Amazon S3를 ClickHouse Cloud와 연동하기
S3 ClickPipe는 Amazon S3 및 S3 호환 오브젝트 스토리지에서 ClickHouse Cloud로 데이터를 수집하기 위한 완전 관리형이고 내결함성이 뛰어난 방식을 제공합니다. 단발성(one-time) 및 지속적 수집(continuous ingestion) 을 모두 지원하며, 정확히 한 번만 처리하는(exactly-once) 시맨틱을 보장합니다.
S3 ClickPipes는 ClickPipes UI를 사용하여 수동으로 배포 및 관리할 수 있고, OpenAPI 및 Terraform을 사용하여 프로그래밍 방식으로도 관리할 수 있습니다.
지원되는 데이터 소스
| Name | Logo | Details |
|---|---|---|
| Amazon S3 | 연속 수집은 기본적으로 사전식 순서가 필요하지만, 임의 순서로 파일을 수집하도록 구성할 수 있습니다. | |
| Cloudflare R2 S3-compatible | 연속 수집에는 사전식 순서가 필요합니다. 비정렬 모드는 지원되지 않습니다. | |
| DigitalOcean Spaces S3-compatible | 연속 수집에는 사전식 순서가 필요합니다. 비정렬 모드는 지원되지 않습니다. | |
| OVH Object Storage S3-compatible |  | 연속 수집에는 사전식 순서가 필요합니다. 비정렬 모드는 지원되지 않습니다. |
객체 스토리지 서비스 제공자마다 URL 형식과 API 구현이 서로 다르므로, 모든 S3 호환 서비스가 기본적으로 지원되는 것은 아닙니다. 사용 중인 서비스가 위 목록에 없고 문제가 발생하는 경우 당사 팀에 문의하십시오.
지원되는 형식
기능
일회성 수집
기본적으로 S3 ClickPipe는 지정된 버킷에서 지정한 패턴과 일치하는 모든 파일을 단일 일괄(batch) 작업으로 ClickHouse 대상 테이블에 로드합니다. 수집 작업이 완료되면 ClickPipe는 자동으로 중지됩니다. 이러한 일회성 수집 모드는 정확히 한 번 처리(exactly-once) 의미론을 제공하여 각 파일이 중복 없이 신뢰성 있게 처리되도록 보장합니다.
지속적인 수집
지속적인 수집이 활성화되면 ClickPipes는 지정된 경로로부터 데이터를 연속적으로 수집합니다. 수집 순서를 결정하기 위해 S3 ClickPipe는 기본적으로 파일의 암묵적인 사전식(lexicographical) 순서에 의존합니다. 또한 Amazon SQS 큐를 버킷에 연결하여 파일을 임의의 순서로 수집하도록 구성할 수도 있습니다.
Lexicographical order
기본적으로 S3 ClickPipe는 파일이 버킷에 사전식(lexicographical) 순서로 추가된다고 가정하며, 이 묵시적 순서에 의존해 파일을 순차적으로 수집합니다. 이는 새 파일이 마지막으로 수집된 파일보다 사전식으로 더 커야 함을 의미합니다. 예를 들어 file1, file2, file3라는 이름의 파일은 순차적으로 수집되지만, 새로운 file 0이 버킷에 추가되면 해당 파일 이름이 마지막으로 수집된 파일보다 사전식으로 크지 않기 때문에 무시됩니다.
이 모드에서 S3 ClickPipe는 지정된 경로에 있는 모든 파일을 초기 로드한 다음, 설정 가능한 간격(기본값 30초)으로 새 파일이 있는지 주기적으로 확인합니다. 특정 파일이나 특정 시점부터 수집을 시작하는 것은 불가능하며, ClickPipes는 항상 지정된 경로의 모든 파일을 로드합니다.
순서 무관
Unordered 모드는 Amazon S3에서만 지원되며, 공개 버킷(public bucket)에서는 지원되지 않습니다. 이 모드를 사용하려면 버킷에 연결된 Amazon SQS 큐를 설정해야 합니다.
S3 ClickPipe를 사용해 암시적인 순서가 없는 파일도 수집하도록 구성할 수 있습니다. 이를 위해 버킷에 연결된 Amazon SQS 큐를 설정하면 됩니다. 이렇게 하면 ClickPipes가 객체 생성 이벤트를 수신하고, 파일 이름 규칙과 관계없이 새 파일을 수집할 수 있습니다.
이 모드에서는 S3 ClickPipe가 먼저 선택한 경로의 모든 파일을 초기 로드한 후, 지정된 경로와 일치하는 ObjectCreated:* 이벤트를 큐에서 계속 수신합니다. 이전에 처리한 파일에 대한 메시지, 경로와 일치하지 않는 파일, 또는 다른 유형의 이벤트는 무시됩니다.
이벤트에 prefix/postfix를 설정하는 것은 선택 사항입니다. 설정하는 경우, ClickPipe에 설정한 경로와 일치하는지 반드시 확인해야 합니다. S3에서는 동일한 이벤트 유형에 대해 서로 겹치는 여러 알림 규칙을 허용하지 않습니다.
파일은 max insert bytes 또는 max file count에 설정된 임계값에 도달하거나, 구성 가능한 간격(기본값 30초)이 지나면 수집됩니다. 특정 파일이나 특정 시점에서 수집을 시작하는 것은 불가능하며, ClickPipes는 항상 선택한 경로의 모든 파일을 로드합니다. DLQ가 구성된 경우, 실패한 메시지는 DLQ의 maxReceiveCount 매개변수에 설정된 횟수만큼 다시 큐에 넣어지고 재처리됩니다.
SQS 큐에 대해 **Dead-Letter-Queue (DLQ)**를 구성할 것을 강력히 권장합니다. 이렇게 하면 실패한 메시지를 디버깅하고 재시도하기가 더 쉬워집니다.
SNS to SQS
SNS 토픽을 통해 S3 이벤트 알림을 SQS로 전송하도록 설정할 수도 있습니다. 이 방식은 직접적인 S3 → SQS 통합에 몇 가지 제약 사항이 있을 때 사용할 수 있습니다. 이 경우 raw message delivery 옵션을 활성화해야 합니다.
파일 패턴 매칭
객체 스토리지 ClickPipes는 파일 패턴 매칭에 POSIX 표준을 따릅니다. 모든 패턴은 대소문자를 구분하며, 버킷 이름 이후의 전체 경로와 일치합니다. 성능을 향상하려면 가능한 한 가장 구체적인 패턴을 사용하십시오(예: *.csv 대신 data-2024-*.csv).
지원되는 패턴
| Pattern | Description | Example | Matches |
|---|---|---|---|
? | /를 제외한 정확히 한 문자를 매칭합니다 | data-?.csv | data-1.csv, data-a.csv, data-x.csv |
* | /를 제외한 0개 이상의 문자를 매칭합니다 | data-*.csv | data-1.csv, data-001.csv, data-report.csv, data-.csv |
** Recursive | /를 포함한 0개 이상의 문자를 매칭합니다. 재귀적인 디렉터리 탐색을 활성화합니다. | logs/**/error.log | logs/error.log, logs/2024/error.log, logs/2024/01/error.log |
예시:
https://bucket.s3.amazonaws.com/folder/*.csvhttps://bucket.s3.amazonaws.com/logs/**/data.jsonhttps://bucket.s3.amazonaws.com/file-?.parquethttps://bucket.s3.amazonaws.com/data-2024-*.csv.gz
지원되지 않는 패턴
| 패턴 | 설명 | 예시 | 대체 방법 |
|---|---|---|---|
{abc,def} | 중괄호 확장(Brace expansion) | {logs,data}/file.csv | 각 경로마다 별도의 ClickPipes를 생성하십시오. |
{N..M} | 숫자 범위 확장(Numeric range expansion) | file-{1..100}.csv | file-*.csv 또는 file-?.csv를 사용하십시오. |
예시:
https://bucket.s3.amazonaws.com/{documents-01,documents-02}.jsonhttps://bucket.s3.amazonaws.com/file-{1..100}.csvhttps://bucket.s3.amazonaws.com/{logs,metrics}/data.parquet
Exactly-once semantics
대규모 데이터 세트를 수집하는 과정에서 여러 유형의 장애가 발생할 수 있으며, 이로 인해 일부만 삽입되거나 데이터가 중복되는 문제가 생길 수 있습니다. Object Storage ClickPipes는 삽입 실패에 대해 내결함성을 가지며 exactly-once semantics를 제공합니다. 이는 임시 "staging" 테이블을 사용하여 구현됩니다. 데이터는 먼저 staging 테이블에 삽입됩니다. 이 삽입 과정에서 문제가 발생하면 staging 테이블을 truncate하여 비운 뒤, 깨끗한 상태에서 삽입을 다시 시도할 수 있습니다. 삽입이 완료되고 성공한 경우에만 staging 테이블의 파티션이 대상 테이블로 이동됩니다. 이 전략에 대한 자세한 내용은 이 블로그 게시글을 참고하십시오.
가상 컬럼
어떤 파일이 수집되었는지 추적하려면 _file 가상 컬럼을 컬럼 매핑 목록에 포함하십시오. _file 가상 컬럼에는 소스 객체의 파일명이 포함되며, 이를 사용하여 어떤 파일이 처리되었는지 조회할 수 있습니다.
접근 제어
권한
S3 ClickPipe는 공개 및 비공개 버킷을 지원합니다. Requester Pays 버킷은 지원하지 않습니다.
S3 버킷
버킷 정책에서 다음 작업을 허용하도록 설정해야 합니다.
SQS 큐
비순차 모드를 사용하는 경우 SQS 큐 정책에서 다음 작업을 허용해야 합니다:
인증
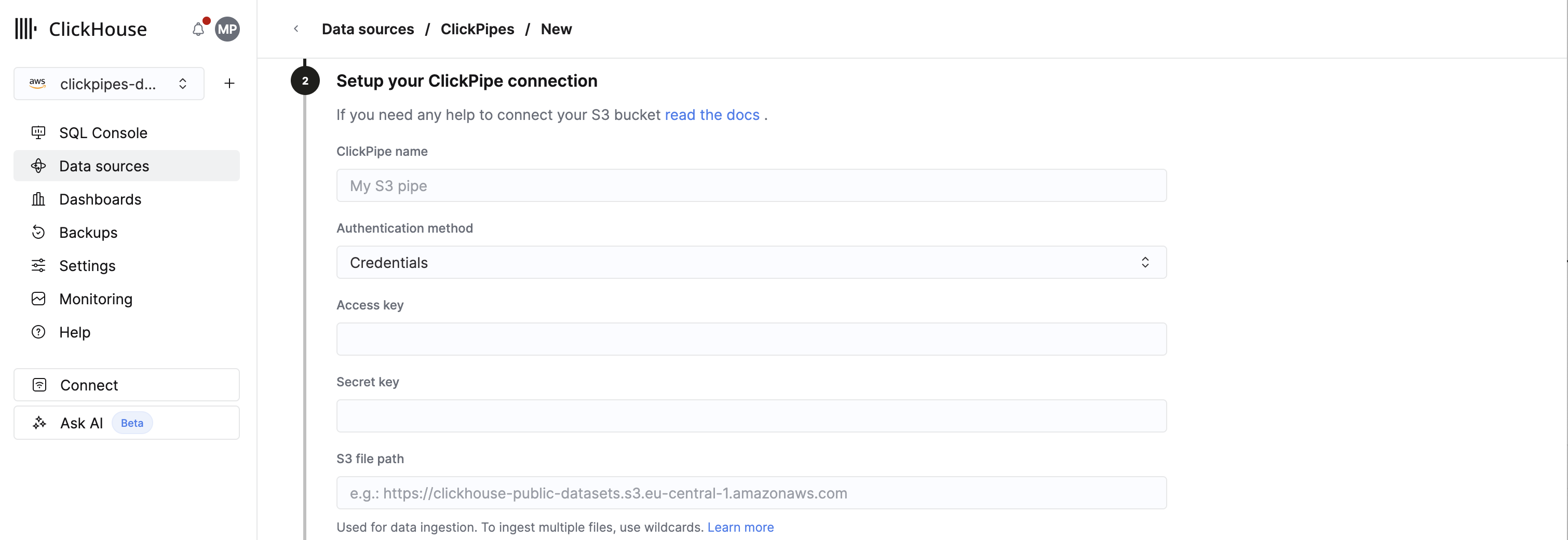
IAM 자격 증명
인증 방법으로 액세스 키를 사용하려면 ClickPipe 연결을 설정할 때 Authentication method에서 Credentials를 선택하십시오. 그런 다음 Access key와 Secret key 항목에 각각 액세스 키 ID(예: AKIAIOSFODNN7EXAMPLE)와 시크릿 액세스 키(예: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY)를 입력하십시오.
IAM 역할
역할 기반 액세스를 사용해 인증하려면 ClickPipe 연결을 설정할 때 Authentication method에서 IAM role을 선택하십시오.
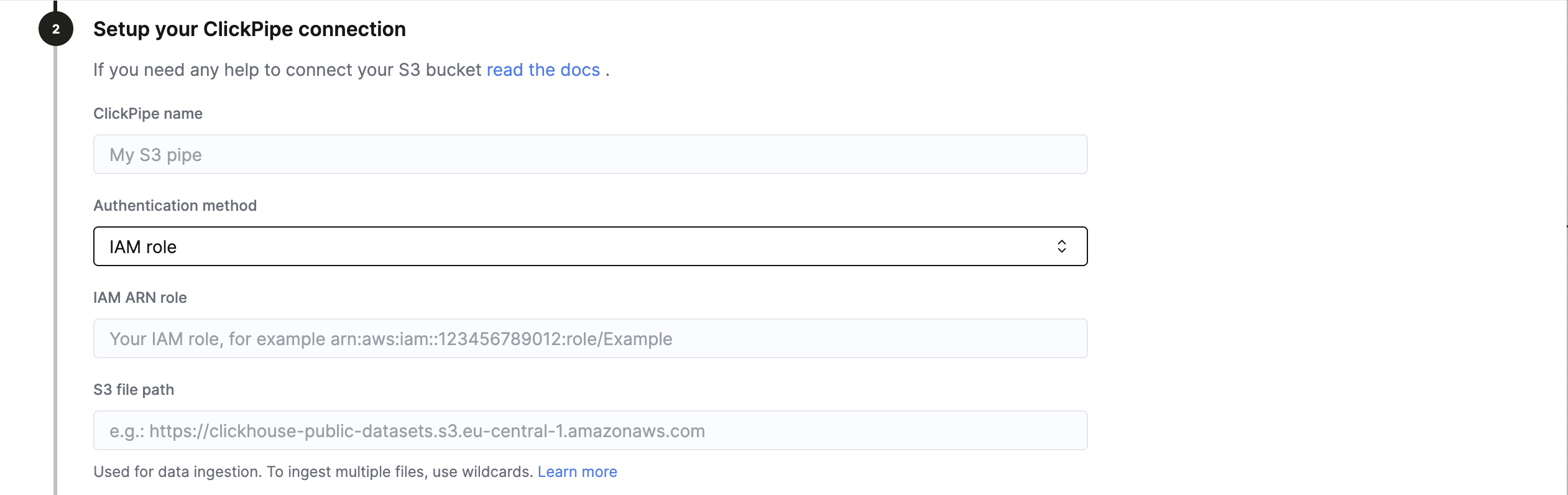
S3 액세스에 필요한 trust policy가 포함된 IAM 역할을 생성하려면 이 가이드를 따라 역할을 생성하십시오. 그런 다음 IAM role ARN 필드에 IAM 역할 ARN을 입력하십시오.
네트워크 액세스
S3 ClickPipes는 메타데이터 검색과 데이터 수집을 위해 각각 ClickPipes 서비스와 ClickHouse Cloud 서비스를 사용하는 두 가지 서로 다른 네트워크 경로를 사용합니다. 추가적인 네트워크 보안 계층(예: 컴플라이언스 목적)을 구성하려는 경우, 두 경로 모두에 대해 네트워크 액세스를 구성해야 합니다.
-
IP 기반 액세스 제어의 경우, S3 버킷 정책은 여기에 나열된 ClickPipes 서비스 리전의 고정 IP와 ClickHouse Cloud 서비스의 고정 IP를 모두 허용해야 합니다. ClickHouse Cloud 리전의 고정 IP를 가져오려면 터미널을 열고 다음을 실행하십시오.
-
VPC 엔드포인트 기반 액세스 제어의 경우, S3 버킷은 ClickHouse Cloud 서비스와 동일한 리전에 있어야 하며,
GetObject작업을 ClickHouse Cloud 서비스의 VPC 엔드포인트 ID로 제한해야 합니다. ClickHouse Cloud 리전의 VPC 엔드포인트를 가져오려면 터미널을 열고 다음을 실행하십시오.
고급 설정
ClickPipes는 대부분의 사용 사례를 충족하는 합리적인 기본값을 제공합니다. 사용 사례에 추가적인 세밀한 조정이 필요하면 다음 설정을 조정할 수 있습니다:
| Setting | Default value | Description |
|---|---|---|
Max insert bytes | 10GB | 단일 insert 배치에서 처리할 최대 바이트 수입니다. |
Max file count | 100 | 단일 insert 배치에서 처리할 파일의 최대 개수입니다. |
Max threads | auto(3) | 파일 처리를 위한 동시 스레드의 최대 개수입니다. |
Max insert threads | 1 | 파일 처리를 위한 동시 insert 스레드의 최대 개수입니다. |
Min insert block size bytes | 1GB | 테이블에 삽입할 수 있는 블록의 최소 바이트 크기입니다. |
Max download threads | 4 | 동시 download 스레드의 최대 개수입니다. |
Object storage polling interval | 30s | ClickHouse 클러스터로 데이터를 삽입하기 전에 대기하는 최대 시간을 설정합니다. |
Parallel distributed insert select | 2 | Parallel distributed insert select 설정입니다. |
Parallel view processing | false | 순차적으로 처리하는 대신 동시에 연결된 뷰로 전송할지 여부입니다. |
Use cluster function | true | 여러 노드에서 파일을 병렬로 처리할지 여부입니다. |
확장
객체 스토리지 ClickPipes는 수직 오토스케일링 설정에 의해 결정되는 최소 ClickHouse 서비스 크기를 기준으로 확장됩니다. ClickPipe의 크기는 파이프를 생성할 때 결정됩니다. 이후 ClickHouse 서비스 설정을 변경해도 ClickPipe 크기에는 영향을 주지 않습니다.
대규모 수집 작업의 처리량을 높이려면 ClickPipe를 생성하기 전에 ClickHouse 서비스를 먼저 확장해 두는 것을 권장합니다.
알려진 제한 사항
파일 크기
ClickPipes는 10GB 이하 크기의 오브젝트만 수집을 시도합니다. 파일 크기가 10GB를 초과하면 ClickPipes 전용 오류 테이블에 오류가 기록됩니다.
호환성
S3 호환 서비스라 하더라도 일부 서비스는 S3 ClickPipe가 분석하지 못할 수 있는 서로 다른 URL 구조를 사용하거나(예: Backblaze B2), 순서를 보장하지 않는 지속적인 수집을 위해 공급자별 큐 서비스와의 통합이 필요할 수 있습니다. Supported data sources에 나와 있지 않은 서비스를 사용 중이며 문제가 발생한 경우, 문의 페이지를 통해 당사 팀에 연락해 주십시오.
뷰 지원
대상 테이블에 대해 정의된 materialized view도 지원합니다. ClickPipes는 대상 테이블뿐만 아니라, 그에 의존하는 모든 materialized view에 대해서도 staging 테이블을 생성합니다.
materialized view가 아닌 일반 view에 대해서는 staging 테이블을 생성하지 않습니다. 따라서 대상 테이블에 하나 이상의 다운스트림 materialized view가 있는 경우, 해당 materialized view는 대상 테이블을 참조하는 일반 view를 통해 데이터를 조회하지 않도록 해야 합니다. 그렇지 않으면 materialized view에서 일부 데이터가 누락될 수 있습니다.
