확장
이 예제에서는 확장 가능한 간단한 ClickHouse 클러스터를 설정하는 방법을 설명합니다. 서버는 총 다섯 대로 구성됩니다. 이 중 두 대는 데이터를 세그먼트로 분산 저장하는 데 사용됩니다. 나머지 세 대의 서버는 클러스터 조정을 위해 사용됩니다.
구성하게 될 클러스터의 아키텍처는 아래와 같습니다:
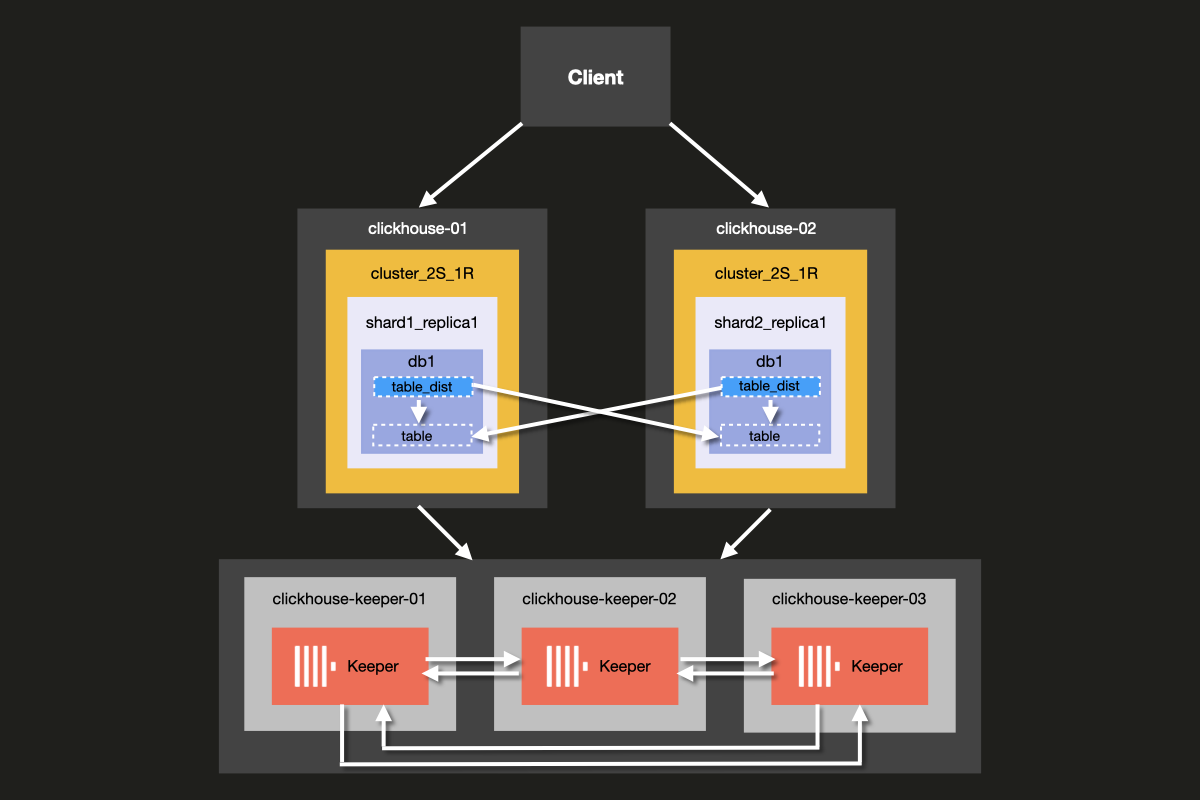
ClickHouse Server와 ClickHouse Keeper를 동일한 서버에서 함께 실행하는 것도 가능하지만, 프로덕션 환경에서는 ClickHouse Keeper에 전용 호스트를 사용하는 것을 강력히 권장하며, 이 예제에서는 이러한 방식을 보여 줍니다.
Keeper 서버는 더 작게 구성해도 되며, 각 Keeper 서버에는 일반적으로 4GB RAM이면 충분합니다. 이는 ClickHouse Server 규모가 상당히 커지기 전까지 유효합니다.
사전 요구 사항
- 이전에 로컬 ClickHouse 서버를 설정해 본 적이 있습니다.
- ClickHouse의 설정 파일 등 기본 설정 개념에 익숙합니다.
- 사용 중인 머신에 Docker가 설치되어 있습니다.
디렉터리 구조 및 테스트 환경 설정하기
다음 단계에서는 클러스터를 처음부터 설정하는 방법을 단계별로 안내합니다.
이 단계를 건너뛰고 바로 클러스터를 실행하려면, examples 리포지토리의 'docker-compose-recipes' 디렉터리에서 예제 파일을 다운로드할 수 있습니다.
이 튜토리얼에서는 Docker compose를 사용하여 ClickHouse 클러스터를 설정합니다. 이 설정은 별도의 로컬 머신, 가상 머신 또는 Cloud 인스턴스에서도 작동하도록 수정할 수 있습니다.
다음 명령을 실행하여 이 예제의 디렉터리 구조를 설정하세요:
clickhouse-cluster 디렉터리에 다음 docker-compose.yml 파일을 추가하세요:
다음 하위 디렉터리와 파일을 생성하세요:
config.d디렉터리에는 ClickHouse 서버 구성 파일config.xml이 포함됩니다. 이 파일에는 각 ClickHouse 노드에 대한 사용자 지정 구성이 정의되어 있으며, 모든 ClickHouse 설치에 포함되는 기본 ClickHouse 구성 파일config.xml과 함께 적용됩니다.users.d디렉터리에는 사용자 구성 파일users.xml이 포함됩니다. 이 파일에는 사용자에 대한 사용자 지정 구성이 정의되어 있으며, 모든 ClickHouse 설치에 포함되는 기본 ClickHouseusers.xml구성 파일과 함께 적용됩니다.
자체 구성을 작성할 때는 /etc/clickhouse-server/config.xml 및 etc/clickhouse-server/users.xml의 기본 구성을 직접 수정하는 대신, config.d 및 users.d 디렉터리를 활용하는 것이 모범 사례입니다.
다음 행은
config.d 및 users.d 디렉터리에 정의된 설정 섹션이 기본 config.xml 및 users.xml 파일에 정의된 기본 설정 섹션보다 우선하도록 합니다.
ClickHouse 노드 구성하기
서버 설정
이제 fs/volumes/clickhouse-{}/etc/clickhouse-server/config.d에 위치한 각 빈 설정 파일 config.xml을 수정하세요. 아래에서 강조 표시된 줄은 각 노드별로 변경해야 합니다:
| 디렉터리 | 파일 |
|---|---|
fs/volumes/clickhouse-01/etc/clickhouse-server/config.d | config.xml |
fs/volumes/clickhouse-02/etc/clickhouse-server/config.d | config.xml |
위 구성 파일의 각 섹션에 대한 자세한 설명은 다음과 같습니다.
네트워킹 및 로깅
네트워크 인터페이스로의 외부 통신은 listen host 설정을 활성화하면 사용할 수 있습니다. 이렇게 하면 다른 호스트에서 ClickHouse 서버 호스트에 접속할 수 있습니다:
HTTP API 포트는 8123으로 설정됩니다:
ClickHouse 기본 프로토콜을 사용하여 clickhouse-client 및 기타 기본 ClickHouse 도구가 clickhouse-server 및 다른 clickhouse-server와 상호 작용할 때 사용하는 TCP 포트는 9000입니다:
로깅은 <logger> 블록에서 정의됩니다. 이 예제 구성은 1000M 크기에 도달할 때마다 롤오버되는 디버그 로그를 제공하며, 총 3회 롤오버됩니다:
로깅 구성에 대한 자세한 내용은 기본 ClickHouse 구성 파일에 포함된 주석을 참조하세요.
클러스터 구성
클러스터 구성은 <remote_servers> 블록에서 설정합니다.
여기에서 클러스터 이름 cluster_2S_1R을 정의합니다.
<cluster_2S_1R></cluster_2S_1R> 블록은 <shard></shard> 및 <replica></replica> 설정을 사용하여 클러스터의 레이아웃을 정의하며, ON CLUSTER 절을 사용하여 클러스터 전체에서 실행되는 쿼리인 분산 DDL 쿼리의 템플릿 역할을 합니다. 기본적으로 분산 DDL 쿼리가 허용되지만, allow_distributed_ddl_queries 설정을 통해 비활성화할 수도 있습니다.
세그먼트당 레플리카가 하나만 존재하므로 internal_replication은 기본적으로 false로 설정되어 있습니다.
각 서버에 대해 다음 매개변수를 지정합니다:
| Parameter | Description | Default Value |
|---|---|---|
host | 원격 서버의 주소입니다. 도메인 또는 IPv4, IPv6 주소를 사용할 수 있습니다. 도메인을 지정하면 서버가 시작될 때 DNS 조회를 수행하며, 그 결과는 서버가 실행되는 동안 유지됩니다. DNS 조회가 실패하면 서버가 시작되지 않습니다. DNS 레코드를 변경한 경우 서버를 다시 시작해야 합니다. | - |
port | 메신저 통신에 사용하는 TCP 포트입니다(config의 tcp_port, 일반적으로 9000으로 설정). http_port와 혼동하지 마십시오. | - |
Keeper 구성
<ZooKeeper> 섹션은 ClickHouse Keeper(또는 ZooKeeper)가 실행 중인 위치를 ClickHouse에 알려줍니다.
ClickHouse Keeper 클러스터를 사용하는 경우, 클러스터의 각 <node>를 지정해야 하며,
<host> 및 <port> 태그를 사용하여 각각의 호스트명과 포트 번호를 지정하십시오.
ClickHouse Keeper 설정은 튜토리얼의 다음 단계에서 설명합니다.
ClickHouse Keeper를 ClickHouse Server와 동일한 서버에서 실행할 수 있지만, 프로덕션 환경에서는 ClickHouse Keeper를 전용 호스트에서 실행하실 것을 강력히 권장합니다.
매크로 설정
또한 <macros> 섹션은 복제된 테이블(Replicated Table)에 대한 매개변수 치환을 정의하는 데 사용됩니다. 이러한 매개변수는 system.macros에 나열되며, 쿼리에서 {shard}(세그먼트)와 {replica}(레플리카) 같은 치환을 사용할 수 있습니다.
이러한 값들은 클러스터의 레이아웃에 따라 고유하게 정의됩니다.
사용자 구성
이제 fs/volumes/clickhouse-{}/etc/clickhouse-server/users.d에 위치한 각 빈 설정 파일 users.xml을 다음과 같이 수정하세요:
| 디렉터리 | 파일 |
|---|---|
fs/volumes/clickhouse-01/etc/clickhouse-server/users.d | users.xml |
fs/volumes/clickhouse-02/etc/clickhouse-server/users.d | users.xml |
이 예제에서는 편의상 기본 사용자를 비밀번호 없이 구성합니다. 실제 환경에서는 이 방식을 권장하지 않습니다.
이 예제에서는 클러스터의 모든 노드에서 각 users.xml 파일이 동일합니다.
ClickHouse Keeper 구성하기
Keeper 설정
복제가 동작하려면 ClickHouse Keeper 클러스터를 설정하고 구성해야 합니다. ClickHouse Keeper는 데이터 복제를 위한 조정 시스템을 제공하며, 대체로 사용할 수 있는 ZooKeeper를 대체하는 역할을 합니다. 하지만 ClickHouse Keeper는 ZooKeeper보다 더 나은 보증과 신뢰성을 제공하고 리소스를 더 적게 사용하므로 권장됩니다. 고가용성과 정족수(quorum)를 유지하기 위해 최소 3개의 ClickHouse Keeper 노드를 실행하는 것이 좋습니다.
ClickHouse Keeper는 클러스터의 어느 노드에서든 ClickHouse와 함께 실행될 수 있지만, 확장 및 ClickHouse Keeper 클러스터를 데이터베이스 클러스터와 독립적으로 관리할 수 있도록 전용 노드에서 실행하는 것이 권장됩니다.
다음 명령을 예제 폴더의 루트에서 실행하여 각 ClickHouse Keeper 노드에 대한
keeper_config.xml 파일을 생성하십시오:
각 노드 디렉터리 fs/volumes/clickhouse-keeper-{}/etc/clickhouse-keeper에 생성된
비어 있는 설정 파일을 수정하십시오. 아래에서 강조 표시된 줄을 각 노드에
맞게 변경해야 합니다.
| 디렉토리 | 파일 |
|---|---|
fs/volumes/clickhouse-keeper-01/etc/clickhouse-keeper | keeper_config.xml |
fs/volumes/clickhouse-keeper-02/etc/clickhouse-keeper | keeper_config.xml |
fs/volumes/clickhouse-keeper-03/etc/clickhouse-keeper | keeper_config.xml |
각 구성 파일에는 아래에 나오는 고유한 구성이 포함됩니다.
server_id 값은 해당 ClickHouse Keeper 노드에 대해 클러스터 내에서 고유해야 하며,
<raft_configuration> 섹션에 정의된 서버 <id>와 일치해야 합니다.
tcp_port는 ClickHouse Keeper의 클라이언트가 사용하는 포트입니다.
다음 섹션에서는 Raft 합의 알고리즘의 정족수(quorum)에 참여하는 서버를 구성합니다.
ClickHouse Cloud는 세그먼트와 레플리카 관리를 수반하는 운영 부담을 제거합니다. 이 플랫폼은 고가용성, 복제, 확장에 대한 결정을 자동으로 처리합니다. 컴퓨팅 리소스와 스토리지는 분리되어 있으며, 수요에 따라 수동 구성이나 지속적인 유지 보수 없이 확장됩니다.
설정 테스트하기
Docker가 머신에서 실행 중인지 확인하세요.
cluster_2S_1R 디렉터리의 루트에서 docker-compose up 명령을 사용하여 클러스터를 시작하세요:
docker가 ClickHouse 및 Keeper 이미지를 가져온 후 컨테이너를 시작하는 것을 확인할 수 있습니다:
클러스터가 실행 중인지 확인하려면 clickhouse-01 또는 clickhouse-02에 연결한 후 다음 쿼리를 실행하세요. 첫 번째 노드에 연결하는 명령은 다음과 같습니다:
성공하면 ClickHouse 클라이언트 프롬프트가 표시됩니다:
다음 쿼리를 실행하여 각 호스트에 정의된 클러스터 토폴로지를 확인하세요:
다음 쿼리를 실행하여 ClickHouse Keeper 클러스터의 상태를 확인하세요:
mntr 명령은 ClickHouse Keeper가 실행 중인지 확인하고,
세 개의 Keeper 노드 간 관계에 대한 상태 정보를 확인하는 데 일반적으로 사용됩니다.
이 예제에서 사용된 구성에는 함께 동작하는 세 개의 노드가 있습니다.
노드들은 리더를 선출하고, 나머지 노드들은 팔로워가 됩니다.
mntr 명령은 성능 관련 정보와 특정 노드가 팔로워인지 리더인지에 대한 정보를 제공합니다.
Keeper에 mntr 명령을 보내기 위해 netcat을 설치해야 할 수도 있습니다.
다운로드 정보는 nmap.org 페이지를 참고하십시오.
각 Keeper 노드의 상태를 확인하기 위해 clickhouse-keeper-01, clickhouse-keeper-02,
clickhouse-keeper-03의 셸에서 아래 명령을 실행합니다. clickhouse-keeper-01에 대한
명령은 아래와 같습니다.
아래는 follower 노드에서 반환된 예시 응답입니다.
아래는 리더 노드의 예시 응답입니다:
이로써 단일 세그먼트와 두 개의 레플리카로 구성된 ClickHouse 클러스터 설정을 완료했습니다. 다음 단계에서는 클러스터에 테이블을 생성하세요.
데이터베이스 생성하기
클러스터가 올바르게 설정되어 실행 중임을 확인했으므로, UK property prices 예제 데이터셋 튜토리얼에서 사용된 것과 동일한 테이블을 재생성하게 됩니다. 이 데이터셋은 1995년 이후 영국 잉글랜드와 웨일스의 부동산 거래 가격에 대한 약 3천만 개의 행으로 구성되어 있습니다.
각 호스트의 클라이언트에 연결하려면 별도의 터미널 탭 또는 창에서 다음 명령을 각각 실행하세요:
각 호스트의 clickhouse-client에서 아래 쿼리를 실행하여 기본 데이터베이스를 제외하고 생성된 데이터베이스가 없음을 확인하세요:
clickhouse-01 클라이언트에서 ON CLUSTER 절을 사용하는 다음 분산 DDL 쿼리를 실행하여 uk라는 새 데이터베이스를 생성하세요:
각 호스트의 클라이언트에서 이전과 동일한 쿼리를 다시 실행하여
clickhouse-01에서만 쿼리를 실행했음에도 불구하고 클러스터 전체에 데이터베이스가
생성되었는지 확인하십시오:
클러스터에 테이블 생성
데이터베이스가 생성되었으므로 테이블을 생성합니다. 호스트 클라이언트 중 하나에서 다음 쿼리를 실행하세요:
이는 영국 부동산 가격 예제 데이터셋 튜토리얼의
원본 CREATE 문에서 사용된 쿼리와 동일하며,
ON CLUSTER 절을 제외하고는 같습니다.
ON CLUSTER 절은 CREATE, DROP, ALTER, RENAME과 같은 DDL(Data Definition Language, 데이터 정의 언어) 쿼리를 분산 실행하기 위해 설계되었으며, 클러스터의 모든 노드에 스키마 변경 사항이 적용되도록 보장합니다.
각 호스트의 클라이언트에서 아래 쿼리를 실행하여 클러스터 전체에 테이블이 생성되었는지 확인하십시오:
영국 부동산 거래 데이터를 삽입하기 전에, 두 호스트 중 하나에서 일반 테이블에 데이터를 삽입하면 어떤 일이 발생하는지 확인하기 위해 간단한 실험을 수행하겠습니다.
다음 쿼리를 사용하여 두 호스트 중 하나에서 테스트 데이터베이스와 테이블을 생성하세요:
이제 clickhouse-01에서 다음 INSERT 쿼리를 실행하세요:
clickhouse-02로 전환한 후 다음 INSERT 쿼리를 실행하세요:
이제 clickhouse-01 또는 clickhouse-02에서 다음 쿼리를 실행하세요:
ReplicatedMergeTree 테이블과 달리, 해당 특정 호스트의 테이블에 삽입된 행만 반환되며 두 행이 모두 반환되지는 않습니다.
두 샤드에 걸쳐 데이터를 읽으려면 모든 샤드에서 쿼리를 처리할 수 있는 인터페이스가 필요합니다. 이 인터페이스는 select 쿼리 실행 시 두 샤드의 데이터를 결합하고, insert 쿼리 실행 시 두 샤드에 데이터를 삽입합니다.
ClickHouse에서 이 인터페이스를 분산 테이블이라고 하며, Distributed 테이블 엔진을 사용하여 생성합니다. 작동 방식을 살펴보겠습니다.
분산 테이블 생성하기
다음 쿼리로 분산 테이블을 생성하세요:
이 예제에서는 rand() 함수를 샤딩 키로 선택하여
삽입 작업이 세그먼트 전체에 무작위로 분산됩니다.
이제 어느 호스트에서든 분산 테이블을 쿼리하면 이전 예제와 달리 두 호스트에 삽입된 두 개의 행이 모두 반환됩니다:
영국 부동산 가격 데이터에 대해서도 동일하게 수행합니다. 호스트 클라이언트 중 하나에서
다음 쿼리를 실행하여 이전에 ON CLUSTER로 생성한 기존 테이블을 사용하는 분산 테이블을 생성하세요:
분산 테이블에 데이터 삽입
이제 호스트 중 하나에 연결하고 데이터를 삽입하세요:
데이터가 삽입된 후 분산 테이블을 사용하여 행 수를 확인하세요:
두 호스트 중 하나에서 다음 쿼리를 실행하면 데이터가 세그먼트 전체에 고르게 분산되어 있음을 확인할 수 있습니다 (삽입할 세그먼트 선택은 rand()로 설정되었으므로 결과가 다를 수 있습니다):
호스트 중 하나가 장애가 발생하면 어떻게 될까요? clickhouse-01을 종료하여 시뮬레이션해 보겠습니다:
다음 명령을 실행하여 호스트가 다운되었는지 확인하세요:
이제 clickhouse-02에서 분산 테이블에 대해 이전에 실행했던 것과 동일한 select 쿼리를 실행하세요:
안타깝게도 이 클러스터는 장애 허용(fault-tolerant) 기능이 없습니다. 호스트 중 하나가 장애를 일으키면 클러스터는 비정상 상태로 간주되며 쿼리가 실패합니다. 이는 이전 예제에서 살펴본 복제된 테이블과 대조됩니다. 복제된 테이블의 경우 호스트 중 하나가 장애를 일으켜도 데이터를 삽입할 수 있었습니다.
결론
이 클러스터 토폴로지의 장점은 데이터가 개별 호스트에 분산되고 노드당 절반의 스토리지만 사용된다는 점입니다. 더 중요하게는 쿼리가 두 세그먼트 전체에 걸쳐 처리되어 메모리 활용 측면에서 더 효율적이며 호스트당 I/O를 줄여 줍니다.
이 클러스터 토폴로지의 주요 단점은, 물론, 호스트 중 하나를 잃게 되면 쿼리를 처리할 수 없게 된다는 점입니다.
다음 예제에서는 두 개의 세그먼트와 두 개의 레플리카로 구성된 클러스터를 설정해 확장성과 장애 허용을 모두 제공하는 방법을 살펴봅니다.
