ClickHouse의 azureBlobStorage 테이블 함수 사용
이 방법은 Azure Blob Storage 또는 Azure Data Lake Storage에서 ClickHouse로 데이터를 복사하는 가장 효율적이고 직관적인 방법 중 하나입니다. 이 테이블 함수를 사용하면 ClickHouse가 Azure 스토리지에 직접 연결하여 필요할 때 데이터를 읽도록 설정할 수 있습니다.
이 함수는 테이블과 유사한 인터페이스를 제공하여 소스에서 직접 데이터를 선택하고, 삽입하고, 필터링할 수 있습니다. 이 함수는 고도로 최적화되어 있으며 CSV, JSON, Parquet, Arrow, TSV, ORC, Avro 등을 포함한 널리 사용되는 많은 파일 형식을 지원합니다. 전체 목록은 "Data formats"을(를) 참조하십시오.
이 섹션에서는 Azure Blob Storage에서 ClickHouse로 데이터를 전송하기 위한 간단한 시작 가이드를 살펴보고, 이 함수를 효과적으로 사용하기 위한 중요한 고려 사항을 설명합니다. 자세한 내용과 고급 옵션은 공식 문서를 참조하십시오:
azureBlobStorage Table Function documentation page
Azure Blob Storage 액세스 키 가져오기
ClickHouse에서 Azure Blob Storage에 액세스하려면 액세스 키가 포함된 연결 문자열이 필요합니다.
-
Azure 포털에서 Storage Account로 이동합니다.
-
왼쪽 메뉴에서 Security + networking 섹션의 Access keys를 선택합니다.
-
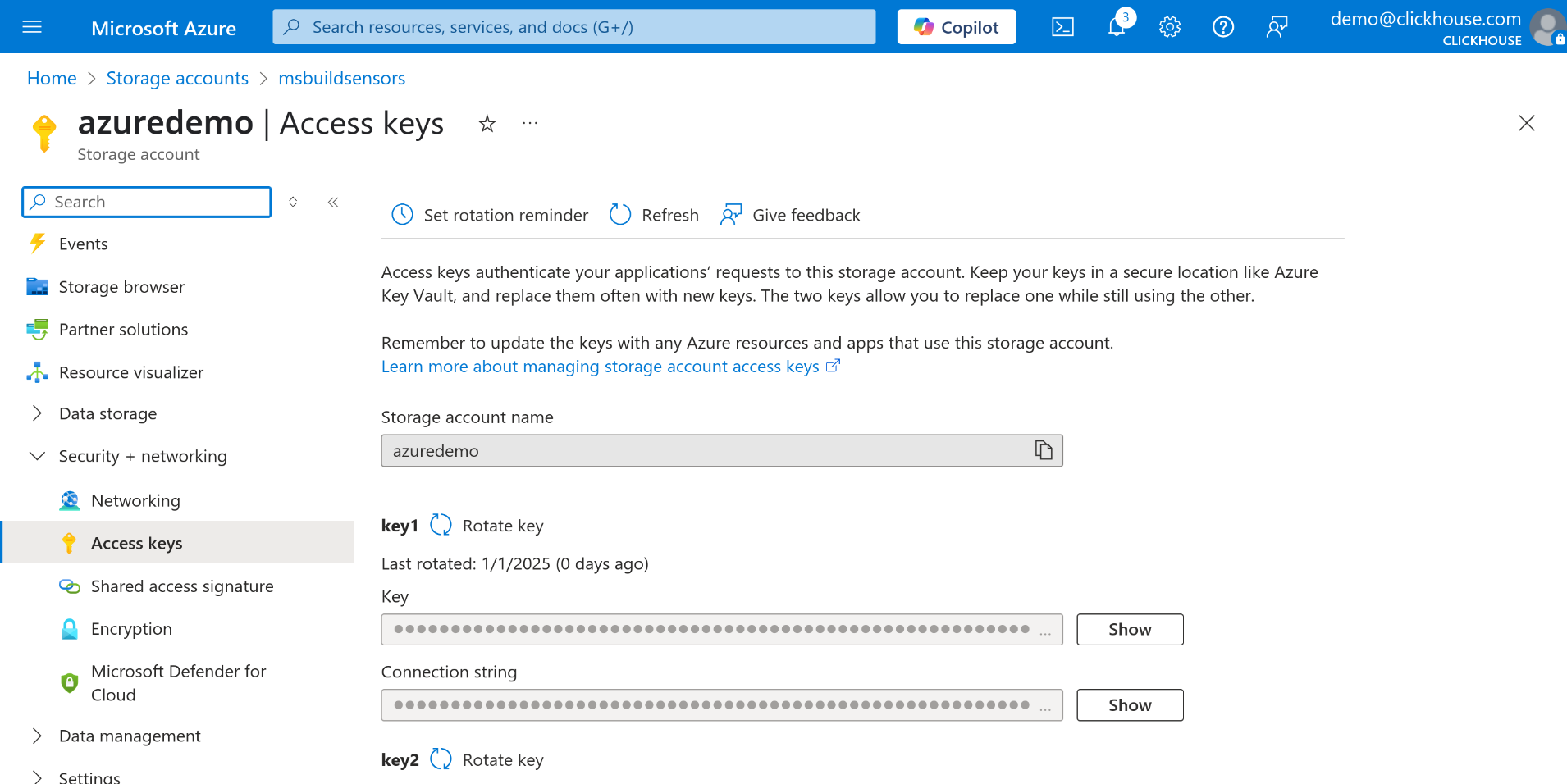
key1 또는 key2 중 하나를 선택한 후 Connection string 필드 옆의 Show 버튼을 클릭합니다.
-
연결 문자열을 복사합니다. 이 문자열은 azureBlobStorage table function의 매개변수로 사용합니다.
Azure Blob Storage에서 데이터 쿼리하기
선호하는 ClickHouse 쿼리 콘솔을 엽니다. ClickHouse Cloud 웹 인터페이스, ClickHouse CLI 클라이언트 또는 평소에 쿼리를 실행할 때 사용하는 다른 도구를 사용할 수 있습니다. 연결 문자열과 ClickHouse 쿼리 콘솔 준비가 완료되면 Azure Blob Storage에서 직접 데이터를 쿼리할 수 있습니다.
다음 예시에서는 data-container라는 이름의 컨테이너에 있는 JSON 파일에 저장된 모든 데이터를 쿼리합니다:
해당 데이터를 로컬 ClickHouse 테이블(예: my_table)에 복사하려면
INSERT INTO ... SELECT 구문을 사용할 수 있습니다:
이 기능을 사용하면 중간 ETL 단계를 수행할 필요 없이 외부 데이터를 ClickHouse로 효율적으로 가져올 수 있습니다.
Environmental Sensors 데이터셋을 사용하는 간단한 예제
예를 들어 Environmental Sensors 데이터셋에서 하나의 파일을 다운로드해 보겠습니다.
-
Environmental Sensors Dataset에서 샘플 파일을 다운로드합니다.
-
Azure Portal에서 아직 스토리지 계정이 없다면 새 스토리지 계정을 만듭니다.
스토리지 계정에서 Allow storage account key access가 활성화되어 있는지 반드시 확인하십시오. 그렇지 않으면 계정 키를 사용하여 데이터에 액세스할 수 없습니다.
-
스토리지 계정에 새 컨테이너를 생성합니다. 이 예제에서는 이름을 sensors로 지정합니다. 기존 컨테이너를 사용하는 경우 이 단계는 건너뛸 수 있습니다.
-
앞에서 다운로드한
2019-06_bmp180.csv.zst파일을 컨테이너에 업로드합니다. -
앞에서 설명한 단계를 따라 Azure Blob Storage 연결 문자열을 가져옵니다.
이제 모든 설정이 완료되었으므로 Azure Blob Storage에서 데이터를 직접 쿼리할 수 있습니다.
- 테이블에 데이터를 적재하려면, 원본 데이터셋에서 사용된
스키마를 단순화한 버전을 생성합니다:
Azure Blob Storage와 같은 외부 소스를 쿼리할 때의 설정 옵션 및 스키마 추론에 대한 자세한 내용은 입력 데이터로부터 자동 스키마 추론(Automatic schema inference from input data)을 참고하십시오.
- 이제 Azure Blob Storage에서 sensors 테이블로 데이터를 삽입합니다:
이제 Azure Blob Storage에 저장된 2019-06_bmp180.csv.zst 파일의 데이터가
sensors 테이블에 채워졌습니다.
추가 리소스
이 문서는 azureBlobStorage 테이블 함수(table function)를 사용하는 방법에 대한 기초적인 소개입니다.
더 고급 옵션과 구성에 대한 자세한 내용은 공식 문서를 참조하십시오:
