Private preview in ClickHouse Cloud
ClickHouse Managed Postgres는 NVMe 스토리지를 기반으로 하는 엔터프라이즈급 Postgres로, EBS와 같은 네트워크 연결 스토리지와 비교하여 디스크에 의해 제약되는 워크로드에서 최대 10배 빠른 성능을 제공합니다. 이 빠른 시작 가이드는 두 부분으로 구성됩니다:
- Part 1: NVMe Postgres를 시작하여 성능을 확인합니다
- Part 2: ClickHouse와 통합하여 실시간 분석을 활성화합니다
Managed Postgres는 현재 여러 AWS 리전에서 제공되며, 프라이빗 프리뷰 기간 동안 무료로 사용할 수 있습니다.
이 빠른 시작 가이드에서 수행할 작업은 다음과 같습니다:
- NVMe 기반 성능을 제공하는 Managed Postgres 인스턴스를 생성합니다
- 100만 개의 샘플 이벤트를 로드하고 NVMe 속도를 직접 확인합니다
- 쿼리를 실행하여 낮은 지연 시간의 성능을 경험합니다
- 데이터를 ClickHouse로 복제하여 실시간 분석을 수행합니다
pg_clickhouse를 사용하여 Postgres에서 ClickHouse를 직접 쿼리합니다
1부: NVMe Postgres 시작하기
데이터베이스 생성
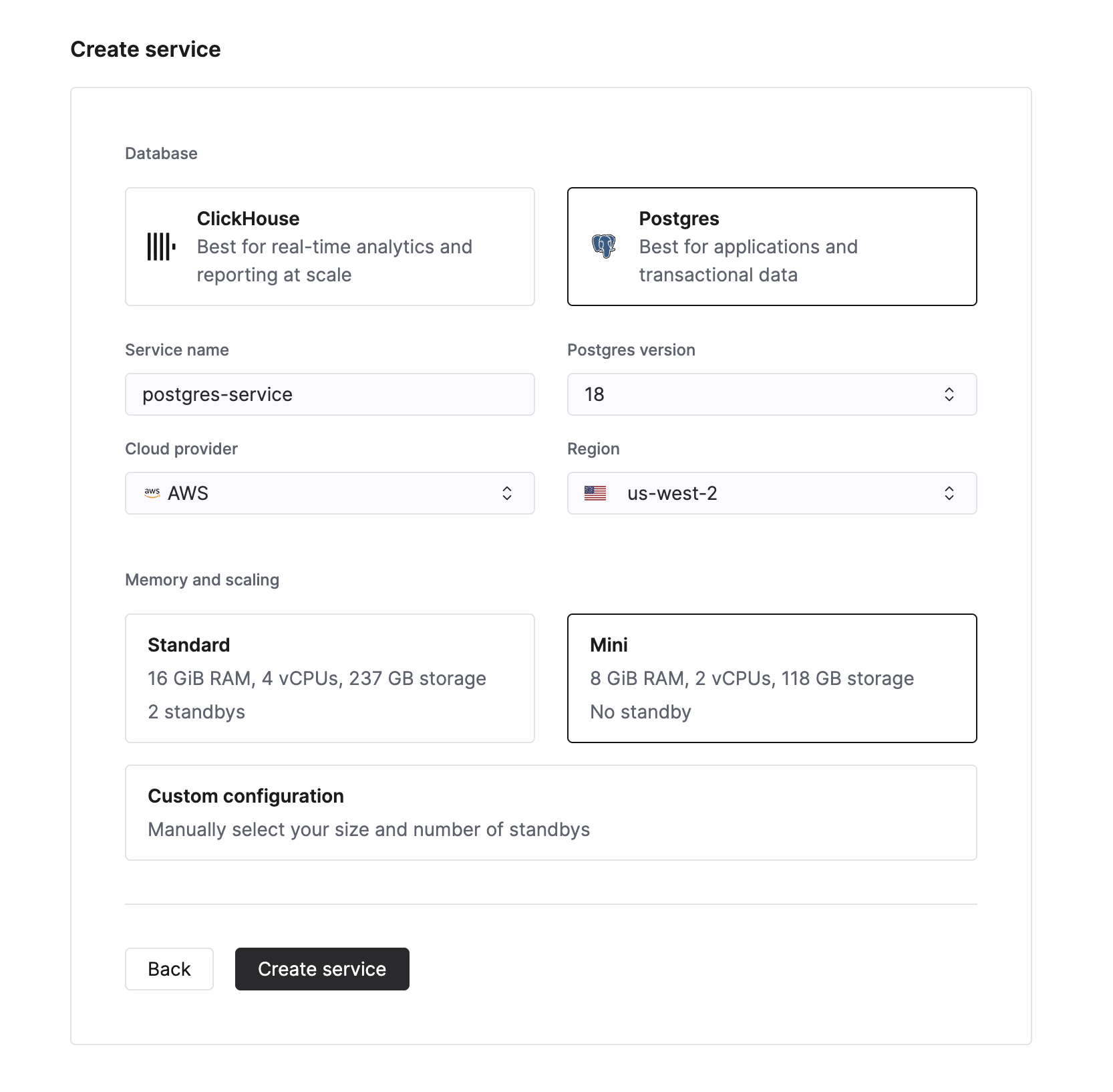
새 Managed Postgres 서비스를 만들려면 Cloud Console의 서비스 목록에서 New service 버튼을 클릭합니다. 그런 다음 데이터베이스 유형으로 Postgres를 선택합니다.
데이터베이스 인스턴스 이름을 입력하고 Create service를 클릭합니다. 그러면 개요 페이지로 이동합니다.
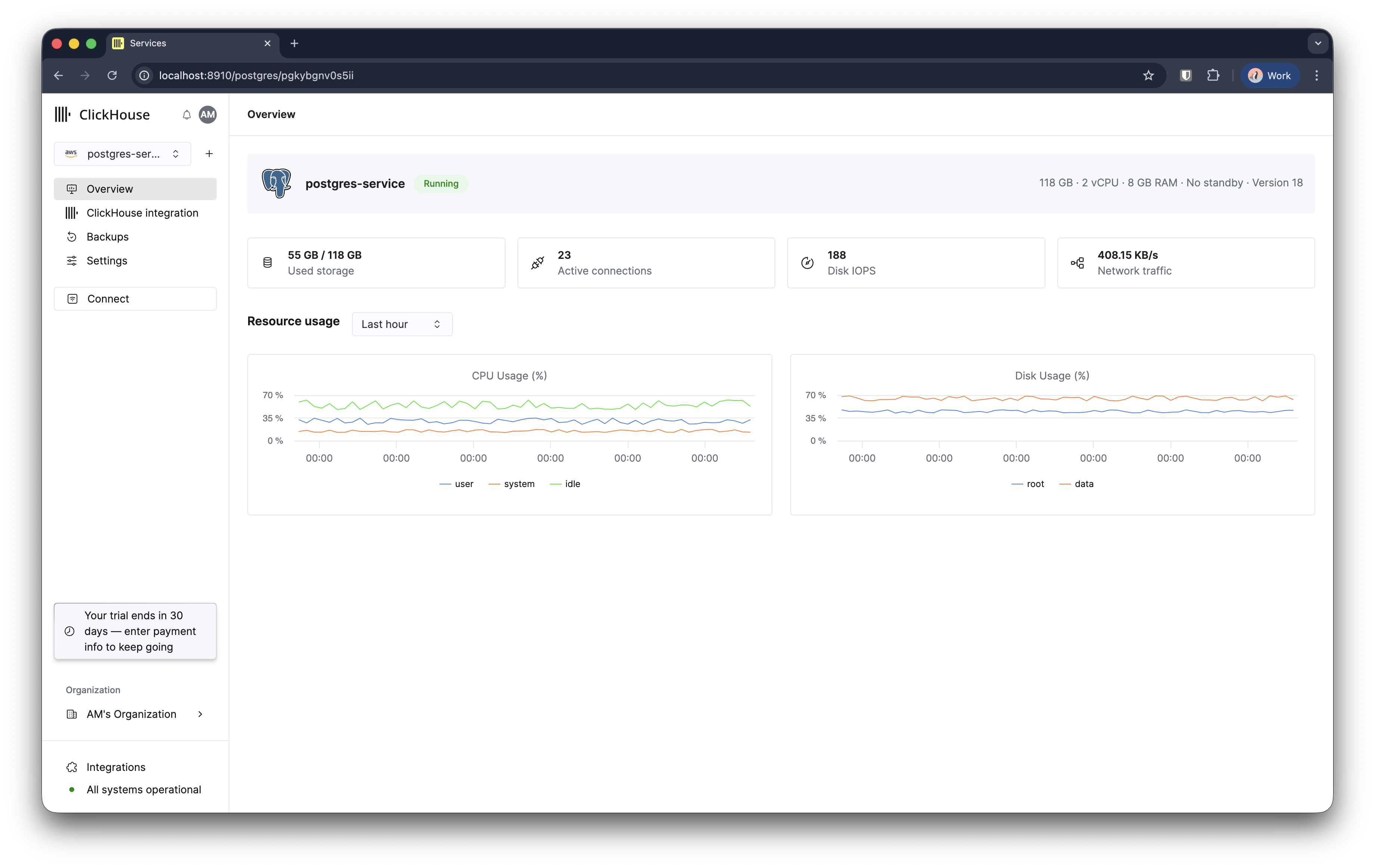
Managed Postgres 인스턴스는 3–5분 이내에 프로비저닝되어 사용할 준비가 됩니다.
데이터베이스에 연결하기
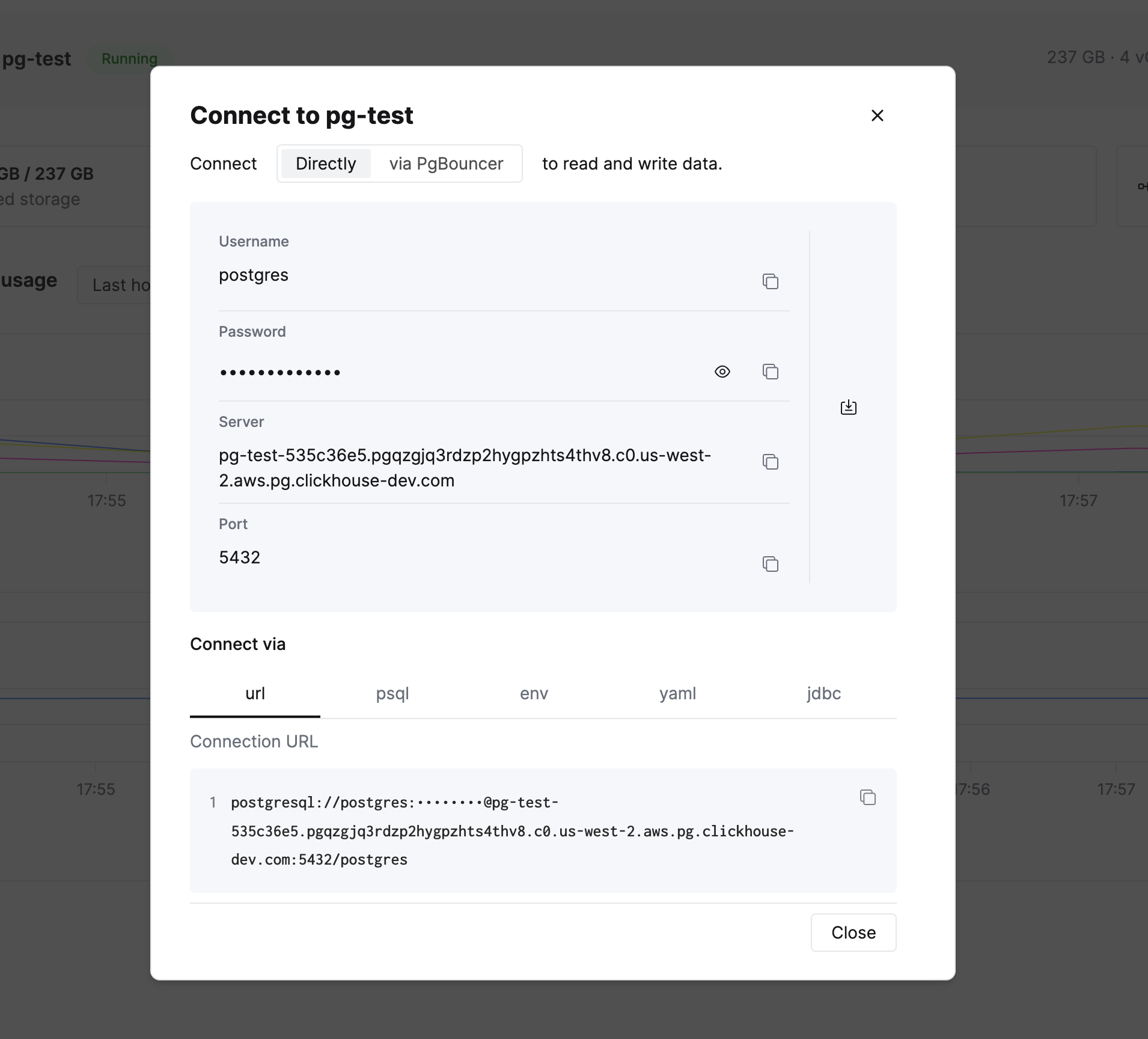
왼쪽 사이드바에 Connect 버튼이 있습니다. 이를 클릭하면 연결 정보와 여러 형식의 연결 문자열을 확인할 수 있습니다.
psql 연결 문자열을 복사한 후 데이터베이스에 연결합니다. DBeaver와 같은 Postgres 호환 클라이언트나 애플리케이션 라이브러리를 사용해도 됩니다.
NVMe로 강화된 성능을 직접 확인해 보겠습니다. 먼저, 쿼리 실행 시간을 측정하기 위해 psql에서 타이밍 기능을 활성화합니다:
이벤트와 사용자 데이터를 위한 샘플 테이블 두 개를 생성합니다:
CREATE TABLE events (
event_id SERIAL PRIMARY KEY,
event_name VARCHAR(255) NOT NULL,
event_type VARCHAR(100),
event_timestamp TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
event_data JSONB,
user_id INT,
user_ip INET,
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
name VARCHAR(100),
country VARCHAR(50),
platform VARCHAR(50)
);
이제 100만 개의 이벤트를 삽입한 후 NVMe 속도를 확인하십시오:
INSERT INTO events (event_name, event_type, event_timestamp, event_data, user_id, user_ip)
SELECT
'Event ' || gs::text AS event_name,
CASE
WHEN random() < 0.5 THEN 'click'
WHEN random() < 0.75 THEN 'view'
WHEN random() < 0.9 THEN 'purchase'
WHEN random() < 0.98 THEN 'signup'
ELSE 'logout'
END AS event_type,
NOW() - INTERVAL '1 day' * (gs % 365) AS event_timestamp,
jsonb_build_object('key', 'value' || gs::text, 'additional_info', 'info_' || (gs % 100)::text) AS event_data,
GREATEST(1, LEAST(1000, FLOOR(POWER(random(), 2) * 1000) + 1)) AS user_id,
('192.168.1.' || ((gs % 254) + 1))::inet AS user_ip
FROM
generate_series(1, 1000000) gs;
INSERT 0 1000000
Time: 3596.542 ms (00:03.597)
NVMe 성능
JSONB 데이터를 포함한 100만 행을 4초 이내에 삽입할 수 있습니다. EBS와 같은 네트워크 연결 스토리지를 사용하는 기존 클라우드 데이터베이스에서는 네트워크 왕복 지연(latency)과 IOPS 제한(throttling) 때문에 동일한 작업에 일반적으로 2~3배 더 오래 걸립니다. NVMe 스토리지는 스토리지를 컴퓨트에 물리적으로 직접 연결하여 이러한 병목 현상을 제거합니다.
성능은 인스턴스 크기, 현재 부하, 데이터 특성에 따라 달라질 수 있습니다.
사용자 1,000명을 삽입:
INSERT INTO users (name, country, platform)
SELECT
first_names[first_idx] || ' ' || last_names[last_idx] AS name,
CASE
WHEN random() < 0.25 THEN 'India'
WHEN random() < 0.5 THEN 'USA'
WHEN random() < 0.7 THEN 'Germany'
WHEN random() < 0.85 THEN 'China'
ELSE 'Other'
END AS country,
CASE
WHEN random() < 0.2 THEN 'iOS'
WHEN random() < 0.4 THEN 'Android'
WHEN random() < 0.6 THEN 'Web'
WHEN random() < 0.75 THEN 'Windows'
WHEN random() < 0.9 THEN 'MacOS'
ELSE 'Linux'
END AS platform
FROM
generate_series(1, 1000) AS seq
CROSS JOIN LATERAL (
SELECT
array['Alice', 'Bob', 'Charlie', 'Diana', 'Eve', 'Frank', 'Grace', 'Hank', 'Ivy', 'Jack', 'Liam', 'Olivia', 'Noah', 'Emma', 'Sophia', 'Benjamin', 'Isabella', 'Lucas', 'Mia', 'Amelia', 'Aarav', 'Riya', 'Arjun', 'Ananya', 'Wei', 'Li', 'Huan', 'Mei', 'Hans', 'Klaus', 'Greta', 'Sofia'] AS first_names,
array['Smith', 'Johnson', 'Williams', 'Brown', 'Jones', 'Garcia', 'Miller', 'Davis', 'Martinez', 'Taylor', 'Anderson', 'Thomas', 'Jackson', 'White', 'Harris', 'Martin', 'Thompson', 'Moore', 'Lee', 'Perez', 'Sharma', 'Patel', 'Gupta', 'Reddy', 'Zhang', 'Wang', 'Chen', 'Liu', 'Schmidt', 'Müller', 'Weber', 'Fischer'] AS last_names,
1 + (seq % 32) AS first_idx,
1 + ((seq / 32)::int % 32) AS last_idx
) AS names;
데이터에 쿼리 실행하기
이제 쿼리를 실행하여 NVMe 스토리지를 사용할 때 Postgres가 얼마나 빠르게 응답하는지 확인해 보겠습니다.
100만 개 이벤트를 유형별로 집계하기:
SELECT event_type, COUNT(*) as count
FROM events
GROUP BY event_type
ORDER BY count DESC;
event_type | count
------------+--------
click | 499523
view | 375644
purchase | 112473
signup | 12117
logout | 243
(5 rows)
Time: 114.883 ms
JSONB 필터와 날짜 범위를 사용하는 쿼리:
SELECT COUNT(*)
FROM events
WHERE event_timestamp > NOW() - INTERVAL '30 days'
AND event_data->>'additional_info' LIKE 'info_5%';
count
-------
9042
(1 row)
Time: 109.294 ms
이벤트와 USER 조인하기:
SELECT u.country, COUNT(*) as events, AVG(LENGTH(e.event_data::text))::int as avg_json_size
FROM events e
JOIN users u ON e.user_id = u.user_id
GROUP BY u.country
ORDER BY events DESC;
country | events | avg_json_size
---------+--------+---------------
USA | 383748 | 52
India | 255990 | 52
Germany | 223781 | 52
China | 127754 | 52
Other | 8727 | 52
(5 rows)
Time: 224.670 ms
Postgres가 준비되었습니다
이제 트랜잭션 워크로드를 처리할 수 있는 고성능 Postgres 데이터베이스가 완전히 준비되었습니다.
2부로 계속 진행하여 네이티브 ClickHouse 통합을 통해 분석을 어떻게 강화할 수 있는지 확인하십시오.
Part 2: ClickHouse로 실시간 분석 추가하기
Postgres는 트랜잭션 워크로드(OLTP)에 뛰어난 반면, ClickHouse는 대규모 데이터셋에 대한 분석용 쿼리(OLAP)에 특화되어 있습니다. 이 둘을 통합하면 다음과 같이 두 가지 장점을 모두 활용할 수 있습니다:
- 애플리케이션의 트랜잭션 데이터(삽입, 수정, 포인트 조회)에는 Postgres
- 수십억 개의 행에 대한 1초 미만 분석에는 ClickHouse
이 섹션에서는 Postgres 데이터를 ClickHouse로 복제하고, 이를 원활하게 쿼리하는 방법을 설명합니다.
ClickHouse 통합 설정
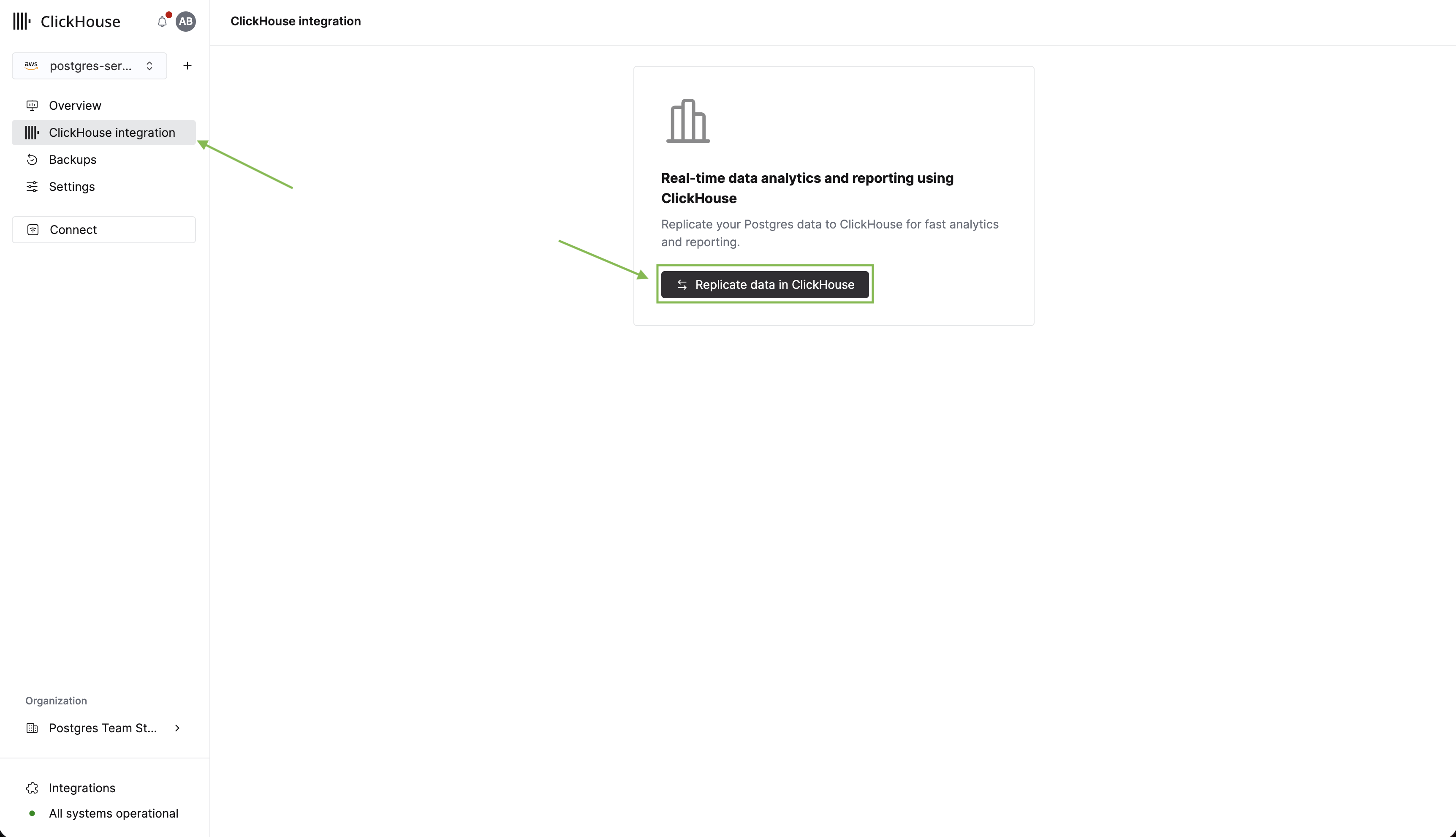
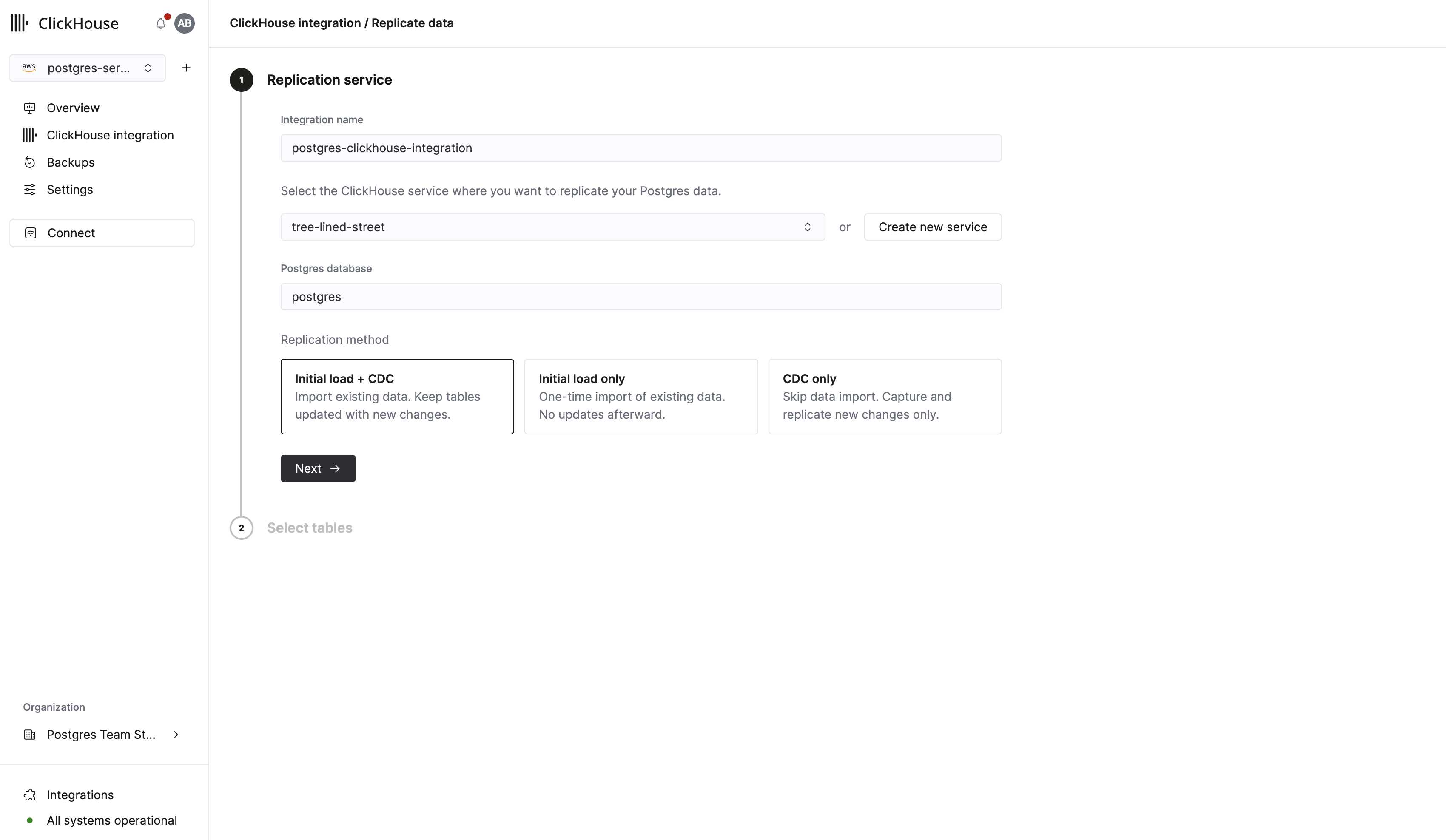
이제 Postgres에 테이블과 데이터가 준비되었으므로, 분석을 위해 테이블을 ClickHouse로 복제합니다. 먼저 사이드바에서 ClickHouse integration을 클릭합니다. 그런 다음 Replicate data in ClickHouse를 클릭합니다.
이어지는 폼에서 통합 이름을 입력하고, 복제 대상이 될 기존 ClickHouse 인스턴스를 선택할 수 있습니다. 아직 ClickHouse 인스턴스가 없다면, 이 폼에서 바로 생성할 수 있습니다.
중요
계속 진행하기 전에 선택한 ClickHouse 서비스 상태가 Running인지 확인하십시오.
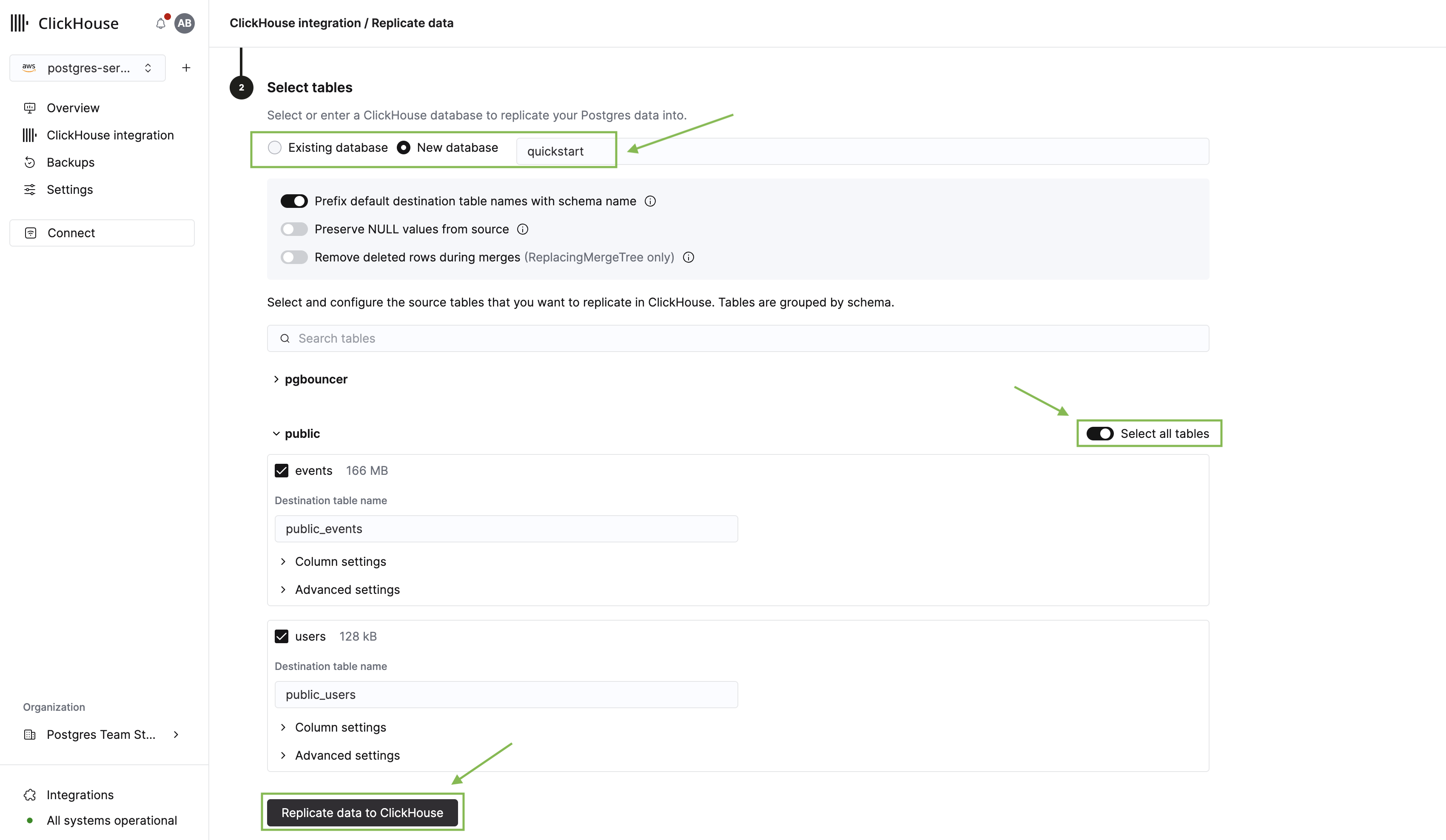
Next를 클릭하면 테이블 선택 화면으로 이동합니다. 여기에서 수행할 작업은 다음과 같습니다.
- 복제 대상 ClickHouse 데이터베이스를 선택합니다.
- public 스키마를 펼치고, 앞에서 생성한 users 및 events 테이블을 선택합니다.
- Replicate data to ClickHouse를 클릭합니다.
복제 작업이 시작되고, 통합 개요 페이지로 이동합니다. 첫 번째 통합인 경우 초기 인프라를 설정하는 데 2–3분 정도 걸릴 수 있습니다. 그동안 새 pg_clickhouse 확장을 살펴보겠습니다.
Postgres에서 ClickHouse 쿼리하기
pg_clickhouse 확장을 사용하면 표준 SQL을 사용하여 Postgres에서 ClickHouse 데이터를 직접 쿼리할 수 있습니다. 이를 통해 애플리케이션에서 Postgres를 트랜잭션 데이터와 분석 데이터를 모두 아우르는 통합 쿼리 계층으로 사용할 수 있습니다. 자세한 내용은 전체 문서를 참조하십시오.
확장을 활성화하십시오:
CREATE EXTENSION pg_clickhouse;
그런 다음 ClickHouse에 대한 foreign server 연결을 생성합니다. 보안 연결을 위해 8443 포트에서 http 드라이버를 사용합니다:
CREATE SERVER ch FOREIGN DATA WRAPPER clickhouse_fdw
OPTIONS(driver 'http', host '<clickhouse_cloud_host>', dbname '<database_name>', port '8443');
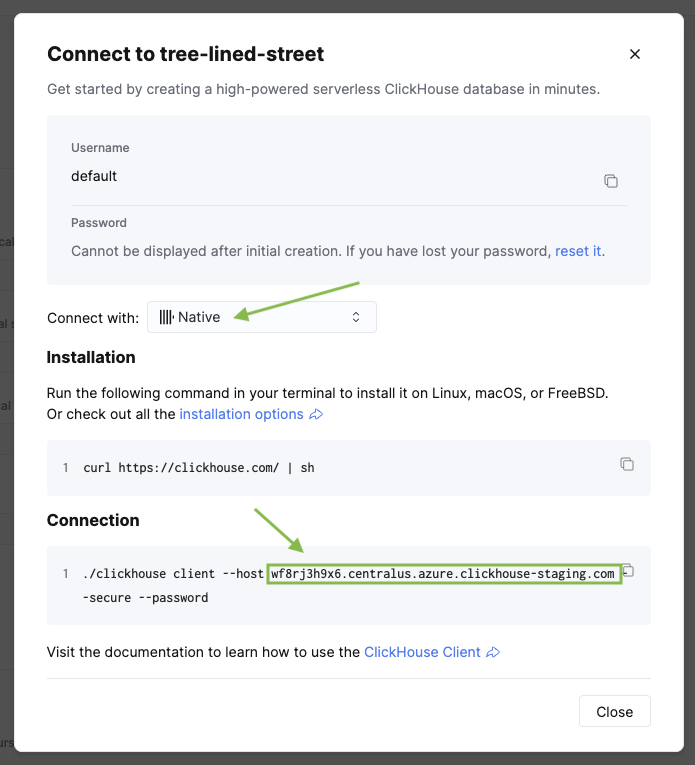
<clickhouse_cloud_host>를 ClickHouse 호스트 이름으로, <database_name>을 복제 설정 시 선택한 데이터베이스 이름으로 바꾸십시오. ClickHouse 서비스의 사이드바에서 Connect를 클릭하면 호스트 이름을 확인할 수 있습니다.
이제 Postgres 사용자를 ClickHouse 서비스의 자격 증명에 매핑합니다.
CREATE USER MAPPING FOR CURRENT_USER SERVER ch
OPTIONS (user 'default', password '<clickhouse_password>');
이제 ClickHouse 테이블을 Postgres 스키마에 가져옵니다.
CREATE SCHEMA organization;
IMPORT FOREIGN SCHEMA "<database_name>" FROM SERVER ch INTO organization;
서버를 생성할 때 사용한 것과 동일한 데이터베이스 이름으로 <database_name>을 변경하십시오.
이제 Postgres 클라이언트에서 ClickHouse 테이블을 모두 확인할 수 있습니다:
분석 결과 확인하기
통합 페이지로 다시 이동합니다. 초기 복제가 완료된 것을 확인할 수 있습니다. 세부 정보를 보려면 통합 이름을 클릭하십시오.
서비스 이름을 클릭하여 ClickHouse 콘솔을 열고 복제된 테이블을 확인하십시오.
이제 몇 가지 분석용 쿼리를 실행하여 Postgres와 ClickHouse 간의 성능을 비교해 보겠습니다. 복제된 테이블(Replicated Table)은 public_<table_name> 명명 규칙을 사용합니다.
쿼리 1: 활동량이 가장 높은 사용자
이 쿼리는 여러 집계를 사용하여 가장 활동적인 사용자를 찾습니다:
-- Via ClickHouse
SELECT
user_id,
COUNT(*) as total_events,
COUNT(DISTINCT event_type) as unique_event_types,
SUM(CASE WHEN event_type = 'purchase' THEN 1 ELSE 0 END) as purchases,
MIN(event_timestamp) as first_event,
MAX(event_timestamp) as last_event
FROM organization.public_events
GROUP BY user_id
ORDER BY total_events DESC
LIMIT 10;
user_id | total_events | unique_event_types | purchases | first_event | last_event
---------+--------------+--------------------+-----------+----------------------------+----------------------------
1 | 31439 | 5 | 3551 | 2025-01-22 22:40:45.612281 | 2026-01-21 22:40:45.612281
2 | 13235 | 4 | 1492 | 2025-01-22 22:40:45.612281 | 2026-01-21 22:40:45.612281
...
(10 rows)
Time: 163.898 ms -- ClickHouse
Time: 554.621 ms -- Same query on Postgres
쿼리 2: 국가 및 플랫폼별 사용자 참여도
이 쿼리는 events 테이블과 users 테이블을 조인하여 참여도 지표를 계산합니다:
-- Via ClickHouse
SELECT
u.country,
u.platform,
COUNT(DISTINCT e.user_id) as users,
COUNT(*) as total_events,
ROUND(COUNT(*)::numeric / COUNT(DISTINCT e.user_id), 2) as events_per_user,
SUM(CASE WHEN e.event_type = 'purchase' THEN 1 ELSE 0 END) as purchases
FROM organization.public_events e
JOIN organization.public_users u ON e.user_id = u.user_id
GROUP BY u.country, u.platform
ORDER BY total_events DESC
LIMIT 10;
country | platform | users | total_events | events_per_user | purchases
---------+----------+-------+--------------+-----------------+-----------
USA | Android | 115 | 109977 | 956 | 12388
USA | Web | 108 | 105057 | 972 | 11847
USA | iOS | 83 | 84594 | 1019 | 9565
Germany | Android | 85 | 77966 | 917 | 8852
India | Android | 80 | 68095 | 851 | 7724
...
(10 rows)
Time: 170.353 ms -- ClickHouse
Time: 1245.560 ms -- Same query on Postgres
성능 비교:
| Query | Postgres (NVMe) | ClickHouse (via pg_clickhouse) | 속도 향상 |
|---|
| Top users (5 aggregations) | 555 ms | 164 ms | 3.4x |
| User engagement (JOIN + aggregations) | 1,246 ms | 170 ms | 7.3x |
ClickHouse를 사용해야 할 때
이렇게 100만 행 규모의 데이터셋에서도 ClickHouse는 JOIN과 여러 집계를 포함한 복잡한 분석 쿼리에 대해 37배 더 빠른 성능을 제공합니다. 규모가 1억 행 이상으로 커질수록 차이는 더욱 커지며, 이때 ClickHouse의 열 지향 저장소와 벡터화 실행은 10100배 수준의 속도 향상을 제공할 수 있습니다.
쿼리 시간은 인스턴스 크기, 서비스 간 네트워크 지연, 데이터 특성, 현재 부하에 따라 달라집니다.
이 빠른 시작 가이드에서 생성한 리소스를 삭제하려면 다음을 수행하십시오.
- 먼저 ClickHouse 서비스에서 ClickPipe 통합을 삭제하십시오.
- 그런 다음 Cloud Console에서 Managed Postgres 인스턴스를 삭제하십시오.