이 섹션에서는 일반적인 시나리오를 통해 analyzer, query profiling, 널 허용 컬럼 피하기와 같은 다양한 성능 및 최적화 기법을 활용하여 ClickHouse 쿼리 성능을 향상시키는 방법을 보여줍니다.
성능 최적화를 고려하기에 가장 좋은 시점은 처음으로 ClickHouse에 데이터를 수집하기 전에 데이터 스키마를 설정할 때입니다.
그러나 실제로는 데이터가 얼마나 늘어날지, 어떤 유형의 쿼리가 실행될지 예측하기가 어렵습니다.
이미 일부 쿼리가 있는 기존 배포 환경에서 성능을 개선하고자 하는 경우, 첫 번째 단계는 해당 쿼리가 어떻게 동작하는지, 그리고 어떤 쿼리는 몇 밀리초 만에 실행되는 반면 다른 쿼리는 더 오래 걸리는 이유를 이해하는 것입니다.
ClickHouse에는 쿼리가 어떤 방식으로 실행되고 실행 과정에서 어떤 리소스가 소모되는지 이해하는 데 도움이 되는 다양한 도구가 제공됩니다.
이 섹션에서는 이러한 도구와 그 사용 방법을 살펴봅니다.
일반적인 고려사항
쿼리 성능을 이해하려면 쿼리가 실행될 때 ClickHouse 내부에서 어떤 일이 발생하는지 살펴볼 필요가 있습니다.
다음 설명은 이해를 돕기 위해 일부 과정을 의도적으로 단순화한 것입니다. 목적은 세부 사항으로 압도하는 것이 아니라 기본 개념을 빠르게 파악하도록 돕는 것입니다. 더 자세한 내용은 쿼리 분석기(query analyzer)에 대한 문서를 참고하십시오.
아주 상위 수준에서 보면, ClickHouse가 쿼리를 실행할 때 다음과 같은 과정이 진행됩니다.
쿼리가 파싱되고 분석되며, 일반적인 쿼리 실행 계획이 생성됩니다.
쿼리 실행 계획이 최적화되고 불필요한 데이터가 제거되며, 쿼리 계획을 기반으로 쿼리 파이프라인이 구성됩니다.
데이터가 병렬로 읽히고 처리됩니다. 이 단계에서 ClickHouse는 필터링, 집계, 정렬과 같은 실제 쿼리 연산을 수행합니다.
결과가 병합되고 정렬되며, 클라이언트로 전송되기 전에 최종 결과 형식으로 포맷됩니다.
실제로는 많은 최적화가 수행되고 있으며, 이 가이드에서 이를 조금 더 자세히 다룰 것입니다. 그러나 지금까지의 주요 개념만으로도 ClickHouse가 쿼리를 실행할 때 내부적으로 어떤 일이 일어나는지 충분히 이해할 수 있습니다.
이러한 상위 수준의 이해를 바탕으로, ClickHouse가 제공하는 도구와 이를 사용하여 쿼리 성능에 영향을 미치는 메트릭을 추적하는 방법을 살펴보겠습니다.
데이터셋
쿼리 성능을 어떻게 개선하는지 설명하기 위해 실제 예제를 사용합니다.
NYC Taxi 데이터셋을 사용하겠습니다. 이 데이터셋에는 뉴욕시 택시 운행 데이터가 포함되어 있습니다. 먼저, 어떠한 최적화도 적용하지 않은 상태로 NYC Taxi 데이터셋을 수집하는 것부터 시작합니다.
아래는 테이블을 생성하고 S3 버킷에서 데이터를 삽입하는 명령어입니다. 스키마를 명시적으로 정의하지 않고 데이터에서 추론하도록 의도적으로 두었으며, 이는 최적화된 방식이 아니라는 점에 유의하십시오.
-- Create table with inferred schema
CREATE TABLE trips_small_inferred
ORDER BY () EMPTY
AS SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/clickhouse-academy/nyc_taxi_2009-2010.parquet');
-- Insert data into table with inferred schema
INSERT INTO trips_small_inferred
SELECT *
FROM s3Cluster
('default','https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/clickhouse-academy/nyc_taxi_2009-2010.parquet');
데이터로부터 자동으로 추론된 테이블 스키마를 살펴보겠습니다.
--- Display inferred table schema
SHOW CREATE TABLE trips_small_inferred
Query id: d97361fd-c050-478e-b831-369469f0784d
CREATE TABLE nyc_taxi.trips_small_inferred
(
`vendor_id` Nullable(String),
`pickup_datetime` Nullable(DateTime64(6, 'UTC')),
`dropoff_datetime` Nullable(DateTime64(6, 'UTC')),
`passenger_count` Nullable(Int64),
`trip_distance` Nullable(Float64),
`ratecode_id` Nullable(String),
`pickup_location_id` Nullable(String),
`dropoff_location_id` Nullable(String),
`payment_type` Nullable(Int64),
`fare_amount` Nullable(Float64),
`extra` Nullable(Float64),
`mta_tax` Nullable(Float64),
`tip_amount` Nullable(Float64),
`tolls_amount` Nullable(Float64),
`total_amount` Nullable(Float64)
)
ORDER BY tuple()
느린 쿼리 파악하기
쿼리 로그
기본적으로 ClickHouse는 실행된 각 쿼리에 대한 정보를 query logs에 수집하고 기록합니다. 이 데이터는 system.query_log 테이블에 저장됩니다.
각 실행된 쿼리에 대해 ClickHouse는 쿼리 실행 시간, 읽은 행 수, CPU·메모리 사용량, 파일시스템 캐시 적중 횟수와 같은 리소스 사용량 등의 통계를 기록합니다.
따라서 쿼리 로그는 느린 쿼리를 조사할 때 좋은 출발점입니다. 실행에 오랜 시간이 걸리는 쿼리를 쉽게 찾아낼 수 있고, 각 쿼리에 대한 리소스 사용 정보를 확인할 수 있습니다.
이제 NYC 택시 데이터셋에서 오래 실행된 쿼리 상위 5개를 찾아보겠습니다.
-- Find top 5 long running queries from nyc_taxi database in the last 1 hour
SELECT
type,
event_time,
query_duration_ms,
query,
read_rows,
tables
FROM clusterAllReplicas(default, system.query_log)
WHERE has(databases, 'nyc_taxi') AND (event_time >= (now() - toIntervalMinute(60))) AND type='QueryFinish'
ORDER BY query_duration_ms DESC
LIMIT 5
FORMAT VERTICAL
Query id: e3d48c9f-32bb-49a4-8303-080f59ed1835
Row 1:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:36
query_duration_ms: 2967
query: WITH
dateDiff('s', pickup_datetime, dropoff_datetime) as trip_time,
trip_distance / trip_time * 3600 AS speed_mph
SELECT
quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM
nyc_taxi.trips_small_inferred
WHERE
speed_mph > 30
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 2:
──────
type: QueryFinish
event_time: 2024-11-27 11:11:33
query_duration_ms: 2026
query: SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM
nyc_taxi.trips_small_inferred
WHERE
pickup_datetime >= '2009-01-01' AND pickup_datetime < '2009-04-01'
GROUP BY
payment_type
ORDER BY
trip_count DESC;
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 3:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:17
query_duration_ms: 1860
query: SELECT
avg(dateDiff('s', pickup_datetime, dropoff_datetime))
FROM nyc_taxi.trips_small_inferred
WHERE passenger_count = 1 or passenger_count = 2
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 4:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:31
query_duration_ms: 690
query: SELECT avg(total_amount) FROM nyc_taxi.trips_small_inferred WHERE trip_distance > 5
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 5:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:44
query_duration_ms: 634
query: SELECT
vendor_id,
avg(total_amount),
avg(trip_distance),
FROM
nyc_taxi.trips_small_inferred
GROUP BY vendor_id
ORDER BY 1 DESC
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
필드 query_duration_ms는 해당 쿼리의 실행에 걸린 시간을 나타냅니다. 쿼리 로그 결과를 살펴보면 첫 번째 쿼리 실행에 2967ms가 소요되고 있으며, 이는 더 개선될 수 있습니다.
또한 어떤 쿼리가 가장 많은 메모리나 CPU를 사용해 시스템에 부하를 주는지 알고 싶을 수도 있습니다.
-- Top queries by memory usage
SELECT
type,
event_time,
query_id,
formatReadableSize(memory_usage) AS memory,
ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')] AS userCPU,
ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')] AS systemCPU,
(ProfileEvents['CachedReadBufferReadFromCacheMicroseconds']) / 1000000 AS FromCacheSeconds,
(ProfileEvents['CachedReadBufferReadFromSourceMicroseconds']) / 1000000 AS FromSourceSeconds,
normalized_query_hash
FROM clusterAllReplicas(default, system.query_log)
WHERE has(databases, 'nyc_taxi') AND (type='QueryFinish') AND ((event_time >= (now() - toIntervalDay(2))) AND (event_time <= now())) AND (user NOT ILIKE '%internal%')
ORDER BY memory_usage DESC
LIMIT 30
앞에서 찾은 오래 실행되는 쿼리를 따로 떼어내어, 응답 시간을 파악하기 위해 여러 번 다시 실행합니다.
이 단계에서는 실행 결과의 재현성을 높이기 위해 enable_filesystem_cache SETTING을 0으로 설정하여 파일 시스템 캐시를 끄는 것이 중요합니다.
-- Disable filesystem cache
set enable_filesystem_cache = 0;
-- Run query 1
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) as trip_time,
trip_distance / trip_time * 3600 AS speed_mph
SELECT
quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM
nyc_taxi.trips_small_inferred
WHERE
speed_mph > 30
FORMAT JSON
----
1 row in set. Elapsed: 1.699 sec. Processed 329.04 million rows, 8.88 GB (193.72 million rows/s., 5.23 GB/s.)
Peak memory usage: 440.24 MiB.
-- Run query 2
SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM
nyc_taxi.trips_small_inferred
WHERE
pickup_datetime >= '2009-01-01' AND pickup_datetime < '2009-04-01'
GROUP BY
payment_type
ORDER BY
trip_count DESC;
---
4 rows in set. Elapsed: 1.419 sec. Processed 329.04 million rows, 5.72 GB (231.86 million rows/s., 4.03 GB/s.)
Peak memory usage: 546.75 MiB.
-- Run query 3
SELECT
avg(dateDiff('s', pickup_datetime, dropoff_datetime))
FROM nyc_taxi.trips_small_inferred
WHERE passenger_count = 1 or passenger_count = 2
FORMAT JSON
---
1 row in set. Elapsed: 1.414 sec. Processed 329.04 million rows, 8.88 GB (232.63 million rows/s., 6.28 GB/s.)
Peak memory usage: 451.53 MiB.
읽기 쉽게 표로 정리해 보겠습니다.
| Name | Elapsed | Rows processed | Peak memory |
|---|
| Query 1 | 1.699 sec | 329.04 million | 440.24 MiB |
| Query 2 | 1.419 sec | 329.04 million | 546.75 MiB |
| Query 3 | 1.414 sec | 329.04 million | 451.53 MiB |
이 쿼리들이 무엇을 수행하는지 조금 더 자세히 살펴보겠습니다.
- Query 1은 평균 속도가 시속 30마일을 초과하는 운행의 거리 분포를 계산합니다.
- Query 2는 주별 운행 횟수와 평균 비용을 구합니다.
- Query 3은 데이터셋에서 각 운행의 평균 소요 시간을 계산합니다.
이 쿼리들 가운데 첫 번째 쿼리가 매번 실행될 때마다 즉석에서 운행 시간을 계산하는 것을 제외하면, 그다지 복잡한 처리를 수행하지는 않습니다. 그러나 각 쿼리는 실행에 1초 이상이 소요되며, ClickHouse 세계에서는 상당히 긴 시간입니다. 또한 쿼리들의 메모리 사용량도 눈여겨볼 만한데, 쿼리 하나당 대략 400Mb는 꽤 많은 메모리입니다. 그리고 각 쿼리가 동일한 행 수(즉, 329.04 million)를 읽는 것으로 보입니다. 이제 이 테이블에 실제로 얼마나 많은 행이 있는지 빠르게 확인해 보겠습니다.
-- Count number of rows in table
SELECT count()
FROM nyc_taxi.trips_small_inferred
Query id: 733372c5-deaf-4719-94e3-261540933b23
┌───count()─┐
1. │ 329044175 │ -- 329.04 million
└───────────┘
이 테이블에는 3억 2,904만 행이 있으므로 각 쿼리는 테이블 전체를 스캔하게 됩니다.
EXPLAIN 문
이제 장시간 실행되는 쿼리가 생겼으니, 해당 쿼리가 어떻게 실행되는지 살펴보겠습니다. 이를 위해 ClickHouse는 EXPLAIN statement command를 지원합니다. 이 도구는 쿼리를 실제로 실행하지 않고도 쿼리 실행의 모든 단계를 매우 상세하게 보여 주는 유용한 도구입니다. ClickHouse 전문가가 아니라면 한눈에 파악하기 부담스러울 수 있지만, 쿼리가 어떻게 실행되는지에 대한 통찰을 얻기 위한 필수 도구입니다.
문서에는 EXPLAIN statement가 무엇인지와 이를 활용해 쿼리 실행을 분석하는 방법에 대한 자세한 가이드가 제공됩니다. 이 가이드의 내용을 반복하기보다는, 여기서는 쿼리 실행 성능의 병목 지점을 찾는 데 도움이 되는 몇 가지 명령에 집중하겠습니다.
Explain indexes = 1
먼저 EXPLAIN indexes = 1을 사용하여 쿼리 플랜을 살펴보겠습니다. 쿼리 플랜은 쿼리가 어떻게 실행될지를 보여 주는 트리 구조입니다. 여기에서 쿼리의 각 절이 어떤 순서로 실행되는지 확인할 수 있습니다. EXPLAIN 문이 반환하는 쿼리 플랜은 아래에서 위로 읽으면 됩니다.
이제 장시간 실행되는 쿼리 중 첫 번째를 사용해 보겠습니다.
EXPLAIN indexes = 1
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) AS trip_time,
(trip_distance / trip_time) * 3600 AS speed_mph
SELECT quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM nyc_taxi.trips_small_inferred
WHERE speed_mph > 30
Query id: f35c412a-edda-4089-914b-fa1622d69868
┌─explain─────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY)) │
2. │ Aggregating │
3. │ Expression (Before GROUP BY) │
4. │ Filter (WHERE) │
5. │ ReadFromMergeTree (nyc_taxi.trips_small_inferred) │
└─────────────────────────────────────────────────────┘
출력 결과는 직관적입니다. 쿼리는 먼저 nyc_taxi.trips_small_inferred 테이블에서 데이터를 읽는 것으로 시작합니다. 그런 다음 WHERE 절이 적용되어 계산된 값을 기준으로 행을 필터링합니다. 필터링된 데이터는 집계를 위해 준비되고, 분위수(quantiles)가 계산됩니다. 마지막으로 결과가 정렬되어 출력됩니다.
여기서는 기본 키(primary key)가 사용되지 않았음을 알 수 있는데, 이는 테이블을 생성할 때 어떤 기본 키도 정의하지 않았기 때문에 자연스러운 결과입니다. 그 결과, ClickHouse는 이 쿼리에 대해 테이블 전체 스캔(full scan)을 수행합니다.
Explain Pipeline
EXPLAIN Pipeline은 쿼리에 대한 구체적인 실행 전략을 보여줍니다. 여기에서 ClickHouse가 앞에서 살펴본 일반적인 쿼리 계획을 실제로 어떻게 실행했는지 확인할 수 있습니다.
EXPLAIN PIPELINE
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) AS trip_time,
(trip_distance / trip_time) * 3600 AS speed_mph
SELECT quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM nyc_taxi.trips_small_inferred
WHERE speed_mph > 30
Query id: c7e11e7b-d970-4e35-936c-ecfc24e3b879
┌─explain─────────────────────────────────────────────────────────────────────────────┐
1. │ (Expression) │
2. │ ExpressionTransform × 59 │
3. │ (Aggregating) │
4. │ Resize 59 → 59 │
5. │ AggregatingTransform × 59 │
6. │ StrictResize 59 → 59 │
7. │ (Expression) │
8. │ ExpressionTransform × 59 │
9. │ (Filter) │
10. │ FilterTransform × 59 │
11. │ (ReadFromMergeTree) │
12. │ MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread) × 59 0 → 1 │
여기에서 쿼리를 실행하는 데 사용된 스레드 개수는 59개이며, 이는 높은 수준의 병렬화를 나타냅니다. 이러한 병렬화는 쿼리 실행 속도를 높여 주며, 더 작은 규모의 머신에서 실행할 때보다 실행 시간이 더 짧아집니다. 동시에 실행되는 스레드 수가 많기 때문에 쿼리가 많은 메모리를 사용하는 이유를 설명할 수 있습니다.
이상적으로는 모든 느린 쿼리를 이와 같은 방식으로 분석하여 불필요하게 복잡한 쿼리 플랜을 식별하고, 각 쿼리가 읽는 행의 개수와 소비되는 리소스를 파악하는 것이 좋습니다.
Methodology
운영 환경에서 문제가 되는 쿼리를 식별하는 일은 쉽지 않습니다. ClickHouse 배포에서는 보통 언제나 매우 많은 쿼리가 실행되고 있기 때문입니다.
어떤 user, 데이터베이스, 또는 테이블에서 문제가 발생하는지 알고 있다면, system.query_logs의 user, tables, databases 필드를 사용해 검색 범위를 좁힐 수 있습니다.
최적화할 쿼리를 식별했다면, 이제 해당 쿼리의 최적화를 진행할 수 있습니다. 이 단계에서 개발자가 흔히 하는 실수는 여러 요소를 동시에 변경하고, 임시(ad-hoc) 실험을 수행해 결과가 뒤섞이게 만드는 것입니다. 더 큰 문제는 쿼리가 왜 빨라졌는지에 대한 충분한 이해를 얻지 못하게 된다는 점입니다.
쿼리 최적화에는 체계가 필요합니다. 여기서 고급 벤치마킹을 말하는 것은 아니지만, 변경 사항이 쿼리 성능에 어떤 영향을 주는지 이해하기 위한 단순한 프로세스를 갖추는 것만으로도 큰 도움이 됩니다.
먼저 쿼리 로그에서 느린 쿼리를 식별한 후, 잠재적인 개선 사항을 각각 분리해서 조사하십시오. 쿼리를 테스트할 때는 filesystem cache를 비활성화해야 합니다.
ClickHouse는 여러 단계에서 쿼리 성능을 높이기 위해 caching을 활용합니다. 이는 쿼리 성능에는 유리하지만, 문제를 해결할 때는 잠재적인 I/O 병목이나 비효율적인 테이블 스키마를 감출 수 있습니다. 이러한 이유로, 테스트하는 동안에는 filesystem cache를 끄는 것을 권장합니다. 운영 환경에서는 반드시 다시 활성화해 두어야 합니다.
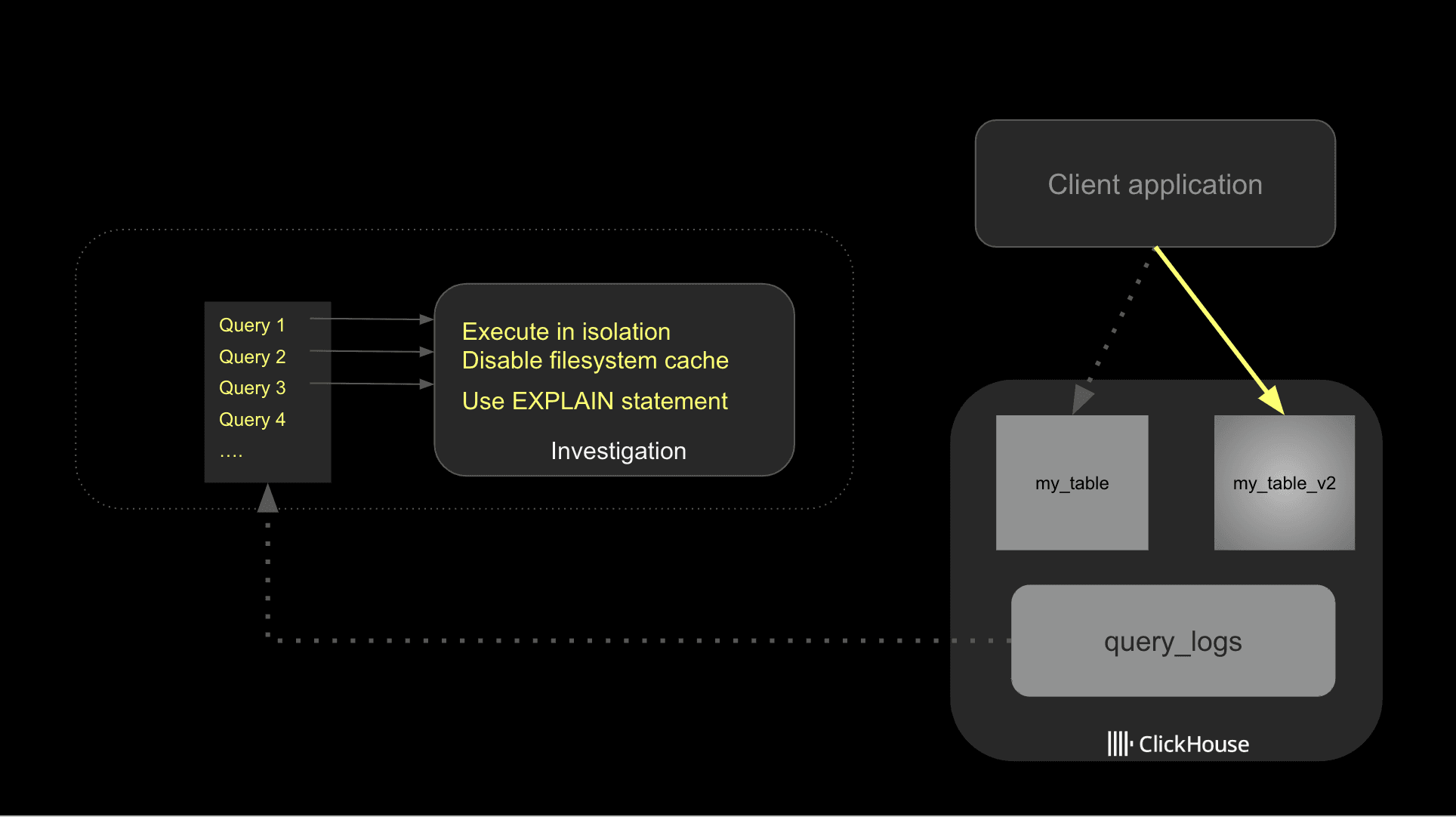
잠재적인 최적화 방법을 파악했다면, 성능에 미치는 영향을 더 잘 추적할 수 있도록 하나씩 순차적으로 적용하는 것이 좋습니다. 아래 다이어그램은 전반적인 접근 방식을 설명합니다.
마지막으로, 이상치(outlier)에 주의해야 합니다. 사용자가 임시로 매우 비용이 큰 쿼리를 실행했거나, 다른 이유로 시스템이 과부하 상태였기 때문에 쿼리가 느리게 실행되는 경우는 매우 흔합니다. 정기적으로 실행되는 비용이 큰 쿼리를 식별하기 위해서는 normalized_query_hash 필드로 GROUP BY하여 확인할 수 있습니다. 이러한 쿼리가 조사 대상이 될 가능성이 가장 높습니다.
기본 최적화
이제 테스트를 위한 프레임워크를 마련했으므로 최적화를 시작할 수 있습니다.
가장 먼저 살펴볼 부분은 데이터가 어떻게 저장되어 있는지입니다. 어떤 데이터베이스든 읽어야 하는 데이터가 적을수록 쿼리 실행 속도는 빨라집니다.
데이터를 어떤 방식으로 수집했는지에 따라, 수집된 데이터를 기반으로 테이블 스키마를 추론하기 위해 ClickHouse의 기능을 활용했을 수 있습니다. 이는 시작 단계에서는 매우 편리하지만, 쿼리 성능을 최적화하려면 사용 목적에 가장 잘 맞도록 데이터 스키마를 다시 검토해야 합니다.
널 허용(Nullable)
모범 사례 문서에 설명된 대로, 가능하면 널 허용 컬럼은 사용을 피하는 것이 좋습니다. 널 허용 컬럼은 데이터 수집 메커니즘을 더 유연하게 만들어 자주 사용하고 싶은 유혹이 있지만, 매번 추가 컬럼을 처리해야 하므로 성능에 부정적인 영향을 줍니다.
NULL 값을 가진 행의 개수를 세는 SQL 쿼리를 실행하면, 실제로 널 허용이 필요한 테이블 컬럼을 쉽게 식별할 수 있습니다.
-- Find non-null values columns
SELECT
countIf(vendor_id IS NULL) AS vendor_id_nulls,
countIf(pickup_datetime IS NULL) AS pickup_datetime_nulls,
countIf(dropoff_datetime IS NULL) AS dropoff_datetime_nulls,
countIf(passenger_count IS NULL) AS passenger_count_nulls,
countIf(trip_distance IS NULL) AS trip_distance_nulls,
countIf(fare_amount IS NULL) AS fare_amount_nulls,
countIf(mta_tax IS NULL) AS mta_tax_nulls,
countIf(tip_amount IS NULL) AS tip_amount_nulls,
countIf(tolls_amount IS NULL) AS tolls_amount_nulls,
countIf(total_amount IS NULL) AS total_amount_nulls,
countIf(payment_type IS NULL) AS payment_type_nulls,
countIf(pickup_location_id IS NULL) AS pickup_location_id_nulls,
countIf(dropoff_location_id IS NULL) AS dropoff_location_id_nulls
FROM trips_small_inferred
FORMAT VERTICAL
Query id: 4a70fc5b-2501-41c8-813c-45ce241d85ae
Row 1:
──────
vendor_id_nulls: 0
pickup_datetime_nulls: 0
dropoff_datetime_nulls: 0
passenger_count_nulls: 0
trip_distance_nulls: 0
fare_amount_nulls: 0
mta_tax_nulls: 137946731
tip_amount_nulls: 0
tolls_amount_nulls: 0
total_amount_nulls: 0
payment_type_nulls: 69305
pickup_location_id_nulls: 0
dropoff_location_id_nulls: 0
NULL 값이 들어 있는 컬럼은 mta_tax와 payment_type 두 개뿐입니다. 나머지 필드는 널 허용 컬럼(Nullable 컬럼)을 사용해서는 안 됩니다.
낮은 카디널리티
String 타입에 쉽게 적용할 수 있는 최적화 방법 중 하나는 LowCardinality 데이터 타입을 적극적으로 활용하는 것입니다. 낮은 카디널리티에 대한 문서에 설명된 것처럼, ClickHouse는 LowCardinality 컬럼에 딕셔너리 코딩을 적용하여 쿼리 성능을 크게 향상시킵니다.
어떤 컬럼이 LowCardinality에 적합한지 판단하기 위한 간단한 기준은, 고유 값이 10,000개 미만인 컬럼은 모두 이상적인 후보라는 점입니다.
다음 SQL 쿼리를 사용하여 고유 값 개수가 낮은 컬럼을 찾을 수 있습니다.
-- Identify low cardinality columns
SELECT
uniq(ratecode_id),
uniq(pickup_location_id),
uniq(dropoff_location_id),
uniq(vendor_id)
FROM trips_small_inferred
FORMAT VERTICAL
Query id: d502c6a1-c9bc-4415-9d86-5de74dd6d932
Row 1:
──────
uniq(ratecode_id): 6
uniq(pickup_location_id): 260
uniq(dropoff_location_id): 260
uniq(vendor_id): 3
카디널리티가 낮으므로 ratecode_id, pickup_location_id, dropoff_location_id, vendor_id 네 개 컬럼은 LowCardinality 필드 타입의 좋은 후보입니다.
데이터 타입 최적화
ClickHouse는 다양한 데이터 타입을 지원합니다. 성능을 최적화하고 디스크에 저장되는 데이터 공간을 줄이기 위해, 사용 사례에 맞는 가능한 한 가장 작은 데이터 타입을 선택해야 합니다.
숫자형 데이터의 경우, 데이터셋의 최소/최대 값을 확인하여 현재 정밀도 설정이 데이터셋의 실제 범위와 일치하는지 점검할 수 있습니다.
-- Find min/max values for the payment_type field
SELECT
min(payment_type),max(payment_type),
min(passenger_count), max(passenger_count)
FROM trips_small_inferred
Query id: 4306a8e1-2a9c-4b06-97b4-4d902d2233eb
┌─min(payment_type)─┬─max(payment_type)─┐
1. │ 1 │ 4 │
└───────────────────┴───────────────────┘
날짜에는 데이터셋에 맞고 실행하려는 쿼리를 최적으로 지원하는 정밀도를 선택해야 합니다.
최적화 적용
최적화된 스키마를 사용하기 위해 새 테이블을 생성하고 데이터를 다시 수집합니다.
-- Create table with optimized data
CREATE TABLE trips_small_no_pk
(
`vendor_id` LowCardinality(String),
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`passenger_count` UInt8,
`trip_distance` Float32,
`ratecode_id` LowCardinality(String),
`pickup_location_id` LowCardinality(String),
`dropoff_location_id` LowCardinality(String),
`payment_type` Nullable(UInt8),
`fare_amount` Decimal32(2),
`extra` Decimal32(2),
`mta_tax` Nullable(Decimal32(2)),
`tip_amount` Decimal32(2),
`tolls_amount` Decimal32(2),
`total_amount` Decimal32(2)
)
ORDER BY tuple();
-- Insert the data
INSERT INTO trips_small_no_pk SELECT * FROM trips_small_inferred
새로운 테이블을 사용하여 다시 쿼리를 실행해 개선 여부를 확인합니다.
| Name | Run 1 - Elapsed | Elapsed | Rows processed | Peak memory |
|---|
| Query 1 | 1.699 sec | 1.353 sec | 329.04 million | 337.12 MiB |
| Query 2 | 1.419 sec | 1.171 sec | 329.04 million | 531.09 MiB |
| Query 3 | 1.414 sec | 1.188 sec | 329.04 million | 265.05 MiB |
쿼리 시간과 메모리 사용량이 모두 개선된 것을 확인할 수 있습니다. 데이터 스키마를 최적화하여 동일한 데이터를 표현하는 데 필요한 전체 데이터 양을 줄였기 때문에, 메모리 사용량이 감소하고 처리 시간도 단축되었습니다.
테이블 크기를 확인하여 차이를 살펴보겠습니다.
SELECT
`table`,
formatReadableSize(sum(data_compressed_bytes) AS size) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes) AS usize) AS uncompressed,
sum(rows) AS rows
FROM system.parts
WHERE (active = 1) AND ((`table` = 'trips_small_no_pk') OR (`table` = 'trips_small_inferred'))
GROUP BY
database,
`table`
ORDER BY size DESC
Query id: 72b5eb1c-ff33-4fdb-9d29-dd076ac6f532
┌─table────────────────┬─compressed─┬─uncompressed─┬──────rows─┐
1. │ trips_small_inferred │ 7.38 GiB │ 37.41 GiB │ 329044175 │
2. │ trips_small_no_pk │ 4.89 GiB │ 15.31 GiB │ 329044175 │
└──────────────────────┴────────────┴──────────────┴───────────┘
새로 생성한 테이블은 이전 테이블보다 상당히 작습니다. 테이블이 차지하는 디스크 공간이 약 34% 감소한 것을 확인할 수 있습니다(7.38 GiB 대비 4.89 GiB).
기본 키의 중요성
ClickHouse에서 기본 키는 대부분의 기존 데이터베이스 시스템과는 다르게 동작합니다. 이런 시스템에서 기본 키는 고유성과 데이터 무결성을 보장합니다. 중복된 기본 키 값을 삽입하려는 모든 시도는 거부되며, 빠른 조회를 위해 보통 B-tree 또는 해시 기반 인덱스가 생성됩니다.
ClickHouse에서 기본 키의 목적은 다릅니다. 고유성을 강제하거나 데이터 무결성에 기여하지 않습니다. 대신 쿼리 성능을 최적화하도록 설계되었습니다. 기본 키는 디스크에 데이터가 저장되는 순서를 정의하며, 각 그래뉼의 첫 번째 행을 가리키는 포인터를 저장하는 희소 인덱스로 구현됩니다.
ClickHouse의 그래뉼은 쿼리 실행 중에 읽히는 데이터의 최소 단위입니다. index_granularity에 의해 결정되는, 최대 고정 개수의 행을 포함하며, 기본값은 8,192행입니다. 그래뉼은 연속적으로 저장되고 기본 키에 의해 정렬됩니다.
적절한 기본 키 집합을 선택하는 것은 성능에 매우 중요하며, 실제로 동일한 데이터를 여러 테이블에 중복 저장하고 서로 다른 기본 키 집합을 사용하여 특정 쿼리 집합을 빠르게 처리하는 경우가 흔합니다.
Projection이나 materialized view와 같이 ClickHouse에서 지원하는 다른 옵션을 사용하면 동일한 데이터에 대해 다른 기본 키 집합을 사용할 수 있습니다. 이 블로그 시리즈의 두 번째 글에서 이에 대해 더 자세히 다룹니다.
기본 키 선택
올바른 기본 키 집합을 선택하는 일은 복잡한 주제이며, 최적의 조합을 찾기 위해 여러 가지 절충과 실험이 필요할 수 있습니다.
지금은 다음과 같은 간단한 모범 사례를 따르겠습니다.
- 대부분의 쿼리에서 필터링에 사용되는 필드를 사용합니다.
- 카디널리티가 더 낮은 컬럼을 먼저 선택합니다.
- 타임스탬프 데이터셋에서는 시간 기준으로 필터링하는 경우가 매우 흔하므로, 기본 키에 시간 기반 요소를 포함하는 방안을 고려합니다.
이번 예제에서는 다음과 같은 기본 키 조합을 사용해 실험합니다: passenger_count, pickup_datetime, dropoff_datetime.
passenger_count의 카디널리티는 낮으며(고유 값 24개) 느린 쿼리에서 사용됩니다. 또한 자주 필터링에 사용될 수 있도록 타임스탬프 필드(pickup_datetime 및 dropoff_datetime)를 추가합니다.
기본 키를 반영한 새 테이블을 만들고 데이터를 다시 수집합니다.
CREATE TABLE trips_small_pk
(
`vendor_id` UInt8,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`passenger_count` UInt8,
`trip_distance` Float32,
`ratecode_id` LowCardinality(String),
`pickup_location_id` UInt16,
`dropoff_location_id` UInt16,
`payment_type` Nullable(UInt8),
`fare_amount` Decimal32(2),
`extra` Decimal32(2),
`mta_tax` Nullable(Decimal32(2)),
`tip_amount` Decimal32(2),
`tolls_amount` Decimal32(2),
`total_amount` Decimal32(2)
)
PRIMARY KEY (passenger_count, pickup_datetime, dropoff_datetime);
-- Insert the data
INSERT INTO trips_small_pk SELECT * FROM trips_small_inferred
이제 쿼리를 다시 실행합니다. 세 번의 실험 결과를 정리하여 경과 시간, 처리한 행 수, 메모리 사용량이 얼마나 개선되었는지 확인합니다.
| 쿼리 1 |
|---|
| 실행 1 | 실행 2 | 실행 3 |
|---|
| 경과 시간 | 1.699 sec | 1.353 sec | 0.765 sec |
| 처리한 행 수 | 329.04 million | 329.04 million | 329.04 million |
| 최대 메모리 사용량 | 440.24 MiB | 337.12 MiB | 444.19 MiB |
| 쿼리 2 |
|---|
| 실행 1 | 실행 2 | 실행 3 |
|---|
| 경과 시간 | 1.419 sec | 1.171 sec | 0.248 sec |
| 처리한 행 수 | 329.04 million | 329.04 million | 41.46 million |
| 최대 메모리 사용량 | 546.75 MiB | 531.09 MiB | 173.50 MiB |
| Query 3 |
|---|
| 1회 실행 | 2회 실행 | 3회 실행 |
|---|
| 경과 시간 | 1.414초 | 1.188초 | 0.431초 |
| 처리된 행 수 | 3.2904억 | 3.2904억 | 2.7699억 |
| 최대 메모리 사용량 | 451.53 MiB | 265.05 MiB | 197.38 MiB |
실행 시간과 메모리 사용량 전반에서 상당한 개선이 있음을 확인할 수 있습니다.
Query 2는 기본 키(primary key)로부터 가장 큰 이점을 얻습니다. 생성된 쿼리 플랜이 이전과 어떻게 달라졌는지 살펴보겠습니다.
EXPLAIN indexes = 1
SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM nyc_taxi.trips_small_pk
WHERE (pickup_datetime >= '2009-01-01') AND (pickup_datetime < '2009-04-01')
GROUP BY payment_type
ORDER BY trip_count DESC
Query id: 30116a77-ba86-4e9f-a9a2-a01670ad2e15
┌─explain──────────────────────────────────────────────────────────────────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY [lifted up part])) │
2. │ Sorting (Sorting for ORDER BY) │
3. │ Expression (Before ORDER BY) │
4. │ Aggregating │
5. │ Expression (Before GROUP BY) │
6. │ Expression │
7. │ ReadFromMergeTree (nyc_taxi.trips_small_pk) │
8. │ Indexes: │
9. │ PrimaryKey │
10. │ Keys: │
11. │ pickup_datetime │
12. │ Condition: and((pickup_datetime in (-Inf, 1238543999]), (pickup_datetime in [1230768000, +Inf))) │
13. │ Parts: 9/9 │
14. │ Granules: 5061/40167 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
기본 키 덕분에 테이블의 그래뉼 중 일부만 선택되었습니다. 이 점만으로도 ClickHouse가 처리해야 하는 데이터가 크게 줄어들어 쿼리 성능이 크게 향상됩니다.
다음 단계
이 가이드가 ClickHouse에서 느린 쿼리를 조사하고 더 빠르게 만드는 방법을 이해하는 데 도움이 되었기를 바랍니다. 이 주제를 더 깊이 살펴보려면 query analyzer와 profiling을 참고하여 ClickHouse가 쿼리를 정확히 어떻게 실행하는지 더 잘 이해하기 바랍니다.
ClickHouse의 특성에 점차 익숙해지면, partitioning keys와 data skipping indexes에 대해 읽어 보기를 권장합니다. 이를 통해 쿼리를 가속화하는 데 활용할 수 있는 보다 고급 기법을 학습할 수 있습니다.