테이블 파티션
ClickHouse의 테이블 파티션이란 무엇입니까?
파티션은 테이블의 데이터 파트를 MergeTree 엔진 계열에서 정리된 논리적 단위로 그룹화한 것입니다. 이는 시간 범위, 범주, 기타 주요 속성과 같이 특정 기준에 맞추어 개념적으로 의미 있게 데이터를 구성하는 방식입니다. 이러한 논리적 단위는 데이터를 더 쉽게 관리하고, 쿼리하고, 최적화할 수 있게 합니다.
PARTITION BY
테이블을 처음 정의할 때 PARTITION BY 절을 사용하여 파티셔닝을 활성화할 수 있습니다. 이 절에는 어떤 컬럼이든 대상으로 하는 SQL 표현식을 포함할 수 있으며, 이 표현식의 결과에 따라 각 행이 속하는 파티션이 결정됩니다.
이를 설명하기 위해, PARTITION BY toStartOfMonth(date) 절을 추가하여 What are table parts 예제 테이블을 확장합니다. 이 절은 부동산 매매가 발생한 월을 기준으로 테이블의 데이터 파트를 구성합니다:
ClickHouse SQL Playground에서 이 테이블에 대해 쿼리를 실행할 수 있습니다.
디스크 상의 구조
테이블에 하나의 행 집합이 삽입될 때, 삽입된 모든 행을 포함하는 단일 데이터 파트만을 생성하는 것(여기에 설명된 것처럼, 적어도 하나의 데이터 파트) 대신, ClickHouse는 삽입된 행들에서 서로 다른 파티션 키 값마다 하나의 새로운 데이터 파트를 생성합니다:
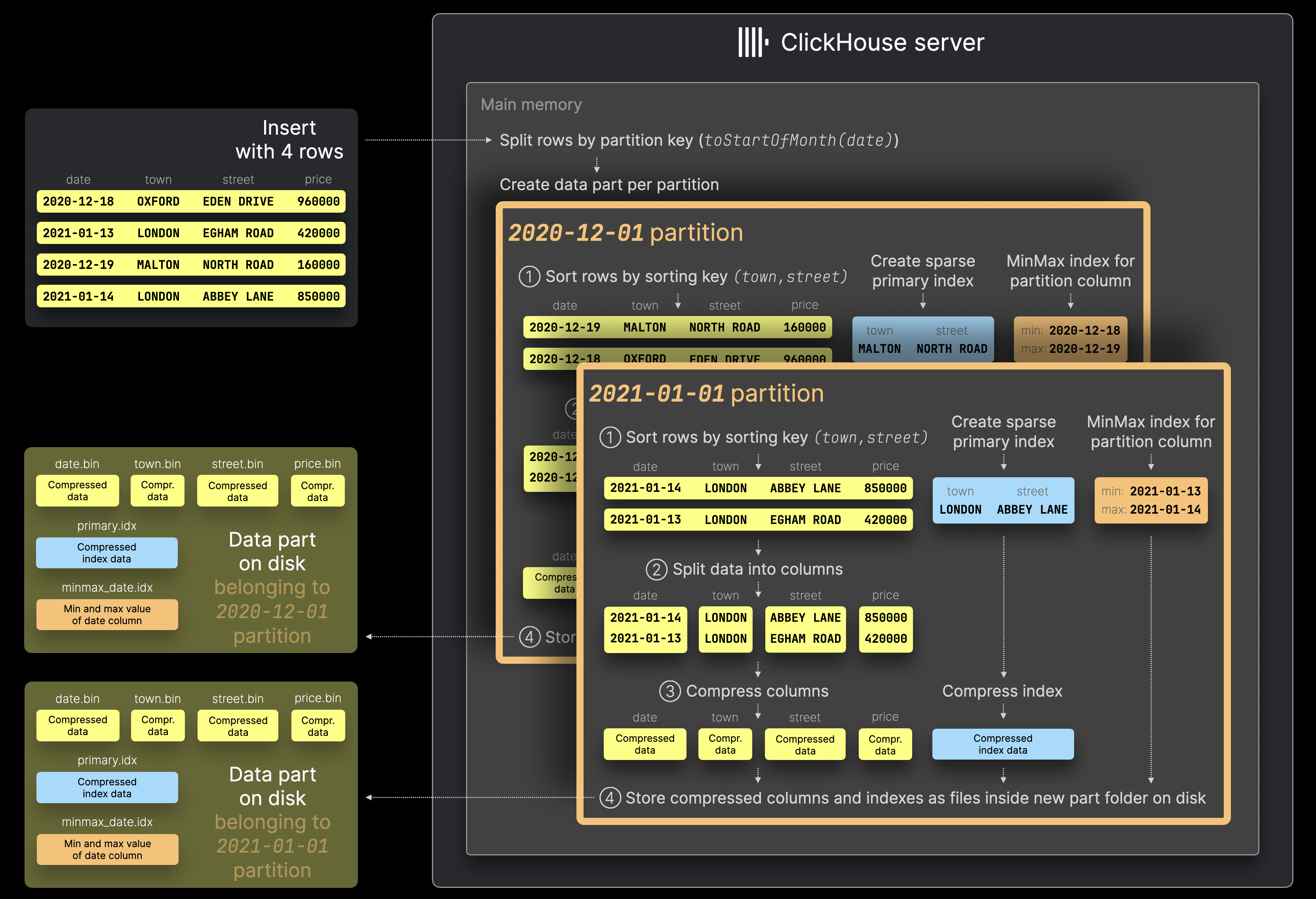
ClickHouse 서버는 위 다이어그램에 스케치된 예시 삽입문의 4개 행을 먼저 파티션 키 값 toStartOfMonth(date)에 따라 분할합니다.
그런 다음, 식별된 각 파티션에 대해, 행들을 여러 순차적 단계(① 정렬, ② 컬럼 단위 분할, ③ 압축, ④ 디스크에 기록)를 수행하여 일반적인 방식대로 처리합니다.
참고로, 파티셔닝이 활성화된 경우, ClickHouse는 각 데이터 파트마다 자동으로 MinMax 인덱스를 생성합니다. 이는 파티션 키 표현식에 사용된 각 테이블 컬럼에 대해 생성되는 파일로, 해당 데이터 파트 내에서 그 컬럼의 최소값과 최대값을 담고 있습니다. 추가 설명은 여기에서 확인할 수 있습니다.
파티션별 병합
파티션이 활성화되어 있으면 ClickHouse는 파티션 간이 아니라 각 파티션 내부에서만 데이터 파트를 병합합니다. 위에서 사용한 예제 테이블을 기준으로 이를 도식화하면 다음과 같습니다:
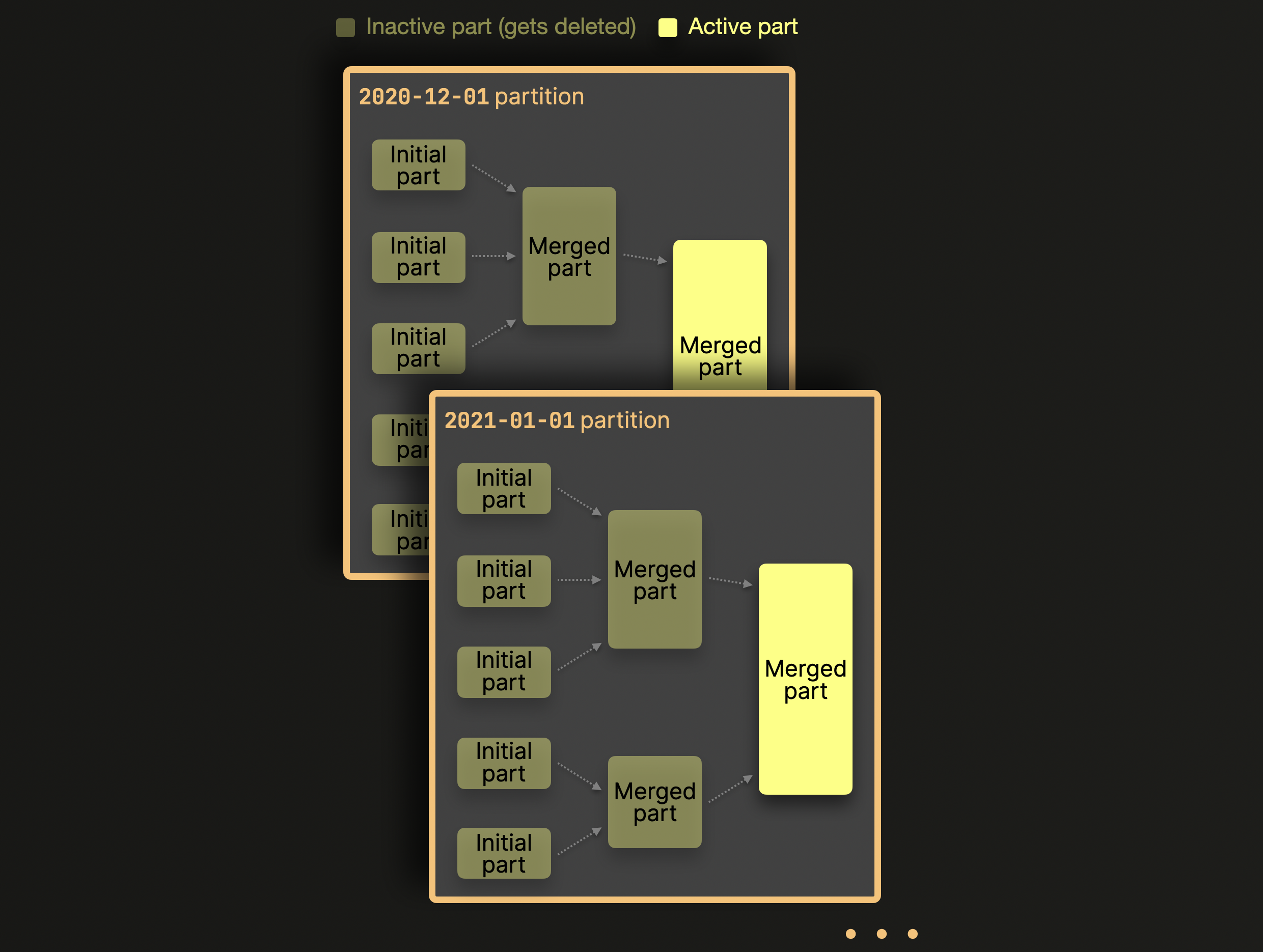
위 다이어그램에서 보듯이, 서로 다른 파티션에 속한 파트는 결코 병합되지 않습니다. 카디널리티가 매우 높은 파티션 키를 선택하면 수천 개의 파티션에 파트가 흩어지게 되고, 이 파트들은 병합 후보가 되지 않아 사전에 설정된 한계를 초과하게 되며, 악명 높은 Too many ^^parts^^ 오류가 발생합니다. 이 문제를 해결하는 방법은 간단합니다. 카디널리티가 1000..10000 이하 수준인 적절한 파티션 키를 선택하면 됩니다.
파티션 모니터링
가상 컬럼 _partition_value를 사용하여 예제 테이블에서 현재 존재하는 모든 고유한 파티션 목록을 쿼리할 수 있습니다.
또는 ClickHouse는 system.parts 시스템 테이블에서 모든 테이블의 모든 파트와 파티션을 추적합니다. 위의 예제 테이블에 대해, 다음 쿼리는 모든 파티션 목록과 함께 각 파티션별 현재 활성 파트 개수 및 해당 파트들에 포함된 행 수의 합계를 반환합니다.
테이블 파티션은 어떤 용도로 사용됩니까?
데이터 관리
ClickHouse에서 파티셔닝은 주로 데이터 관리 기능입니다. 파티션 표현식에 따라 데이터를 논리적으로 구성하면 각 파티션을 독립적으로 관리할 수 있습니다. 예를 들어, 위의 예시 테이블에 적용된 파티셔닝 방식은 TTL 규칙을 사용해 오래된 데이터를 자동으로 제거함으로써 메인 테이블에 최근 12개월치 데이터만 유지하는 시나리오를 구현할 수 있도록 합니다(DDL 문에서 추가된 마지막 행을 참조하십시오).
테이블이 toStartOfMonth(date)로 파티션되어 있으므로, TTL 조건을 만족하는 전체 파티션(테이블 파트 집합)이 삭제되어 정리 작업이 더 효율적으로 수행되며, 파트를 다시 쓸 필요가 없습니다.
마찬가지로, 오래된 데이터를 삭제하는 대신 보다 비용 효율적인 스토리지 계층으로 자동이고 효율적으로 이동하도록 설정할 수도 있습니다:
쿼리 최적화
파티션은 쿼리 성능 향상에 도움이 될 수 있지만, 이는 접근 패턴에 크게 좌우됩니다. 쿼리가 소수의 파티션(이상적으로는 1개)만을 대상으로 하는 경우 성능이 향상될 수 있습니다. 이는 일반적으로 파티셔닝 키가 기본 키에 포함되어 있지 않으면서, 아래 예시 쿼리에서처럼 해당 키로 필터링하는 경우에만 유용합니다.
이 쿼리는 위에서 사용한 예제 테이블에 대해 실행되며, 테이블의 파티션 키에 사용된 컬럼(date)과 기본 키에 사용된 컬럼(town)에 모두 필터를 적용하여 2020년 12월 런던에서 판매된 모든 부동산의 최고 가격을 계산합니다 (date는 기본 키의 일부가 아닙니다).
ClickHouse는 이 쿼리를 처리할 때, 관련 없는 데이터를 평가하지 않기 위해 일련의 프루닝(pruning) 기법을 적용합니다:
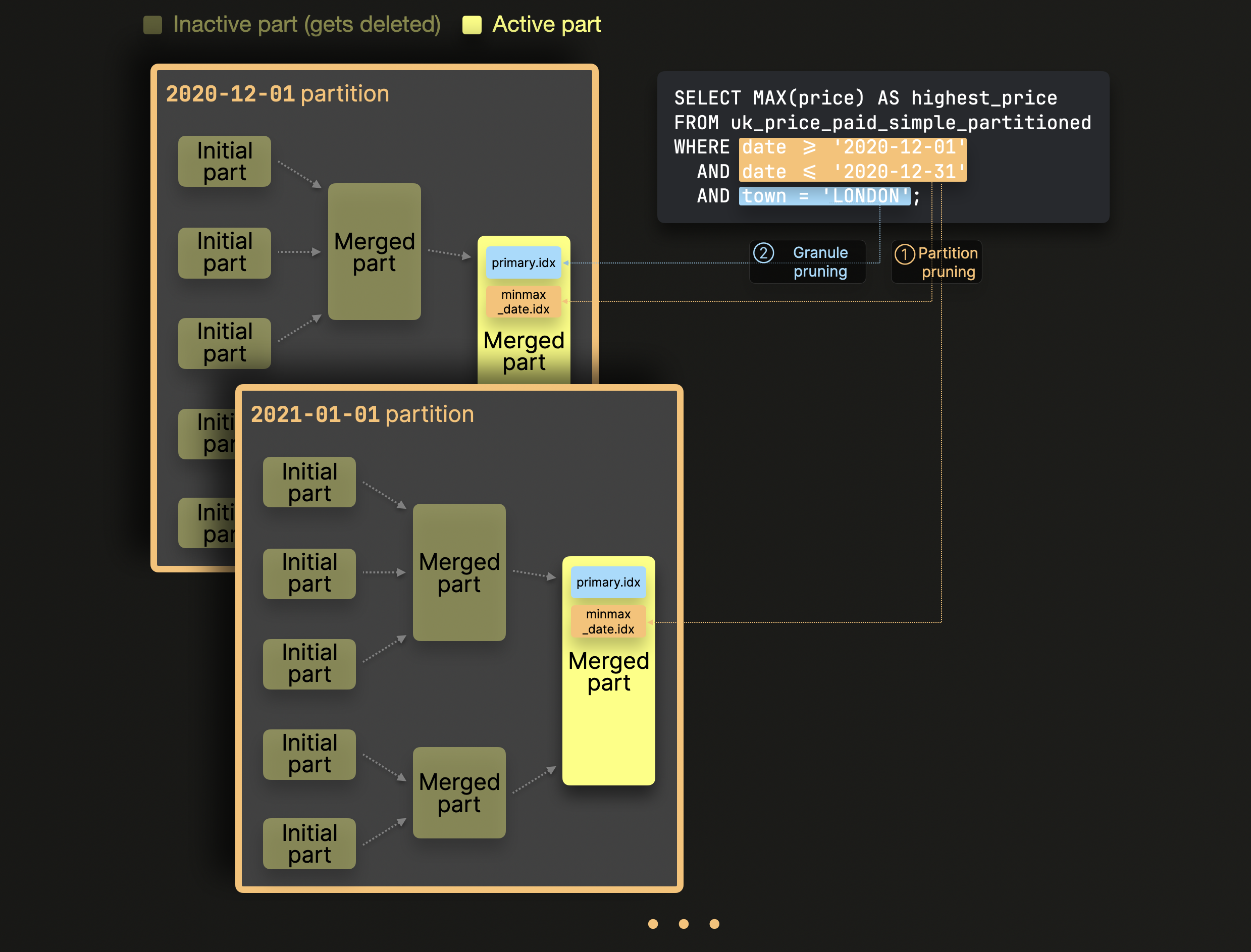
① 파티션 프루닝(Partition pruning): MinMax 인덱스를 사용하여, 테이블의 파티션 키에 사용된 컬럼에 대한 쿼리의 필터와 논리적으로 일치할 수 없는 전체 파티션(파트 집합)을 무시합니다.
② 그래뉼 프루닝(Granule pruning): ①단계 이후 남은 데이터 파트에 대해서는 기본 인덱스(primary index)를 사용하여, 테이블의 기본 키에 사용된 컬럼에 대한 쿼리의 필터와 논리적으로 일치할 수 없는 모든 그래뉼(행 블록)을 무시합니다.
이러한 데이터 프루닝 단계를, 위의 예제 쿼리에 대한 물리적 쿼리 실행 계획을 EXPLAIN 절을 통해 검사함으로써 확인할 수 있습니다:
위 출력은 다음을 보여 줍니다:
① 파티션 프루닝: 위 EXPLAIN 출력의 7행부터 18행은 ClickHouse가 먼저 date 필드의 MinMax index를 사용하여, 3257개의 기존 granules (행 블록) 가운데 쿼리의 date 필터와 일치하는 행을 포함한 11개 그래뉼을 식별하며, 이 11개 그래뉼은 활성 데이터 파트 436개 중 1개에 저장되어 있다는 것을 보여 줍니다.
② 그래뉼 프루닝: 위 EXPLAIN 출력의 19행부터 24행은, 단계 ①에서 식별된 데이터 파트의 primary index (town 필드에 대해 생성됨)를 ClickHouse가 이후 사용하여, (쿼리의 town 필터와도 잠재적으로 일치하는 행을 포함할 수 있는) 그래뉼 개수를 11개에서 1개로 추가로 줄인다는 것을 나타냅니다. 이 내용은 실행한 쿼리에 대해 위에서 출력한 ClickHouse client 결과에도 반영되어 있습니다.
즉, ClickHouse가 쿼리 결과를 계산하기 위해 1개의 그라뉼( 8192 행으로 구성된 블록)을 스캔하고 처리하는 데 6밀리초가 걸렸다는 의미입니다.
파티셔닝은 주로 데이터 관리 기능입니다
모든 파티션을 대상으로 쿼리를 실행하면, 동일한 쿼리를 파티셔닝되지 않은 테이블에서 실행하는 것보다 일반적으로 더 느려집니다.
파티셔닝을 사용하면 데이터가 보통 더 많은 데이터 파트에 분산되며, 이로 인해 ClickHouse가 더 많은 양의 데이터를 스캔하고 처리해야 하는 경우가 많습니다.
이는 동일한 쿼리를 What are table parts 예제 테이블(파티셔닝이 비활성화된 테이블)과, 위에서 사용한 현재 예제 테이블(파티셔닝이 활성화된 테이블) 모두에서 실행해 보면 확인할 수 있습니다. 두 테이블은 동일한 데이터와 행 수를 포함합니다:
그러나 파티션을 활성화한 테이블은 다음에서 볼 수 있듯이 더 많은 활성 데이터 파트를 가집니다. 이는 앞에서 언급했듯이 ClickHouse가 파티션 내에서만 데이터 파트를 병합하고 파티션 간에는 병합하지 않기 때문입니다:
위에서 살펴본 것처럼, 파티션된 테이블 uk_price_paid_simple_partitioned에는 600개가 넘는 파티션이 있으며, 그 결과 활성 데이터 파트가 600,306개에 이릅니다. 반면, 비파티션 테이블 uk_price_paid_simple의 모든 초기 데이터 파트는 백그라운드 머지 작업을 통해 하나의 활성 파트로 머지될 수 있습니다.
위에서 살펴본 예시 쿼리에 대해 파티션 필터 없이 파티션된 테이블 전체를 대상으로 실행했을 때, EXPLAIN 절을 사용하여 물리적 쿼리 실행 계획을 확인하면, 아래 출력의 19행과 20행에서 ClickHouse가 존재하는 3,257개의 그래뉼 (행 블록) 중 671개, 그리고 존재하는 활성 데이터 파트 436개 중 431개에 쿼리의 필터와 일치할 가능성이 있는 행이 포함되어 있다고 판단했음을 확인할 수 있으며, 따라서 해당 그래뉼과 파트가 쿼리 엔진에 의해 스캔되고 처리됩니다.
파티션이 없는 테이블에서 동일한 예제 쿼리를 실행했을 때의 물리적 쿼리 실행 계획은 아래 출력의 11행과 12행에서 확인할 수 있듯이, ClickHouse가 테이블의 단일 활성 데이터 파트에 존재하는 3083개의 행 블록 중 241개를 쿼리의 필터와 일치하는 행을 포함할 가능성이 있는 것으로 식별했음을 보여줍니다:
파티션된 테이블 버전에서 쿼리를 실행하면, ClickHouse는 약 550만 행에 해당하는 671개의 행 블록을 90밀리초 만에 스캔하고 처리합니다:
반면 파티션이 없는 테이블에서 쿼리를 실행하면, ClickHouse는 약 200만 행에 해당하는 241개의 블록을 12밀리초 만에 스캔하고 처리합니다:
