ClickHouse Cloud 모니터링
이 가이드는 ClickHouse Cloud를 평가하는 엔터프라이즈 팀을 대상으로, 프로덕션 배포 환경에서의 모니터링 및 관측성 기능에 대한 종합적인 정보를 제공합니다. 엔터프라이즈 고객은 기본 제공 모니터링 기능, Datadog 및 AWS CloudWatch와 같은 도구를 포함한 기존 관측성 스택과의 통합, 그리고 ClickHouse의 모니터링 기능이 셀프 호스팅 배포와 어떻게 비교되는지에 대해 자주 문의합니다.
고급 관측성 대시보드
ClickHouse Cloud는 「Monitoring」 섹션에서 액세스할 수 있는 기본 제공 대시보드 인터페이스를 통해 포괄적인 모니터링 기능을 제공합니다. 이 대시보드들은 추가 설정 없이 실시간으로 시스템 및 성능 메트릭을 시각화하며, ClickHouse Cloud 내에서 실시간 프로덕션 모니터링을 위한 기본 도구로 사용됩니다.
- Advanced Dashboard: 「Monitoring → Advanced dashboard」를 통해 액세스할 수 있는 주요 대시보드 인터페이스로, 쿼리 처리 속도, 리소스 사용량, 시스템 상태, 스토리지 성능을 실시간으로 보여줍니다. 이 대시보드는 별도의 인증이 필요하지 않으며, 인스턴스가 유휴 상태로 전환되는 것을 방해하지 않고, 프로덕션 시스템에 쿼리 부하를 추가하지 않습니다. 각 시각화는 사용자 정의 가능한 SQL 쿼리로 구동되며, 기본 제공 차트는 ClickHouse 관련 메트릭, 시스템 상태 메트릭, Cloud 관련 메트릭 그룹으로 구성됩니다. SQL 콘솔에서 직접 사용자 정의 쿼리를 생성하여 모니터링을 확장할 수 있습니다.
이 메트릭에 액세스하더라도 백엔드 서비스에 쿼리가 실행되지 않으며, 유휴 서비스가 깨워지지 않습니다.
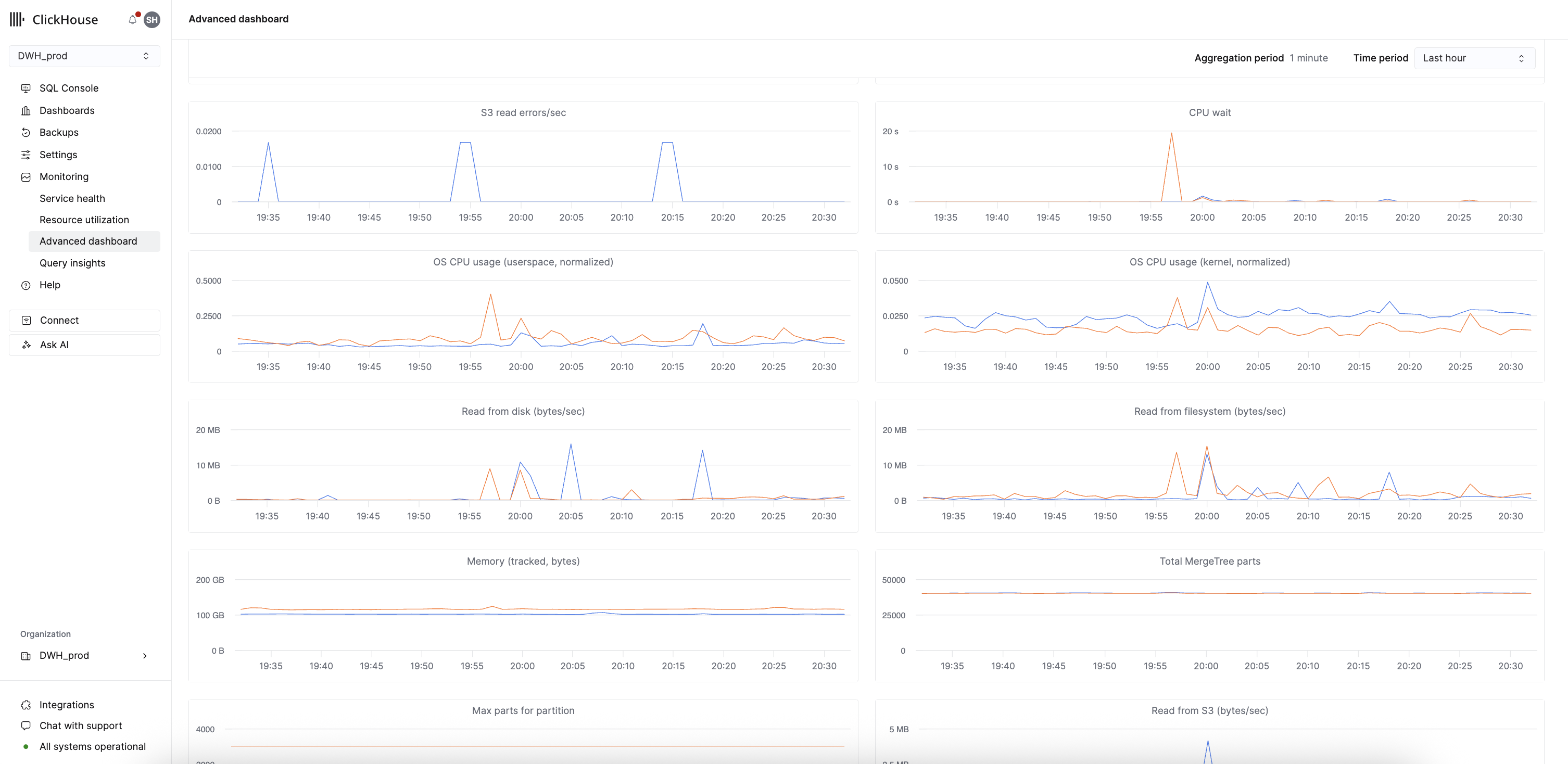
시각화를 확장하려는 사용자는 ClickHouse Cloud의 대시보드 기능을 사용하여 시스템 테이블을 직접 쿼리할 수 있습니다.
- Native advanced dashboard: Monitoring 섹션 내의 "You can still access the native advanced dashboard" 링크를 통해 액세스할 수 있는 대체 대시보드 인터페이스입니다. 별도의 탭에서 인증과 함께 열리며, 시스템 및 서비스 상태 모니터링을 위한 또 다른 UI를 제공합니다. 이 대시보드는 고급 분석을 지원하며, 기본이 되는 SQL 쿼리를 수정할 수 있습니다.
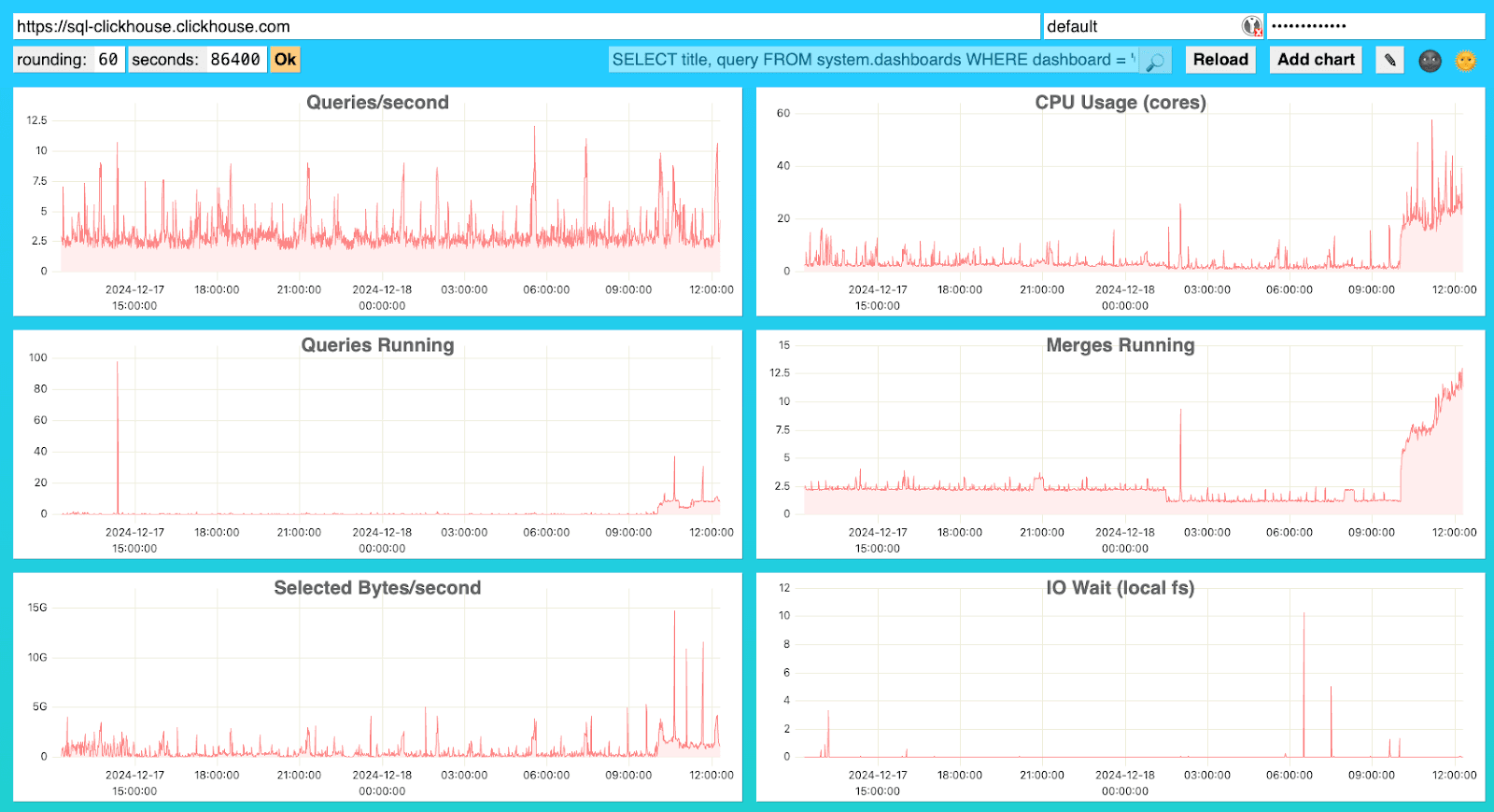
두 대시보드 모두 외부 종속성 없이 서비스 상태와 성능에 대한 즉각적인 가시성을 제공하며, 디버깅에 초점을 둔 외부 도구인 ClickStack과는 구분됩니다.
대시보드의 상세 기능 및 사용 가능한 메트릭에 대해서는 고급 대시보드 문서를 참고하십시오.
쿼리 인사이트와 리소스 모니터링
ClickHouse Cloud에는 다음과 같은 추가 모니터링 기능이 제공됩니다:
- Query Insights: 쿼리 성능 분석과 문제 해결을 위한 기본 제공 인터페이스입니다.
- Resource Utilization Dashboard: 메모리, CPU 할당, 데이터 전송 패턴을 추적합니다. CPU 사용량 및 메모리 사용량 그래프는 특정 기간 동안의 최대 사용률 지표(metric)를 보여 줍니다. CPU 사용량 그래프는 시스템 수준 CPU 사용률 지표(metric)를 나타내며, ClickHouse CPU 사용률 지표(metric)는 아닙니다.
자세한 기능은 query insights 및 resource utilization 문서를 참고하십시오.
Prometheus 호환 메트릭 엔드포인트
ClickHouse Cloud는 Prometheus 엔드포인트를 제공합니다. 이를 통해 기존 워크플로를 그대로 유지하고, 기존 팀의 전문성을 활용하며, Grafana, Datadog 및 기타 Prometheus 호환 도구를 포함한 엔터프라이즈 모니터링 플랫폼에 ClickHouse 메트릭을 통합할 수 있습니다.
조직 수준 엔드포인트는 모든 서비스의 메트릭을 연합(federation) 방식으로 수집하고, 서비스별 엔드포인트는 세밀한 모니터링을 제공합니다. 주요 기능은 다음과 같습니다:
- 필터링된 메트릭 옵션: 선택적인
filtered_metrics=true매개변수를 사용하면 1000개가 넘는 사용 가능한 메트릭에서 125개의 「미션 크리티컬」 메트릭으로 페이로드를 줄여 비용을 최적화하고 모니터링 대상을 명확히 할 수 있습니다. - 캐시된 메트릭 제공: 운영 시스템에 대한 쿼리 부하를 최소화하기 위해 매 분마다 새로 고침되는 materialized view를 사용합니다.
이 방식은 서비스 유휴 동작을 그대로 유지하므로, 서비스가 쿼리를 활발히 처리하지 않을 때 비용을 최적화할 수 있습니다. 이 API 엔드포인트는 ClickHouse Cloud API 자격 증명을 사용합니다. 자세한 엔드포인트 구성 방법은 ClickHouse Cloud Prometheus 문서를 참고하십시오.
통합 예시
외부 통합을 사용하면 조직은 기존에 구축한 모니터링 워크플로를 유지하면서 익숙한 도구에 대한 팀의 전문성을 그대로 활용하고, 현재 프로세스를 방해하거나 과도한 재교육 비용을 들이지 않고도 ClickHouse 모니터링을 더 넓은 인프라 관측성과 통합할 수 있습니다. 팀은 기존의 알림 규칙과 에스컬레이션 절차를 ClickHouse 메트릭에 적용하는 한편, 통합된 관측성 플랫폼 내에서 데이터베이스 성능을 애플리케이션 및 인프라 상태와 연관 지을 수 있습니다. 이러한 접근 방식은 현재 모니터링 구성에 대한 투자 수익률(ROI)을 극대화하고, 통합 대시보드와 익숙한 도구 인터페이스를 통해 문제 해결 속도를 높이는 데 도움이 됩니다.
Grafana Cloud 모니터링
Grafana는 직접 플러그인 통합과 Prometheus 기반 방식을 통해 ClickHouse 모니터링을 제공합니다. Prometheus 엔드포인트 통합은 모니터링 워크로드와 프로덕션 워크로드 간의 운영 상의 분리를 유지하면서, 기존 Grafana Cloud 인프라 내에서 시각화를 가능하게 합니다. 구성 방법은 Grafana의 ClickHouse 문서를 참고하십시오.
Datadog 모니터링
Datadog은 서비스의 유휴(idle) 상태 동작을 고려하면서 적절한 Cloud 서비스 모니터링을 제공하는 전용 API 통합을 개발 중입니다. 그동안에는 운영 분리와 비용 효율적인 모니터링을 위해 ClickHouse Prometheus 엔드포인트를 활용한 OpenMetrics 통합 방식을 사용할 수 있습니다. 구성에 대한 안내는 Datadog의 Prometheus 및 OpenMetrics 통합 문서를 참고하십시오.
ClickStack
ClickStack는 시스템 심층 분석과 디버깅을 위한 ClickHouse 권장 관측성 솔루션으로, ClickHouse를 스토리지 엔진으로 사용하는 로그, 메트릭, 트레이스를 위한 통합 플랫폼을 제공합니다. 이 방식은 ClickStack UI인 HyperDX가 ClickHouse 인스턴스 내부의 시스템 테이블에 직접 연결하는 것에 기반합니다. HyperDX는 Selects, Inserts, Infrastructure 탭을 포함하는 ClickHouse 중심 대시보드를 기본으로 제공합니다. 팀은 Lucene 또는 SQL 구문을 사용하여 시스템 테이블과 로그를 검색할 수 있으며, Chart Explorer를 통해 맞춤형 시각화를 생성하여 상세한 시스템 분석을 수행할 수 있습니다. 이 방식은 실시간 운영 환경 알림보다는 복잡한 문제 디버깅, 성능 분석, 심층적인 시스템 내부 분석에 적합합니다.
HyperDX가 시스템 테이블을 직접 쿼리하므로 이 방식은 유휴 상태의 서비스도 활성화될 수 있습니다.
ClickStack 배포 옵션
- ClickHouse Cloud의 HyperDX (프라이빗 프리뷰): HyperDX는 모든 ClickHouse Cloud 서비스에서 실행할 수 있습니다.
- Helm: Kubernetes 기반 디버깅 환경에 권장되는 방식입니다. ClickHouse Cloud와의 통합을 지원하며,
values.yaml을 통해 환경별 설정, 리소스 한도, 확장을 구성할 수 있습니다. - Docker Compose: 각 구성 요소(ClickHouse, HyperDX, OTel collector, MongoDB)를 개별적으로 배포합니다. ClickHouse Cloud와 통합할 때 사용하지 않는 구성 요소, 특히 ClickHouse와 OpenTelemetry Collector를 제거하도록 compose 파일을 수정할 수 있습니다.
- HyperDX Only: 독립 실행형 HyperDX 컨테이너입니다.
전체 배포 옵션과 아키텍처 상세 내용은 ClickStack 문서 및 데이터 수집 가이드를 참고하십시오.
OpenTelemetry Collector를 통해 ClickHouse Cloud Prometheus 엔드포인트에서 메트릭을 수집한 후, 시각화를 위해 별도로 배포된 ClickStack으로 전달할 수도 있습니다.
Grafana 플러그인 직접 통합
Grafana용 ClickHouse 데이터 소스 플러그인은 system 테이블을 활용하여 ClickHouse의 데이터를 직접 시각화하고 탐색할 수 있게 해줍니다. 이 방식은 성능을 모니터링하고 상세한 시스템 분석을 위한 사용자 정의 대시보드를 만드는 데 적합합니다. 플러그인 설치 및 구성에 대한 자세한 내용은 ClickHouse data source plugin을 참조하십시오. 미리 구성된 대시보드와 알림 규칙이 포함된 Prometheus-Grafana mix-in을 사용하여 완전한 모니터링 구성을 설정하는 방법은 Monitor ClickHouse with the new Prometheus-Grafana mix-in을 참조하십시오.
Datadog 직접 통합
Datadog은 에이전트용 ClickHouse Monitoring 플러그인을 제공하며, 이 플러그인은 시스템 테이블을 직접 조회합니다. 이 통합 방식은 clusterAllReplicas 기능을 통해 클러스터 인지 기능(cluster awareness)을 포함한 포괄적인 데이터베이스 모니터링을 제공합니다.
이 통합 방식은 비용 최적화를 위한 유휴 상태 동작과 Cloud 프록시 계층의 운영상 제약으로 인해 호환되지 않으므로, ClickHouse Cloud 배포 환경에서는 권장되지 않습니다.
시스템 테이블을 직접 사용하기
특히 system.query_log와 같은 ClickHouse 시스템 테이블에 연결해 직접 쿼리하면 쿼리 성능을 심층적으로 분석할 수 있습니다. SQL 콘솔이나 clickhouse client를 사용하여 느린 쿼리를 식별하고, 리소스 사용량을 분석하며, 조직 전체의 사용 패턴을 추적할 수 있습니다.
쿼리 성능 분석(Query Performance Analysis)
시스템 테이블의 쿼리 로그를 사용하여 쿼리 성능 분석(Query Performance Analysis)을 수행할 수 있습니다.
예제 쿼리: 클러스터의 모든 레플리카에서 오래 실행되는 쿼리 상위 5개를 조회:
커뮤니티 모니터링 솔루션
ClickHouse 커뮤니티에서는 인기 있는 관측성 스택과 통합되는 종합적인 모니터링 솔루션을 개발했습니다. ClickHouse Monitoring은 미리 구성된 대시보드를 포함한 완전한 모니터링 환경을 제공합니다. 이 오픈 소스 프로젝트는 검증된 모범 사례와 대시보드 구성을 기반으로 ClickHouse 모니터링을 도입하려는 팀을 위한 빠르게 시작할 수 있는 방법을 제공합니다.
다른 데이터베이스 직접 모니터링 방식과 마찬가지로, 이 솔루션은 ClickHouse 시스템 테이블을 직접 쿼리하므로 인스턴스가 유휴 상태가 되는 것을 방지하고, 그 결과 비용 최적화에 영향을 줄 수 있습니다.
시스템 영향 고려 사항
위에서 설명한 모든 접근 방식은 Prometheus 엔드포인트에 의존하거나, ClickHouse Cloud에서 관리되거나, 시스템 테이블을 직접 쿼리하는 방법을 조합해 사용합니다. 이 중 마지막 옵션은 프로덕션 ClickHouse 서비스에 쿼리를 수행하는 방식에 의존합니다. 이는 관찰 대상 시스템에 쿼리 부하를 추가하고 ClickHouse Cloud 인스턴스가 유휴 상태로 전환되는 것을 막아 비용 최적화에 부정적인 영향을 줄 수 있습니다. 또한 운영 시스템에 장애가 발생하면 둘이 긴밀히 결합되어 있기 때문에 모니터링도 영향을 받을 수 있습니다. 이 접근 방식은 심층적인 내부 상태 분석 및 디버깅에는 적합하지만, 실시간 운영 모니터링에는 덜 적합합니다. 다음 섹션에서 설명하는 외부 도구 연동 방식과 직접 Grafana 연동 방식을 평가할 때, 상세한 시스템 분석 기능과 운영 오버헤드 간의 이러한 트레이드오프를 고려해야 합니다.
