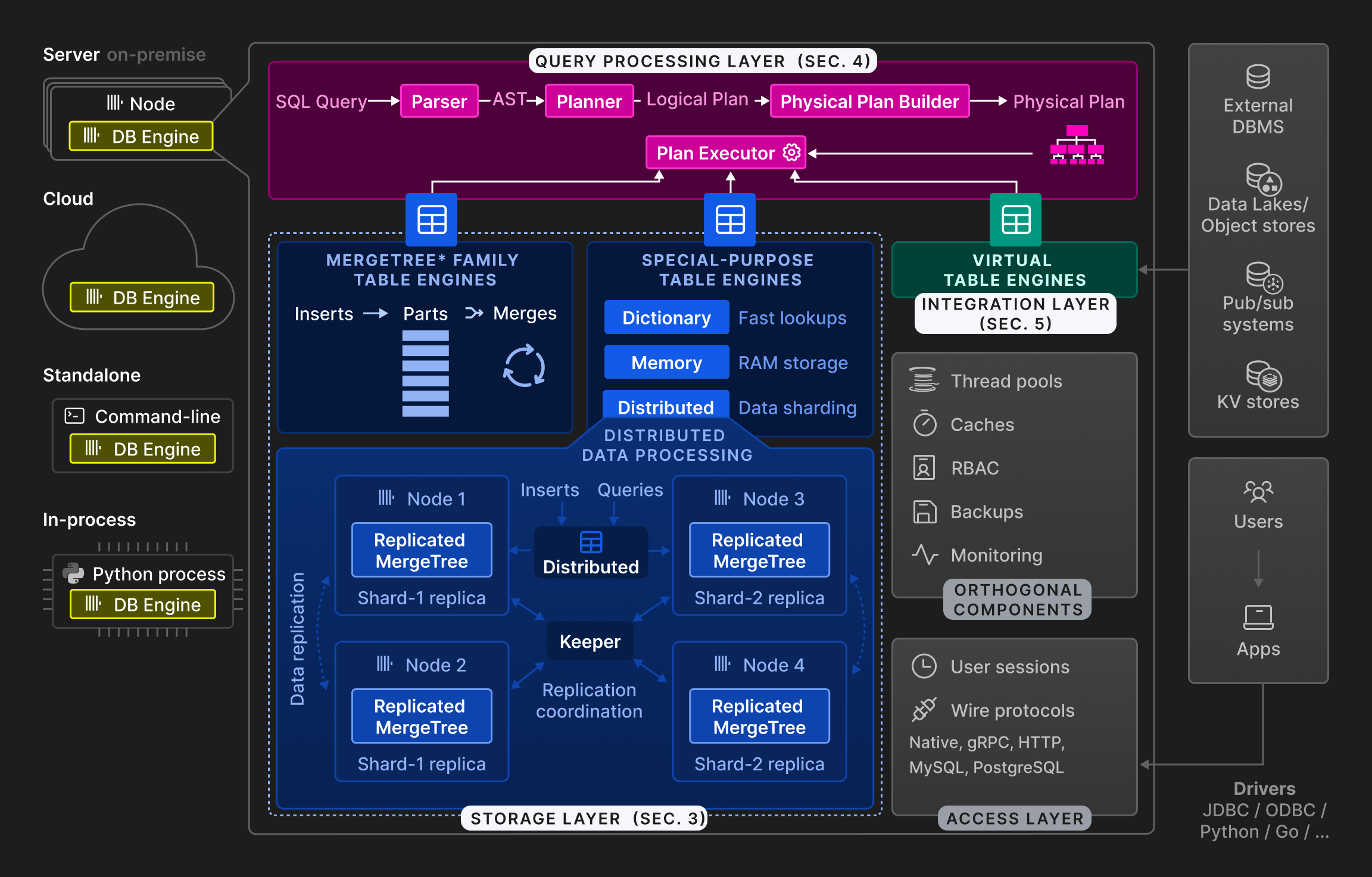
Figure 2: The high-level architecture of the ClickHouse database engine.
As shown by Figure 2, the ClickHouse engine is split into three main layers: the query processing layer (described in Section 4), the storage layer (Section 3), and the integration layer (Section 5). Besides these, an access layer manages user sessions and communication with applications via different protocols. There are orthogonal components for threading, caching, role-based access control, backups, and continuous monitoring. ClickHouse is built in C++ as a single, statically-linked binary without dependencies.
Query processing follows the traditional paradigm of parsing incoming queries, building and optimizing logical and physical query plans, and execution. ClickHouse uses a vectorized execution model similar to MonetDB/X100 [11], in combination with opportunistic code compilation [53]. Queries can be written in a feature-rich SQL dialect, PRQL [76], or Kusto's KQL [50].
The storage layer consists of different table engines that encapsulate the format and location of table data. Table engines fall into three categories: The first category is the ^^MergeTree^^* family of table engines which represent the primary persistence format in ClickHouse. Based on the idea of LSM trees [60], tables are split into horizontal, sorted ^^parts^^, which are continuously merged by a background process. Individual ^^MergeTree^^* table engines differ in the way the merge combines the rows from its input ^^parts^^. For example, rows can be aggregated or replaced, if outdated.
The second category are special-purpose table engines, which are used to speed up or distribute query execution. This category includes in-memory key-value table engines called dictionaries. A dictionary caches the result of a query periodically executed against an internal or external data source. This significantly reduces access latencies in scenarios, where a degree of data staleness can be tolerated. Other examples of special-purpose table engines include a pure in-memory engine used for temporary tables and the ^^Distributed table^^ engine for transparent data sharding (see below).
The third category of table engines are virtual table engines for bidirectional data exchange with external systems such as relational databases (e.g. PostgreSQL, MySQL), publish/subscribe systems (e.g. Kafka, RabbitMQ [24]), or key/value stores (e.g. Redis). Virtual engines can also interact with data lakes (e.g. Iceberg, DeltaLake, Hudi [36]) or files in object storage (e.g. AWS S3, Google GCP).
ClickHouse supports sharding and replication of tables across multiple ^^cluster^^ nodes for scalability and availability. Sharding partitions a table into a set of table shards according to a sharding expression. The individual shards are mutually independent tables and typically located on different nodes. Clients can read and write shards directly, i.e. treat them as separate tables, or use the Distributed special ^^table engine^^, which provides a global view of all table shards. The main purpose of sharding is to process data sets which exceed the capacity of individual nodes (typically, a few dozens terabytes of data). Another use of sharding is to distribute the read-write load for a table over multiple nodes, i.e., load balancing. Orthogonal to that, a ^^shard^^ can be replicated across multiple nodes for tolerance against node failures. To that end, each Merge-Tree* ^^table engine^^ has a corresponding ReplicatedMergeTree* engine which uses a multi-master coordination scheme based on Raft consensus [59] (implemented by Keeper, a drop-in replacement for Apache Zookeeper written in C++) to guarantee that every ^^shard^^ has, at all times, a configurable number of replicas. Section 3.6 discusses the replication mechanism in detail. As an example, Figure 2 shows a table with two shards, each replicated to two nodes.
마지막으로, ClickHouse 데이터베이스 엔진은 온프레미스, 클라우드, standalone, in-process 모드로 운영할 수 있습니다. 온프레미스 모드에서 사용자는 ClickHouse를 단일 서버 또는 세그먼트 및/또는 복제가 적용된 다중 노드 ^^cluster^^로 로컬에 구축합니다. 클라이언트는 네이티브, MySQL의, PostgreSQL의 바이너리 와이어 프로토콜 또는 HTTP 기반 REST API를 통해 데이터베이스와 통신합니다. 클라우드 모드는 완전 관리형 자동 확장 DBaaS인 ClickHouse Cloud로 제공됩니다. 이 문서는 온프레미스 모드에 초점을 맞추지만, 후속 문서에서 ClickHouse Cloud의 아키텍처를 설명할 예정입니다. standalone mode는 ClickHouse를 파일 분석 및 변환용 명령줄 유틸리티로 전환하여, cat과 grep 같은 Unix 도구에 대한 SQL 기반 대안으로 만듭니다. 별도의 사전 구성이 필요하지 않지만, standalone 모드는 단일 서버로 제한됩니다. 최근에는 Jupyter notebooks [37]와 Pandas dataframes [61] 같은 대화형 데이터 분석 사용 사례를 위해 chDB [15]라는 in-process 모드가 개발되었습니다. DuckDB [67]에서 영감을 받은 chDB는 ClickHouse를 고성능 OLAP 엔진으로 호스트 프로세스에 내장합니다. 다른 모드와 비교하면, 동일한 주소 공간에서 실행되므로 데이터베이스 엔진과 애플리케이션 사이에서 원본 데이터와 결과 데이터를 복사 없이 효율적으로 전달할 수 있습니다.
3 STORAGE LAYER
이 섹션에서는 ClickHouse의 기본 스토리지 형식인 ^^MergeTree^^* 테이블 엔진에 대해 설명합니다. 디스크 상 표현 방식을 설명하고, ClickHouse에서 사용되는 세 가지 데이터 프루닝(pruning) 기법을 논의합니다. 이후, 동시에 수행되는 삽입 작업에 영향을 주지 않으면서 데이터를 지속적으로 변환하는 머지(merge) 전략을 설명합니다. 마지막으로, 업데이트와 삭제가 어떻게 구현되는지, 그리고 데이터 중복 제거, 데이터 복제, ACID 준수 방식에 대해 설명합니다.
3.1 On-Disk Format
^^MergeTree^^* ^^table engine^^에서는 각 테이블이 변경 불가능한 테이블 ^^parts^^의 집합으로 구성됩니다. 하나의 파트는 일련의 행이 테이블에 INSERT될 때마다 생성됩니다. ^^Parts^^는 별도의 중앙 카탈로그 조회 없이도 그 내용을 해석하는 데 필요한 모든 메타데이터를 자체적으로 포함한다는 점에서 독립적입니다. 테이블당 ^^parts^^ 개수를 낮게 유지하기 위해, 백그라운드 머지 작업이 주기적으로 여러 개의 작은 ^^parts^^를 병합하여 구성 가능한 파트 크기(기본값 150 GB)에 도달할 때까지 더 큰 파트로 결합합니다. ^^parts^^는 테이블의 ^^primary key^^ 컬럼으로 정렬되어 있기 때문에(3.2절(3.2) 참조), 효율적인 k-방향 머지 소트 [40]가 머지에 사용됩니다. 소스 ^^parts^^는 비활성으로 표시되며, 참조 카운트가 0으로 떨어지는 즉시, 즉 더 이상 해당 파트에서 데이터를 읽는 쿼리가 없게 되면 최종적으로 삭제됩니다.
행을 INSERT하는 방식은 두 가지 모드가 있습니다. 동기식 INSERT 모드에서는 각 INSERT 문이 새로운 파트를 생성하고 이를 테이블에 추가합니다. 머지 오버헤드를 최소화하기 위해 데이터베이스 클라이언트에서는 예를 들어 한 번에 20,000개의 행처럼 튜플을 대량으로 INSERT하는 것이 권장됩니다. 그러나 데이터가 실시간으로 분석되어야 하는 경우 클라이언트 측 배칭으로 인한 지연은 종종 허용되기 어렵습니다. 예를 들어 관측성 사용 사례에서는 수천 개의 모니터링 에이전트가 적은 양의 이벤트 및 메트릭 데이터를 지속적으로 전송하는 경우가 자주 발생합니다. 이러한 시나리오에서는 비동기식 INSERT 모드를 사용할 수 있으며, 이 모드에서 ClickHouse는 동일한 테이블로 들어오는 여러 INSERT로부터 행을 버퍼링하고, 버퍼 크기가 구성 가능한 임계값을 초과하거나 타임아웃이 만료된 후에만 새로운 파트를 생성합니다.
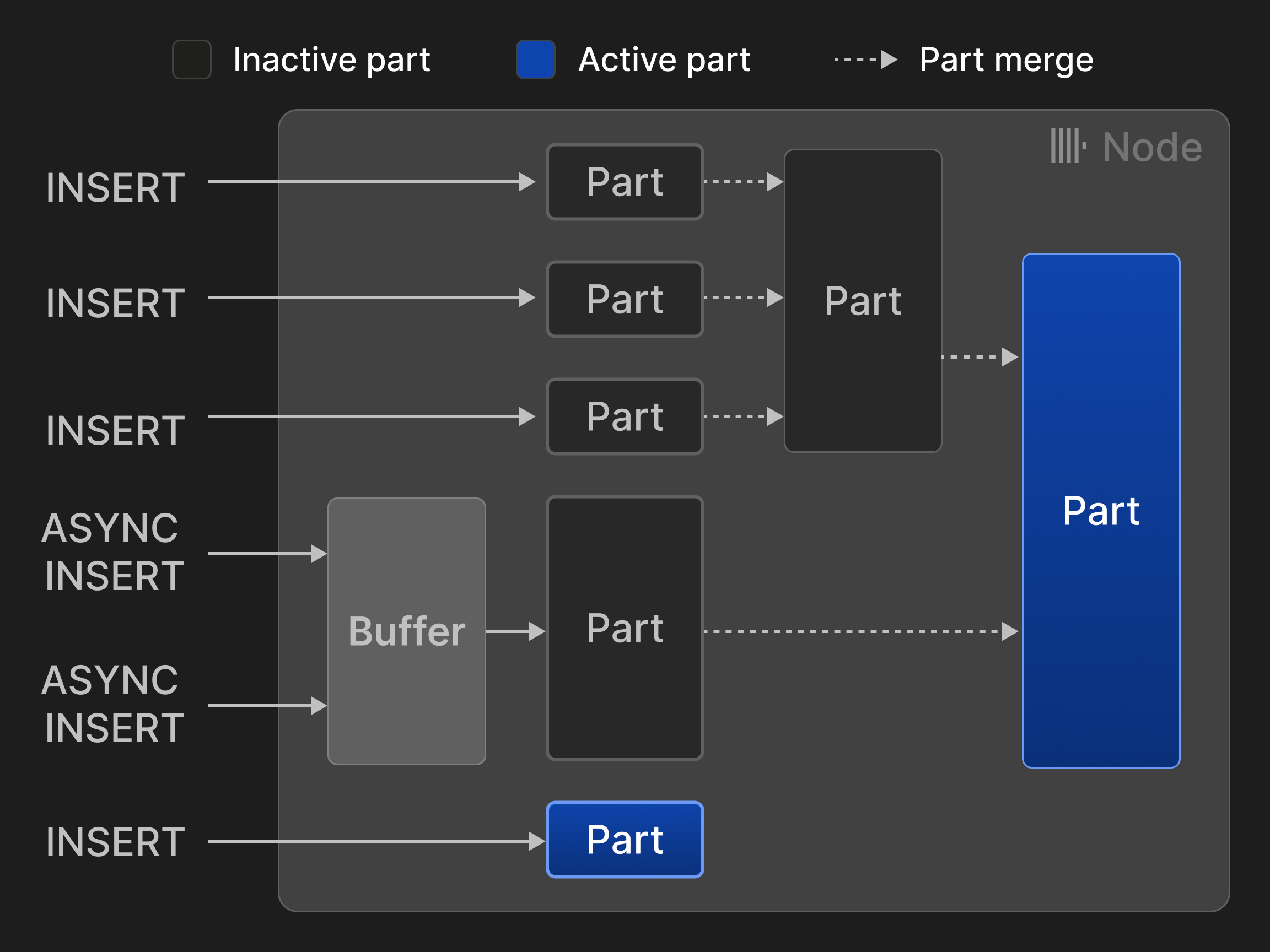
그림 3: ^^MergeTree^^* 엔진 테이블에서의 INSERT와 머지.
그림 3은 ^^MergeTree^^* 엔진 테이블에 대한 네 번의 동기식 INSERT와 두 번의 비동기식 INSERT를 보여 줍니다. 두 번의 머지를 통해 활성 ^^parts^^ 개수가 처음 다섯 개에서 두 개로 줄어들었습니다.
LSM 트리 [58]와 이를 다양한 데이터베이스에 구현한 사례들 [13, 26, [56]](#page-13-8)과 비교하면, ClickHouse는 ^^parts^^를 계층 구조로 배열하는 대신 모두 동등하게 취급합니다. 그 결과 머지는 더 이상 동일한 레벨의 ^^parts^^로 제한되지 않습니다. 이로 인해 ^^parts^^의 암묵적인 시간순 정렬도 포기하게 되므로, 톰스톤(tombstone)에 기반하지 않는 업데이트 및 삭제를 위한 대체 메커니즘이 필요합니다(3.4절(3.4) 참조). ClickHouse는 INSERT를 직접 디스크에 기록하는 반면, 다른 LSM 트리 기반 스토어들은 일반적으로 쓰기 전 로그(write-ahead logging)를 사용합니다(3.7절(3.7) 참조).
하나의 파트는 디스크 상의 디렉터리에 해당하며, 각 컬럼마다 하나의 파일을 포함합니다. 최적화를 위해, 작은 파트(기본값 10 MB 미만)의 컬럼들은 읽기 및 쓰기의 공간 지역성을 높이기 위해 하나의 파일에 연속적으로 저장됩니다. 파트의 행은 추가로 8192개의 레코드로 이루어진 그룹들로 논리적으로 나뉘며, 이를 그래뉼(granule)이라고 합니다. 하나의 ^^granule^^은 ClickHouse에서 스캔 및 인덱스 조회 연산자가 처리하는 가장 작은 불가분 데이터 단위를 나타냅니다. 그러나 디스크 상 데이터의 읽기와 쓰기는 ^^granule^^ 수준에서 수행되지 않고, 컬럼 내에서 인접한 여러 그래뉼을 결합한 블록(block) 단위의 세분성에서 수행됩니다. 새로운 블록은 ^^block^^당 구성 가능한 바이트 크기(기본값 1 MB)를 기준으로 형성되며, 즉 하나의 ^^block^^에 포함되는 그래뉼 개수는 가변적이며 컬럼의 데이터 타입과 분포에 따라 달라집니다. 블록은 크기와 I/O 비용을 줄이기 위해 추가로 압축됩니다. 기본적으로 ClickHouse는 범용 압축 알고리즘으로 LZ4 [75]를 사용하지만, 사용자는 부동소수점 데이터에 대해 Gorilla [63]나 FPC [12]와 같은 특수 코덱을 지정할 수도 있습니다. 압축 알고리즘은 체이닝도 가능합니다. 예를 들어, 먼저 delta coding [23]을 사용해 수치 값의 논리적 중복성을 줄인 다음, 고강도 압축을 수행하고, 마지막으로 AES 코덱을 사용해 데이터를 암호화할 수 있습니다. 블록은 디스크에서 메모리로 로드될 때 즉시(on-the-fly) 압축 해제됩니다. 압축에도 불구하고 개별 그래뉼에 대한 빠른 임의 접근을 가능하게 하기 위해, ClickHouse는 추가로 각 컬럼마다 모든 ^^granule^^ ID를 그 그래뉼이 포함된 압축된 ^^block^^의 컬럼 파일 내 오프셋과 비압축 ^^block^^ 내에서의 ^^granule^^ 오프셋에 매핑하는 정보를 저장합니다.
컬럼은 추가로 ^^딕셔너리^^ 인코딩[2, 77, [81]](#page-13-12)을 적용하거나, 두 가지 특수 래퍼 데이터 타입을 사용해 널 허용으로 만들 수 있습니다. LowCardinality(T)는 원래 컬럼 값을 정수 ID로 대체하여 고유 값 개수가 적은 데이터의 저장 오버헤드를 크게 줄입니다. Nullable(T)는 컬럼 T에 내부 비트맵을 추가하여 각 컬럼 값이 NULL인지 아닌지를 표현합니다.
마지막으로, 테이블은 임의의 파티션 표현식을 사용하여 범위, 해시, 또는 라운드 로빈 방식으로 파티션 분할할 수 있습니다. 파티션 프루닝(partition pruning)을 활성화하기 위해 ClickHouse는 각 파티션마다 파티션 표현식의 최소값과 최대값도 함께 저장합니다. 사용자는 선택적으로 더 고급 컬럼 통계(예: HyperLogLog [30] 또는 t-digest [28] 통계)를 생성하여 기수(cardinality) 추정값을 제공하도록 할 수 있습니다.
3.2 Data Pruning
대부분의 사용 사례에서 단일 쿼리에 답하기 위해 페타바이트 규모의 데이터를 스캔하는 것은 너무 느리고 비용이 많이 듭니다. ClickHouse는 검색 중 대부분의 행을 건너뛰어 쿼리 속도를 크게 높일 수 있게 해 주는 3가지 데이터 프루닝(data pruning) 기법을 지원합니다.
첫째, 사용자 정의 ^^primary key^^ index를 테이블에 정의할 수 있습니다. ^^primary key^^ 컬럼은 각 파트 내 행의 정렬 순서를 결정하며, 즉 인덱스는 로컬 클러스터 형태입니다. ClickHouse는 추가로 각 파트마다, 각 ^^granule^^의 첫 번째 행의 ^^primary key^^ 컬럼 값에서 해당 ^^granule^^의 ID로의 매핑을 저장하므로 인덱스는 희소[sparse]합니다 [31]. 이렇게 생성된 데이터 구조는 일반적으로 전체를 메모리에 상주시킬 만큼 충분히 작습니다. 예를 들어, 810만 개의 행을 인덱싱하는 데 1,000개의 엔트리만 필요합니다. ^^primary key^^의 주요 목적은 자주 필터링되는 컬럼에 대한 동등 및 범위 조건을 순차 스캔 대신 이진 검색으로 평가하는 것입니다(섹션 4.4). 또한 로컬 정렬은 파트 병합 및 쿼리 최적화에 활용할 수 있으며, 예를 들어 정렬 기반 집계나 ^^primary key^^ 컬럼이 정렬 컬럼의 접두어를 이룰 때 물리 실행 계획에서 정렬 연산자를 제거하는 데 사용할 수 있습니다.
Figure 4는 페이지 조회 통계 테이블의 EventTime 컬럼에 대한 ^^primary key^^ 인덱스를 보여줍니다. 쿼리의 범위 조건과 일치하는 그래뉼은 EventTime을 순차적으로 스캔하는 대신 ^^primary key^^ 인덱스를 이진 검색하여 찾을 수 있습니다.

Figure 4: ^^primary key^^ 인덱스를 사용한 필터 평가.
둘째, 사용자 정의 table projections를 생성할 수 있습니다. 이는 동일한 행을 포함하지만 다른 ^^primary key^^로 정렬된 테이블의 대체 버전입니다 [71]. 프로젝션은 기본 테이블의 ^^primary key^^와 다른 컬럼을 기준으로 필터링하는 쿼리를 가속하는 대신, INSERT, 파트 병합, 저장 공간 사용량에 대한 오버헤드를 증가시킵니다. 기본적으로 프로젝션은 기존 ^^parts^^가 아니라 기본 테이블에 새로 삽입되는 ^^parts^^에서만 지연(lazy) 방식으로 채워집니다. 사용자가 ^^projection^^ 전체를 머티리얼라이즈(materialize)하지 않는 한 그렇습니다. 쿼리 옵티마이저는 추정된 I/O 비용을 기반으로 기본 테이블에서 읽을지 ^^projection^^에서 읽을지 선택합니다. 어떤 파트에 대해 ^^projection^^이 존재하지 않으면 쿼리 실행은 해당 기본 테이블 파트로 되돌아갑니다.
셋째, skipping indices는 프로젝션에 대한 경량 대안을 제공합니다. 스키핑 인덱스의 개념은 여러 연속된 그래뉼 수준에서 소량의 메타데이터를 저장하여 관련 없는 행의 스캔을 피하는 것입니다. 스키핑 인덱스는 임의의 인덱스 표현식에 대해 생성할 수 있으며, 구성 가능한 그래뉼리티(즉, 하나의 ^^skipping index^^ 블록에 포함된 그래뉼 수)를 사용할 수 있습니다. 사용 가능한 ^^skipping index^^ 유형은 다음과 같습니다. 1. Min-max 인덱스 [51]: 각 인덱스 ^^block^^에 대해 인덱스 표현식의 최소값과 최대값을 저장합니다. 이 인덱스 유형은 느슨하게 정렬된 데이터처럼 로컬 클러스터링이 되어 있고 절대 범위가 작은 데이터에 잘 동작합니다. 2. Set 인덱스: 구성 가능한 개수의 고유 인덱스 ^^block^^ 값을 저장합니다. 이러한 인덱스는 「뭉쳐 있는」 값처럼 로컬 카디널리티가 작은 데이터에 가장 적합합니다. 3. 블룸 필터(bloom filter) 인덱스 [9]: 구성 가능한 거짓 양성률을 갖도록 행, 토큰 또는 n-그램 값에 대해 구축됩니다. 이러한 인덱스는 텍스트 검색을 지원하지만 [73], min-max 및 set 인덱스와 달리 범위나 부정 조건에는 사용할 수 없습니다.
3.3 머지 시점 데이터 변환
비즈니스 인텔리전스와 관측성 사용 사례에서는 지속적으로 높거나 일시적으로 폭증하는 속도로 생성되는 데이터를 처리해야 하는 경우가 많습니다. 또한 의미 있는 실시간 인사이트를 위해서는 최근에 생성된 데이터가 과거 데이터보다 일반적으로 더 중요합니다. 이러한 사용 사례에서는 집계나 데이터 에이징과 같은 기법을 통해 역사적 데이터의 양을 지속적으로 줄이면서도 높은 데이터 수집(ingestion) 속도를 유지할 수 있는 데이터베이스가 필요합니다. ClickHouse는 서로 다른 머지 전략을 사용하여 기존 데이터를 지속적이고 점진적으로 변환할 수 있습니다. 머지 시점 데이터 변환은 INSERT 문 성능을 저하시키지 않지만, 테이블에 원치 않는 값(예: 오래되었거나 아직 집계되지 않은 값)이 전혀 존재하지 않는다고 보장할 수는 없습니다. 필요하다면, 모든 머지 시점 변환은 SELECT 문에서 키워드 FINAL을 지정하여 쿼리 시점에 적용할 수 있습니다.
Replacing 머지는 파트를 생성한 시점의 타임스탬프를 기준으로 가장 최근에 삽입된 튜플 버전만 유지하고, 더 오래된 버전은 삭제합니다. ^^primary key^^ 컬럼 값이 동일하면 튜플이 동등한 것으로 간주합니다. 어떤 튜플을 유지할지 명시적으로 제어해야 하는 경우, 비교를 위해 별도의 버전 컬럼을 지정할 수도 있습니다. Replacing 머지는 일반적으로 머지 시점 업데이트 메커니즘(업데이트가 빈번한 사용 사례에서 주로 사용)으로 사용되거나, 삽입 시점 데이터 중복 제거(Section 3.5)의 대안으로 사용됩니다.
Aggregating 머지는 ^^primary key^^ 컬럼 값이 같은 행들을 하나의 집계된 행으로 축약합니다. ^^primary key^^가 아닌 컬럼은 요약 값을 보관하는 부분 집계 상태여야 합니다. 예를 들어 avg()에 대한 합과 개수(count)처럼 두 개의 부분 집계 상태를 새로운 부분 집계 상태로 결합합니다. Aggregating 머지는 일반 테이블 대신 materialized view에서 주로 사용됩니다. Materialized view는 소스 테이블에 대한 변환 쿼리 결과를 기반으로 채워집니다. 다른 데이터베이스와 달리 ClickHouse는 소스 테이블의 전체 내용을 주기적으로 다시 읽어 materialized view를 갱신하지 않습니다. 대신, 소스 테이블에 새로운 파트가 삽입될 때마다 변환 쿼리 결과를 기반으로 materialized view를 점진적으로 업데이트합니다.
Figure 5는 페이지 노출 통계 테이블에 정의된 ^^materialized view^^를 보여 줍니다. 소스 테이블에 새로운 ^^parts^^가 삽입되면, 변환 쿼리가 지역별로 최대 지연 시간과 평균 지연 시간을 계산하고 그 결과를 ^^materialized view^^에 삽입합니다. avg()와 max()에 -State 확장을 사용한 집계 함수는 실제 결과 대신 부분 집계 상태를 반환합니다. ^^materialized view^^에 정의된 aggregating 머지는 서로 다른 ^^parts^^의 부분 집계 상태를 지속적으로 결합합니다. 최종 결과를 얻기 위해 사용자는 ^^materialized view^^ 내 부분 집계 상태에 대해 -Merge 확장을 사용한 avg()와 max()를 실행하여 이를 통합합니다.
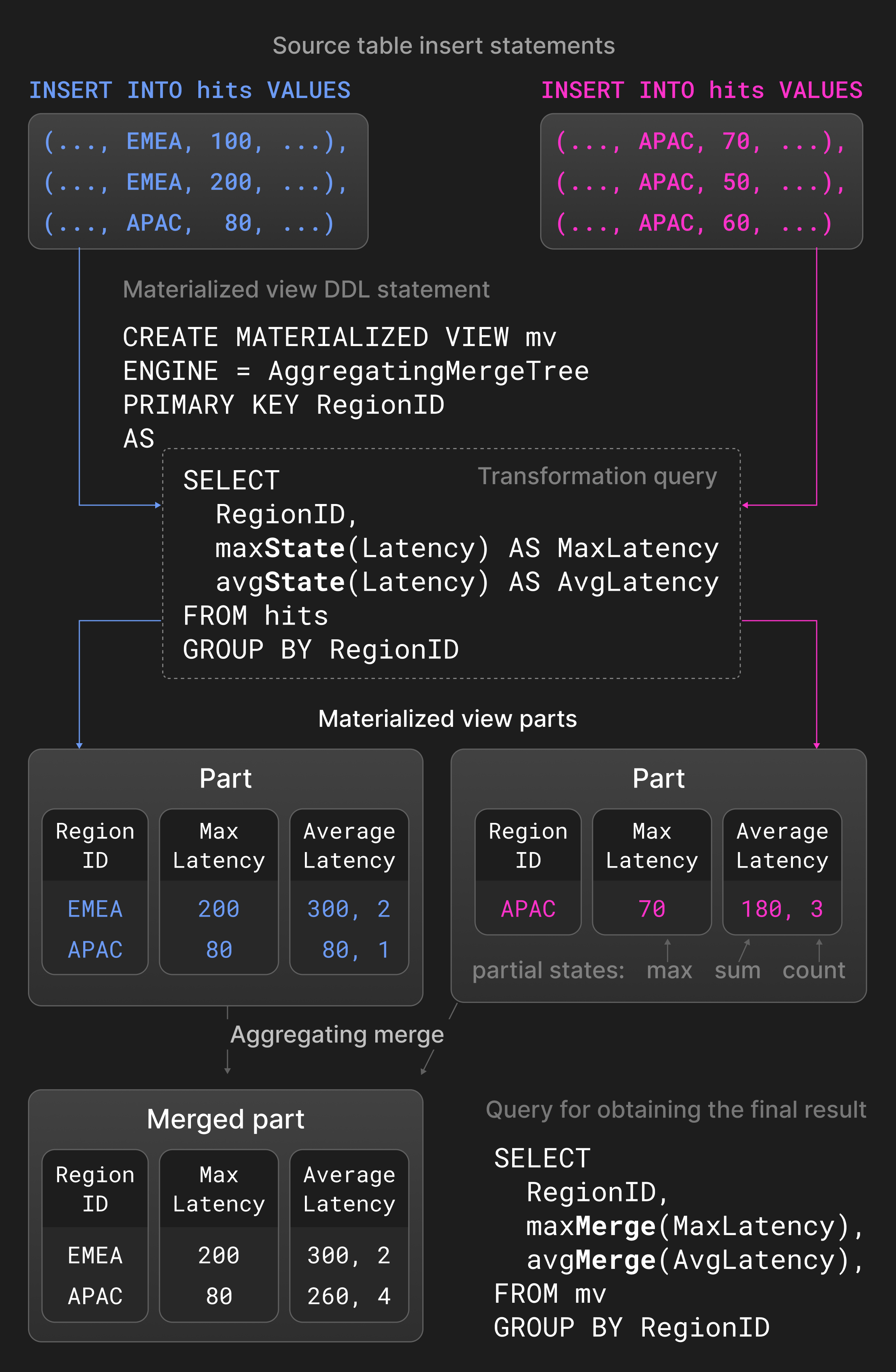
Figure 5: materialized view에서의 aggregating 머지.
^^TTL^^(time-to-live) 머지는 역사적 데이터에 대한 에이징을 제공합니다. 삭제 및 집계 머지와 달리 ^^TTL^^ 머지는 한 번에 하나의 파트만 처리합니다. ^^TTL^^ 머지는 트리거와 액션으로 구성된 규칙 형태로 정의됩니다. 트리거는 각 행에 대한 타임스탬프를 계산하는 표현식이며, 이는 ^^TTL^^ 머지가 실행되는 시각과 비교됩니다. 이를 통해 행 단위로 액션을 제어할 수 있지만, 모든 행이 주어진 조건을 만족하는지 확인하고 파트 전체에 액션을 수행하는 것으로 충분한 것으로 확인했습니다. 가능한 액션에는 1. 파트를 다른 볼륨(예: 더 저렴하고 느린 스토리지)으로 이동, 2. 파트를 다시 압축(예: 더 무거운 코덱 사용), 3. 파트 삭제, 4. 롤업(roll-up), 즉 그룹 키와 집계 함수를 사용하여 행을 집계하는 작업이 포함됩니다.
예로 Listing 1.의 로깅 테이블 정의를 살펴보겠습니다. ClickHouse는 timestamp 컬럼 값이 1주일보다 오래된 ^^parts^^를 느리지만 저렴한 S3 객체 스토리지로 이동합니다.
목록 1: 일주일 후 파트를 객체 스토리지로 이동합니다.
3.4 업데이트 및 삭제
^^MergeTree^^* 테이블 엔진의 설계는 추가 전용(append-only) 워크로드에 유리하지만, 규제 준수 등의 이유로 가끔 기존 데이터를 수정해야 하는 사용 사례도 있습니다. 데이터를 업데이트하거나 삭제하는 두 가지 접근 방식이 있으며, 어느 것도 병렬 INSERT 작업을 ^^차단^^하지 않습니다.
뮤테이션은 테이블의 모든 ^^파트^^를 제자리에서 다시 씁니다. 테이블(삭제) 또는 컬럼(업데이트)의 크기가 일시적으로 두 배가 되는 것을 방지하기 위해 이 작업은 원자적이지 않습니다. 즉, 병렬 SELECT 쿼리는 뮤테이션이 적용된 파트와 적용되지 않은 ^^파트^^를 모두 읽을 수 있습니다. 뮤테이션은 작업이 끝날 때 데이터가 물리적으로 변경되었음을 보장합니다. 삭제 뮤테이션은 모든 ^^파트^^의 모든 컬럼을 다시 쓰기 때문에 여전히 비용이 많이 듭니다.
대안으로, 경량한 삭제는 행이 삭제되었는지 여부를 나타내는 내부 비트맵 컬럼만 업데이트합니다. ClickHouse는 삭제된 행을 결과에서 제외하기 위해 비트맵 컬럼에 대한 추가 필터를 SELECT 쿼리에 자동으로 추가합니다. 삭제된 행은 향후 어느 시점에 정기적인 머지 작업을 통해서만 물리적으로 제거됩니다. 컬럼 개수에 따라, 경량한 삭제는 SELECT가 느려지는 대가로 뮤테이션보다 훨씬 빠를 수 있습니다.
동일한 테이블에서 수행되는 업데이트 및 삭제 작업은 논리적 충돌을 피하기 위해 드물게 수행되고 직렬화되는 것이 바람직합니다.
3.5 Idempotent Inserts
실무에서 자주 발생하는 문제는, 클라이언트가 서버로 테이블에 삽입할 데이터를 전송한 뒤 연결 시간 초과가 발생했을 때 이를 어떻게 처리해야 하는지입니다. 이런 상황에서는 데이터가 실제로 성공적으로 삽입되었는지 여부를 클라이언트가 구분하기 어렵습니다. 이 문제는 전통적으로 클라이언트에서 서버로 데이터를 다시 전송하고, ^^primary key^^ 또는 고유 제약 조건에 의존하여 중복 삽입을 거부하는 방식으로 해결해 왔습니다. 데이터베이스는 이때 이진 트리를 기반으로 하는 인덱스 구조 [39, [68]](#page-13-16), radix 트리 [45], 또는 해시 테이블 [29]을 사용해 필요한 포인트 조회를 빠르게 수행합니다. 이러한 자료 구조는 모든 튜플을 인덱싱하기 때문에, 대규모 데이터 세트와 높은 수집 속도에서는 공간 및 갱신 오버헤드가 감당하기 어려운 수준이 됩니다.
ClickHouse는 각 삽입이 결국 하나의 파트를 생성한다는 사실에 기반해 더 경량한 대안을 제공합니다. 보다 구체적으로, 서버는 최근 삽입된 N개의 ^^파트^^(예: N=100)에 대한 해시를 유지하며, 이미 알려진 해시를 가진 ^^파트^^의 재삽입을 무시합니다. 비복제 테이블과 복제된 테이블(Replicated Table)에 대한 해시는 각각 로컬에, 그리고 Keeper에 저장됩니다. 그 결과 삽입 연산은 멱등(idempotent)이 되므로, 클라이언트는 시간 초과가 발생한 후 동일한 행 배치를 단순히 다시 전송하고, 서버가 중복 제거를 처리한다고 가정하면 됩니다. 중복 제거 과정에 대해 더 세밀한 제어가 필요할 경우, 클라이언트는 선택적으로 파트 해시 역할을 하는 삽입 토큰을 제공할 수 있습니다. 해시 기반 중복 제거는 새로운 행을 해싱하는 데 따른 오버헤드를 수반하지만, 해시를 저장하고 비교하는 비용은 무시할 수 있는 수준입니다.
3.6 Data Replication
복제는 고가용성(노드 장애에 대한 내성)을 위한 필수 조건일 뿐만 아니라, 로드 밸런싱과 무중단 업그레이드에도 사용됩니다 [14]. ClickHouse에서 복제는 테이블 상태의 개념에 기반하며, 이 테이블 상태는 테이블 ^^파트^^의 집합(Section 3.1)과 컬럼 이름 및 타입과 같은 테이블 메타데이터로 구성됩니다. 노드는 세 가지 연산을 사용하여 테이블 상태를 진전시킵니다. 1. insert는 상태에 새 파트를 추가하고, 2. merge는 상태에 새 파트를 추가하고 기존 ^^파트^^를 삭제하며, 3. 뮤테이션과 DDL 문은 구체적인 연산에 따라 ^^파트^^를 추가 및/또는 삭제하고, 및/또는 테이블 메타데이터를 변경합니다. 이러한 연산은 단일 노드에서 로컬로 수행되며, 전역 복제 로그에 상태 전이 시퀀스로 기록됩니다.
복제 로그는 일반적으로 세 개의 ClickHouse Keeper 프로세스로 구성된 앙상블에 의해 유지되며, 이들은 Raft 합의 알고리즘 [59]을 사용하여 ClickHouse 노드 ^^클러스터^^를 위한 분산되고 장애 허용적인 코디네이션 레이어를 제공합니다. 모든 ^^클러스터^^ 노드는 초기에는 복제 로그의 동일한 위치를 가리킵니다. 노드가 로컬 insert, merge, 뮤테이션, DDL 문을 실행하는 동안, 복제 로그는 다른 모든 노드에서 비동기적으로 재생됩니다. 그 결과, 복제된 테이블은 최종적 일관성(eventual consistency)을 갖게 되며, 즉 노드가 최신 상태로 수렴하는 동안 일시적으로 오래된 테이블 상태를 읽을 수 있습니다. 앞서 언급한 대부분의 연산은, 예를 들어 노드의 과반수 또는 모든 노드와 같이, 노드 정족수(quorum)가 새 상태를 채택할 때까지 동기적으로 실행되도록 할 수도 있습니다.
예로서, Figure 6은 세 개의 ClickHouse 노드로 구성된 ^^클러스터^^에서 초기에는 비어 있는 복제 테이블을 보여줍니다. Node 1은 먼저 두 개의 insert SQL 문을 수신하고 이를 Keeper 앙상블에 저장된 복제 로그에 ( 1 2 )로 기록합니다. 다음으로, Node 2는 첫 번째 로그 엔트리를 가져와서( 3 ) Node 1에서 새 파트를 다운로드함으로써( 4 ) 이를 재생하고, Node 3은 두 로그 엔트리를 모두 재생합니다( 3 4 5 6 ). 마지막으로, Node 3은 두 ^^파트^^를 하나의 새 파트로 병합하고 입력 ^^파트^^를 삭제한 뒤, merge 엔트리를 복제 로그에 기록합니다( 7 ).
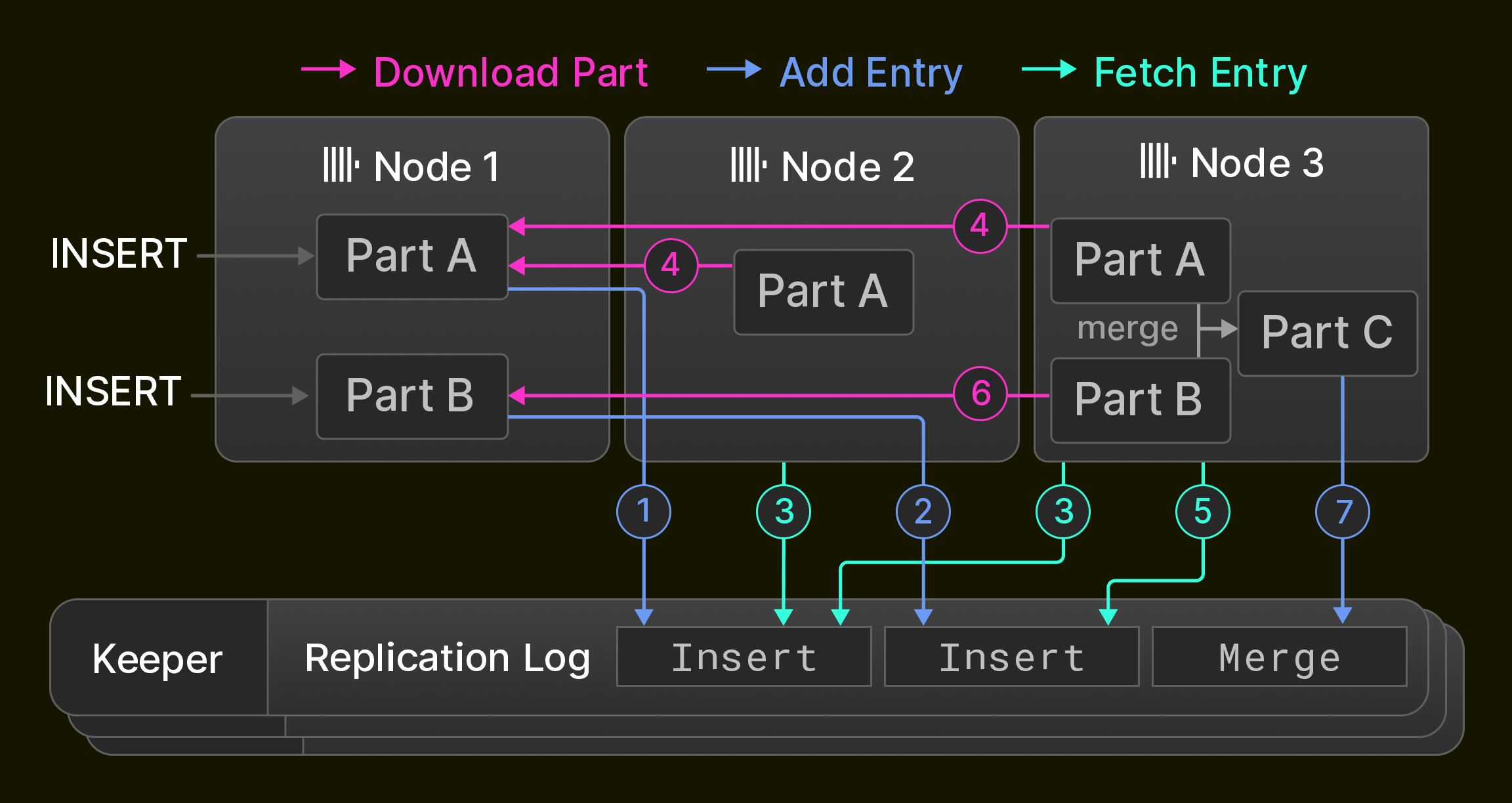
Figure 6: 세 개의 노드로 구성된 ^^클러스터^^에서의 복제.
동기화를 가속화하기 위한 세 가지 최적화가 있습니다. 첫째, ^^클러스터^^에 새로 추가된 노드는 복제 로그를 처음부터 재생하지 않고, 마지막 복제 로그 엔트리를 기록한 노드의 상태를 그대로 복사합니다. 둘째, merge는 로컬에서 다시 수행하거나 다른 노드에서 결과 파트를 가져와 재생합니다. 동작 방식은 설정할 수 있으며 CPU 사용량과 네트워크 I/O 사이의 균형을 조정할 수 있습니다. 예를 들어, 데이터 센터 간 복제는 운영 비용을 최소화하기 위해 일반적으로 로컬 merge를 선호합니다. 셋째, 노드는 서로 독립적인 복제 로그 엔트리를 병렬로 재생합니다. 이는 예를 들어 동일한 테이블에 연속적으로 insert된 새 ^^파트^^를 가져오는 작업이나, 서로 다른 테이블에 대한 연산을 포함합니다.
3.7 ACID 준수
동시 읽기 및 쓰기 작업의 성능을 극대화하기 위해 ClickHouse는 가능한 한 래치(latch) 사용을 피합니다. 쿼리는 쿼리 시작 시점에 생성된, 관련된 모든 테이블의 모든 ^^파트^^에 대한 스냅샷을 대상으로 실행됩니다. 이를 통해 병렬 INSERT 또는 머지(섹션 3.1)에 의해 새로 삽입된 ^^파트^^는 실행에 참여하지 않도록 보장합니다. ^^파트^^가 동시에 수정되거나 제거되는 것(섹션 3.4)을 방지하기 위해, 처리 중인 ^^파트^^의 참조 카운트는 쿼리가 실행되는 동안 증가된 상태로 유지됩니다. 형식적으로 이는 버전 관리된 ^^파트^^에 기반한 MVCC 변형[6]에 의해 실현되는 스냅샷 격리에 해당합니다. 그 결과, 스냅샷이 생성되는 시점에 발생하는 동시 쓰기 작업이 각각 단일 파트에만 영향을 미치는 예외적인 경우를 제외하면, SQL 문은 일반적으로 ACID를 준수하지 않습니다.
실무에서는 ClickHouse의 대부분의 쓰기 부하가 높은 의사결정용 사용 사례가 정전이 발생할 경우 일부 신규 데이터 손실의 작은 위험을 허용합니다. 데이터베이스는 이를 활용하여 기본적으로 새로 삽입된 ^^파트^^를 디스크에 커밋(fsync)하도록 강제하지 않고, 그 대신 ^^원자성^^을 일부 포기하는 대가로 커널이 쓰기 작업을 배치할 수 있도록 합니다.
4 QUERY PROCESSING LAYER
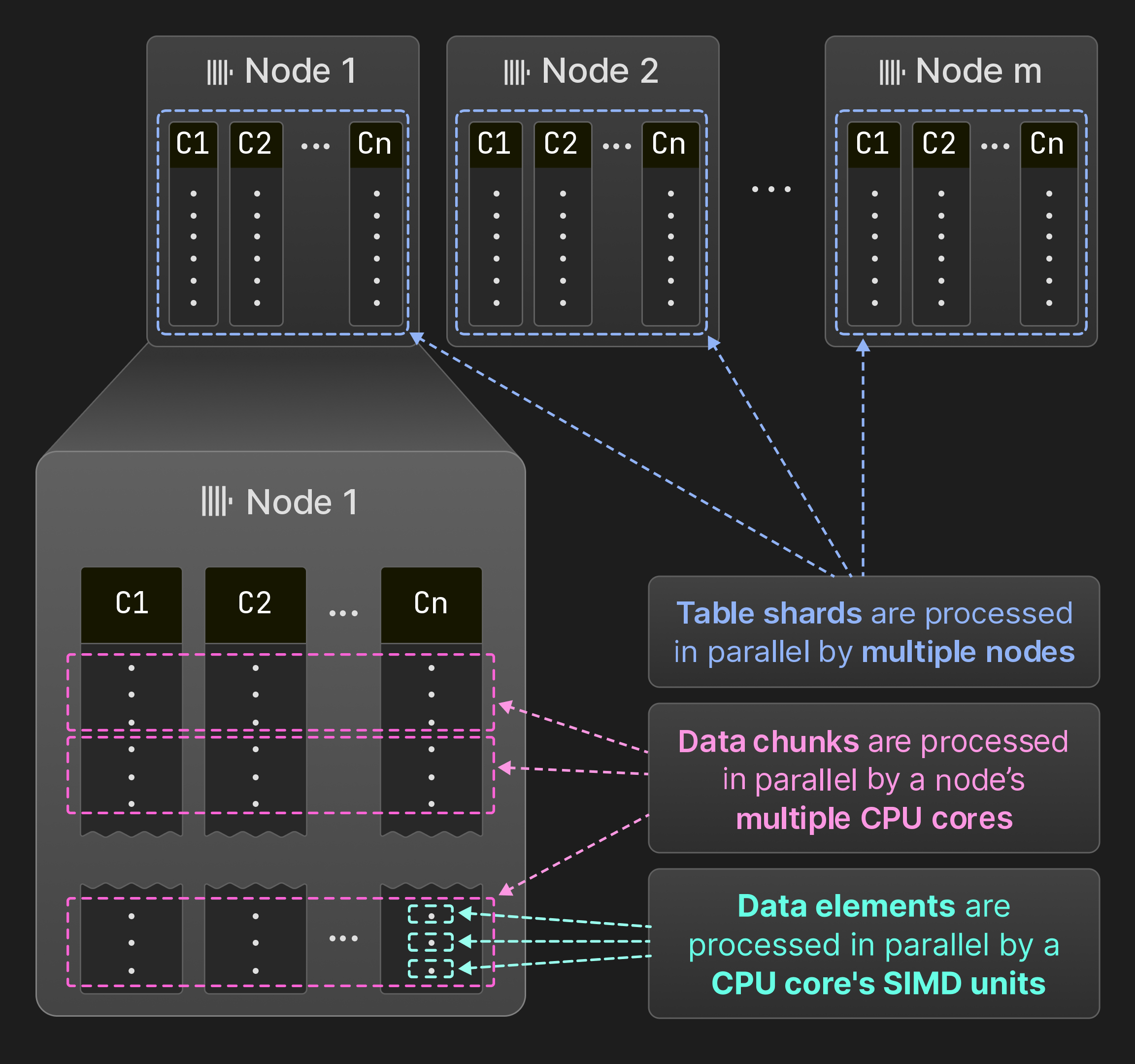
그림 7: SIMD 유닛, 코어 및 노드 간의 병렬화.
그림 7에 나타난 것처럼, ClickHouse는 데이터 요소, 데이터 청크, 테이블 세그먼트 수준에서 쿼리를 병렬화합니다. 여러 데이터 요소는 SIMD 명령어를 사용하여 연산자 내에서 한 번에 처리될 수 있습니다. 단일 노드에서는 쿼리 엔진이 여러 스레드에서 연산자를 동시에 실행합니다. ClickHouse는 MonetDB/X100 [11]과 동일한 벡터화 모델을 사용합니다. 즉, 연산자는 단일 행이 아니라 여러 행(데이터 청크)을 생성, 전달 및 소비하여 가상 함수 호출의 오버헤드를 최소화합니다. 소스 테이블이 서로 겹치지 않는 테이블 세그먼트로 분할되어 있는 경우, 여러 노드가 세그먼트를 동시에 스캔할 수 있습니다. 그 결과 모든 하드웨어 리소스를 완전히 활용할 수 있으며, 노드를 추가하여 수평적으로, 코어를 추가하여 수직적으로 쿼리 처리를 확장할 수 있습니다.
이 절의 나머지 부분에서는 먼저 데이터 요소, 데이터 청크 및 ^^세그먼트^^ 단위의 병렬 처리를 보다 자세히 설명합니다. 그런 다음 쿼리 성능을 극대화하기 위한 선택된 핵심 최적화를 제시합니다. 마지막으로, 동시에 실행되는 여러 쿼리가 있는 상황에서 ClickHouse가 공유 시스템 리소스를 어떻게 관리하는지 설명합니다.
4.1 SIMD Parallelization
연산자 사이에서 여러 개의 행을 한 번에 전달하면 벡터화(vectorization)를 적용할 수 있는 기회를 제공합니다. 벡터화는 수동으로 작성한 intrinsic 기반 기법[64, [80]](#page-13-19)이거나, 컴파일러 자동 벡터화[25]에 기반합니다. 벡터화의 이점을 얻는 코드는 서로 다른 계산 커널로 컴파일됩니다. 예를 들어, 쿼리 연산자의 내부 핵심 루프(inner hot loop)는 비벡터화 커널, 자동 벡터화된 AVX2 커널, 그리고 수동으로 벡터화된 AVX-512 커널 형태로 구현될 수 있습니다. 가장 빠른 커널은 cpuid 명령을 기반으로 런타임에 선택됩니다. 이 접근 방식 덕분에 ClickHouse는 최소 요구 사항으로 SSE 4.2만 필요로 하는, 최대 15년 된 시스템에서도 실행되는 동시에 최신 하드웨어에서는 상당한 속도 향상을 제공합니다.
4.2 Multi-Core Parallelization
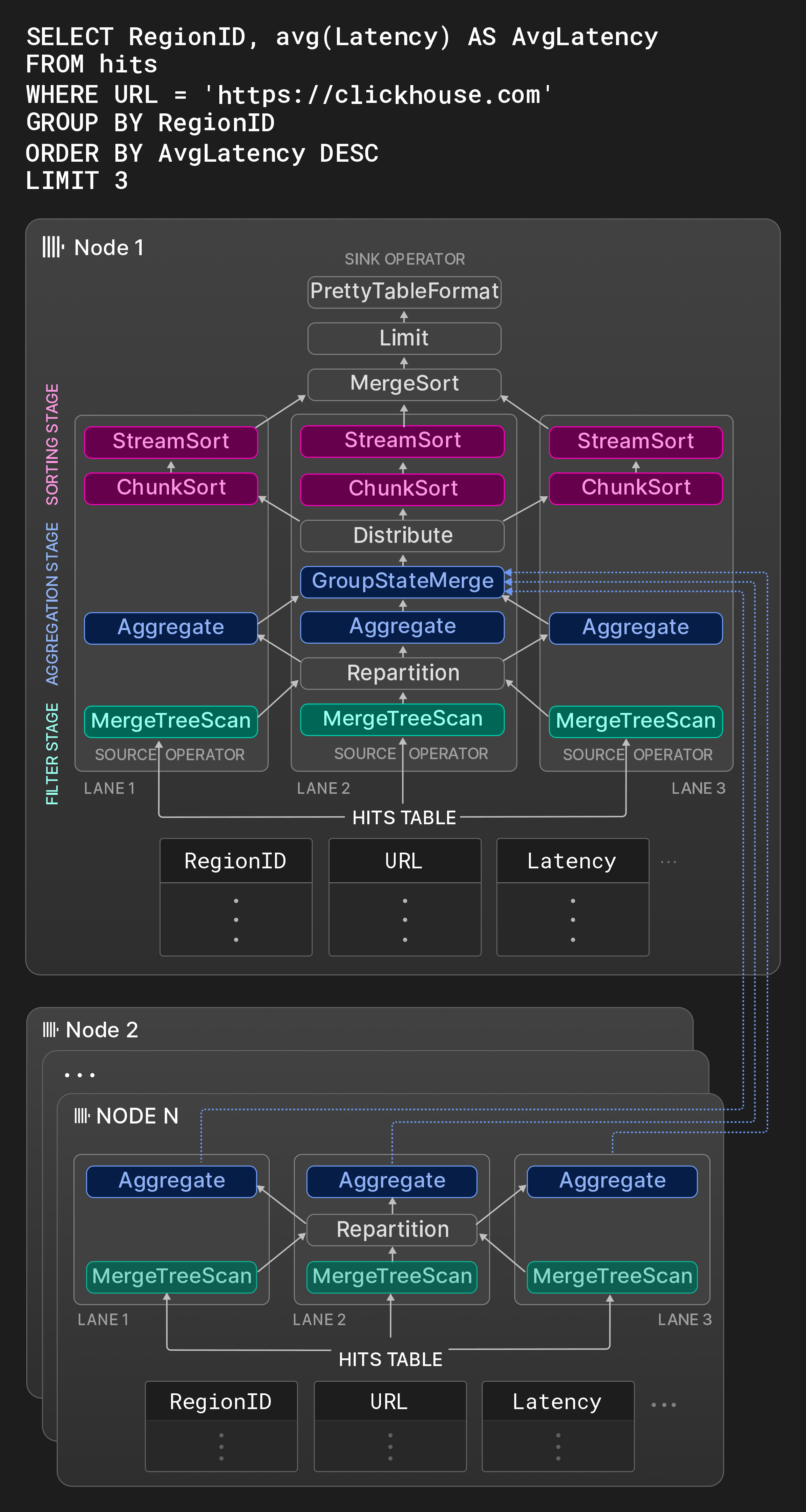
그림 8: 세 개의 레인을 가진 물리 연산자 계획.
ClickHouse는 SQL 쿼리를 물리적 계획 연산자의 유향 그래프로 변환하는 전통적인 접근 방식 [31]을 따릅니다. 연산자 계획의 입력은 네이티브 형식 또는 지원되는 서드파티 형식(5절 5) 참고) 중 하나로 데이터를 읽는 특수 소스 연산자로 표현됩니다. 마찬가지로, 특수 싱크 연산자는 결과를 원하는 출력 형식으로 변환합니다. 물리 연산자 계획은 쿼리 컴파일 시점에 설정 가능한 최대 워커 스레드 수(기본값은 코어 수)와 소스 테이블 크기에 따라 서로 독립적인 실행 레인으로 전개됩니다. 레인은 병렬 연산자가 처리할 데이터를 서로 겹치지 않는 범위로 분해합니다. 병렬 처리 기회를 극대화하기 위해 레인은 가능한 한 늦게 병합합니다.
예로, 그림 8의 Node 1 박스는 페이지 노출 통계가 있는 테이블에 대한 전형적인 OLAP 쿼리의 연산자 그래프를 보여 줍니다. 첫 번째 단계에서 소스 테이블의 서로 분리된 세 개의 범위가 동시에 필터링됩니다. Repartition exchange 연산자는 처리 스레드가 균등하게 활용되도록 결과 청크를 첫 번째 단계와 두 번째 단계 사이에서 동적으로 라우팅합니다. 스캔한 범위의 선택도가 크게 다를 경우, 첫 번째 단계 이후 레인 간의 부하가 불균형해질 수 있습니다. 두 번째 단계에서는 필터를 통과한 행이 RegionID로 그룹화됩니다. Aggregate 연산자는 RegionID를 그룹화 컬럼으로 사용하고, avg()를 위한 그룹별 합계와 개수를 부분 집계 상태로 유지하는 로컬 결과 그룹을 관리합니다. 로컬 집계 결과는 결국 GroupStateMerge 연산자에 의해 글로벌 집계 결과로 병합됩니다. 이 연산자는 파이프라인 차단 지점(pipeline breaker)이기도 하므로, 집계 결과가 완전히 계산된 이후에만 세 번째 단계를 시작할 수 있습니다. 세 번째 단계에서는 결과 그룹이 먼저 Distribute exchange 연산자에 의해 크기가 동일한 세 개의 서로 분리된 파티션으로 분할되고, 그런 다음 AvgLatency 기준으로 정렬됩니다. 정렬은 세 단계로 수행됩니다. 먼저 ChunkSort 연산자가 각 파티션의 개별 청크를 정렬합니다. 두 번째로 StreamSort 연산자는 로컬 정렬 결과를 유지하고, 여기에 들어오는 정렬된 청크를 2-way 병합 정렬을 사용해 결합합니다. 마지막으로 MergeSort 연산자가 로컬 결과를 k-way 정렬을 통해 결합하여 최종 결과를 얻습니다.
연산자는 상태 머신(state machine)이며 입력 및 출력 포트를 통해 서로 연결됩니다. 연산자의 가능한 세 가지 상태는 need-chunk, ready, done입니다. need-chunk에서 ready로 전이하려면 청크를 연산자의 입력 포트에 배치합니다. ready에서 done으로 전이하려면 연산자가 입력 청크를 처리하고 출력 청크를 생성합니다. done에서 need-chunk로 전이하려면 연산자의 출력 포트에서 출력 청크를 제거합니다. 서로 연결된 두 연산자에서 첫 번째와 세 번째 상태 전이는 결합된 단계로만 수행될 수 있습니다. 소스 연산자(싱크 연산자)는 ready와 done(need-chunk와 done) 상태만 가집니다.
워커 스레드는 물리 연산자 계획을 지속적으로 순회하면서 상태 전이를 수행합니다. CPU 캐시 효율을 높이기 위해 계획에는 동일한 스레드가 동일한 레인에서 연속된 연산자를 처리해야 한다는 힌트가 포함됩니다. 병렬 처리는 한 단계 내에서 서로 분리된 입력을 가로질러 수평적으로(예: 그림 8에서 Aggregate 연산자는 동시에 실행됨) 이루어지고, 파이프라인 차단 지점으로 분리되지 않은 단계들을 세로로 가로질러(예: 그림 8에서 동일 레인 내의 Filter와 Aggregate 연산자가 동시에 실행될 수 있음) 이루어집니다. 새로운 쿼리가 시작되거나 동시 쿼리가 종료될 때 과도하거나 부족한 스레드 할당을 피하기 위해, 병렬성 수준은 쿼리 도중에도 쿼리 시작 시 지정된 해당 쿼리의 워커 스레드 최대 수와 1 사이에서 변경될 수 있습니다(4.5절 4.5) 참고).
연산자는 런타임에 두 가지 방식으로 쿼리 실행에 추가적인 영향을 줄 수 있습니다. 첫째, 연산자는 동적으로 새로운 연산자를 생성하고 연결할 수 있습니다. 이는 주로 메모리 사용량이 설정 가능한 임계값을 초과할 때 쿼리를 취소하는 대신 외부 집계, 정렬, 조인 알고리즘으로 전환하는 데 사용됩니다. 둘째, 연산자는 워커 스레드가 비동기 큐로 이동하도록 요청할 수 있습니다. 이는 원격 데이터를 기다리는 동안 워커 스레드를 보다 효율적으로 사용할 수 있게 합니다.
ClickHouse의 쿼리 실행 엔진과 morsel 기반 병렬 처리[44]는 일반적으로 lane이 서로 다른 코어/NUMA 소켓에서 실행되고 워커 스레드가 다른 lane의 작업을 훔쳐올 수 있다는 점에서 유사합니다. 또한 중앙 스케줄링 컴포넌트가 없으며, 워커 스레드는 연산자 플랜을 지속적으로 순회하면서 개별적으로 작업을 선택합니다. morsel 기반 병렬 처리와 달리 ClickHouse는 플랜에 최대 병렬 처리 수준을 미리 고정하고, 기본 morsel 크기(약 100,000행)에 비해 훨씬 큰 범위를 사용하여 소스 테이블을 파티션합니다. 이는 일부 경우(예: 서로 다른 lane에서 필터 연산자의 런타임이 크게 차이날 때) 지연을 유발할 수 있지만, Repartition과 같은 exchange 연산자를 적극적으로 사용하면 적어도 이러한 불균형이 여러 단계에 걸쳐 누적되는 것은 방지할 수 있음을 확인했습니다.
4.3 다중 노드 병렬화
쿼리의 소스 테이블이 세그먼트로 분할되어 있는 경우, 쿼리를 수신한 노드(initiator 노드)의 쿼리 옵티마이저는 가능한 한 많은 작업을 다른 노드에서 수행하도록 합니다. 다른 노드의 결과는 쿼리 플랜의 서로 다른 지점에 통합될 수 있습니다. 쿼리에 따라 원격 노드는 1. 소스 테이블의 원시 컬럼 데이터를 initiator 노드로 스트리밍하거나, 2. 소스 컬럼을 필터링하고 남은 행만 전송하거나, 3. 필터와 집계 단계를 실행하고 부분 집계 상태가 포함된 로컬 결과 그룹을 전송하거나, 4. 필터, 집계, 정렬을 포함한 전체 쿼리를 실행할 수 있습니다.
그림 8의 노드 2 ... N은 hits 테이블의 세그먼트를 보유한 다른 노드에서 실행되는 플랜 조각을 보여 줍니다. 이 노드들은 로컬 데이터를 필터링하고 그룹화한 뒤 그 결과를 initiator 노드로 전송합니다. 노드 1의 GroupStateMerge 연산자는 결과 그룹이 최종적으로 정렬되기 전에 로컬 및 원격 결과를 병합합니다.
4.4 총체적 성능 최적화
이 절에서는 쿼리 실행의 서로 다른 단계에 적용되는 핵심 성능 최적화 기법들을 선별하여 제시합니다.
쿼리 최적화(Query optimization). 첫 번째 최적화 그룹은 쿼리의 AST로부터 얻은 의미 기반 쿼리 표현 위에서 적용됩니다. 이러한 최적화의 예로는 상수 접기(constant folding) (예: concat(lower('a'),upper('b'))가 'aB'로 대체), 특정 집계 함수로부터 스칼라 추출 (예: sum(a2)가 2 * sum(a)로 대체), 공통 부분식 제거, 여러 개의 동등 비교를 OR로 연결한 필터를 IN 리스트로 변환 (예: x=c OR x=d가 x IN (c,d)로 대체) 등이 있습니다. 최적화된 의미 기반 쿼리 표현은 이후 논리 연산자 플랜(logical operator plan)으로 변환됩니다. 논리 플랜 상의 최적화에는 필터 푸시다운(filter pushdown), 함수 평가 및 정렬 단계의 재배치 등이 포함되며, 둘 중 어느 쪽의 비용이 더 큰지에 대한 추정에 따라 결정됩니다. 마지막으로, 논리 쿼리 플랜은 물리 연산자 플랜(physical operator plan)으로 변환됩니다. 이 변환 과정에서는 관련 테이블 엔진(table engines)의 특성을 활용할 수 있습니다. 예를 들어 ^^MergeTree^^-^^table engine^^의 경우, ORDER BY 컬럼이 ^^primary key^^의 접두(prefix)를 형성하면 데이터를 디스크 순서대로 읽을 수 있으므로, 플랜에서 정렬 연산자를 제거할 수 있습니다. 또한, 집계에서 사용되는 그룹화 컬럼이 ^^primary key^^의 접두를 이루는 경우, ClickHouse는 정렬 집계(sort aggregation) [33], 즉 사전 정렬된 입력에서 동일한 값의 구간(run)을 직접 집계하는 방식을 사용할 수 있습니다. 해시 집계(hash aggregation)와 비교할 때, 정렬 집계는 메모리 사용량이 현저히 적고, 각 구간의 처리가 끝나자마자 집계 값을 다음 연산자로 바로 전달할 수 있습니다.
쿼리 컴파일(Query compilation). ClickHouse는 LLVM 기반 쿼리 컴파일을 사용하여 인접한 플랜 연산자들을 동적으로 융합합니다 [38, [53]](#page-13-0). 예를 들어, a * b + c + 1 식을 세 개의 연산자가 아닌 단일 연산자로 결합할 수 있습니다. 표현식 외에도 ClickHouse는 여러 집계 함수를 동시에 평가하는 경우(즉, GROUP BY를 위한 경우)와 두 개 이상 정렬 키가 있는 정렬에 대해서도 컴파일을 활용합니다. 쿼리 컴파일은 가상 호출 수를 줄이고, 데이터를 레지스터나 CPU 캐시에 유지하며, 실행해야 할 코드가 줄어들기 때문에 분기 예측기의 성능을 향상시킵니다. 추가로, 런타임 컴파일은 논리적 최적화 및 컴파일러에 구현된 피홀(peephole) 최적화 등 다양한 최적화를 가능하게 하며, 로컬에서 사용 가능한 가장 빠른 CPU 명령어에 접근할 수 있게 합니다. 컴파일은 동일한 일반 표현식, 집계 표현식 또는 정렬 표현식이 서로 다른 쿼리에 의해 설정 가능한 횟수 이상 반복 실행될 때에만 시작됩니다. 컴파일된 쿼리 연산자는 캐시에 저장되며 이후 쿼리에서 재사용될 수 있습니다.[7]
^^Primary key^^ 인덱스 평가. ClickHouse는 WHERE 조건을 평가할 때, 해당 조건의 논리곱 정규형(conjunctive normal form, CNF)에 포함된 필터 절 일부가 ^^primary key^^ 컬럼의 접두를 구성하면 ^^primary key^^ 인덱스를 사용합니다. ^^primary key^^ 인덱스는 키 값의 사전식 정렬 구간(range)을 기준으로 왼쪽에서 오른쪽으로 분석됩니다. ^^primary key^^ 컬럼에 해당하는 필터 절은 삼진 논리로 평가되며, 해당 구간의 값들에 대해 모두 참, 모두 거짓, 또는 참/거짓이 섞여 있는지로 구분됩니다. 마지막 경우에는 구간을 더 작은 하위 구간으로 분할하고 재귀적으로 분석합니다. 필터 조건에 포함된 함수에 대해서도 추가 최적화가 있습니다. 첫째, 함수에는 단조성(monotonicity)을 설명하는 특성이 정의되어 있으며, 예를 들어 toDayOfMonth(date)는 한 달 내에서는 구간별 단조(piecewise monotonic)입니다. 단조성 특성은 정렬된 입력 키 값 구간에 대해 함수가 정렬된 결과를 산출하는지 추론할 수 있게 해 줍니다. 둘째, 일부 함수는 주어진 함수 결과의 역상(preimage)을 계산할 수 있습니다. 이는 키 컬럼에 대한 함수 호출과 상수 비교를, 키 컬럼 값과 그 역상을 비교하는 것으로 대체하는 데 사용됩니다. 예를 들어 toYear(k) = 2024는 k >= 2024-01-01 && k < 2025-01-01로 대체할 수 있습니다.
데이터 스키핑(Data skipping). ClickHouse는 3.2절에서 소개한 데이터 구조들을 사용하여 쿼리 실행 시 데이터 읽기를 회피하려고 시도합니다. 추가로, 서로 다른 컬럼에 대한 필터는 휴리스틱과 (선택적인) 컬럼 통계를 기반으로 추정된 선택도(selectivity)가 높은 순서대로 순차적으로 평가됩니다. 최소 한 개 이상의 일치하는 행을 포함하는 데이터 청크만 다음 프레디케이트로 전달됩니다. 이렇게 함으로써 각 프레디케이트를 거칠 때마다 읽어야 하는 데이터 양과 수행해야 하는 연산 수가 점진적으로 감소합니다. 이 최적화는 최소 하나의 높은 선택도를 가진 프레디케이트가 존재하는 경우에만 적용되며, 그렇지 않으면 모든 프레디케이트를 병렬로 평가하는 경우와 비교해 쿼리 지연 시간이 악화될 수 있습니다.
Hash tables. 해시 테이블은 집계와 해시 조인을 위한 기본적인 자료 구조입니다. 올바른 유형의 해시 테이블을 선택하는 것은 성능에 매우 중요합니다. ClickHouse는 해시 함수, allocator, cell 타입, 리사이즈 정책을 변형 지점으로 사용하는 범용 해시 테이블 템플릿으로부터 다양한 해시 테이블(2024년 3월 기준 30개 이상)을 인스턴스화합니다. 그룹화 컬럼의 데이터 타입, 해시 테이블 카디널리티 추정값, 기타 요인에 따라 각 쿼리 연산자마다 가장 빠른 해시 테이블이 개별적으로 선택됩니다. 해시 테이블에 대해 구현된 추가 최적화는 다음과 같습니다.
- 매우 큰 키 집합을 지원하기 위해 해시의 첫 바이트를 기준으로 256개의 서브 테이블로 구성된 2레벨(two-level) 레이아웃,
- 서로 다른 문자열 길이에 대해 서로 다른 해시 함수를 사용하는 4개의 서브 테이블을 가진 문자열 해시 테이블 [79],
- 키 개수가 적을 때 키를 직접 버킷 인덱스로 사용하는(즉, 해싱을 하지 않는) 룩업 테이블,
- 비교 비용이 큰 경우(예: 문자열, AST) 충돌 해결을 빠르게 하기 위해 해시 값을 값에 내장하는 방식,
- 불필요한 리사이즈를 피하기 위해 런타임 통계로부터 예측된 크기에 기반해 해시 테이블을 생성하는 방식,
- 단일 메모리 슬랩에서 동일한 생성/소멸 라이프사이클을 가진 여러 개의 작은 해시 테이블을 할당하는 방식,
- 해시 맵별·셀별 버전 카운터를 사용하여 재사용을 위해 해시 테이블을 즉시 비우는 방식,
- 키를 해싱한 후 값을 조회할 때 속도를 높이기 위해 CPU prefetch(
__builtin_prefetch)를 사용하는 방식.
Joins. ClickHouse는 처음에는 조인을 제한적으로만 지원했기 때문에, 역사적으로 많은 사용 사례에서 비정규화된 테이블을 사용했습니다. 현재 데이터베이스는 SQL에서 사용 가능한 모든 조인 유형(내부, 좌/우/완전 외부, 교차, as-of)과 함께 해시 조인(naïve, grace), sort-merge 조인, 빠른 키-값 룩업(일반적으로 dictionary)에 적합한 테이블 엔진용 인덱스 조인과 같은 다양한 조인 알고리즘을 제공합니다.
조인은 가장 비용이 큰 데이터베이스 연산 중 하나이므로, 이상적으로는 공간/시간 절충을 구성 가능하게 하는 고전적인 조인 알고리즘의 병렬 변형을 제공하는 것이 중요합니다. 해시 조인의 경우 ClickHouse는 [7]에 제시된 non-blocking, shared partition 알고리즘을 구현합니다. 예를 들어 그림 9의 쿼리는 페이지 히트 통계 테이블에 대한 self-join을 통해 사용자가 URL 사이를 어떻게 이동하는지를 계산합니다. 조인의 build 단계는 원본 테이블의 서로 겹치지 않는 세 개 범위를 처리하는 세 개의 레인으로 분할됩니다. 전역 해시 테이블 대신 파티션된 해시 테이블이 사용됩니다. (일반적으로 세 개인) 워커 스레드는 해시 함수의 모듈러 연산을 계산하여 build 측 입력 행마다 대상 파티션을 결정합니다. 해시 테이블 파티션에 대한 접근은 Gather exchange 연산자를 사용하여 동기화됩니다. probe 단계는 입력 튜플의 대상 파티션을 이와 유사한 방식으로 찾습니다. 이 알고리즘은 튜플마다 두 번의 해시 계산을 추가로 수행하지만, 해시 테이블 파티션 수에 따라 build 단계에서의 래치 경합을 크게 줄여 줍니다.
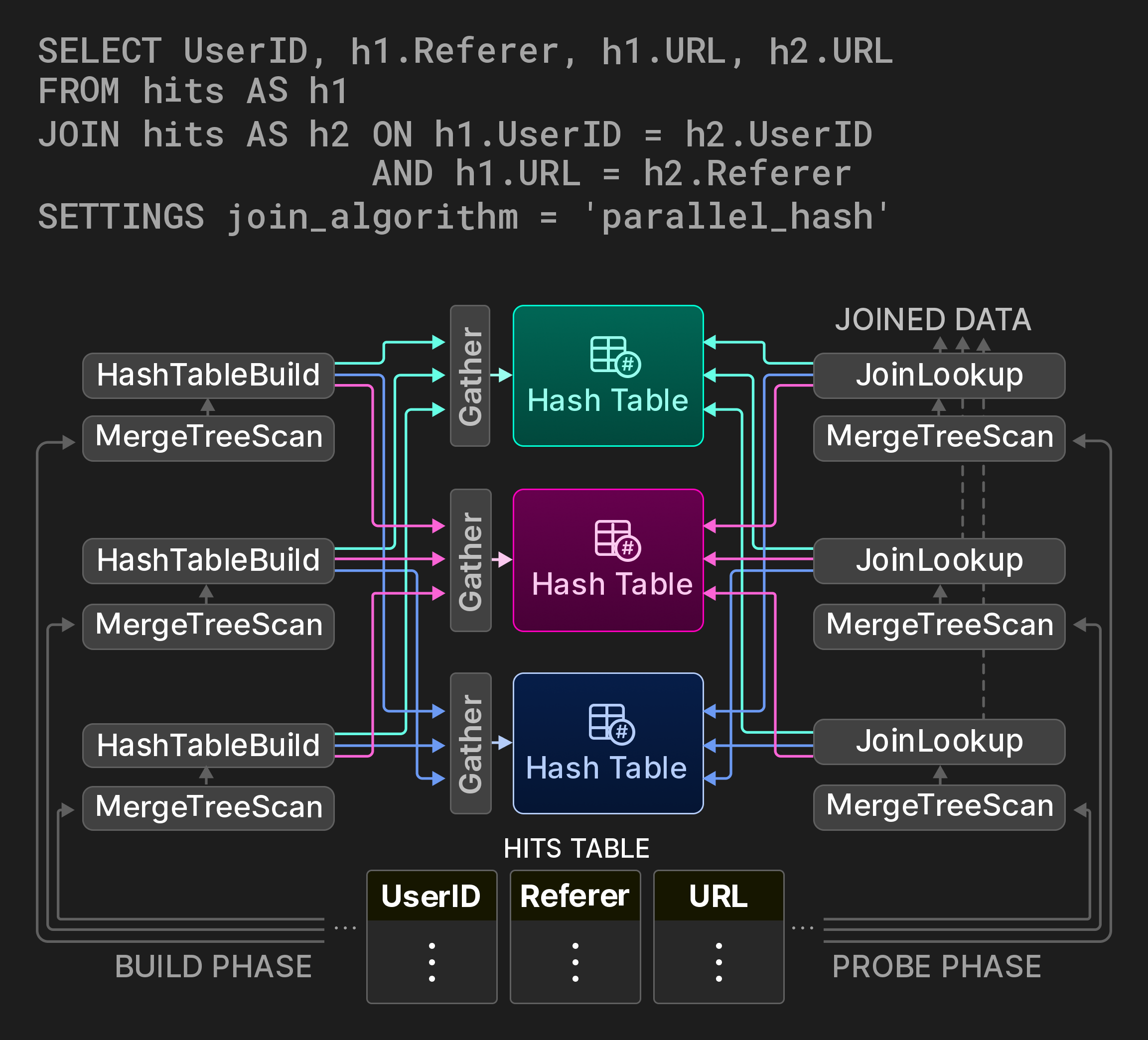
그림 9: 세 개의 해시 테이블 파티션을 사용하는 병렬 해시 조인.
4.5 Workload Isolation
ClickHouse는 동시성 제어, 메모리 사용 한도, I/O 스케줄링을 제공하여 쿼리를 워크로드 클래스 단위로 격리할 수 있도록 합니다. 특정 워크로드 클래스에 대해 공유 리소스(CPU 코어, DRAM, 디스크 및 네트워크 I/O)의 한도를 설정하면, 해당 클래스의 쿼리가 다른 중요한 비즈니스 쿼리에 영향을 주지 않도록 보장합니다.
동시성 제어는 많은 수의 동시 쿼리가 있는 상황에서 스레드 과다 할당을 방지합니다. 보다 구체적으로, 쿼리당 워커 스레드 수는 사용 가능한 CPU 코어 수에 대한 지정된 비율을 기준으로 동적으로 조정됩니다.
ClickHouse는 서버, 사용자, 쿼리 수준에서 메모리 할당의 바이트 크기를 추적하여 유연한 메모리 사용 한도 설정을 가능하게 합니다. 메모리 오버커밋을 사용하면 쿼리가 보장된 메모리보다 추가로 사용 가능한 여유 메모리를 활용할 수 있으며, 동시에 다른 쿼리에 대한 메모리 한도는 보장됩니다. 또한 aggregation, sort, join 절의 메모리 사용량에 한도를 둘 수 있으며, 메모리 한도를 초과할 경우 외부 알고리즘을 사용하는 방식으로 대체되도록 할 수 있습니다.
마지막으로, I/O 스케줄링을 통해 워크로드 클래스별로 최대 대역폭, 동시 처리 요청 수(in-flight requests), 그리고 정책(예: FIFO, SFC [32])에 기반하여 로컬 및 원격 디스크 접근을 제한할 수 있습니다.
5 통합 레이어
실시간 의사결정 애플리케이션은 여러 위치에 있는 데이터에 대한 효율적이고 낮은 지연 시간의 접근에 의존하는 경우가 많습니다. OLAP 데이터베이스에서 외부 데이터를 사용할 수 있도록 하는 두 가지 접근 방식이 있습니다. 푸시 기반 데이터 접근 방식에서는 제3자 컴포넌트가 데이터베이스와 외부 데이터 저장소를 연결합니다. 이러한 예로는 원격 데이터를 대상 시스템으로 푸시하는 특수한 추출-변환-적재(ETL) 도구가 있습니다. 풀 기반 모델에서는 데이터베이스 자체가 원격 데이터 소스에 연결하여 쿼리를 위해 로컬 테이블로 데이터를 가져오거나 원격 시스템으로 데이터를 내보냅니다. 푸시 기반 접근 방식이 더 다양하고 일반적이지만, 더 큰 아키텍처 공간과 확장성 병목 현상을 수반합니다. 반면, 데이터베이스에서 직접 원격 연결을 제공하면 로컬 데이터와 원격 데이터 간의 조인과 같은 흥미로운 기능을 제공하면서도 전체 아키텍처를 단순하게 유지하고 인사이트 도출 시간을 단축할 수 있습니다.
이 섹션의 나머지 부분에서는 원격 위치의 데이터에 접근하기 위한 ClickHouse의 풀 기반 데이터 통합 방법을 살펴봅니다. SQL 데이터베이스에서 원격 연결이라는 개념은 새로운 것이 아닙니다. 예를 들어, 2001년에 도입되고 2011년부터 PostgreSQL에서 구현된 [35] SQL/MED 표준 [65]은 외부 데이터를 관리하기 위한 통합 인터페이스로 외부 데이터 래퍼를 제안합니다. 다른 데이터 저장소 및 저장 형식과의 최대 상호 운용성은 ClickHouse의 설계 목표 중 하나입니다. 2024년 3월 기준으로 ClickHouse는 모든 분석 데이터베이스 중에서 가장 많은 내장 데이터 통합 옵션을 제공합니다.
외부 연결. ClickHouse는 ODBC, MySQL, PostgreSQL, SQLite, Kafka, Hive, MongoDB, Redis, S3/GCP/Azure 객체 저장소 및 다양한 데이터 레이크를 포함하여 외부 시스템 및 저장 위치와의 연결을 위한 50개 이상의 통합 테이블 함수와 엔진을 제공합니다. 다음 보너스 그림(원본 vldb 논문의 일부가 아님)에 표시된 범주로 더 세분화합니다.
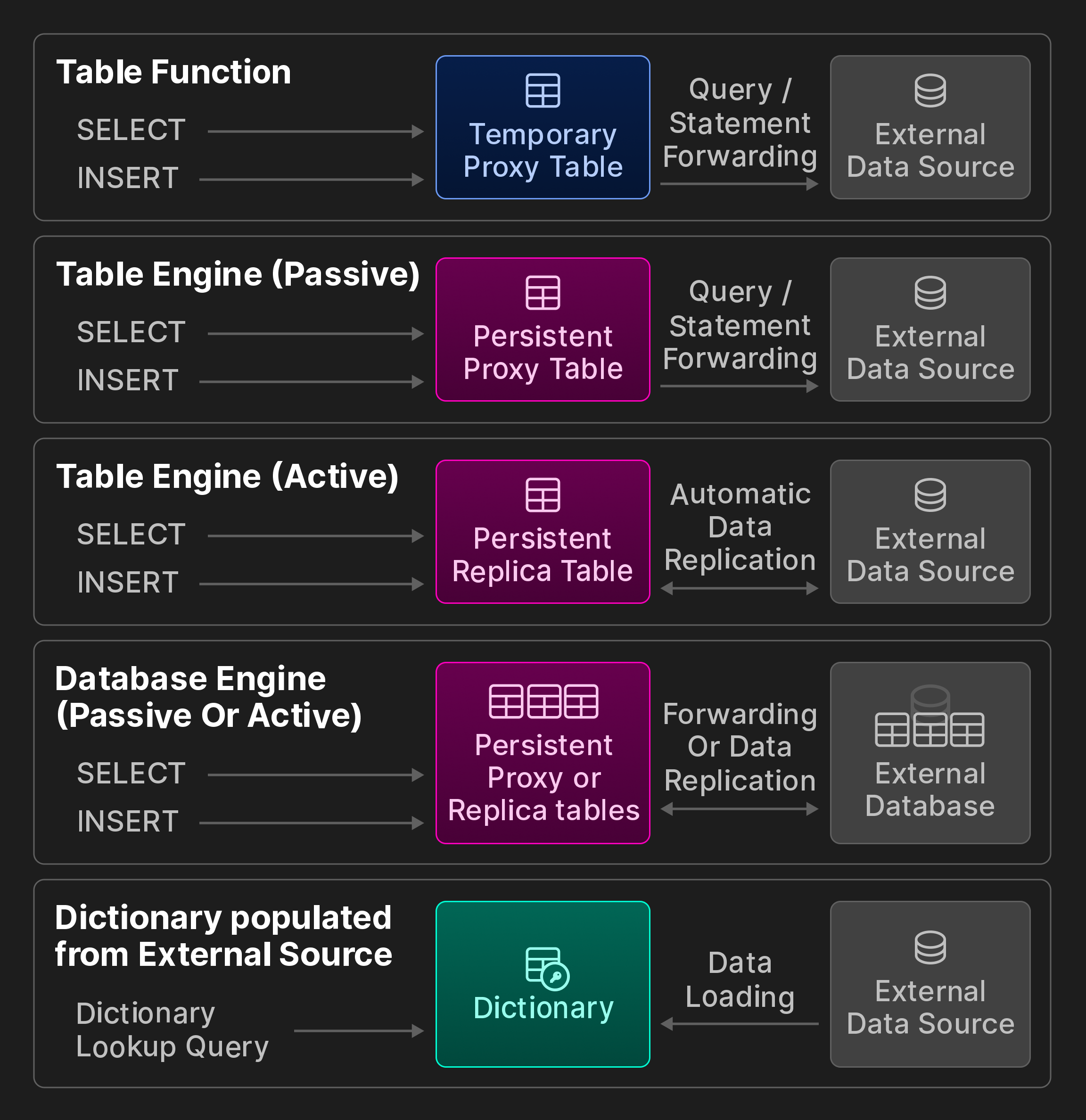
보너스 그림: ClickBench의 상호 운용성 옵션.
통합 테이블 함수를 사용한 임시 접근. 테이블 함수는 SELECT 쿼리의 FROM 절에서 호출되어 탐색적 임시 쿼리를 위해 원격 데이터를 읽을 수 있습니다. 또는 INSERT INTO TABLE FUNCTION 문을 사용하여 원격 저장소에 데이터를 쓰는 데 사용할 수 있습니다.
영구 접근. 원격 데이터 저장소 및 처리 시스템과의 영구 연결을 생성하는 세 가지 방법이 있습니다.
첫째, 통합 테이블 엔진은 MySQL 테이블과 같은 원격 데이터 소스를 영구 로컬 테이블로 나타냅니다. CREATE TABLE AS 구문을 SELECT 쿼리 및 테이블 함수와 결합하여 테이블 정의를 저장합니다. 예를 들어 원격 컬럼의 하위 집합만 참조하거나 스키마 추론을 사용하여 컬럼 이름과 동등한 ClickHouse 타입을 자동으로 결정하는 사용자 정의 스키마를 지정할 수 있습니다. 수동 및 능동 런타임 동작을 추가로 구분합니다. 수동 테이블 엔진은 쿼리를 원격 시스템으로 전달하고 결과로 로컬 프록시 테이블을 채웁니다. 반면, 능동 테이블 엔진은 원격 시스템에서 주기적으로 데이터를 가져오거나 PostgreSQL의 논리적 복제 프로토콜과 같은 방법을 통해 원격 변경 사항을 구독합니다. 결과적으로 로컬 테이블에는 원격 테이블의 전체 복사본이 포함됩니다.
둘째, 통합 데이터베이스 엔진은 원격 데이터 저장소의 테이블 스키마에 있는 모든 테이블을 ClickHouse에 매핑합니다. 전자와 달리 일반적으로 원격 데이터 저장소가 관계형 데이터베이스여야 하며 DDL 문에 대한 제한적인 지원을 추가로 제공합니다.
셋째, 딕셔너리는 해당 통합 테이블 함수 또는 엔진이 있는 거의 모든 가능한 데이터 소스에 대한 임의의 쿼리를 사용하여 채울 수 있습니다. 데이터가 원격 저장소에서 일정한 간격으로 가져오기 때문에 런타임 동작은 능동적입니다.
데이터 형식. 제3자 시스템과 상호 작용하려면 최신 분석 데이터베이스도 모든 형식의 데이터를 처리할 수 있어야 합니다. ClickHouse는 기본 형식 외에도 CSV, JSON, Parquet, Avro, ORC, Arrow 및 Protobuf를 포함하여 90개 이상의 형식을 지원합니다. 각 형식은 입력 형식(ClickHouse가 읽을 수 있음), 출력 형식(ClickHouse가 내보낼 수 있음) 또는 둘 다일 수 있습니다. Parquet와 같은 일부 분석 지향 형식은 쿼리 처리와도 통합되어 있습니다. 즉, 옵티마이저가 내장된 통계를 활용할 수 있으며 필터가 압축된 데이터에서 직접 평가됩니다.
호환성 인터페이스. 기본 바이너리 와이어 프로토콜 및 HTTP 외에도 클라이언트는 MySQL 또는 PostgreSQL 와이어 프로토콜 호환 인터페이스를 통해 ClickHouse와 상호 작용할 수 있습니다. 이 호환성 기능은 벤더가 아직 기본 ClickHouse 연결을 구현하지 않은 독점 애플리케이션(예: 특정 비즈니스 인텔리전스 도구)에서 접근을 가능하게 하는 데 유용합니다.
6 기능으로서의 성능
이 섹션에서는 성능 분석을 위한 내장 도구를 소개하고, 실제 환경의 쿼리와 벤치마크 쿼리를 사용하여 성능을 평가합니다.
6.1 Built-in Performance Analysis Tools
개별 쿼리 또는 백그라운드 작업에서 발생하는 성능 병목 현상을 조사하기 위한 다양한 도구가 제공됩니다. 모든 도구는 시스템 테이블을 기반으로 한 통일된 인터페이스를 통해 사용할 수 있습니다.
서버 및 쿼리 메트릭. 활성 파트 개수, 네트워크 처리량, 캐시 적중률과 같은 서버 수준 통계는, 읽은 블록 수나 인덱스 사용 통계와 같은 쿼리별 통계로 보완됩니다. 메트릭은 동기식(요청 시) 또는 구성 가능한 간격으로 비동기식으로 계산됩니다.
샘플링 프로파일러. 샘플링 프로파일러를 사용하여 서버 스레드의 콜 스택을 수집할 수 있습니다. 결과는 선택적으로 플레임그래프(flamegraph) 시각화 도구와 같은 외부 도구로 내보낼 수 있습니다.
OpenTelemetry 통합. OpenTelemetry는 여러 데이터 처리 시스템 전반에 걸쳐 데이터 행을 추적하기 위한 개방형 표준입니다 [8]. ClickHouse는 모든 쿼리 처리 단계에 대해 세분성을 구성할 수 있는 OpenTelemetry 로그 스팬을 생성할 수 있으며, 다른 시스템에서 생성된 OpenTelemetry 로그 스팬을 수집하고 분석할 수도 있습니다.
Explain 쿼리. 다른 데이터베이스와 마찬가지로, SELECT 쿼리 앞에 EXPLAIN을 사용하여 쿼리의 AST, 논리 및 물리 연산자 계획, 실행 시 동작에 대한 자세한 정보를 얻을 수 있습니다.
6.2 Benchmarks
벤치마크는 충분히 현실적이지 않다는 비판을 받아왔지만 [10, 52, 66, [74]](#page-13-24), 여전히 데이터베이스의 강점과 약점을 파악하는 데 유용합니다. 이하에서는 ClickHouse의 성능을 평가하는 데 벤치마크가 어떻게 사용되는지 설명합니다.
6.2.1 Denormalized Tables
정규화되지 않은 fact 테이블에 대한 필터 및 집계 쿼리는 역사적으로 ClickHouse의 주요 사용 사례입니다. 여기서는 ClickBench 실행 시간(runtime)을 보고합니다. ClickBench는 클릭스트림 및 트래픽 분석에 사용되는 임시(ad-hoc) 및 주기적 보고 쿼리를 시뮬레이션하는, 이와 같은 유형의 대표적인 워크로드입니다. 이 벤치마크는 웹에서 가장 큰 분석 플랫폼 중 하나에서 수집한, 익명 처리된 1억 개의 페이지 히트가 포함된 테이블에 대해 43개의 쿼리를 실행합니다. 온라인 대시보드 [17]는 2024년 6월 기준으로 45개가 넘는 상용 및 연구용 데이터베이스에 대해 측정된 값(콜드/핫 런타임, 데이터 임포트 시간, 디스크 상 크기)을 보여줍니다. 결과는 공개된 데이터 세트와 쿼리 [16]를 기반으로 독립적인 기여자들이 제출합니다. 이들 쿼리는 순차 및 인덱스 스캔 접근 경로를 테스트하며, CPU, IO 또는 메모리에 의해 병목이 되는 관계 연산자를 반복적으로 드러냅니다.
Figure 10은 분석용으로 자주 사용되는 데이터베이스에서 모든 ClickBench 쿼리를 순차적으로 실행했을 때의 총 상대 콜드 및 핫 런타임을 보여줍니다. 측정은 16 vCPU, 32 GB RAM, 5000 IOPS / 1000 MiB/s 디스크를 갖춘 단일 노드 AWS EC2 c6a.4xlarge 인스턴스에서 수행되었습니다. Redshift(ra3.4xlarge, 12 vCPU, 96 GB RAM) 및 Snowfake(warehouse size S: 2x8 vCPU, 2x16 GB RAM)를 위해서는 이에 상응하는 시스템을 사용했습니다. 물리적 데이터베이스 설계는 예를 들어 기본 키를 지정하는 정도로만 최소한으로 튜닝되었으며, 개별 컬럼의 압축 방식을 변경하거나, 프로젝션을 생성하거나, 데이터 스키핑 인덱스를 생성하지는 않았습니다. 또한 각 콜드 쿼리 실행 전에 Linux 페이지 캐시를 플러시하지만, 데이터베이스나 운영체제의 튜닝 파라미터는 조정하지 않습니다. 각 쿼리에 대해 데이터베이스 간 최단 런타임을 기준선으로 사용합니다. 다른 데이터베이스의 상대 쿼리 런타임은 ( + 10)/(_ + 10)으로 계산합니다. 데이터베이스의 총 상대 런타임은 쿼리별 비율의 기하평균입니다. 연구용 데이터베이스인 Umbra [54]가 전체적인 핫 런타임 측면에서 최상의 결과를 달성하긴 하지만, ClickHouse는 핫 및 콜드 런타임 모두에서 다른 모든 프로덕션급 데이터베이스를 능가합니다.
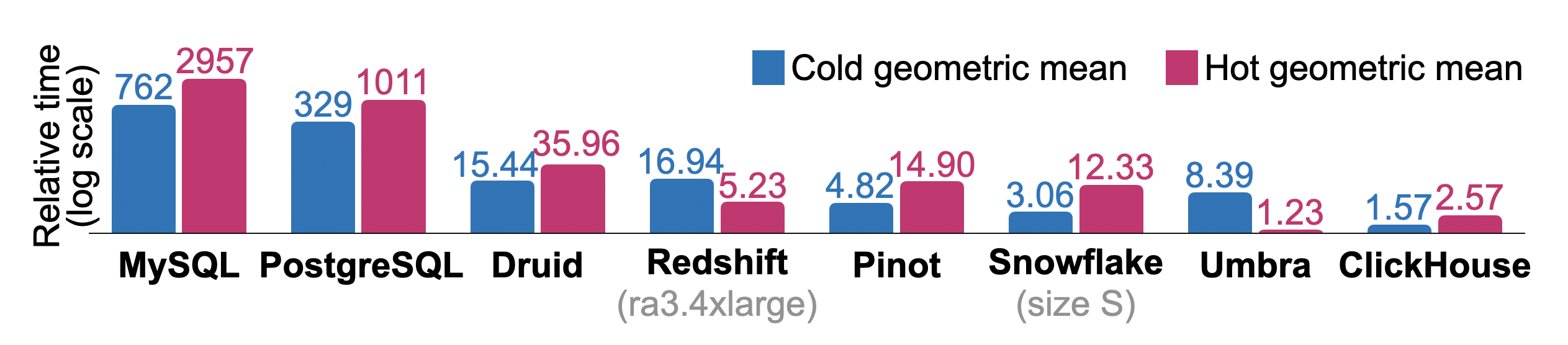
Figure 10: ClickBench의 상대 콜드 및 핫 런타임.
보다 다양한 워크로드에서 SELECT 성능을 장기간에 걸쳐 추적하기 위해, ClickHouse에서는 VersionsBench [19]라 불리는 네 가지 벤치마크 조합을 사용합니다. 이 벤치마크는 새 릴리스가 게시될 때마다 월 1회 실행되어 성능을 평가하고 [20], 성능 저하를 유발했을 가능성이 있는 코드 변경을 식별합니다. 개별 벤치마크는 다음과 같습니다. 1. 앞서 설명한 ClickBench, 2. 15개의 MgBench [21] 쿼리, 3. 6억 행이 있는 정규화되지 않은 Star Schema Benchmark [57] fact 테이블에 대한 13개의 쿼리, 4. 34억 행이 있는 NYC Taxi Rides에 대한 4개의 쿼리 [70].
Figure 11은 2018년 3월부터 2024년 3월까지 77개 ClickHouse 버전에 대해 측정한 VersionsBench 런타임의 변화를 보여줍니다. 개별 쿼리의 상대 런타임 차이를 보정하기 위해, 모든 버전에서의 최소 쿼리 런타임과의 비율을 가중치로 사용하여 기하평균으로 런타임을 정규화했습니다. VersionsBench 성능은 지난 6년 동안 1.72배 개선되었습니다. 장기 지원(LTS)이 제공되는 릴리스의 날짜는 x축에 표시되어 있습니다. 일부 기간 동안 성능이 일시적으로 저하되기도 했지만, LTS 릴리스는 일반적으로 이전 LTS 버전과 비슷하거나 더 나은 성능을 보입니다. 2022년 8월의 큰 개선은 Section 4.4.에 설명된, 컬럼별 필터 평가 기법에 의해 발생했습니다.
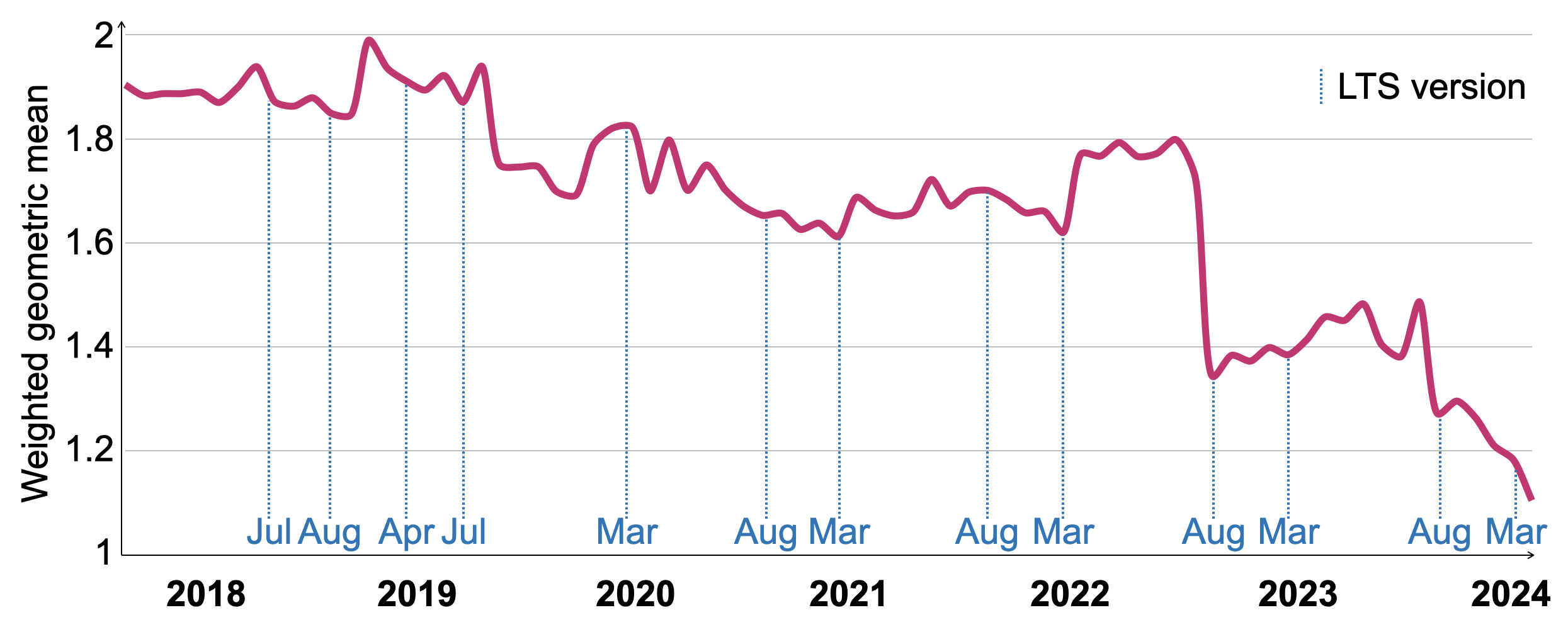
Figure 11: 2018-2024년 VersionsBench의 상대 핫 런타임.
6.2.2 Normalized tables
고전적인 데이터 웨어하우징에서는 데이터를 스타(star) 또는 snowfake 스키마를 사용해 모델링하는 경우가 많습니다. 여기서는 TPC-H 쿼리(스케일 팩터 100)의 런타임을 제시하지만, 정규화된 테이블이 ClickHouse의 새로운 사용 사례로 부상하고 있음을 함께 언급합니다. 그림 12는 4.4절에 설명된 병렬 해시 조인(parallel hash join) 알고리즘을 기반으로 한 TPC-H 쿼리의 핫 런타임(hot runtime)을 보여 줍니다. 측정은 64 vCPU, 128 GB RAM, 5000 IOPS / 1000 MiB/s 디스크를 가진 단일 노드 AWS EC2 c6i.16xlarge 인스턴스에서 수행되었습니다. 5회 실행 중 가장 빠른 결과를 기록했습니다. 비교를 위해, 유사한 규모의 Snowfake 시스템(웨어하우스 크기 L, 8x8 vCPU, 8x16 GB RAM)에서도 동일한 측정을 수행했습니다. 11개의 쿼리 결과는 표에서 제외했습니다. 쿼리 Q2, Q4, Q13, Q17 및 Q20-22는 ClickHouse v24.6 기준으로 아직 지원되지 않는 상호 연관된 서브쿼리(correlated subqueries)를 포함합니다. 쿼리 Q7-Q9 및 Q19는 실행 가능한 런타임을 달성하기 위해 조인 재정렬(join reordering) 및 조인 프레디케이트 푸시다운(join predicate pushdown)(둘 다 ClickHouse v24.6 기준으로 미지원)과 같은 조인에 대한 확장된 플랜 수준 최적화에 의존합니다. 서브쿼리 자동 디코릴레이션(subquery decorrelation)과 조인에 대한 더 나은 옵티마이저(optimizer) 지원은 2024년에 구현할 계획입니다 [18]. 나머지 11개 쿼리 중 5개(6개) 쿼리가 각각 ClickHouse(Snowfake)에서 더 빠르게 실행되었습니다. 앞서 언급한 최적화들이 성능에 중요하다고 알려져 있으므로 [27], 구현이 완료되면 이러한 쿼리들의 런타임이 추가로 개선될 것으로 예상합니다.

그림 12: TPC-H 쿼리에 대한 핫 런타임(초 단위).
7 RELATED WORK
분석 데이터베이스는 지난 수십 년 동안 학계와 산업계 모두에서 큰 관심을 받아 왔습니다 [1]. Sybase IQ [48], Teradata [72], Vertica [42], Greenplum [47]과 같은 초기 시스템은 비용이 많이 드는 배치 ETL 작업과 온프레미스 특성으로 인한 탄력성 부족이라는 특징이 있었습니다. 2010년대 초반에는 Snowfake [22], BigQuery [49], Redshift [4]와 같은 클라우드 네이티브 데이터 웨어하우스 및 데이터베이스-서비스(DBaaS) 제품이 등장하면서, 조직 입장에서 분석의 비용과 복잡성이 크게 감소하는 한편, 고가용성과 자동 리소스 스케일링의 이점을 함께 누리게 되었습니다. 보다 최근에는 Photon [5]과 Velox [62]와 같은 분석 실행 커널이 다양한 분석, 스트리밍, 머신 러닝 애플리케이션에서 사용할 수 있도록 공동 최적화된 데이터 처리 기능을 제공합니다.
목표와 설계 원칙 측면에서 ClickHouse와 가장 유사한 데이터베이스는 Druid [78]와 Pinot [34]입니다. 두 시스템 모두 높은 데이터 수집(ingestion) 속도를 갖는 실시간 분석(real-time analytics)을 목표로 합니다. ClickHouse와 마찬가지로 테이블은 세그먼트라고 불리는 수평 ^^파트^^로 분할됩니다. ClickHouse는 Section 3.3의 기법을 사용하여 작은 ^^파트^^들을 지속적으로 머지하고 선택적으로 데이터 용량을 줄이는 반면, Druid와 Pinot에서는 ^^파트^^가 영구적으로 불변 상태로 유지됩니다. 또한 Druid와 Pinot은 테이블을 생성, 변경, 검색하기 위해 특수화된 노드를 필요로 하는 반면, ClickHouse는 이러한 작업을 위해 단일 바이너리를 사용합니다.
Snowfake [22]는 공유 디스크 아키텍처에 기반한 인기 있는 상용 클라우드 데이터 웨어하우스입니다. 테이블을 마이크로 파티션으로 나누는 Snowfake의 접근 방식은 ClickHouse의 ^^파트^^ 개념과 유사합니다. Snowfake는 영속성을 위해 하이브리드 PAX 페이지 [3]를 사용하는 반면, ClickHouse의 저장 형식은 엄격히 열 지향(columnar)입니다. Snowfake는 또한 자동으로 생성되는 경량 인덱스 [31, [51]](#page-13-14)를 활용한 로컬 캐싱과 데이터 프루닝을 성능 향상의 주요 요인으로 강조합니다. ClickHouse의 기본 키와 유사하게, 사용자는 동일한 값을 갖는 데이터가 함께 위치하도록 클러스터드 인덱스를 선택적으로 생성할 수 있습니다.
Photon [5]과 Velox [62]는 복잡한 데이터 관리 시스템의 구성 요소로 사용되도록 설계된 쿼리 실행 엔진입니다. 두 시스템 모두 쿼리 플랜을 입력으로 전달받아 로컬 노드에서 Parquet(Photon) 또는 Arrow(Velox) 파일 [46]에 대해 이를 실행합니다. ClickHouse는 이러한 범용 포맷으로 데이터를 읽고 쓸 수 있지만, 저장 시에는 자체 네이티브 파일 포맷을 선호합니다. Velox와 Photon은 쿼리 플랜을 최적화하지는 않지만(Velox는 기본적인 표현식 최적화를 수행), 데이터 특성에 따라 연산 커널을 동적으로 전환하는 등의 런타임 적응 기법을 활용합니다. 이와 유사하게, ClickHouse의 플랜 연산자는
쿼리 메모리 사용량을 기준으로 주로 외부 집계 또는 조인 연산자로 전환하기 위해 런타임에 다른 연산자를 생성할 수 있습니다. Photon 논문에서는 코드 생성 기반 설계 [38, 41, [53]](#page-13-0)가 인터프리터 방식의 벡터화 설계 [11]보다 개발 및 디버깅이 더 어렵다고 언급합니다. Velox의 (실험적인) 코드 생성 지원은 런타임에 생성된 C++ 코드로부터 공유 라이브러리를 빌드하고 링크하는 방식인 반면, ClickHouse는 LLVM의 온디맨드 컴파일 API와 직접 상호작용합니다.
DuckDB [67]는 호스트 프로세스에 내장되어 사용되도록 설계되었을 뿐만 아니라, 쿼리 최적화와 트랜잭션도 제공합니다. 이 시스템은 OLAP 쿼리에 간헐적인 OLTP SQL 문이 섞인 워크로드를 위해 설계되었습니다. 이에 따라 DuckDB는 DataBlocks [43] 스토리지 포맷을 선택했으며, 순서 보존 사전(order-preserving dictionaries)이나 frame-of-reference [2]와 같은 경량 압축 기법을 사용하여 하이브리드 워크로드에서 높은 성능을 발휘합니다. 이에 비해 ClickHouse는 추가 전용(append-only) 방식의 유스 케이스, 즉 업데이트와 삭제가 전혀 없거나 매우 드문 경우에 최적화되어 있습니다. 블록은 LZ4와 같은 고비용 압축 기법을 사용해 압축되며, 사용자가 빈번한 쿼리를 가속하기 위해 데이터 프루닝을 적극 활용하고, 나머지 쿼리에 대해서는 I/O 비용이 압축 해제 비용보다 훨씬 크다고 가정합니다. DuckDB는 또한 Hyper의 MVCC 방식 [55]을 기반으로 직렬화 가능한(serializable) 트랜잭션을 제공하는 반면, ClickHouse는 스냅샷 격리만 제공합니다.
8 CONCLUSION AND OUTLOOK
본 논문에서는 오픈 소스 고성능 OLAP 데이터베이스인 ClickHouse의 아키텍처를 제시하였습니다. 쓰기 작업에 최적화된 스토리지 계층과 최첨단 벡터화 쿼리 엔진을 기반으로 ClickHouse는 페타바이트 규모 데이터 세트에 대해 높은 수집 속도를 유지하면서 실시간 분석을 가능하게 합니다. 백그라운드에서 데이터를 비동기적으로 병합하고 변환함으로써 ClickHouse는 데이터 유지 관리와 병렬 삽입을 효율적으로 분리합니다. 스토리지 계층은 희소 기본 키 인덱스, 스키핑 인덱스, ^^프로젝션^^ 테이블을 활용한 적극적인 데이터 프루닝(pruning)을 지원합니다. 또한 ClickHouse의 업데이트와 삭제, 멱등 삽입, 노드 간 고가용성을 위한 데이터 복제 구현에 대해 설명하였습니다. 쿼리 처리 계층은 다양한 기법을 사용하여 쿼리를 최적화하고, 모든 서버 및 ^^클러스터^^ 자원 전반에 걸쳐 실행을 병렬화합니다. 통합 테이블 엔진과 함수는 다른 데이터 관리 시스템 및 데이터 포맷과 원활하게 상호 작용할 수 있는 편리한 방법을 제공합니다. 벤치마크를 통해 ClickHouse가 시장에서 가장 빠른 분석 데이터베이스 중 하나임을 보였으며, 여러 해에 걸친 실제 ClickHouse 배포 환경에서 전형적인 쿼리 성능이 크게 향상된 점을 입증하였습니다.
2024년에 계획된 모든 기능과 개선 사항은 공개 로드맵 [18]에 정리되어 있습니다. 계획된 개선 사항에는 사용자 트랜잭션 지원, 대안 쿼리 언어로서의 PromQL [69], 반정형 데이터(예: JSON)를 위한 새로운 데이터 타입, 조인의 보다 향상된 플랜 수준 최적화, 경량 삭제를 보완하기 위한 경량 업데이트 구현 등이 포함됩니다.
감사의 글
버전 24.6 기준 SELECT * FROM system.contributors를 실행하면 ClickHouse에 기여한 1,994명이 반환됩니다. 이 데이터베이스를 함께 만들어 주신 ClickHouse Inc.의 전체 엔지니어링 팀과 뛰어난 ClickHouse 오픈 소스 커뮤니티 여러분께 깊이 감사드립니다.
참고 자료
- [1] Daniel Abadi, Peter Boncz, Stavros Harizopoulos, Stratos Idreaos, and Samuel Madden. 2013. 현대 컬럼 지향 데이터베이스 시스템의 설계와 구현. https://doi.org/10.1561/9781601987556
- [2] Daniel Abadi, Samuel Madden, and Miguel Ferreira. 2006. 컬럼 지향 데이터베이스 시스템에서 압축과 실행의 통합. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data (SIGMOD '06). 671–682. https://doi.org/10.1145/1142473.1142548
- [3] Anastassia Ailamaki, David J. DeWitt, Mark D. Hill, and Marios Skounakis. 2001. Weaving Relations for Cache Performance. In Proceedings of the 27th International Conference on Very Large Data Bases (VLDB '01). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 169–180.
- [4] Nikos Armenatzoglou, Sanuj Basu, Naga Bhanoori, Mengchu Cai, Naresh Chainani, Kiran Chinta, Venkatraman Govindaraju, Todd J. Green, Monish Gupta, Sebastian Hillig, Eric Hotinger, Yan Leshinksy, Jintian Liang, Michael McCreedy, Fabian Nagel, Ippokratis Pandis, Panos Parchas, Rahul Pathak, Orestis Polychroniou, Foyzur Rahman, Gaurav Saxena, Gokul Soundararajan, Sriram Subramanian, and Doug Terry. 2022년. 「Amazon Redshift Re-Invented」. 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD '22) 논문집에 수록됨. Association for Computing Machinery, New York, NY, USA, 2205–2217. https://doi.org/10.1145/3514221.3526045
- [5] Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bussel, Herman van Hovell, Maryann Xue, Reynold Xin, 그리고 Matei Zaharia. 2022. Photon: 레이크하우스 시스템을 위한 빠른 쿼리 엔진 (SIGMOD '22). Association for Computing Machinery, New York, NY, USA, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- [6] Philip A. Bernstein 및 Nathan Goodman. 1981년. Concurrency Control in Distributed Database Systems. ACM Computing Survey 13, 2 (1981년), 185–221쪽. https://doi.org/10.1145/356842.356846
- [7] Spyros Blanas, Yinan Li, and Jignesh M. Patel. 2011. 멀티코어 CPU를 위한 메인 메모리 해시 조인 알고리즘의 설계와 평가. 2011년 ACM SIGMOD International Conference on Management of Data (Athens, Greece) (SIGMOD '11) 논문집, Association for Computing Machinery, New York, NY, USA, 37–48. https://doi.org/10.1145/1989323.1989328
- [8] Daniel Gomez Blanco. 2023. Practical OpenTelemetry. Springer Nature.
- [9] Burton H. Bloom. 1970. Space/Time Trade-Ofs in Hash Coding with Allowable Errors(허용 오차가 있는 해시 코딩에서의 공간/시간 트레이드오프). Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- [10] Peter Boncz, Thomas Neumann, Orri Erling. 2014년. TPC-H Analyzed: Hidden Messages and Lessons Learned from an Infuential Benchmark. Performance Characterization and Benchmarking에 수록됨. 61–76. https://doi.org/10.1007/978-3-319- 04936-6_5
- [11] Peter Boncz, Marcin Zukowski, 및 Niels Nes. 2005. MonetDB/X100: Hyper-Pipelining Query Execution. CIDR.
- [12] Martin Burtscher and Paruj Ratanaworabhan. 2007. 배정밀도 부동소수점 데이터의 고처리량 압축. In Data Compression Conference (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- [13] Jef Carpenter와 Eben Hewitt. 2016. Cassandra: The Definitive Guide (2nd ed.). O'Reilly Media, Inc.
- [14] Bernadette Charron-Bost, Fernando Pedone, and André Schiper (편). 2010. Replication: Theory and Practice. Springer-Verlag.
- [15] chDB. 2024. chDB - 임베디드 OLAP SQL Engine. 2024-06-20에 https://github.com/chdb-io/chdb에서 열람함
- [16] ClickHouse. 2024. ClickBench: 분석 데이터베이스용 벤치마크. 2024-06-20에 https://github.com/ClickHouse/ClickBench에서 조회함
- [17] ClickHouse. 2024. ClickBench: 비교 측정. 2024-06-20에 https://benchmark.clickhouse.com에서 검색함.
- [18] ClickHouse. 2024. ClickHouse Roadmap 2024 (GitHub). 2024-06-20에 https://github.com/ClickHouse/ClickHouse/issues/58392에서 검색함
- [19] ClickHouse. 2024. ClickHouse Versions Benchmark. 2024-06-20에 https://github.com/ClickHouse/ClickBench/tree/main/versions에서 조회함
- [20] ClickHouse. 2024. ClickHouse 버전 벤치마크 결과. 2024-06-20에 https://benchmark.clickhouse.com/versions/에서 조회함.
- [21] Andrew Crotty. 2022. MgBench. 2024-06-20에 https://github.com/ andrewcrotty/mgbench에서 검색함
- [22] Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, 그리고 Philipp Unterbrunner. 2016. The Snowfake Elastic Data Warehouse. 2016년 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD '16) 논문집. Association for Computing Machinery, New York, NY, USA, 215–226. https: //doi.org/10.1145/2882903.2903741
- [23] Patrick Damme, Annett Ungethüm, Juliana Hildebrandt, Dirk Habich, and Wolfgang Lehner. 2019. 경량 정수 압축 알고리즘에 대한 포괄적인 실험적 조사와 비용 기반 선택 전략. ACM Trans. Database Syst. 44, 3, Article 9 (2019), 46 pages. https://doi.org/10.1145/3323991
- [24] Philippe Dobbelaere and Kyumars Sheykh Esmaili. 2017. Kafka versus RabbitMQ: 두 가지 업계 표준 Publish/Subscribe 구현에 대한 비교 연구: Industry Paper (DEBS '17). Association for Computing Machinery, New York, NY, USA, 227–238. https://doi.org/10.1145/3093742.3093908
- [25] LLVM 문서. 2024. LLVM의 자동 벡터화(Auto-Vectorization in LLVM). 2024-06-20에 https://llvm.org/docs/Vectorizers.html에서 조회함
- [26] Siying Dong, Andrew Kryczka, Yanqin Jin, and Michael Stumm. 2021. RocksDB: 대규모 애플리케이션을 위한 키-값 저장소에서의 개발 우선순위 변화. ACM Transactions on Storage 17, 4, Article 26 (2021), 32쪽. https://doi.org/10.1145/3483840
- [27] Markus Dreseler, Martin Boissier, Tilmann Rabl, and Matthias Ufacker. 2020. TPC-H 병목 지점과 그 최적화의 정량적 분석. Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- [28] Ted Dunning. 2021년. The t-digest: efficient estimates of distributions. Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- [29] Martin Faust, Martin Boissier, Marvin Keller, David Schwalb, Holger Bischof, Katrin Eisenreich, Franz Färber, and Hasso Plattner. 2016년. SAP HANA에서 해시 인덱스를 사용한 공간 절감 및 유일성 보장. Database and Expert Systems Applications. 137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- [30] Philippe Flajolet, Eric Fusy, Olivier Gandouet, and Frederic Meunier. 2007. HyperLogLog: 거의 최적인 카디널리티 추정 알고리즘의 분석. In AofA: Analysis of Algorithms, Vol. DMTCS Proceedings vol. AH, 2007 Conference on Analysis of Algorithms (AofA 07). Discrete Mathematics and Theoretical Computer Science, 137–156. https://doi.org/10.46298/dmtcs.3545
- [31] Hector Garcia-Molina, Jefrey D. Ullman, 및 Jennifer Widom. 2009. Database Systems - The Complete Book (제2판).
- [32] Pawan Goyal, Harrick M. Vin, 및 Haichen Chen. 1996. Start-time fair queueing: 통합 서비스 패킷 스위칭 네트워크를 위한 스케줄링 알고리즘. 26, 4 (1996), 157–168. https://doi.org/10.1145/248157.248171
- [33] Goetz Graefe. 1993. Query Evaluation Techniques for Large Databases. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- [34] Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li, 그리고 Ravi Aringunram. 2018. Pinot: 5억 3천만 명의 사용자를 위한 실시간 OLAP. 2018년 International Conference on Management of Data(SIGMOD '18, 휴스턴, 텍사스, 미국) 논문집. Association for Computing Machinery, 미국 뉴욕, NY, 583–594. https://doi.org/10.1145/3183713.3190661
- [35] ISO/IEC 9075-9:2001 2001. 정보기술 — 데이터베이스 언어 — SQL — 제9부: 외부 데이터 관리(SQL/MED). 표준. International Organization for Standardization(ISO).
- [36] Paras Jain, Peter Kraft, Conor Power, Tathagata Das, Ion Stoica, and Matei Zaharia. 2023. Lakehouse 스토리지 시스템 분석 및 비교. CIDR.
- [37] Project Jupyter. 2024. Jupyter Notebooks. 2024-06-20에 조회함. https: //jupyter.org/
- [38] Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo, and Peter Boncz. 2018. 컴파일 및 벡터화된 쿼리에 대해 알고 싶었지만 차마 질문하지 못했던 모든 것. Proc. VLDB Endow. 11, 13 (2018년 9월), 2209–2222. https://doi.org/10.14778/3275366.3284966
- [39] Changkyu Kim, Jatin Chhugani, Nadathur Satish, Eric Sedlar, Anthony D. Nguyen, Tim Kaldewey, Victor W. Lee, Scott A. Brandt, and Pradeep Dubey. 2010. FAST: 현대 CPU 및 GPU에서 아키텍처 특성을 고려한 고속 트리 탐색. 2010 ACM SIGMOD International Conference on Management of Data (Indianapolis, Indiana, USA) (SIGMOD '10) 논문집. Association for Computing Machinery, New York, NY, USA, 339–350. https://doi.org/10.1145/1807167.1807206
- [40] Donald E. Knuth. 1973. The Art of Computer Programming, Volume III: Sorting and Searching. Addison-Wesley.
- [41] André Kohn, Viktor Leis, and Thomas Neumann. 2018. 컴파일된 쿼리의 적응형 실행(Adaptive Execution of Compiled Queries). 2018년 IEEE 제34회 국제 데이터 공학 회의(ICDE) 논문집, 197–208. https://doi.org/10.1109/ICDE.2018.00027
- [42] Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, 그리고 Chuck Bear. 2012. The Vertica Analytic Database: C-Store 7 Years Later. Proc. VLDB Endow. 5, 12 (2012년 8월), 1790–1801. https://doi.org/10. 14778/2367502.2367518
- [43] Harald Lang, Tobias Mühlbauer, Florian Funke, Peter A. Boncz, Thomas Neumann, 그리고 Alfons Kemper. 2016. Data Blocks: 압축 스토리지에서 Vectorization과 Compilation을 모두 사용한 Hybrid OLTP 및 OLAP용 Data Blocks. In Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD '16). Association for Computing Machinery, New York, NY, USA, 311–326. https://doi.org/10.1145/2882903.2882925
- [44] Viktor Leis, Peter Boncz, Alfons Kemper, 그리고 Thomas Neumann. 2014. Morseldriven parallelism: a NUMA-aware query evaluation framework for the manycore age. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD '14). Association for Computing Machinery, New York, NY, USA, 743–754. https://doi.org/10.1145/2588555. 2610507
- [45] Viktor Leis, Alfons Kemper, 그리고 Thomas Neumann. 2013. The adaptive radix tree: 메인 메모리 데이터베이스를 위한 ART 기반 인덱싱. In 2013 IEEE 29th International Conference on Data Engineering (ICDE). 38–49. https://doi.org/10.1109/ICDE. 2013.6544812
- [46] Chunwei Liu, Anna Pavlenko, Matteo Interlandi 및 Brandon Haynes. 2023. A Deep Dive into Common Open Formats for Analytical DBMSs. 16, 11 (2023년 7월), 3044–3056. https://doi.org/10.14778/3611479.3611507
- [47] Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Gang Guo, Haozhou Wang, Jinbao Chen, Asim Praveen, Yu Yang, Xiaoming Gao, Alexandra Wang, Wen Lin, Ashwin Agrawal, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang, and Venkatesh Raghavan. 2021. Greenplum: 트랜잭션 및 분석 워크로드용 하이브리드 데이터베이스 (SIGMOD '21). Association for Computing Machinery, New York, NY, USA, 2530–2542. https: //doi.org/10.1145/3448016.3457562
- [48] Roger MacNicol and Blaine French. 2004. Sybase IQ Multiplex - Designed for Analytics. 제30회 Very Large Data Bases 국제 학술대회(VLDB '04) 논문집, 캐나다 토론토. VLDB Endowment, 1227–1230.
- [49] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geofrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky, and Jef Shute. 2020. Dremel: 웹 규모 대화형 SQL 분석의 10년. Proc. VLDB Endow. 13, 12 (2020년 8월), 3461–3472. https://doi.org/10.14778/3415478.3415568
- [50] Microsoft. 2024. Kusto Query Language. 2024-06-20에 조회함: https: //github.com/microsoft/Kusto-Query-Language
- [51] Guido Moerkotte. 1998. Small Materialized Aggregates: 데이터 웨어하우징을 위한 경량 인덱스 구조. 제24회 Very Large Data Bases 국제학술대회(VLDB '98) 논문집, 476–487.
- [52] Jalal Mostafa, Sara Wehbi, Suren Chilingaryan, and Andreas Kopmann. 2022. SciTS: 과학 실험 및 산업용 사물 인터넷 환경에서의 시계열 데이터베이스를 위한 벤치마크. Proceedings of the 34th International Conference on Scientifc and Statistical Database Management (SSDBM '22)에 수록. Article 12. https: //doi.org/10.1145/3538712.3538723
- [53] Thomas Neumann. 2011. 현대 하드웨어용 효율적인 쿼리 플랜의 효율적 컴파일. Proc. VLDB Endow. 4, 9 (2011년 6월), 539–550. https://doi.org/10.14778/ 2002938.2002940
- [54] Thomas Neumann 및 Michael J. Freitag. 2020. Umbra: 메모리 수준의 성능을 갖춘 디스크 기반 시스템. 2020년 1월 12-15일, 네덜란드 암스테르담에서 열린 10th Conference on Innovative Data Systems Research, CIDR 2020, 온라인 프로시딩 수록. www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- [55] Thomas Neumann, Tobias Mühlbauer, and Alfons Kemper. 2015. 메인 메모리형 데이터베이스 시스템을 위한 고속 직렬 가능 다중 버전 동시성 제어. 2015 ACM SIGMOD International Conference on Management of Data (Melbourne, Victoria, Australia) (SIGMOD '15) 논문집. Association for Computing Machinery, New York, NY, USA, 677–689쪽. https://doi.org/10.1145/2723372. 2749436
- [56] GitHub의 LevelDB. 2024. LevelDB. 2024-06-20에 다음에서 조회함: https://github. com/google/leveldb
- [57] Patrick O'Neil, Elizabeth O'Neil, Xuedong Chen, 그리고 Stephen Revilak. 2009. Star Schema Benchmark와 보강된 팩트 테이블 인덱싱. Performance Evaluation and Benchmarking에 수록. Springer Berlin Heidelberg, 237–252. https: //doi.org/10.1007/978-3-642-10424-4_17
- [58] Patrick E. O'Neil, Edward Y. C. Cheng, Dieter Gawlick 및 Elizabeth J. O'Neil. 1996년. The log-structured Merge-Tree (LSM-tree). Acta Informatica 33 (1996), 351–385. https://doi.org/10.1007/s002360050048
- [59] Diego Ongaro와 John Ousterhout. 2014. 이해하기 쉬운 합의 알고리즘을 찾아서(In Search of an Understandable Consensus Algorithm). 2014 USENIX Conference on USENIX Annual Technical Conference (USENIX ATC'14) 논문집, 305–320쪽. https://doi.org/doi/10. 5555/2643634.2643666
- [60] Patrick O'Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O'Neil. 1996. 로그 구조 병합 트리(Log-Structured Merge-Tree, LSM-Tree). Acta Inf. 33, 4 (1996), 351–385. https: //doi.org/10.1007/s002360050048
- [61] Pandas. 2024. Pandas 데이터프레임. 2024-06-20에 https://pandas.pydata.org/ pydata.org/에서 검색함.
- [62] Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He, 그리고 Biswapesh Chattopadhyay. 2022. Velox: Meta's Unified Execution Engine. Proc. VLDB Endow. 15, 12 (2022년 8월), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- [63] Tuomas Pelkonen, Scott Franklin, Justin Teller, Paul Cavallaro, Qi Huang, Justin Meza, 그리고 Kaushik Veeraraghavan. 2015. Gorilla: 빠르고 확장 가능한 인메모리 시계열 데이터베이스. Proceedings of the VLDB Endowment 8, 12 (2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
- [64] Orestis Polychroniou, Arun Raghavan, and Kenneth A. Ross. 2015. 「Rethinking SIMD Vectorization for In-Memory Databases」. 2015년 ACM SIGMOD International Conference on Management of Data (SIGMOD '15) 논문집에 수록, 1493–1508쪽. https://doi.org/10.1145/2723372.2747645
- [65] PostgreSQL. 2024. PostgreSQL - Foreign Data Wrappers. 2024-06-20에 https://wiki.postgresql.org/wiki/Foreign_data_wrappers에서 검색함
- [66] Mark Raasveldt, Pedro Holanda, Tim Gubner, and Hannes Mühleisen. 2018. 공정한 벤치마킹은 어려운 일이다: 데이터베이스 성능 테스트에서 흔히 발생하는 함정들. In Proceedings of the Workshop on Testing Database Systems (Houston, TX, USA) (DBTest'18). Article 2, 6페이지. https://doi.org/10.1145/3209950.3209955
- [67] Mark Raasveldt and Hannes Mühleisen. 2019. DuckDB: An Embeddable Analytical Database (SIGMOD '19). Association for Computing Machinery, New York, NY, USA, 1981–1984. https://doi.org/10.1145/3299869.3320212
- [68] Jun Rao and Kenneth A. Ross. 1999. 메인 메모리에서 의사결정 지원을 위한 캐시 인식 인덱싱. In Proceedings of the 25th International Conference on Very Large Data Bases (VLDB '99). San Francisco, CA, USA, 78–89.
- [69] Navin C. Sabharwal and Piyush Kant Pandey. 2020. Prometheus Query Language (PromQL) 활용. 마이크로서비스 및 컨테이너화된 애플리케이션 모니터링. https://doi.org/10.1007/978-1-4842-6216-0_5
- [70] Todd W. Schneider. 2022. New York City Taxi and For-Hire Vehicle Data. 2024-06-20에 https://github.com/toddwschneider/nyc-taxi-data에서 검색함.
- [71] Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O'Neil, Pat O'Neil, Alex Rasin, Nga Tran, 그리고 Stan Zdonik. 2005. C-Store: 컬럼 지향 DBMS. 제31회 Very Large Data Bases 국제 학술대회(VLDB '05) 논문집, 553–564.
- [72] Teradata. 2024. Teradata Database. 2024-06-20에 조회함. https://www. teradata.com/resources/datasheets/teradata-database
- [73] Frederik Transier. 2010. 인메모리 텍스트 검색 엔진을 위한 알고리즘과 자료 구조. 박사학위 논문. https://doi.org/10.5445/IR/1000015824
- [74] Adrian Vogelsgesang, Michael Haubenschild, Jan Finis, Alfons Kemper, Viktor Leis, Tobias Muehlbauer, Thomas Neumann, 그리고 Manuel Then. 2018. Get Real: 벤치마크가 현실 세계를 제대로 대표하지 못하는 이유. Testing Database Systems 워크숍(DBTest'18, Houston, TX, USA) 논문집(Proceedings)에 수록. Article 1, 6쪽. https://doi.org/10.1145/3209950.3209952
- [75] LZ4 웹사이트. 2024. LZ4. 2024-06-20에 https://lz4.org/에서 검색함
- [76] PRQL 웹사이트. 2024. PRQL. 2024-06-20에 https://prql-lang.org에서 확인함 [77] Till Westmann, Donald Kossmann, Sven Helmer, and Guido Moerkotte. 2000. The Implementation and Performance of Compressed Databases. SIGMOD Rec.
- 29권 3호 (2000년 9월), 55–67. https://doi.org/10.1145/362084.362137 [78] Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, and Deep Ganguli. 2014. Druid: A Real-Time Analytical Data Store. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD '14). Association for Computing Machinery, New York, NY, USA, 157–168. https://doi.org/10.1145/2588555.2595631
- [79] Tianqi Zheng, Zhibin Zhang, and Xueqi Cheng. 2020. SAHA: 분석형 데이터베이스용 문자열 적응형 해시 테이블. Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
- [80] Jingren Zhou 및 Kenneth A. Ross. 2002. SIMD 명령어를 사용한 데이터베이스 연산의 구현. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data (SIGMOD '02). 145–156. https://doi.org/10. 1145/564691.564709
- [81] Marcin Zukowski, Sandor Heman, Niels Nes, and Peter Boncz. 2006. Super-Scalar RAM-CPU 캐시 압축. 제22회 International Conference on Data Engineering (ICDE '06) 논문집, 59쪽. https://doi.org/10.1109/ICDE. 2006.150
