데이터 모델링 기법
이 가이드는 PostgreSQL에서 ClickHouse로 마이그레이션하는 방법에 대한 안내서의 3부입니다. 실제 예제를 사용하여 PostgreSQL에서 마이그레이션할 때 ClickHouse에서 데이터를 어떻게 모델링할 수 있는지 보여 줍니다.
Postgres에서 마이그레이션하려는 경우 ClickHouse에서 데이터 모델링을 위한 가이드를 먼저 읽을 것을 권장합니다. 이 가이드는 동일한 Stack Overflow 데이터셋을 사용하며, ClickHouse 기능을 활용한 여러 가지 접근 방식을 살펴봅니다.
ClickHouse의 기본(정렬) 키
OLTP 데이터베이스를 사용해 오던 사용자는 ClickHouse에서 이에 상응하는 개념을 찾는 경우가 많습니다. ClickHouse가 PRIMARY KEY 구문을 지원하는 것을 보고, 소스 OLTP 데이터베이스와 동일한 키를 사용해 테이블 스키마를 정의하고 싶어질 수 있습니다. 그러나 이는 적절하지 않습니다.
ClickHouse의 기본 키는 어떻게 다릅니까?
OLTP 기본 키를 그대로 ClickHouse에 사용하는 것이 적절하지 않은 이유를 이해하려면, ClickHouse 인덱싱의 기초를 이해해야 합니다. 비교 예로 Postgres를 사용하지만, 이 일반적인 개념은 다른 OLTP 데이터베이스에도 적용됩니다.
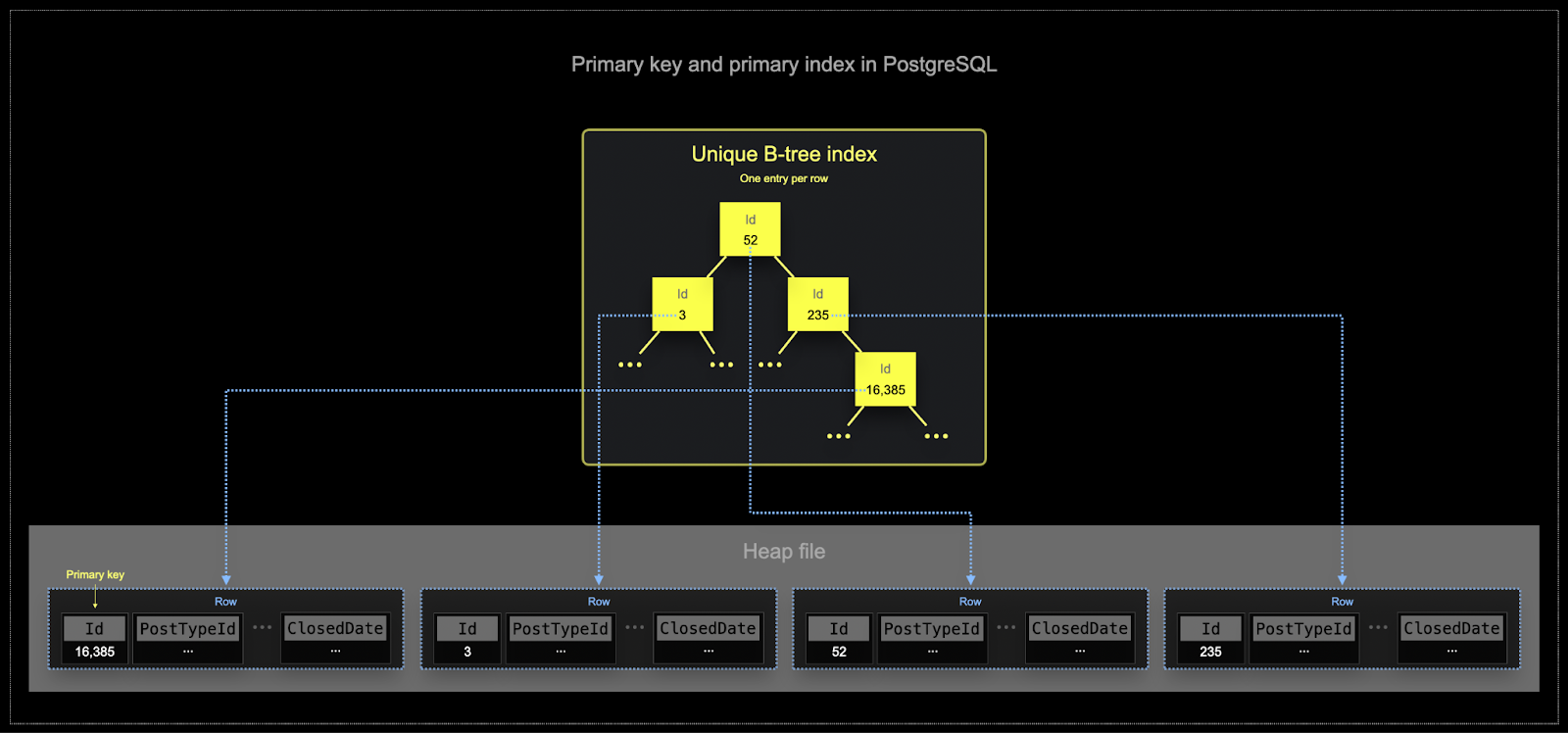
- Postgres 기본 키는 정의상 각 행마다 고유합니다. B-tree 구조를 사용하면 이 키로 단일 행을 효율적으로 조회할 수 있습니다. ClickHouse도 단일 행 값을 조회하도록 최적화할 수 있지만, 분석 워크로드에서는 일반적으로 소수의 컬럼을 매우 많은 행에 대해 읽어야 합니다. 필터는 집계가 수행될 행의 부분 집합을 더 자주 식별해야 합니다.
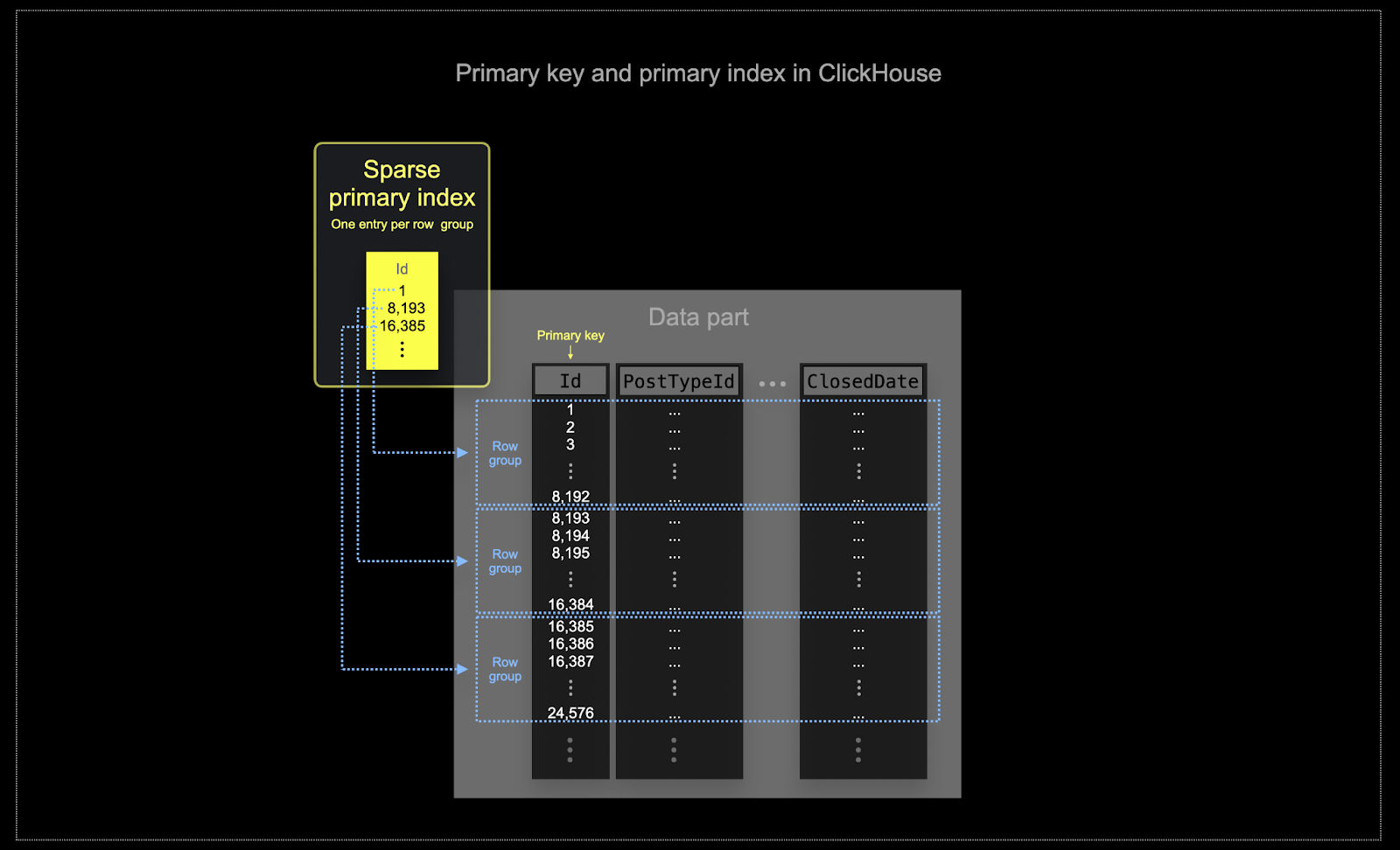
- 메모리 및 디스크 효율성은 ClickHouse가 자주 사용되는 규모에서 무엇보다 중요합니다. 데이터는 파트(parts)로 알려진 청크로 ClickHouse 테이블에 기록되며, 백그라운드에서 파트를 병합하기 위한 규칙이 적용됩니다. ClickHouse에서 각 파트는 자체 기본 인덱스를 가집니다. 파트가 병합되면, 병합된 파트의 기본 인덱스도 함께 병합됩니다. Postgres와 달리 이 인덱스들은 각 행마다 구축되지 않습니다. 대신, 하나의 파트에 대한 기본 인덱스는 행 그룹당 하나의 인덱스 엔트리를 가지며, 이러한 기법을 **희소 인덱싱(sparse indexing)**이라고 합니다.
- 희소 인덱싱이 가능한 이유는 ClickHouse가 지정된 키에 따라 파트의 행을 디스크에 정렬된 상태로 저장하기 때문입니다. 단일 행을 직접 찾는 것(B-Tree 기반 인덱스처럼) 대신, 희소 기본 인덱스는 인덱스 엔트리에 대한 이진 검색을 통해 쿼리와 일치할 수 있는 행 그룹을 빠르게 식별할 수 있게 합니다. 이렇게 식별된 잠재적으로 일치하는 행 그룹은 이후 병렬로 ClickHouse 엔진으로 스트리밍되어 실제 일치 항목을 찾습니다. 이 인덱스 설계는 기본 인덱스가 작게 유지되도록(전체가 주 메모리에 완전히 적재됨) 하면서도 쿼리 실행 시간을 크게 단축해 줍니다. 특히 데이터 분석 사용 사례에서 일반적인 범위 쿼리에 매우 효과적입니다.
자세한 내용은 이 심층 가이드를 참고하십시오.
ClickHouse에서 선택된 키는 인덱스뿐만 아니라 데이터가 디스크에 기록되는 순서도 결정합니다. 이 때문에 압축 수준에 큰 영향을 줄 수 있고, 이는 다시 쿼리 성능에 영향을 줄 수 있습니다. 대부분의 컬럼 값이 연속된 순서로 기록되도록 하는 정렬 키를 사용하면, 선택한 압축 알고리즘(및 코덱)이 데이터를 더 효과적으로 압축할 수 있습니다.
테이블의 모든 컬럼은 지정된 정렬 키의 값에 따라 정렬되며, 해당 컬럼이 키 자체에 포함되어 있는지 여부와 관계없이 동일하게 적용됩니다. 예를 들어
CreationDate가 키로 사용되면, 다른 모든 컬럼의 값 순서는CreationDate컬럼의 값 순서와 일치하게 됩니다. 여러 개의 정렬 키를 지정할 수 있으며, 이는SELECT쿼리의ORDER BY절과 동일한 의미로 정렬을 수행합니다.
정렬 키 선택하기
posts 테이블을 예시로 정렬 키를 선택하는 과정에서 고려해야 할 사항과 단계는 여기를 참고하십시오.
CDC 기반의 실시간 복제를 사용할 때에는 추가로 염두에 두어야 할 제약 조건이 있습니다. CDC에서 정렬 키를 사용자 정의하는 기법은 이 문서를 참고하십시오.
파티션
Postgres를 사용해 본 경우라면, 큰 데이터베이스의 성능과 관리 효율을 높이기 위해 테이블을 더 작고 관리하기 쉬운 단위인 파티션으로 나누는 테이블 파티셔닝 개념에 익숙할 것입니다. 이러한 파티셔닝은 지정된 컬럼(예: 날짜)에 대한 범위, 미리 정의된 목록, 또는 키에 대한 해시를 사용해 구현할 수 있습니다. 이를 통해 관리자는 날짜 범위나 지리적 위치와 같은 특정 기준에 따라 데이터를 구성할 수 있습니다. 파티셔닝은 파티션 프루닝(partition pruning)과 더 효율적인 인덱싱을 통해 더 빠른 데이터 액세스를 가능하게 하여 쿼리 성능을 개선합니다. 또한 전체 테이블이 아니라 개별 파티션 단위로 작업할 수 있게 하여 백업 및 데이터 삭제와 같은 유지 관리 작업에도 도움이 됩니다. 추가적으로, 파티셔닝은 여러 파티션에 부하를 분산함으로써 PostgreSQL 데이터베이스의 확장성을 크게 향상시킬 수 있습니다.
ClickHouse에서 파티셔닝은 테이블을 처음 정의할 때 PARTITION BY 절을 사용하여 지정합니다. 이 절에는 임의의 컬럼에 대한 SQL 표현식을 포함할 수 있으며, 그 결과에 따라 각 행이 어느 파티션으로 전송될지가 결정됩니다.
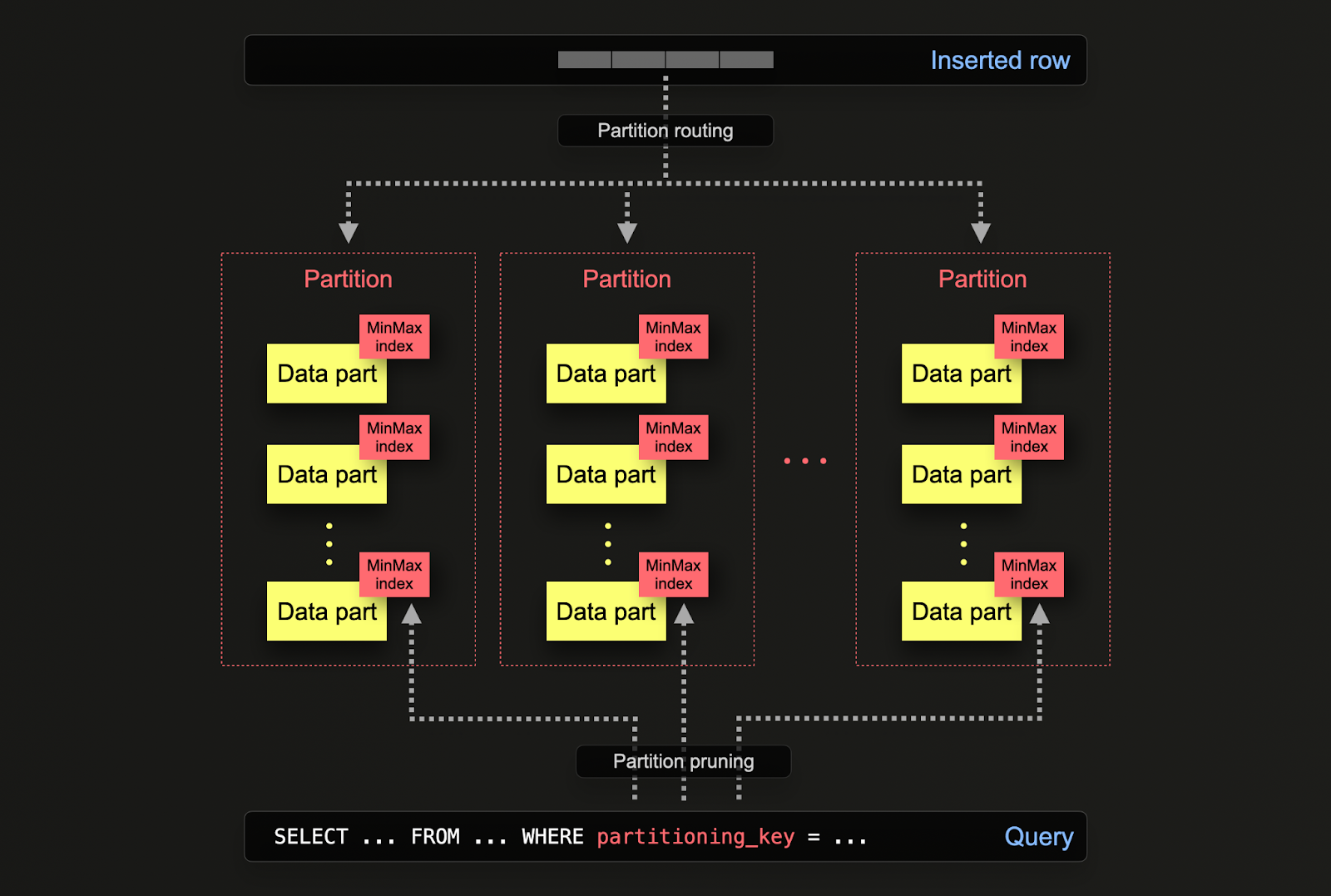
데이터 파트는 디스크에서 각 파티션과 논리적으로 연결되며, 개별적으로 쿼리할 수 있습니다. 아래 예시에서는 posts 테이블을 toYear(CreationDate) 표현식을 사용해 연도별로 파티셔닝합니다. 행이 ClickHouse에 삽입될 때마다 이 표현식은 각 행에 대해 평가되며, 그 결과에 해당하는 파티션이 존재하면 해당 파티션으로 라우팅됩니다(해당 연도의 첫 번째 행인 경우, 그 파티션이 생성됩니다).
파티션에 대한 자세한 설명은 "Table partitions"를 참조하십시오.
파티션의 활용
ClickHouse에서의 파티션은 Postgres에서의 파티션과 유사하게 활용되지만, 몇 가지 미묘한 차이가 있습니다. 보다 구체적으로는 다음과 같습니다.
- 데이터 관리 - ClickHouse에서 파티션은 기본적으로 쿼리 최적화 기법이 아니라 데이터 관리 기능으로 간주해야 합니다. 키를 기준으로 데이터를 논리적으로 분리하면, 각 파티션을 예를 들어 삭제와 같이 독립적으로 조작할 수 있습니다. 이를 통해 스토리지 계층 간에 파티션, 즉 데이터의 부분 집합을 시간 기준으로 효율적으로 이동하거나, 데이터를 만료시키거나 클러스터에서 효율적으로 삭제할 수 있습니다. 예를 들어, 아래에서는 2008년의 게시글을 제거합니다.
- 쿼리 최적화 - 파티션은 쿼리 성능 향상에 도움이 될 수 있지만, 이는 데이터 접근 패턴에 크게 좌우됩니다. 쿼리가 소수의 파티션(이상적으로는 하나)만을 대상으로 하는 경우 성능이 향상될 수 있습니다. 이는 일반적으로 파티셔닝 키가 기본 키에 포함되어 있지 않고 해당 키로 필터링하는 경우에만 유용합니다. 반대로, 여러 파티션을 대상으로 해야 하는 쿼리는 파티셔닝을 사용하지 않는 경우보다 성능이 나빠질 수 있습니다(파티셔닝 결과로 더 많은 파트가 생길 수 있기 때문입니다). 파티셔닝 키가 이미 기본 키에서 앞쪽에 위치해 있는 경우 단일 파티션만을 대상으로 하는 이점은 거의 사라지거나 의미가 없어집니다. 각 파티션 내의 값이 고유하다면, 파티셔닝은 GROUP BY 쿼리 최적화에도 사용될 수 있습니다. 그러나 일반적으로는 우선 기본 키가 잘 최적화되어 있는지를 확인해야 하며, 일 단위로 파티셔닝했을 때 대부분의 쿼리가 최근 1일 구간에 집중되는 경우처럼 접근 패턴이 하루 중 특정 예측 가능한 하위 구간에만 집중되는 예외적인 경우에 한해서만 쿼리 최적화 기법으로 파티셔닝을 고려하는 것이 좋습니다.
파티션에 대한 권장 사항
파티셔닝은 데이터 관리 기법으로서 고려해야 합니다. 특히 시계열 데이터를 다루면서 클러스터에서 데이터를 만료해야 할 때 이상적입니다. 예를 들어, 가장 오래된 파티션은 간단히 드롭할 수 있습니다.
중요: 파티셔닝 키 표현식이 고유값 개수가 매우 큰(high cardinality) 집합이 되지 않도록 해야 합니다. 즉, 100개가 넘는 파티션이 생성되는 상황은 피해야 합니다. 예를 들어, 클라이언트 식별자나 이름처럼 고유값 개수가 큰 컬럼으로 데이터를 파티셔닝하지 마십시오. 대신 클라이언트 식별자나 이름을 ORDER BY 표현식의 첫 번째 컬럼으로 두는 방식이 좋습니다.
내부적으로 ClickHouse는 삽입된 데이터에 대해 파트를 생성합니다. 더 많은 데이터가 삽입될수록 파트 개수는 증가합니다. 지나치게 많은 파트가 생기면 쿼리 성능이 저하됩니다(읽어야 할 파일이 많아짐). 이를 방지하기 위해 파트는 백그라운드 비동기 프로세스에서 서로 병합됩니다. 파트 개수가 사전에 설정된 한도를 초과하면 ClickHouse는 데이터 삽입 시 예외를 발생시키며 「too many parts」 오류를 반환합니다. 이는 정상적인 운영 환경에서는 발생해서는 안 되며, ClickHouse가 잘못 설정되었거나 잘못 사용된 경우(예: 아주 작은 규모의 insert 작업을 많이 수행하는 경우)에만 발생합니다.
파트는 파티션마다 독립적으로 생성되므로, 파티션 개수가 증가하면 파트 개수도 증가하며, 이는 파티션 개수의 배수가 됩니다. 따라서 고유값 개수가 큰 파티셔닝 키는 이러한 오류를 유발할 수 있으므로 피해야 합니다.
Materialized view와 프로젝션 비교
Postgres는 하나의 테이블에 여러 인덱스를 생성할 수 있어, 다양한 액세스 패턴에 대해 최적화할 수 있습니다. 이러한 유연성 덕분에 관리자와 개발자는 특정 쿼리와 운영 요구 사항에 맞춰 데이터베이스 성능을 조정할 수 있습니다. ClickHouse의 프로젝션 개념은 이것과 정확히 같은 것은 아니지만, 테이블에 대해 여러 개의 ORDER BY 절을 지정할 수 있게 해줍니다.
ClickHouse data modeling docs에서는 ClickHouse에서 materialized view를 사용하여 사전 집계를 수행하고, 행을 변환하며, 다양한 액세스 패턴에 맞게 쿼리를 최적화하는 방법을 설명합니다.
이 중 마지막인, 다양한 액세스 패턴에 맞게 쿼리를 최적화하는 방법과 관련해서는, materialized view가 삽입을 받는 원본 테이블과는 다른 정렬 키를 가진 대상 테이블로 행을 전송하는 예시를 제시했습니다.
예를 들어, 다음 쿼리를 살펴보십시오:
이 쿼리는 UserId가 정렬 키가 아니므로 (비교적 빠르긴 하지만) 전체 9,000만 행을 스캔해야 합니다.
앞에서는 PostId를 조회하기 위한 materialized view를 사용해 이 문제를 해결했습니다. 동일한 문제는
projection을 사용해도 해결할 수 있습니다. 아래 명령은
ORDER BY user_id에 대한 프로젝션을 추가합니다.
먼저 PROJECTION을 생성한 다음 이를 구체화해야 합니다. 두 번째 명령은 디스크에 데이터가 서로 다른 정렬 순서로 두 번 저장되도록 합니다. 아래 예시와 같이 데이터를 생성할 때 PROJECTION을 함께 정의할 수도 있으며, 이후 데이터가 삽입될 때 자동으로 유지 관리됩니다.
ALTER를 통해 PROJECTION을 생성하는 경우, MATERIALIZE PROJECTION 명령을 실행하면 생성이 비동기적으로 처리됩니다. 다음 쿼리로 이 작업의 진행 상태를 확인할 수 있으며, is_done=1이 될 때까지 대기합니다.
위 쿼리를 다시 실행해 보면, 추가 스토리지 사용이라는 대가를 치르고 성능이 상당히 향상된 것을 확인할 수 있습니다.
EXPLAIN 명령으로 이 쿼리를 처리하는 데 프로젝션이 사용되었는지 확인할 수 있습니다.
프로젝션을 언제 사용해야 하는가
프로젝션은 데이터가 삽입될 때 자동으로 유지 관리되기 때문에 신규 사용자에게 매력적인 기능입니다. 또한 쿼리를 단일 테이블로 전송하기만 하면, 가능한 경우 프로젝션이 자동으로 활용되어 응답 시간이 단축됩니다.
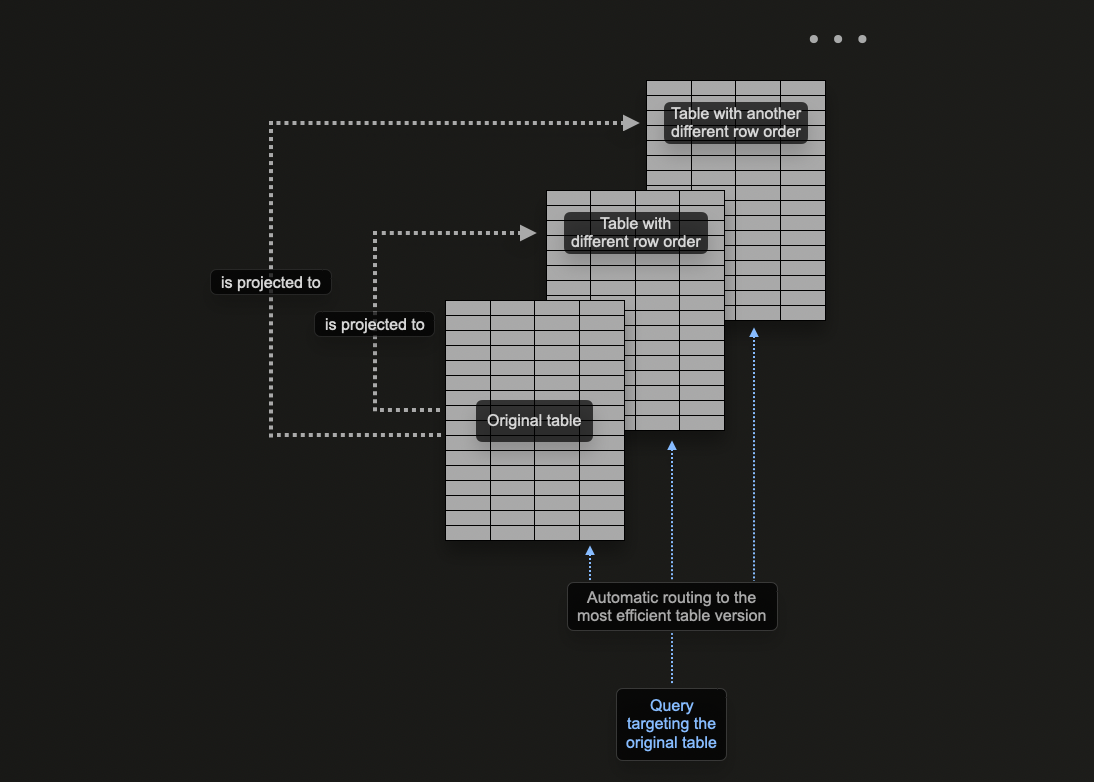
이는 materialized view와는 대조적입니다. materialized view의 경우, 사용자가 필터에 따라 적절하게 최적화된 대상 테이블을 선택하거나 쿼리를 다시 작성해야 합니다. 이로 인해 사용자 애플리케이션에 더 많은 부담이 가해지고 클라이언트 측 복잡성이 증가합니다.
이러한 이점에도 불구하고 프로젝션에는 알아두어야 할 내재적인 제약 사항이 있으며, 따라서 프로젝션은 필요한 경우에만 신중하게 사용하는 것이 좋습니다.
프로젝션은 다음과 같은 경우 사용을 권장합니다:
- 데이터의 전체 재정렬이 필요한 경우입니다. 이론적으로 프로젝션의 표현식에서
GROUP BY를 사용할 수 있지만, 집계를 유지 관리하는 데에는 materialized view가 더 효과적입니다. 쿼리 옵티마이저는SELECT * ORDER BY x와 같이 단순한 재정렬을 사용하는 프로젝션을 더 잘 활용하는 경향이 있습니다. 저장 공간을 줄이기 위해 이 표현식에서 일부 컬럼만 선택할 수 있습니다. - 저장 공간 사용량 증가와 데이터를 두 번 기록하는 오버헤드를 수용할 수 있는 경우입니다. 삽입 속도에 미치는 영향을 테스트하고 저장 공간 오버헤드를 평가하십시오.
버전 25.5부터 ClickHouse는 프로젝션에서 가상 컬럼 _part_offset을 지원합니다.
이를 통해 프로젝션을 더 공간 효율적으로 저장할 수 있습니다.
자세한 내용은 "Projections" 및 내재적인 제약 사항를 참고하십시오.
비정규화(Denormalization)
Postgres는 관계형 데이터베이스이므로 데이터 모델이 정규화되어 있는 경우가 많으며, 수백 개의 테이블로 구성되는 경우도 흔합니다. ClickHouse에서는 JOIN 성능을 최적화하기 위해 비정규화(denormalization)가 도움이 될 수 있습니다.
ClickHouse에서 Stack Overflow 데이터셋을 비정규화했을 때의 이점을 보여주는 가이드를 참고하십시오.
Postgres에서 ClickHouse로 마이그레이션하는 경우를 위한 기본 가이드는 여기까지입니다. 더 고급 ClickHouse 기능을 알아보려면 ClickHouse에서 데이터 모델링을 위한 가이드를 읽어 볼 것을 권장합니다.
