ClickStack OpenTelemetry Collector
이 페이지에서는 공식 ClickStack OpenTelemetry(OTel) collector의 구성 세부 사항을 설명합니다.
Collector roles
OpenTelemetry collector는 두 가지 주요 역할로 배포할 수 있습니다:
-
Agent - 에이전트 인스턴스는 서버나 Kubernetes 노드와 같이 엣지에서 데이터를 수집하거나, OpenTelemetry SDK로 계측된 애플리케이션으로부터 직접 이벤트를 수신합니다. 후자의 경우 에이전트 인스턴스는 애플리케이션과 함께, 또는 애플리케이션과 동일한 호스트(사이드카 또는 데몬셋 등)에서 실행됩니다. 에이전트는 수집한 데이터를 직접 ClickHouse로 전송하거나 게이트웨이 인스턴스로 전송할 수 있습니다. 전자의 경우 이를 Agent 배포 패턴이라고 부릅니다.
-
Gateway - 게이트웨이 인스턴스는 (예: Kubernetes의 배포와 같은) 독립 실행형 서비스를 제공하며, 일반적으로 클러스터별, 데이터 센터별 또는 리전별로 구성됩니다. 이 인스턴스들은 단일 OTLP 엔드포인트를 통해 애플리케이션(또는 에이전트 역할의 다른 collector)에서 이벤트를 수신합니다. 일반적으로 여러 개의 게이트웨이 인스턴스를 배포하고, 기성 로드 밸런서를 사용하여 인스턴스 간에 부하를 분산합니다. 모든 에이전트와 애플리케이션이 이 단일 엔드포인트로 시그널을 전송하는 경우, 이를 Gateway 배포 패턴이라고 부릅니다.
중요: ClickStack의 기본 배포판을 포함한 collector는, 에이전트 또는 SDK로부터 데이터를 수신하는 게이트웨이 역할을 수행한다고 가정합니다.
에이전트 역할로 OTel collector를 배포하는 사용자는 일반적으로 ClickStack 버전이 아닌 collector의 기본 contrib 배포판을 사용하지만, Fluentd 및 Vector와 같은 다른 OTLP 호환 기술을 자유롭게 사용할 수 있습니다.
컬렉터 배포
- 관리형 ClickStack
- 오픈소스 ClickStack
가능한 경우 Managed ClickStack으로 전송할 때 게이트웨이 역할을 수행하도록 collector용 공식 ClickStack 배포판 사용을 권장합니다. 별도로 준비한 collector를 사용하려는 경우에는 ClickHouse exporter가 포함되어 있는지 확인하십시오.
독립 실행 모드로 ClickStack 배포판의 OTel connector를 배포하려면 다음 Docker 명령을 실행하십시오:
ClickStack 이미지는 이제 clickhouse/clickstack-* 형식으로 배포됩니다 (이전에는 docker.hyperdx.io/hyperdx/*).
CLICKHOUSE_ENDPOINT, CLICKHOUSE_USERNAME, CLICKHOUSE_PASSWORD 환경 변수를 사용하여 대상 ClickHouse 인스턴스를 재정의할 수 있습니다. CLICKHOUSE_ENDPOINT에는 프로토콜과 포트를 포함한 전체 ClickHouse Cloud HTTP 엔드포인트를 지정해야 합니다. 예를 들어 https://99rr6dm6v3.us-central1.gcp.clickhouse.cloud:8443 와 같습니다.
Managed ClickStack 자격 증명을 확인하는 방법에 대한 자세한 내용은 여기를 참조하십시오.
프로덕션 환경에서는 적절한 자격 증명을 가진 사용자를 사용해야 합니다.
구성 수정
Managed ClickStack 인스턴스 구성
OpenTelemetry collector를 포함한 모든 docker 이미지는 CLICKHOUSE_ENDPOINT, CLICKHOUSE_USERNAME, CLICKHOUSE_PASSWORD 환경 변수를 통해 Managed ClickStack 인스턴스를 사용하도록 구성할 수 있습니다.
예를 들어 all-in-one 이미지의 경우:
collector 구성 확장하기
ClickStack 배포판의 OTel collector는 사용자 정의 구성 파일을 마운트하고 환경 변수를 설정하여 기본 구성을 확장할 수 있도록 지원합니다.
사용자 정의 receiver, processor 또는 pipeline을 추가하려면:
- 추가 구성이 포함된 사용자 정의 구성 파일을 생성합니다.
- 파일을
/etc/otelcol-contrib/custom.config.yaml경로에 마운트합니다. - 환경 변수
CUSTOM_OTELCOL_CONFIG_FILE=/etc/otelcol-contrib/custom.config.yaml를 설정합니다.
사용자 정의 구성 예시:
독립 실행형 컬렉터를 사용하여 배포:
사용자 정의 구성에서는 새로운 receiver, processor, pipeline만 정의합니다. 기본 processor인 memory_limiter, batch와 exporter인 clickhouse는 이미 정의되어 있으므로 이름으로만 참조하면 됩니다. 사용자 정의 구성은 기본 구성과 병합되며, 기존 구성 요소를 덮어쓸 수 없습니다.
보다 복잡한 구성이 필요한 경우 기본 ClickStack collector 구성과 ClickHouse exporter 문서를 참고하십시오.
구성 구조
receivers, operators, processors를 포함한 OTel collector 구성에 대한 자세한 내용은 공식 OpenTelemetry collector 문서를 참고하십시오.
Docker Compose
Docker Compose를 사용하는 경우, 위와 동일한 환경 변수를 사용하여 collector 설정을 수정합니다:
독립형 배포로 OpenTelemetry collector를 직접 관리하는 경우(예: HyperDX 전용 배포판을 사용하는 경우), 가능하다면 게이트웨이 역할에는 ClickStack에서 제공하는 collector 공식 배포판을 계속 사용하는 것을 권장합니다. 하지만 직접 준비한 collector를 사용하기로 한 경우에는, ClickHouse exporter가 포함되어 있는지 확인하십시오.
독립형 모드에서 OTel connector의 ClickStack 배포판을 배포하려면, 다음 Docker 명령을 실행합니다.
ClickStack 이미지는 이제 clickhouse/clickstack-* 형태로 게시됩니다(이전에는 docker.hyperdx.io/hyperdx/*).
환경 변수 CLICKHOUSE_ENDPOINT, CLICKHOUSE_USERNAME, CLICKHOUSE_PASSWORD를 사용하여 대상 ClickHouse 인스턴스를 재정의할 수 있습니다. CLICKHOUSE_ENDPOINT에는 프로토콜과 포트를 포함한 전체 ClickHouse HTTP 엔드포인트를 지정해야 합니다. 예: http://localhost:8123.
이 환경 변수들은 커넥터가 포함된 모든 Docker 배포본에서 사용할 수 있습니다.
OPAMP_SERVER_URL은 HyperDX 배포 주소를 가리켜야 합니다. 예: http://localhost:4320. HyperDX는 기본적으로 포트 4320에서 /v1/opamp 경로로 OpAMP(Open Agent Management Protocol) 서버를 노출합니다. HyperDX가 실행 중인 컨테이너에서 이 포트를 반드시 노출해야 합니다(예: -p 4320:4320 사용).
수집기가 OpAMP 포트에 연결하려면 HyperDX 컨테이너에서 해당 포트를 노출해야 합니다(예: -p 4320:4320). 로컬 테스트의 경우, OSX 사용자는 OPAMP_SERVER_URL=http://host.docker.internal:4320로 설정할 수 있습니다. Linux 사용자는 --network=host 옵션으로 수집기 컨테이너를 시작할 수 있습니다.
운영 환경에서는 적절한 자격 증명을 가진 사용자 계정을 사용해야 합니다.
Modifying configuration
Configuring ClickHouse instance
OpenTelemetry collector를 포함하는 모든 Docker 이미지는 OPAMP_SERVER_URL, CLICKHOUSE_ENDPOINT, CLICKHOUSE_USERNAME, CLICKHOUSE_PASSWORD 환경 변수를 통해 ClickHouse 인스턴스를 사용하도록 구성할 수 있습니다:
예를 들어 all-in-one 이미지는 다음과 같습니다:
collector 구성 확장하기
ClickStack 배포판의 OTel collector는 사용자 정의 구성 파일을 마운트하고 환경 변수를 설정하여 기본 구성을 확장할 수 있도록 지원합니다.
사용자 정의 receiver, processor 또는 pipeline을 추가하려면:
- 추가 구성이 포함된 사용자 정의 구성 파일을 생성합니다.
- 파일을
/etc/otelcol-contrib/custom.config.yaml경로에 마운트합니다. - 환경 변수
CUSTOM_OTELCOL_CONFIG_FILE=/etc/otelcol-contrib/custom.config.yaml를 설정합니다.
사용자 정의 구성 예시:
독립 실행형 컬렉터를 사용하여 배포:
사용자 정의 구성에서는 새로운 receiver, processor, pipeline만 정의합니다. 기본 processor인 memory_limiter, batch와 exporter인 clickhouse는 이미 정의되어 있으므로 이름으로만 참조하면 됩니다. 사용자 정의 구성은 기본 구성과 병합되며, 기존 구성 요소를 덮어쓸 수 없습니다.
보다 복잡한 구성이 필요한 경우 기본 ClickStack collector 구성과 ClickHouse exporter 문서를 참고하십시오.
구성 구조
receivers, operators, processors를 포함한 OTel collector 구성에 대한 자세한 내용은 공식 OpenTelemetry collector 문서를 참고하십시오.
Docker Compose
Docker Compose를 사용하는 경우 위와 동일한 환경 변수를 사용하여 콜렉터 구성을 수정하십시오.
수집기 보안 설정
- Managed ClickStack
- Open Source ClickStack
기본적으로 ClickStack OpenTelemetry Collector는 오픈 소스 배포판 외부에 배포될 때 보안 구성이 되어 있지 않으며, OTLP 포트에서 인증을 요구하지 않습니다.
수집을 보호하려면 OTLP_AUTH_TOKEN 환경 변수를 사용하여 수집기를 배포할 때 인증 토큰을 지정하십시오. 예시는 다음과 같습니다:
또한 다음과 같은 구성을 권장합니다.
- 수집기가 ClickHouse와 HTTPS를 통해 통신하도록 구성합니다.
- 아래 내용을 참고하여, 권한이 제한된 수집 전용 사용자를 생성합니다.
- OTLP 엔드포인트에 TLS를 활성화하여 SDK/에이전트와 수집기 간 통신이 암호화되도록 합니다. 이는 사용자 정의 수집기 구성을 통해 설정할 수 있습니다.
수집 전용 사용자 생성
Managed ClickStack으로 수집하기 위해 OTel collector용 전용 데이터베이스와 사용자를 생성할 것을 권장합니다. 이 사용자에게는 ClickStack에서 생성 및 사용되는 테이블을 생성하고 데이터 삽입을 수행할 수 있는 권한이 있어야 합니다.
이는 수집기가 otel 데이터베이스를 사용하도록 구성되어 있다고 가정합니다. 이는 HYPERDX_OTEL_EXPORTER_CLICKHOUSE_DATABASE 환경 변수를 통해 제어할 수 있습니다. 이 값을 다른 환경 변수와 동일한 방식으로 수집기에 전달하십시오.
ClickStack 배포판의 OpenTelemetry collector는 OpAMP(Open Agent Management Protocol)에 대한 내장 지원을 포함하고 있으며, 이를 사용하여 OTLP 엔드포인트를 안전하게 구성하고 관리합니다. 시작 시 OPAMP_SERVER_URL 환경 변수를 제공해야 하며, 이는 OpAMP API가 /v1/opamp에 호스팅되어 있는 HyperDX 앱을 가리켜야 합니다.
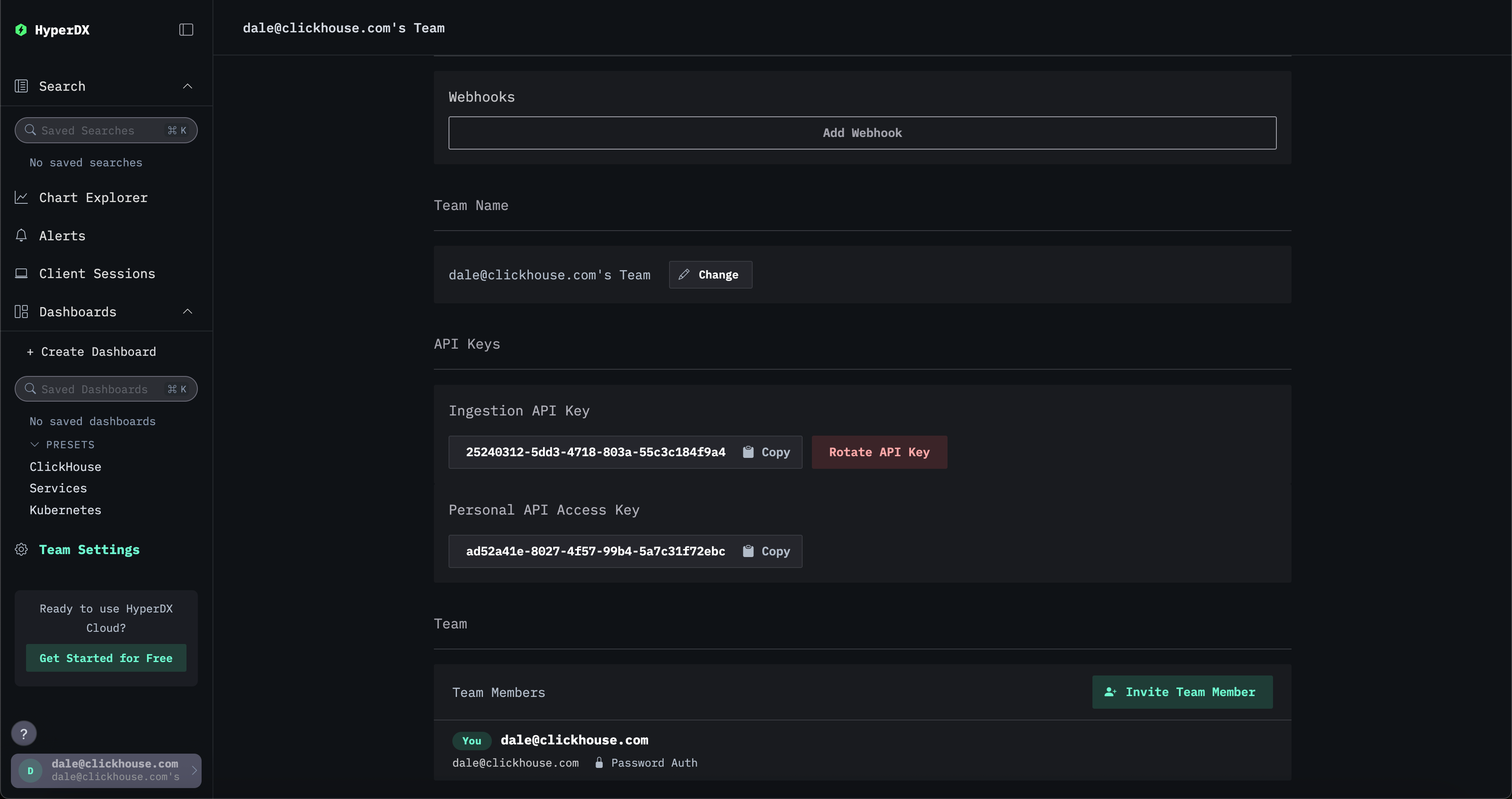
이 통합을 통해 HyperDX 앱이 배포될 때 자동으로 생성되는 수집 API key를 사용하여 OTLP 엔드포인트를 보호할 수 있습니다. 수집기에 전송되는 모든 텔레메트리 데이터에는 인증을 위해 이 API key가 포함되어야 합니다. 이 키는 HyperDX 앱의 Team Settings → API Keys에서 확인할 수 있습니다.
배포를 추가로 보호하기 위해 다음 구성을 권장합니다.
- 수집기가 ClickHouse와 HTTPS를 통해 통신하도록 구성합니다.
- 아래 내용을 참고하여, 권한이 제한된 수집 전용 사용자를 생성합니다.
- OTLP 엔드포인트에 TLS를 활성화하여 SDK/에이전트와 수집기 간 통신이 암호화되도록 합니다. 이는 사용자 정의 수집기 구성을 통해 설정할 수 있습니다.
수집 전용 사용자 생성
ClickHouse로 수집하기 위해 OTel collector용 전용 데이터베이스와 사용자를 생성할 것을 권장합니다. 이 사용자에게는 ClickStack에서 생성 및 사용되는 테이블을 생성하고 데이터 삽입을 수행할 수 있는 권한이 있어야 합니다.
이는 수집기가 otel 데이터베이스를 사용하도록 구성되어 있다고 가정합니다. 이는 HYPERDX_OTEL_EXPORTER_CLICKHOUSE_DATABASE 환경 변수를 통해 제어할 수 있습니다. 이 값을 수집기를 호스팅하는 이미지에 다른 환경 변수와 동일한 방식으로 전달하십시오.
처리 - 필터링, 변환, 보강
수집 중에는 이벤트 메시지를 필터링하고 변환하며 보강하려는 요구가 필연적으로 발생합니다. ClickStack 커넥터의 설정은 수정할 수 없으므로, 추가적인 이벤트 필터링과 처리가 필요한 경우 다음 둘 중 하나를 권장합니다.
- 필터링과 처리를 수행하는 자체 버전의 OTel collector를 배포하고, OTLP를 통해 이벤트를 ClickStack collector로 전송하여 ClickHouse에 수집합니다.
- 자체 버전의 OTel collector를 배포하고 ClickHouse exporter를 사용하여 이벤트를 ClickHouse로 직접 전송합니다.
OTel collector로 처리를 수행하는 경우 게이트웨이 인스턴스에서 변환을 수행하고, 에이전트 인스턴스에서 수행되는 작업은 최소화할 것을 권장합니다. 이렇게 하면 서버에서 실행되는 엣지 에이전트에 필요한 리소스를 가능한 한 최소화할 수 있습니다. 일반적으로는 불필요한 네트워크 사용을 줄이기 위한 필터링, 타임스탬프 설정(operators를 통해), 그리고 에이전트에서 컨텍스트를 필요로 하는 보강 정도만 수행하는 경우가 많습니다. 예를 들어 게이트웨이 인스턴스가 다른 Kubernetes 클러스터에 있는 경우, k8s 보강은 에이전트에서 수행되어야 합니다.
OpenTelemetry는 다음과 같은 처리 및 필터링 기능을 제공하며, 이를 활용할 수 있습니다.
-
Processors - Processors는 receivers가 수집한 데이터를 수정하거나 변환한 후 exporters로 전송합니다. Processors는 collector 설정의
processors섹션에 구성된 순서대로 적용됩니다. 선택 사항이지만, 최소 구성은 일반적으로 권장됩니다. OTel collector를 ClickHouse와 함께 사용할 때에는 processors를 다음 수준으로 제한하는 것을 권장합니다. -
memory_limiter는 collector에서 메모리 부족 상황을 방지하는 데 사용됩니다. 권장 사항은 리소스 추정을 참조하십시오.
-
컨텍스트 기반 보강을 수행하는 processor. 예를 들어 Kubernetes Attributes Processor는 k8s 메타데이터를 사용하여 span, metric, log 리소스 속성을 자동으로 설정할 수 있습니다. 예: 이벤트에 소스 파드 ID를 보강.
-
트레이스에 필요하다면 tail 또는 head 샘플링.
-
기본 필터링 - 아래에 설명된 operator로 수행할 수 없는 경우, 필요하지 않은 이벤트를 드롭합니다.
-
Batching - 데이터를 배치 단위로 전송하도록 보장하기 위해 ClickHouse와 함께 작업할 때 필수입니다. "삽입 최적화"를 참조하십시오.
-
Operators - Operators는 receiver 수준에서 사용 가능한 가장 기본적인 처리 단위를 제공합니다. 기본적인 파싱을 지원하여 Severity 및 Timestamp와 같은 필드를 설정할 수 있습니다. 여기에서는 JSON 및 정규식(regex) 파싱뿐 아니라 이벤트 필터링과 기본적인 변환도 지원됩니다. 이벤트 필터링은 여기에서 수행할 것을 권장합니다.
Operators 또는 transform processors를 사용하여 과도한 이벤트 처리를 수행하지 않을 것을 권장합니다. 특히 JSON 파싱은 상당한 메모리 및 CPU 오버헤드를 발생시킬 수 있습니다. 일부 예외(예: k8s 메타데이터 추가와 같은 컨텍스트 인식 보강)를 제외하면, ClickHouse에서는 materialized view와 컬럼을 사용하여 삽입 시점에 모든 처리를 수행할 수 있습니다. 자세한 내용은 SQL을 사용한 구조 추출을 참조하십시오.
예시
다음 구성은 이 비구조화 로그 파일을 수집하는 예시입니다. 이 구성은 에이전트 역할을 하는 수집기가 데이터를 ClickStack 게이트웨이로 전송하는 데 사용할 수 있습니다.
로그 줄에서 구조를 추출하기 위한 연산자(regex_parser)와 이벤트를 필터링하는 연산자의 사용, 그리고 이벤트를 배치로 처리하고 메모리 사용량을 제한하기 위한 프로세서 사용에 유의하십시오.
모든 OTLP 통신에는 수집 API key가 포함된 authorization 헤더를 함께 전송해야 합니다.
보다 고급 구성이 필요한 경우 OpenTelemetry collector 문서를 참고하십시오.
삽입 최적화
강력한 일관성을 보장하면서 높은 삽입 성능을 얻으려면 ClickStack collector를 통해 관측성 데이터를 ClickHouse에 삽입할 때 몇 가지 간단한 규칙을 따라야 합니다. OTel collector를 올바르게 구성하면 다음 규칙들을 쉽게 준수할 수 있습니다. 이는 또한 처음 ClickHouse를 사용할 때 사용자가 겪기 쉬운 일반적인 문제를 방지하는 데 도움이 됩니다.
배치 처리
기본적으로 ClickHouse로 전송되는 각 insert는, 해당 insert의 데이터와 함께 저장해야 하는 기타 메타데이터를 포함하는 저장소 파트를 ClickHouse가 즉시 생성합니다. 따라서 더 적은 횟수의 insert에 더 많은 데이터를 담아 보내는 것이, 더 적은 데이터를 담은 insert를 많이 보내는 것보다 필요한 쓰기 작업 횟수를 줄여 줍니다. 한 번에 최소 1,000개의 행 이상을 포함하는 비교적 큰 배치로 데이터를 insert할 것을 권장합니다. 자세한 내용은 여기를 참고하십시오.
기본적으로 ClickHouse로의 insert는 동기(synchronous) 방식이며, 동일한 내용일 경우 멱등적(idempotent)입니다. MergeTree 엔진 계열 테이블의 경우 ClickHouse는 기본 설정으로 insert 시 자동 중복 제거(deduplicate inserts)를 수행합니다. 이는 insert 동작이 다음과 같은 상황에서도 안전하게 처리된다는 의미입니다:
- (1) 데이터를 수신하는 노드에 문제가 있는 경우, insert 쿼리는 타임아웃되거나(또는 더 구체적인 오류가 발생하거나) 확인 응답을 받지 못합니다.
- (2) 노드가 데이터를 기록했으나, 네트워크 중단으로 인해 쿼리 발신자에게 확인 응답을 반환할 수 없는 경우, 발신자는 타임아웃 또는 네트워크 오류를 받게 됩니다.
collector의 관점에서는 (1)과 (2)를 구분하기 어려울 수 있습니다. 그러나 두 경우 모두, 확인 응답을 받지 못한 insert는 즉시 재시도할 수 있습니다. 재시도된 insert 쿼리가 동일한 데이터와 동일한 순서를 포함하는 한, 원래의(확인 응답을 받지 못한) insert가 성공했다면 ClickHouse는 재시도된 insert를 자동으로 무시합니다.
이러한 이유로, ClickStack 배포판의 OTel collector는 batch processor를 사용합니다. 이를 통해 insert가 위 요구 사항을 만족하는 일관된 행 배치로 전송되도록 보장합니다. collector가 높은 처리량(초당 이벤트 수)을 처리할 것으로 예상되고, 각 insert에 최소 5,000개의 이벤트를 포함해 보낼 수 있는 경우, 일반적으로 파이프라인에서 필요한 배치 처리는 이것으로 충분합니다. 이 경우 collector는 batch processor의 timeout에 도달하기 전에 배치를 플러시하여, 파이프라인의 종단 간 지연 시간이 낮게 유지되고 배치 크기가 일관되도록 합니다.
비동기 insert 사용
일반적으로 수집기의 처리량이 낮으면 더 작은 배치로 데이터를 전송해야 하며, 그럼에도 최소한의 엔드 투 엔드 지연 시간으로 데이터가 ClickHouse에 도달하기를 기대합니다. 이 경우 배치 프로세서의 timeout이 만료될 때 작은 배치가 전송됩니다. 이는 문제를 일으킬 수 있으며, 이러한 경우 비동기 insert가 필요합니다. ClickStack 수집기를 게이트웨이 역할로 동작시키는 구성에서 데이터를 전송하는 경우에는 이 문제가 드물게 발생합니다. 수집기가 집계기 역할을 수행하여 이 문제를 완화하기 때문입니다. 자세한 내용은 Collector roles를 참고하십시오.
큰 배치를 보장할 수 없다면, Asynchronous Inserts를 사용하여 배치 작업을 ClickHouse에 위임할 수 있습니다. 비동기 insert에서는 먼저 데이터가 버퍼에 insert된 후, 이후에 데이터베이스 스토리지에 동기식이 아닌 방식으로 기록됩니다.
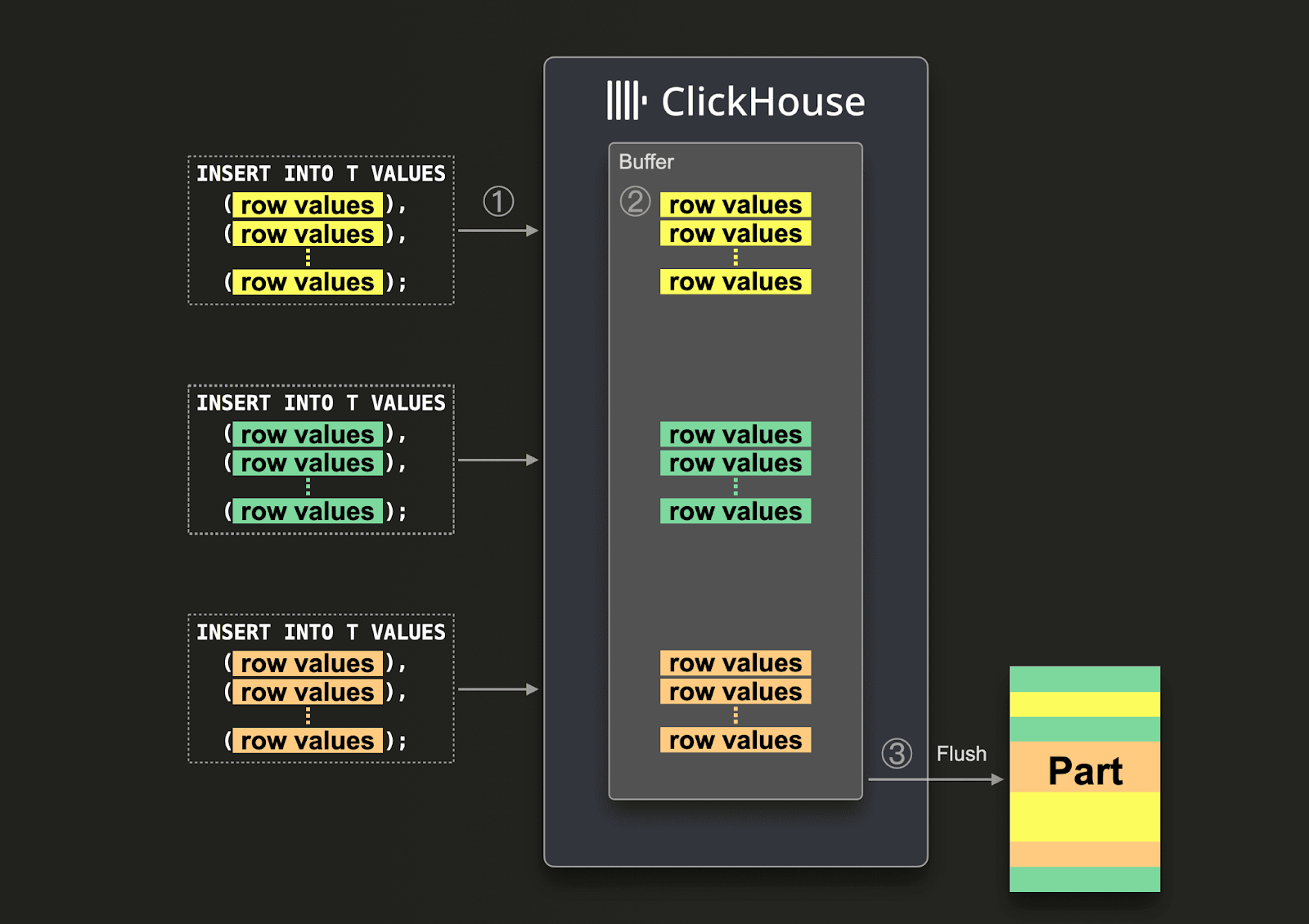
비동기 insert가 활성화되면, ClickHouse가 ① insert 쿼리를 수신할 때 쿼리의 데이터는 ② 먼저 즉시 메모리 내 버퍼에 기록됩니다. ③ 이후 버퍼 플러시가 발생하면 버퍼의 데이터가 정렬된 뒤 파트(part)로 데이터베이스 스토리지에 기록됩니다. 데이터가 데이터베이스 스토리지로 플러시되기 전에는 쿼리로 검색할 수 없다는 점에 유의하십시오. 버퍼 플러시 시점은 설정 가능합니다.
수집기에 대해 비동기 insert를 활성화하려면 연결 문자열에 async_insert=1을 추가하십시오. 전달 보장을 위해 wait_for_async_insert=1(기본값) 사용을 권장합니다. 자세한 내용은 여기를 참고하십시오.
비동기 insert로 전송된 데이터는 ClickHouse 버퍼가 플러시될 때 insert됩니다. 이는 async_insert_max_data_size를 초과한 이후이거나, 첫 번째 INSERT 쿼리 이후 async_insert_busy_timeout_ms 밀리초가 경과한 후에 발생합니다. async_insert_stale_timeout_ms가 0이 아닌 값으로 설정된 경우, 마지막 쿼리 이후 async_insert_stale_timeout_ms 밀리초가 지나면 데이터가 insert됩니다. 이러한 설정을 조정하여 파이프라인의 엔드 투 엔드 지연 시간을 제어할 수 있습니다. 버퍼 플러시를 조정하는 데 사용할 수 있는 추가 설정은 여기에 문서화되어 있습니다. 일반적으로 기본값이 적절합니다.
사용 중인 에이전트 수가 적고 처리량은 낮지만 엄격한 엔드 투 엔드 지연 시간 요구 사항이 있는 경우, adaptive asynchronous inserts가 유용할 수 있습니다. 일반적으로 이는 ClickHouse에서 볼 수 있는 것처럼 처리량이 높은 관측성(Observability) 사용 사례에는 적용되지 않습니다.
마지막으로, ClickHouse에 대한 동기 insert에 연관되었던 기존의 중복 제거(deduplication) 동작은 비동기 insert를 사용할 때 기본적으로 활성화되지 않습니다. 필요하다면 async_insert_deduplicate 설정을 참고하십시오.
이 기능을 구성하는 방법에 대한 전체 세부 정보는 이 문서 페이지 또는 심층 블로그 게시물에서 확인할 수 있습니다.
확장
ClickStack OTel collector는 게이트웨이 역할의 인스턴스로 동작합니다. 자세한 내용은 Collector roles를 참고하십시오. 이러한 인스턴스는 일반적으로 데이터 센터별 또는 리전별로 배포되는 독립형 서비스입니다. 애플리케이션(또는 에이전트 역할의 다른 collector)에서 단일 OTLP 엔드포인트를 통해 이벤트를 수신합니다. 보통 여러 collector 인스턴스를 함께 배포하고, 기본 제공 로드 밸런서를 사용하여 이들 사이에 부하를 분산합니다.

이 아키텍처의 목적은 에이전트에서 계산 집약적인 처리를 분리하여 에이전트의 리소스 사용량을 최소화하는 것입니다. 이러한 ClickStack 게이트웨이는 원래 에이전트에서 수행해야 할 변환 작업을 대신 처리할 수 있습니다. 또한 많은 에이전트에서 이벤트를 집계함으로써, 게이트웨이는 ClickHouse로 대용량 배치를 전송하도록 하여 효율적으로 삽입할 수 있게 합니다. 에이전트와 SDK 소스가 추가되고 이벤트 처리량이 증가함에 따라 이러한 게이트웨이 collector는 손쉽게 확장할 수 있습니다.
Kafka 추가
위의 아키텍처에서는 메시지 큐로 Kafka를 사용하지 않습니다.
Kafka 큐를 메시지 버퍼로 사용하는 것은 로깅 아키텍처에서 흔히 보이는 설계 패턴이며, ELK 스택을 통해 널리 알려졌습니다. 이는 몇 가지 이점을 제공합니다. 주된 이점은 더 강력한 메시지 전달 보장을 제공하고 역압(backpressure) 처리를 돕는다는 점입니다. 메시지는 수집 에이전트에서 Kafka로 전송되어 디스크에 기록됩니다. 이론적으로는, 클러스터 구성된 Kafka 인스턴스는 디스크에 데이터를 선형적으로 기록하는 것이 메시지를 파싱하고 처리하는 것보다 계산 오버헤드가 적기 때문에, 높은 처리량의 메시지 버퍼를 제공해야 합니다. 예를 들어 Elastic에서는 토큰화와 인덱싱에 상당한 오버헤드가 발생합니다. 데이터를 에이전트 외부로 이동함으로써, 소스에서 로그 로테이션으로 인해 메시지를 잃어버릴 위험 또한 줄어듭니다. 마지막으로, 일부 사용 사례에서 매력적일 수 있는 메시지 재생(replay) 및 리전 간 복제 기능도 제공합니다.
그러나 ClickHouse는 상당히 빠르게 데이터를 삽입할 수 있으며, 보통 수준의 하드웨어에서도 초당 수백만 개의 행을 처리할 수 있습니다. ClickHouse로 인한 역압은 드뭅니다. 종종 Kafka 큐를 사용하는 것은 아키텍처 복잡성과 비용 증가를 의미합니다. 로그는 은행 거래나 기타 미션 크리티컬 데이터와 동일한 수준의 전달 보장이 필요하지 않다는 원칙을 받아들일 수 있다면, Kafka를 도입해 복잡성을 높이는 것은 피하는 것이 좋습니다.
하지만 높은 전달 보장이나 데이터 재생(잠재적으로 여러 소스로)을 위한 기능이 필요한 경우, Kafka는 유용한 아키텍처 구성 요소가 될 수 있습니다.
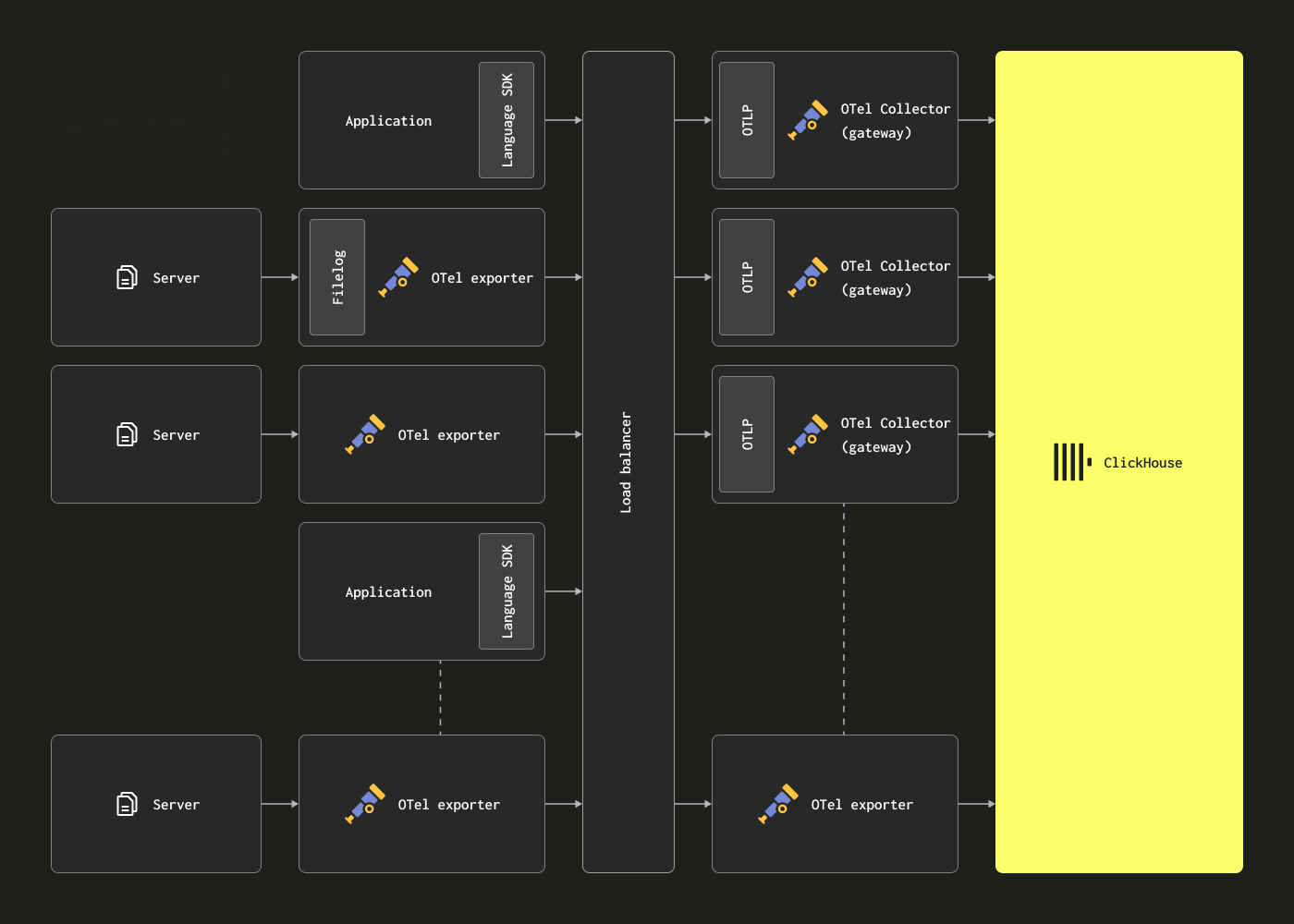
이 경우 OTel 에이전트는 Kafka exporter를 통해 Kafka로 데이터를 전송하도록 설정할 수 있습니다. 게이트웨이 인스턴스는 Kafka receiver를 사용해 메시지를 소비합니다. 자세한 내용은 Confluent 및 OTel 문서를 참고하기를 권장합니다.
ClickStack OpenTelemetry collector 배포는 사용자 지정 collector 구성을 사용하여 Kafka와 함께 구성할 수 있습니다.
리소스 추정
OTel collector의 리소스 요구 사항은 이벤트 처리량, 메시지 크기, 수행되는 처리 작업의 양에 따라 달라집니다. OpenTelemetry 프로젝트에서는 리소스 요구 사항을 추정하는 데 사용할 수 있는 벤치마크를 제공합니다.
실제 운영 경험에 따르면, 코어 3개와 12GB RAM을 가진 ClickStack 게이트웨이 인스턴스는 초당 약 60k 이벤트를 처리할 수 있습니다. 이는 필드 이름 변경만 수행하고 정규식을 사용하지 않는 최소 처리 파이프라인을 가정합니다.
게이트웨이로 이벤트를 전송하고 이벤트의 타임스탬프만 설정하는 에이전트 인스턴스의 경우, 예상 초당 로그 수를 기준으로 리소스를 산정할 것을 권장합니다. 다음 값들은 시작점으로 참고할 수 있는 대략적인 수치입니다:
| 로깅 속도 | collector 에이전트 리소스 |
|---|---|
| 1k/second | 0.2 CPU, 0.2 GiB |
| 5k/second | 0.5 CPU, 0.5 GiB |
| 10k/second | 1 CPU, 1 GiB |
JSON 지원
ClickStack는 버전 2.0.4부터 JSON type에 대한 베타 지원을 제공합니다.
ClickStack의 JSON type 지원은 베타 기능입니다. JSON type 자체는 ClickHouse 25.3+에서 프로덕션 환경에 사용할 수 있을 정도로 안정적이지만, ClickStack 내 JSON type 통합 기능은 아직 활발히 개발 중이며 제한 사항이 있을 수 있고, 향후 변경되거나 버그가 포함될 수 있습니다.
JSON 타입의 이점
JSON 타입은 ClickStack 사용자에게 다음과 같은 이점을 제공합니다.
- 타입 보존 - 숫자는 숫자로, 불리언은 불리언으로 유지되며, 모든 값을 문자열로 평탄화할 필요가 없습니다. 덕분에 캐스팅이 줄어들고 쿼리가 단순해지며, 집계 정확도가 향상됩니다.
- 경로 수준 컬럼 - 각 JSON 경로가 자체 하위 컬럼이 되어 I/O가 줄어듭니다. 쿼리는 필요한 필드만 읽기 때문에, 특정 필드를 쿼리하기 위해 전체 컬럼을 읽어야 했던 기존 Map 타입 대비 큰 성능 향상을 제공합니다.
- 깊은 중첩도 문제없이 동작 - 복잡하고 깊게 중첩된 구조를 Map 타입처럼 수동으로 평탄화하거나, 이후 어색한 JSONExtract 함수를 사용할 필요 없이 자연스럽게 처리합니다.
- 동적이고 진화하는 스키마 - 팀에서 시간이 지나면서 새로운 태그와 속성을 추가하는 관측성 데이터에 최적입니다. JSON은 스키마 마이그레이션 없이 이러한 변경을 자동으로 처리합니다.
- 더 빠른 쿼리, 더 적은 메모리 -
LogAttributes와 같은 속성에 대한 일반적인 집계 시 읽는 데이터 양이 5–10배 줄어들고 속도가 크게 향상되어, 쿼리 시간과 피크 메모리 사용량 모두 감소합니다. - 간단한 관리 - 성능을 위해 미리 컬럼을 구체화할 필요가 없습니다. 각 필드는 자체 하위 컬럼이 되며, 기본 ClickHouse 컬럼과 동일한 속도를 제공합니다.
JSON 지원 활성화
- Managed ClickStack
- Open Source ClickStack
Managed ClickStack에서 JSON 지원을 활성화하려면 아래의 collector를 구성하기 전에 지원팀에 문의하십시오. 이 기능은 ClickHouse Cloud의 ClickStack UI(HyperDX)에서도 활성화되어야 합니다.
collector에서 이 기능을 활성화하려면 환경 변수 OTEL_AGENT_FEATURE_GATE_ARG='--feature-gates=clickhouse.json'를 설정하십시오. 이렇게 하면 스키마가 ClickHouse에서 JSON 타입을 사용하여 생성됩니다.
예를 들어:
collector에 대해 이 기능을 활성화하려면, collector가 포함된 모든 배포에 환경 변수 OTEL_AGENT_FEATURE_GATE_ARG='--feature-gates=clickhouse.json'를 설정하십시오. 이렇게 하면 스키마가 ClickHouse에서 JSON 타입을 사용하여 생성됩니다.
JSON 타입을 쿼리하려면, 환경 변수 BETA_CH_OTEL_JSON_SCHEMA_ENABLED=true를 통해 HyperDX 애플리케이션 레이어에서도 지원을 활성화해야 합니다.
예를 들어:
맵 기반 스키마에서 JSON 타입으로 마이그레이션하기
JSON 타입은 기존 맵 기반 스키마와 하위 호환되지 않습니다. 이 기능을 활성화하면 JSON 타입을 사용하는 새 테이블이 생성되며, 기존 데이터는 수동으로 마이그레이션해야 합니다.
맵(Map) 기반 스키마에서 마이그레이션하려면 다음 단계를 따릅니다:
OTel collector 중지하기
collector 배포하기
OTEL_AGENT_FEATURE_GATE_ARG가 설정된 상태로 collector를 배포합니다.
JSON 스키마 지원을 활성화하여 HyperDX 컨테이너 다시 시작하기
새 데이터 소스 생성하기
JSON 테이블을 참조하도록 HyperDX에서 새 데이터 소스를 생성합니다.
기존 데이터 마이그레이션(선택 사항)
기존 데이터를 새 JSON 테이블로 이전하려면 다음을 수행합니다:
약 100억 행 미만의 데이터셋에만 권장합니다. 이전에 Map 타입으로 저장된 데이터는 데이터 타입의 정밀도가 유지되지 않았습니다(모든 값이 문자열이었습니다). 그 결과, 이 기존 데이터는 만료되어 사라질 때까지 새 스키마에서 문자열로 표시되며, 프런트엔드에서 추가적인 캐스팅이 필요합니다. 새로 저장되는 데이터의 타입은 JSON 타입으로 유지됩니다.
