데이터 수집을 위한 OpenTelemetry 통합
모든 관측성(Observability) 솔루션에는 로그와 트레이스를 수집하고 내보내는 수단이 필요합니다. 이러한 목적을 위해 ClickHouse는 OpenTelemetry (OTel) 프로젝트를 권장합니다.
「OpenTelemetry는 트레이스, 메트릭, 로그와 같은 텔레메트리 데이터를 생성하고 관리하도록 설계된 관측성(Observability) 프레임워크이자 툴킷입니다.」
ClickHouse나 Prometheus와 달리 OpenTelemetry는 관측성 백엔드가 아니며, 텔레메트리 데이터의 생성, 수집, 관리, 내보내기에 중점을 둡니다. OpenTelemetry의 초기 목표는 언어별 SDKs를 사용하여 애플리케이션이나 시스템을 손쉽게 계측할 수 있도록 하는 것이었으나, 이후 텔레메트리 데이터를 수신·처리·내보내는 에이전트이자 프록시인 OpenTelemetry collector를 통해 로그 수집까지 포함하도록 확장되었습니다.
ClickHouse relevant components
OpenTelemetry는 여러 구성 요소로 구성됩니다. 데이터 및 API 사양, 표준화된 프로토콜, 필드/컬럼에 대한 명명 규칙을 제공할 뿐만 아니라, ClickHouse로 관측성 솔루션을 구축하는 데 근간이 되는 두 가지 기능을 추가로 제공합니다:
- OpenTelemetry Collector는 텔레메트리 데이터를 수신, 처리, 내보내는 프록시입니다. ClickHouse 기반 솔루션에서는 이 컴포넌트를 사용하여 로그를 수집하고 이벤트를 처리한 다음, 배치한 후 삽입하는 데 사용합니다.
- 명세, API, 텔레메트리 데이터 내보내기를 구현하는 Language SDKs입니다. 이러한 SDK는 애플리케이션 코드 내에서 트레이스가 올바르게 기록되도록 보장하며, 개별 스팬을 생성하고 메타데이터를 통해 서비스 간에 컨텍스트가 전파되도록 함으로써 분산 트레이스를 구성하고 스팬이 서로 연관될 수 있도록 합니다. 또한 이러한 SDK는 공통 라이브러리 및 프레임워크를 자동으로 계측하는 생태계의 지원을 받으므로, 사용자가 코드를 변경할 필요 없이 바로 계측을 사용할 수 있습니다.
ClickHouse 기반 관측성 솔루션은 이 두 도구를 모두 활용합니다.
배포판
OpenTelemetry collector에는 여러 배포판이 있습니다. ClickHouse 솔루션에 필요한 filelog receiver와 ClickHouse exporter는 OpenTelemetry Collector Contrib Distro에만 포함되어 있습니다.
이 배포판에는 많은 컴포넌트가 포함되어 있어 다양한 구성으로 실험할 수 있습니다. 그러나 프로덕션 환경에서 실행할 때는 해당 환경에 필요한 컴포넌트만 포함하도록 collector를 제한하는 것이 좋습니다. 이렇게 하는 이유는 다음과 같습니다.
- collector 크기를 줄여 배포 시간을 단축합니다.
- 사용 가능한 공격 표면을 줄여 collector의 보안을 강화합니다.
커스텀 collector는 OpenTelemetry Collector Builder를 사용하여 빌드할 수 있습니다.
OTel을 사용한 데이터 수집
Collector deployment roles
로그를 수집하여 ClickHouse에 적재하기 위해 OpenTelemetry Collector 사용을 권장합니다. OpenTelemetry Collector는 주로 두 가지 역할로 배포할 수 있습니다:
- Agent - Agent 인스턴스는 서버나 Kubernetes 노드와 같은 엣지에서 데이터를 수집하거나, OpenTelemetry SDK로 계측된 애플리케이션으로부터 직접 이벤트를 수신합니다. 후자의 경우, Agent 인스턴스는 애플리케이션과 함께 또는 애플리케이션과 동일한 호스트(예: 사이드카 또는 데몬셋)에서 실행됩니다. Agent는 수집한 데이터를 직접 ClickHouse로 전송하거나 게이트웨이 인스턴스로 전송할 수 있습니다. 전자의 경우 이를 Agent deployment pattern이라고 합니다.
- Gateway - Gateway 인스턴스는 독립 실행형 서비스(예: Kubernetes의 배포)로 제공되며, 일반적으로 클러스터당, 데이터 센터당, 리전당 하나씩 구성합니다. 이 인스턴스들은 단일 OTLP 엔드포인트를 통해 애플리케이션(또는 Agent 역할을 하는 다른 Collector)으로부터 이벤트를 수신합니다. 일반적으로 여러 Gateway 인스턴스를 배포하고, 기본 제공 로드 밸런서를 사용하여 이들 사이에 부하를 분산합니다. 모든 Agent와 애플리케이션이 이 단일 엔드포인트로 시그널을 전송하는 경우, 이를 Gateway deployment pattern이라고 부릅니다.
아래 내용에서는 간단한 Agent Collector가 이벤트를 직접 ClickHouse로 전송하는 구성을 가정합니다. 게이트웨이 사용 방법과 적용 시점에 대한 자세한 내용은 Scaling with Gateways를 참조하십시오.
로그 수집
Collector를 사용하면 서비스가 데이터를 빠르게 전송한 뒤, Collector가 재시도, 배치 처리, 암호화, 민감한 데이터 필터링과 같은 추가 처리를 담당하도록 할 수 있다는 점이 가장 큰 장점입니다.
Collector는 세 가지 주요 처리 단계에 대해 receiver, processor, exporter라는 용어를 사용합니다. Receiver는 데이터 수집에 사용되며 pull 또는 push 방식 모두 가능합니다. Processor는 메시지를 변환하고 정보를 보강하는 기능을 제공합니다. Exporter는 데이터를 다운스트림 서비스로 전송하는 역할을 담당합니다. 이 서비스는 이론적으로 또 다른 Collector일 수 있지만, 아래 초기 설명에서는 모든 데이터가 직접 ClickHouse로 전송된다고 가정합니다.
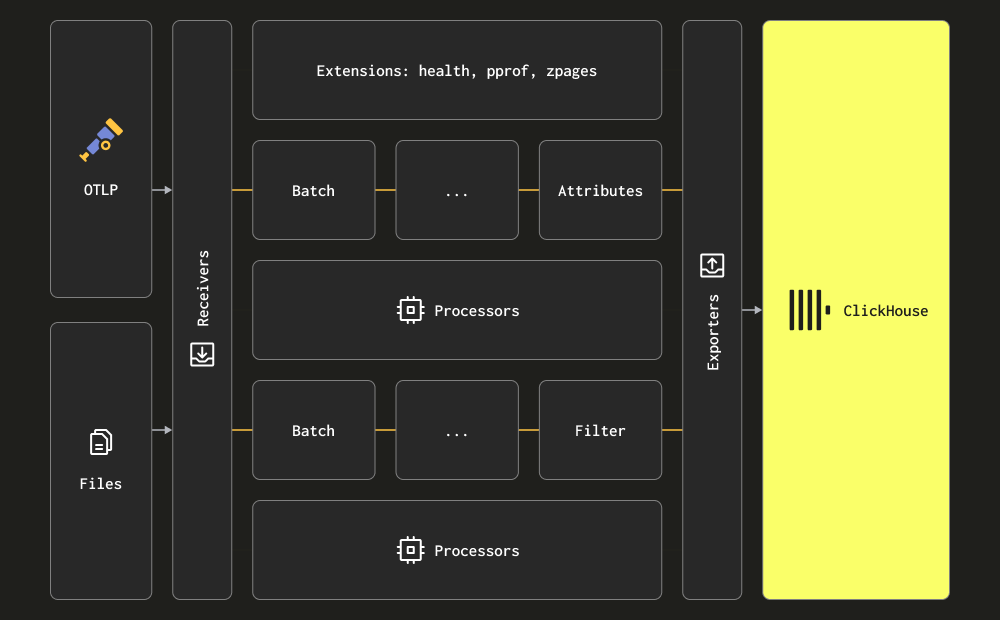
receiver, processor, exporter 전체 구성 요소와 종류를 충분히 숙지하는 것이 좋습니다.
Collector는 로그 수집을 위해 두 가지 주요 receiver를 제공합니다.
OTLP를 통한 수집 - 이 경우, 로그는 OpenTelemetry SDK에서 OTLP 프로토콜을 통해 Collector로 직접(푸시 방식으로) 전송됩니다. OpenTelemetry demo는 이 방식을 사용하며, 각 언어의 OTLP exporter는 로컬 Collector 엔드포인트를 가정합니다. 이 경우 Collector는 OTLP receiver로 구성되어야 합니다. 구성 예시는 위 데모 구성을 참고하십시오. 이 방식의 장점은 로그 데이터에 Trace ID가 자동으로 포함되어, 이후 특정 로그에 대한 트레이스를 식별하고 그 반대 방향의 추적도 가능하다는 점입니다.
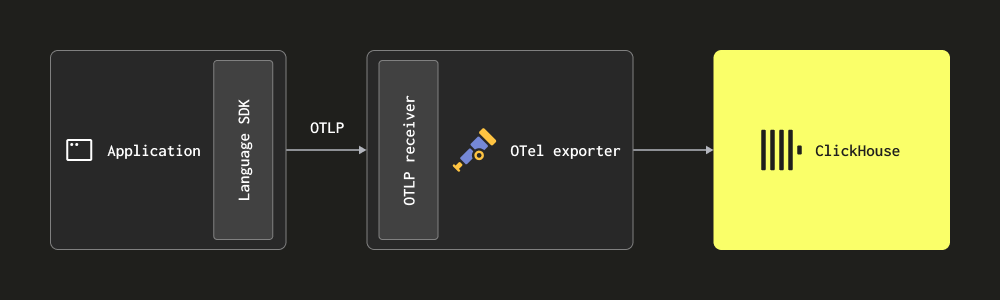
이 방식에서는 해당 언어 SDK를 사용해 코드를 계측해야 합니다.
- Filelog receiver를 통한 스크레이핑 - 이 receiver는 디스크상의 파일을 tail링하여 로그 메시지를 구성하고, 이를 ClickHouse로 전송합니다. 이 receiver는 여러 줄에 걸친 메시지 감지, 로그 롤오버 처리, 재시작에 대한 내구성을 위한 체크포인팅, 구조 추출 등 복잡한 작업을 처리합니다. 추가로, 이 receiver는 Docker 및 Kubernetes 컨테이너 로그도 tail할 수 있으며, Helm 차트로 배포하여 이들로부터 구조를 추출하고 파드 세부 정보로 로그를 보강할 수 있습니다.
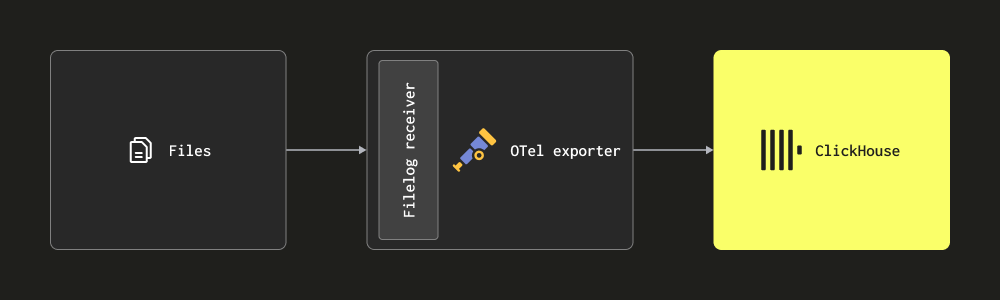
대부분의 배포 환경에서는 위 receiver들을 조합하여 사용합니다. collector 문서를 읽고 기본 개념과 함께 구성 구조, 설치 방법을 충분히 숙지할 것을 권장합니다.
구조화 로그와 비구조화 로그
로그는 구조화되거나 비구조화될 수 있습니다.
구조화 로그는 JSON과 같은 데이터 형식을 사용하여 HTTP 코드, 출발지 IP 주소와 같은 메타데이터 필드를 정의합니다.
비구조화 로그는 보통 정규식 패턴을 통해 추출할 수 있는 어느 정도의 내재된 구조를 갖고 있기도 하지만, 로그 자체는 단일 문자열로만 표현됩니다.
가능한 경우 구조화된 로깅을 사용하고 로그를 JSON 형식(예: ndjson)으로 기록할 것을 권장합니다. 이렇게 하면 Collector processors를 사용해 ClickHouse로 전송하기 전이든, 삽입 시점에 materialized view를 사용하든 이후 로그 처리에 필요한 작업이 단순해집니다. 구조화된 로그를 사용하면 후속 처리에 필요한 리소스를 절감하여 ClickHouse 솔루션에서 필요한 CPU를 줄이는 데 도움이 됩니다.
예시
예시를 위해 각각 약 1,000만 행으로 구성된 구조화(JSON 형식) 및 비구조화 로그 데이터셋을 아래 링크에서 제공합니다:
아래 예제에서는 구조화된 데이터셋을 사용합니다. 이후 예제를 재현하려면 이 파일을 다운로드한 후 압축을 해제하십시오.
다음은 디스크에 있는 이 파일들을 filelog receiver를 사용해 읽고, 결과 메시지를 stdout으로 출력하는 OTel collector의 간단한 설정 예시입니다. 로그가 구조화되어 있으므로 json_parser operator를 사용합니다. access-structured.log 파일의 경로를 수정하십시오.
아래 예제는 로그에서 타임스탬프를 추출합니다. 이를 위해 전체 로그 한 줄을 JSON 문자열로 변환하여 결과를 LogAttributes에 넣는 json_parser operator가 필요합니다. 이는 계산 비용이 많이 들 수 있으며, ClickHouse에서 더 효율적으로 수행할 수 있습니다 - SQL로 구조 추출하기. 동일한 작업을 수행하기 위해 regex_parser를 사용하는 비구조화 로그 예시는 여기에서 확인할 수 있습니다.
공식 지침을 따라 로컬 환경에 collector를 설치할 수 있습니다. 이때 filelog receiver가 포함된 contrib 배포판을 사용하도록 지침을 조정해야 합니다. 예를 들어 otelcol_0.102.1_darwin_arm64.tar.gz 대신 otelcol-contrib_0.102.1_darwin_arm64.tar.gz를 다운로드해야 합니다. 릴리스는 여기에서 확인할 수 있습니다.
설치가 완료되면, OTel collector는 다음 명령으로 실행할 수 있습니다:
구조화된 로그를 사용한다고 가정하면, 출력되는 메시지는 다음과 같은 형태입니다:
위 예시는 OTel collector가 생성한 단일 로그 메시지를 나타냅니다. 이후 섹션에서 동일한 메시지를 ClickHouse로 수집합니다.
로그 메시지의 전체 스키마와, 다른 receiver를 사용하는 경우 존재할 수 있는 추가 컬럼에 대한 내용은 여기에 정리되어 있습니다. 이 스키마를 충분히 숙지할 것을 강력히 권장합니다.
여기서 핵심은 로그 라인 자체는 Body 필드 내 문자열로 유지되지만, json_parser 덕분에 JSON이 자동으로 추출되어 Attributes 필드에 저장된다는 점입니다. 동일한 operator를 사용하여 타임스탬프도 적절한 Timestamp 컬럼으로 추출합니다. OTel을 사용한 로그 처리에 대한 권장 사항은 Processing을 참조하십시오.
Operator는 로그 처리의 가장 기본 단위입니다. 각 operator는 파일에서 라인을 읽거나, 필드에서 JSON을 파싱하는 것과 같이 단일 책임을 수행합니다. 그런 다음 operator들을 파이프라인으로 연결하여 원하는 결과를 얻습니다.
위 메시지에는 TraceID 또는 SpanID 필드가 없습니다. 예를 들어 분산 트레이싱(distributed tracing)을 구현하여 해당 필드가 존재하는 경우, 위에서 보여 준 동일한 기법을 사용하여 JSON에서 이를 추출할 수 있습니다.
로컬 또는 Kubernetes 로그 파일을 수집해야 하는 사용자는 filelog receiver에 제공된 설정 옵션과, offsets, 멀티라인 로그 파싱 처리 방식을 숙지할 것을 권장합니다.
Kubernetes 로그 수집
Kubernetes 로그 수집을 위해 OpenTelemetry Kubernetes 가이드를 참고하는 것을 권장합니다. 파드 메타데이터로 로그와 메트릭을 보강하기 위해 Kubernetes Attributes Processor를 사용하는 것이 좋습니다. 이를 통해 예를 들어 라벨과 같은 동적 메타데이터를 생성하여 컬럼 ResourceAttributes에 저장할 수 있습니다. ClickHouse는 현재 이 컬럼에 Map(String, String) 타입을 사용합니다. 이 타입을 처리하고 최적화하는 방법에 대한 자세한 내용은 맵 사용 및 맵에서 추출을 참고하십시오.
트레이스 수집
코드를 계측하여 트레이스를 수집하려면 공식 OTel 문서를 따르는 것을 권장합니다.
이벤트를 ClickHouse로 전송하려면 적절한 receiver를 통해 OTLP 프로토콜로 트레이스 이벤트를 수신하는 OTel collector를 배포해야 합니다. OpenTelemetry 데모에서는 지원되는 각 언어를 계측하는 예시와 이벤트를 collector로 전송하는 방법을 제공합니다. 다음은 이벤트를 stdout으로 출력하는 적절한 collector 설정 예시입니다:
예제
트레이스는 반드시 OTLP를 통해 수신해야 하므로, 트레이스 데이터를 생성하는 데 telemetrygen 도구를 사용합니다. 설치 방법은 여기를 참고하십시오.
다음 구성은 OTLP receiver에서 트레이스 이벤트를 수신한 후 이를 표준 출력(stdout)으로 전송합니다.
다음과 같이 이 구성을 실행하십시오:
telemetrygen을 사용하여 트레이스 이벤트를 collector로 전송하십시오:`
이 작업을 수행하면 아래 예시와 유사한 trace 메시지가 stdout으로 출력됩니다:
위 내용은 OTel collector에서 생성된 단일 트레이스 메시지를 나타냅니다. 이후 섹션에서는 동일한 메시지를 ClickHouse로 수집합니다.
트레이스 메시지의 전체 스키마는 여기에서 확인할 수 있습니다. 이 스키마를 충분히 숙지해 둘 것을 강력히 권장합니다.
Processing - filtering, transforming and enriching
앞선 로그 이벤트의 타임스탬프를 설정하는 예에서 보았듯, 이벤트 메시지를 필터링하고 변환하며 추가 정보로 보강(enrichment)하고자 하는 경우가 거의 항상 발생합니다. 이는 OpenTelemetry의 여러 기능을 사용하여 수행할 수 있습니다:
-
Processors - Processor는 receivers가 수집한 데이터를 수정하거나 변환한 뒤 exporters로 전송하는 역할을 합니다. Processor는 collector 설정의
processors섹션에 구성된 순서대로 적용됩니다. 선택 사항이지만, 최소 구성은 일반적으로 권장됩니다. OTel collector를 ClickHouse와 함께 사용할 때는 Processor를 다음으로 제한할 것을 권장합니다:- memory_limiter는 collector에서 메모리 부족(out of memory) 상황을 방지하는 데 사용됩니다. 권장 사항은 Estimating Resources를 참고하십시오.
- 컨텍스트 기반 보강(enrichment)을 수행하는 Processor. 예를 들어, Kubernetes Attributes Processor는 k8s 메타데이터를 사용하여 span, metric, log의 resource attribute를 자동으로 설정합니다. 예를 들어, 이벤트에 해당 소스 파드 ID를 추가하여 보강할 수 있습니다.
- trace에 필요하다면 tail 또는 head sampling.
- 기본적인 필터링 - 아래의 operator로 처리할 수 없는 경우, 필요하지 않은 이벤트를 드롭합니다.
- Batching - ClickHouse와 함께 작업할 때 데이터를 배치 단위로 전송하기 위해 필수입니다. "Exporting to ClickHouse"를 참고하십시오.
-
Operators - Operators는 receiver에서 사용할 수 있는 가장 기본적인 처리 단위를 제공합니다. 기본적인 파싱이 지원되며, 이를 통해 Severity와 Timestamp와 같은 필드를 설정할 수 있습니다. 여기에서는 JSON 및 정규식(regex) 파싱뿐 아니라 이벤트 필터링과 기본적인 변환도 지원합니다. 이벤트 필터링은 여기에서 수행할 것을 권장합니다.
Operator 또는 transform processors를 사용하여 과도한 이벤트 처리를 수행하지 않기를 권장합니다. 특히 JSON 파싱은 상당한 메모리와 CPU 오버헤드를 유발할 수 있습니다. 일부 예외(특히 컨텍스트 인식 보강(enrichment), 예: k8s 메타데이터 추가)를 제외하면, insert 시점에 ClickHouse에서 materialized view와 컬럼을 사용하여 모든 처리를 수행할 수 있습니다. 자세한 내용은 Extracting structure with SQL을 참고하십시오.
처리를 OTel collector에서 수행하는 경우, 게이트웨이 인스턴스에서 변환을 수행하고 에이전트 인스턴스에서의 작업은 최소화할 것을 권장합니다. 이렇게 하면 서버에서 실행되는 엣지의 에이전트가 필요로 하는 리소스를 가능한 한 최소화할 수 있습니다. 일반적으로 사용자는 불필요한 네트워크 사용을 줄이기 위한 필터링, operator를 통한 타임스탬프 설정, 그리고 컨텍스트가 필요한 보강(enrichment)만을 에이전트에서 수행하는 패턴을 보입니다. 예를 들어, 게이트웨이 인스턴스가 다른 Kubernetes 클러스터에 위치하는 경우, k8s 메타데이터 보강(enrichment)은 에이전트에서 수행해야 합니다.
예시
다음 구성은 비정형 로그 파일 수집 예시입니다. 로그 한 줄에서 구조를 추출하기 위한 연산자(regex_parser)와 이벤트를 필터링하기 위한 연산자, 그리고 이벤트를 배치로 처리하고 메모리 사용량을 제한하기 위한 프로세서(processor) 사용에 주목하십시오.
config-unstructured-logs-with-processor.yaml
ClickHouse로 내보내기
Exporter는 하나 이상의 백엔드 또는 대상으로 데이터를 전송하는 구성 요소입니다. Exporter는 pull 방식 또는 push 방식일 수 있습니다. 이벤트를 ClickHouse로 전송하려면 push 방식의 ClickHouse exporter를 사용해야 합니다.
ClickHouse exporter는 코어 배포본이 아니라 OpenTelemetry Collector Contrib의 일부입니다. contrib 배포판을 사용하거나 자체 collector를 빌드할 수 있습니다.
전체 설정 파일 예시는 아래와 같습니다.
다음 주요 설정을 확인하십시오:
- pipelines - 위 구성은 pipelines의 사용을 강조합니다. 이는 로그용 하나, 트레이스용 하나로 구성된 일련의 receiver, processor, exporter 세트로 이루어집니다.
- endpoint - ClickHouse와의 통신은
endpoint파라미터로 구성합니다. 연결 문자열tcp://localhost:9000?dial_timeout=10s&compress=lz4&async_insert=1는 TCP를 통해 통신이 이루어지도록 합니다. 트래픽 스위칭 등의 이유로 HTTP를 선호하는 경우, 여기에 설명된 대로 이 연결 문자열을 수정하십시오. 이 연결 문자열 내에서 사용자 이름과 비밀번호를 지정하는 방법을 포함한 전체 연결 세부 정보는 여기에 설명되어 있습니다.
중요: 위 연결 문자열은 압축(lz4)과 비동기 insert를 모두 활성화합니다. 두 옵션을 항상 활성화할 것을 권장합니다. 비동기 insert에 대한 자세한 내용은 Batching을 참조하십시오. 압축은 항상 지정해야 하며, exporter의 이전 버전에서는 기본적으로 활성화되지 않습니다.
- ttl - 이 값은 데이터가 얼마나 오래 보존되는지를 결정합니다. 자세한 내용은 「Managing data」에서 확인할 수 있습니다. 예: 72h와 같이 시간 단위(시간)로 지정해야 합니다. 아래 예제에서는 데이터가 2019년 것이어서 ClickHouse에 삽입되는 즉시 제거되기 때문에 TTL을 비활성화합니다.
- traces_table_name 및 logs_table_name - 로그 및 트레이스 테이블의 이름을 결정합니다.
- create_schema - 시작 시 기본 스키마로 테이블을 생성할지 여부를 결정합니다. 시작 단계에서는 기본값인 true를 사용합니다. 이후에는 값을 false로 설정하고 자체 스키마를 정의해야 합니다.
- database - 대상 데이터베이스입니다.
- retry_on_failure - 실패한 배치를 재시도할지 여부를 결정하는 설정입니다.
- batch - batch processor는 이벤트가 배치 단위로 전송되도록 보장합니다. 약 5000 정도의 값과 5초의 timeout을 권장합니다. 이 둘 중 어느 하나에 먼저 도달하면 배치가 생성되어 exporter로 전송됩니다. 이 값을 낮추면 ClickHouse로 더 많은 연결과 배치를 전송하는 대가로, 지연 시간이 더 짧은 파이프라인과 더 빠른 쿼리 가능 데이터를 얻게 됩니다. 이는 비동기 insert를 사용하지 않는 경우 ClickHouse에서 너무 많은 파트 문제가 발생할 수 있으므로 권장되지 않습니다. 반대로 비동기 insert를 사용하는 경우, 데이터가 쿼리에 사용 가능해지는 시점은 비동기 insert 설정에도 좌우되지만, 커넥터에서 데이터 자체는 더 빠르게 플러시됩니다. 자세한 내용은 Batching을 참조하십시오.
- sending_queue - sending queue의 크기를 제어합니다. 큐의 각 항목은 하나의 배치를 포함합니다. 예를 들어 ClickHouse에 접속할 수 없는 상황에서 이벤트가 계속 도착해 이 큐가 초과되면 해당 배치들은 드롭됩니다.
구조화된 로그 파일을 추출했고 (기본 인증으로) 로컬 ClickHouse 인스턴스를 실행 중이라고 가정하면, 이 구성을 다음 명령으로 실행할 수 있습니다:
이 수집기로 트레이스 데이터를 전송하려면 telemetrygen 도구를 사용하여 다음 명령을 실행하십시오:
실행이 시작되면 간단한 쿼리로 로그 이벤트가 수집되었는지 확인합니다:
기본 제공 스키마
기본적으로 ClickHouse exporter는 로그와 트레이스를 위해 각각 대상 테이블을 생성합니다. 이는 create_schema 설정을 통해 비활성화할 수 있습니다. 또한 위에서 언급한 설정을 통해 로그 및 트레이스 테이블 이름을 기본값인 otel_logs 및 otel_traces에서 다른 이름으로 변경할 수 있습니다.
아래 스키마에서는 TTL이 72시간으로 설정되어 있다고 가정합니다.
로그에 대한 기본 스키마는 아래와 같습니다 (otelcol-contrib v0.102.1):
여기의 컬럼들은 여기에 문서화된 로그용 OTel 공식 스펙과 연관됩니다.
이 스키마에 대한 몇 가지 중요한 참고 사항은 다음과 같습니다.
- 기본적으로 테이블은
PARTITION BY toDate(Timestamp)를 통해 날짜별로 파티션됩니다. 이는 만료된 데이터를 삭제하는 작업을 효율적으로 수행할 수 있게 해 줍니다. - TTL은
TTL toDateTime(Timestamp) + toIntervalDay(3)로 설정되며, 수집기 설정에 지정된 값과 대응합니다.ttl_only_drop_parts=1은(는) 포함된 모든 행이 만료되었을 때에만 전체 파트를 삭제함을 의미합니다. 이는 파트 내의 개별 행을 삭제하는 것(비용이 큰 delete를 발생시킴)보다 더 효율적입니다. 이 값을 항상 설정해 둘 것을 권장합니다. 자세한 내용은 Data management with TTL을 참조하십시오. - 테이블은 클래식
MergeTree엔진을 사용합니다. 이는 로그와 트레이스에 권장되며, 변경할 필요가 없습니다. - 테이블은
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)로 정렬됩니다. 이는ServiceName,SeverityText,Timestamp,TraceId에 대한 필터 쿼리가 최적화된다는 의미입니다. 목록의 앞쪽 컬럼일수록 뒤쪽 컬럼보다 더 빠르게 필터링됩니다. 예를 들어ServiceName으로 필터링하는 것이TraceId로 필터링하는 것보다 훨씬 빠릅니다. 예상되는 액세스 패턴에 맞게 이 정렬을 수정해야 합니다. 자세한 내용은 Choosing a primary key를 참조하십시오. - 위 스키마는 컬럼에
ZSTD(1)을 적용합니다. 이는 로그에 대해 가장 우수한 압축률을 제공합니다. 더 나은 압축을 위해 ZSTD 압축 레벨(기본값 1보다 큰 값)을 올릴 수 있지만, 실제로 유의미한 이득이 있는 경우는 드뭅니다. 이 값을 높이면 삽입 시점(압축 시점)에 CPU 오버헤드가 증가하지만, 압축 해제(따라서 쿼리) 속도는 비슷한 수준을 유지합니다. 자세한 내용은 여기를 참조하십시오. 추가로, 디스크 상에서 크기를 줄이기 위해 Timestamp에 델타 인코딩이 적용됩니다. ResourceAttributes,LogAttributes,ScopeAttributes가 모두 맵이라는 점에 주목해야 합니다. 이들 간의 차이를 이해하는 것이 중요합니다. 이러한 맵에 접근하고 그 안의 키 접근을 최적화하는 방법은 Using maps를 참조하십시오.- 여기에서 대부분의 다른 타입(예: LowCardinality로 정의된
ServiceName)도 최적화되어 있습니다. 예제 로그에서 JSON인Body는 String으로 저장된다는 점에 유의하십시오. - 블룸 필터는 맵의 키와 값뿐만 아니라
Body컬럼에도 적용됩니다. 이는 이러한 컬럼에 접근하는 쿼리의 시간을 단축하는 것을 목표로 하지만, 일반적으로 필수는 아닙니다. 자세한 내용은 Secondary/Data skipping indices를 참조하십시오.
마찬가지로, 이는 여기에 문서화되어 있는 OTel 공식 trace 스펙에 해당하는 컬럼들과 연관됩니다. 여기에서 사용하는 스키마는 위에서 설명한 로그 스키마와 많은 설정을 공유하며, span에 특화된 추가적인 Link 컬럼들을 포함합니다.
자동 스키마 생성을 비활성화하고 테이블을 수동으로 생성할 것을 권장합니다. 이렇게 하면 기본 키와 보조 키를 수정할 수 있을 뿐만 아니라 쿼리 성능을 최적화하기 위한 추가 컬럼을 도입할 수도 있습니다. 자세한 내용은 스키마 설계를 참조하십시오.
삽입 최적화
수집기를 통해 ClickHouse에 관측성(observability) 데이터를 삽입하면서 높은 삽입 성능과 강한 일관성을 확보하려면 몇 가지 간단한 규칙을 따르면 됩니다. OTel collector를 올바르게 구성하면 다음 규칙을 쉽게 준수할 수 있습니다. 이는 또한 처음 ClickHouse를 사용할 때 사용자가 겪기 쉬운 일반적인 문제를 방지하는 데 도움이 됩니다.
Batching
기본적으로 ClickHouse로 전송되는 각 insert는, insert된 데이터와 함께 저장해야 하는 기타 메타데이터를 포함하는 스토리지 파트(part)를 ClickHouse가 즉시 생성합니다. 따라서 각 insert에 적은 양의 데이터만 담아 자주 보내는 것보다, 각 insert에 더 많은 데이터를 담아 횟수를 줄여 보내는 방식이 필요한 쓰기 작업 수를 줄여 줍니다. 최소 한 번에 1,000개의 행 이상을 포함하는 비교적 큰 배치(batch) 단위로 데이터를 insert할 것을 권장합니다. 자세한 내용은 여기를 참고하십시오.
기본적으로 ClickHouse로의 insert는 동기(synchronous) 방식이며, 동일한 insert의 경우 멱등(idempotent)입니다. merge tree 엔진 계열의 테이블에서는 ClickHouse가 기본 설정으로 insert를 자동으로 중복 제거(deduplicate inserts)합니다. 이는 insert가 다음과 같은 상황에서 내결함성을 가진다는 의미입니다.
- (1) 데이터를 수신하는 노드에 문제가 있는 경우, insert 쿼리는 시간 초과(또는 더 구체적인 오류)를 발생시키고, 승인(acknowledgement)을 받지 못합니다.
- (2) 데이터가 노드에 의해 기록되었지만, 네트워크 중단으로 인해 쿼리 발신자에게 승인을 반환할 수 없는 경우, 발신자는 시간 초과 또는 네트워크 오류를 받게 됩니다.
collector의 관점에서는 (1)과 (2)를 구분하기 어려울 수 있습니다. 그러나 두 경우 모두, 승인되지 않은 insert는 즉시 재시도할 수 있습니다. 재시도한 insert 쿼리에 동일한 데이터가 동일한 순서로 포함되어 있는 한, (승인되지 않은) 원래 insert가 이미 성공했을 경우 ClickHouse는 재시도된 insert를 자동으로 무시합니다.
위 요구 사항을 충족하기 위해, 앞선 설정 예시에서 사용한 batch processor를 사용할 것을 권장합니다. 이렇게 하면 insert가 위 조건을 만족하는 행들의 일관된 배치로 전송되도록 보장됩니다. collector에서 높은 처리량(초당 이벤트 수)이 예상되고, 각 insert에 최소 5,000개의 이벤트를 포함할 수 있는 경우, 일반적으로 파이프라인에서 필요한 batching은 이것으로 충분합니다. 이 경우 collector는 batch processor의 timeout에 도달하기 전에 배치를 flush하여, 파이프라인의 종단 간 지연 시간이 낮게 유지되고 배치 크기가 일관되도록 합니다.
비동기 insert 사용
일반적으로 콜렉터의 처리량이 낮을 때는 더 작은 배치를 전송하게 되지만, 여전히 데이터가 최소한의 엔드 투 엔드 지연 시간으로 ClickHouse에 도달하기를 기대합니다. 이 경우 배치 프로세서의 timeout 이 만료되면 작은 배치가 전송됩니다. 이는 문제를 유발할 수 있으며, 이런 상황에서 비동기 insert가 필요합니다. 이러한 경우는 에이전트 역할의 콜렉터가 ClickHouse로 직접 전송하도록 구성된 경우에 주로 발생합니다. 게이트웨이는 집계자 역할을 수행함으로써 이 문제를 완화할 수 있습니다. 게이트웨이를 통한 확장을 참고하십시오.
큰 배치를 보장할 수 없다면 Asynchronous Inserts를 사용하여 배치 작업을 ClickHouse에 위임할 수 있습니다. 비동기 insert에서는 데이터가 먼저 버퍼에 insert된 후, 나중에 또는 비동기적으로 데이터베이스 스토리지에 기록됩니다.
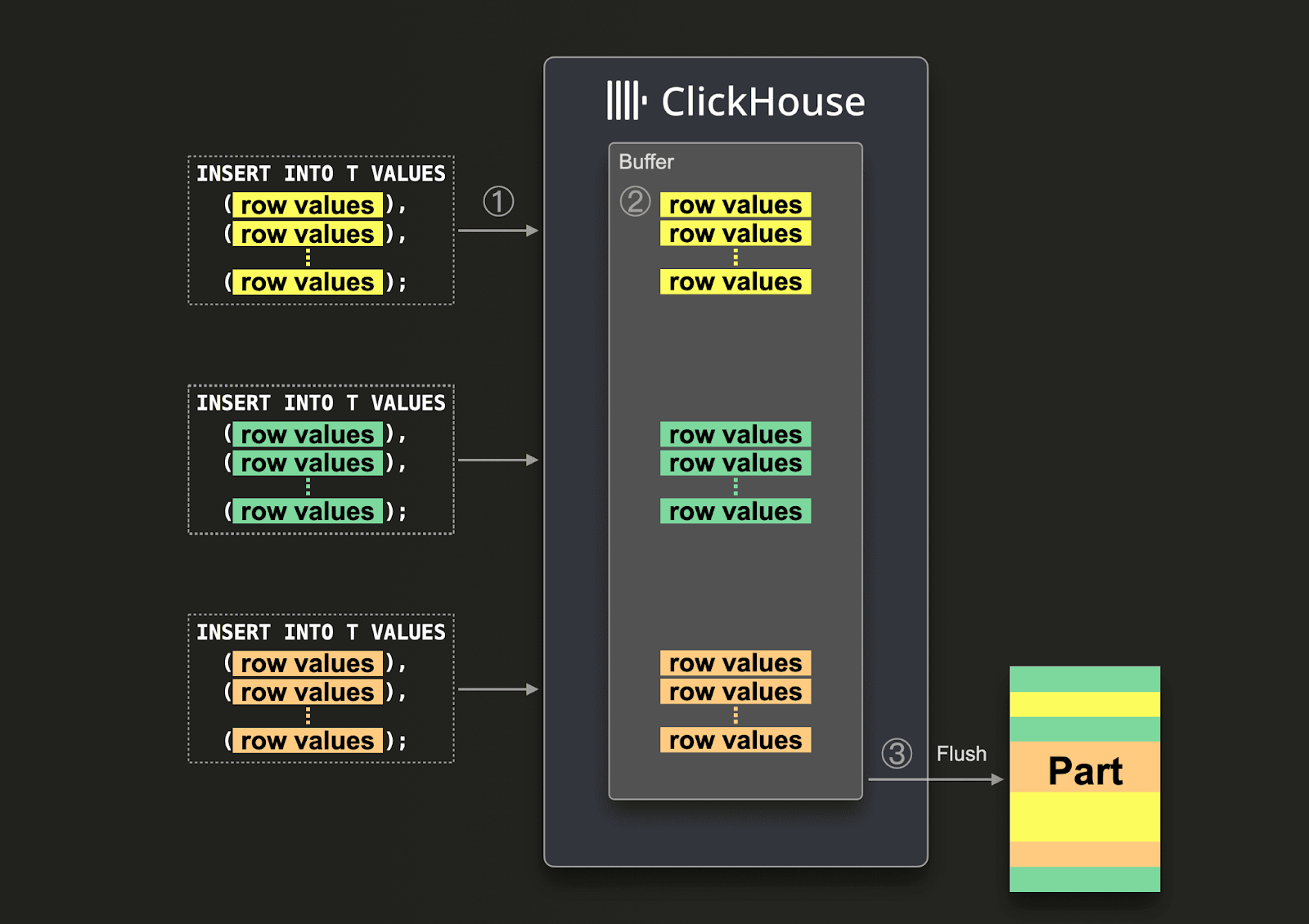
비동기 insert를 활성화하면, ClickHouse가 ① insert 쿼리를 수신했을 때 쿼리의 데이터는 ② 즉시 인메모리 버퍼에 먼저 기록됩니다. ③ 다음 버퍼 플러시가 발생하면, 버퍼의 데이터는 정렬된 후 하나의 파트로 데이터베이스 스토리지에 기록됩니다. 데이터는 데이터베이스 스토리지로 플러시되기 전까지는 쿼리로 검색할 수 없다는 점에 유의해야 합니다. 버퍼 플러시는 설정 가능합니다.
콜렉터에 대해 비동기 insert를 활성화하려면 연결 문자열에 async_insert=1 을 추가하십시오. 전송 보장을 위해 wait_for_async_insert=1 (기본값)을 사용할 것을 권장합니다. 자세한 내용은 여기를 참고하십시오.
비동기 insert에서 들어온 데이터는 ClickHouse 버퍼가 플러시될 때 insert됩니다. 이는 async_insert_max_data_size를 초과했을 때 또는 첫 번째 INSERT 쿼리 이후 async_insert_busy_timeout_ms 밀리초가 지나면 발생합니다. async_insert_stale_timeout_ms 가 0이 아닌 값으로 설정된 경우, 마지막 쿼리 이후 async_insert_stale_timeout_ms 밀리초가 지나면 데이터가 insert됩니다. 이러한 설정을 조정하여 파이프라인의 엔드 투 엔드 지연 시간을 제어할 수 있습니다. 버퍼 플러시를 튜닝하는 데 사용할 수 있는 추가 설정은 여기에 문서화되어 있습니다. 일반적으로 기본값으로 충분합니다.
소수의 에이전트만 사용하면서 처리량은 낮지만 엄격한 엔드 투 엔드 지연 시간 요구 사항이 있는 경우, adaptive asynchronous inserts가 유용할 수 있습니다. 일반적으로 이는 ClickHouse에서 볼 수 있는 고처리량 관측성 사용 사례에는 적합하지 않습니다.
마지막으로, ClickHouse에 대한 동기 insert와 연관된 이전의 중복 제거(deduplication) 동작은 비동기 insert를 사용할 때 기본적으로 활성화되어 있지 않습니다. 필요한 경우 async_insert_deduplicate 설정을 참고하십시오.
이 기능 구성에 대한 전체 세부 사항은 여기에서 확인할 수 있으며, 보다 심층적인 내용은 여기를 참고하십시오.
배포 아키텍처
OTel collector를 ClickHouse와 함께 사용할 때는 여러 가지 배포 아키텍처를 사용할 수 있습니다. 아래에서 각 방식을 설명하고, 어떤 상황에서 적합한지 설명합니다.
Agents only
에이전트 전용(Agents only) 아키텍처에서는 사용자가 OTel collector를 에이전트로 엣지에 배포합니다. 이 에이전트는 로컬 애플리케이션(예: 사이드카 컨테이너)에서 트레이스를 수신하고, 서버와 Kubernetes 노드에서 로그를 수집합니다. 이 모드에서는 에이전트가 수집한 데이터를 직접 ClickHouse로 전송합니다.
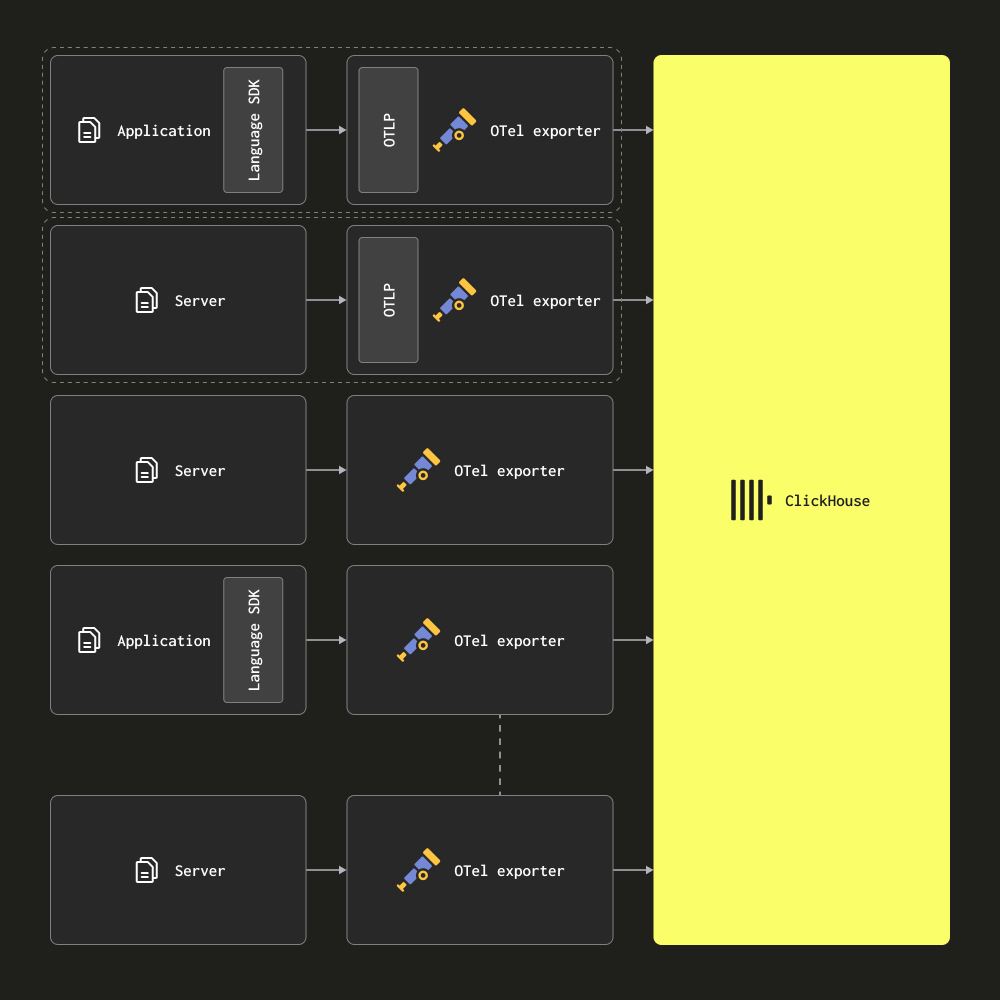
이 아키텍처는 소규모에서 중간 규모의 배포 환경에 적합합니다. 주요 장점은 추가 하드웨어가 필요하지 않고, 애플리케이션과 collector 간의 단순한 매핑을 유지하면서 ClickHouse 관측성(observability) 솔루션의 전체 리소스 사용량을 최소화한다는 점입니다.
에이전트 수가 수백 개를 초과하기 시작하면 Gateway 기반 아키텍처로 마이그레이션하는 것을 고려해야 합니다. 이 아키텍처에는 확장을 어렵게 만드는 여러 단점이 있습니다.
- 연결 확장(Connection scaling) - 각 에이전트는 ClickHouse에 대한 연결을 개별적으로 생성합니다. ClickHouse는 수백(또는 수천) 개의 동시 insert 연결을 유지할 수 있지만, 결국 이는 제한 요소가 되어 insert 효율성을 떨어뜨리고, ClickHouse가 연결을 유지하는 데 더 많은 리소스를 사용하게 됩니다. Gateway를 사용하면 연결 수를 최소화하고 insert를 더 효율적으로 만들 수 있습니다.
- 엣지에서의 처리(Processing at the edge) - 이 아키텍처에서는 모든 변환이나 이벤트 처리를 엣지 또는 ClickHouse에서 수행해야 합니다. 이는 제약이 될 뿐만 아니라, 복잡한 ClickHouse materialized view를 사용해야 하거나, 중요한 서비스에 영향을 줄 수 있고 리소스가 제한적인 엣지에 상당한 연산 부담을 떠넘기는 결과가 될 수 있습니다.
- 작은 배치와 지연 시간(Small batches and latencies) - 에이전트 collector는 개별적으로 매우 적은 수의 이벤트만 수집할 수 있습니다. 일반적으로 이는 전달 SLA를 충족하기 위해 일정한 간격마다 플러시하도록 구성해야 함을 의미합니다. 그 결과 collector가 ClickHouse로 작은 배치만 전송하는 상황이 발생할 수 있습니다. 이는 단점이지만, 비동기 insert(Asynchronous inserts)를 사용하여 완화할 수 있습니다. 자세한 내용은 Optimizing inserts를 참조하십시오.
게이트웨이를 통한 확장
OTel collector는 위의 한계를 해결하기 위해 Gateway 인스턴스로 배포할 수 있습니다. 이러한 인스턴스는 일반적으로 데이터 센터별 또는 리전별로 배포되는 독립 실행형 서비스입니다. 애플리케이션(또는 에이전트 역할의 다른 collector)에서 단일 OTLP 엔드포인트를 통해 이벤트를 수신합니다. 일반적으로 여러 개의 Gateway 인스턴스를 배포하고, 기성의 로드 밸런서를 사용하여 이들 사이에 부하를 분산합니다.
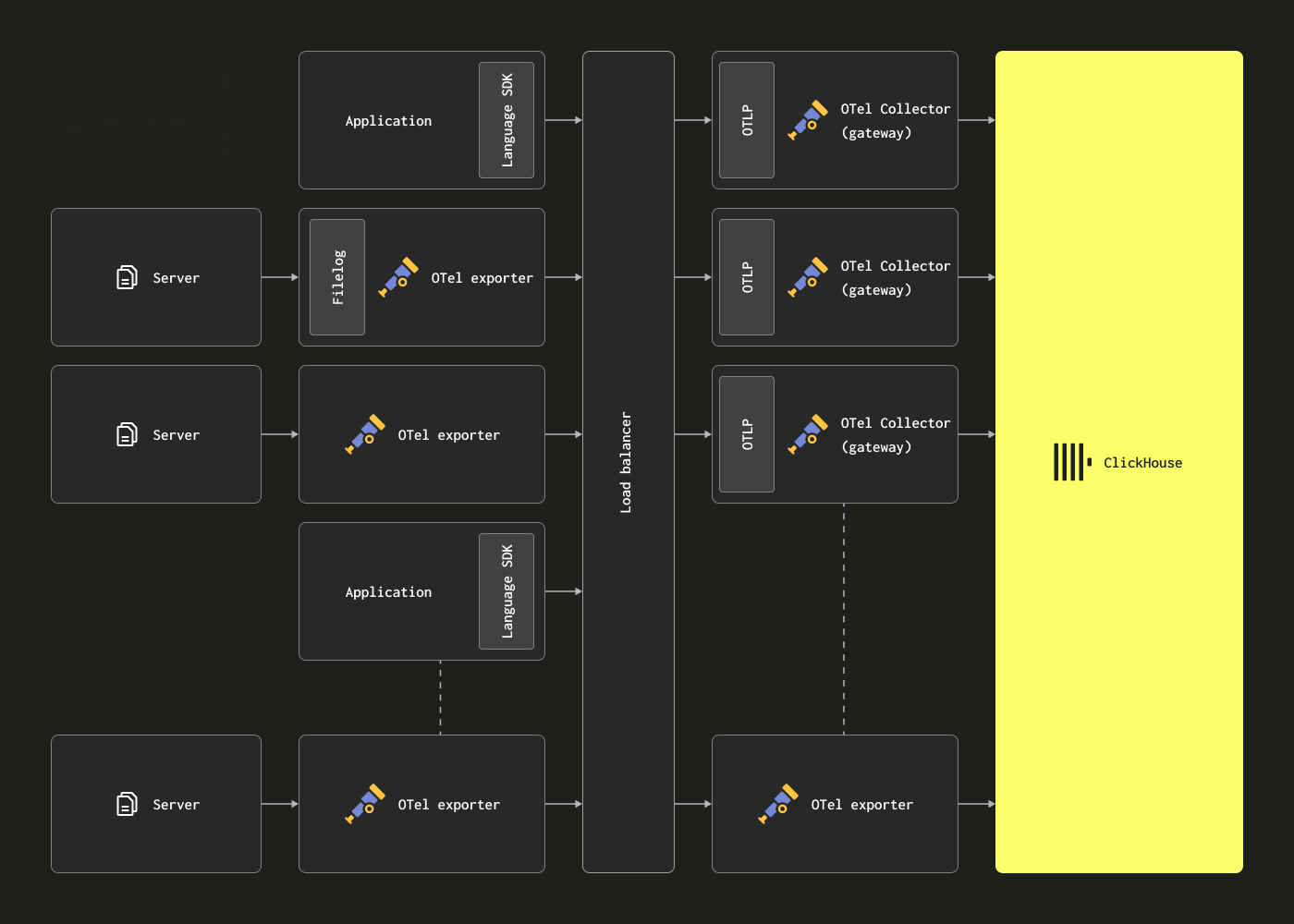
이 아키텍처의 목적은 에이전트에서 계산 집약적인 처리를 분리함으로써 에이전트의 리소스 사용량을 최소화하는 것입니다. 이러한 Gateway는 원래 에이전트에서 수행해야 하는 변환 작업을 대신 수행할 수 있습니다. 또한 다수의 에이전트에서 이벤트를 집계함으로써 Gateway는 ClickHouse로 대용량 배치를 전송하여 효율적인 삽입을 보장할 수 있습니다. 이러한 게이트웨이 collector는 더 많은 에이전트가 추가되고 이벤트 처리량이 증가함에 따라 쉽게 확장할 수 있습니다. 예제 구조화 로그 파일을 수집하는 관련 에이전트 구성과 함께 예제 Gateway 구성은 아래와 같습니다. 에이전트와 Gateway 간 통신에 OTLP를 사용하는 점에 주목하십시오.
clickhouse-gateway-config.yaml
이 구성은 다음 명령어로 실행할 수 있습니다.
이 아키텍처의 주요 단점은 여러 개의 collector를 관리하는 데 따르는 비용과 관리 오버헤드입니다.
더 큰 gateway 기반 아키텍처를 관리하는 예시와 그와 관련된 학습 내용을 확인하려면 이 블로그 게시물을 참고하십시오.
Kafka 추가
위의 아키텍처에서는 Kafka를 메시지 큐로 사용하지 않는다는 점을 알 수 있습니다.
Kafka 큐를 메시지 버퍼로 사용하는 것은 로깅 아키텍처에서 자주 보이는 인기 있는 설계 패턴이며, ELK 스택으로 널리 알려졌습니다. 이 방식은 몇 가지 이점을 제공합니다. 가장 중요한 것은 더 강력한 메시지 전송 보장과 배압(backpressure) 처리 능력을 제공한다는 점입니다. 수집 에이전트에서 Kafka로 메시지를 전송하면 디스크에 기록됩니다. 이론적으로, 클러스터링된 Kafka 인스턴스는 디스크에 데이터를 선형으로 기록하는 것이 메시지를 파싱하고 처리하는 것보다 계산 오버헤드가 적기 때문에 높은 처리량의 메시지 버퍼를 제공해야 합니다. 예를 들어 Elastic에서는 토크나이즈와 인덱싱에 상당한 오버헤드가 발생합니다. 데이터를 에이전트에서 분리하면, 소스에서 로그 로테이션이 일어날 때 메시지를 잃어버릴 위험도 줄어듭니다. 마지막으로, 일부 사용 사례에서 매력적일 수 있는 메시지 재생 및 리전 간 복제 기능도 제공합니다.
그러나 ClickHouse는 비교적 보통 수준의 하드웨어에서도 초당 수백만 행을 매우 빠르게 삽입할 수 있습니다. ClickHouse로부터의 배압(backpressure)은 드뭅니다. 많은 경우 Kafka 큐를 도입하면 아키텍처 복잡성과 비용만 증가하는 경우가 많습니다. 로그가 은행 거래 및 기타 미션 크리티컬 데이터와 동일한 수준의 전송 보장을 필요로 하지 않는다는 원칙을 받아들일 수 있다면, Kafka로 인한 복잡성을 피하는 것을 권장합니다.
하지만 높은 전송 보장이나 데이터 재생(잠재적으로 여러 소스로)을 위한 기능이 필요한 경우, Kafka는 유용한 아키텍처 구성 요소가 될 수 있습니다.
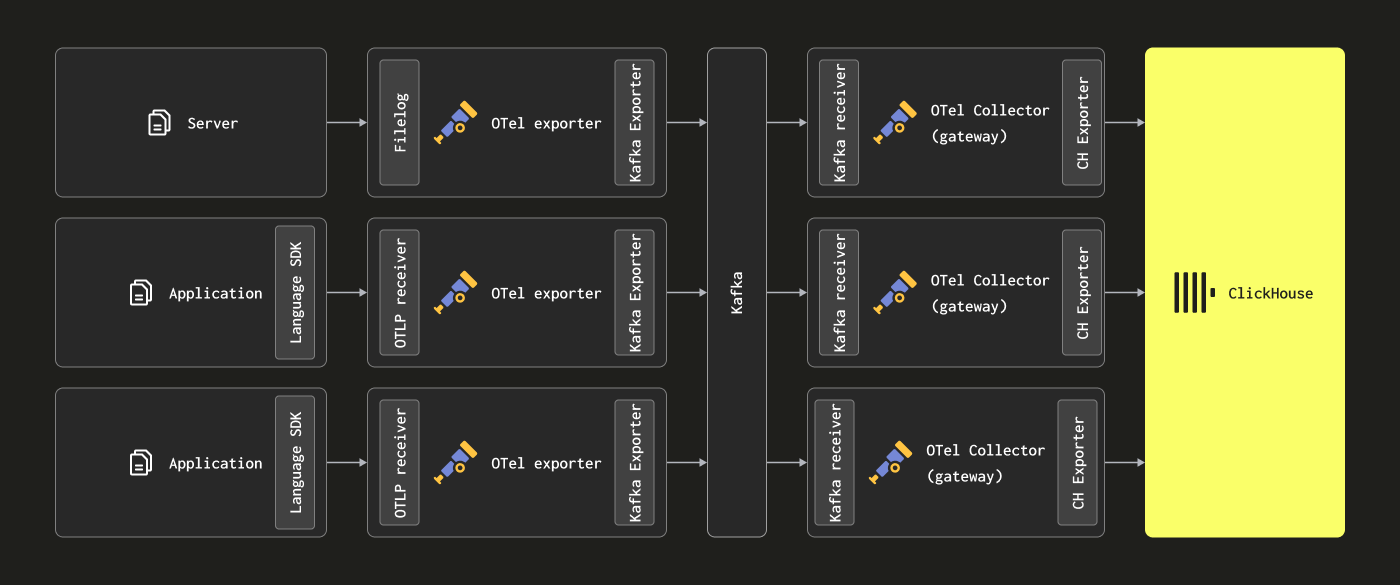
이 경우 OTel 에이전트는 Kafka exporter를 통해 Kafka로 데이터를 전송하도록 설정할 수 있습니다. 게이트웨이 인스턴스는 Kafka receiver를 사용해 메시지를 소비합니다. 자세한 내용은 Confluent 및 OTel 문서를 참고하시기 바랍니다.
리소스 추정
OTel collector의 리소스 요구 사항은 이벤트 처리량, 메시지 크기, 수행되는 처리 작업의 양에 따라 달라집니다. OpenTelemetry 프로젝트에서는 리소스 요구 사항을 추정하는 데 참고할 수 있는 벤치마크를 제공합니다.
운영 경험에 따르면, 3개의 코어와 12GB RAM을 가진 게이트웨이 인스턴스는 초당 약 6만 개의 이벤트를 처리할 수 있습니다. 이는 필드 이름 변경만 수행하고 정규 표현식을 사용하지 않는 최소한의 처리 파이프라인을 가정한 수치입니다.
이벤트를 게이트웨이로 전달하고 이벤트에 타임스탬프만 설정하는 에이전트 인스턴스의 경우, 예상되는 초당 로그 수를 기준으로 리소스를 산정할 것을 권장합니다. 아래는 시작점으로 사용할 수 있는 대략적인 수치입니다.
| 로깅 속도 | collector 에이전트에 필요한 리소스 |
|---|---|
| 1k/second | 0.2CPU, 0.2GiB |
| 5k/second | 0.5 CPU, 0.5GiB |
| 10k/second | 1 CPU, 1GiB |
