ClickHouse가 쿼리를 병렬로 실행하는 방법
ClickHouse는 속도를 위해 설계되었습니다. 사용 가능한 모든 CPU 코어를 활용하고, 데이터를 여러 처리 레인으로 분산하며, 종종 하드웨어의 한계에 가까운 수준까지 밀어붙이면서 쿼리를 고도로 병렬화된 방식으로 실행합니다.
이 가이드는 ClickHouse에서 쿼리 병렬성이 어떻게 동작하는지, 그리고 대규모 워크로드에서 성능을 향상시키기 위해 이를 어떻게 조정하거나 모니터링할 수 있는지에 대해 설명합니다.
주요 개념을 설명하기 위해 uk_price_paid_simple 데이터셋에 대한 집계 쿼리를 사용합니다.
단계별 설명: ClickHouse가 집계 쿼리를 병렬 처리하는 방식
ClickHouse가 테이블의 기본 키에 대한 필터가 포함된 집계 쿼리를 실행하면, ① 기본 인덱스를 메모리에 로드하고 ② 어떤 그래뉼을 처리해야 하는지와 ③ 어떤 그래뉼을 안전하게 건너뛸 수 있는지를 판별합니다:
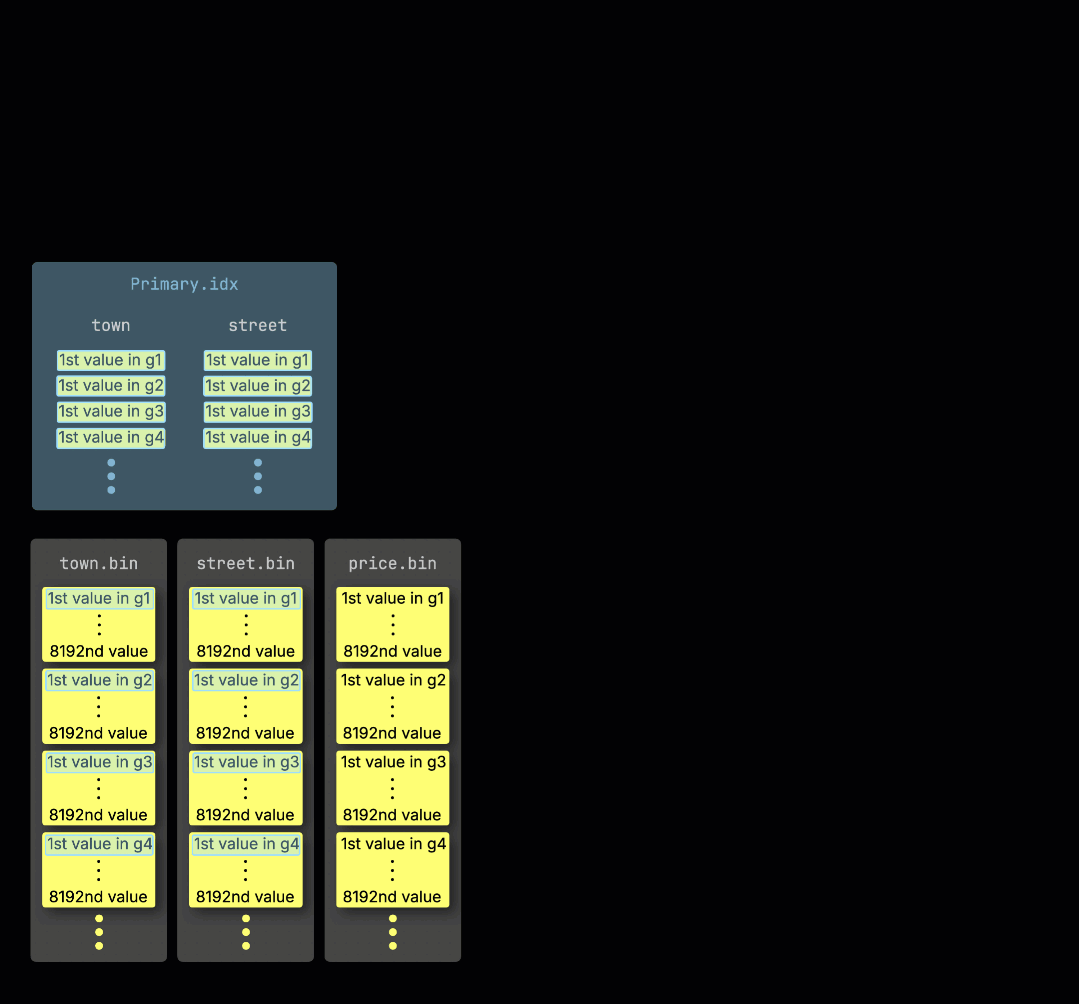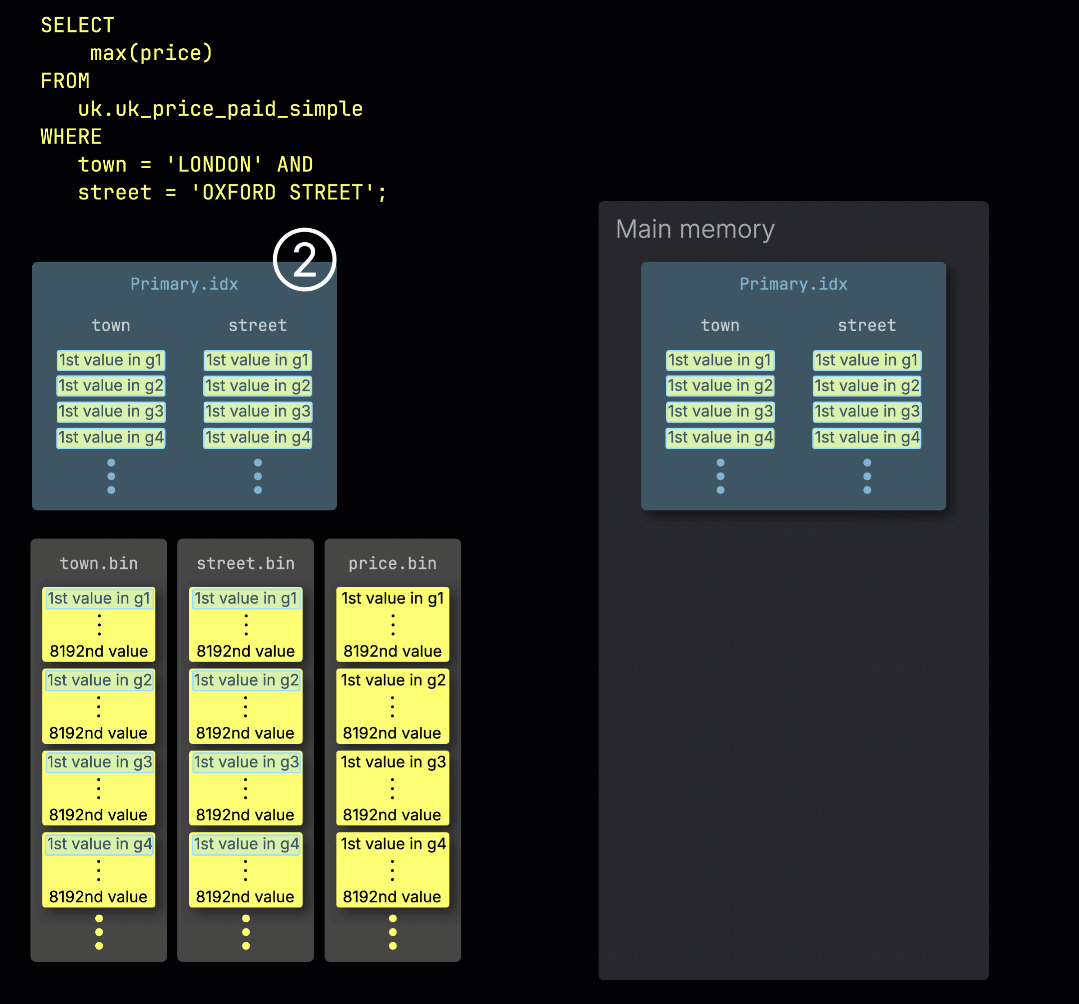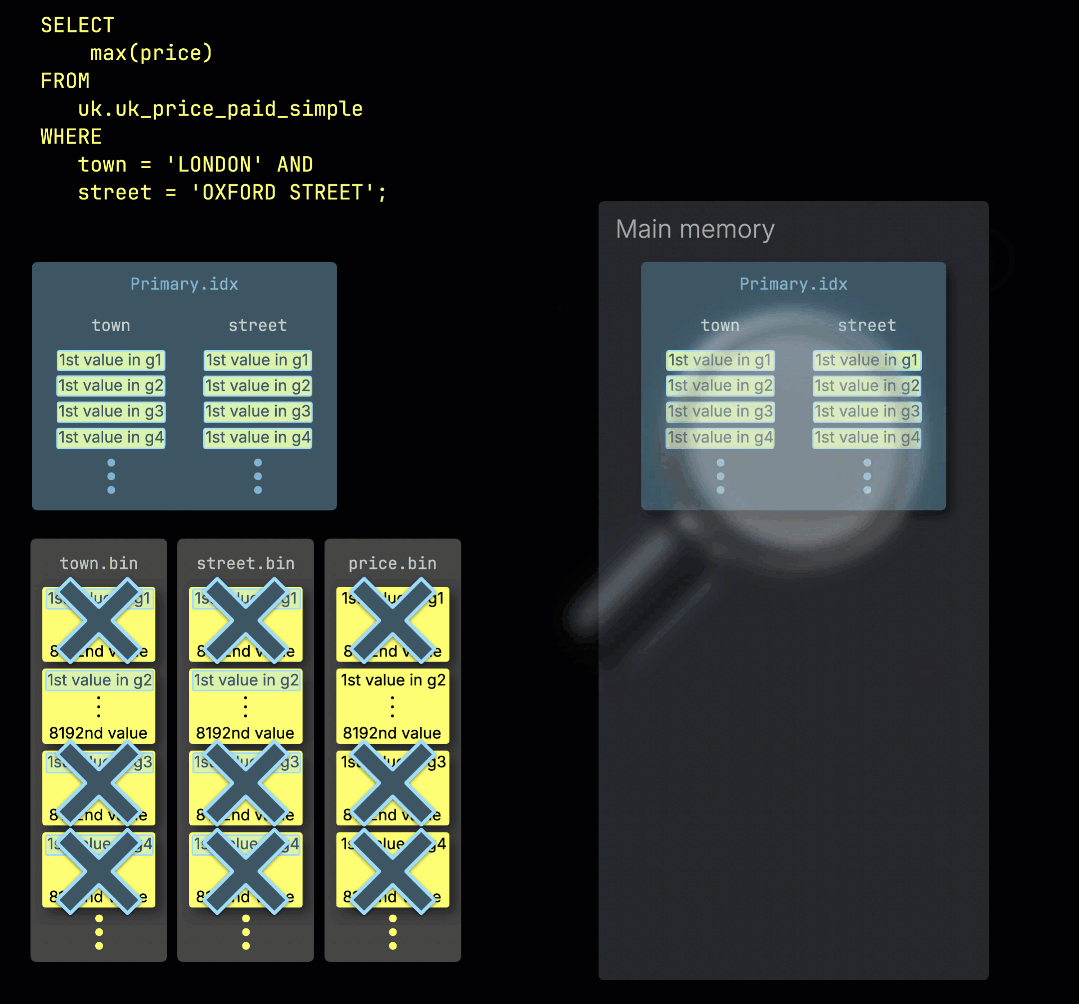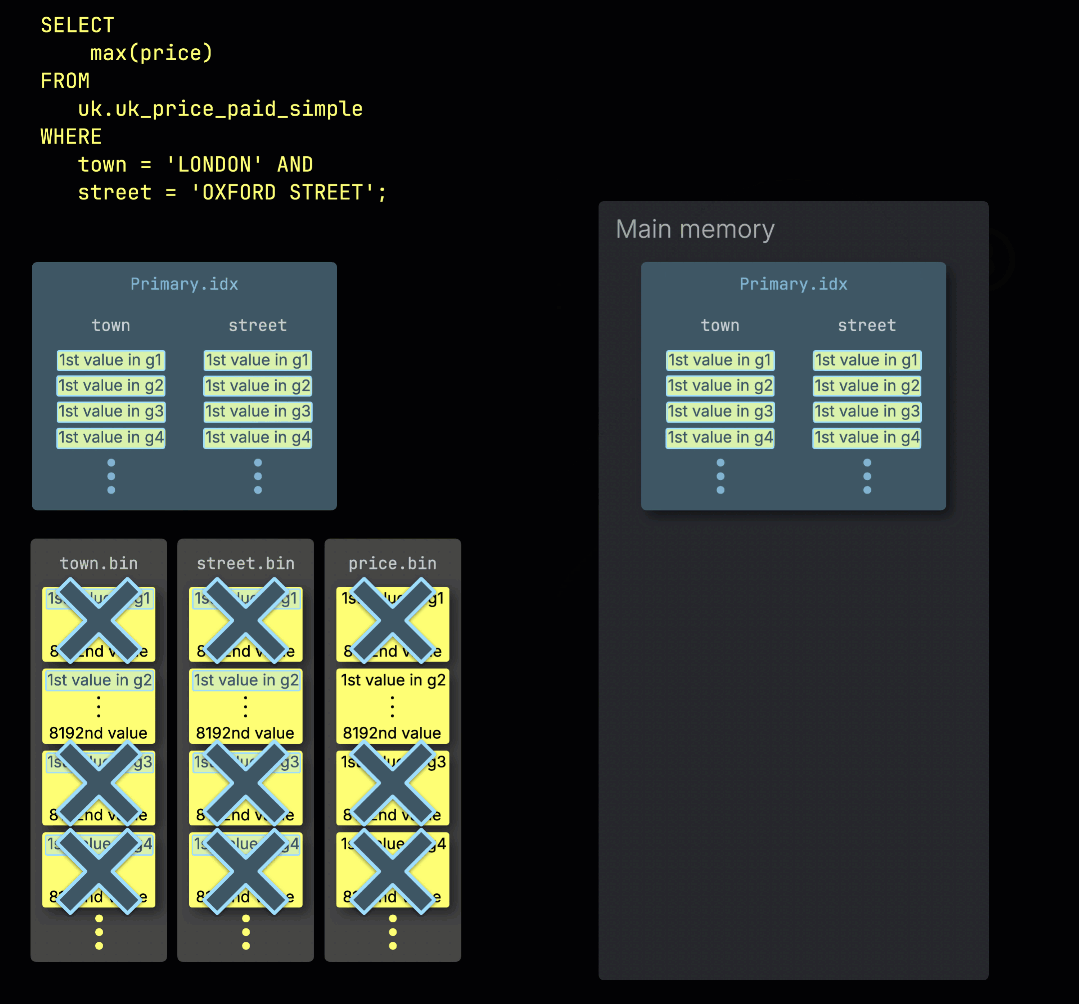
처리 레인 간 작업 분배
선택된 데이터는 이후 n개의 병렬 처리 레인에 동적으로 분배되며, 각 레인은 데이터를 블록 단위로 스트리밍하고 처리하여 최종 결과를 생성합니다:
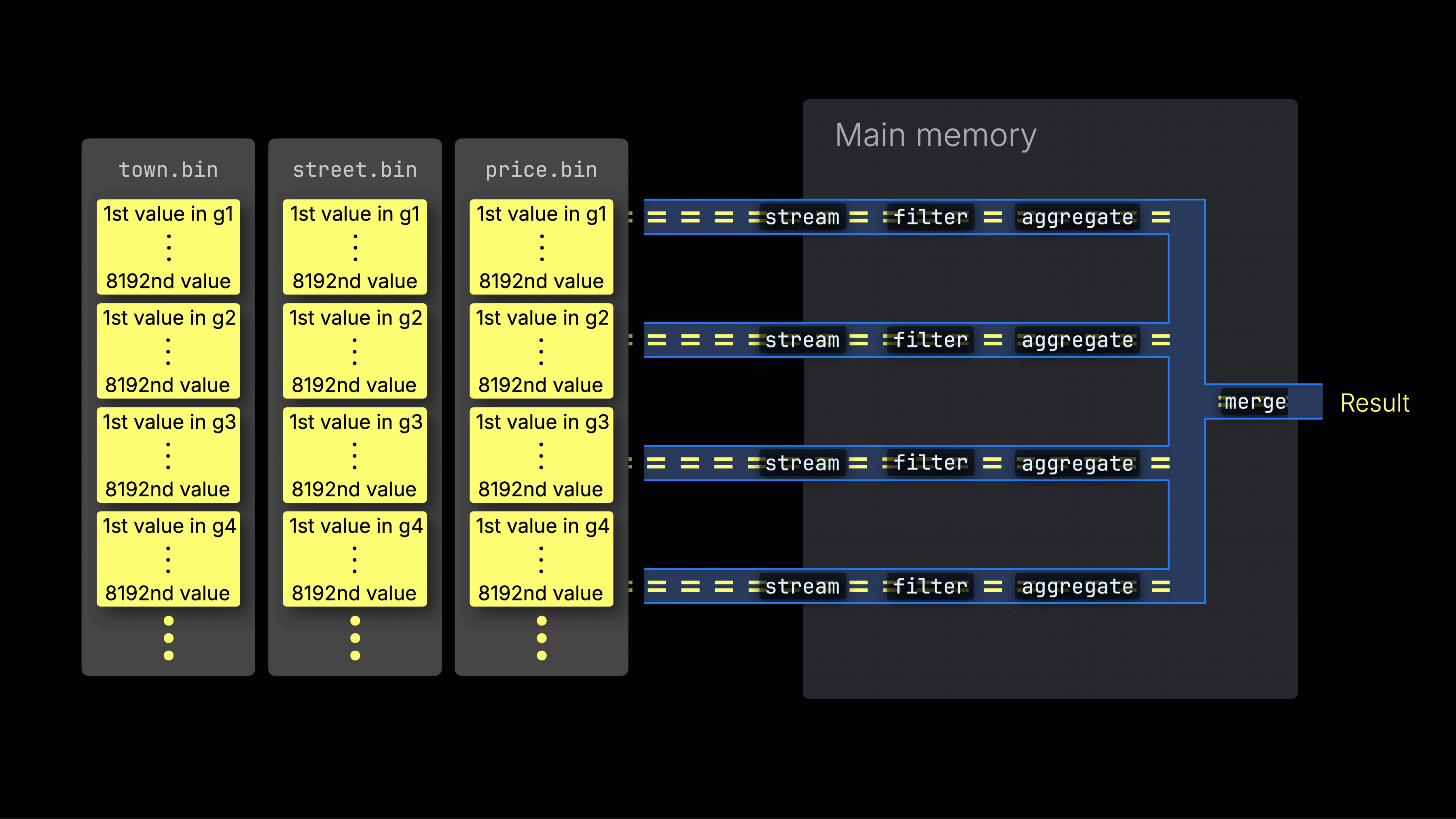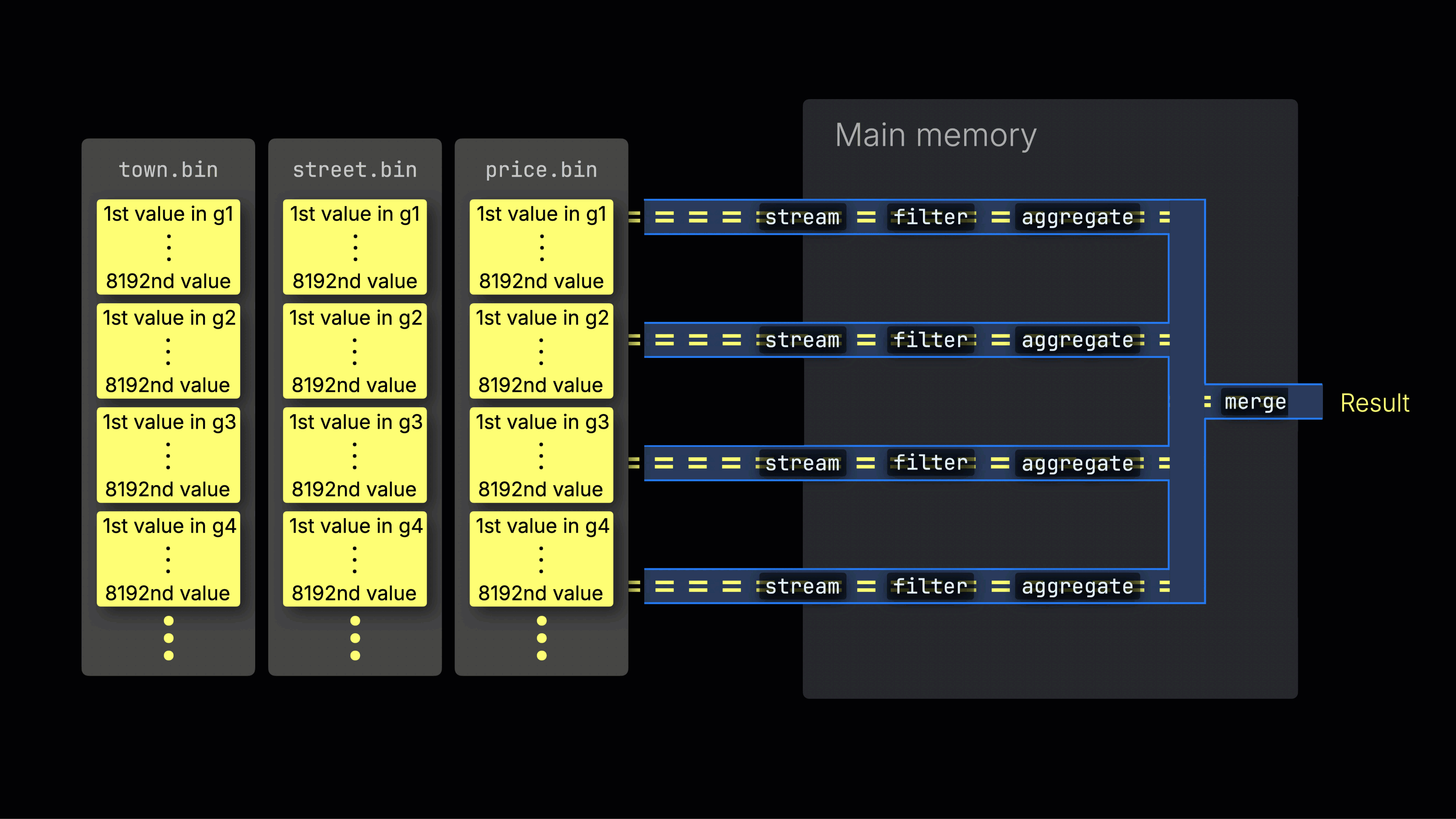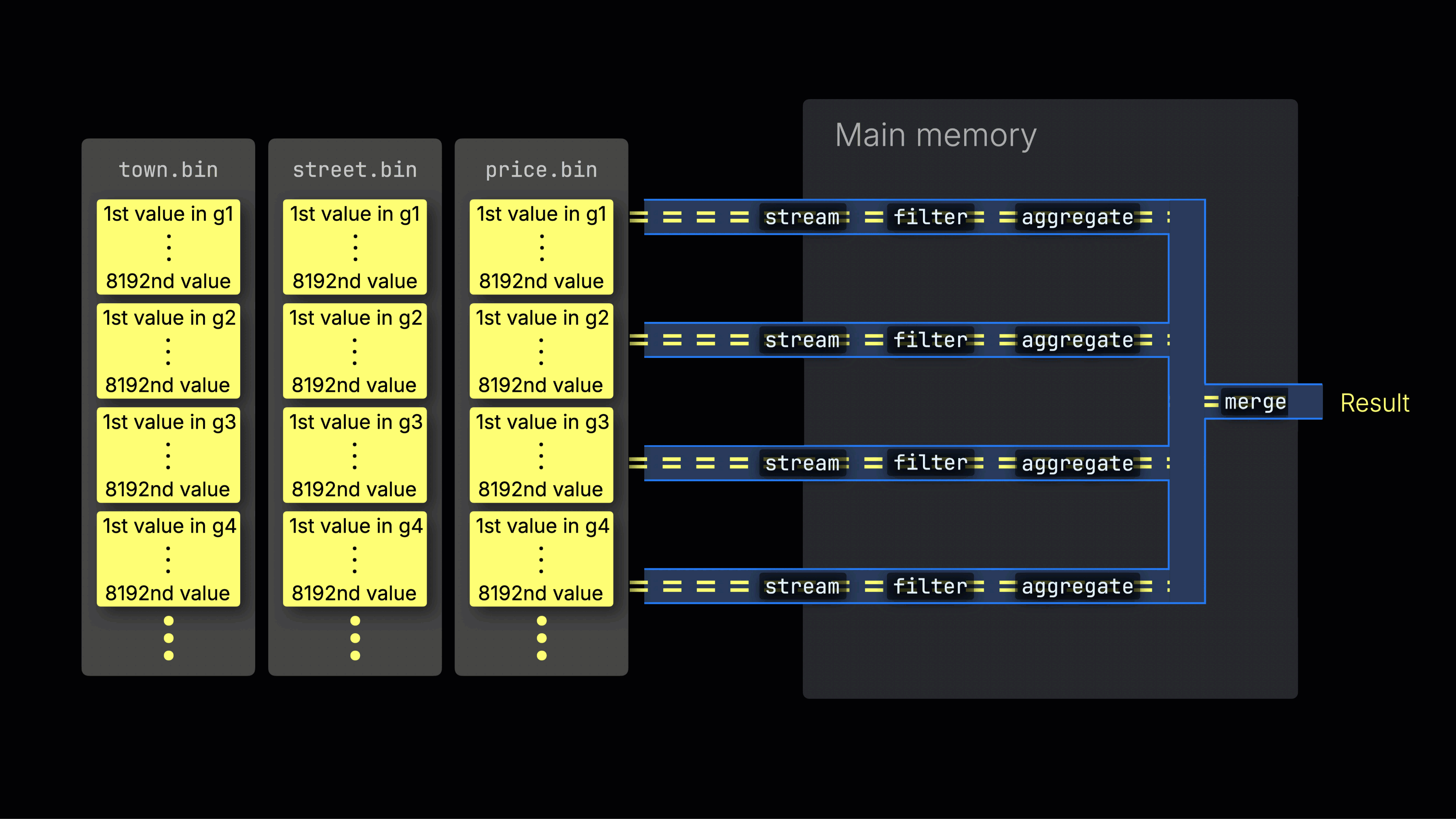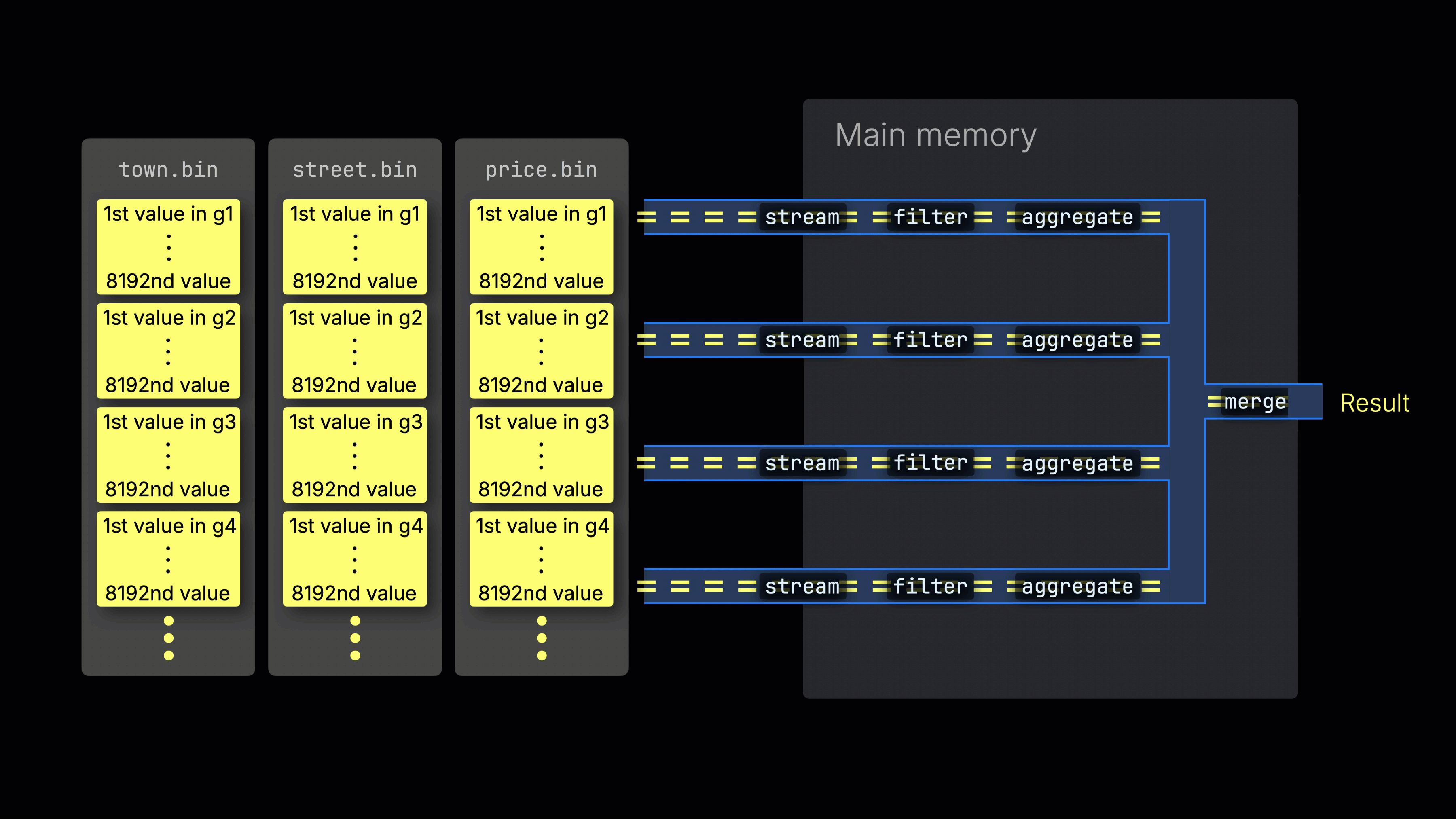
n개의 병렬 처리 레인 수는 max_threads 설정으로 제어되며, 기본값은 서버에서 ClickHouse가 사용할 수 있는 단일 CPU의 코어(스레드) 수와 동일합니다. 위 예시에서는 4개의 코어가 있다고 가정합니다.
8개의 코어가 있는 머신에서는 더 많은 레인이 데이터를 병렬로 처리하므로 쿼리 처리량이 대략 두 배로 증가합니다(그에 따라 메모리 사용량도 증가함):
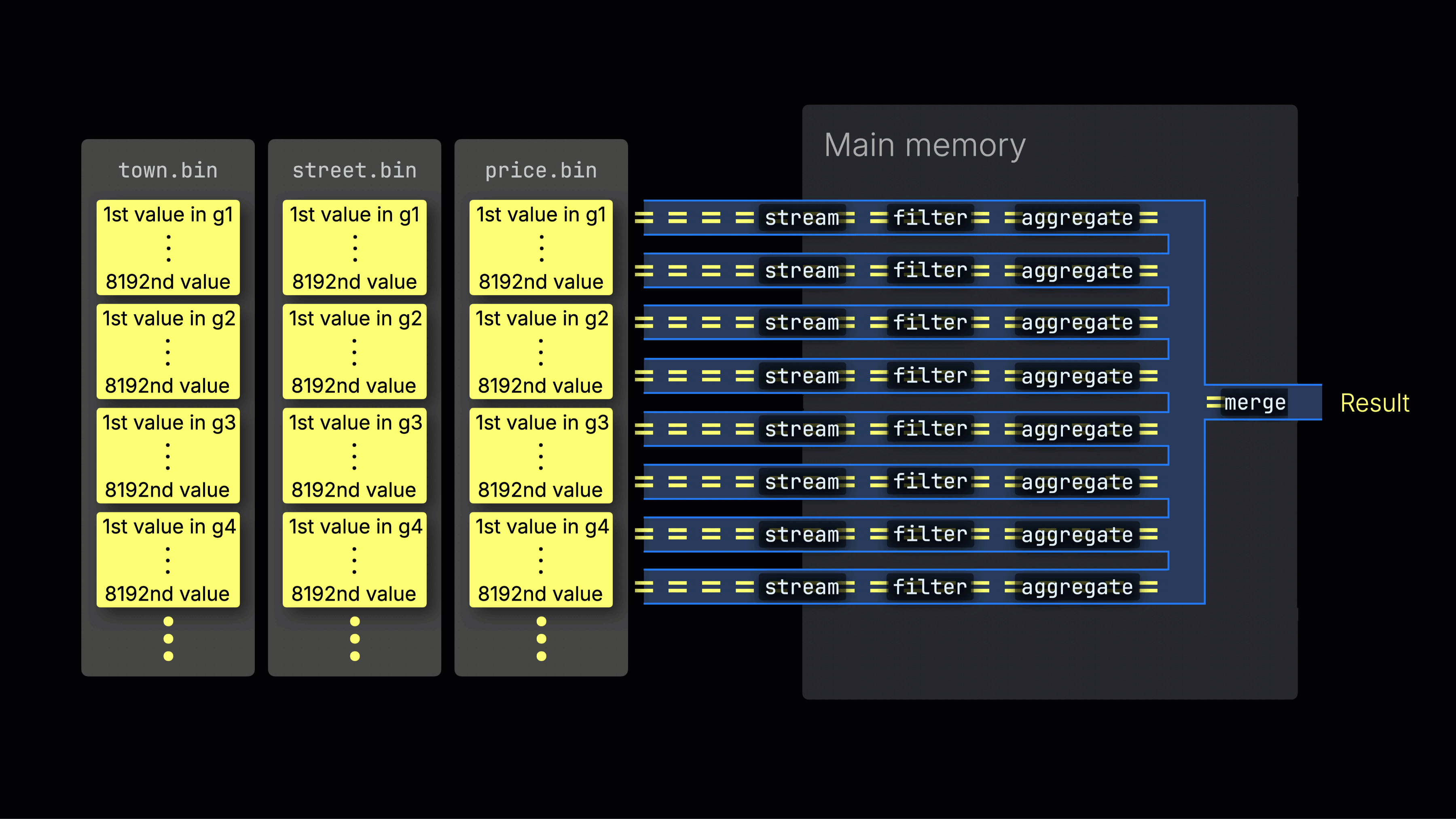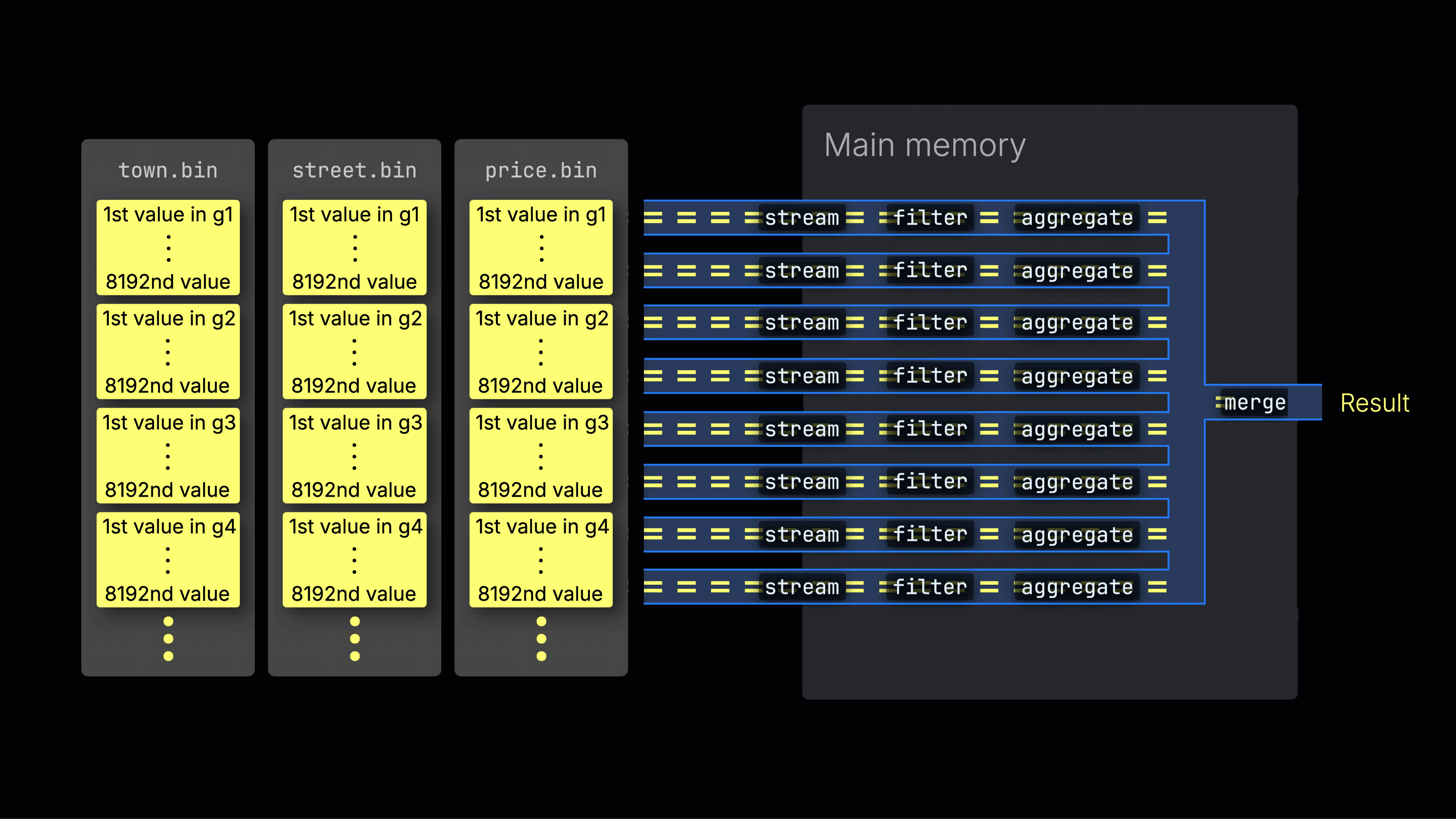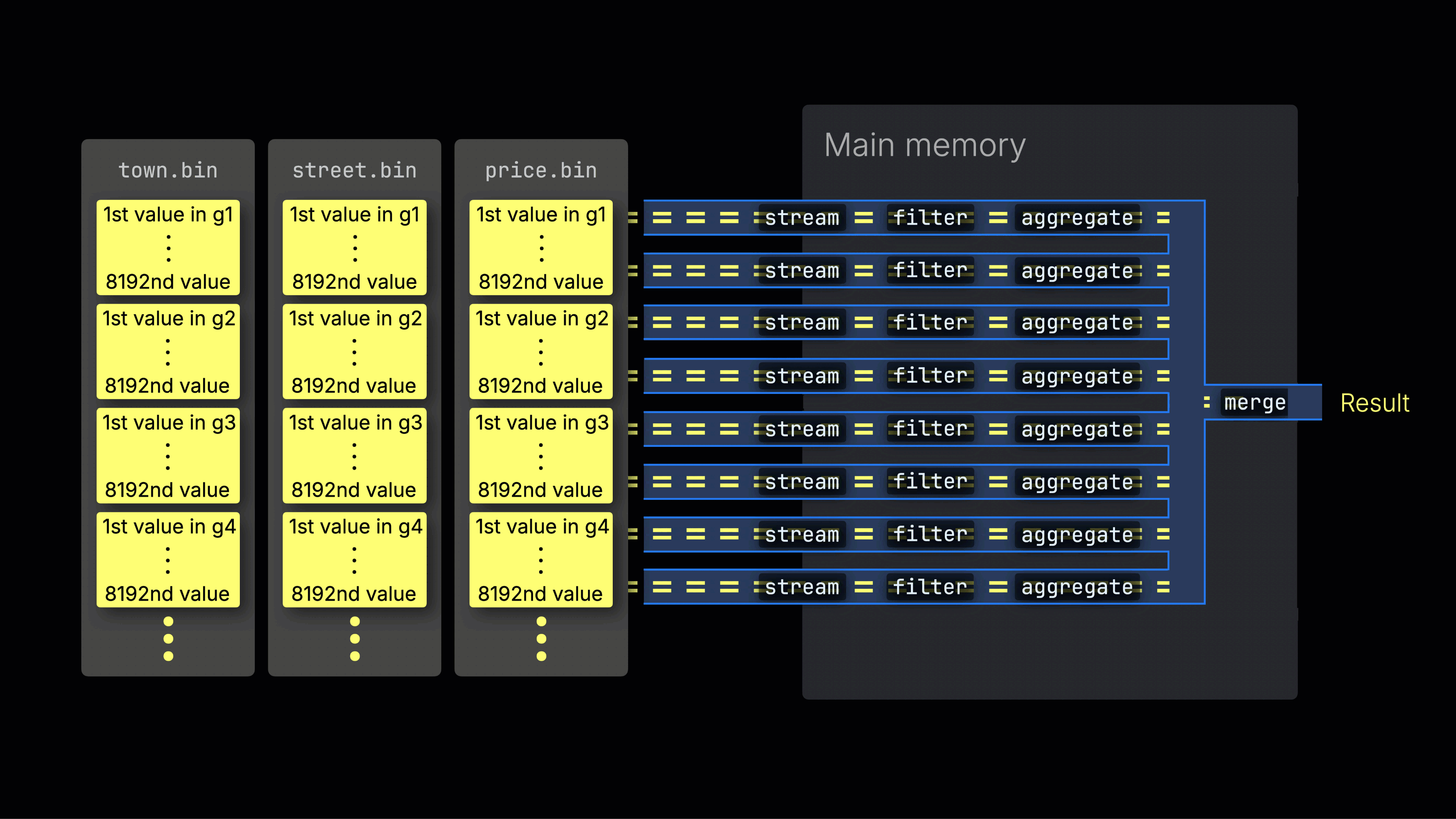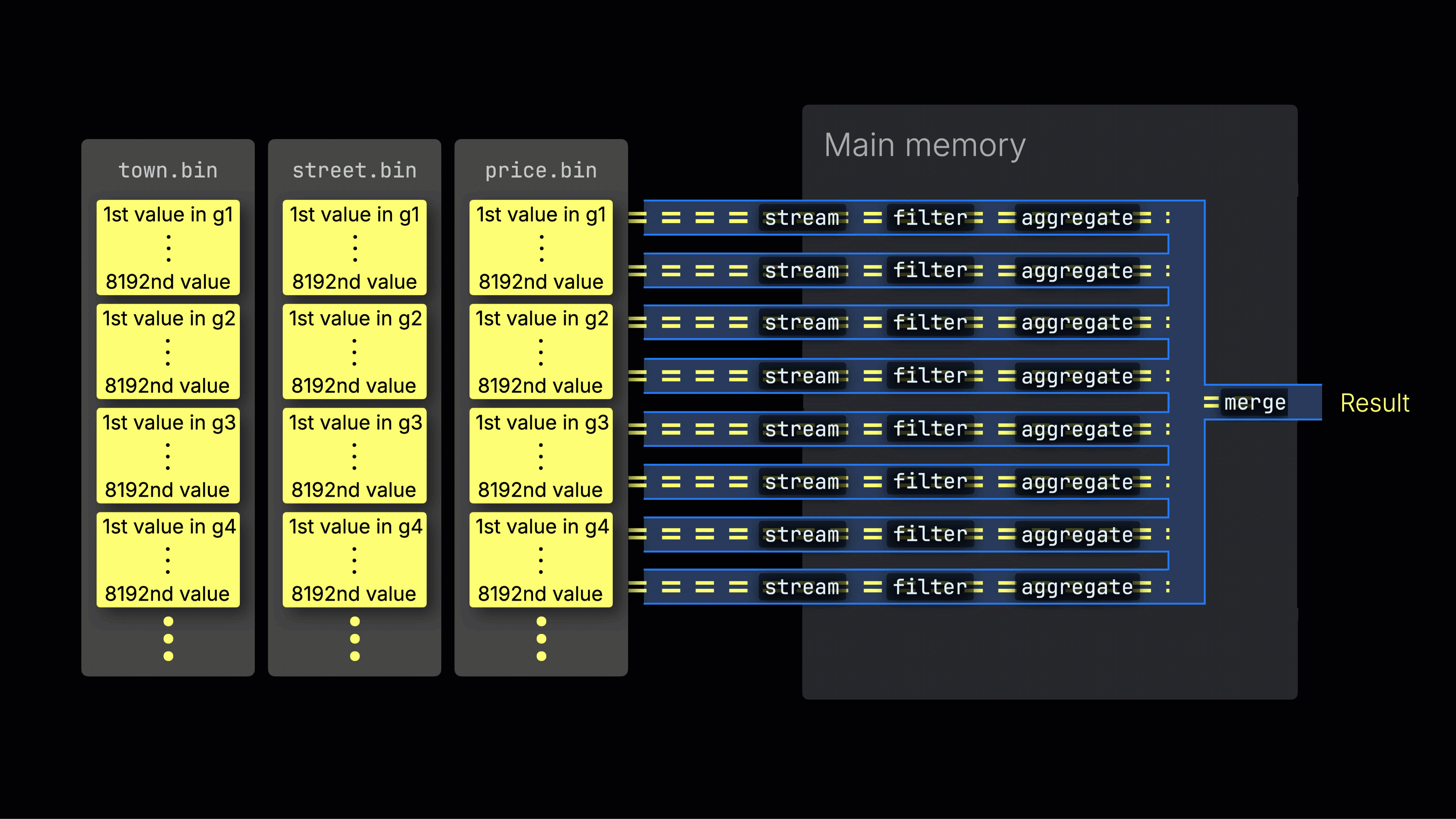
작업을 처리 레인에 효율적으로 분배하는 것이 CPU 활용도를 최대화하고 전체 쿼리 시간을 줄이는 핵심입니다.
세그먼트 테이블에서 쿼리 처리하기
테이블 데이터가 여러 서버에 세그먼트로 분산되어 있는 경우, 각 서버는 자신에게 할당된 세그먼트를 병렬로 처리합니다. 각 서버 내부에서는 위에서 설명한 것과 동일하게 로컬 데이터가 병렬 처리 레인에서 처리됩니다:
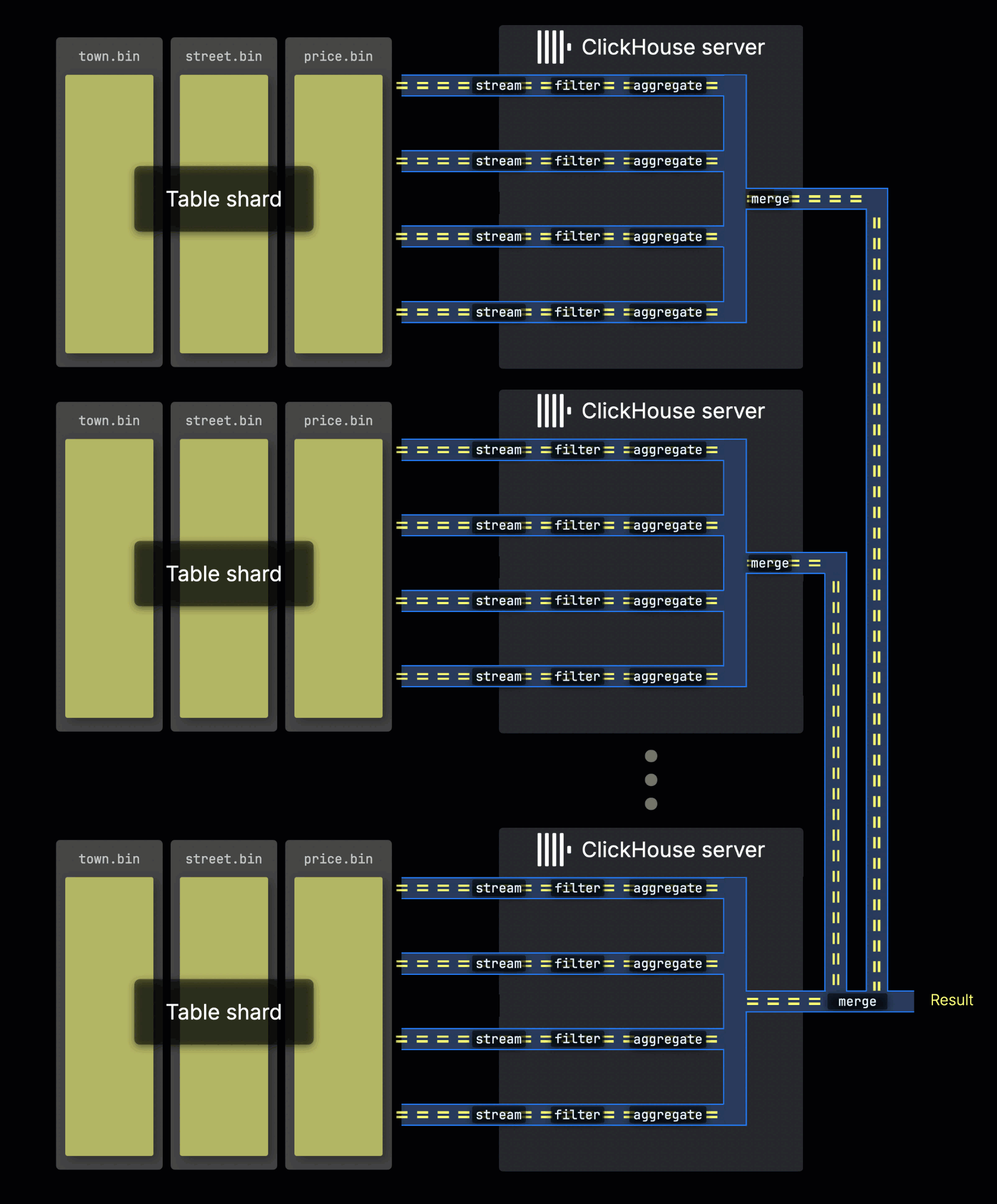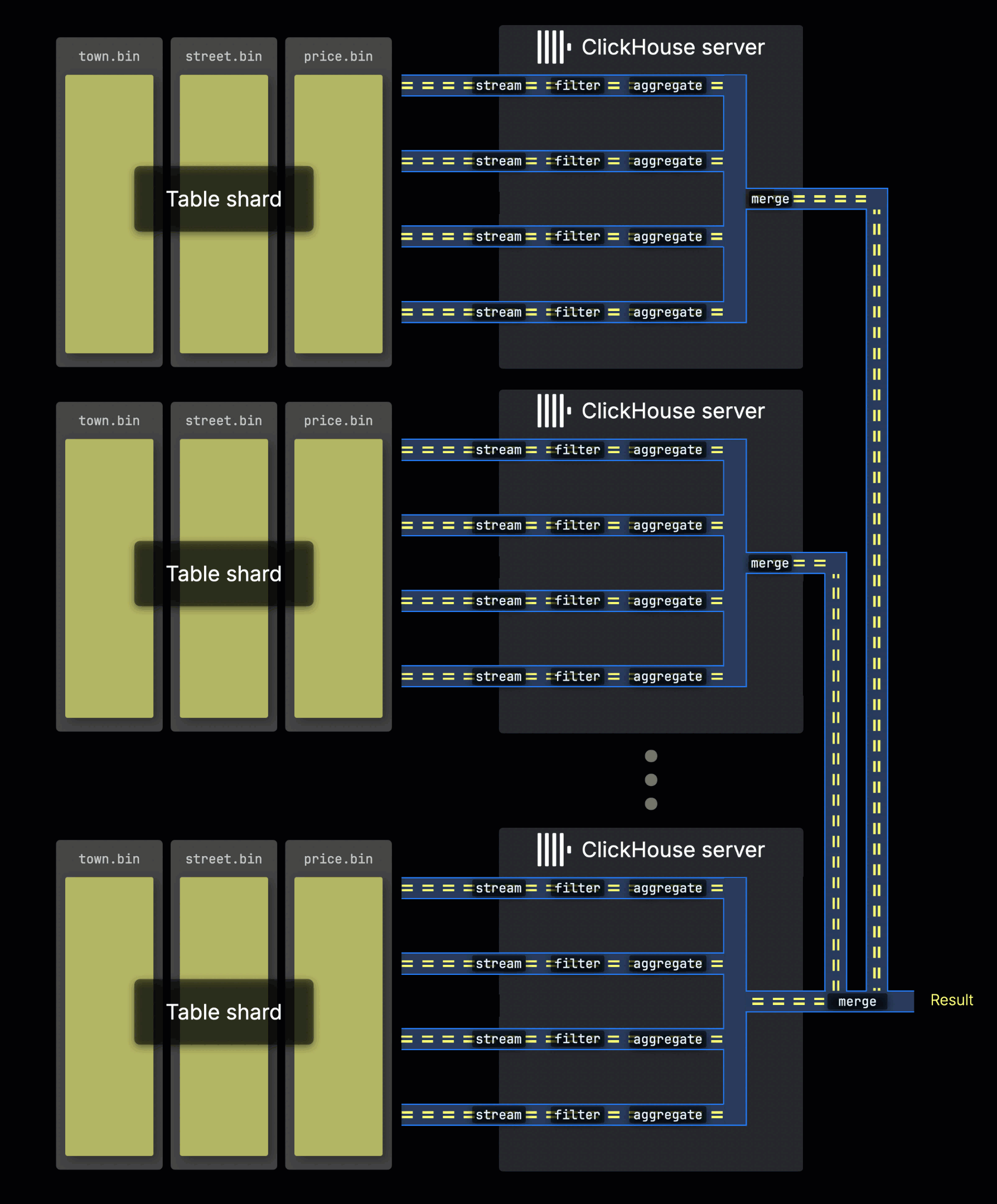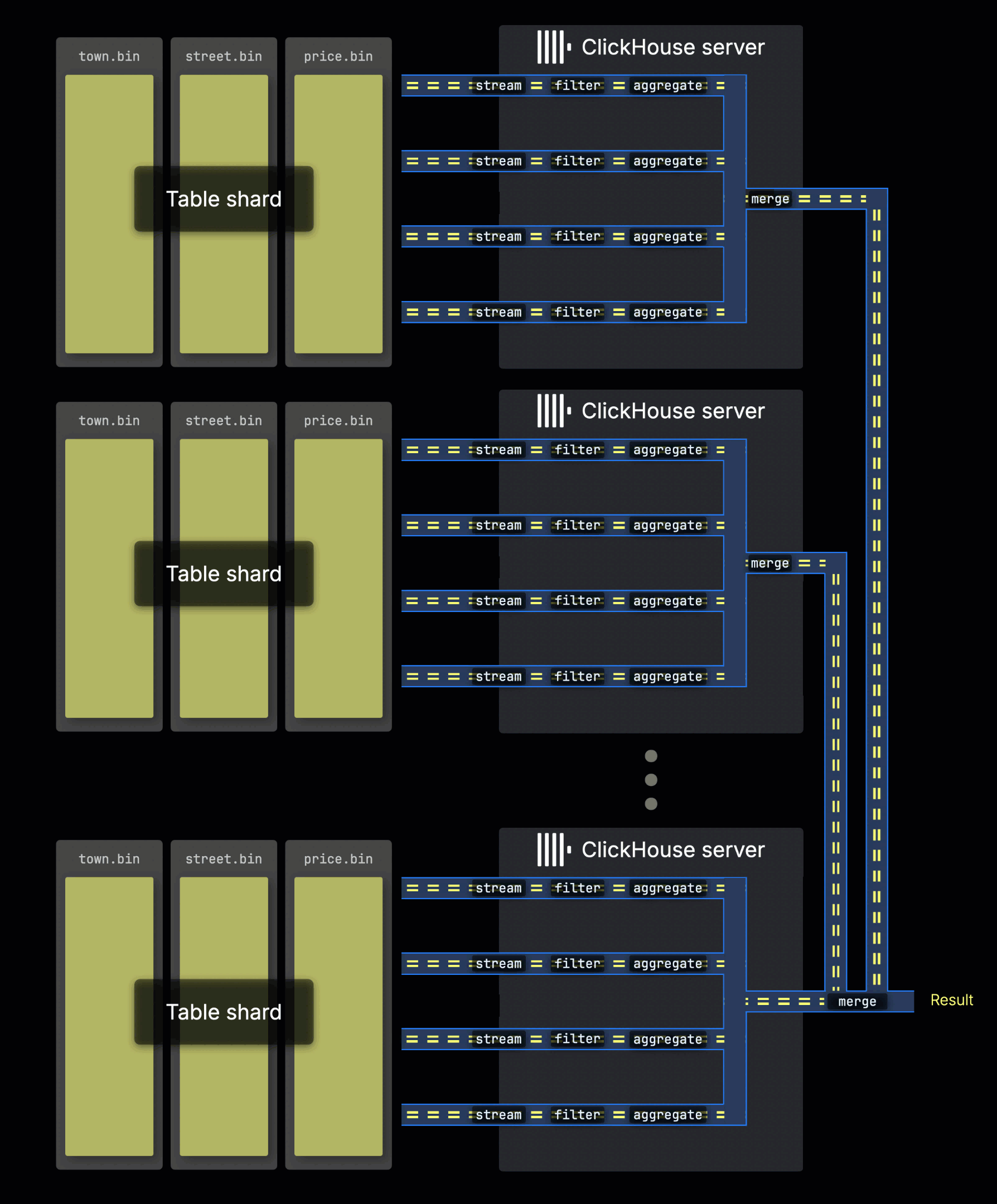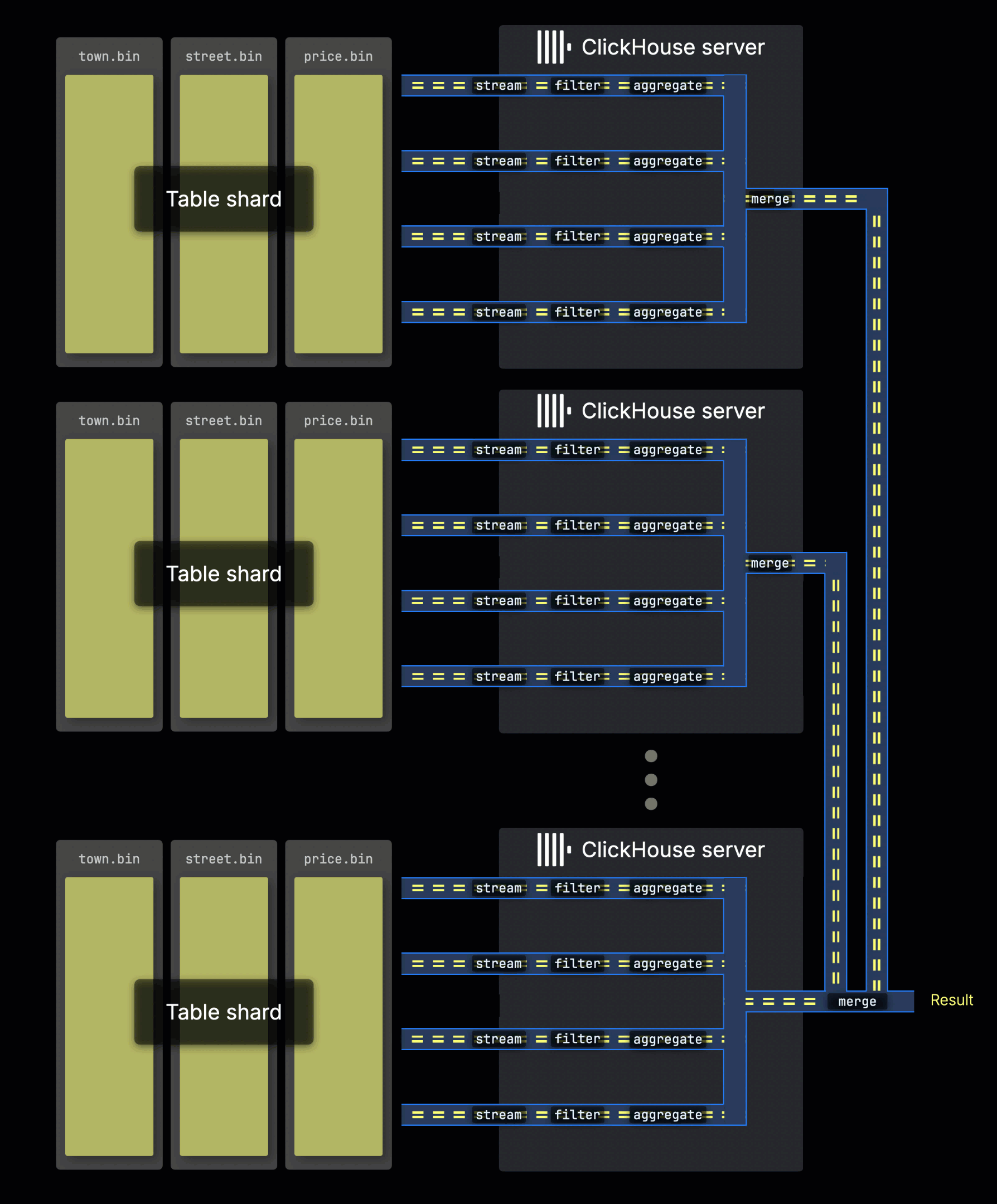
쿼리를 처음 수신한 서버는 각 세그먼트에서 생성된 모든 하위 결과를 수집한 후, 이를 결합하여 최종 전역 결과를 생성합니다.
쿼리 부하를 여러 세그먼트에 분산하면, 특히 높은 처리량 환경에서 병렬성을 수평으로 확장할 수 있습니다.
ClickHouse Cloud에서는 동일한 형태의 병렬성이 parallel replicas를 통해 구현됩니다. 이는 공유-없음(shared-nothing) 클러스터에서 세그먼트와 유사하게 동작합니다. 각 ClickHouse Cloud 레플리카(상태 비저장 컴퓨트 노드)는 데이터의 일부를 병렬로 처리하고, 독립적인 세그먼트와 마찬가지로 최종 결과에 기여합니다.
쿼리 병렬성 모니터링
다음 도구를 사용하여 쿼리가 사용 가능한 CPU 자원을 충분히 활용하는지 확인하고, 그렇지 않은 경우 그 원인을 진단할 수 있습니다.
이 예제는 59개의 CPU 코어가 있는 테스트 서버에서 실행하며, 이를 통해 ClickHouse의 쿼리 병렬 처리 기능을 충분히 보여줄 수 있습니다.
예제 쿼리가 어떻게 실행되는지 관찰하기 위해, 집계 쿼리를 수행하는 동안 ClickHouse 서버가 모든 trace 레벨 로그 엔트리를 반환하도록 설정할 수 있습니다. 이 데모에서는 쿼리의 조건절을 제거했습니다. 조건절이 남아 있으면 3개의 그래뉼만 처리되어, ClickHouse가 여러 개의 병렬 처리 레인을 활용하기에는 데이터가 충분하지 않기 때문입니다:
다음과 같이 확인할 수 있습니다.
- ① ClickHouse는 3개의 데이터 범위에 걸쳐 3,609개의 그래뉼(트레이스 로그에서 마크로 표시됨)을 읽어야 합니다.
- ② 59개의 CPU 코어를 사용하여 이 작업을 59개의 병렬 처리 스트림으로 분산합니다. 각 스트림은 하나의 레인에 대응합니다.
또는 EXPLAIN 절을 사용하여 집계 쿼리에 대한 물리 연산자 계획, 즉 「query pipeline」을 확인할 수도 있습니다.
참고: 위의 연산자 계획은 아래에서 위로 읽어야 합니다. 각 줄은 물리적 실행 계획의 한 단계를 나타내며, 맨 아래는 스토리지에서 데이터를 읽는 단계로 시작해서 위로 갈수록 최종 처리 단계로 끝납니다. × 59로 표시된 연산자는 59개의 병렬 처리 레인에서 서로 겹치지 않는 데이터 영역에 대해 동시에 실행됩니다. 이는 max_threads 값에 해당하며, 쿼리의 각 단계가 CPU 코어 전반에 걸쳐 어떻게 병렬화되는지를 보여 줍니다.
ClickHouse의 embedded web UI (/play 엔드포인트에서 사용 가능)에서는 위의 물리적 계획을 그래픽으로 시각화해 보여 줄 수 있습니다. 이 예시에서는 시각화를 간단하게 유지하기 위해 max_threads를 4로 설정하여, 4개의 병렬 처리 레인만 표시합니다:

참고: 시각화는 왼쪽에서 오른쪽으로 읽어야 합니다. 각 행은 데이터 블록을 스트리밍하면서 필터링, 집계, 최종 처리 단계와 같은 변환을 적용하는 병렬 처리 레인을 나타냅니다. 이 예시에서는 max_threads = 4 설정에 해당하는 네 개의 병렬 레인을 확인할 수 있습니다.
처리 레인 간 부하 분산
위 물리적 계획에서 Resize 연산자는 데이터 블록 스트림을 처리 레인 간에 재파티셔닝 및 재분배하여 각 처리 레인이 균등하게 활용되도록 합니다. 데이터 범위마다 쿼리 조건과 일치하는 행 수가 크게 다른 경우, 이러한 재분배는 특히 중요합니다. 그렇지 않으면 일부 레인은 과부하가 걸리고 다른 레인은 유휴 상태가 될 수 있습니다. 작업을 재분배하면 더 빠른 레인이 상대적으로 느린 레인의 처리를 효과적으로 보조하여 전체 쿼리 실행 시간을 최적화합니다.
max_threads가 항상 적용되지 않는 이유
앞에서 언급했듯이, n개의 병렬 처리 경로 수는 max_threads 설정에 의해 제어되며, 기본값은 서버에서 ClickHouse가 사용할 수 있는 CPU 코어 수와 동일합니다:
그러나 처리 대상으로 선택된 데이터 양에 따라 max_threads 값이 무시될 수 있습니다:
위의 연산자 플랜 발췌에서 볼 수 있듯이 max_threads가 59로 설정되어 있어도 ClickHouse는 데이터를 스캔할 때 30개의 동시 스트림만 사용합니다.
이제 쿼리를 실행해 보겠습니다:
위 출력에서 볼 수 있듯이, 이 쿼리는 231만 개의 행을 처리하고 13.66MB의 데이터를 읽었습니다. 이는 인덱스 분석 단계에서 ClickHouse가 처리할 대상으로 282개의 그래뉼을 선택했기 때문이며, 각 그래뉼에는 8,192개의 행이 포함되어 있어 총 약 231만 개의 행이 됩니다:
설정된 max_threads 값과 관계없이 ClickHouse는 추가 병렬 처리 경로를 사용할 만큼 충분한 데이터가 있을 때에만 이를 할당합니다. max_threads의 "max"는 상한선을 의미할 뿐, 실제로 사용되는 스레드 수를 보장하지는 않습니다.
「충분한 데이터」의 기준은 주로 두 개의 설정으로 결정되며, 각 처리 경로가 담당해야 하는 최소 행(기본값 163,840개) 수와 최소 바이트(기본값 2,097,152바이트) 수를 정의합니다.
공유 스토리지가 없는(shared-nothing) 클러스터의 경우:
공유 스토리지(예: ClickHouse Cloud)를 사용하는 클러스터의 경우:
- merge_tree_min_rows_for_concurrent_read_for_remote_filesystem
- merge_tree_min_bytes_for_concurrent_read_for_remote_filesystem
추가로, 읽기 작업 크기에 대한 엄격한 하한이 있으며, 다음 설정으로 제어됩니다:
프로덕션 환경에서 이 설정들을 수정하는 것은 권장하지 않습니다. 이 설정들은 max_threads가 실제 병렬 처리 수준을 항상 결정하지 않는 이유를 설명하기 위해서만 예시로 제시되었습니다.
데모를 위해 이러한 설정을 재정의하여 최대 동시성을 강제한 상태에서 물리 실행 계획을 살펴보겠습니다.
이제 ClickHouse는 데이터를 스캔하기 위해 59개의 동시 스트림을 사용하며, 설정된 max_threads를 완전히 준수합니다.
이는 작은 데이터셋에 대한 쿼리에서는 ClickHouse가 의도적으로 동시 실행 수준을 제한함을 보여줍니다. 비효율적인 실행이나 리소스 경합을 초래할 수 있으므로, 설정 재정의는 테스트 목적으로만 사용하고 운영 환경에서는 사용하지 않는 것이 좋습니다.
핵심 요약
- ClickHouse는
max_threads와 연결된 처리 레인(lane)을 사용해 쿼리를 병렬로 실행합니다. - 실제 사용되는 레인 수는 처리 대상으로 선택된 데이터의 크기에 따라 달라집니다.
EXPLAIN PIPELINE과 트레이스 로그를 사용해 레인 사용 현황을 분석하십시오.
추가 정보
ClickHouse가 쿼리를 어떻게 병렬로 실행하고, 대규모 환경에서 고성능을 어떻게 달성하는지 더 깊이 이해하고자 한다면 다음 자료를 참고하십시오:
-
Query Processing Layer – VLDB 2024 Paper (Web Edition) - 스케줄링, 파이프라이닝, 연산자 설계를 포함한 ClickHouse 내부 실행 모델에 대한 상세한 분석입니다.
-
Partial aggregation states explained - 부분 집계 상태가 처리 레인 전반에서 효율적인 병렬 실행을 어떻게 가능하게 하는지에 대한 기술적 심층 분석입니다.
-
ClickHouse 쿼리 처리 단계 전체를 자세히 설명하는 비디오 튜토리얼:
