ReplacingMergeTree
트랜잭션 데이터베이스는 트랜잭션 기반의 업데이트 및 삭제 워크로드에 최적화되어 있는 반면, OLAP 데이터베이스는 이러한 연산에 대해서는 상대적으로 보장 수준이 낮습니다. 대신 배치 단위로 삽입되는 불변(immutable) 데이터에 최적화하여 분석 쿼리를 훨씬 더 빠르게 실행할 수 있도록 합니다. ClickHouse는 뮤테이션을 통한 업데이트 연산과 행 삭제를 위한 경량 메커니즘을 제공하지만, 컬럼 지향 구조를 사용하므로 위에서 설명한 것처럼 이러한 연산은 신중하게 스케줄링해야 합니다. 이러한 연산은 비동기적으로 처리되며 단일 스레드로 수행되고, (업데이트의 경우) 디스크의 데이터를 다시 쓰는 작업이 필요합니다. 따라서 많은 수의 소규모 변경 작업에는 사용하지 않아야 합니다. 위와 같은 사용 패턴을 피하면서 업데이트 및 삭제 행의 스트림을 처리하기 위해 ClickHouse 테이블 엔진인 ReplacingMergeTree를 사용할 수 있습니다.
삽입된 행의 자동 업서트(upsert)
ReplacingMergeTree table engine를 사용하면, 비효율적인 ALTER 또는 DELETE SQL 문을 사용할 필요 없이 동일한 행을 여러 번 삽입하고 그중 하나를 최신 버전으로 표시하는 방식으로 행에 대한 업데이트 작업을 적용할 수 있습니다. 그런 다음 백그라운드 프로세스가 동일한 행의 오래된 버전을 비동기적으로 제거하여, 불변(append-only) 삽입을 사용해 업데이트 작업을 효율적으로 모방합니다.
이는 테이블 엔진이 중복 행을 식별할 수 있는 능력에 의존합니다. ORDER BY 절을 사용하여 고유성을 결정하며, 즉 ORDER BY에 지정된 컬럼들의 값이 두 행에서 동일하면 해당 행들은 중복으로 간주됩니다. 테이블 정의 시 지정하는 version 컬럼을 사용하면 두 행이 중복으로 식별될 때 행의 최신 버전을 유지할 수 있습니다. 즉, 가장 높은 version 값을 가진 행이 유지됩니다.
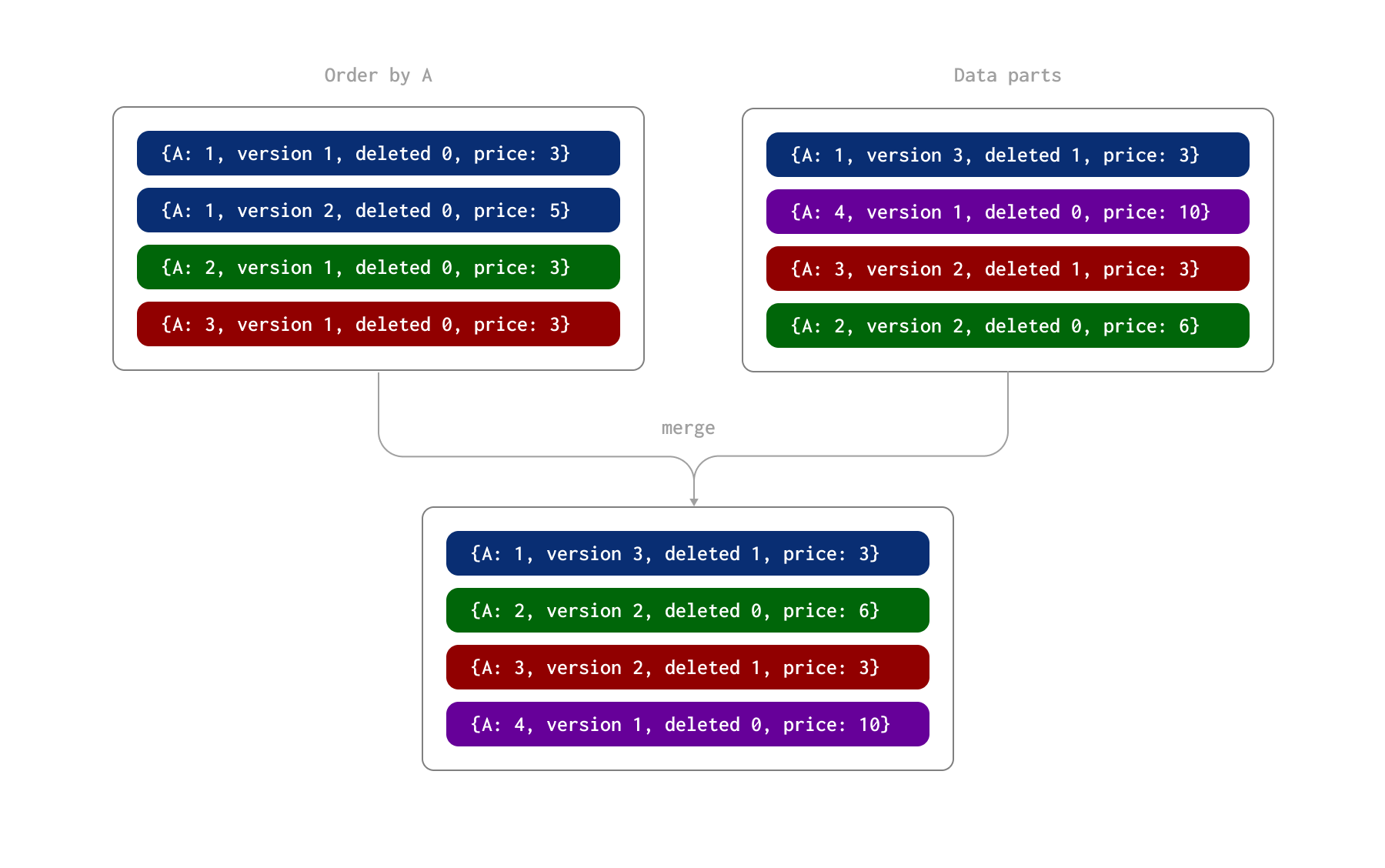
아래 예제에서 이 프로세스를 설명합니다. 여기서 행들은 A 컬럼(테이블의 ORDER BY)으로 고유하게 식별됩니다. 이 행들이 두 번의 배치로 삽입되었다고 가정하며, 그 결과 디스크에 두 개의 데이터 파트가 생성됩니다. 이후 비동기 백그라운드 프로세스 동안 이 파트들이 병합됩니다.
ReplacingMergeTree는 추가로 삭제 플래그용 컬럼을 지정할 수 있습니다. 이 컬럼에는 0 또는 1이 저장될 수 있으며, 값이 1이면 해당 행(및 그 중복 행들)이 삭제되었음을 의미하고, 그렇지 않을 경우 0이 사용됩니다. 참고: 삭제된 행은 병합 시점에 제거되지 않습니다.
이 프로세스에서, 파트 병합 동안 다음과 같은 일이 발생합니다.
- 컬럼 A의 값 1로 식별되는 행에는 version 2의 업데이트 행과 version 3의 삭제 행(삭제 플래그 컬럼 값이 1)이 모두 존재합니다. 따라서 삭제로 표시된 최신 행이 유지됩니다.
- 컬럼 A의 값 2로 식별되는 행에는 두 개의 업데이트 행이 있습니다. 이 중 나중 행이 price 컬럼 값 6과 함께 유지됩니다.
- 컬럼 A의 값 3으로 식별되는 행에는 version 1의 행과 version 2의 삭제 행이 있습니다. 이 삭제 행이 유지됩니다.
이 병합 과정의 결과로, 최종 상태를 나타내는 네 개의 행이 생성됩니다:
삭제된 행은 절대 자동으로 제거되지 않는다는 점에 유의해야 합니다. OPTIMIZE table FINAL CLEANUP을 사용하여 강제로 삭제할 수 있습니다. 이를 위해서는 실험적 설정 allow_experimental_replacing_merge_with_cleanup=1이 필요합니다. 이 명령은 다음 조건을 모두 만족할 때에만 실행해야 합니다.
- 정리 대상이 되는 행들에 대해, 오래된 버전의 행이 이 작업 실행 이후에 삽입되지 않는다는 점을 확신할 수 있어야 합니다. 이러한 행이 삽입되면, 삭제된 행이 더 이상 존재하지 않기 때문에 잘못 유지되게 됩니다.
- 정리를 실행하기 전에 모든 레플리카가 동기화되어 있는지 확인해야 합니다. 이는 다음 명령으로 달성할 수 있습니다.
(1)이 보장되면, 해당 명령과 이후 정리 작업이 완료될 때까지 데이터 삽입을 일시 중지할 것을 권장합니다.
ReplacingMergeTree를 사용해 삭제를 처리하는 방법은, 위 조건으로 정리를 수행할 수 있는 기간을 미리 예약할 수 있는 경우가 아니라면, 삭제 비율이 낮거나 중간 수준(10% 미만)인 테이블에만 사용하는 것이 좋습니다.
팁: 더 이상 변경이 발생하지 않는 특정 파티션에 대해서만
OPTIMIZE FINAL CLEANUP을 실행할 수도 있습니다.
기본/중복 제거 키 선택
앞에서 ReplacingMergeTree의 경우 반드시 만족해야 하는 중요한 추가 제약 조건을 설명했습니다. ORDER BY에 지정된 컬럼들의 값이 변경 전후를 통틀어 하나의 행을 고유하게 식별해야 합니다. Postgres와 같은 트랜잭션 데이터베이스에서 마이그레이션하는 경우, 원래 Postgres 기본 키를 ClickHouse ORDER BY 절에 포함해야 합니다.
ClickHouse 사용자는 테이블의 ORDER BY 절에 어떤 컬럼을 사용할지 선택해 쿼리 성능을 최적화하는 작업에 익숙할 것입니다. 일반적으로 이러한 컬럼은 자주 사용하는 쿼리를 기준으로 선택하고, 카디널리티가 낮은 것에서 높은 순으로 나열해야 합니다. 중요한 점은 ReplacingMergeTree가 추가 제약 조건을 부과한다는 것입니다. 이 컬럼들은 불변(immutable)이어야 합니다. 즉, Postgres에서 복제하는 경우, 기본 Postgres 데이터에서 값이 변경되지 않는 컬럼만 이 절에 추가해야 합니다. 다른 컬럼들은 변경될 수 있지만, 행을 고유하게 식별하기 위해서는 이 컬럼들의 값이 일관되게 유지되어야 합니다.
분석 워크로드에서는 단일 행 조회를 수행하는 경우가 거의 없기 때문에, Postgres 기본 키는 일반적으로 큰 효용이 없습니다. 컬럼을 카디널리티가 낮은 것에서 높은 순으로 배치할 것을 권장하며, ORDER BY에서 앞쪽에 나열된 컬럼에서 매칭이 발생할수록 보통 더 빠르다는 점을 고려하면, Postgres 기본 키는 (분석적 가치가 없는 한) ORDER BY의 끝에 추가하는 것이 좋습니다. Postgres에서 여러 컬럼이 기본 키를 구성하는 경우, 카디널리티와 쿼리에서 사용될 가능성을 고려한 순서를 유지한 채 ORDER BY 끝에 이어서 추가해야 합니다. 또한 MATERIALIZED 컬럼을 사용하여 여러 값을 연결(concatenation)해 고유한 기본 키를 생성하는 방법도 고려할 수 있습니다.
Stack Overflow 데이터셋의 posts 테이블을 예로 들어 보겠습니다.
(PostTypeId, toDate(CreationDate), CreationDate, Id)를 ORDER BY 키로 사용합니다. 각 게시물에 대해 고유한 Id 컬럼이 있어 행을 중복 제거할 수 있습니다. 필요에 따라 스키마에 Version 및 Deleted 컬럼이 추가됩니다.
ReplacingMergeTree 쿼리하기
머지 시점에 ReplacingMergeTree는 ORDER BY 컬럼의 값을 고유 식별자로 사용하여 중복 행을 식별하고, 가장 높은 버전만 유지하거나 최신 버전이 삭제를 나타내는 경우 모든 중복을 제거합니다. 그러나 이는 궁극적으로만 올바른 상태에 수렴하도록 할 뿐, 행이 반드시 중복 제거된다고 보장하지 않으므로 이에 의존해서는 안 됩니다. 따라서 쿼리에서 업데이트 및 삭제 행이 함께 고려되면 잘못된 결과가 발생할 수 있습니다.
정확한 결과를 얻으려면, 백그라운드 머지에 더해 쿼리 시점의 중복 제거와 삭제 행 제거를 보완해야 합니다. 이를 위해 FINAL 연산자를 사용할 수 있습니다.
위의 posts 테이블을 생각해 보십시오. 일반적인 방법으로 이 데이터셋을 로드하되, 값 컬럼 외에 기본값이 0인 deleted 컬럼과 version 컬럼을 추가로 지정합니다. 예제를 위해 10000행만 로드합니다.
행 수를 확인해 보겠습니다:
이제 답변 이후의 통계값을 업데이트합니다. 기존 값을 갱신하는 대신 5000개의 행 사본을 새로 삽입하고, 각 행의 버전 번호에 1을 더합니다(이렇게 하면 테이블에는 150개의 행이 존재하게 됩니다). 이는 간단한 INSERT INTO SELECT로 시뮬레이션할 수 있습니다:
또한, deleted 컬럼 값을 1로 설정하여 행을 다시 삽입하는 방식으로 무작위 게시물 1000개를 삭제합니다. 마찬가지로, 이는 간단한 INSERT INTO SELECT로 시뮬레이션할 수 있습니다.
위의 연산 결과는 16,000행, 즉 10,000 + 5,000 + 1,000이 됩니다. 그러나 여기서 올바른 총합은, 실제로는 원래 총합에서 1,000행만 줄어든 값이어야 하므로 10,000 - 1,000 = 9,000입니다.
여기에서 나오는 결과는 수행된 머지 작업에 따라 달라질 수 있습니다. 중복 행이 있기 때문에 여기에서의 합계가 다른 것을 확인할 수 있습니다. 테이블에 FINAL을 적용하면 올바른 결과를 얻을 수 있습니다.
FINAL 성능
FINAL 연산자는 쿼리에 약간의 성능 오버헤드를 유발합니다.
이는 쿼리가 기본 키 컬럼으로 필터링되지 않을 때 가장 두드러지게 나타나며,
더 많은 데이터를 읽게 되고 중복 제거 오버헤드가 증가하는 결과를 초래합니다. WHERE
조건에서 키 컬럼으로 필터링하면, 중복 제거를 위해 로드되고 전달되는
데이터가 줄어듭니다.
WHERE 조건이 키 컬럼을 사용하지 않는 경우, ClickHouse는 현재 FINAL을 사용할 때 PREWHERE 최적화를 활용하지 않습니다. 이 최적화는 필터링 대상이 아닌 컬럼에 대해 읽는 행 수를 줄이는 것을 목표로 합니다. 이 PREWHERE 동작을 에뮬레이션하여 잠재적으로 성능을 개선하는 예시는 여기에서 확인할 수 있습니다.
ReplacingMergeTree에서 파티션을 활용하는 방법
ClickHouse에서 데이터 병합은 파티션 단위로 수행됩니다. ReplacingMergeTree를 사용할 때는, 해당 행에 대한 파티셔닝 키가 변경되지 않음을 보장할 수 있는 경우 모범 사례에 따라 테이블을 파티션할 것을 권장합니다. 이렇게 하면 동일한 행에 대한 업데이트가 동일한 ClickHouse 파티션으로 전송되도록 보장할 수 있습니다. 여기에서 제시한 모범 사례를 준수한다면 Postgres와 동일한 파티션 키를 재사용해도 됩니다.
이 조건을 만족하는 경우, FINAL 쿼리 성능을 향상하기 위해 do_not_merge_across_partitions_select_final=1 SETTING을 사용할 수 있습니다. 이 SETTING은 FINAL을 사용할 때 파티션을 서로 독립적으로 병합하고 처리합니다.
다음은 파티셔닝을 사용하지 않은 posts 테이블 예시입니다:
FINAL이 실제로 일정한 작업을 수행해야 하는 상황을 보장하기 위해, 중복 행을 삽입하여 100만 행의 AnswerCount를 증가시키는 업데이트를 수행합니다.
FINAL을 사용해 연도별 답변 합계 계산:
연도 단위로 파티션된 테이블에 대해서도 동일한 단계를 반복하고, do_not_merge_across_partitions_select_final=1 설정을 적용하여 위 쿼리를 다시 실행합니다.
위에서 보듯이, 이 사례에서는 파티션 단위에서 중복 제거를 병렬로 수행할 수 있게 함으로써 파티셔닝이 쿼리 성능을 크게 향상시켰습니다.
병합 동작 관련 고려 사항
ClickHouse의 병합 선택 메커니즘은 단순히 파트를 병합하는 수준을 넘어서는 기능을 제공합니다. 아래에서는 ReplacingMergeTree의 동작을 중심으로, 오래된 데이터에 대해 더 적극적인 병합을 활성화하기 위한 설정 옵션과 더 큰 파트에 대한 고려 사항을 살펴봅니다.
머지 선택 로직
머지 작업은 파트 수를 최소화하는 것을 목표로 하지만, 동시에 쓰기 증폭(write amplification) 비용과 이 목표 사이에서 균형을 맞춥니다. 그 결과, 내부 계산을 통해 쓰기 증폭이 과도하게 증가할 것으로 판단되는 경우에는 특정 파트 범위가 머지 대상에서 제외됩니다. 이러한 동작을 통해 불필요한 리소스 사용을 방지하고 스토리지 구성 요소의 수명을 연장할 수 있습니다.
큰 파트에서의 머지 동작
ClickHouse의 ReplacingMergeTree 엔진은 지정된 고유 키를 기준으로 데이터 파트를 머지하여 각 행의 최신 버전만 유지함으로써 중복 행을 효율적으로 관리하도록 최적화되어 있습니다. 그러나 머지된 파트가 max_bytes_to_merge_at_max_space_in_pool 임계값에 도달하면, min_age_to_force_merge_seconds가 설정되어 있더라도 더 이상 추가 머지 대상으로 선택되지 않습니다. 그 결과, 지속적인 데이터 삽입으로 인해 누적될 수 있는 중복을 제거하기 위해 자동 머지에 더 이상 의존할 수 없습니다.
이를 해결하기 위해 OPTIMIZE FINAL을 사용하여 파트를 수동으로 머지하고 중복을 제거할 수 있습니다. 자동 머지와 달리 OPTIMIZE FINAL은 max_bytes_to_merge_at_max_space_in_pool 임계값을 무시하고, 각 파티션에 하나의 파트만 남을 때까지 사용 가능한 리소스(특히 디스크 공간)에만 기반하여 파트를 머지합니다. 그러나 이 방식은 대용량 테이블에서는 메모리 사용량이 많을 수 있으며, 새로운 데이터가 계속 추가되면 여러 번 실행해야 할 수 있습니다.
성능을 유지하면서 더 지속 가능한 방법으로는 테이블을 파티션하는 것이 좋습니다. 이렇게 하면 데이터 파트가 최대 머지 크기에 도달하는 것을 방지하고, 반복적인 수동 최적화 필요성을 줄이는 데 도움이 됩니다.
Partitioning and merging across partitions
「Exploiting Partitions with ReplacingMergeTree」에서 설명한 것처럼, 테이블을 파티션으로 나누는 것을 모범 사례로 권장합니다. 파티션을 사용하면 데이터를 분리하여 병합 효율을 높이고, 특히 쿼리 실행 중에 파티션 간 병합을 피할 수 있습니다. 이 동작은 23.12 버전부터 더욱 향상되었습니다. 파티션 키가 정렬 키의 접두사인 경우 쿼리 시점에는 파티션 간 병합이 수행되지 않으며, 그 결과 쿼리 성능이 향상됩니다.
더 나은 쿼리 성능을 위한 머지 튜닝
기본적으로 min_age_to_force_merge_seconds와 min_age_to_force_merge_on_partition_only는 각각 0과 false로 설정되어 있어, 해당 기능이 비활성화됩니다. 이 구성에서는 ClickHouse가 파티션의 경과 시간을 기준으로 머지를 강제하지 않고, 표준 머지 동작을 적용합니다.
min_age_to_force_merge_seconds에 값을 지정하면, ClickHouse는 지정된 기간보다 오래된 파트에 대해서는 일반적인 머지 휴리스틱을 무시합니다. 이는 일반적으로 전체 파트 수를 최소화하는 것이 목표일 때에만 효과적인 설정이지만, 쿼리 시점에 머지가 필요한 파트 수를 줄여 ReplacingMergeTree에서 쿼리 성능을 향상시키는 데 도움이 될 수 있습니다.
이 동작은 min_age_to_force_merge_on_partition_only=true로 설정하여 추가로 튜닝할 수 있습니다. 이렇게 하면, 공격적인 머지를 수행하기 위해 해당 파티션의 모든 파트가 min_age_to_force_merge_seconds보다 오래되어야 합니다. 이 구성은 시간이 지남에 따라 오래된 파티션이 단일 파트로 머지되도록 하여 데이터를 통합하고, 쿼리 성능을 유지할 수 있도록 합니다.
권장 설정
머지 동작 튜닝은 고급 작업입니다. 프로덕션 워크로드에서 이 설정을 활성화하기 전에 ClickHouse 지원팀과 상담할 것을 권장합니다.
대부분의 경우 min_age_to_force_merge_seconds 값을 파티션 주기보다 훨씬 작은 값으로 설정하는 것이 바람직합니다. 이렇게 하면 파트 수를 최소화하고, 쿼리 시 FINAL 연산자를 사용할 때 발생하는 불필요한 머지를 방지할 수 있습니다.
예를 들어, 이미 하나의 파트로 머지된 월별 파티션이 있다고 가정합니다. 이 파티션 안에서 소량의 단발성 insert 작업으로 인해 새 파트가 생성되면, 머지가 완료될 때까지 ClickHouse가 여러 파트를 읽어야 하므로 쿼리 성능이 저하될 수 있습니다. min_age_to_force_merge_seconds를 설정하면 이러한 파트가 적극적으로 머지되도록 보장하여 쿼리 성능 저하를 방지할 수 있습니다.
