Background
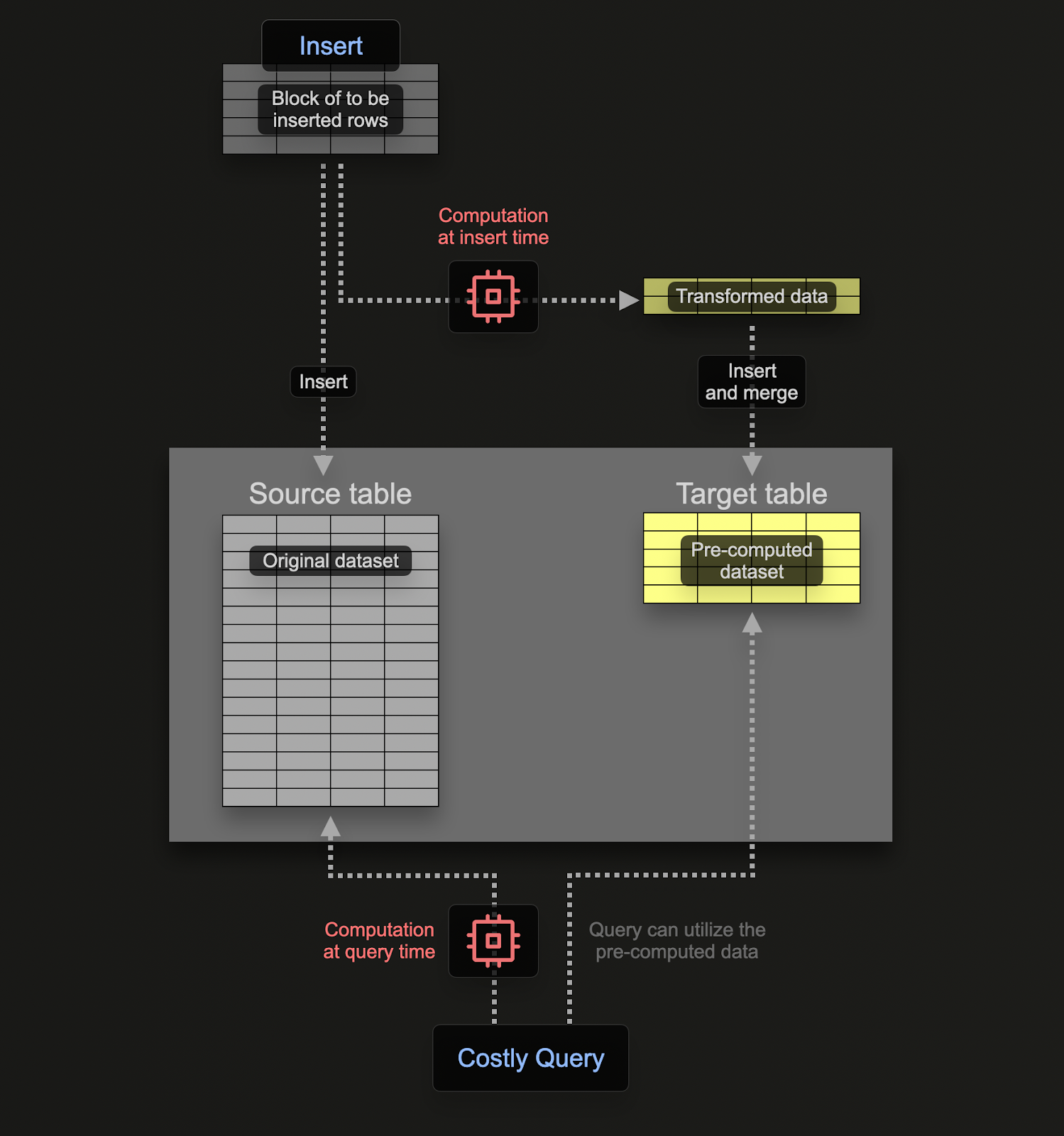
증분형 materialized view(Materialized View)를 사용하면 연산 비용을 쿼리 실행 시점에서 삽입 시점으로 옮겨, SELECT 쿼리의 속도를 높일 수 있습니다.
Postgres와 같은 트랜잭션 데이터베이스와는 달리, ClickHouse의 materialized view는 테이블에 데이터 블록이 삽입될 때 쿼리를 실행하는 트리거 역할만 합니다. 이 쿼리의 결과는 두 번째 「대상(target)」 테이블에 삽입됩니다. 이후 행이 더 삽입되면 결과가 다시 대상 테이블로 기록되어 중간 결과가 갱신되고 병합(merge)됩니다. 이렇게 병합된 결과는 원본 전체 데이터에 대해 쿼리를 실행한 것과 동일한 결과입니다.
Materialized View를 사용하는 주된 이유는, 대상 테이블에 삽입되는 결과가 행에 대해 수행된 집계, 필터링 또는 변환의 결과를 나타내기 때문입니다. 이 결과는 (집계의 경우 부분적인 스케치처럼) 원본 데이터보다 더 축약된 형태인 경우가 많습니다. 또한 대상 테이블에서 이 결과를 읽기 위한 쿼리가 단순하므로, 동일한 연산을 원본 데이터에 대해 직접 수행하는 것보다 쿼리 시간이 더 짧아지며, 연산(따라서 쿼리 지연 시간)을 쿼리 시점에서 삽입 시점으로 이전할 수 있습니다.
ClickHouse의 materialized view는 기반이 되는 테이블로 데이터가 유입될 때마다 실시간으로 업데이트되며, 계속해서 갱신되는 인덱스에 더 가깝게 동작합니다. 이는 Materialized View가 일반적으로 쿼리 결과의 정적 스냅샷이며, ClickHouse의 갱신 가능 구체화 뷰(Refreshable Materialized Views)처럼 명시적으로 새로 고쳐야 하는 다른 데이터베이스와는 대조적입니다.
예시로 "Schema Design"에 설명된 Stack Overflow 데이터셋을 사용합니다.
하루 단위로 특정 게시물이 받은 찬성표와 반대표 수를 구한다고 가정합니다.
CREATE TABLE votes
(
`Id` UInt32,
`PostId` Int32,
`VoteTypeId` UInt8,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`BountyAmount` UInt8
)
ENGINE = MergeTree
ORDER BY (VoteTypeId, CreationDate, PostId)
INSERT INTO votes SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 29.359 sec. Processed 238.98 million rows, 2.13 GB (8.14 million rows/s., 72.45 MB/s.)
toStartOfDay FUNCTION 덕분에 ClickHouse에서는 이 쿼리를 비교적 간단하게 작성할 수 있습니다.
SELECT toStartOfDay(CreationDate) AS day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY day
ORDER BY day ASC
LIMIT 10
┌─────────────────day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 00:00:00 │ 6 │ 0 │
│ 2008-08-01 00:00:00 │ 182 │ 50 │
│ 2008-08-02 00:00:00 │ 436 │ 107 │
│ 2008-08-03 00:00:00 │ 564 │ 100 │
│ 2008-08-04 00:00:00 │ 1306 │ 259 │
│ 2008-08-05 00:00:00 │ 1368 │ 269 │
│ 2008-08-06 00:00:00 │ 1701 │ 211 │
│ 2008-08-07 00:00:00 │ 1544 │ 211 │
│ 2008-08-08 00:00:00 │ 1241 │ 212 │
│ 2008-08-09 00:00:00 │ 576 │ 46 │
└─────────────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.133 sec. Processed 238.98 million rows, 2.15 GB (1.79 billion rows/s., 16.14 GB/s.)
Peak memory usage: 363.22 MiB.
이 쿼리는 ClickHouse 덕분에 이미 빠르지만, 더 개선할 수 있을까요?
구체화된 뷰(materialized view)를 사용하여 삽입 시점에 이 값을 계산하려면, 결과를 저장할 테이블이 필요합니다. 이 테이블은 하루당 1개의 행만 유지해야 합니다. 기존 일자에 대한 업데이트가 들어오면, 다른 컬럼은 해당 일자의 기존 행에 병합되어야 합니다. 이러한 증분 상태의 병합이 일어나려면, 다른 컬럼에 대해서는 부분 상태가 저장되어야 합니다.
이를 위해서는 ClickHouse에서 특수한 엔진 타입이 필요합니다: SummingMergeTree. 이 엔진은 동일한 정렬 키를 가진 모든 행을 하나의 행으로 대체하며, 그 행에는 숫자 컬럼의 합산된 값이 포함됩니다. 다음 테이블은 동일한 날짜를 가진 행들을 병합하고, 숫자 컬럼을 모두 합산합니다:
CREATE TABLE up_down_votes_per_day
(
`Day` Date,
`UpVotes` UInt32,
`DownVotes` UInt32
)
ENGINE = SummingMergeTree
ORDER BY Day
materialized view를 시연하기 위해 votes 테이블이 비어 있고 아직 어떤 데이터도 들어오지 않았다고 가정합니다. materialized view는 votes에 삽입되는 데이터에 대해 위의 SELECT를 수행하고, 그 결과를 up_down_votes_per_day로 보냅니다:
CREATE MATERIALIZED VIEW up_down_votes_per_day_mv TO up_down_votes_per_day AS
SELECT toStartOfDay(CreationDate)::Date AS Day,
countIf(VoteTypeId = 2) AS UpVotes,
countIf(VoteTypeId = 3) AS DownVotes
FROM votes
GROUP BY Day
여기서 TO 절은 결과가 전송될 대상, 즉 up_down_votes_per_day를 나타내는 핵심 요소입니다.
이전에 수행한 insert 문을 사용하여 votes 테이블을 다시 채울 수 있습니다:
INSERT INTO votes SELECT toUInt32(Id) AS Id, toInt32(PostId) AS PostId, VoteTypeId, CreationDate, UserId, BountyAmount
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/votes/*.parquet')
0 rows in set. Elapsed: 111.964 sec. Processed 477.97 million rows, 3.89 GB (4.27 million rows/s., 34.71 MB/s.)
Peak memory usage: 283.49 MiB.
작업이 완료되면 up_down_votes_per_day의 크기를 확인할 수 있습니다. 하루에 1개의 행이 있어야 합니다.
SELECT count()
FROM up_down_votes_per_day
FINAL
┌─count()─┐
│ 5723 │
└─────────┘
여기서는 쿼리 결과를 저장함으로써 votes의 2억 3,800만 개 행을 5,000개로 실질적으로 줄였습니다. 하지만 여기서 핵심은, 새로운 투표가 votes 테이블에 삽입되면 해당 날짜에 대한 새로운 값이 up_down_votes_per_day에 기록되고, 백그라운드에서 비동기적으로 자동 병합되어 하루에 하나의 행만 유지된다는 점입니다. 따라서 up_down_votes_per_day는 항상 작고 최신 상태를 유지합니다.
행 병합은 비동기적으로 수행되므로, 사용자가 쿼리를 실행할 때는 하루에 하나 이상의 투표가 존재할 수 있습니다. 쿼리 시점에 남아 있는 모든 행이 병합되도록 하려면 두 가지 옵션이 있습니다:
- 테이블 이름에
FINAL 수정자를 사용합니다. 위의 COUNT 쿼리에서 이렇게 했습니다.
- 최종 테이블에서 사용한 정렬 키(예:
CreationDate)로 집계하고, 메트릭을 합산합니다. 일반적으로 이 방법이 더 효율적이고 유연하며(테이블을 다른 용도로도 사용할 수 있음), 첫 번째 방법이 일부 쿼리에서는 더 단순할 수 있습니다. 아래에 두 방법 모두를 보여줍니다:
SELECT
Day,
UpVotes,
DownVotes
FROM up_down_votes_per_day
FINAL
ORDER BY Day ASC
LIMIT 10
10 rows in set. Elapsed: 0.004 sec. Processed 8.97 thousand rows, 89.68 KB (2.09 million rows/s., 20.89 MB/s.)
Peak memory usage: 289.75 KiB.
SELECT Day, sum(UpVotes) AS UpVotes, sum(DownVotes) AS DownVotes
FROM up_down_votes_per_day
GROUP BY Day
ORDER BY Day ASC
LIMIT 10
┌────────Day─┬─UpVotes─┬─DownVotes─┐
│ 2008-07-31 │ 6 │ 0 │
│ 2008-08-01 │ 182 │ 50 │
│ 2008-08-02 │ 436 │ 107 │
│ 2008-08-03 │ 564 │ 100 │
│ 2008-08-04 │ 1306 │ 259 │
│ 2008-08-05 │ 1368 │ 269 │
│ 2008-08-06 │ 1701 │ 211 │
│ 2008-08-07 │ 1544 │ 211 │
│ 2008-08-08 │ 1241 │ 212 │
│ 2008-08-09 │ 576 │ 46 │
└────────────┴─────────┴───────────┘
10 rows in set. Elapsed: 0.010 sec. Processed 8.97 thousand rows, 89.68 KB (907.32 thousand rows/s., 9.07 MB/s.)
Peak memory usage: 567.61 KiB.
이로 인해 쿼리 속도가 0.133초에서 0.004초로 빨라졌으며, 25배 이상 성능이 향상되었습니다!
참조
Important: ORDER BY = GROUP BY대부분의 경우 materialized view 변환에서 GROUP BY 절에 사용되는 컬럼은 SummingMergeTree 또는 AggregatingMergeTree 테이블 엔진을 사용하는 대상 테이블의 ORDER BY 절에 사용되는 컬럼과 일치해야 합니다. 이러한 엔진은 백그라운드 병합 작업 동안 동일한 값을 가진 행을 병합하기 위해 ORDER BY 컬럼에 의존합니다. GROUP BY와 ORDER BY 컬럼이 일치하지 않으면 쿼리 성능 저하, 비효율적인 병합, 심지어 데이터 불일치로 이어질 수 있습니다.
더 복잡한 예제
위 예제에서는 구체화된 뷰(Materialized View)를 사용해 하루마다 두 가지 합계를 계산하고 유지합니다. 합계는 부분 상태를 유지하기 위한 가장 단순한 형태의 집계입니다. 새 값이 도착하면 기존 값에 단순히 더해 주기만 하면 되기 때문입니다. 그러나 ClickHouse의 구체화된 뷰(Materialized View)는 어떤 유형의 집계에도 사용할 수 있습니다.
매일 게시물에 대해 몇 가지 통계를 계산한다고 가정해 보겠습니다. Score에 대해서는 99.9번째 퍼센타일, CommentCount에 대해서는 평균을 계산하려고 합니다. 이를 계산하는 쿼리는 다음과 같을 수 있습니다.
SELECT
toStartOfDay(CreationDate) AS Day,
quantile(0.999)(Score) AS Score_99th,
avg(CommentCount) AS AvgCommentCount
FROM posts
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
┌─────────────────Day─┬────────Score_99th─┬────AvgCommentCount─┐
│ 2024-03-31 00:00:00 │ 5.23700000000008 │ 1.3429811866859624 │
│ 2024-03-30 00:00:00 │ 5 │ 1.3097158891616976 │
│ 2024-03-29 00:00:00 │ 5.78899999999976 │ 1.2827635327635327 │
│ 2024-03-28 00:00:00 │ 7 │ 1.277746158224246 │
│ 2024-03-27 00:00:00 │ 5.738999999999578 │ 1.2113264918282023 │
│ 2024-03-26 00:00:00 │ 6 │ 1.3097536945812809 │
│ 2024-03-25 00:00:00 │ 6 │ 1.2836721018539201 │
│ 2024-03-24 00:00:00 │ 5.278999999999996 │ 1.2931667891256429 │
│ 2024-03-23 00:00:00 │ 6.253000000000156 │ 1.334061135371179 │
│ 2024-03-22 00:00:00 │ 9.310999999999694 │ 1.2388059701492538 │
└─────────────────────┴───────────────────┴────────────────────┘
10 rows in set. Elapsed: 0.113 sec. Processed 59.82 million rows, 777.65 MB (528.48 million rows/s., 6.87 GB/s.)
Peak memory usage: 658.84 MiB.
앞서와 마찬가지로, posts 테이블에 새 게시물이 삽입될 때마다 위 쿼리를 실행하는 materialized view(Materialized View)를 생성할 수 있습니다.
예시를 위해, 그리고 S3에서 게시물 데이터를 로드하지 않기 위해 posts와 동일한 스키마를 가지는 posts_null 테이블을 하나 더 생성하겠습니다. 단, 이 테이블은 어떠한 데이터도 저장하지 않으며, 행이 삽입될 때 materialized view(Materialized View)에서만 사용됩니다. 데이터 저장을 방지하기 위해 Null table engine type을 사용할 수 있습니다.
CREATE TABLE posts_null AS posts ENGINE = Null
Null 테이블 엔진은 매우 강력한 최적화 기능으로, /dev/null과 같다고 생각하면 됩니다. 이 materialized view는 posts_null 테이블이 행을 삽입받는 시점에 요약 통계를 계산하여 저장하며, 일종의 트리거처럼 동작합니다. 그러나 원시(raw) 데이터는 저장되지 않습니다. 이 예제에서는 여전히 원본 게시물을 저장하고자 할 가능성이 크지만, 이 접근 방식은 원시 데이터의 저장 오버헤드를 피하면서 집계를 계산하는 데 활용할 수 있습니다.
따라서 materialized view는 다음과 같습니다:
CREATE MATERIALIZED VIEW post_stats_mv TO post_stats_per_day AS
SELECT toStartOfDay(CreationDate) AS Day,
quantileState(0.999)(Score) AS Score_quantiles,
avgState(CommentCount) AS AvgCommentCount
FROM posts_null
GROUP BY Day
집계 함수 이름 끝에 State 접미사를 추가하는 것에 주목하십시오. 이렇게 하면 최종 결과 대신 함수의 집계 상태가 반환됩니다. 이렇게 반환되는 부분 집계 상태(partial aggregation states)에는 다른 상태와 병합할 수 있도록 하는 추가 정보가 포함됩니다. 예를 들어 평균의 경우, 컬럼의 개수와 합계가 포함됩니다.
올바른 결과를 계산하려면 부분 집계 상태가 필요합니다. 예를 들어 평균을 계산할 때, 단순히 하위 구간 평균들의 평균을 내면 올바르지 않은 결과가 생성됩니다.
이제 이러한 부분 집계 상태를 저장하는 뷰 post_stats_per_day의 대상 테이블을 생성합니다:
CREATE TABLE post_stats_per_day
(
`Day` Date,
`Score_quantiles` AggregateFunction(quantile(0.999), Int32),
`AvgCommentCount` AggregateFunction(avg, UInt8)
)
ENGINE = AggregatingMergeTree
ORDER BY Day
이전에 SummingMergeTree로 카운트를 저장하기에는 충분했지만, 다른 함수들을 위해서는 더 발전된 엔진 타입이 필요합니다. 바로 AggregatingMergeTree입니다.
ClickHouse가 집계 상태가 저장된다는 것을 알 수 있도록, Score_quantiles와 AvgCommentCount를 타입 AggregateFunction으로 정의하고, 부분 상태의 함수 소스와 해당 소스 컬럼 타입을 지정합니다. SummingMergeTree와 마찬가지로, 동일한 ORDER BY 키 값을 가진 행(위 예시에서는 Day)은 머지됩니다.
materialized view를 통해 post_stats_per_day를 채우기 위해, posts의 모든 행을 posts_null에 그대로 삽입하면 됩니다:
INSERT INTO posts_null SELECT * FROM posts
0 rows in set. Elapsed: 13.329 sec. Processed 119.64 million rows, 76.99 GB (8.98 million rows/s., 5.78 GB/s.)
프로덕션 환경에서는 일반적으로 이 materialized view를 posts 테이블에 연결합니다. 여기서는 null 테이블을 보여 주기 위해 posts_null을 사용했습니다.
최종 쿼리에서는 컬럼에 부분 집계 상태가 저장되므로 함수에 Merge 접미사를 사용해야 합니다:
SELECT
Day,
quantileMerge(0.999)(Score_quantiles),
avgMerge(AvgCommentCount)
FROM post_stats_per_day
GROUP BY Day
ORDER BY Day DESC
LIMIT 10
여기서는 FINAL 대신 GROUP BY를 사용합니다.
기타 활용 사례
위에서는 주로 materialized view를 사용하여 데이터의 부분 집계를 점진적으로 갱신하고, 이로써 계산을 쿼리 시점에서 삽입 시점으로 옮기는 방법에 초점을 맞추었습니다. 이러한 일반적인 사용 사례 외에도 materialized view는 다양한 방식으로 활용될 수 있습니다.
일부 상황에서는 삽입 시 행과 컬럼의 일부만 삽입하려는 경우가 있을 수 있습니다. 이때 posts_null 테이블이 삽입을 받도록 하고, SELECT 쿼리로 posts 테이블에 삽입하기 전에 행을 필터링하도록 할 수 있습니다. 예를 들어 posts 테이블의 Tags 컬럼을 변환하려 한다고 가정해 보겠습니다. 이 컬럼에는 태그 이름이 파이프 기호로 구분된 목록이 들어 있습니다. 이를 배열로 변환하면 개별 태그 값별로 더 쉽게 집계할 수 있습니다.
이 변환은 INSERT INTO SELECT를 실행할 때 수행할 수 있습니다. materialized view를 사용하면 이 로직을 ClickHouse DDL 안에 캡슐화하여, 모든 새로운 행에 변환이 적용되도록 하면서도 INSERT를 단순하게 유지할 수 있습니다.
이 변환을 위한 materialized view는 아래와 같습니다:
CREATE MATERIALIZED VIEW posts_mv TO posts AS
SELECT * EXCEPT Tags, arrayFilter(t -> (t != ''), splitByChar('|', Tags)) as Tags FROM posts_null
조회 테이블
ClickHouse 정렬 키를 선택할 때는 접근 패턴을 고려해야 합니다. 필터 및 집계 절에서 자주 사용되는 컬럼을 정렬 키로 사용하는 것이 좋습니다. 하지만 이는 사용자 접근 패턴이 더 다양하여 단일 컬럼 집합만으로는 표현할 수 없는 시나리오에서는 제약이 될 수 있습니다. 예를 들어, 다음 comments 테이블을 살펴보십시오:
CREATE TABLE comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY PostId
0 rows in set. Elapsed: 46.357 sec. Processed 90.38 million rows, 11.14 GB (1.95 million rows/s., 240.22 MB/s.)
여기에서 정렬 키는 PostId로 필터링하는 쿼리가 효율적으로 수행되도록 테이블을 최적화합니다.
어떤 사용자가 특정 UserId로 필터링하고 해당 사용자의 평균 Score를 계산하려 한다고 가정해 보겠습니다:
SELECT avg(Score)
FROM comments
WHERE UserId = 8592047
┌──────────avg(Score)─┐
│ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.778 sec. Processed 90.38 million rows, 361.59 MB (116.16 million rows/s., 464.74 MB/s.)
Peak memory usage: 217.08 MiB.
속도는 빠르지만(ClickHouse 입장에서는 데이터가 작기 때문입니다), 처리된 행 수인 9,038만 개를 보면 전체 테이블 스캔이 필요했음을 알 수 있습니다. 더 큰 데이터셋에서는 필터링에 사용할 컬럼 UserId에 대해 정렬 키 값 PostId를 조회하기 위해 구체화된 뷰(materialized view)를 사용할 수 있습니다. 이렇게 얻은 값은 효율적인 조회를 수행하는 데 사용됩니다.
이 예제에서 사용하는 구체화된 뷰(materialized view)는 매우 단순하며, insert 시점에 comments에서 PostId와 UserId만 선택합니다. 이 결과는 UserId로 정렬된 comments_posts_users 테이블로 전송됩니다. 아래에서는 comments 테이블의 비어 있는(null) 버전을 생성한 뒤, 이를 사용하여 materialized view와 comments_posts_users 테이블을 채웁니다:
CREATE TABLE comments_posts_users (
PostId UInt32,
UserId Int32
) ENGINE = MergeTree ORDER BY UserId
CREATE TABLE comments_null AS comments
ENGINE = Null
CREATE MATERIALIZED VIEW comments_posts_users_mv TO comments_posts_users AS
SELECT PostId, UserId FROM comments_null
INSERT INTO comments_null SELECT * FROM comments
0 rows in set. Elapsed: 5.163 sec. Processed 90.38 million rows, 17.25 GB (17.51 million rows/s., 3.34 GB/s.)
이제 이 View를 서브쿼리에서 사용하여 앞서의 쿼리를 더 빠르게 실행할 수 있습니다:
SELECT avg(Score)
FROM comments
WHERE PostId IN (
SELECT PostId
FROM comments_posts_users
WHERE UserId = 8592047
) AND UserId = 8592047
┌──────────avg(Score)─┐
│ 0.18181818181818182 │
└─────────────────────┘
1 row in set. Elapsed: 0.012 sec. Processed 88.61 thousand rows, 771.37 KB (7.09 million rows/s., 61.73 MB/s.)
materialized view 체이닝 / 캐스캐이딩
materialized view는 체이닝(또는 캐스캐이딩)해 복잡한 워크플로를 구성할 수 있습니다.
자세한 내용은 가이드 「Cascading materialized views」를 참고하십시오.
Materialized views와 JOIN(조인)
갱신 가능 구체화 뷰(Refreshable Materialized Views)
아래 내용은 증분형 materialized view(Incremental Materialized Views)에만 적용됩니다. 갱신 가능 구체화 뷰(Refreshable Materialized Views)는 전체 대상 데이터 세트에 대해 주기적으로 쿼리를 실행하며, JOIN(조인)을 완전히 지원합니다. 결과의 최신성이 다소 떨어져도 괜찮다면 복잡한 JOIN(조인)에 대해 갱신 가능 구체화 뷰 사용을 고려하십시오.
ClickHouse의 증분형 materialized view는 JOIN 연산을 완전히 지원하지만, 하나의 중요한 제약이 있습니다. materialized view는 쿼리에서 가장 왼쪽에 있는 소스 테이블(원본 테이블)에 대한 INSERT가 발생할 때만 트리거됩니다. JOIN의 오른쪽 테이블은 데이터가 변경되더라도 업데이트를 트리거하지 않습니다. 이 동작은 삽입 시점에 데이터를 집계하거나 변환하는 증분형 materialized view를 구성할 때 특히 중요합니다.
증분형 materialized view가 JOIN을 사용해 정의되면, SELECT 쿼리에서 가장 왼쪽에 있는 테이블이 소스 역할을 합니다. 새 행이 이 테이블에 INSERT되면, ClickHouse는 materialized view 쿼리를 그 새로 INSERT된 행들에 대해서만 실행합니다. JOIN의 오른쪽 테이블들은 이 실행 동안 전체를 스캔하지만, 해당 테이블들만 변경되었을 때는 view가 트리거되지 않습니다.
이 동작으로 인해 materialized view에서의 JOIN은 정적인 차원 데이터에 대한 스냅샷 조인과 유사하게 작동합니다.
이는 참조 테이블이나 차원 테이블을 사용해 데이터를 보강(enrich)하는 데에는 적합합니다. 그러나 오른쪽 테이블(예: 사용자 메타데이터)에 대한 모든 업데이트는 materialized view에 소급하여 반영되지 않습니다. 변경된 데이터를 조회하려면 소스 테이블로 새로운 INSERT가 발생해야 합니다.
Stack Overflow 데이터셋을 사용하는 구체적인 예를 살펴보겠습니다. users 테이블의 사용자 표시 이름을 포함하여 사용자별 일간 배지를 계산하기 위해 materialized view를 사용합니다.
참고로 테이블 스키마는 다음과 같습니다:
CREATE TABLE badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
CREATE TABLE users
(
`Id` Int32,
`Reputation` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`DisplayName` LowCardinality(String),
`LastAccessDate` DateTime64(3, 'UTC'),
`Location` LowCardinality(String),
`Views` UInt32,
`UpVotes` UInt32,
`DownVotes` UInt32
)
ENGINE = MergeTree
ORDER BY Id;
users 테이블에 데이터가 미리 들어 있다고 가정합니다:
INSERT INTO users
SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/users.parquet');
materialized view와 관련된 대상 테이블은 다음과 같이 정의됩니다:
CREATE TABLE daily_badges_by_user
(
Day Date,
UserId Int32,
DisplayName LowCardinality(String),
Gold UInt32,
Silver UInt32,
Bronze UInt32
)
ENGINE = SummingMergeTree
ORDER BY (DisplayName, UserId, Day);
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user AS
SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN users AS u ON b.UserId = u.Id
GROUP BY Day, b.UserId, u.DisplayName;
그룹화 및 정렬 일치(Alignment)
materialized view의 GROUP BY 절에는 SummingMergeTree 대상 테이블의 ORDER BY와 일치하도록 DisplayName, UserId, Day가 포함되어야 합니다. 이렇게 하면 행이 올바르게 집계되고 병합됩니다. 이 중 하나라도 누락되면 결과가 부정확해지거나 비효율적인 병합이 발생할 수 있습니다.
이제 배지 데이터를 적재하면 뷰가 트리거되어 daily_badges_by_user 테이블이 채워집니다.
INSERT INTO badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 433.762 sec. Processed 1.16 billion rows, 28.50 GB (2.67 million rows/s., 65.70 MB/s.)
특정 사용자가 획득한 배지를 조회하려면 다음과 같은 쿼리를 작성하면 됩니다:
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'gingerwizard'
┌────────Day─┬──UserId─┬─DisplayName──┬─Gold─┬─Silver─┬─Bronze─┐
│ 2023-02-27 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-28 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-10-30 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2024-03-04 │ 2936484 │ gingerwizard │ 0 │ 1 │ 0 │
│ 2024-03-05 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-04-17 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-11-18 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-10-31 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
└────────────┴─────────┴──────────────┴──────┴────────┴────────┘
8 rows in set. Elapsed: 0.018 sec. Processed 32.77 thousand rows, 642.14 KB (1.86 million rows/s., 36.44 MB/s.)
이제 이 사용자가 새 배지를 받고 행이 하나 삽입되면, 해당 뷰가 업데이트됩니다:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 7.517 sec.
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'gingerwizard'
┌────────Day─┬──UserId─┬─DisplayName──┬─Gold─┬─Silver─┬─Bronze─┐
│ 2013-10-30 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2013-11-18 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-27 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-02-28 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-04-17 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2023-10-31 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2024-03-04 │ 2936484 │ gingerwizard │ 0 │ 1 │ 0 │
│ 2024-03-05 │ 2936484 │ gingerwizard │ 0 │ 0 │ 1 │
│ 2025-04-13 │ 2936484 │ gingerwizard │ 1 │ 0 │ 0 │
└────────────┴─────────┴──────────────┴──────┴────────┴────────┘
9 rows in set. Elapsed: 0.017 sec. Processed 32.77 thousand rows, 642.27 KB (1.96 million rows/s., 38.50 MB/s.)
참고
여기에서 insert 작업의 지연 시간을 확인하십시오. 삽입된 user 행을 전체 users 테이블과 조인하기 때문에 insert 성능에 큰 영향을 미칩니다. 이에 대한 대응 방법은 아래의 "필터와 조인에서 source 테이블 사용하기"에서 설명합니다.
반대로 새 user에 대한 badge를 먼저 insert한 다음 해당 user 행을 insert하면, materialized view는 해당 사용자의 메트릭을 캡처하지 못합니다.
INSERT INTO badges VALUES (53505059, 23923286, 'Good Answer', now(), 'Bronze', 0);
INSERT INTO users VALUES (23923286, 1, now(), 'brand_new_user', now(), 'UK', 1, 1, 0);
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'brand_new_user';
0 rows in set. Elapsed: 0.017 sec. Processed 32.77 thousand rows, 644.32 KB (1.98 million rows/s., 38.94 MB/s.)
이 경우 뷰는 사용자 행이 존재하기 전에 수행되는 배지 삽입에 대해서만 실행됩니다. 이후 해당 사용자에 대해 배지를 하나 더 삽입하면, 기대한 대로 행이 삽입됩니다.
INSERT INTO badges VALUES (53505060, 23923286, 'Teacher', now(), 'Bronze', 0);
SELECT *
FROM daily_badges_by_user
FINAL
WHERE DisplayName = 'brand_new_user'
┌────────Day─┬───UserId─┬─DisplayName────┬─Gold─┬─Silver─┬─Bronze─┐
│ 2025-04-13 │ 23923286 │ brand_new_user │ 0 │ 0 │ 1 │
└────────────┴──────────┴────────────────┴──────┴────────┴────────┘
1 row in set. Elapsed: 0.018 sec. Processed 32.77 thousand rows, 644.48 KB (1.87 million rows/s., 36.72 MB/s.)
단, 이 결과는 올바르지 않습니다.
materialized view에서 JOIN 사용 시 모범 사례
-
가장 왼쪽 테이블을 트리거로 사용합니다. SELECT 문에서 왼쪽에 있는 테이블만 materialized view의 갱신을 트리거합니다. 오른쪽 테이블의 변경 사항은 업데이트를 트리거하지 않습니다.
-
조인 대상 데이터를 먼저 삽입합니다. 소스 테이블에 행을 삽입하기 전에 조인되는 테이블의 데이터가 먼저 존재하도록 해야 합니다. JOIN은 삽입 시점에 평가되므로, 필요한 데이터가 없으면 일치하지 않는 행이나 NULL이 발생합니다.
-
조인에서 가져오는 컬럼 수를 제한합니다. 메모리 사용량을 최소화하고 삽입 시점 지연 시간을 줄이기 위해, 조인된 테이블에서 필요한 컬럼만 선택합니다(아래 참조).
-
삽입 시점 성능을 평가합니다. JOIN은 특히 오른쪽 테이블이 큰 경우 삽입 비용을 증가시킵니다. 실제 운영 환경을 잘 대표하는 데이터로 삽입 속도를 벤치마크하십시오.
-
단순 조회에는 딕셔너리를 선호합니다. 비용이 큰 JOIN 연산을 피하기 위해, 키-값 조회(예: user ID → name)에는 Dictionaries를 사용합니다.
-
병합 효율을 위해 GROUP BY와 ORDER BY를 맞춥니다. SummingMergeTree 또는 AggregatingMergeTree를 사용하는 경우, 대상 테이블에서 효율적인 행 병합이 가능하도록 GROUP BY가 ORDER BY 절과 일치하도록 합니다.
-
명시적인 컬럼 별칭을 사용합니다. 테이블에 겹치는 컬럼 이름이 있는 경우, 별칭을 사용하여 모호성을 방지하고 대상 테이블에서 올바른 결과를 보장합니다.
-
삽입량과 빈도를 고려합니다. JOIN은 적당한 수준의 삽입 워크로드에 적합합니다. 고처리량 수집이 필요한 경우, 스테이징 테이블, 사전 조인(pre-join), Dictionaries 및 갱신 가능 구체화 뷰(Refreshable Materialized Views)와 같은 다른 접근 방식을 고려하십시오.
필터와 조인에서 소스 테이블 사용하기
ClickHouse에서 구체화된 뷰(Materialized View)를 사용할 때에는 해당 뷰의 쿼리가 실행되는 동안 소스 테이블이 어떻게 처리되는지 이해하는 것이 중요합니다. 구체적으로, 구체화된 뷰의 쿼리에서 소스 테이블은 삽입된 데이터 블록으로 간주되어, 그 데이터 블록으로 대체됩니다. 이러한 동작을 제대로 이해하지 못하면 예기치 않은 결과가 발생할 수 있습니다.
예시 시나리오
다음과 같은 구성을 가정합니다:
CREATE TABLE t0 (`c0` Int) ENGINE = Memory;
CREATE TABLE mvw1_inner (`c0` Int) ENGINE = Memory;
CREATE TABLE mvw2_inner (`c0` Int) ENGINE = Memory;
CREATE VIEW vt0 AS SELECT * FROM t0;
CREATE MATERIALIZED VIEW mvw1 TO mvw1_inner
AS SELECT count(*) AS c0
FROM t0
LEFT JOIN ( SELECT * FROM t0 ) AS x ON t0.c0 = x.c0;
CREATE MATERIALIZED VIEW mvw2 TO mvw2_inner
AS SELECT count(*) AS c0
FROM t0
LEFT JOIN vt0 ON t0.c0 = vt0.c0;
INSERT INTO t0 VALUES (1),(2),(3);
INSERT INTO t0 VALUES (1),(2),(3),(4),(5);
SELECT * FROM mvw1;
┌─c0─┐
│ 3 │
│ 5 │
└────┘
SELECT * FROM mvw2;
┌─c0─┐
│ 3 │
│ 8 │
└────┘
Explanation
위 예제에서 두 개의 materialized view인 mvw1과 mvw2가 있으며, 둘 다 유사한 작업을 수행하지만 소스 테이블 t0를 참조하는 방식에 약간의 차이가 있습니다.
mvw1에서는 테이블 t0가 JOIN의 오른쪽에 있는 (SELECT * FROM t0) 서브쿼리 안에서 직접 참조됩니다. t0에 데이터가 삽입될 때 materialized view의 쿼리가 실행되며, 이때 t0는 삽입된 데이터 블록으로 대체됩니다. 이는 JOIN 연산이 전체 테이블이 아니라 새로 삽입된 행에 대해서만 수행된다는 의미입니다.
두 번째 경우인 vt0와의 JOIN에서는, 이 view가 t0의 모든 데이터를 읽습니다. 이렇게 하면 JOIN 연산이 새로 삽입된 블록만이 아니라 t0의 모든 행을 고려하도록 보장됩니다.
핵심 차이는 ClickHouse가 materialized view의 쿼리에서 소스 테이블을 처리하는 방식에 있습니다. materialized view가 insert에 의해 트리거될 때, 소스 테이블(이 예제에서는 t0)은 삽입된 데이터 블록으로 대체됩니다. 이 동작은 쿼리를 최적화하는 데 활용할 수 있지만, 예기치 않은 결과를 피하려면 주의 깊은 고려가 필요합니다.
사용 사례와 주의 사항
실무에서는 이 동작을 활용하여 소스 테이블 데이터의 일부만 처리하면 되는 materialized view를 최적화할 수 있습니다. 예를 들어, 다른 테이블과 조인하기 전에 서브쿼리를 사용해 소스 테이블을 필터링할 수 있습니다. 이렇게 하면 materialized view가 처리해야 하는 데이터 양을 줄이고 성능을 향상하는 데 도움이 됩니다.
CREATE TABLE t0 (id UInt32, value String) ENGINE = MergeTree() ORDER BY id;
CREATE TABLE t1 (id UInt32, description String) ENGINE = MergeTree() ORDER BY id;
INSERT INTO t1 VALUES (1, 'A'), (2, 'B'), (3, 'C');
CREATE TABLE mvw1_target_table (id UInt32, value String, description String) ENGINE = MergeTree() ORDER BY id;
CREATE MATERIALIZED VIEW mvw1 TO mvw1_target_table AS
SELECT t0.id, t0.value, t1.description
FROM t0
JOIN (SELECT * FROM t1 WHERE t1.id IN (SELECT id FROM t0)) AS t1
ON t0.id = t1.id;
이 예제에서 IN (SELECT id FROM t0) 서브쿼리로부터 만들어진 Set에는 새로 삽입된 행만 포함되며, 이를 활용하면 t1을 이 Set과 비교하여 필터링할 수 있습니다.
Stack Overflow 예시
users 테이블의 사용자 표시 이름을 포함하여 사용자별 일일 배지를 계산하는, 앞서 살펴본 materialized view 예시를 다시 고려합니다.
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user
AS SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN users AS u ON b.UserId = u.Id
GROUP BY Day, b.UserId, u.DisplayName;
이 VIEW는 예를 들어 badges 테이블의 삽입 지연 시간(insert latency)에 상당한 영향을 주었습니다.
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 7.517 sec.
위에서 설명한 접근 방식을 사용하여 이 뷰를 최적화할 수 있습니다. 삽입된 배지 행의 사용자 ID를 사용하여 users 테이블에 필터를 추가합니다:
CREATE MATERIALIZED VIEW daily_badges_by_user_mv TO daily_badges_by_user
AS SELECT
toDate(Date) AS Day,
b.UserId,
u.DisplayName,
countIf(Class = 'Gold') AS Gold,
countIf(Class = 'Silver') AS Silver,
countIf(Class = 'Bronze') AS Bronze
FROM badges AS b
LEFT JOIN
(
SELECT
Id,
DisplayName
FROM users
WHERE Id IN (
SELECT UserId
FROM badges
)
) AS u ON b.UserId = u.Id
GROUP BY
Day,
b.UserId,
u.DisplayName
이는 초기 badges INSERT 작업을 더 빠르게 할 뿐만 아니라:
INSERT INTO badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
0 rows in set. Elapsed: 132.118 sec. Processed 323.43 million rows, 4.69 GB (2.45 million rows/s., 35.49 MB/s.)
Peak memory usage: 1.99 GiB.
또한 이는 향후 badge를 삽입하는 작업도 효율적으로 수행된다는 의미입니다:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
1 row in set. Elapsed: 0.583 sec.
위 연산에서는 사용자 ID 2936484에 대해 users 테이블에서 단 하나의 행만 조회됩니다. 이 조회 역시 테이블 정렬 키인 Id로 최적화됩니다.
materialized view와 UNION
UNION ALL 쿼리는 여러 소스 테이블의 데이터를 하나의 결과 집합으로 결합할 때 흔히 사용됩니다.
UNION ALL은 증분형 materialized view에서 직접 지원되지는 않지만, 각 SELECT 분기마다 별도의 materialized view를 생성하고 그 결과를 공통 대상 테이블에 기록하도록 설정하면 동일한 효과를 얻을 수 있습니다.
예제로 Stack Overflow 데이터셋을 사용합니다. 아래의 badges 및 comments 테이블은 각각 사용자가 획득한 배지와 게시물에 남긴 댓글을 나타냅니다.
CREATE TABLE stackoverflow.comments
(
`Id` UInt32,
`PostId` UInt32,
`Score` UInt16,
`Text` String,
`CreationDate` DateTime64(3, 'UTC'),
`UserId` Int32,
`UserDisplayName` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY CreationDate
CREATE TABLE stackoverflow.badges
(
`Id` UInt32,
`UserId` Int32,
`Name` LowCardinality(String),
`Date` DateTime64(3, 'UTC'),
`Class` Enum8('Gold' = 1, 'Silver' = 2, 'Bronze' = 3),
`TagBased` Bool
)
ENGINE = MergeTree
ORDER BY UserId
다음 INSERT INTO 명령으로 채울 수 있습니다:
INSERT INTO stackoverflow.badges SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/badges.parquet')
INSERT INTO stackoverflow.comments SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/comments/*.parquet')
두 테이블을 결합해 각 사용자별 마지막 활동을 보여주는 통합 사용자 활동 뷰를 만들고자 한다고 가정해 보겠습니다.
SELECT
UserId,
argMax(description, event_time) AS last_description,
argMax(activity_type, event_time) AS activity_type,
max(event_time) AS last_activity
FROM
(
SELECT
UserId,
CreationDate AS event_time,
Text AS description,
'comment' AS activity_type
FROM stackoverflow.comments
UNION ALL
SELECT
UserId,
Date AS event_time,
Name AS description,
'badge' AS activity_type
FROM stackoverflow.badges
)
GROUP BY UserId
ORDER BY last_activity DESC
LIMIT 10
이 쿼리 결과를 받을 대상 테이블이 있다고 가정합니다. 결과가 올바르게 병합되도록 AggregatingMergeTree 테이블 엔진과 AggregateFunction을 사용한다는 점에 유의하십시오.
CREATE TABLE user_activity
(
`UserId` String,
`last_description` AggregateFunction(argMax, String, DateTime64(3, 'UTC')),
`activity_type` AggregateFunction(argMax, String, DateTime64(3, 'UTC')),
`last_activity` SimpleAggregateFunction(max, DateTime64(3, 'UTC'))
)
ENGINE = AggregatingMergeTree
ORDER BY UserId
badges 또는 comments에 새 행이 삽입될 때마다 이 테이블이 업데이트되도록 하고 싶다면, 이 문제에 대한 순진한(naive) 접근 방식으로 앞서의 union 쿼리를 사용해 materialized view를 생성해 보려 할 수 있습니다:
CREATE MATERIALIZED VIEW user_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(description, event_time) AS last_description,
argMaxState(activity_type, event_time) AS activity_type,
max(event_time) AS last_activity
FROM
(
SELECT
UserId,
CreationDate AS event_time,
Text AS description,
'comment' AS activity_type
FROM stackoverflow.comments
UNION ALL
SELECT
UserId,
Date AS event_time,
Name AS description,
'badge' AS activity_type
FROM stackoverflow.badges
)
GROUP BY UserId
ORDER BY last_activity DESC
문법적으로는 올바르지만 의도하지 않은 결과를 만들어냅니다. 이 뷰는 comments 테이블로의 INSERT에 대해서만 동작합니다. 예를 들어 다음과 같습니다.
INSERT INTO comments VALUES (99999999, 23121, 1, 'The answer is 42', now(), 2936484, 'gingerwizard');
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 09:56:19.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.005 sec.
badges 테이블에 대한 INSERT 작업은 뷰를 트리거하지 않으므로 user_activity는 업데이트되지 않습니다:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId;
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 09:56:19.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.005 sec.
이 문제를 해결하기 위해 각 SELECT 문에 대해 materialized view를 하나씩 간단히 생성하면 됩니다.
DROP TABLE user_activity_mv;
TRUNCATE TABLE user_activity;
CREATE MATERIALIZED VIEW comment_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(Text, CreationDate) AS last_description,
argMaxState('comment', CreationDate) AS activity_type,
max(CreationDate) AS last_activity
FROM stackoverflow.comments
GROUP BY UserId;
CREATE MATERIALIZED VIEW badges_activity_mv TO user_activity AS
SELECT
UserId,
argMaxState(Name, Date) AS last_description,
argMaxState('badge', Date) AS activity_type,
max(Date) AS last_activity
FROM stackoverflow.badges
GROUP BY UserId;
이제 두 테이블 중 어느 쪽에 데이터를 삽입하더라도 올바른 결과를 얻을 수 있습니다. 예를 들어 comments 테이블에 데이터를 삽입하면 다음과 같습니다.
INSERT INTO comments VALUES (99999999, 23121, 1, 'The answer is 42', now(), 2936484, 'gingerwizard');
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId;
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ The answer is 42 │ comment │ 2025-04-15 10:18:47.000 │
└─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.006 sec.
마찬가지로 badges 테이블에 대한 INSERT는 user_activity 테이블에도 반영됩니다:
INSERT INTO badges VALUES (53505058, 2936484, 'gingerwizard', now(), 'Gold', 0);
SELECT
UserId,
argMaxMerge(last_description) AS description,
argMaxMerge(activity_type) AS activity_type,
max(last_activity) AS last_activity
FROM user_activity
WHERE UserId = '2936484'
GROUP BY UserId
┌─UserId──┬─description──┬─activity_type─┬───────────last_activity─┐
│ 2936484 │ gingerwizard │ badge │ 2025-04-15 10:20:18.000 │
└─────────┴──────────────┴───────────────┴─────────────────────────┘
1 row in set. Elapsed: 0.006 sec.
병렬 처리 vs 순차 처리
이전 예제에서 보여드린 것처럼, 하나의 테이블은 여러 materialized view의 소스로 사용될 수 있습니다. 이러한 뷰들이 실행되는 순서는 parallel_view_processing 설정에 따라 결정됩니다.
기본적으로 이 설정 값은 0 (false)이며, 이는 materialized view가 uuid 순서로 순차적으로 실행된다는 것을 의미합니다.
예를 들어, 다음과 같은 source 테이블과 3개의 Materialized View가 있으며, 각 뷰는 target 테이블로 행을 전송합니다:
CREATE TABLE source
(
`message` String
)
ENGINE = MergeTree
ORDER BY tuple();
CREATE TABLE target
(
`message` String,
`from` String,
`now` DateTime64(9),
`sleep` UInt8
)
ENGINE = MergeTree
ORDER BY tuple();
CREATE MATERIALIZED VIEW mv_2 TO target
AS SELECT
message,
'mv2' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
CREATE MATERIALIZED VIEW mv_3 TO target
AS SELECT
message,
'mv3' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
CREATE MATERIALIZED VIEW mv_1 TO target
AS SELECT
message,
'mv1' AS from,
now64(9) as now,
sleep(1) as sleep
FROM source;
각 뷰가 target 테이블에 행을 삽입하기 전에 1초 동안 일시 중지하며, 뷰 이름과 삽입 시간도 함께 포함한다는 점을 확인하십시오.
source 테이블에 행을 삽입하는 데 약 3초가 소요되며, 각 뷰가 순차적으로 실행됩니다:
INSERT INTO source VALUES ('test')
1 row in set. Elapsed: 3.786 sec.
SELECT를 사용하여 각 행의 도착을 확인할 수 있습니다:
SELECT
message,
from,
now
FROM target
ORDER BY now ASC
┌─message─┬─from─┬───────────────────────────now─┐
│ test │ mv3 │ 2025-04-15 14:52:01.306162309 │
│ test │ mv1 │ 2025-04-15 14:52:02.307693521 │
│ test │ mv2 │ 2025-04-15 14:52:03.309250283 │
└─────────┴──────┴───────────────────────────────┘
3 rows in set. Elapsed: 0.015 sec.
이는 뷰(View)의 uuid와 일치합니다:
SELECT
name,
uuid
FROM system.tables
WHERE name IN ('mv_1', 'mv_2', 'mv_3')
ORDER BY uuid ASC
┌─name─┬─uuid─────────────────────────────────┐
│ mv_3 │ ba5e36d0-fa9e-4fe8-8f8c-bc4f72324111 │
│ mv_1 │ b961c3ac-5a0e-4117-ab71-baa585824d43 │
│ mv_2 │ e611cc31-70e5-499b-adcc-53fb12b109f5 │
└──────┴──────────────────────────────────────┘
3 rows in set. Elapsed: 0.004 sec.
반대로, parallel_view_processing=1을 활성화한 상태에서 행을 삽입할 경우 어떤 일이 발생하는지 살펴보겠습니다. 이 설정을 활성화하면 뷰가 병렬로 실행되며, 대상 테이블에 행이 도착하는 순서는 보장되지 않습니다:
TRUNCATE target;
SET parallel_view_processing = 1;
INSERT INTO source VALUES ('test');
1 row in set. Elapsed: 1.588 sec.
SELECT
message,
from,
now
FROM target
ORDER BY now ASC
┌─message─┬─from─┬───────────────────────────now─┐
│ test │ mv3 │ 2025-04-15 19:47:32.242937372 │
│ test │ mv1 │ 2025-04-15 19:47:32.243058183 │
│ test │ mv2 │ 2025-04-15 19:47:32.337921800 │
└─────────┴──────┴───────────────────────────────┘
3 rows in set. Elapsed: 0.004 sec.
각 뷰에서 도착하는 행의 순서가 동일하지만, 이는 보장되지 않습니다. 각 행의 삽입 시간이 유사한 것으로 이를 확인할 수 있습니다. 또한 삽입 성능이 향상된 것을 확인할 수 있습니다.
병렬 처리를 사용할 때
parallel_view_processing=1을 활성화하면, 특히 여러 Materialized View가 하나의 테이블에 연결되어 있는 경우 위에서 보듯 삽입 처리량이 크게 향상될 수 있습니다. 다만 다음과 같은 트레이드오프를 이해하는 것이 중요합니다.
- 삽입 부하 증가: 모든 Materialized View가 동시에 실행되어 CPU와 메모리 사용량이 증가합니다. 각 뷰가 무거운 연산이나 조인을 수행하는 경우 시스템이 과부하 상태가 될 수 있습니다.
- 엄격한 실행 순서 필요: 뷰 실행 순서가 중요한 워크플로(예: 체인 형태의 의존성)에서는 병렬 실행으로 인해 상태 불일치나 경쟁 조건이 발생할 수 있습니다. 이를 피하도록 설계하는 것은 가능하지만, 이러한 구성은 취약하며 향후 버전에서 동작이 깨질 수 있습니다.
Historical defaults and stability
순차 실행은 오랜 기간 기본값이었는데, 이는 부분적으로 오류 처리의 복잡성 때문입니다. 과거에는 하나의 materialized view에서 오류가 발생하면 다른 뷰의 실행도 차단될 수 있었습니다. 최신 버전에서는 블록 단위로 오류를 격리하여 이 문제를 개선했지만, 순차 실행이 여전히 오류 발생 시 동작을 더 명확하게 해 줍니다.
일반적으로 다음과 같은 경우 parallel_view_processing=1을 활성화하십시오.
- 서로 독립적인 여러 Materialized View가 있는 경우
- 삽입 성능을 최대화하려는 경우
- 동시 뷰 실행을 처리할 수 있는 시스템 용량을 충분히 파악하고 있는 경우
다음과 같은 경우에는 비활성화 상태로 유지하십시오.
- Materialized View 간에 상호 의존성이 있는 경우
- 예측 가능하고 순차적인 실행이 필요한 경우
- 삽입 동작을 디버깅하거나 감사해야 하며, 결정적인 재실행이 필요한 경우
materialized view와 공통 테이블 표현식(CTE)
비재귀 공통 테이블 표현식(CTE)는 materialized view에서 지원됩니다.
참고
공통 테이블 표현식은 구체화되지 않습니다ClickHouse는 CTE를 구체화하지 않고, 대신 CTE 정의를 쿼리 본문에 직접 대체합니다. 이 때문에 동일한 표현식이 여러 번 평가될 수 있습니다(CTE가 두 번 이상 사용되는 경우).
각 게시물 유형별 일별 활동량을 계산하는 다음 예제를 살펴보십시오.
CREATE TABLE daily_post_activity
(
Day Date,
PostType String,
PostsCreated SimpleAggregateFunction(sum, UInt64),
AvgScore AggregateFunction(avg, Int32),
TotalViews SimpleAggregateFunction(sum, UInt64)
)
ENGINE = AggregatingMergeTree
ORDER BY (Day, PostType);
CREATE MATERIALIZED VIEW daily_post_activity_mv TO daily_post_activity AS
WITH filtered_posts AS (
SELECT
toDate(CreationDate) AS Day,
PostTypeId,
Score,
ViewCount
FROM posts
WHERE Score > 0 AND PostTypeId IN (1, 2) -- Question or Answer
)
SELECT
Day,
CASE PostTypeId
WHEN 1 THEN 'Question'
WHEN 2 THEN 'Answer'
END AS PostType,
count() AS PostsCreated,
avgState(Score) AS AvgScore,
sum(ViewCount) AS TotalViews
FROM filtered_posts
GROUP BY Day, PostTypeId;
이 예제에서는 CTE가 엄밀히 말해 꼭 필요하지는 않지만, 예시를 위해 사용하면 VIEW는 의도한 대로 동작합니다:
INSERT INTO posts
SELECT *
FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/by_month/*.parquet')
SELECT
Day,
PostType,
avgMerge(AvgScore) AS AvgScore,
sum(PostsCreated) AS PostsCreated,
sum(TotalViews) AS TotalViews
FROM daily_post_activity
GROUP BY
Day,
PostType
ORDER BY Day DESC
LIMIT 10
┌────────Day─┬─PostType─┬───────────AvgScore─┬─PostsCreated─┬─TotalViews─┐
│ 2024-03-31 │ Question │ 1.3317757009345794 │ 214 │ 9728 │
│ 2024-03-31 │ Answer │ 1.4747191011235956 │ 356 │ 0 │
│ 2024-03-30 │ Answer │ 1.4587912087912087 │ 364 │ 0 │
│ 2024-03-30 │ Question │ 1.2748815165876777 │ 211 │ 9606 │
│ 2024-03-29 │ Question │ 1.2641509433962264 │ 318 │ 14552 │
│ 2024-03-29 │ Answer │ 1.4706927175843694 │ 563 │ 0 │
│ 2024-03-28 │ Answer │ 1.601637107776262 │ 733 │ 0 │
│ 2024-03-28 │ Question │ 1.3530864197530865 │ 405 │ 24564 │
│ 2024-03-27 │ Question │ 1.3225806451612903 │ 434 │ 21346 │
│ 2024-03-27 │ Answer │ 1.4907539118065434 │ 703 │ 0 │
└────────────┴──────────┴────────────────────┴──────────────┴────────────┘
10 rows in set. Elapsed: 0.013 sec. Processed 11.45 thousand rows, 663.87 KB (866.53 thousand rows/s., 50.26 MB/s.)
Peak memory usage: 989.53 KiB.
ClickHouse에서 CTE는 인라인 처리되므로 최적화 과정에서 쿼리에 사실상 복사해 붙여넣은 것처럼 되며, 별도의 결과로 materialized되지 않습니다. 이는 다음을 의미합니다:
- CTE가 소스 테이블(즉, materialized view가 연결된 테이블)과 다른 테이블을 참조하고
JOIN 또는 IN 절에서 사용되는 경우, 트리거가 아니라 서브쿼리 또는 조인처럼 동작합니다.
- materialized view는 여전히 기본 소스 테이블로의 INSERT에 대해서만 트리거되지만, CTE는 INSERT가 발생할 때마다 다시 실행되며, 특히 참조되는 테이블이 큰 경우 불필요한 오버헤드를 유발할 수 있습니다.
예를 들어,
WITH recent_users AS (
SELECT Id FROM stackoverflow.users WHERE CreationDate > now() - INTERVAL 7 DAY
)
SELECT * FROM stackoverflow.posts WHERE OwnerUserId IN (SELECT Id FROM recent_users)
이 경우 users CTE는 posts에 행이 삽입될 때마다 다시 평가되며, materialized view는 새로운 users가 삽입될 때가 아니라 posts가 삽입될 때에만 업데이트됩니다.
일반적으로, materialized view가 연결된 동일한 소스 테이블에서 동작하는 로직에 CTE를 사용하거나, 참조되는 테이블이 작고 성능 병목을 유발할 가능성이 낮은지 확인해야 합니다. 또는 materialized view에서 JOIN을 사용할 때와 동일한 최적화를 고려하십시오.