이 페이지에서는 "ordering key"라는 용어를 "primary key"와 혼용해 사용합니다. 엄밀히 말하면 ClickHouse에서는 이 둘이 다릅니다. 그러나 이 문서의 목적상 두 용어를 같은 의미로 사용해도 되며, ordering key는 테이블의 ORDER BY에 지정된 컬럼을 가리키는 것으로 이해하면 됩니다.
ClickHouse의 primary key는 Postgres와 같은 OLTP 데이터베이스에서 사용되는 유사한 용어와는 동작 방식이 매우 다릅니다.
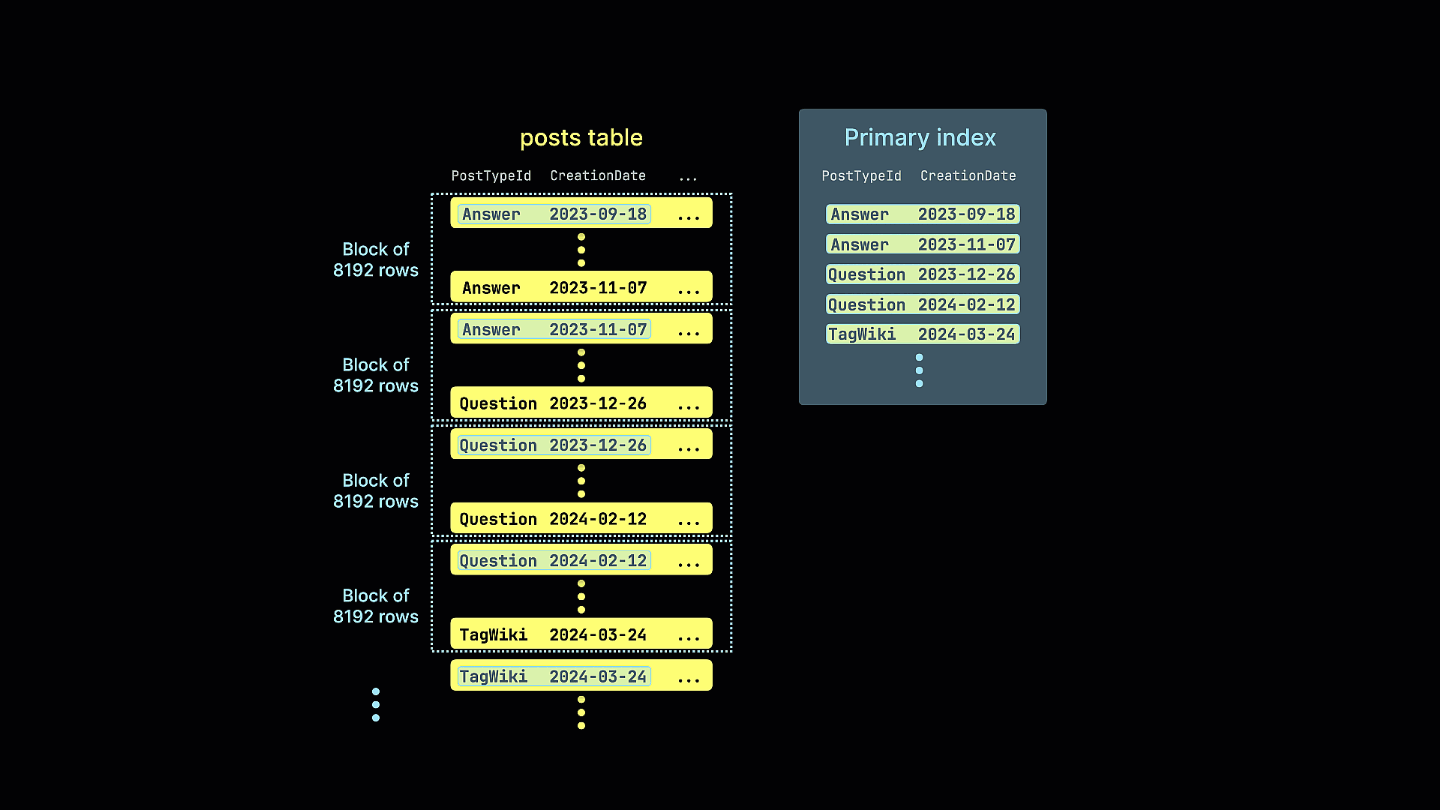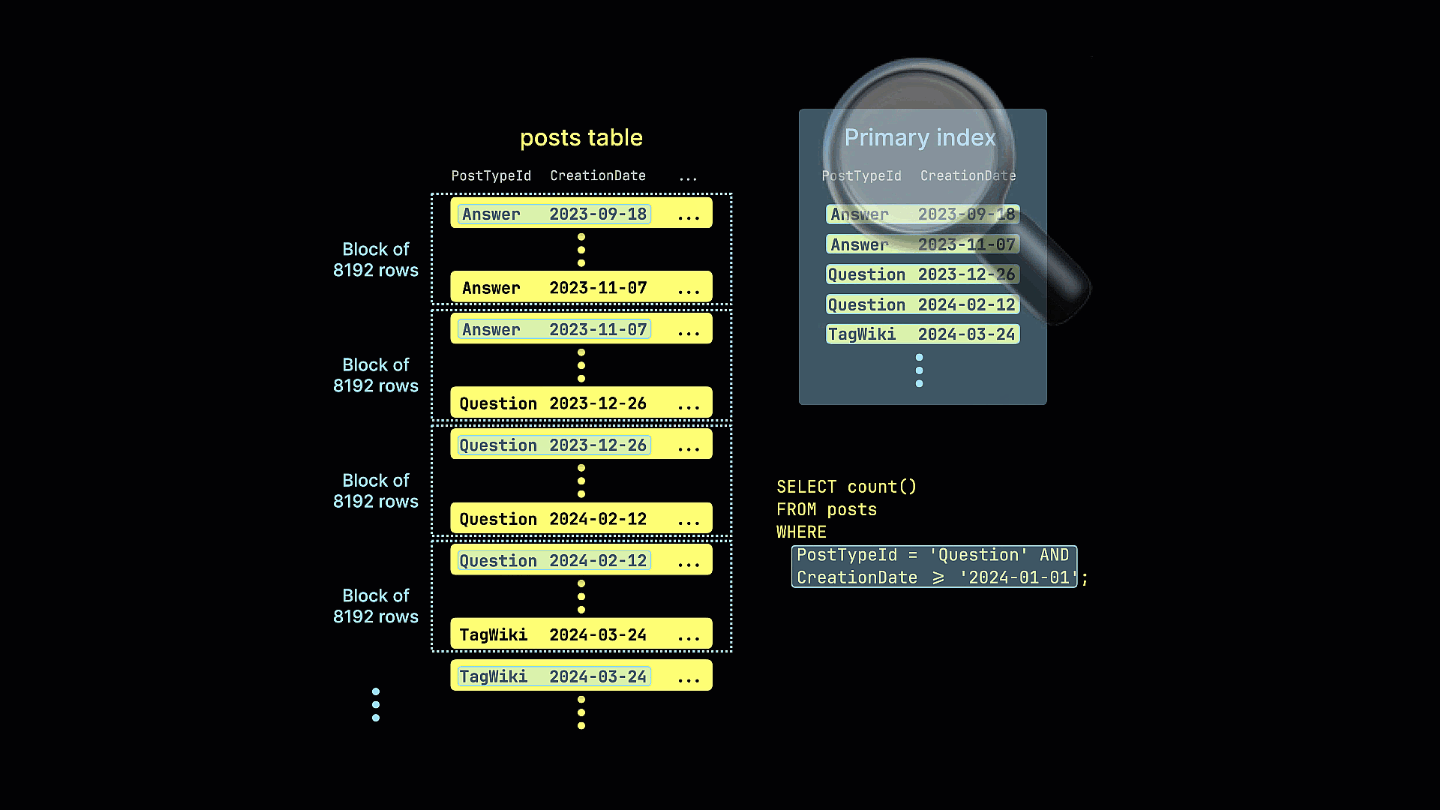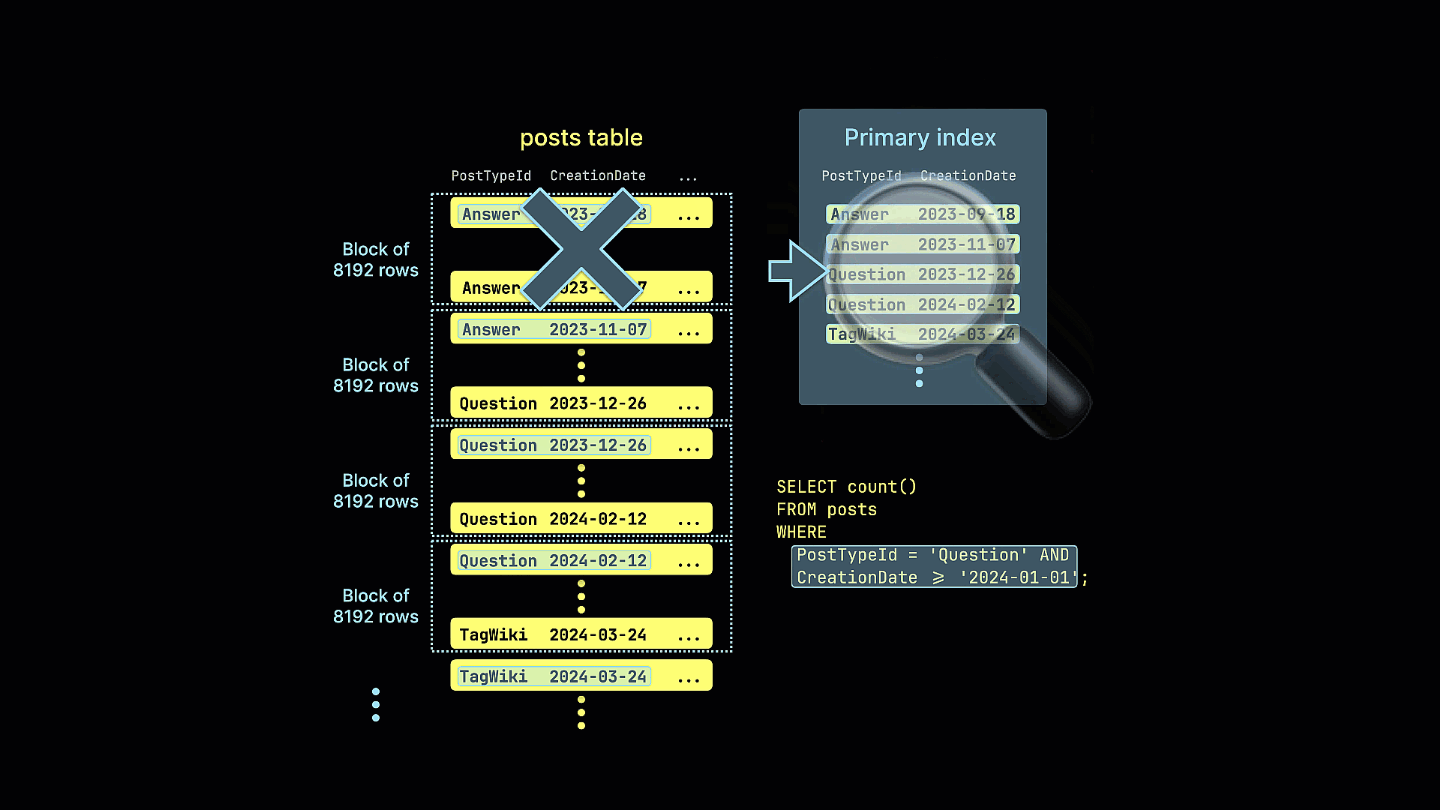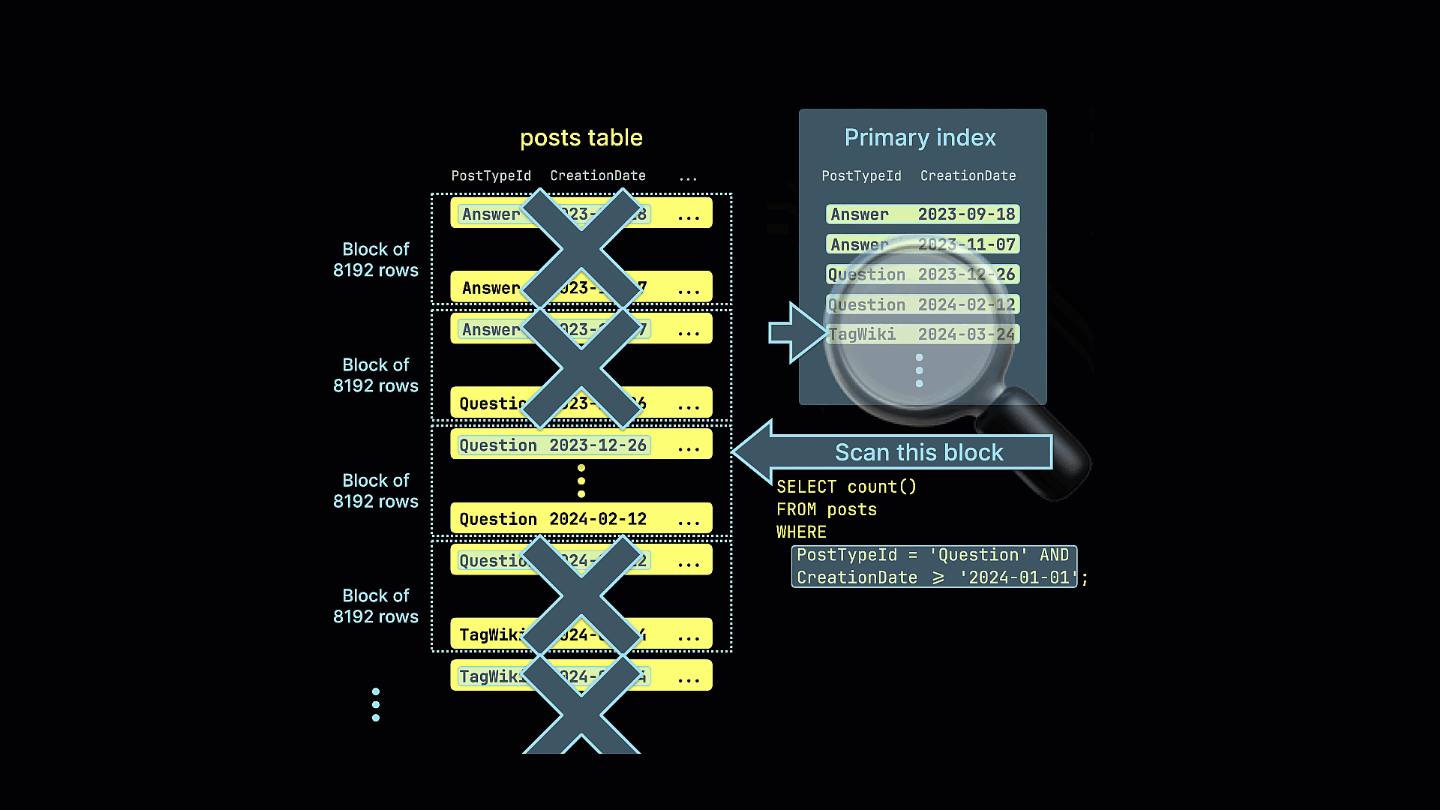
ClickHouse에서 효과적인 primary key를 선택하는 것은 쿼리 성능과 저장 효율성에 매우 중요합니다. ClickHouse는 데이터를 파트로 구성하며, 각 파트에는 자체적인 희소 primary 인덱스가 포함됩니다. 이 인덱스는 스캔되는 데이터의 양을 줄여 쿼리 성능을 크게 향상시킵니다. 또한 primary key는 디스크에서 데이터의 물리적 순서를 결정하므로, 압축 효율에도 직접적인 영향을 미칩니다. 최적으로 정렬된 데이터는 더 잘 압축되며, 이는 I/O를 줄여 성능을 더욱 향상시킵니다.
- ordering key를 선택할 때에는 쿼리 필터(즉,
WHERE 절)에서 자주 사용되는 컬럼, 특히 많은 행을 제외하는 컬럼에 우선순위를 두십시오.
- 테이블의 다른 데이터와 높은 상관성을 가지는 컬럼 또한 유리합니다. 인접하게 저장되면 압축률이 개선되고,
GROUP BY 및 ORDER BY 연산 중 메모리 효율이 향상되기 때문입니다.
ordering key를 선택하는 데 도움이 되는 몇 가지 간단한 규칙을 적용할 수 있습니다. 다음 원칙들은 서로 충돌할 수 있으므로, 순서대로 고려하십시오. 이 과정을 통해 여러 개의 키를 도출할 수 있으며, 일반적으로 4–5개면 충분합니다.
중요
Ordering key는 테이블 생성 시 정의해야 하며 나중에 추가할 수 없습니다. 추가 정렬은 프로젝션(projections)이라는 기능을 통해 데이터 삽입 이후(또는 이전)에 테이블에 추가할 수 있습니다. 이 기능은 데이터가 중복 저장된다는 점에 유의해야 합니다. 자세한 내용은 여기를 참조하십시오.
다음 posts_unordered 테이블을 참고하세요. 이 테이블은 Stack Overflow 게시물마다 하나의 행을 포함합니다.
이 테이블에는 기본 키가 없습니다 - ORDER BY tuple()로 표시됩니다.
CREATE TABLE posts_unordered
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4,
'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense`LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
사용자가 2024년 이후 제출된 질문 수를 계산하고자 하며, 이것이 가장 일반적인 접근 패턴이라고 가정합니다.
SELECT count()
FROM stackoverflow.posts_unordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─count()─┐
│ 192611 │
└─────────┘
--highlight-next-line
1 row in set. Elapsed: 0.055 sec. Processed 59.82 million rows, 361.34 MB (1.09 billion rows/s., 6.61 GB/s.)
이 쿼리가 읽은 행 수와 바이트 수를 확인하세요. 기본 키가 없으면 쿼리는 전체 데이터셋을 스캔해야 합니다.
EXPLAIN indexes=1을 사용하면 인덱싱이 없어 전체 테이블 스캔이 발생함을 확인할 수 있습니다.
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts_unordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─explain───────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts_unordered) │
└───────────────────────────────────────────────────────────┘
5 rows in set. Elapsed: 0.003 sec.
동일한 데이터를 포함하는 posts_ordered 테이블이 ORDER BY를 (PostTypeId, toDate(CreationDate))로 정의되어 있다고 가정하겠습니다. 즉,
CREATE TABLE posts_ordered
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6,
'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
...
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate))
PostTypeId는 카디널리티가 8이며 정렬 키의 첫 번째 항목으로 논리적인 선택입니다. 날짜 단위 필터링만으로도 충분할 것으로 판단되므로(datetime 필터에도 여전히 도움이 됩니다) toDate(CreationDate)를 키의 두 번째 구성 요소로 사용합니다. 날짜는 16비트로 표현할 수 있기 때문에 더 작은 인덱스가 생성되어 필터링 속도가 향상됩니다.
다음 애니메이션은 Stack Overflow 게시물 테이블에 대해 최적화된 희소 기본 인덱스가 생성되는 과정을 보여줍니다. 개별 행을 인덱싱하는 대신, 인덱스는 행 블록을 대상으로 합니다:
동일한 쿼리를 이 정렬 키를 가진 테이블에서 반복 실행하면:
SELECT count()
FROM stackoverflow.posts_ordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─count()─┐
│ 192611 │
└─────────┘
--highlight-next-line
1 row in set. Elapsed: 0.013 sec. Processed 196.53 thousand rows, 1.77 MB (14.64 million rows/s., 131.78 MB/s.)
이 쿼리는 이제 희소 인덱싱을 활용하여 읽는 데이터 양을 크게 줄이고 실행 시간을 4배 단축합니다. 읽힌 행 수와 바이트 수가 줄어든 것을 확인할 수 있습니다.
인덱스 사용 여부는 EXPLAIN indexes=1로 확인할 수 있습니다.
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts_ordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─explain─────────────────────────────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts_ordered) │
│ Indexes: │
│ PrimaryKey │
│ Keys: │
│ PostTypeId │
│ toDate(CreationDate) │
│ Condition: and((PostTypeId in [1, 1]), (toDate(CreationDate) in [19723, +Inf))) │
│ Parts: 14/14 │
│ Granules: 39/7578 │
└─────────────────────────────────────────────────────────────────────────────────────────────┘
13 rows in set. Elapsed: 0.004 sec.
추가로, 희소 인덱스가 예제 쿼리에 대해 일치할 가능성이 전혀 없는 모든 행 블록을 어떻게 걸러내는지 시각화합니다:
참고
테이블의 모든 컬럼은 지정된 정렬 키의 값에 따라 정렬되며, 이는 해당 컬럼이 키에 포함되어 있는지 여부와 상관없습니다. 예를 들어 CreationDate가 키로 사용되는 경우, 다른 모든 컬럼의 값 순서는 CreationDate 컬럼의 값 순서와 일치하게 됩니다. 여러 개의 정렬 키를 지정할 수 있으며, 이는 SELECT 쿼리에서 ORDER BY 절을 사용하는 것과 동일한 방식으로 정렬이 수행됩니다.
기본 키 선택에 대한 포괄적인 고급 가이드는 여기에서 확인할 수 있습니다.
정렬 키가 압축을 향상하고 저장소를 추가로 최적화하는 방법에 대해 더 깊이 이해하려면, Compression in ClickHouse 및 Column Compression Codecs에 대한 공식 가이드를 참고하십시오.