GitHub 데이터를 사용하여 ClickHouse에서 쿼리 작성하기
이 데이터세트에는 ClickHouse 저장소의 모든 커밋과 변경 사항이 포함됩니다. ClickHouse와 함께 배포되는 네이티브 git-import 도구를 사용하여 생성할 수 있습니다.
생성된 데이터는 다음 각 테이블마다 하나의 tsv 파일을 제공합니다:
commits- 통계 정보를 포함한 커밋.file_changes- 각 커밋에서 변경된 파일과 해당 변경 정보 및 통계 정보.line_changes- 각 커밋에서 변경된 모든 파일의 변경된 모든 행에 대해, 해당 행에 대한 전체 정보와 이 행의 이전 변경에 대한 정보를 포함한 데이터.
2022년 11월 8일 기준으로, 각 TSV의 대략적인 크기와 행 수는 다음과 같습니다:
commits- 7.8M - 266,051 행file_changes- 53M - 266,051 행line_changes- 2.7G - 7,535,157 행
데이터 생성
이 단계는 선택 사항입니다. 데이터는 자유롭게 제공됩니다. 자세한 내용은 데이터 다운로드 및 삽입을 참고하십시오.
git clone git@github.com:ClickHouse/ClickHouse.git
cd ClickHouse
clickhouse git-import --skip-paths 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/' --skip-commits-with-messages '^Merge branch '
ClickHouse 저장소를 대상으로 실행할 경우 작업을 완료하는 데 약 3분 정도 소요됩니다(2022년 11월 8일 기준, MacBook Pro 2021에서 측정).
사용 가능한 전체 옵션 목록은 도구의 내장 도움말에서 확인할 수 있습니다.
clickhouse git-import -h
이 도움말에서는 위의 각 테이블에 대한 DDL도 제공합니다. 예를 들어,
CREATE TABLE git.commits
(
hash String,
author LowCardinality(String),
time DateTime,
message String,
files_added UInt32,
files_deleted UInt32,
files_renamed UInt32,
files_modified UInt32,
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
이 쿼리는 어떤 리포지토리에서나 실행할 수 있습니다. 자유롭게 탐색해 보고 분석 결과를 공유하십시오. 2022년 11월 기준 실행 시간에 대한 몇 가지 가이드라인은 다음과 같습니다.
- Linux -
~/clickhouse git-import- 160분
데이터 다운로드 및 삽입
다음 데이터는 동작 환경을 재현하는 데 사용할 수 있습니다. 또한 이 데이터셋은 play.clickhouse.com에서도 사용할 수 있습니다. 자세한 내용은 Queries를 참조하십시오.
다음 리포지토리용으로 생성된 파일은 아래와 같습니다.
- ClickHouse (2022년 11월 8일)
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/commits.tsv.xz - 2.5 MB
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/file_changes.tsv.xz - 4.5MB
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/line_changes.tsv.xz - 127.4 MB
- Linux (2022년 11월 8일)
이 데이터를 삽입하려면 다음 쿼리를 실행하여 데이터베이스를 준비하십시오:
DROP DATABASE IF EXISTS git;
CREATE DATABASE git;
CREATE TABLE git.commits
(
hash String,
author LowCardinality(String),
time DateTime,
message String,
files_added UInt32,
files_deleted UInt32,
files_renamed UInt32,
files_modified UInt32,
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
CREATE TABLE git.file_changes
(
change_type Enum('Add' = 1, 'Delete' = 2, 'Modify' = 3, 'Rename' = 4, 'Copy' = 5, 'Type' = 6),
path LowCardinality(String),
old_path LowCardinality(String),
file_extension LowCardinality(String),
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32,
commit_hash String,
author LowCardinality(String),
time DateTime,
commit_message String,
commit_files_added UInt32,
commit_files_deleted UInt32,
commit_files_renamed UInt32,
commit_files_modified UInt32,
commit_lines_added UInt32,
commit_lines_deleted UInt32,
commit_hunks_added UInt32,
commit_hunks_removed UInt32,
commit_hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
CREATE TABLE git.line_changes
(
sign Int8,
line_number_old UInt32,
line_number_new UInt32,
hunk_num UInt32,
hunk_start_line_number_old UInt32,
hunk_start_line_number_new UInt32,
hunk_lines_added UInt32,
hunk_lines_deleted UInt32,
hunk_context LowCardinality(String),
line LowCardinality(String),
indent UInt8,
line_type Enum('Empty' = 0, 'Comment' = 1, 'Punct' = 2, 'Code' = 3),
prev_commit_hash String,
prev_author LowCardinality(String),
prev_time DateTime,
file_change_type Enum('Add' = 1, 'Delete' = 2, 'Modify' = 3, 'Rename' = 4, 'Copy' = 5, 'Type' = 6),
path LowCardinality(String),
old_path LowCardinality(String),
file_extension LowCardinality(String),
file_lines_added UInt32,
file_lines_deleted UInt32,
file_hunks_added UInt32,
file_hunks_removed UInt32,
file_hunks_changed UInt32,
commit_hash String,
author LowCardinality(String),
time DateTime,
commit_message String,
commit_files_added UInt32,
commit_files_deleted UInt32,
commit_files_renamed UInt32,
commit_files_modified UInt32,
commit_lines_added UInt32,
commit_lines_deleted UInt32,
commit_hunks_added UInt32,
commit_hunks_removed UInt32,
commit_hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
INSERT INTO SELECT와 s3 함수를 사용해 데이터를 삽입합니다. 예를 들어 아래에서는 각 ClickHouse 파일을 해당하는 테이블에 삽입합니다:
commits
INSERT INTO git.commits SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/commits.tsv.xz', 'TSV', 'hash String,author LowCardinality(String), time DateTime, message String, files_added UInt32, files_deleted UInt32, files_renamed UInt32, files_modified UInt32, lines_added UInt32, lines_deleted UInt32, hunks_added UInt32, hunks_removed UInt32, hunks_changed UInt32')
0 rows in set. Elapsed: 1.826 sec. Processed 62.78 thousand rows, 8.50 MB (34.39 thousand rows/s., 4.66 MB/s.)
file_changes
INSERT INTO git.file_changes SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/file_changes.tsv.xz', 'TSV', 'change_type Enum(\'Add\' = 1, \'Delete\' = 2, \'Modify\' = 3, \'Rename\' = 4, \'Copy\' = 5, \'Type\' = 6), path LowCardinality(String), old_path LowCardinality(String), file_extension LowCardinality(String), lines_added UInt32, lines_deleted UInt32, hunks_added UInt32, hunks_removed UInt32, hunks_changed UInt32, commit_hash String, author LowCardinality(String), time DateTime, commit_message String, commit_files_added UInt32, commit_files_deleted UInt32, commit_files_renamed UInt32, commit_files_modified UInt32, commit_lines_added UInt32, commit_lines_deleted UInt32, commit_hunks_added UInt32, commit_hunks_removed UInt32, commit_hunks_changed UInt32')
0 rows in set. Elapsed: 2.688 sec. Processed 266.05 thousand rows, 48.30 MB (98.97 thousand rows/s., 17.97 MB/s.)
line_changes
INSERT INTO git.line_changes SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/line_changes.tsv.xz', 'TSV', ' sign Int8, line_number_old UInt32, line_number_new UInt32, hunk_num UInt32, hunk_start_line_number_old UInt32, hunk_start_line_number_new UInt32, hunk_lines_added UInt32,\n hunk_lines_deleted UInt32, hunk_context LowCardinality(String), line LowCardinality(String), indent UInt8, line_type Enum(\'Empty\' = 0, \'Comment\' = 1, \'Punct\' = 2, \'Code\' = 3), prev_commit_hash String, prev_author LowCardinality(String), prev_time DateTime, file_change_type Enum(\'Add\' = 1, \'Delete\' = 2, \'Modify\' = 3, \'Rename\' = 4, \'Copy\' = 5, \'Type\' = 6),\n path LowCardinality(String), old_path LowCardinality(String), file_extension LowCardinality(String), file_lines_added UInt32, file_lines_deleted UInt32, file_hunks_added UInt32, file_hunks_removed UInt32, file_hunks_changed UInt32, commit_hash String,\n author LowCardinality(String), time DateTime, commit_message String, commit_files_added UInt32, commit_files_deleted UInt32, commit_files_renamed UInt32, commit_files_modified UInt32, commit_lines_added UInt32, commit_lines_deleted UInt32, commit_hunks_added UInt32, commit_hunks_removed UInt32, commit_hunks_changed UInt32')
0 rows in set. Elapsed: 50.535 sec. Processed 7.54 million rows, 2.09 GB (149.11 thousand rows/s., 41.40 MB/s.)
Queries
이 도구는 help 출력에서 여러 쿼리를 제안합니다. 본 문서에서는 이에 대한 답변과 함께, 추가로 흥미로운 보충 질문들에 대한 답변도 제공합니다. 이 쿼리들은 도구가 임의로 나열한 순서와는 별개로, 대략적으로 난이도가 증가하는 순서로 정리되어 있습니다.
이 데이터셋은 play.clickhouse.com의 git_clickhouse 데이터베이스에서 사용할 수 있습니다. 모든 쿼리에 대해 필요에 따라 데이터베이스 이름을 조정하여 이 환경에 대한 링크를 제공합니다. 데이터 수집 시점의 차이로 인해, play 환경에서의 결과는 여기서 제시된 결과와 달라질 수 있습니다.
단일 파일의 변경 이력
가장 간단한 쿼리입니다. 여기서는 StorageReplicatedMergeTree.cpp에 대한 모든 커밋 메시지를 살펴봅니다. 이 메시지들이 더 흥미로울 수 있으므로, 가장 최근 메시지가 먼저 오도록 정렬합니다.
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
change_type,
author,
path,
old_path,
lines_added,
lines_deleted,
commit_message
FROM git.file_changes
WHERE path = 'src/Storages/StorageReplicatedMergeTree.cpp'
ORDER BY time DESC
LIMIT 10
┌────────────────time─┬─commit──────┬─change_type─┬─author─────────────┬─path────────────────────────────────────────┬─old_path─┬─lines_added─┬─lines_deleted─┬─commit_message───────────────────────────────────┐
│ 2022-10-30 16:30:51 │ c68ab231f91 │ Modify │ Alexander Tokmakov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 13 │ 10 │ fix accessing part in Deleting state │
│ 2022-10-23 16:24:20 │ b40d9200d20 │ Modify │ Anton Popov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 28 │ 30 │ better semantic of constsness of DataPartStorage │
│ 2022-10-23 01:23:15 │ 56e5daba0c9 │ Modify │ Anton Popov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 28 │ 44 │ remove DataPartStorageBuilder │
│ 2022-10-21 13:35:37 │ 851f556d65a │ Modify │ Igor Nikonov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 2 │ Remove unused parameter │
│ 2022-10-21 13:02:52 │ 13d31eefbc3 │ Modify │ Igor Nikonov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 4 │ 4 │ Replicated merge tree polishing │
│ 2022-10-21 12:25:19 │ 4e76629aafc │ Modify │ Azat Khuzhin │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 2 │ Fixes for -Wshorten-64-to-32 │
│ 2022-10-19 13:59:28 │ 05e6b94b541 │ Modify │ Antonio Andelic │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 4 │ 0 │ Polishing │
│ 2022-10-19 13:34:20 │ e5408aac991 │ Modify │ Antonio Andelic │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 53 │ Simplify logic │
│ 2022-10-18 15:36:11 │ 7befe2825c9 │ Modify │ Alexey Milovidov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 2 │ 2 │ Update StorageReplicatedMergeTree.cpp │
│ 2022-10-18 15:35:44 │ 0623ad4e374 │ Modify │ Alexey Milovidov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 1 │ 1 │ Update StorageReplicatedMergeTree.cpp │
└─────────────────────┴─────────────┴─────────────┴────────────────────┴─────────────────────────────────────────────┴──────────┴─────────────┴───────────────┴──────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.006 sec. Processed 12.10 thousand rows, 1.60 MB (1.93 million rows/s., 255.40 MB/s.)
파일 이름 변경은 제외하고, 즉 파일이 다른 이름으로 존재하던 시점 이전의 변경 사항은 표시하지 않은 채 줄 단위 변경 이력만 검토할 수도 있습니다:
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
sign,
line_number_old,
line_number_new,
author,
line
FROM git.line_changes
WHERE path = 'src/Storages/StorageReplicatedMergeTree.cpp'
ORDER BY line_number_new ASC
LIMIT 10
┌────────────────time─┬─commit──────┬─sign─┬─line_number_old─┬─line_number_new─┬─author───────────┬─line──────────────────────────────────────────────────┐
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ -1 │ 1 │ 1 │ Alexey Milovidov │ #include <Disks/DiskSpaceMonitor.h> │
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ 1 │ 2 │ 1 │ Alexey Milovidov │ #include <Core/Defines.h> │
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ 1 │ 2 │ 2 │ Alexey Milovidov │ │
│ 2021-05-03 23:46:51 │ 02ce9cc7254 │ -1 │ 3 │ 2 │ Alexey Milovidov │ #include <Common/FieldVisitors.h> │
│ 2021-05-27 22:21:02 │ e2f29b9df02 │ -1 │ 3 │ 2 │ s-kat │ #include <Common/FieldVisitors.h> │
│ 2022-10-03 22:30:50 │ 210882b9c4d │ 1 │ 2 │ 3 │ alesapin │ #include <ranges> │
│ 2022-10-23 16:24:20 │ b40d9200d20 │ 1 │ 2 │ 3 │ Anton Popov │ #include <cstddef> │
│ 2021-06-20 09:24:43 │ 4c391f8e994 │ 1 │ 2 │ 3 │ Mike Kot │ #include "Common/hex.h" │
│ 2021-12-29 09:18:56 │ 8112a712336 │ -1 │ 6 │ 5 │ avogar │ #include <Common/ThreadPool.h> │
│ 2022-04-21 20:19:13 │ 9133e398b8c │ 1 │ 11 │ 12 │ Nikolai Kochetov │ #include <Storages/MergeTree/DataPartStorageOnDisk.h> │
└─────────────────────┴─────────────┴──────┴─────────────────┴─────────────────┴──────────────────┴───────────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.258 sec. Processed 7.54 million rows, 654.92 MB (29.24 million rows/s., 2.54 GB/s.)
이 쿼리보다 더 복잡한 형태로, 이름 변경을 고려하여 파일의 줄 단위 커밋 이력을 조회하는 방법이 있습니다.
현재 활성 파일 찾기
이 단계는 이후 분석에서 저장소의 현재 파일만을 대상으로 하기 위해 중요합니다. 이 집합은 이름이 변경되거나 삭제되었다가(그 후 다시 추가되거나 이름이 다시 변경된) 않은 파일들로 추정합니다.
dbms, libs, tests/testflows/ 디렉터리의 파일들의 이름이 변경되는 과정에서 커밋 이력이 손상된 것으로 보입니다. 따라서 이들 역시 제외합니다.
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)') ORDER BY path
LIMIT 10
┌─path────────────────────────────────────────────────────────────┐
│ tests/queries/0_stateless/01054_random_printable_ascii_ubsan.sh │
│ tests/queries/0_stateless/02247_read_bools_as_numbers_json.sh │
│ tests/performance/file_table_function.xml │
│ tests/queries/0_stateless/01902_self_aliases_in_columns.sql │
│ tests/queries/0_stateless/01070_h3_get_base_cell.reference │
│ src/Functions/ztest.cpp │
│ src/Interpreters/InterpreterShowTablesQuery.h │
│ src/Parsers/Kusto/ParserKQLStatement.h │
│ tests/queries/0_stateless/00938_dataset_test.sql │
│ src/Dictionaries/Embedded/GeodataProviders/Types.h │
└─────────────────────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.085 sec. Processed 532.10 thousand rows, 8.68 MB (6.30 million rows/s., 102.64 MB/s.)
이는 파일 이름을 변경한 후 다시 원래 이름으로 되돌리는 것도 가능하다는 점에 유의해야 합니다. 먼저 이름 변경으로 인해 삭제된 파일 목록에 대해 old_path를 집계합니다. 그런 다음 각 path에 대한 마지막 작업과 이를 UNION 합니다. 마지막으로, 최종 이벤트가 Delete가 아닌 항목만 남도록 이 목록을 필터링합니다.
SELECT uniq(path)
FROM
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)') ORDER BY path
)
┌─uniq(path)─┐
│ 18559 │
└────────────┘
1 row in set. Elapsed: 0.089 sec. Processed 532.10 thousand rows, 8.68 MB (6.01 million rows/s., 97.99 MB/s.)
다음과 같이 가져오기 과정에서 여러 디렉터리를 건너뛰었다는 점에 유의하십시오.
--skip-paths 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/'
이 패턴을 git list-files에 적용하면 18,155개의 파일이 보고됩니다.
git ls-files | grep -v -E 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/' | wc -l
18155
따라서 현재 솔루션은 현재 파일 수에 대한 추정치일 뿐입니다
여기에서 나타나는 차이는 다음과 같은 몇 가지 요인에서 비롯됩니다:
- 파일 이름 변경은 파일에 대한 다른 수정과 함께 발생할 수 있습니다. 이러한 변경 사항은
file_changes에서 동일한 시각을 가지는 별도의 이벤트로 나열됩니다.argMax함수는 이를 구분할 방법이 없어 첫 번째 값을 선택합니다. 데이터 삽입의 자연스러운 순서(정확한 순서를 알 수 있는 유일한 수단)는union연산 결과 전반에서 유지되지 않으므로 수정(Modify) 이벤트가 선택될 수 있습니다. 예를 들어, 아래에서src/Functions/geometryFromColumn.h파일은src/Functions/geometryConverters.h로 이름이 변경되기 전에 여러 번 수정됩니다. 현재 사용 중인 해결 방식에서는 Modify 이벤트를 최신 변경으로 선택하여src/Functions/geometryFromColumn.h가 유지되는 결과를 초래할 수 있습니다.
SELECT
change_type,
path,
old_path,
time,
commit_hash
FROM git.file_changes
WHERE (path = 'src/Functions/geometryFromColumn.h') OR (old_path = 'src/Functions/geometryFromColumn.h')
┌─change_type─┬─path───────────────────────────────┬─old_path───────────────────────────┬────────────────time─┬─commit_hash──────────────────────────────┐
│ Add │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 9376b676e9a9bb8911b872e1887da85a45f7479d │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 6d59be5ea4768034f6526f7f9813062e0c369f7b │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 33acc2aa5dc091a7cb948f78c558529789b2bad8 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 78e0db268ceadc42f82bc63a77ee1a4da6002463 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 14a891057d292a164c4179bfddaef45a74eaf83a │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ d0d6e6953c2a2af9fb2300921ff96b9362f22edb │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ fe8382521139a58c0ba277eb848e88894658db66 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 3be3d5cde8788165bc0558f1e2a22568311c3103 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ afad9bf4d0a55ed52a3f55483bc0973456e10a56 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ e3290ecc78ca3ea82b49ebcda22b5d3a4df154e6 │
│ Rename │ src/Functions/geometryConverters.h │ src/Functions/geometryFromColumn.h │ 2021-03-11 12:08:16 │ 125945769586baf6ffd15919b29565b1b2a63218 │
└─────────────┴────────────────────────────────────┴────────────────────────────────────┴─────────────────────┴──────────────────────────────────────────┘
11 rows in set. Elapsed: 0.030 sec. Processed 266.05 thousand rows, 6.61 MB (8.89 million rows/s., 220.82 MB/s.)
- 손상된 커밋 히스토리 - delete 이벤트가 누락되었습니다. 데이터 소스와 원인은 추후 결정 예정입니다.
이러한 차이는 분석 결과에 유의미한 영향을 주지 않을 것입니다. 이 쿼리의 개선된 버전을 제안해 주시면 환영합니다.
수정이 가장 많은 파일 나열
현재 파일로 한정하면, 수정 횟수는 삭제와 추가 횟수의 합으로 간주합니다.
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) + sum(lines_deleted) AS modifications
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
ORDER BY modifications DESC
LIMIT 10
┌─path───────────────────────────────────────────────────┬─modifications─┐
│ src/Storages/StorageReplicatedMergeTree.cpp │ 21871 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 17709 │
│ programs/client/Client.cpp │ 15882 │
│ src/Storages/MergeTree/MergeTreeDataSelectExecutor.cpp │ 14249 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 12636 │
│ src/Parsers/ExpressionListParsers.cpp │ 11794 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 11760 │
│ src/Coordination/KeeperStorage.cpp │ 10225 │
│ src/Functions/FunctionsConversion.h │ 9247 │
│ src/Parsers/ExpressionElementParsers.cpp │ 8197 │
└────────────────────────────────────────────────────────┴───────────────┘
10 rows in set. Elapsed: 0.134 sec. Processed 798.15 thousand rows, 16.46 MB (5.95 million rows/s., 122.62 MB/s.)
커밋은 주로 일주일 중 어느 요일에 발생합니까?
SELECT
day_of_week,
count() AS c
FROM git.commits
GROUP BY dayOfWeek(time) AS day_of_week
┌─day_of_week─┬─────c─┐
│ 1 │ 10575 │
│ 2 │ 10645 │
│ 3 │ 10748 │
│ 4 │ 10944 │
│ 5 │ 10090 │
│ 6 │ 4617 │
│ 7 │ 5166 │
└─────────────┴───────┘
7 rows in set. Elapsed: 0.262 sec. Processed 62.78 thousand rows, 251.14 KB (239.73 thousand rows/s., 958.93 KB/s.)
금요일에 생산성이 다소 떨어지는 양상과도 잘 들어맞습니다. 주말에도 코드를 커밋해 주시는 것을 보니 정말 반갑습니다! 기여자 여러분께 진심으로 감사드립니다!
하위 디렉터리/파일의 변경 이력 - 시간 경과에 따른 줄 수, 커밋 수 및 기여자 수
이 쿼리는 필터를 적용하지 않으면 표시하거나 시각화하기에 현실적이지 않을 정도로 큰 결과를 생성합니다. 따라서 아래 예제에서는 파일이나 하위 디렉터리를 기준으로 필터링하도록 합니다. 여기서는 toStartOfWeek 함수를 사용해 주 단위로 그룹화합니다. 필요에 따라 수정하십시오.
SELECT
week,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted,
uniq(commit_hash) AS num_commits,
uniq(author) AS authors
FROM git.file_changes
WHERE path LIKE 'src/Storages%'
GROUP BY toStartOfWeek(time) AS week
ORDER BY week ASC
LIMIT 10
┌───────week─┬─lines_added─┬─lines_deleted─┬─num_commits─┬─authors─┐
│ 2020-03-29 │ 49 │ 35 │ 4 │ 3 │
│ 2020-04-05 │ 940 │ 601 │ 55 │ 14 │
│ 2020-04-12 │ 1472 │ 607 │ 32 │ 11 │
│ 2020-04-19 │ 917 │ 841 │ 39 │ 12 │
│ 2020-04-26 │ 1067 │ 626 │ 36 │ 10 │
│ 2020-05-03 │ 514 │ 435 │ 27 │ 10 │
│ 2020-05-10 │ 2552 │ 537 │ 48 │ 12 │
│ 2020-05-17 │ 3585 │ 1913 │ 83 │ 9 │
│ 2020-05-24 │ 2851 │ 1812 │ 74 │ 18 │
│ 2020-05-31 │ 2771 │ 2077 │ 77 │ 16 │
└────────────┴─────────────┴───────────────┴─────────────┴─────────┘
10 rows in set. Elapsed: 0.043 sec. Processed 266.05 thousand rows, 15.85 MB (6.12 million rows/s., 364.61 MB/s.)
이 데이터는 시각화에 적합합니다. 아래에서는 Superset을 사용합니다.
추가 및 삭제된 라인 수:
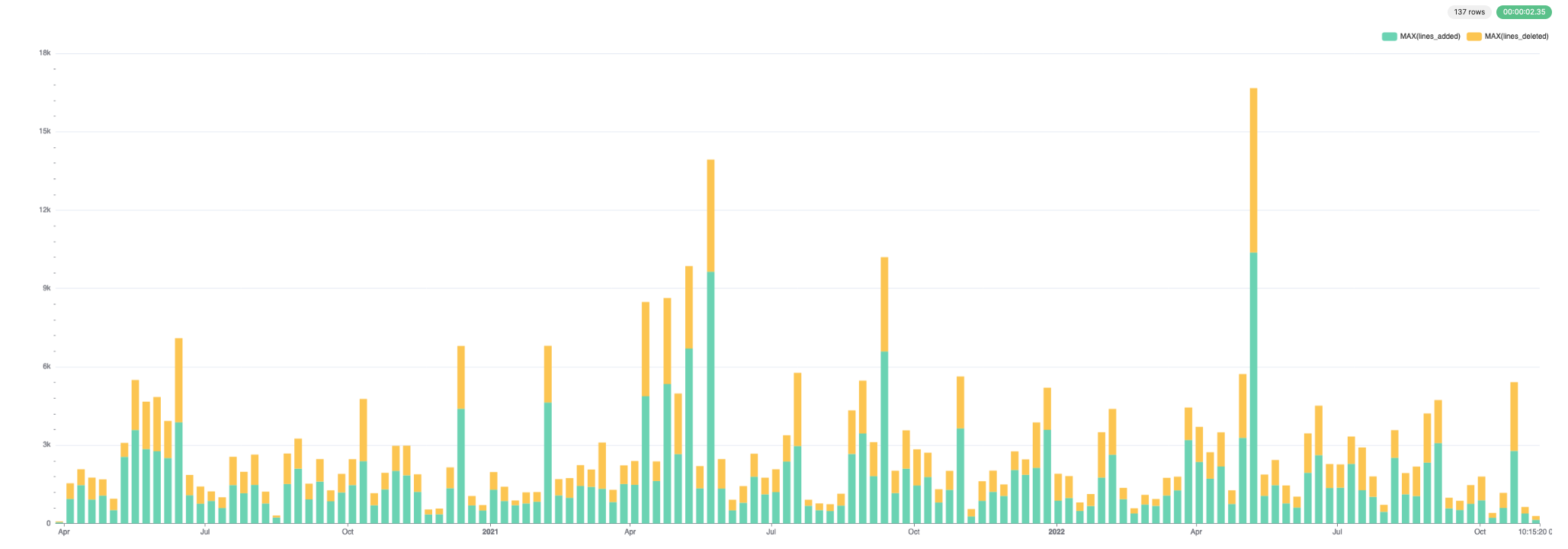
커밋 및 작성자:
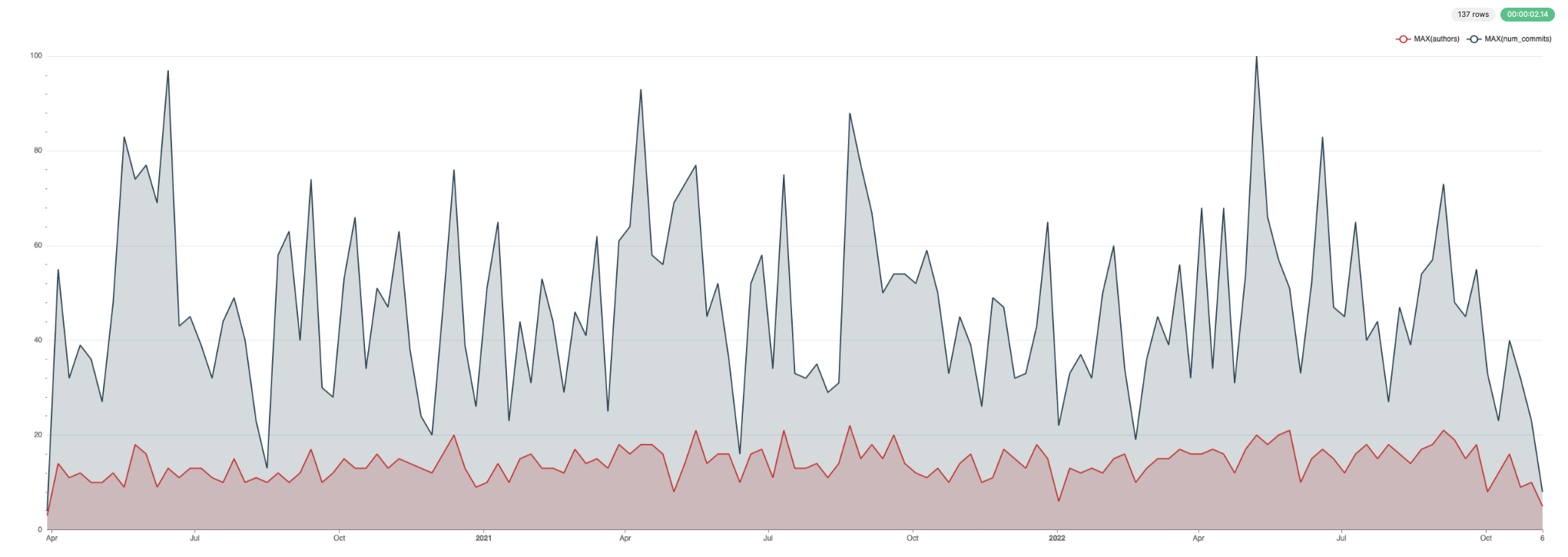
작성자가 가장 많은 파일 목록
현재 존재하는 파일로만 제한합니다.
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
uniq(author) AS num_authors
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY num_authors DESC
LIMIT 10
┌─path────────────────────────────────────────┬─num_authors─┐
│ src/Core/Settings.h │ 127 │
│ CMakeLists.txt │ 96 │
│ .gitmodules │ 85 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 72 │
│ src/CMakeLists.txt │ 71 │
│ programs/server/Server.cpp │ 70 │
│ src/Interpreters/Context.cpp │ 64 │
│ src/Storages/StorageReplicatedMergeTree.cpp │ 63 │
│ src/Common/ErrorCodes.cpp │ 61 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 59 │
└─────────────────────────────────────────────┴─────────────┘
10 rows in set. Elapsed: 0.239 sec. Processed 798.15 thousand rows, 14.13 MB (3.35 million rows/s., 59.22 MB/s.)
저장소에서 가장 오래된 코드 줄
현재 파일에만 적용됩니다.
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
any(path) AS file_path,
line,
max(time) AS latest_change,
any(file_change_type)
FROM git.line_changes
WHERE path IN (current_files)
GROUP BY line
ORDER BY latest_change ASC
LIMIT 10
┌─file_path───────────────────────────────────┬─line────────────────────────────────────────────────────────┬───────latest_change─┬─any(file_change_type)─┐
│ utils/compressor/test.sh │ ./compressor -d < compressor.snp > compressor2 │ 2011-06-17 22:19:39 │ Modify │
│ utils/compressor/test.sh │ ./compressor < compressor > compressor.snp │ 2011-06-17 22:19:39 │ Modify │
│ utils/compressor/test.sh │ ./compressor -d < compressor.qlz > compressor2 │ 2014-02-24 03:14:30 │ Add │
│ utils/compressor/test.sh │ ./compressor < compressor > compressor.qlz │ 2014-02-24 03:14:30 │ Add │
│ utils/config-processor/config-processor.cpp │ if (argc != 2) │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "std::exception: " << e.what() << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "Exception: " << e.displayText() << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ Poco::XML::DOMWriter().writeNode(std::cout, document); │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "Some exception" << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "usage: " << argv[0] << " path" << std::endl; │ 2014-02-26 19:10:00 │ Add │
└─────────────────────────────────────────────┴─────────────────────────────────────────────────────────────┴─────────────────────┴───────────────────────┘
10 rows in set. Elapsed: 1.101 sec. Processed 8.07 million rows, 905.86 MB (7.33 million rows/s., 823.13 MB/s.)
변경 이력이 가장 오래된 파일
현재 파일만 대상으로 합니다.
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
count() AS c,
path,
max(time) AS latest_change
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌───c─┬─path────────────────────────────────────────┬───────latest_change─┐
│ 790 │ src/Storages/StorageReplicatedMergeTree.cpp │ 2022-10-30 16:30:51 │
│ 788 │ src/Storages/MergeTree/MergeTreeData.cpp │ 2022-11-04 09:26:44 │
│ 752 │ src/Core/Settings.h │ 2022-10-25 11:35:25 │
│ 749 │ CMakeLists.txt │ 2022-10-05 21:00:49 │
│ 575 │ src/Interpreters/InterpreterSelectQuery.cpp │ 2022-11-01 10:20:10 │
│ 563 │ CHANGELOG.md │ 2022-10-27 08:19:50 │
│ 491 │ src/Interpreters/Context.cpp │ 2022-10-25 12:26:29 │
│ 437 │ programs/server/Server.cpp │ 2022-10-21 12:25:19 │
│ 375 │ programs/client/Client.cpp │ 2022-11-03 03:16:55 │
│ 350 │ src/CMakeLists.txt │ 2022-10-24 09:22:37 │
└─────┴─────────────────────────────────────────────┴─────────────────────┘
10 rows in set. Elapsed: 0.124 sec. Processed 798.15 thousand rows, 14.71 MB (6.44 million rows/s., 118.61 MB/s.)
핵심 데이터 구조인 MergeTree는 긴 역사 속에서 수많은 수정이 이루어져 왔으며, 지금도 끊임없이 발전하고 있습니다!
한 달 동안 문서와 코드 기준으로 본 기여자 분포
데이터를 수집하는 동안 커밋 이력이 지나치게 지저분해 docs/ 폴더의 변경 사항은 제외되었습니다. 따라서 이 쿼리의 결과는 정확하지 않습니다.
월별로 특정 시점(예: 릴리스 날짜 전후)에 더 많은 문서를 작성하는지 확인할 수 있습니다. 이를 위해 countIf 함수로 간단한 비율을 계산하고, bar 함수를 사용해 결과를 시각화할 수 있습니다.
SELECT
day,
bar(docs_ratio * 1000, 0, 100, 100) AS bar
FROM
(
SELECT
day,
countIf(file_extension IN ('h', 'cpp', 'sql')) AS code,
countIf(file_extension = 'md') AS docs,
docs / (code + docs) AS docs_ratio
FROM git.line_changes
WHERE (sign = 1) AND (file_extension IN ('h', 'cpp', 'sql', 'md'))
GROUP BY dayOfMonth(time) AS day
)
┌─day─┬─bar─────────────────────────────────────────────────────────────┐
│ 1 │ ███████████████████████████████████▍ │
│ 2 │ ███████████████████████▋ │
│ 3 │ ████████████████████████████████▋ │
│ 4 │ █████████████ │
│ 5 │ █████████████████████▎ │
│ 6 │ ████████ │
│ 7 │ ███▋ │
│ 8 │ ████████▌ │
│ 9 │ ██████████████▎ │
│ 10 │ █████████████████▏ │
│ 11 │ █████████████▎ │
│ 12 │ ███████████████████████████████████▋ │
│ 13 │ █████████████████████████████▎ │
│ 14 │ ██████▋ │
│ 15 │ █████████████████████████████████████████▊ │
│ 16 │ ██████████▎ │
│ 17 │ ██████████████████████████████████████▋ │
│ 18 │ █████████████████████████████████▌ │
│ 19 │ ███████████ │
│ 20 │ █████████████████████████████████▊ │
│ 21 │ █████ │
│ 22 │ ███████████████████████▋ │
│ 23 │ ███████████████████████████▌ │
│ 24 │ ███████▌ │
│ 25 │ ██████████████████████████████████▎ │
│ 26 │ ███████████▏ │
│ 27 │ ███████████████████████████████████████████████████████████████ │
│ 28 │ ████████████████████████████████████████████████████▏ │
│ 29 │ ███▌ │
│ 30 │ ████████████████████████████████████████▎ │
│ 31 │ █████████████████████████████████▏ │
└─────┴─────────────────────────────────────────────────────────────────┘
31 rows in set. Elapsed: 0.043 sec. Processed 7.54 million rows, 40.53 MB (176.71 million rows/s., 950.40 MB/s.)
아마도 월말 무렵에 수치가 조금 더 높아지기는 하지만, 전반적으로는 균등한 분포를 잘 유지합니다. 다만 데이터 삽입 시 적용되는 문서 필터링 때문에 이 분포는 완전히 신뢰하기는 어렵습니다.
가장 다양한 파일에 기여한 작성자
여기서 「다양성」은 한 작성자가 기여한 서로 다른 파일의 개수를 의미합니다.
SELECT
author,
uniq(path) AS num_files
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY author
ORDER BY num_files DESC
LIMIT 10
┌─author─────────────┬─num_files─┐
│ Alexey Milovidov │ 8433 │
│ Nikolai Kochetov │ 3257 │
│ Vitaly Baranov │ 2316 │
│ Maksim Kita │ 2172 │
│ Azat Khuzhin │ 1988 │
│ alesapin │ 1818 │
│ Alexander Tokmakov │ 1751 │
│ Amos Bird │ 1641 │
│ Ivan │ 1629 │
│ alexey-milovidov │ 1581 │
└────────────────────┴───────────┘
10 rows in set. Elapsed: 0.041 sec. Processed 266.05 thousand rows, 4.92 MB (6.56 million rows/s., 121.21 MB/s.)
최근 작업에서 누가 가장 다양한 커밋을 했는지 살펴보겠습니다. 날짜로 제한하는 대신, 특정 작성자의 최근 N개의 커밋만 대상으로 하겠습니다(여기서는 3개를 사용했지만, 원하는 대로 수정해도 됩니다):
SELECT
author,
sum(num_files_commit) AS num_files
FROM
(
SELECT
author,
commit_hash,
uniq(path) AS num_files_commit,
max(time) AS commit_time
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
author,
commit_hash
ORDER BY
author ASC,
commit_time DESC
LIMIT 3 BY author
)
GROUP BY author
ORDER BY num_files DESC
LIMIT 10
┌─author───────────────┬─num_files─┐
│ Mikhail │ 782 │
│ Li Yin │ 553 │
│ Roman Peshkurov │ 119 │
│ Vladimir Smirnov │ 88 │
│ f1yegor │ 65 │
│ maiha │ 54 │
│ Vitaliy Lyudvichenko │ 53 │
│ Pradeep Chhetri │ 40 │
│ Orivej Desh │ 38 │
│ liyang │ 36 │
└──────────────────────┴───────────┘
10 rows in set. Elapsed: 0.106 sec. Processed 266.05 thousand rows, 21.04 MB (2.52 million rows/s., 198.93 MB/s.)
특정 작성자의 선호 파일
여기서는 창립자인 Alexey Milovidov을 선택하고 현재 파일로 분석 범위를 제한합니다.
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
count() AS c
FROM git.file_changes
WHERE (author = 'Alexey Milovidov') AND (path IN (current_files))
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌─path────────────────────────────────────────┬───c─┐
│ CMakeLists.txt │ 165 │
│ CHANGELOG.md │ 126 │
│ programs/server/Server.cpp │ 73 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 71 │
│ src/Storages/StorageReplicatedMergeTree.cpp │ 68 │
│ src/Core/Settings.h │ 65 │
│ programs/client/Client.cpp │ 57 │
│ programs/server/play.html │ 48 │
│ .gitmodules │ 47 │
│ programs/install/Install.cpp │ 37 │
└─────────────────────────────────────────────┴─────┘
10 rows in set. Elapsed: 0.106 sec. Processed 798.15 thousand rows, 13.97 MB (7.51 million rows/s., 131.41 MB/s.)
이는 Alexey가 변경 로그(Change log)를 유지 관리해 온 책임자이기 때문에 이해할 수 있는 결과입니다. 하지만 파일의 기본 이름을 사용해 그가 기여한 인기 있는 파일을 식별하도록 해 보겠습니다. 이렇게 하면 파일 이름이 변경되더라도 추적할 수 있고, 코드 기여에 더욱 초점을 맞출 수 있습니다.
SELECT
base,
count() AS c
FROM git.file_changes
WHERE (author = 'Alexey Milovidov') AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY basename(path) AS base
ORDER BY c DESC
LIMIT 10
┌─base───────────────────────────┬───c─┐
│ StorageReplicatedMergeTree.cpp │ 393 │
│ InterpreterSelectQuery.cpp │ 299 │
│ Aggregator.cpp │ 297 │
│ Client.cpp │ 280 │
│ MergeTreeData.cpp │ 274 │
│ Server.cpp │ 264 │
│ ExpressionAnalyzer.cpp │ 259 │
│ StorageMergeTree.cpp │ 239 │
│ Settings.h │ 225 │
│ TCPHandler.cpp │ 205 │
└────────────────────────────────┴─────┘
10 rows in set. Elapsed: 0.032 sec. Processed 266.05 thousand rows, 5.68 MB (8.22 million rows/s., 175.50 MB/s.)
이는 아마 그의 관심 분야를 더 잘 반영합니다.
작성자 수가 가장 적은 대용량 파일
이를 위해 먼저 가장 큰 파일을 식별해야 합니다. 커밋 히스토리 전체에서 모든 파일을 대상으로, 파일을 완전히 재구성하여 크기를 추정하는 방식은 비용이 매우 많이 듭니다.
이를 추정하기 위해, 현재 존재하는 파일로만 범위를 제한한다고 가정하고 추가된 라인 수를 합산한 뒤 삭제된 라인 수를 뺍니다. 그런 다음 파일 길이를 작성자 수로 나눈 비율을 계산할 수 있습니다.
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY lines_author_ratio DESC
LIMIT 10
┌─path──────────────────────────────────────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ src/Common/ClassificationDictionaries/emotional_dictionary_rus.txt │ 148590 │ 1 │ 148590 │
│ src/Functions/ClassificationDictionaries/emotional_dictionary_rus.txt │ 55533 │ 1 │ 55533 │
│ src/Functions/ClassificationDictionaries/charset_freq.txt │ 35722 │ 1 │ 35722 │
│ src/Common/ClassificationDictionaries/charset_freq.txt │ 35722 │ 1 │ 35722 │
│ tests/integration/test_storage_meilisearch/movies.json │ 19549 │ 1 │ 19549 │
│ tests/queries/0_stateless/02364_multiSearch_function_family.reference │ 12874 │ 1 │ 12874 │
│ src/Functions/ClassificationDictionaries/programming_freq.txt │ 9434 │ 1 │ 9434 │
│ src/Common/ClassificationDictionaries/programming_freq.txt │ 9434 │ 1 │ 9434 │
│ tests/performance/explain_ast.xml │ 5911 │ 1 │ 5911 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 5686 │ 1 │ 5686 │
└───────────────────────────────────────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 rows in set. Elapsed: 0.138 sec. Processed 798.15 thousand rows, 16.57 MB (5.79 million rows/s., 120.11 MB/s.)
텍스트 사전을 만드는 것은 그다지 현실적이지 않으므로, 파일 확장자 필터를 사용해 코드 파일만 대상으로 제한해 보겠습니다!
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
ORDER BY lines_author_ratio DESC
LIMIT 10
┌─path──────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ src/Analyzer/QueryAnalysisPass.cpp │ 5686 │ 1 │ 5686 │
│ src/Analyzer/QueryTreeBuilder.cpp │ 880 │ 1 │ 880 │
│ src/Planner/Planner.cpp │ 873 │ 1 │ 873 │
│ src/Backups/RestorerFromBackup.cpp │ 869 │ 1 │ 869 │
│ utils/memcpy-bench/FastMemcpy.h │ 770 │ 1 │ 770 │
│ src/Planner/PlannerActionsVisitor.cpp │ 765 │ 1 │ 765 │
│ src/Functions/sphinxstemen.cpp │ 728 │ 1 │ 728 │
│ src/Planner/PlannerJoinTree.cpp │ 708 │ 1 │ 708 │
│ src/Planner/PlannerJoins.cpp │ 695 │ 1 │ 695 │
│ src/Analyzer/QueryNode.h │ 607 │ 1 │ 607 │
└───────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 rows in set. Elapsed: 0.140 sec. Processed 798.15 thousand rows, 16.84 MB (5.70 million rows/s., 120.32 MB/s.)
여기에는 최근에 생성된 파일 쪽으로 약간의 편향이 있습니다. 새 파일은 커밋할 수 있는 기회가 더 적기 때문입니다. 최소 1년 이상 된 파일로만 제한하면 어떨까요?
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
min(time) AS min_date,
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
HAVING min_date <= (now() - toIntervalYear(1))
ORDER BY lines_author_ratio DESC
LIMIT 10
┌────────────min_date─┬─path───────────────────────────────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ 2021-03-08 07:00:54 │ utils/memcpy-bench/FastMemcpy.h │ 770 │ 1 │ 770 │
│ 2021-05-04 13:47:34 │ src/Functions/sphinxstemen.cpp │ 728 │ 1 │ 728 │
│ 2021-03-14 16:52:51 │ utils/memcpy-bench/glibc/dwarf2.h │ 592 │ 1 │ 592 │
│ 2021-03-08 09:04:52 │ utils/memcpy-bench/FastMemcpy_Avx.h │ 496 │ 1 │ 496 │
│ 2020-10-19 01:10:50 │ tests/queries/0_stateless/01518_nullable_aggregate_states2.sql │ 411 │ 1 │ 411 │
│ 2020-11-24 14:53:34 │ programs/server/GRPCHandler.cpp │ 399 │ 1 │ 399 │
│ 2021-03-09 14:10:28 │ src/DataTypes/Serializations/SerializationSparse.cpp │ 363 │ 1 │ 363 │
│ 2021-08-20 15:06:57 │ src/Functions/vectorFunctions.cpp │ 1327 │ 4 │ 331.75 │
│ 2020-08-04 03:26:23 │ src/Interpreters/MySQL/CreateQueryConvertVisitor.cpp │ 311 │ 1 │ 311 │
│ 2020-11-06 15:45:13 │ src/Storages/Rocksdb/StorageEmbeddedRocksdb.cpp │ 611 │ 2 │ 305.5 │
└─────────────────────┴────────────────────────────────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 rows in set. Elapsed: 0.143 sec. Processed 798.15 thousand rows, 18.00 MB (5.58 million rows/s., 125.87 MB/s.)
시간대별 커밋 및 코드 줄 수 분포; 요일별, 작성자별, 특정 하위 디렉터리별
여기서는 이를 요일별로 추가 및 제거된 코드 줄 수로 해석합니다. 이 경우 Functions 디렉터리에 초점을 맞춥니다.
SELECT
dayOfWeek,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toDayOfWeek(time) AS dayOfWeek
┌─dayOfWeek─┬─commits─┬─lines_added─┬─lines_deleted─┐
│ 1 │ 476 │ 24619 │ 15782 │
│ 2 │ 434 │ 18098 │ 9938 │
│ 3 │ 496 │ 26562 │ 20883 │
│ 4 │ 587 │ 65674 │ 18862 │
│ 5 │ 504 │ 85917 │ 14518 │
│ 6 │ 314 │ 13604 │ 10144 │
│ 7 │ 294 │ 11938 │ 6451 │
└───────────┴─────────┴─────────────┴───────────────┘
7 rows in set. Elapsed: 0.034 sec. Processed 266.05 thousand rows, 14.66 MB (7.73 million rows/s., 425.56 MB/s.)
그리고 하루 중 시간대별로,
SELECT
hourOfDay,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toHour(time) AS hourOfDay
┌─hourOfDay─┬─commits─┬─lines_added─┬─lines_deleted─┐
│ 0 │ 71 │ 4169 │ 3404 │
│ 1 │ 90 │ 2174 │ 1927 │
│ 2 │ 65 │ 2343 │ 1515 │
│ 3 │ 76 │ 2552 │ 493 │
│ 4 │ 62 │ 1480 │ 1304 │
│ 5 │ 38 │ 1644 │ 253 │
│ 6 │ 104 │ 4434 │ 2979 │
│ 7 │ 117 │ 4171 │ 1678 │
│ 8 │ 106 │ 4604 │ 4673 │
│ 9 │ 135 │ 60550 │ 2678 │
│ 10 │ 149 │ 6133 │ 3482 │
│ 11 │ 182 │ 8040 │ 3833 │
│ 12 │ 209 │ 29428 │ 15040 │
│ 13 │ 187 │ 10204 │ 5491 │
│ 14 │ 204 │ 9028 │ 6060 │
│ 15 │ 231 │ 15179 │ 10077 │
│ 16 │ 196 │ 9568 │ 5925 │
│ 17 │ 138 │ 4941 │ 3849 │
│ 18 │ 123 │ 4193 │ 3036 │
│ 19 │ 165 │ 8817 │ 6646 │
│ 20 │ 140 │ 3749 │ 2379 │
│ 21 │ 132 │ 41585 │ 4182 │
│ 22 │ 85 │ 4094 │ 3955 │
│ 23 │ 100 │ 3332 │ 1719 │
└───────────┴─────────┴─────────────┴───────────────┘
24 rows in set. Elapsed: 0.039 sec. Processed 266.05 thousand rows, 14.66 MB (6.77 million rows/s., 372.89 MB/s.)
대부분의 개발팀이 암스테르담에 있기 때문에 이러한 분포는 자연스럽습니다. bar 함수는 이러한 분포를 시각화하는 데 도움이 됩니다:
SELECT
hourOfDay,
bar(commits, 0, 400, 50) AS commits,
bar(lines_added, 0, 30000, 50) AS lines_added,
bar(lines_deleted, 0, 15000, 50) AS lines_deleted
FROM
(
SELECT
hourOfDay,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toHour(time) AS hourOfDay
)
┌─hourOfDay─┬─commits───────────────────────┬─lines_added────────────────────────────────────────┬─lines_deleted──────────────────────────────────────┐
│ 0 │ ████████▊ │ ██████▊ │ ███████████▎ │
│ 1 │ ███████████▎ │ ███▌ │ ██████▍ │
│ 2 │ ████████ │ ███▊ │ █████ │
│ 3 │ █████████▌ │ ████▎ │ █▋ │
│ 4 │ ███████▋ │ ██▍ │ ████▎ │
│ 5 │ ████▋ │ ██▋ │ ▋ │
│ 6 │ █████████████ │ ███████▍ │ █████████▊ │
│ 7 │ ██████████████▋ │ ██████▊ │ █████▌ │
│ 8 │ █████████████▎ │ ███████▋ │ ███████████████▌ │
│ 9 │ ████████████████▊ │ ██████████████████████████████████████████████████ │ ████████▊ │
│ 10 │ ██████████████████▋ │ ██████████▏ │ ███████████▌ │
│ 11 │ ██████████████████████▋ │ █████████████▍ │ ████████████▋ │
│ 12 │ ██████████████████████████ │ █████████████████████████████████████████████████ │ ██████████████████████████████████████████████████ │
│ 13 │ ███████████████████████▍ │ █████████████████ │ ██████████████████▎ │
│ 14 │ █████████████████████████▌ │ ███████████████ │ ████████████████████▏ │
│ 15 │ ████████████████████████████▊ │ █████████████████████████▎ │ █████████████████████████████████▌ │
│ 16 │ ████████████████████████▌ │ ███████████████▊ │ ███████████████████▋ │
│ 17 │ █████████████████▎ │ ████████▏ │ ████████████▋ │
│ 18 │ ███████████████▍ │ ██████▊ │ ██████████ │
│ 19 │ ████████████████████▋ │ ██████████████▋ │ ██████████████████████▏ │
│ 20 │ █████████████████▌ │ ██████▏ │ ███████▊ │
│ 21 │ ████████████████▌ │ ██████████████████████████████████████████████████ │ █████████████▊ │
│ 22 │ ██████████▋ │ ██████▋ │ █████████████▏ │
│ 23 │ ████████████▌ │ █████▌ │ █████▋ │
└───────────┴───────────────────────────────┴────────────────────────────────────────────────────┴────────────────────────────────────────────────────┘
24 rows in set. Elapsed: 0.038 sec. Processed 266.05 thousand rows, 14.66 MB (7.09 million rows/s., 390.69 MB/s.)
어떤 작성자가 다른 작성자의 코드를 다시 작성하는 경향이 있는지 보여주는 작성자 매트릭스
sign = -1은 코드 삭제를 의미합니다. 문장 부호와 빈 줄 추가는 제외합니다.
SELECT
prev_author || '(a)' AS add_author,
author || '(d)' AS delete_author,
count() AS c
FROM git.line_changes
WHERE (sign = -1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty')) AND (author != prev_author) AND (prev_author != '')
GROUP BY
prev_author,
author
ORDER BY c DESC
LIMIT 1 BY prev_author
LIMIT 100
┌─prev_author──────────┬─author───────────┬─────c─┐
│ Ivan │ Alexey Milovidov │ 18554 │
│ Alexey Arno │ Alexey Milovidov │ 18475 │
│ Michael Kolupaev │ Alexey Milovidov │ 14135 │
│ Alexey Milovidov │ Nikolai Kochetov │ 13435 │
│ Andrey Mironov │ Alexey Milovidov │ 10418 │
│ proller │ Alexey Milovidov │ 7280 │
│ Nikolai Kochetov │ Alexey Milovidov │ 6806 │
│ alexey-milovidov │ Alexey Milovidov │ 5027 │
│ Vitaliy Lyudvichenko │ Alexey Milovidov │ 4390 │
│ Amos Bird │ Ivan Lezhankin │ 3125 │
│ f1yegor │ Alexey Milovidov │ 3119 │
│ Pavel Kartavyy │ Alexey Milovidov │ 3087 │
│ Alexey Zatelepin │ Alexey Milovidov │ 2978 │
│ alesapin │ Alexey Milovidov │ 2949 │
│ Sergey Fedorov │ Alexey Milovidov │ 2727 │
│ Ivan Lezhankin │ Alexey Milovidov │ 2618 │
│ Vasily Nemkov │ Alexey Milovidov │ 2547 │
│ Alexander Tokmakov │ Alexey Milovidov │ 2493 │
│ Nikita Vasilev │ Maksim Kita │ 2420 │
│ Anton Popov │ Amos Bird │ 2127 │
└──────────────────────┴──────────────────┴───────┘
20 rows in set. Elapsed: 0.098 sec. Processed 7.54 million rows, 42.16 MB (76.67 million rows/s., 428.99 MB/s.)
Sankey 차트(SuperSet)를 사용하면 이를 보기 좋게 시각화할 수 있습니다. 시각적 다양성을 높이기 위해 각 작성자별로 코드를 가장 많이 삭제한 사람 상위 3명을 얻도록 LIMIT BY를 3으로 늘립니다.
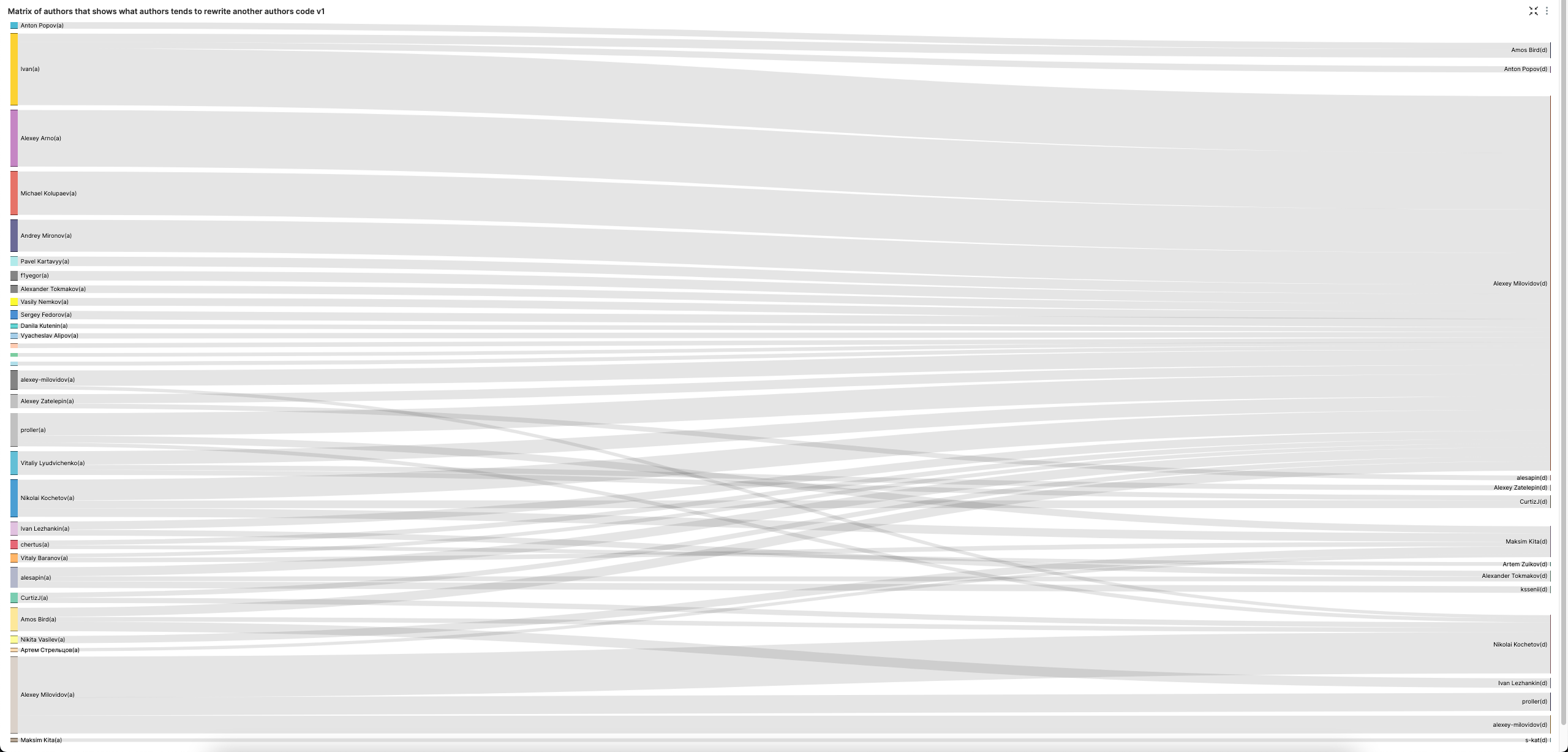
Alexey는 다른 사람들의 코드를 삭제하는 것을 확실히 좋아합니다. 코드 삭제에 대한 보다 균형 잡힌 관점을 위해 그를 제외해 보겠습니다.

요일별로 기여 비율이 가장 높은 기여자는 누구입니까?
커밋 횟수만 기준으로 보면:
SELECT
day_of_week,
author,
count() AS c
FROM git.commits
GROUP BY
dayOfWeek(time) AS day_of_week,
author
ORDER BY
day_of_week ASC,
c DESC
LIMIT 1 BY day_of_week
┌─day_of_week─┬─author───────────┬────c─┐
│ 1 │ Alexey Milovidov │ 2204 │
│ 2 │ Alexey Milovidov │ 1588 │
│ 3 │ Alexey Milovidov │ 1725 │
│ 4 │ Alexey Milovidov │ 1915 │
│ 5 │ Alexey Milovidov │ 1940 │
│ 6 │ Alexey Milovidov │ 1851 │
│ 7 │ Alexey Milovidov │ 2400 │
└─────────────┴──────────────────┴──────┘
7 rows in set. Elapsed: 0.012 sec. Processed 62.78 thousand rows, 395.47 KB (5.44 million rows/s., 34.27 MB/s.)
좋습니다, 여기에서는 가장 오랫동안 기여한 사람인 우리 설립자 Alexey에게 다소 유리한 점이 있을 수 있습니다. 분석 범위를 지난 1년으로 한정해 보겠습니다.
SELECT
day_of_week,
author,
count() AS c
FROM git.commits
WHERE time > (now() - toIntervalYear(1))
GROUP BY
dayOfWeek(time) AS day_of_week,
author
ORDER BY
day_of_week ASC,
c DESC
LIMIT 1 BY day_of_week
┌─day_of_week─┬─author───────────┬───c─┐
│ 1 │ Alexey Milovidov │ 198 │
│ 2 │ alesapin │ 162 │
│ 3 │ alesapin │ 163 │
│ 4 │ Azat Khuzhin │ 166 │
│ 5 │ alesapin │ 191 │
│ 6 │ Alexey Milovidov │ 179 │
│ 7 │ Alexey Milovidov │ 243 │
└─────────────┴──────────────────┴─────┘
7 rows in set. Elapsed: 0.004 sec. Processed 21.82 thousand rows, 140.02 KB (4.88 million rows/s., 31.29 MB/s.)
이 예시는 아직 다소 단순하며 사람들의 실제 작업을 충분히 반영하지 못합니다.
더 나은 지표는 지난 1년 동안 수행된 전체 작업량에서 매일 누가 가장 많은 기여를 했는지를 비율로 보는 것일 수 있습니다. 여기서는 코드 삭제와 추가를 동일하게 취급한다는 점에 유의하십시오.
SELECT
top_author.day_of_week,
top_author.author,
top_author.author_work / all_work.total_work AS top_author_percent
FROM
(
SELECT
day_of_week,
author,
sum(lines_added) + sum(lines_deleted) AS author_work
FROM git.file_changes
WHERE time > (now() - toIntervalYear(1))
GROUP BY
author,
dayOfWeek(time) AS day_of_week
ORDER BY
day_of_week ASC,
author_work DESC
LIMIT 1 BY day_of_week
) AS top_author
INNER JOIN
(
SELECT
day_of_week,
sum(lines_added) + sum(lines_deleted) AS total_work
FROM git.file_changes
WHERE time > (now() - toIntervalYear(1))
GROUP BY dayOfWeek(time) AS day_of_week
) AS all_work USING (day_of_week)
┌─day_of_week─┬─author──────────────┬──top_author_percent─┐
│ 1 │ Alexey Milovidov │ 0.3168282877768332 │
│ 2 │ Mikhail f. Shiryaev │ 0.3523434231193969 │
│ 3 │ vdimir │ 0.11859742484577324 │
│ 4 │ Nikolay Degterinsky │ 0.34577318920318467 │
│ 5 │ Alexey Milovidov │ 0.13208704423684223 │
│ 6 │ Alexey Milovidov │ 0.18895257783624633 │
│ 7 │ Robert Schulze │ 0.3617405888930302 │
└─────────────┴─────────────────────┴─────────────────────┘
7 rows in set. Elapsed: 0.014 sec. Processed 106.12 thousand rows, 1.38 MB (7.61 million rows/s., 98.65 MB/s.)
저장소 전체의 코드 연령 분포
분석은 현재 존재하는 파일로만 제한합니다. 결과를 간단히 보기 위해 루트 폴더당 최대 5개의 파일을 포함하여 깊이 2까지로 결과를 제한합니다. 필요에 따라 조정하십시오.
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
concat(root, '/', sub_folder) AS folder,
round(avg(days_present)) AS avg_age_of_files,
min(days_present) AS min_age_files,
max(days_present) AS max_age_files,
count() AS c
FROM
(
SELECT
path,
dateDiff('day', min(time), toDate('2022-11-03')) AS days_present
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
)
GROUP BY
splitByChar('/', path)[1] AS root,
splitByChar('/', path)[2] AS sub_folder
ORDER BY
root ASC,
c DESC
LIMIT 5 BY root
┌─folder───────────────────────────┬─avg_age_of_files─┬─min_age_files─┬─max_age_files─┬────c─┐
│ base/base │ 387 │ 201 │ 397 │ 84 │
│ base/glibc-compatibility │ 887 │ 59 │ 993 │ 19 │
│ base/consistent-hashing │ 993 │ 993 │ 993 │ 5 │
│ base/widechar_width │ 993 │ 993 │ 993 │ 2 │
│ base/consistent-hashing-sumbur │ 993 │ 993 │ 993 │ 2 │
│ docker/test │ 1043 │ 1043 │ 1043 │ 1 │
│ programs/odbc-bridge │ 835 │ 91 │ 945 │ 25 │
│ programs/copier │ 587 │ 14 │ 945 │ 22 │
│ programs/library-bridge │ 155 │ 47 │ 608 │ 21 │
│ programs/disks │ 144 │ 62 │ 150 │ 14 │
│ programs/server │ 874 │ 709 │ 945 │ 10 │
│ rust/BLAKE3 │ 52 │ 52 │ 52 │ 1 │
│ src/Functions │ 752 │ 0 │ 944 │ 809 │
│ src/Storages │ 700 │ 8 │ 944 │ 736 │
│ src/Interpreters │ 684 │ 3 │ 944 │ 490 │
│ src/Processors │ 703 │ 44 │ 944 │ 482 │
│ src/Common │ 673 │ 7 │ 944 │ 473 │
│ tests/queries │ 674 │ -5 │ 945 │ 3777 │
│ tests/integration │ 656 │ 132 │ 945 │ 4 │
│ utils/memcpy-bench │ 601 │ 599 │ 605 │ 10 │
│ utils/keeper-bench │ 570 │ 569 │ 570 │ 7 │
│ utils/durability-test │ 793 │ 793 │ 793 │ 4 │
│ utils/self-extracting-executable │ 143 │ 143 │ 143 │ 3 │
│ utils/self-extr-exec │ 224 │ 224 │ 224 │ 2 │
└──────────────────────────────────┴──────────────────┴───────────────┴───────────────┴──────┘
24 rows in set. Elapsed: 0.129 sec. Processed 798.15 thousand rows, 15.11 MB (6.19 million rows/s., 117.08 MB/s.)
특정 작성자가 작성한 코드 가운데 다른 작성자에 의해 제거된 비율은 얼마입니까?
이 질문에 답하려면 특정 작성자가 작성한 코드 줄 수를 다른 기여자가 제거한 전체 코드 줄 수로 나누면 됩니다.
SELECT
k,
written_code.c,
removed_code.c,
removed_code.c / written_code.c AS remove_ratio
FROM
(
SELECT
author AS k,
count() AS c
FROM git.line_changes
WHERE (sign = 1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY k
) AS written_code
INNER JOIN
(
SELECT
prev_author AS k,
count() AS c
FROM git.line_changes
WHERE (sign = -1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty')) AND (author != prev_author)
GROUP BY k
) AS removed_code USING (k)
WHERE written_code.c > 1000
ORDER BY remove_ratio DESC
LIMIT 10
┌─k──────────────────┬─────c─┬─removed_code.c─┬───────remove_ratio─┐
│ Marek Vavruša │ 1458 │ 1318 │ 0.9039780521262003 │
│ Ivan │ 32715 │ 27500 │ 0.8405930001528351 │
│ artpaul │ 3450 │ 2840 │ 0.8231884057971014 │
│ Silviu Caragea │ 1542 │ 1209 │ 0.7840466926070039 │
│ Ruslan │ 1027 │ 802 │ 0.7809152872444012 │
│ Tsarkova Anastasia │ 1755 │ 1364 │ 0.7772079772079772 │
│ Vyacheslav Alipov │ 3526 │ 2727 │ 0.7733976176971072 │
│ Marek Vavruša │ 1467 │ 1124 │ 0.7661895023858214 │
│ f1yegor │ 7194 │ 5213 │ 0.7246316374756742 │
│ kreuzerkrieg │ 3406 │ 2468 │ 0.724603640634175 │
└────────────────────┴───────┴────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.126 sec. Processed 15.07 million rows, 73.51 MB (119.97 million rows/s., 585.16 MB/s.)
가장 많이 다시 수정된 파일 나열하기
이 질문에 대한 가장 간단한 방법은 (현재 존재하는 파일로 제한하여) 경로별로 수정된 줄 수를 단순히 집계하는 것입니다. 예를 들면 다음과 같습니다:
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
count() AS c
FROM git.line_changes
WHERE (file_extension IN ('h', 'cpp', 'sql')) AND (path IN (current_files))
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌─path───────────────────────────────────────────────────┬─────c─┐
│ src/Storages/StorageReplicatedMergeTree.cpp │ 21871 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 17709 │
│ programs/client/Client.cpp │ 15882 │
│ src/Storages/MergeTree/MergeTreeDataSelectExecutor.cpp │ 14249 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 12636 │
│ src/Parsers/ExpressionListParsers.cpp │ 11794 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 11760 │
│ src/Coordination/KeeperStorage.cpp │ 10225 │
│ src/Functions/FunctionsConversion.h │ 9247 │
│ src/Parsers/ExpressionElementParsers.cpp │ 8197 │
└────────────────────────────────────────────────────────┴───────┘
10 rows in set. Elapsed: 0.160 sec. Processed 8.07 million rows, 98.99 MB (50.49 million rows/s., 619.49 MB/s.)
그러나 이는 어떤 커밋에서든 파일의 큰 부분이 변경되는 「재작성(rewrite)」 개념을 포착하지는 못합니다. 이를 처리하려면 더 복잡한 쿼리가 필요합니다. 재작성을 파일의 50% 이상이 삭제되고 50% 이상이 추가되는 경우로 간주한다고 하면, 무엇을 재작성으로 볼 것인지에 대한 해석에 따라 쿼리를 조정할 수 있습니다.
쿼리는 현재 존재하는 파일에만 한정됩니다. path 및 commit_hash 로 그룹화하여 모든 파일 변경을 나열하고, 추가된 줄 수와 제거된 줄 수를 반환합니다. 윈도우 함수(window function)를 사용하여 누적 합을 수행하고, 파일 크기에 대한 각 변경의 영향을 lines added - lines removed 로 추정하여, 임의의 시점에서 파일의 전체 크기를 추산합니다. 이 통계를 사용하여 각 변경에 대해 파일에서 추가되거나 제거된 부분이 차지하는 비율을 계산할 수 있습니다. 마지막으로, 파일별로 재작성을 구성하는 파일 변경 횟수, 즉 (percent_add >= 0.5) AND (percent_delete >= 0.5) AND current_size > 50 인 경우를 셉니다. 파일이 50줄을 초과하도록 요구하는 이유는 파일의 초기 기여가 재작성으로 계산되는 것을 방지하기 위해서입니다. 이는 또한 재작성 가능성이 더 높을 수 있는 매우 작은 파일에 대한 편향을 피하는 효과도 있습니다.
WITH
current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
),
changes AS
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(lines_added) AS num_added,
any(lines_deleted) AS num_deleted,
any(change_type) AS type
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
),
rewrites AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM changes
)
SELECT
path,
count() AS num_rewrites
FROM rewrites
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
GROUP BY path
ORDER BY num_rewrites DESC
LIMIT 10
┌─path──────────────────────────────────────────────────┬─num_rewrites─┐
│ src/Storages/WindowView/StorageWindowView.cpp │ 8 │
│ src/Functions/array/arrayIndex.h │ 7 │
│ src/Dictionaries/CacheDictionary.cpp │ 6 │
│ src/Dictionaries/RangeHashedDictionary.cpp │ 5 │
│ programs/client/Client.cpp │ 4 │
│ src/Functions/polygonPerimeter.cpp │ 4 │
│ src/Functions/polygonsEquals.cpp │ 4 │
│ src/Functions/polygonsWithin.cpp │ 4 │
│ src/Processors/Formats/Impl/ArrowColumnToCHColumn.cpp │ 4 │
│ src/Functions/polygonsSymDifference.cpp │ 4 │
└───────────────────────────────────────────────────────┴──────────────┘
10 rows in set. Elapsed: 0.299 sec. Processed 798.15 thousand rows, 31.52 MB (2.67 million rows/s., 105.29 MB/s.)
코드가 저장소에 남아 있을 확률이 가장 높은 요일은 언제입니까?
이를 위해서는 코드 한 줄을 고유하게 식별해야 합니다. 동일한 줄이 파일에 여러 번 나타날 수 있으므로, 경로와 줄 내용을 함께 사용해 이를 추정합니다.
추가된 라인에 대해 쿼리를 실행한 뒤, 이를 제거된 라인과 조인하고, 제거 시점이 추가 시점보다 나중인 경우만 필터링합니다. 이렇게 하면 삭제된 라인을 얻을 수 있고, 이 두 이벤트 사이의 시간을 계산할 수 있습니다.
마지막으로, 이 데이터셋 전체를 집계하여 요일별로 코드 라인이 저장소에 머무는 평균 일수를 계산합니다.
SELECT
day_of_week_added,
count() AS num,
avg(days_present) AS avg_days_present
FROM
(
SELECT
added_code.line,
added_code.time AS added_day,
dateDiff('day', added_code.time, removed_code.time) AS days_present
FROM
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = 1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS added_code
INNER JOIN
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = -1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS removed_code USING (path, line)
WHERE removed_code.time > added_code.time
)
GROUP BY dayOfWeek(added_day) AS day_of_week_added
┌─day_of_week_added─┬────num─┬───avg_days_present─┐
│ 1 │ 171879 │ 193.81759260875384 │
│ 2 │ 141448 │ 153.0931013517335 │
│ 3 │ 161230 │ 137.61553681076722 │
│ 4 │ 255728 │ 121.14149799787273 │
│ 5 │ 203907 │ 141.60181847606998 │
│ 6 │ 62305 │ 202.43449161383518 │
│ 7 │ 70904 │ 220.0266134491707 │
└───────────────────┴────────┴────────────────────┘
7 rows in set. Elapsed: 3.965 sec. Processed 15.07 million rows, 1.92 GB (3.80 million rows/s., 483.50 MB/s.)
평균 코드 연령으로 정렬된 파일
이 쿼리는 파일 경로와 코드 라인의 내용을 사용하여 코드 라인을 고유하게 식별한다는 점에서 어느 요일에 추가된 코드가 저장소에 남아 있을 확률이 가장 높은가와 동일한 원리를 사용합니다. 이를 통해 한 라인이 추가된 시점과 제거된 시점 사이의 시간을 산출할 수 있습니다. 여기서는 현재 존재하는 파일의 코드만을 대상으로 필터링하고, 각 파일에 대해 라인별 시간을 평균합니다.
WITH
current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.clickhouse_file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
),
lines_removed AS
(
SELECT
added_code.path AS path,
added_code.line,
added_code.time AS added_day,
dateDiff('day', added_code.time, removed_code.time) AS days_present
FROM
(
SELECT
path,
line,
max(time) AS time,
any(file_extension) AS file_extension
FROM git.line_changes
WHERE (sign = 1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS added_code
INNER JOIN
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = -1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS removed_code USING (path, line)
WHERE (removed_code.time > added_code.time) AND (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
)
SELECT
path,
avg(days_present) AS avg_code_age
FROM lines_removed
GROUP BY path
ORDER BY avg_code_age DESC
LIMIT 10
┌─path────────────────────────────────────────────────────────────┬──────avg_code_age─┐
│ utils/corrector_utf8/corrector_utf8.cpp │ 1353.888888888889 │
│ tests/queries/0_stateless/01288_shard_max_network_bandwidth.sql │ 881 │
│ src/Functions/replaceRegexpOne.cpp │ 861 │
│ src/Functions/replaceRegexpAll.cpp │ 861 │
│ src/Functions/replaceOne.cpp │ 861 │
│ utils/zookeeper-remove-by-list/main.cpp │ 838.25 │
│ tests/queries/0_stateless/01356_state_resample.sql │ 819 │
│ tests/queries/0_stateless/01293_create_role.sql │ 819 │
│ src/Functions/ReplaceStringImpl.h │ 810 │
│ src/Interpreters/createBlockSelector.cpp │ 795 │
└─────────────────────────────────────────────────────────────────┴───────────────────┘
10 rows in set. Elapsed: 3.134 sec. Processed 16.13 million rows, 1.83 GB (5.15 million rows/s., 582.99 MB/s.)
누가 더 많은 테스트 / CPP 코드 / 주석을 작성하는 경향이 있을까요?
이 질문에는 몇 가지 방식으로 접근할 수 있습니다. 코드 대비 테스트 비율에 집중하면, 이 쿼리는 비교적 단순합니다. tests를 포함하는 폴더에 대한 기여 횟수를 세고, 전체 기여 횟수에 대한 비율을 계산하면 됩니다.
여기서는 정기적으로 커밋하는 사용자에 집중하고 단발성 기여로 인한 편향을 피하기 위해, 변경 사항이 20개를 넘는 사용자로 쿼리를 제한합니다.
SELECT
author,
countIf((file_extension IN ('h', 'cpp', 'sql', 'sh', 'py', 'expect')) AND (path LIKE '%tests%')) AS test,
countIf((file_extension IN ('h', 'cpp', 'sql')) AND (NOT (path LIKE '%tests%'))) AS code,
code / (code + test) AS ratio_code
FROM git.clickhouse_file_changes
GROUP BY author
HAVING code > 20
ORDER BY code DESC
LIMIT 20
┌─author───────────────┬─test─┬──code─┬─────────ratio_code─┐
│ Alexey Milovidov │ 6617 │ 41799 │ 0.8633303040317251 │
│ Nikolai Kochetov │ 916 │ 13361 │ 0.9358408629263851 │
│ alesapin │ 2408 │ 8796 │ 0.785076758300607 │
│ kssenii │ 869 │ 6769 │ 0.8862267609321812 │
│ Maksim Kita │ 799 │ 5862 │ 0.8800480408347096 │
│ Alexander Tokmakov │ 1472 │ 5727 │ 0.7955271565495208 │
│ Vitaly Baranov │ 1764 │ 5521 │ 0.7578586135895676 │
│ Ivan Lezhankin │ 843 │ 4698 │ 0.8478613968597726 │
│ Anton Popov │ 599 │ 4346 │ 0.8788675429726996 │
│ Ivan │ 2630 │ 4269 │ 0.6187853312074214 │
│ Azat Khuzhin │ 1664 │ 3697 │ 0.689610147360567 │
│ Amos Bird │ 400 │ 2901 │ 0.8788245986064829 │
│ proller │ 1207 │ 2377 │ 0.6632254464285714 │
│ chertus │ 453 │ 2359 │ 0.8389046941678521 │
│ alexey-milovidov │ 303 │ 2321 │ 0.8845274390243902 │
│ Alexey Arno │ 169 │ 2310 │ 0.9318273497377975 │
│ Vitaliy Lyudvichenko │ 334 │ 2283 │ 0.8723729461215132 │
│ Robert Schulze │ 182 │ 2196 │ 0.9234650967199327 │
│ CurtizJ │ 460 │ 2158 │ 0.8242933537051184 │
│ Alexander Kuzmenkov │ 298 │ 2092 │ 0.8753138075313808 │
└──────────────────────┴──────┴───────┴────────────────────┘
20 rows in set. Elapsed: 0.034 sec. Processed 266.05 thousand rows, 4.65 MB (7.93 million rows/s., 138.76 MB/s.)
이 분포를 히스토그램으로 그릴 수 있습니다.
WITH (
SELECT histogram(10)(ratio_code) AS hist
FROM
(
SELECT
author,
countIf((file_extension IN ('h', 'cpp', 'sql', 'sh', 'py', 'expect')) AND (path LIKE '%tests%')) AS test,
countIf((file_extension IN ('h', 'cpp', 'sql')) AND (NOT (path LIKE '%tests%'))) AS code,
code / (code + test) AS ratio_code
FROM git.clickhouse_file_changes
GROUP BY author
HAVING code > 20
ORDER BY code DESC
LIMIT 20
)
) AS hist
SELECT
arrayJoin(hist).1 AS lower,
arrayJoin(hist).2 AS upper,
bar(arrayJoin(hist).3, 0, 100, 500) AS bar
┌──────────────lower─┬──────────────upper─┬─bar───────────────────────────┐
│ 0.6187853312074214 │ 0.6410053888179964 │ █████ │
│ 0.6410053888179964 │ 0.6764177968945693 │ █████ │
│ 0.6764177968945693 │ 0.7237343804750673 │ █████ │
│ 0.7237343804750673 │ 0.7740802855073157 │ █████▋ │
│ 0.7740802855073157 │ 0.807297655565091 │ ████████▋ │
│ 0.807297655565091 │ 0.8338381996094653 │ ██████▎ │
│ 0.8338381996094653 │ 0.8533566747727687 │ ████████▋ │
│ 0.8533566747727687 │ 0.871392376017531 │ █████████▍ │
│ 0.871392376017531 │ 0.904916108899021 │ ████████████████████████████▋ │
│ 0.904916108899021 │ 0.9358408629263851 │ █████████████████▌ │
└────────────────────┴────────────────────┴───────────────────────────────┘
10 rows in set. Elapsed: 0.051 sec. Processed 266.05 thousand rows, 4.65 MB (5.24 million rows/s., 91.64 MB/s.)
대부분의 기여자는 예상대로 테스트보다 코드를 더 많이 작성합니다.
코드를 기여할 때 주석을 가장 많이 추가하는 사람은 누구일까요?
SELECT
author,
avg(ratio_comments) AS avg_ratio_comments,
sum(code) AS code
FROM
(
SELECT
author,
commit_hash,
countIf(line_type = 'Comment') AS comments,
countIf(line_type = 'Code') AS code,
if(comments > 0, comments / (comments + code), 0) AS ratio_comments
FROM git.clickhouse_line_changes
GROUP BY
author,
commit_hash
)
GROUP BY author
ORDER BY code DESC
LIMIT 10
┌─author─────────────┬──avg_ratio_comments─┬────code─┐
│ Alexey Milovidov │ 0.1034915408309902 │ 1147196 │
│ s-kat │ 0.1361718900215362 │ 614224 │
│ Nikolai Kochetov │ 0.08722993407690126 │ 218328 │
│ alesapin │ 0.1040477684726504 │ 198082 │
│ Vitaly Baranov │ 0.06446875712939285 │ 161801 │
│ Maksim Kita │ 0.06863376297549255 │ 156381 │
│ Alexey Arno │ 0.11252677608033655 │ 146642 │
│ Vitaliy Zakaznikov │ 0.06199215397180561 │ 138530 │
│ kssenii │ 0.07455322590796751 │ 131143 │
│ Artur │ 0.12383737231074826 │ 121484 │
└────────────────────┴─────────────────────┴─────────┘
10 rows in set. Elapsed: 0.290 sec. Processed 7.54 million rows, 394.57 MB (26.00 million rows/s., 1.36 GB/s.)
코드 기여도를 기준으로 정렬한다는 점에 유의하십시오. 주요 기여자들의 코드 비율이 예상외로 높으며, 이는 우리 코드의 가독성이 높은 이유 중 하나입니다.
작성자의 커밋에서 코드/주석 비율은 시간 경과에 따라 어떻게 변합니까?
작성자 기준으로 이를 계산하는 것은 간단합니다.
SELECT
author,
countIf(line_type = 'Code') AS code_lines,
countIf((line_type = 'Comment') OR (line_type = 'Punct')) AS comments,
code_lines / (comments + code_lines) AS ratio_code,
toStartOfWeek(time) AS week
FROM git.line_changes
GROUP BY
time,
author
ORDER BY
author ASC,
time ASC
LIMIT 10
┌─author──────────────────────┬─code_lines─┬─comments─┬─────────ratio_code─┬───────week─┐
│ 1lann │ 8 │ 0 │ 1 │ 2022-03-06 │
│ 20018712 │ 2 │ 0 │ 1 │ 2020-09-13 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 2 │ 0 │ 2020-12-06 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 112 │ 0 │ 2020-12-06 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 14 │ 0 │ 2020-12-06 │
│ 3ldar-nasyrov │ 2 │ 0 │ 1 │ 2021-03-14 │
│ 821008736@qq.com │ 27 │ 2 │ 0.9310344827586207 │ 2019-04-21 │
│ ANDREI STAROVEROV │ 182 │ 60 │ 0.7520661157024794 │ 2021-05-09 │
│ ANDREI STAROVEROV │ 7 │ 0 │ 1 │ 2021-05-09 │
│ ANDREI STAROVEROV │ 32 │ 12 │ 0.7272727272727273 │ 2021-05-09 │
└─────────────────────────────┴────────────┴──────────┴────────────────────┴────────────┘
10 rows in set. Elapsed: 0.145 sec. Processed 7.54 million rows, 51.09 MB (51.83 million rows/s., 351.44 MB/s.)
그러나 이상적으로는, 각 작성자가 커밋을 시작한 첫날부터 모든 작성자를 합쳐 보았을 때, 시간이 지나며 이 값이 어떻게 변하는지 확인하고자 합니다. 시간이 지남에 따라 작성자가 작성하는 주석의 수를 서서히 줄이는지 보고 싶습니다.
이를 계산하기 위해 먼저 Who tends to write more tests / CPP code / comments?와 유사하게, 시간에 따른 각 작성자의 주석 비율(comments ratio)을 계산합니다. 그런 다음 이 값을 각 작성자의 시작 날짜와 조인하여, 시작 시점으로부터의 주(week) 단위 오프셋별 주석 비율을 계산합니다.
모든 작성자에 대해 주 단위 오프셋별 평균을 계산한 후, 이 결과에서 매 10번째 주를 선택하여 샘플링합니다.
WITH author_ratios_by_offset AS
(
SELECT
author,
dateDiff('week', start_dates.start_date, contributions.week) AS week_offset,
ratio_code
FROM
(
SELECT
author,
toStartOfWeek(min(time)) AS start_date
FROM git.line_changes
WHERE file_extension IN ('h', 'cpp', 'sql')
GROUP BY author AS start_dates
) AS start_dates
INNER JOIN
(
SELECT
author,
countIf(line_type = 'Code') AS code,
countIf((line_type = 'Comment') OR (line_type = 'Punct')) AS comments,
comments / (comments + code) AS ratio_code,
toStartOfWeek(time) AS week
FROM git.line_changes
WHERE (file_extension IN ('h', 'cpp', 'sql')) AND (sign = 1)
GROUP BY
time,
author
HAVING code > 20
ORDER BY
author ASC,
time ASC
) AS contributions USING (author)
)
SELECT
week_offset,
avg(ratio_code) AS avg_code_ratio
FROM author_ratios_by_offset
GROUP BY week_offset
HAVING (week_offset % 10) = 0
ORDER BY week_offset ASC
LIMIT 20
┌─week_offset─┬──────avg_code_ratio─┐
│ 0 │ 0.21626798253005078 │
│ 10 │ 0.18299433892099454 │
│ 20 │ 0.22847255749045017 │
│ 30 │ 0.2037816688365288 │
│ 40 │ 0.1987063517030308 │
│ 50 │ 0.17341406302829748 │
│ 60 │ 0.1808884776496144 │
│ 70 │ 0.18711773536450496 │
│ 80 │ 0.18905573684766458 │
│ 90 │ 0.2505147771581594 │
│ 100 │ 0.2427673990917429 │
│ 110 │ 0.19088569009169926 │
│ 120 │ 0.14218574654598348 │
│ 130 │ 0.20894252550489317 │
│ 140 │ 0.22316626978848397 │
│ 150 │ 0.1859507592277053 │
│ 160 │ 0.22007759757363546 │
│ 170 │ 0.20406936638195144 │
│ 180 │ 0.1412102467834332 │
│ 190 │ 0.20677550885049117 │
└─────────────┴─────────────────────┘
20 rows in set. Elapsed: 0.167 sec. Processed 15.07 million rows, 101.74 MB (90.51 million rows/s., 610.98 MB/s.)
고무적인 점은 comment %가 거의 일정하게 유지되며, 작성자들의 기여 기간이 길어져도 감소하지 않는다는 것입니다.
코드가 다시 작성되기까지의 평균 시간과 중앙값(코드 붕괴의 반감기)은 얼마입니까?
가장 많이 다시 작성되었거나 가장 많은 작성자가 수정한 파일 목록과 동일한 원리를 사용하여, 모든 파일을 대상으로 재작성을 식별합니다. 윈도 함수(window function)를 사용하여 각 파일에 대해 재작성 간 경과 시간을 계산합니다. 이를 기반으로 모든 파일에 대한 평균과 중앙값을 계산할 수 있습니다.
WITH
changes AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(lines_added) AS num_added,
any(lines_deleted) AS num_deleted,
any(change_type) AS type
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT
*,
any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite,
dateDiff('day', previous_rewrite, max_time) AS rewrite_days
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
avgIf(rewrite_days, rewrite_days > 0) AS avg_rewrite_time,
quantilesTimingIf(0.5)(rewrite_days, rewrite_days > 0) AS half_life
FROM rewrites
┌─avg_rewrite_time─┬─half_life─┐
│ 122.2890625 │ [23] │
└──────────────────┴───────────┘
1 row in set. Elapsed: 0.388 sec. Processed 266.05 thousand rows, 22.85 MB (685.82 thousand rows/s., 58.89 MB/s.)
코드가 나중에 다시 작성될 가능성이 가장 높은, 즉 코드를 작성하기에 가장 좋지 않은 시간은 언제입니까?
코드가 다시 작성되기까지의 평균 시간과 중앙값(코드 부식의 반감기)은 얼마입니까? 및 가장 많이 다시 작성되었거나 가장 많은 작성자에 의해 수정된 파일 목록과 유사하지만, 여기서는 요일별로 집계합니다. 필요에 따라, 예를 들어 연중 월별 등으로 조정하여 사용할 수 있습니다.
WITH
changes AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(file_lines_added) AS num_added,
any(file_lines_deleted) AS num_deleted,
any(file_change_type) AS type
FROM git.line_changes
WHERE (file_change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
dayOfWeek(previous_rewrite) AS dayOfWeek,
count() AS num_re_writes
FROM rewrites
GROUP BY dayOfWeek
┌─dayOfWeek─┬─num_re_writes─┐
│ 1 │ 111 │
│ 2 │ 121 │
│ 3 │ 91 │
│ 4 │ 111 │
│ 5 │ 90 │
│ 6 │ 64 │
│ 7 │ 46 │
└───────────┴───────────────┘
7 rows in set. Elapsed: 0.466 sec. Processed 7.54 million rows, 701.52 MB (16.15 million rows/s., 1.50 GB/s.)
어떤 작성자의 코드가 가장 오래 유지되나요?
여기서 「끈끈하다(sticky)」는 한 작성자의 코드가 다른 코드로 재작성되기까지 얼마나 오래 유지되는지를 의미합니다. 이전 질문인 코드가 다시 작성되기까지의 평균 시간과 중앙값(코드 부패의 반감기)은 얼마인가요?과 마찬가지로, 재작성 기준은 파일에 대해 추가(additions) 50%, 삭제(deletions) 50%가 발생하는 것으로 정의합니다. 작성자별 평균 재작성 시간을 계산하며, 2개를 초과하는 파일을 가진 기여자만 대상으로 합니다.
WITH
changes AS
(
SELECT
path,
author,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
any(author) AS author,
max(time) AS max_time,
commit_hash,
any(file_lines_added) AS num_added,
any(file_lines_deleted) AS num_deleted,
any(file_change_type) AS type
FROM git.line_changes
WHERE (file_change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT
*,
any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite,
dateDiff('day', previous_rewrite, max_time) AS rewrite_days,
any(author) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS prev_author
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
prev_author,
avg(rewrite_days) AS c,
uniq(path) AS num_files
FROM rewrites
GROUP BY prev_author
HAVING num_files > 2
ORDER BY c DESC
LIMIT 10
┌─prev_author─────────┬──────────────────c─┬─num_files─┐
│ Michael Kolupaev │ 304.6 │ 4 │
│ alexey-milovidov │ 81.83333333333333 │ 4 │
│ Alexander Kuzmenkov │ 64.5 │ 5 │
│ Pavel Kruglov │ 55.8 │ 6 │
│ Alexey Milovidov │ 48.416666666666664 │ 90 │
│ Amos Bird │ 42.8 │ 4 │
│ alesapin │ 38.083333333333336 │ 12 │
│ Nikolai Kochetov │ 33.18421052631579 │ 26 │
│ Alexander Tokmakov │ 31.866666666666667 │ 12 │
│ Alexey Zatelepin │ 22.5 │ 4 │
└─────────────────────┴────────────────────┴───────────┘
10 rows in set. Elapsed: 0.555 sec. Processed 7.54 million rows, 720.60 MB (13.58 million rows/s., 1.30 GB/s.)
특정 작성자가 가장 많이 연속으로 커밋한 일수
이 쿼리는 먼저 작성자가 커밋한 날짜를 구해야 합니다. 윈도우 함수(window function)를 사용해 작성자별로 파티션을 나누면, 각 커밋 간의 날짜 차이를 계산할 수 있습니다. 각 커밋에 대해 마지막 커밋 이후 경과 시간이 1일이면 연속(1)으로, 그렇지 않으면 0으로 표시하고 이 값을 consecutive_day에 저장합니다.
이후 배열 함수를 사용하여 각 작성자의 가장 긴 연속된 1 구간을 계산합니다. 먼저 groupArray 함수를 사용해 작성자별 모든 consecutive_day 값을 모읍니다. 이렇게 얻은 1과 0으로 이루어진 배열을 0 값을 기준으로 나누어 부분 배열들로 분리합니다. 마지막으로, 가장 긴 부분 배열의 길이를 계산합니다.
WITH commit_days AS
(
SELECT
author,
day,
any(day) OVER (PARTITION BY author ORDER BY day ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_commit,
dateDiff('day', previous_commit, day) AS days_since_last,
if(days_since_last = 1, 1, 0) AS consecutive_day
FROM
(
SELECT
author,
toStartOfDay(time) AS day
FROM git.commits
GROUP BY
author,
day
ORDER BY
author ASC,
day ASC
)
)
SELECT
author,
arrayMax(arrayMap(x -> length(x), arraySplit(x -> (x = 0), groupArray(consecutive_day)))) - 1 AS max_consecutive_days
FROM commit_days
GROUP BY author
ORDER BY max_consecutive_days DESC
LIMIT 10
┌─author───────────┬─max_consecutive_days─┐
│ kssenii │ 32 │
│ Alexey Milovidov │ 30 │
│ alesapin │ 26 │
│ Azat Khuzhin │ 23 │
│ Nikolai Kochetov │ 15 │
│ feng lv │ 11 │
│ alexey-milovidov │ 11 │
│ Igor Nikonov │ 11 │
│ Maksim Kita │ 11 │
│ Nikita Vasilev │ 11 │
└──────────────────┴──────────────────────┘
10 rows in set. Elapsed: 0.025 sec. Processed 62.78 thousand rows, 395.47 KB (2.54 million rows/s., 16.02 MB/s.)
파일의 줄별 커밋 이력
파일은 이름이 변경될 수 있습니다. 이 경우 rename 이벤트가 발생하며, path 컬럼에는 파일의 새 경로가 설정되고 old_path는 이전 경로를 나타냅니다. 예:
SELECT
time,
path,
old_path,
commit_hash,
commit_message
FROM git.file_changes
WHERE (path = 'src/Storages/StorageReplicatedMergeTree.cpp') AND (change_type = 'Rename')
┌────────────────time─┬─path────────────────────────────────────────┬─old_path─────────────────────────────────────┬─commit_hash──────────────────────────────┬─commit_message─┐
│ 2020-04-03 16:14:31 │ src/Storages/StorageReplicatedMergeTree.cpp │ dbms/Storages/StorageReplicatedMergeTree.cpp │ 06446b4f08a142d6f1bc30664c47ded88ab51782 │ dbms/ → src/ │
└─────────────────────┴─────────────────────────────────────────────┴──────────────────────────────────────────────┴──────────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 0.135 sec. Processed 266.05 thousand rows, 20.73 MB (1.98 million rows/s., 154.04 MB/s.)
이 때문에 모든 라인 또는 파일 변경을 연결하는 단일 값이 없기 때문에, 파일의 전체 이력을 조회하기가 어렵습니다.
이를 해결하기 위해 User Defined Functions(UDFs)를 사용할 수 있습니다. 현재 UDF는 재귀적으로 사용할 수 없으므로, 파일의 이력을 식별하려면 서로를 명시적으로 호출하는 일련의 UDF를 정의해야 합니다.
이는 이름 변경 내역을 최대 깊이까지만 추적할 수 있음을 의미하며, 아래 예시는 5단계까지 추적합니다. 파일이 이보다 더 많이 이름이 변경되는 경우는 드물기 때문에, 현재로서는 이것으로 충분합니다.
CREATE FUNCTION file_path_history AS (n) -> if(empty(n), [], arrayConcat([n], file_path_history_01((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_01 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_02((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_02 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_03((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_03 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_04((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_04 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_05((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_05 AS (n) -> if(isNull(n), [], [n]);
file_path_history('src/Storages/StorageReplicatedMergeTree.cpp')를 호출하면 이름 변경 이력을 재귀적으로 따라가게 되며, 각 단계에서 함수가 old_path를 인자로 다음 단계를 호출합니다. 이렇게 얻은 결과는 arrayConcat으로 하나로 합쳐집니다.
예를 들어,
SELECT file_path_history('src/Storages/StorageReplicatedMergeTree.cpp') AS paths
┌─paths─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ ['src/Storages/StorageReplicatedMergeTree.cpp','dbms/Storages/StorageReplicatedMergeTree.cpp','dbms/src/Storages/StorageReplicatedMergeTree.cpp'] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.074 sec. Processed 344.06 thousand rows, 6.27 MB (4.65 million rows/s., 84.71 MB/s.)
이제 이 기능을 사용하여 파일의 전체 변경 이력에 대한 커밋을 구성할 수 있습니다. 이 예시에서는 각 path 값마다 하나의 커밋을 보여 줍니다.
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
change_type,
author,
path,
commit_message
FROM git.file_changes
WHERE path IN file_path_history('src/Storages/StorageReplicatedMergeTree.cpp')
ORDER BY time DESC
LIMIT 1 BY path
FORMAT PrettyCompactMonoBlock
┌────────────────time─┬─commit──────┬─change_type─┬─author─────────────┬─path─────────────────────────────────────────────┬─commit_message──────────────────────────────────────────────────────────────────┐
│ 2022-10-30 16:30:51 │ c68ab231f91 │ Modify │ Alexander Tokmakov │ src/Storages/StorageReplicatedMergeTree.cpp │ fix accessing part in Deleting state │
│ 2020-04-03 15:21:24 │ 38a50f44d34 │ Modify │ alesapin │ dbms/Storages/StorageReplicatedMergeTree.cpp │ Remove empty line │
│ 2020-04-01 19:21:27 │ 1d5a77c1132 │ Modify │ alesapin │ dbms/src/Storages/StorageReplicatedMergeTree.cpp │ Tried to add ability to rename primary key columns but just banned this ability │
└─────────────────────┴─────────────┴─────────────┴────────────────────┴──────────────────────────────────────────────────┴─────────────────────────────────────────────────────────────────────────────────┘
3 rows in set. Elapsed: 0.170 sec. Processed 611.53 thousand rows, 41.76 MB (3.60 million rows/s., 246.07 MB/s.)
미해결 문제
Git blame
현재 배열 함수에서 상태를 유지할 수 없기 때문에 정확한 결과를 얻기가 특히 어렵습니다. 각 반복에서 상태를 유지하도록 해 주는 arrayFold 또는 arrayReduce를 사용하면 가능해집니다.
고수준 분석에 충분한 근사 해법은 다음과 같은 형태가 될 수 있습니다:
SELECT
line_number_new,
argMax(author, time),
argMax(line, time)
FROM git.line_changes
WHERE path IN file_path_history('src/Storages/StorageReplicatedMergeTree.cpp')
GROUP BY line_number_new
ORDER BY line_number_new ASC
LIMIT 20
┌─line_number_new─┬─argMax(author, time)─┬─argMax(line, time)────────────────────────────────────────────┐
│ 1 │ Alexey Milovidov │ #include <Disks/DiskSpaceMonitor.h> │
│ 2 │ s-kat │ #include <Common/FieldVisitors.h> │
│ 3 │ Anton Popov │ #include <cstddef> │
│ 4 │ Alexander Burmak │ #include <Common/typeid_cast.h> │
│ 5 │ avogar │ #include <Common/ThreadPool.h> │
│ 6 │ Alexander Burmak │ #include <Common/DiskSpaceMonitor.h> │
│ 7 │ Alexander Burmak │ #include <Common/ZooKeeper/Types.h> │
│ 8 │ Alexander Burmak │ #include <Common/escapeForFileName.h> │
│ 9 │ Alexander Burmak │ #include <Common/formatReadable.h> │
│ 10 │ Alexander Burmak │ #include <Common/thread_local_rng.h> │
│ 11 │ Alexander Burmak │ #include <Common/typeid_cast.h> │
│ 12 │ Nikolai Kochetov │ #include <Storages/MergeTree/DataPartStorageOnDisk.h> │
│ 13 │ alesapin │ #include <Disks/ObjectStorages/IMetadataStorage.h> │
│ 14 │ alesapin │ │
│ 15 │ Alexey Milovidov │ #include <DB/Databases/IDatabase.h> │
│ 16 │ Alexey Zatelepin │ #include <Storages/MergeTree/ReplicatedMergeTreePartheckout er.h> │
│ 17 │ CurtizJ │ #include <Storages/MergeTree/MergeTreeDataPart.h> │
│ 18 │ Kirill Shvakov │ #include <Parsers/ASTDropQuery.h> │
│ 19 │ s-kat │ #include <Storages/MergeTree/PinnedPartUUIDs.h> │
│ 20 │ Nikita Mikhaylov │ #include <Storages/MergeTree/MergeMutateExecutor.h> │
└─────────────────┴──────────────────────┴───────────────────────────────────────────────────────────────┘
20 rows in set. Elapsed: 0.547 sec. Processed 7.88 million rows, 679.20 MB (14.42 million rows/s., 1.24 GB/s.)
여기에서는 정확한 해결 방법은 물론, 더 나은 개선안도 환영합니다.
