SharedMergeTree table engine
SharedMergeTree 테이블 엔진 계열은 ReplicatedMergeTree 엔진을 대체하는 클라우드 네이티브 방식의 엔진으로, 공유 스토리지(예: Amazon S3, Google Cloud Storage, MinIO, Azure Blob Storage) 위에서 동작하도록 최적화되어 있습니다. 모든 MergeTree 엔진 타입마다 이에 상응하는 SharedMergeTree 엔진이 있으며, 예를 들어 SharedReplacingMergeTree는 ReplicatedReplacingMergeTree를 대체합니다.
SharedMergeTree 테이블 엔진 계열은 ClickHouse Cloud의 핵심 기반입니다. 최종 사용자는 ReplicatedMergeTree 기반 엔진 대신 SharedMergeTree 엔진 계열을 사용하기 위해 별도로 변경해야 할 사항이 없습니다. SharedMergeTree는 다음과 같은 추가 이점을 제공합니다:
- 더 높은 삽입 처리량
- 백그라운드 머지 처리량 향상
- 뮤테이션 처리량 향상
- 더 빠른 스케일 업 및 스케일 다운 작업
SELECT쿼리에 대한 더 가벼운 강한 일관성 제공
SharedMergeTree가 제공하는 중요한 개선 사항 중 하나는 ReplicatedMergeTree와 비교하여 컴퓨트와 스토리지 간의 분리를 한층 더 심화한다는 점입니다. 아래에서 ReplicatedMergeTree가 컴퓨트와 스토리지를 어떻게 분리하는지 확인할 수 있습니다:
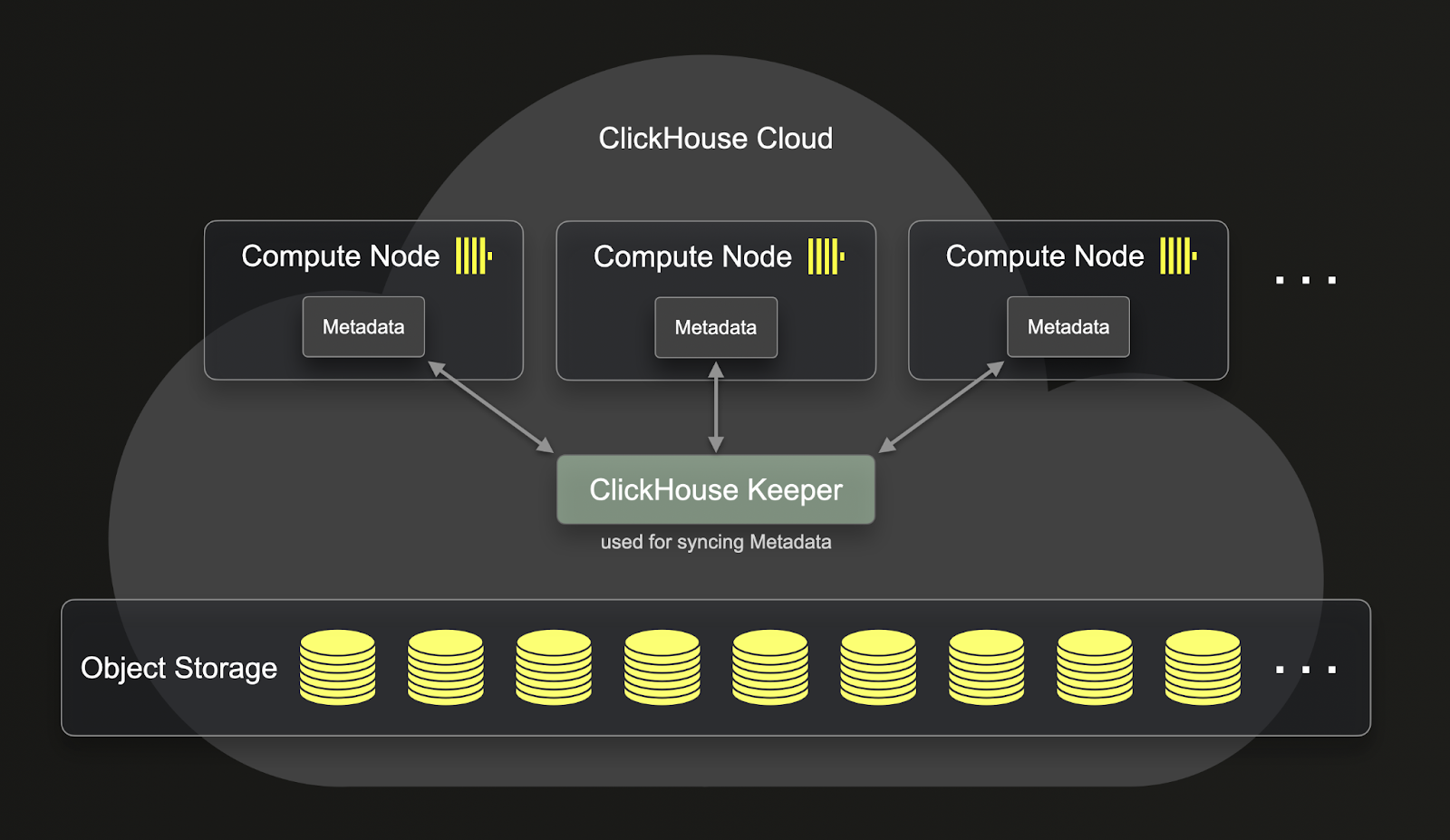
위 그림에서 보듯이, ReplicatedMergeTree의 데이터는 객체 스토리지에 저장되지만, 메타데이터는 여전히 각 clickhouse-server에 상주합니다. 이는 모든 복제 작업마다 메타데이터도 모든 레플리카에 복제되어야 함을 의미합니다.
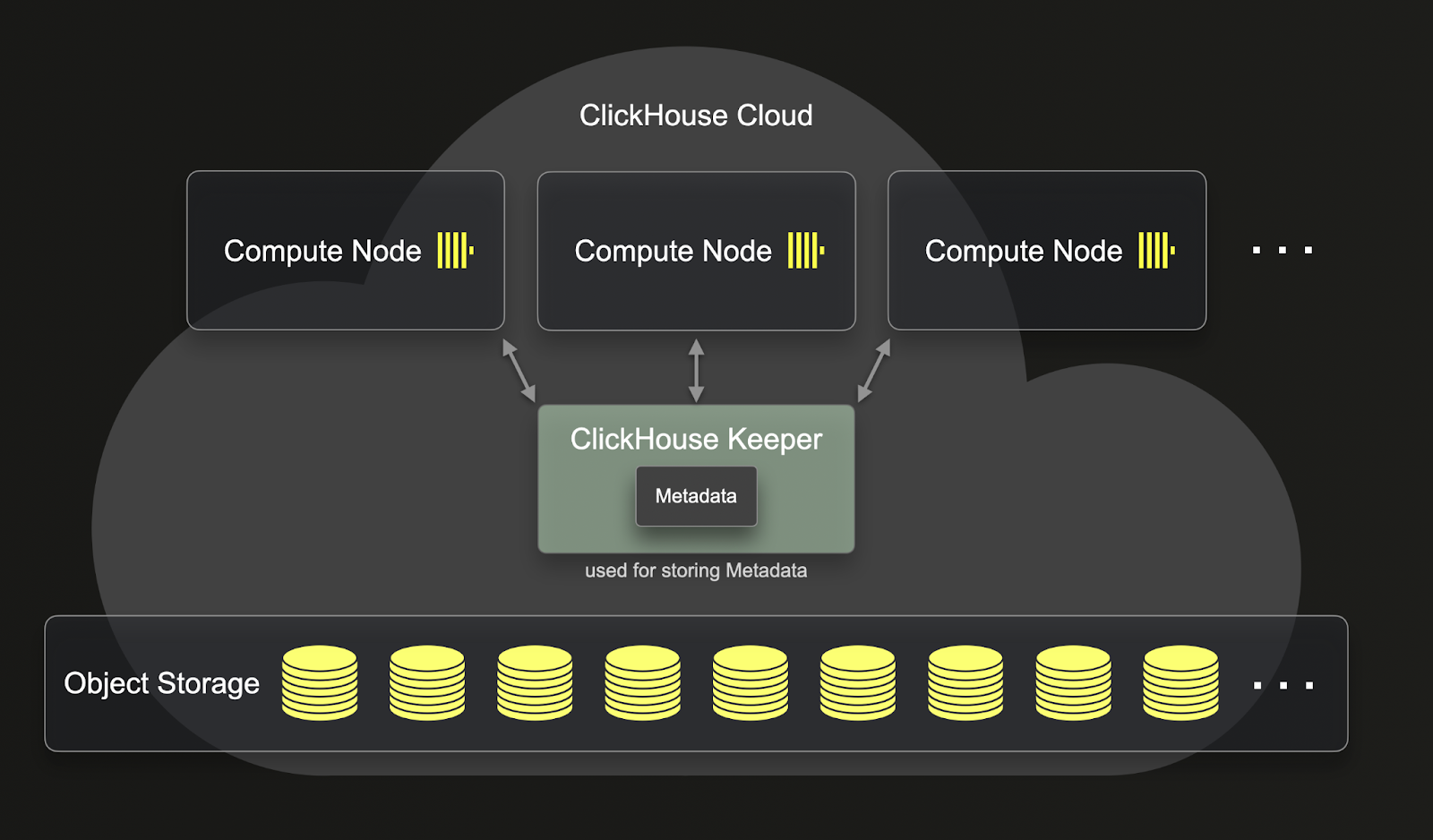
ReplicatedMergeTree와 달리 SharedMergeTree는 레플리카 간의 직접 통신을 필요로 하지 않습니다. 대신 모든 통신은 공유 스토리지와 clickhouse-keeper를 통해 이루어집니다. SharedMergeTree는 비동기 리더리스 복제를 구현하며, 조정 및 메타데이터 저장을 위해 clickhouse-keeper를 사용합니다. 이는 서비스가 스케일 업 및 스케일 다운될 때 메타데이터를 별도로 복제할 필요가 없음을 의미합니다. 그 결과 복제, 뮤테이션, 머지 및 스케일 업 작업이 더 빨라집니다. SharedMergeTree는 각 테이블에 대해 수백 개의 레플리카를 허용하여, 세그먼트 없이도 동적으로 스케일링하는 것이 가능해집니다. ClickHouse Cloud에서는 쿼리에 더 많은 컴퓨트 리소스를 활용하기 위해 분산 쿼리 실행 방식이 사용됩니다.
인트로스펙션
ReplicatedMergeTree 인트로스펙션에 사용되는 system 테이블 대부분은 SharedMergeTree에도 존재하지만, 데이터와 메타데이터의 복제가 발생하지 않기 때문에 system.replication_queue 및 system.replicated_fetches 는 존재하지 않습니다. 대신 SharedMergeTree에는 이 두 테이블에 해당하는 대체 테이블이 있습니다.
system.virtual_parts
이 테이블은 SharedMergeTree에서 system.replication_queue 를 대체하는 역할을 합니다. 현재 파트 집합 중 가장 최근 상태에 대한 정보와, 머지(merge), 뮤테이션(mutations), 삭제된 파티션(dropped partitions)과 같이 진행 중인 향후 파트에 대한 정보를 저장합니다.
system.shared_merge_tree_fetches
이 테이블은 SharedMergeTree에서 system.replicated_fetches 를 대체합니다. 기본 키(primary key)와 체크섬(checksum)을 메모리로 가져오는, 현재 진행 중인 fetch 작업에 대한 정보를 포함합니다.
SharedMergeTree 활성화
SharedMergeTree는 기본적으로 활성화되어 있습니다.
SharedMergeTree 테이블 엔진을 지원하는 서비스에서는 별도로 수동으로 활성화할 필요가 없습니다. 이전과 동일한 방식으로 테이블을 생성하면 CREATE TABLE 쿼리에서 지정한 엔진에 대응하는 SharedMergeTree 기반 테이블 엔진이 자동으로 사용됩니다.
이는 SharedMergeTree 테이블 엔진을 사용하여 my_table 테이블을 생성합니다.
ClickHouse Cloud에서는 default_table_engine=MergeTree로 설정되어 있으므로 ENGINE=MergeTree를 별도로 지정할 필요가 없습니다. 아래 쿼리는 위 쿼리와 동일합니다.
Replacing, Collapsing, Aggregating, Summing, VersionedCollapsing 또는 Graphite MergeTree 테이블을 사용하는 경우, 해당 테이블 엔진은 자동으로 이에 상응하는 SharedMergeTree 기반 테이블 엔진으로 변환됩니다.
특정 테이블에 대해 SHOW CREATE TABLE을(를) 사용하여 CREATE TABLE 문에서 어떤 테이블 엔진이 사용되었는지 확인할 수 있습니다:
설정
일부 설정의 동작이 크게 변경됩니다:
insert_quorum-- SharedMergeTree로의 모든 insert는 쿼럼 insert(공유 스토리지에 기록됨)이므로 SharedMergeTree 테이블 엔진을 사용할 때는 이 설정이 필요하지 않습니다.insert_quorum_parallel-- SharedMergeTree로의 모든 insert는 쿼럼 insert(공유 스토리지에 기록됨)이므로 SharedMergeTree 테이블 엔진을 사용할 때는 이 설정이 필요하지 않습니다.select_sequential_consistency-- 쿼럼 insert를 요구하지 않으며,SELECT쿼리에서 ClickHouse Keeper에 대한 추가 부하를 유발합니다.
Consistency
SharedMergeTree는 ReplicatedMergeTree보다 더 나은 경량 일관성을 제공합니다. SharedMergeTree에 데이터를 삽입할 때는 insert_quorum 또는 insert_quorum_parallel 같은 설정을 지정할 필요가 없습니다. 삽입은 쿼럼 삽입으로 동작하므로 메타데이터는 ClickHouse-Keeper에 저장되며, 이 메타데이터는 최소한 쿼럼에 해당하는 수의 ClickHouse-Keeper로 복제됩니다. 클러스터의 각 레플리카는 ClickHouse-Keeper에서 새로운 정보를 비동기적으로 가져옵니다.
대부분의 경우 select_sequential_consistency 또는 SYSTEM SYNC REPLICA LIGHTWEIGHT를 사용할 필요가 없습니다. 비동기 복제는 대부분의 시나리오를 커버하며 지연 시간이 매우 짧습니다. 오래된 데이터를 읽는 것(스테일 읽기)을 반드시 방지해야 하는 드문 경우에는 다음 권장 사항을 우선순위 순으로 따르십시오:
-
동일한 세션 또는 동일한 노드에서 쓰기와 읽기를 수행하는 경우, 해당 레플리카는 이미 최신 메타데이터를 보유하고 있으므로
select_sequential_consistency를 사용할 필요가 없습니다. -
한 레플리카에 쓰고 다른 레플리카에서 읽는 경우,
SYSTEM SYNC REPLICA LIGHTWEIGHT를 사용하여 해당 레플리카가 ClickHouse-Keeper에서 메타데이터를 가져오도록 강제할 수 있습니다. -
쿼리의 설정으로
select_sequential_consistency를 사용하십시오.
