Splunk을 ClickHouse에 연결하기
ClickHouse 감사 로그를 Splunk에 저장하려는 경우 「"Storing ClickHouse Cloud Audit logs into Splunk"」 가이드를 참조하십시오.
Splunk은 보안 및 관측성에 널리 사용되는 플랫폼입니다. 또한 강력한 검색 및 대시보드 엔진이기도 합니다. 다양한 사용 사례를 지원하는 수백 개의 Splunk 앱이 제공됩니다.
특히 ClickHouse의 경우 Splunk DB Connect App을 활용하여, 고성능 ClickHouse JDBC 드라이버와의 간단한 통합을 통해 ClickHouse 테이블을 직접 쿼리합니다.
이 통합의 이상적인 활용 시나리오는 NetFlow, Avro 또는 Protobuf 바이너리 데이터, DNS, VPC 플로우 로그, 그리고 팀이 Splunk에서 검색하고 대시보드를 생성할 수 있도록 공유할 수 있는 기타 OTel 로그처럼, 대용량 데이터 소스에 ClickHouse를 사용하는 경우입니다. 이 방식을 사용하면 데이터가 Splunk 인덱스 계층으로 수집되지 않고, Metabase 또는 Superset과 같은 다른 시각화 통합과 마찬가지로 ClickHouse에서 직접 쿼리됩니다.
목표
이 가이드에서는 ClickHouse JDBC 드라이버를 사용하여 ClickHouse를 Splunk에 연결합니다. 로컬 버전의 Splunk Enterprise를 설치하지만 데이터를 인덱싱하지는 않습니다. 대신 DB Connect 쿼리 엔진을 통해 검색 기능만 사용합니다.
이 가이드를 통해 다음과 유사한 ClickHouse에 연결된 대시보드를 생성할 수 있습니다:
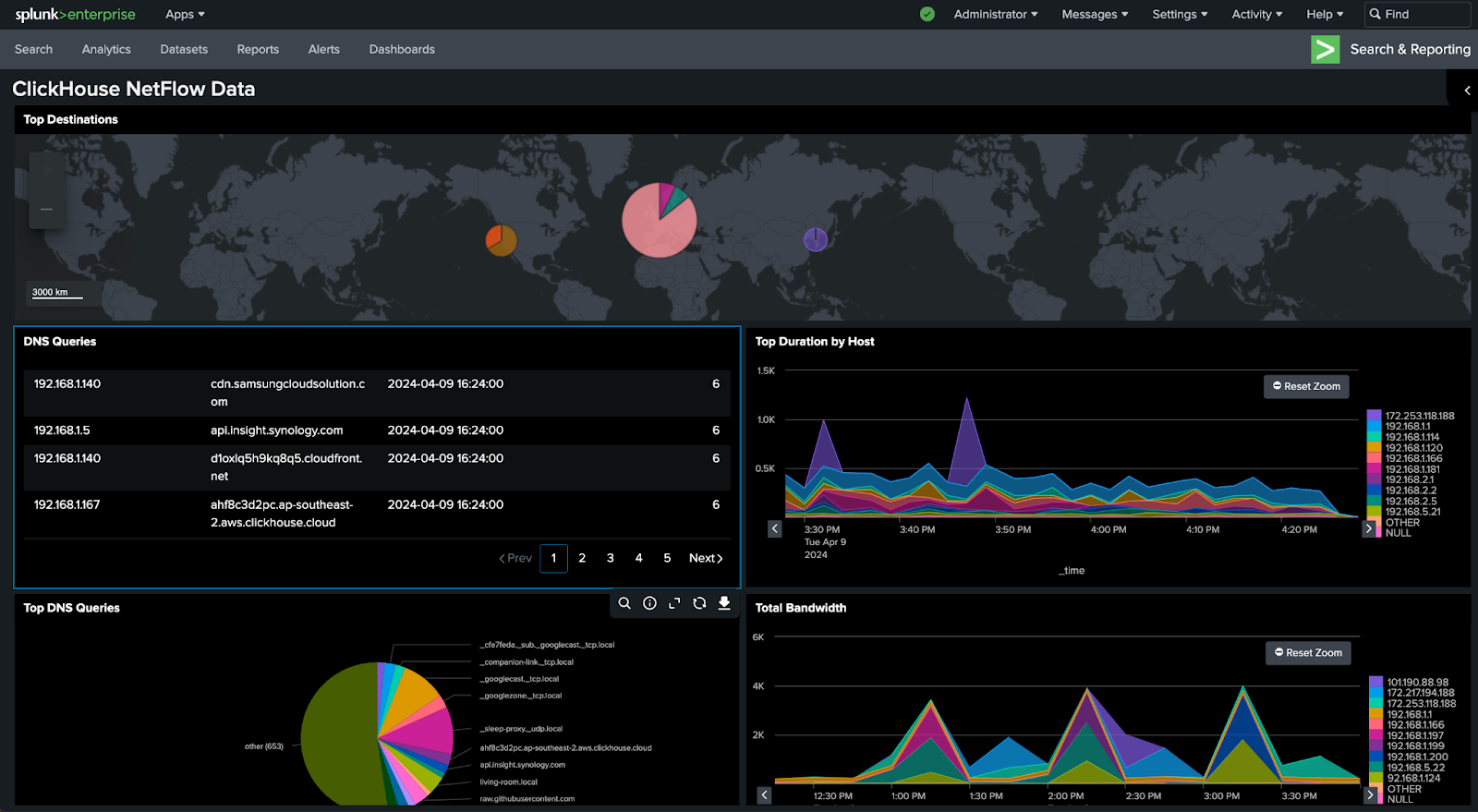
이 가이드에서는 New York City Taxi 데이터셋을 사용합니다. 문서에서 사용할 수 있는 다른 데이터셋들도 다수 제공됩니다.
필수 조건
시작하기 전에 다음이 필요합니다.
- 검색 헤드 기능을 사용할 수 있는 Splunk Enterprise
- OS 또는 컨테이너에 설치된 Java Runtime Environment (JRE)
- Splunk DB Connect
- Splunk Enterprise OS 인스턴스에 대한 관리자 권한 또는 SSH 접속 권한
- ClickHouse 연결 정보(ClickHouse Cloud를 사용하는 경우 여기를 참조하십시오)
Splunk Enterprise에서 DB Connect 설치 및 구성
먼저 Splunk Enterprise 인스턴스에 Java Runtime Environment를 설치해야 합니다. Docker를 사용하는 경우 microdnf install java-11-openjdk 명령을 실행할 수 있습니다.
java_home 경로를 메모해 둡니다: java -XshowSettings:properties -version.
Splunk Enterprise에 DB Connect App이 설치되어 있는지 확인합니다. Splunk Web UI의 Apps 섹션에서 확인할 수 있습니다.
- Splunk Web에 로그인한 후 Apps > Find More Apps로 이동합니다.
- 검색 상자를 사용하여 DB Connect를 찾습니다.
- Splunk DB Connect 옆의 녹색 "Install" 버튼을 클릭합니다.
- "Restart Splunk"를 클릭합니다.
DB Connect App 설치에 문제가 발생하는 경우, 추가 지침은 이 링크를 참조하십시오.
DB Connect App이 설치되었음을 확인한 후 Configuration -> Settings에서 DB Connect App에 java_home 경로를 추가하고, "Save"를 클릭한 다음 "Reset"을 실행합니다.
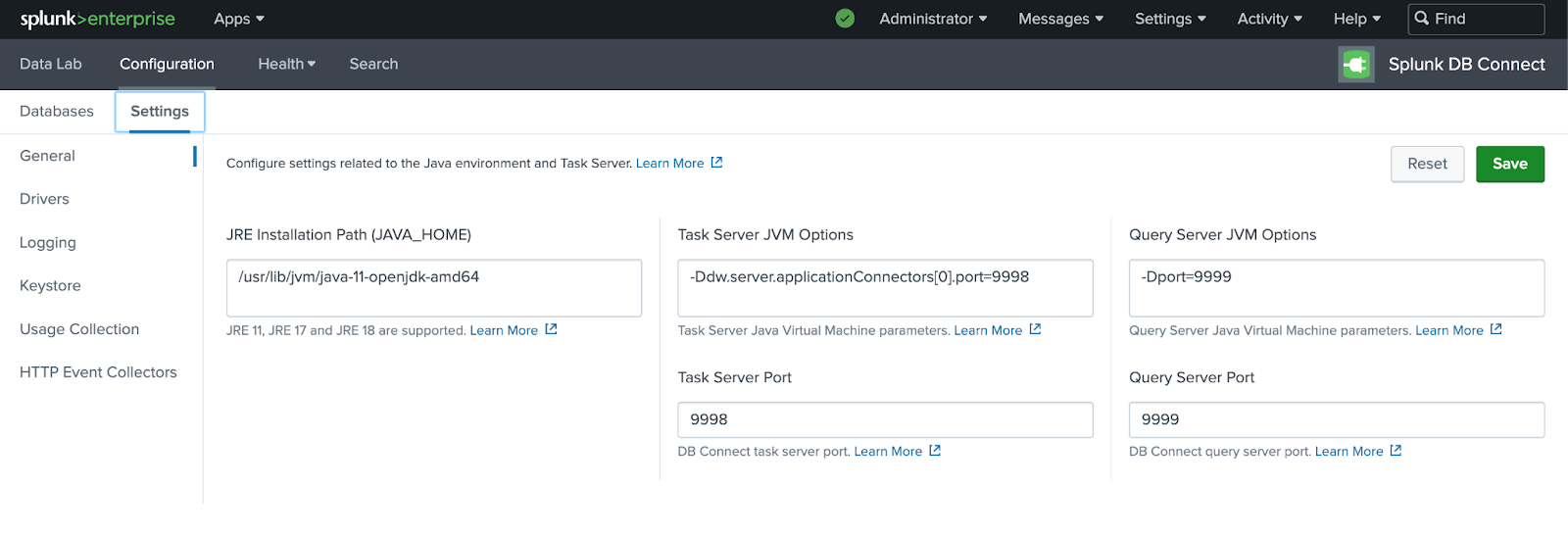
ClickHouse용 JDBC 구성
ClickHouse JDBC driver JAR 파일을 다운로드한 후 다음 위치에 있는 DB Connect Drivers 폴더에 복사합니다:
DB Connect 앱에서 필요한 모든 종속성을 사용할 수 있도록 하려면 다음 중 하나를 다운로드하십시오.
그런 다음 $SPLUNK_HOME/etc/apps/splunk_app_db_connect/local/db_connection_types.conf에 있는 연결 유형 설정을 수정하여 ClickHouse JDBC Driver 클래스 정보를 추가해야 합니다. db_connection_types.conf에 다음 섹션을 추가하십시오:
$SPLUNK_HOME/bin/splunk restart를 실행하여 Splunk를 다시 시작합니다.
DB Connect App으로 돌아가 Configuration > Settings > Drivers로 이동합니다. ClickHouse 옆에 초록색 체크 표시가 표시되는지 확인합니다.
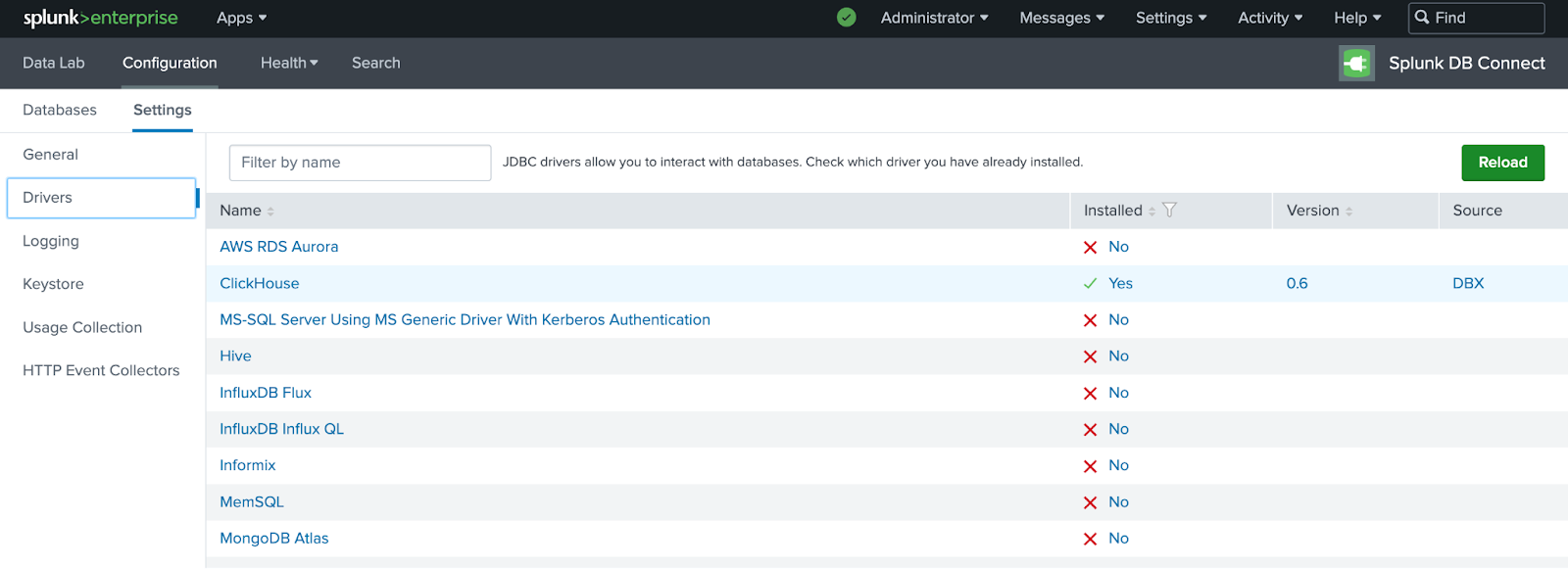
Splunk 검색을 ClickHouse에 연결하기
DB Connect App Configuration -> Databases -> Identities로 이동한 후, ClickHouse용 Identity를 생성합니다.
Configuration -> Databases -> Connections에서 ClickHouse에 대한 새 Connection을 생성하고 "New Connection"을 선택합니다.
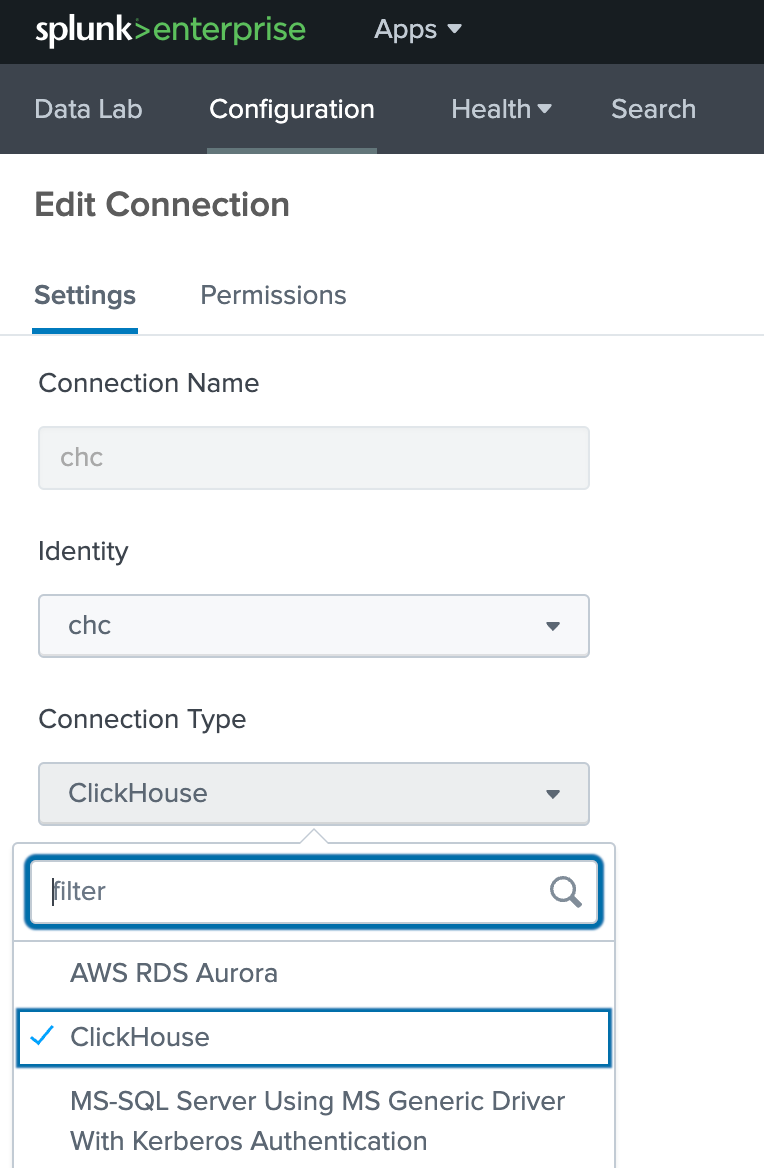
ClickHouse 호스트 정보를 추가하고 "Enable SSL"이 선택되어 있는지 확인합니다:
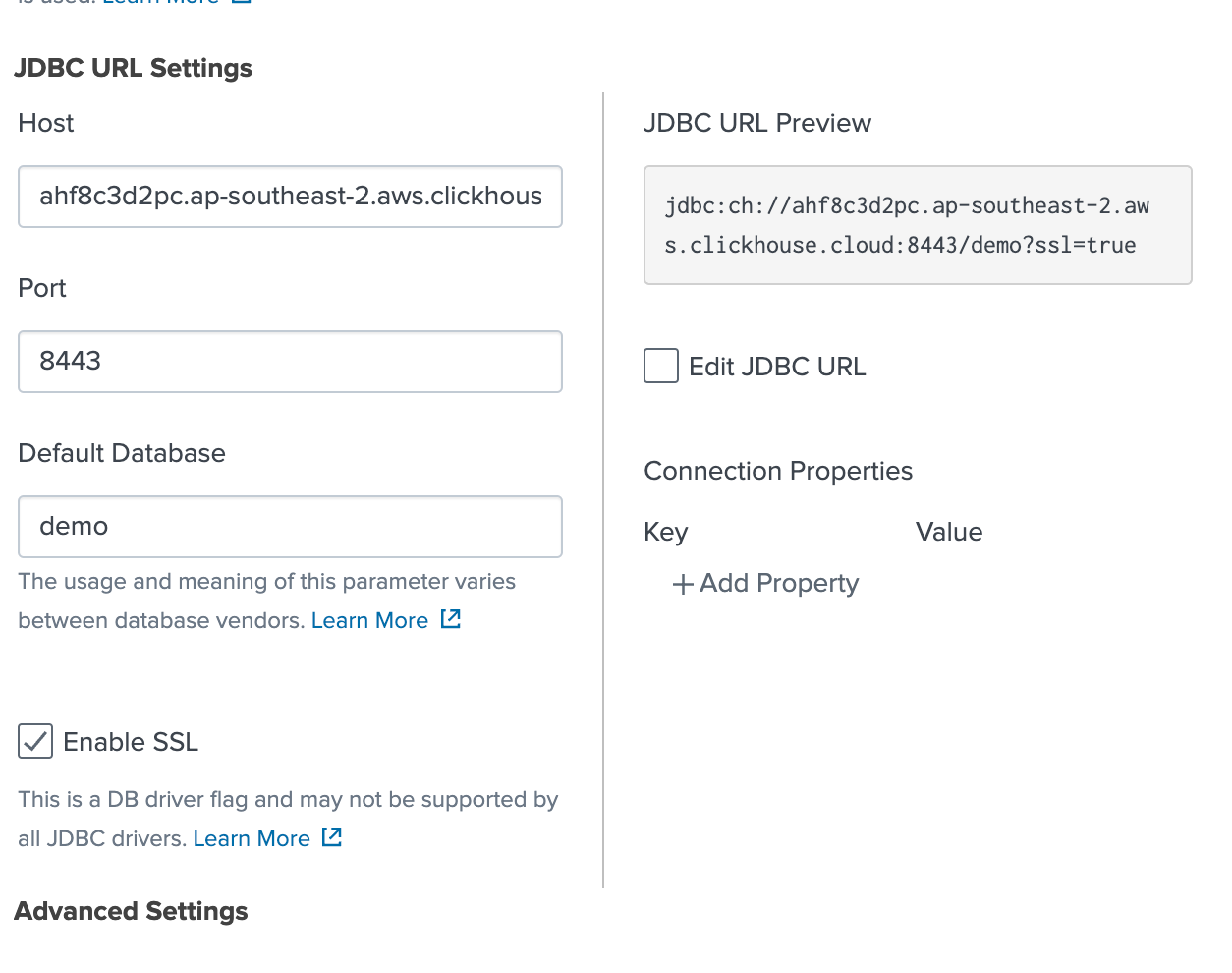
연결을 저장하면 ClickHouse와 Splunk의 연결이 성공적으로 설정됩니다.
오류가 발생하면 Splunk 인스턴스의 IP 주소를 ClickHouse Cloud IP Access List에 추가했는지 확인하십시오. 자세한 내용은 문서를 참고하십시오.
SQL 쿼리 실행
이제 SQL 쿼리를 실행하여 모든 것이 정상적으로 동작하는지 테스트합니다.
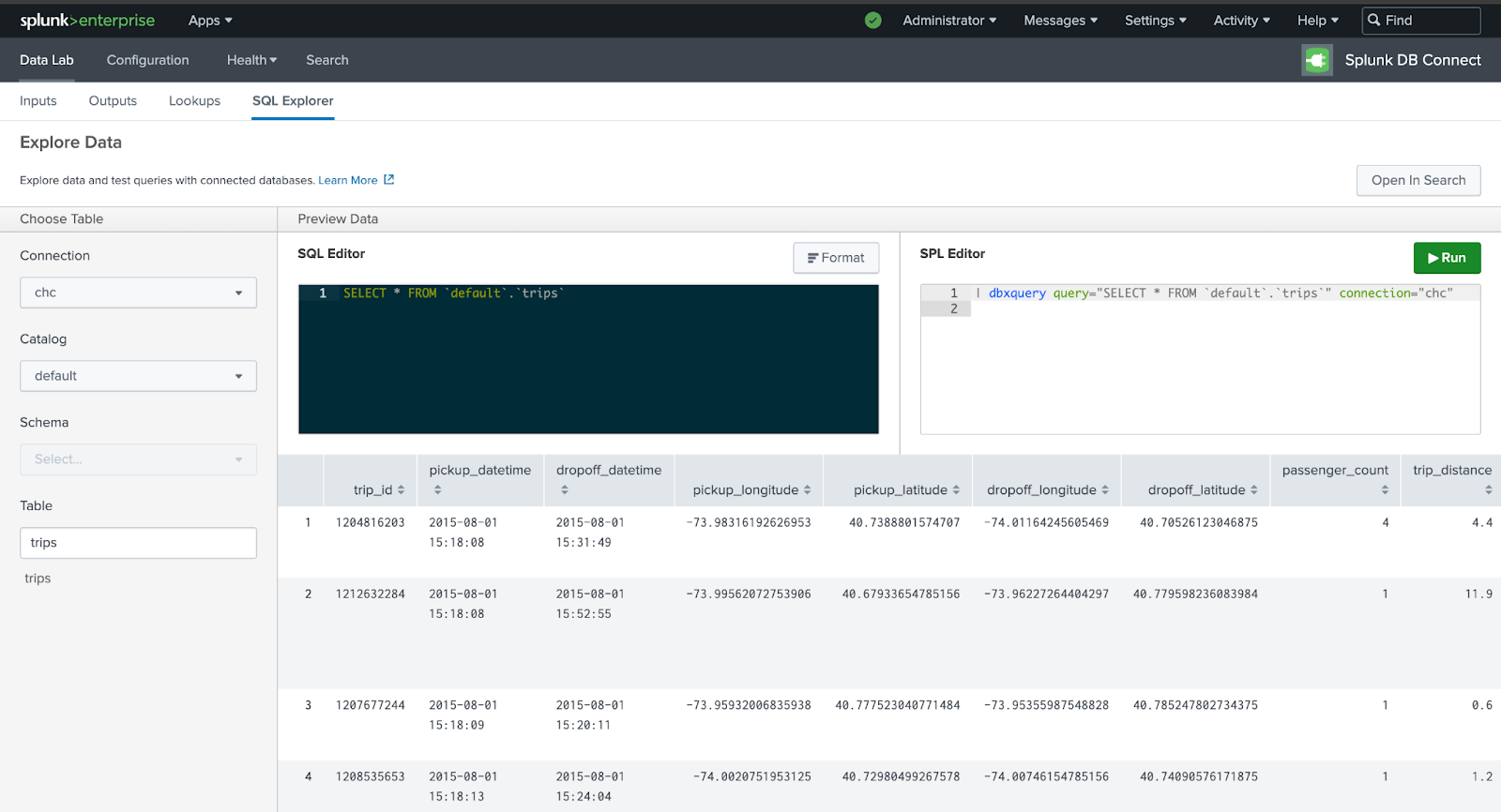
DB Connect App의 DataLab 섹션에서 SQL Explorer를 열고 연결 정보를 선택합니다. 이 데모에서는 trips 테이블을 사용합니다:
trips 테이블에 대해 해당 테이블의 전체 레코드 수를 반환하는 SQL 쿼리를 실행합니다:
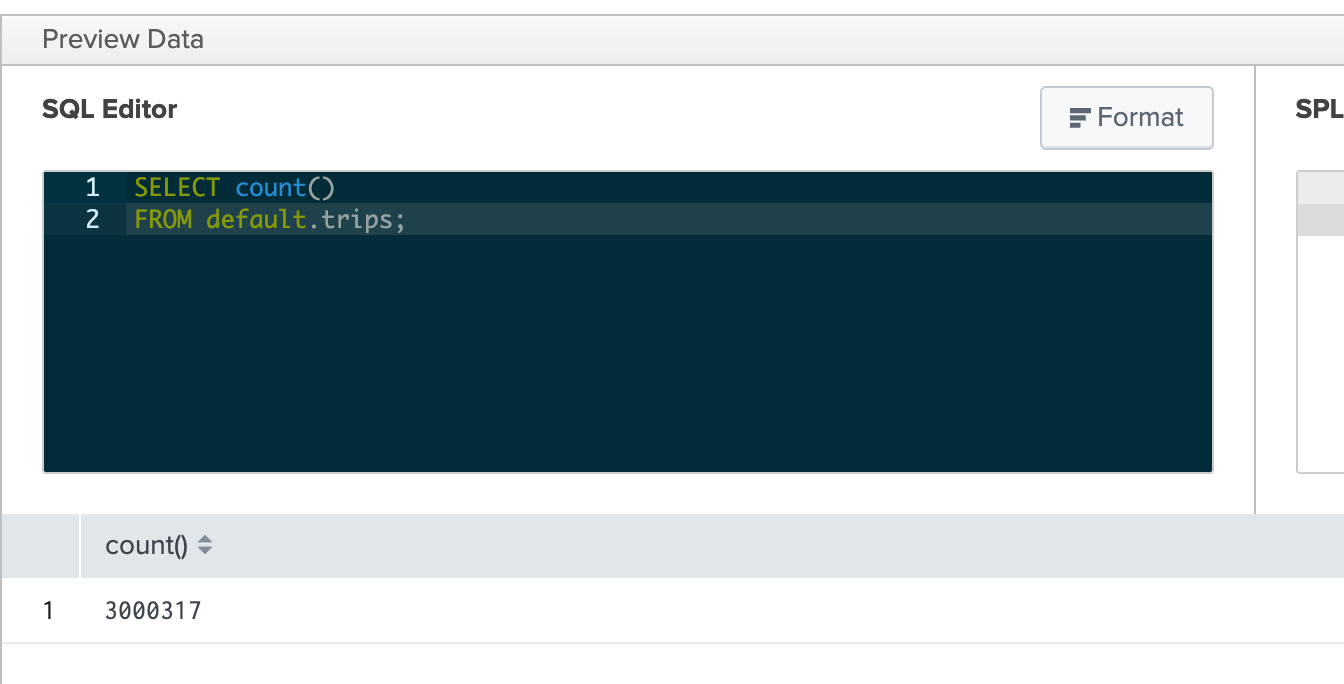
쿼리가 성공적으로 실행되면 결과가 표시됩니다.
대시보드 생성
SQL과 강력한 Splunk Processing Language(SPL)을 함께 활용하는 대시보드를 만들어 보겠습니다.
계속 진행하기 전에 먼저 Deactivate DPL Safeguards를 비활성화해야 합니다.
다음 쿼리를 실행하여 픽업이 가장 자주 발생하는 상위 10개 지역을 확인합니다:
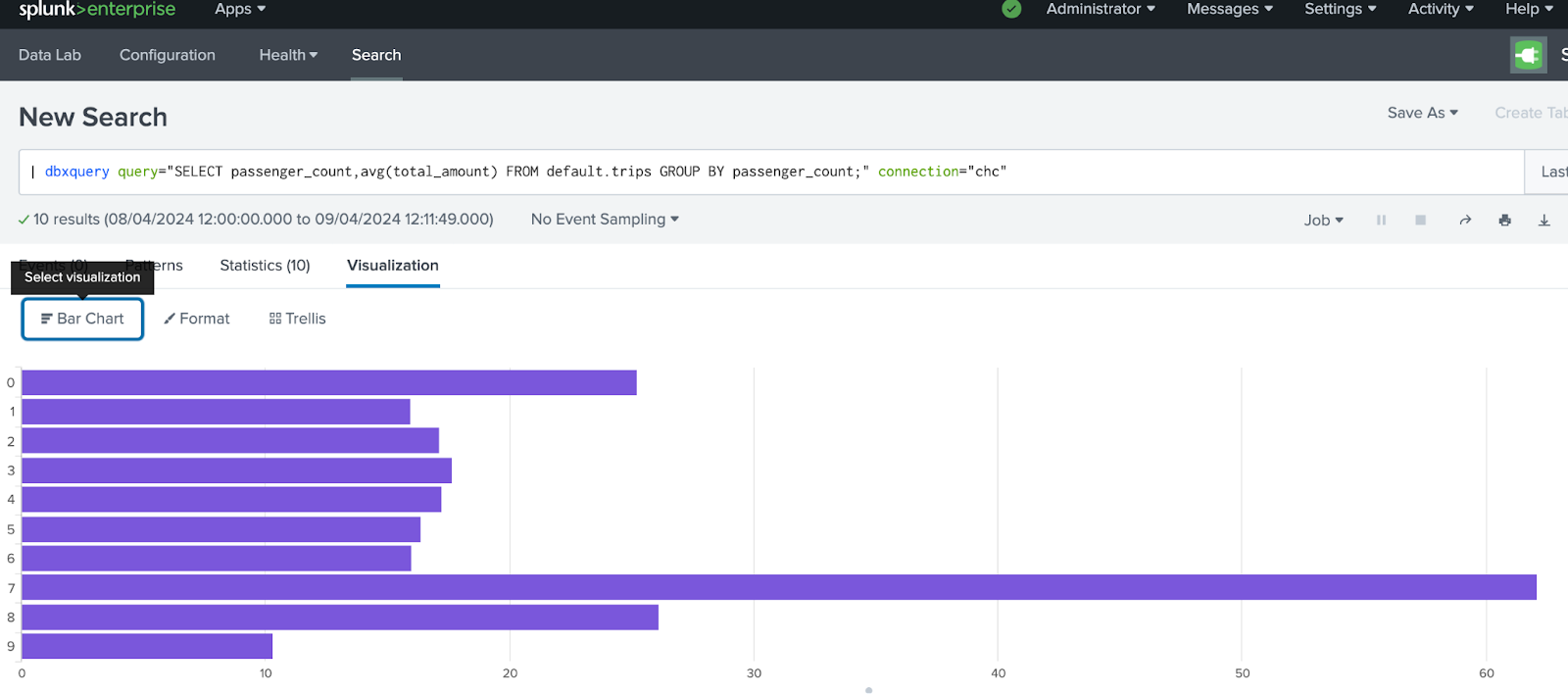
시각화 탭을 선택하여 생성된 막대 차트를 확인합니다:
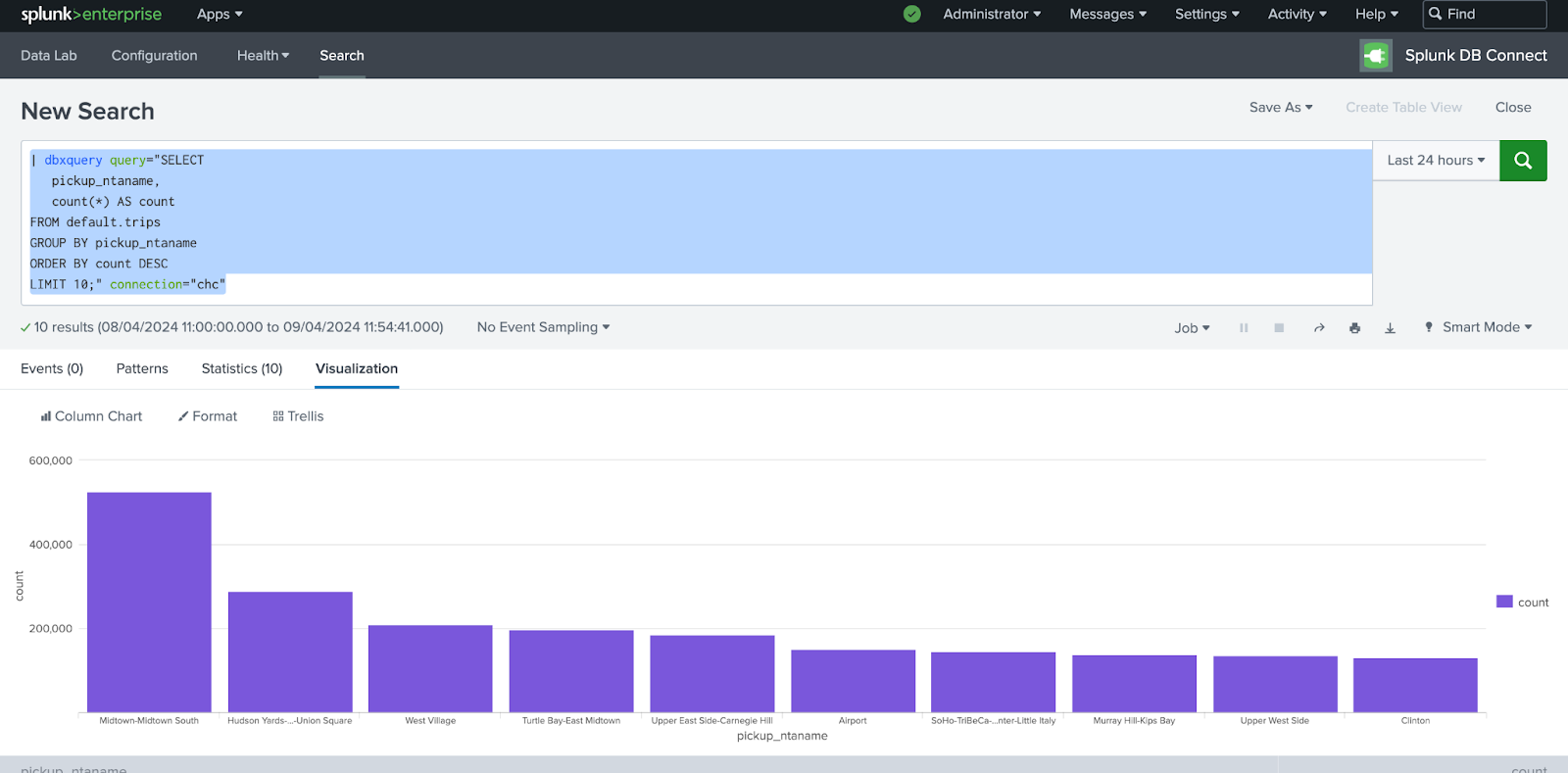
이제 「Save As」 > 「Save to a Dashboard」를 클릭하여 대시보드를 생성합니다.
다음으로 승객 수별 평균 요금을 보여주는 또 다른 쿼리를 추가합니다.
이번에는 막대 차트 시각화를 생성하여 앞에서 만든 대시보드에 저장합니다.
마지막으로, 승객 수와 이동 거리 간의 상관관계를 보여 주는 쿼리를 하나 더 추가합니다.
최종 대시보드는 다음과 같습니다:
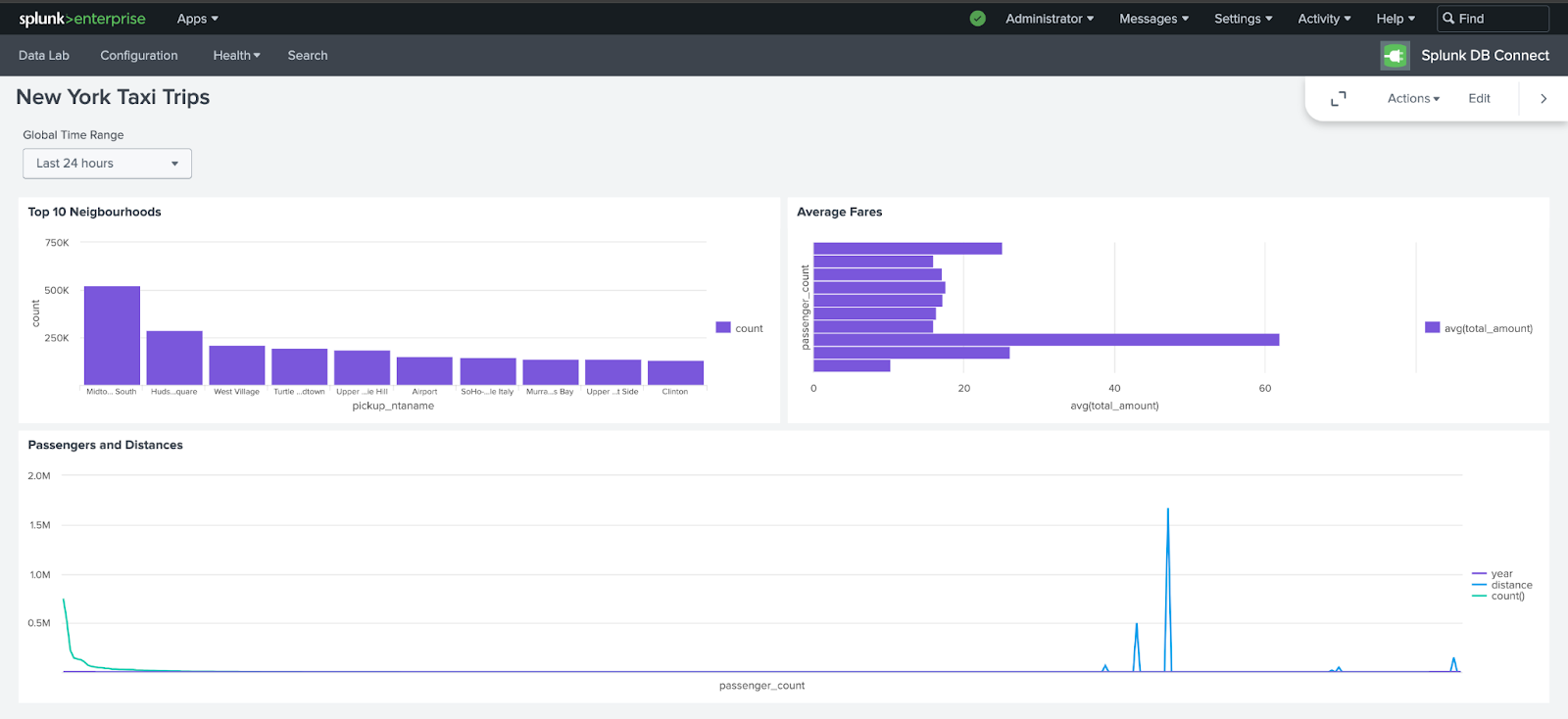
시계열 데이터
Splunk에는 대시보드에서 시계열 데이터를 시각화하고 표현하는 데 사용할 수 있는 수백 개의 내장 함수가 있습니다. 이 예제에서는 SQL과 SPL을 결합하여 Splunk에서 시계열 데이터용으로 사용할 수 있는 쿼리를 작성합니다.
더 알아보기
Splunk DB Connect 및 대시보드 구축 방법에 대한 자세한 내용은 Splunk 문서를 참조하십시오.
