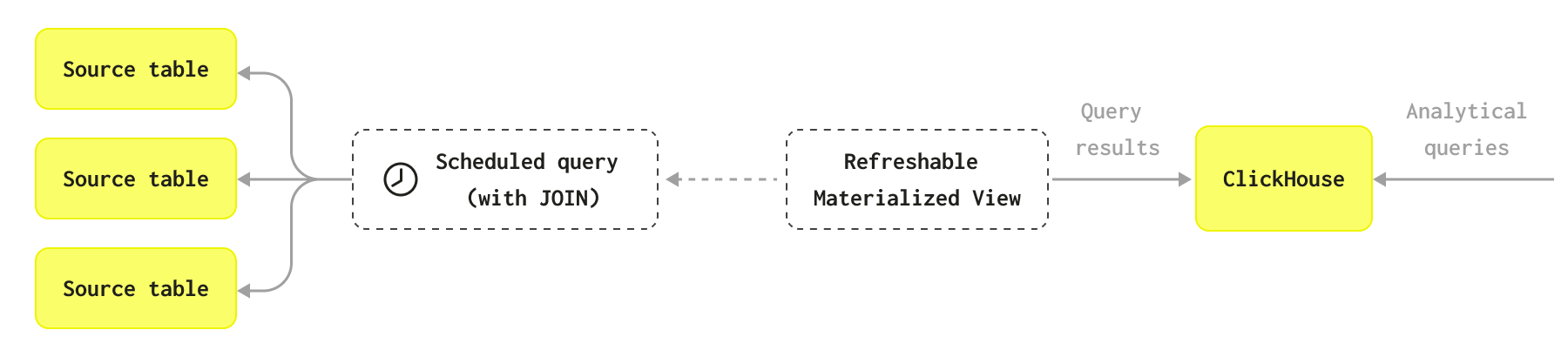
갱신 가능 구체화 뷰는 개념적으로 전통적인 OLTP 데이터베이스의 materialized view와 유사하며, 지정된 쿼리의 결과를 저장하여 빠르게 조회할 수 있게 하고, 리소스를 많이 소모하는 쿼리를 반복 실행할 필요를 줄여 줍니다. ClickHouse의 증분형 materialized view와 달리, 전체 데이터셋에 대해 해당 쿼리를 주기적으로 실행해야 하며, 그 결과는 조회를 위해 대상 테이블에 저장됩니다. 이 결과 집합은 이론적으로 원래 데이터셋보다 작기 때문에 이후 쿼리가 더 빠르게 실행될 수 있습니다.
ClickHouse 증분형 materialized view는 매우 강력하며, 특히 단일 테이블에 대한 집계를 수행해야 하는 경우 갱신 가능 구체화 뷰가 사용하는 방식보다 일반적으로 훨씬 더 잘 확장됩니다. 데이터가 삽입될 때마다 각 데이터 블록에 대해서만 집계를 수행하고 최종 테이블에서 증분 상태를 병합하므로, 쿼리는 항상 전체 데이터가 아닌 일부 데이터에 대해서만 실행됩니다. 이 방식은 잠재적으로 페타바이트 단위의 데이터까지 확장 가능하며, 보통 선호되는 방법입니다.
그러나 이러한 증분 처리 과정이 필요하지 않거나 적용할 수 없는 사용 사례도 있습니다. 일부 문제는 증분형 접근 방식과 호환되지 않거나 실시간 업데이트가 필요하지 않고, 주기적인 재생성이 더 적절한 경우가 있습니다. 예를 들어, 복잡한 조인을 사용하여 증분형 접근 방식과 호환되지 않는 경우 전체 데이터셋에 대한 뷰를 정기적으로 완전히 재계산하고자 할 수 있습니다.
갱신 가능 구체화 뷰는 비정규화와 같은 작업을 수행하는 배치 프로세스를 실행할 수 있습니다. 갱신 가능 구체화 뷰 간에 종속성을 생성하여, 한 뷰가 다른 뷰의 결과에 의존하도록 하고 선행 뷰가 완료된 후에만 실행되도록 설정할 수 있습니다. 이는 예약된 워크플로우 또는 dbt 작업과 같은 단순한 DAG를 대체할 수 있습니다. 갱신 가능 구체화 뷰 간의 종속성 설정 방법에 대해 더 알아보려면 CREATE VIEW의 Dependencies 섹션을 참조하십시오.
이 데이터 세트의 uuid 컬럼에는 4096개의 값이 있습니다. 총 개수가 가장 큰 값들을 찾기 위해 다음 쿼리를 사용할 수 있습니다:
SELECT
uuid,
sum(count) AS count
FROM events
GROUP BY ALL
ORDER BY count DESC
LIMIT 10
┌─uuid─┬───count─┐
│ c6f │ 5676468 │
│ 951 │ 5669731 │
│ 6a6 │ 5664552 │
│ b06 │ 5662036 │
│ 0ca │ 5658580 │
│ 2cd │ 5657182 │
│ 32a │ 5656475 │
│ ffe │ 5653952 │
│ f33 │ 5653783 │
│ c5b │ 5649936 │
└──────┴─────────┘
각 uuid에 대해 10초마다 카운트를 집계하여 events_snapshot이라는 새 테이블에 저장한다고 가정해 보겠습니다. events_snapshot의 스키마는 다음과 같습니다.
CREATE TABLE events_snapshot (
ts DateTime32,
uuid String,
count UInt64
)
ENGINE = MergeTree
ORDER BY uuid;
그러면 이 테이블에 데이터를 적재하기 위해 갱신 가능 구체화 뷰를 생성할 수 있습니다:
CREATE MATERIALIZED VIEW events_snapshot_mv
REFRESH EVERY 10 SECOND APPEND TO events_snapshot
AS SELECT
now() AS ts,
uuid,
sum(count) AS count
FROM events
GROUP BY ALL;
그런 다음 특정 uuid에 대해 시간에 따른 개수를 확인하기 위해 events_snapshot을 쿼리할 수 있습니다.
데이터 비정규화 가이드에서는 Stack Overflow 데이터셋을 사용하여 데이터를 비정규화하는 다양한 기법을 설명합니다. votes, users, badges, posts, postlinks 테이블에 데이터를 적재합니다.
해당 가이드에서는 다음 쿼리를 사용하여 postlinks 데이터셋을 posts 테이블에 비정규화하는 방법을 보여줍니다:
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
앞서 이 데이터를 posts_with_links 테이블에 한 번만 삽입하는 방법을 살펴보았지만, 프로덕션 시스템에서는 이 작업을 정기적으로 실행되도록 구성하는 것이 필요합니다.
posts 테이블과 postlinks 테이블은 모두 업데이트될 수 있습니다. 따라서 증분형 materialized view를 사용해 이 조인을 구현하려고 하기보다는, 이 쿼리가 예를 들어 매시간 한 번과 같이 일정한 간격으로 실행되도록 스케줄링하고, 결과를 post_with_links 테이블에 저장하는 것만으로도 충분할 수 있습니다.
이럴 때 갱신 가능 구체화 뷰가 도움이 되며, 다음 쿼리로 이를 생성할 수 있습니다.
CREATE MATERIALIZED VIEW posts_with_links_mv
REFRESH EVERY 1 HOUR TO posts_with_links AS
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
뷰는 즉시 실행되며, 그 이후에는 구성된 대로 매시간 실행되어 소스 테이블의 변경 사항이 반영되도록 합니다. 특히 쿼리가 다시 실행될 때 결과 집합은 원자적으로, 그리고 투명하게 업데이트됩니다.
참고
여기에서 사용하는 구문은 증분형 materialized view와 동일하지만, REFRESH 절을 추가로 포함합니다.
이후 다음 쿼리를 사용하면 각 배우에 대한 요약을 계산하고, 출연 영화 수가 많은 순으로 정렬할 수 있습니다.
SELECT
id, any(actor_name) AS name, uniqExact(movie_id) AS movies,
round(avg(rank), 2) AS avg_rank, uniqExact(genre) AS genres,
uniqExact(director_name) AS directors, max(created_at) AS updated_at
FROM (
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id, imdb.movies.rank AS rank, genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY movies DESC
LIMIT 5;
CREATE MATERIALIZED VIEW imdb.actor_summary_mv
REFRESH EVERY 1 MINUTE TO imdb.actor_summary AS
SELECT
id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM
(
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC;
이 VIEW는 즉시 한 번 실행되고, 이후에는 설정에 따라 매분 실행되어 소스 테이블의 변경 사항이 반영되도록 합니다. 앞에서 사용한 배우 요약 정보를 얻는 쿼리는 문법적으로 더 단순해지고, 실행 속도도 크게 빨라집니다!
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5
원본 데이터에 새로운 배우 "Clicky McClickHouse"를 추가했는데, 이 배우가 매우 많은 영화에 출연했다고 가정해 보겠습니다.
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
INSERT INTO imdb.roles SELECT
845466 AS actor_id,
id AS movie_id,
'Himself' AS role,
now() AS created_at
FROM imdb.movies
LIMIT 10000, 910;
60초도 지나지 않아 대상 테이블이 업데이트되어 Clicky의 왕성한 출연 활동이 반영됩니다.
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5;