중복 제거 전략(CDC 사용)
Postgres에서 ClickHouse로 복제되는 업데이트 및 삭제 작업은 ClickHouse의 데이터 저장 구조와 복제 방식 때문에 ClickHouse에 중복된 행이 생성되도록 합니다. 이 페이지에서는 이러한 현상이 발생하는 이유와, 중복을 처리하기 위해 ClickHouse에서 활용할 수 있는 전략을 설명합니다.
데이터는 어떻게 복제됩니까?
PostgreSQL 논리 디코딩
ClickPipes는 Postgres에서 발생하는 변경 사항을 수집하기 위해 Postgres Logical Decoding을 사용합니다. Postgres의 Logical Decoding 프로세스는 ClickPipes와 같은 클라이언트가 변경 사항을 사람이 읽을 수 있는 형식, 즉 일련의 INSERT, UPDATE, DELETE로 수신할 수 있도록 해줍니다.
ReplacingMergeTree
ClickPipes는 Postgres 테이블을 ReplacingMergeTree 엔진을 사용하여 ClickHouse에 매핑합니다. ClickHouse는 append-only 워크로드에서 최상의 성능을 발휘하며, 빈번한 UPDATE를 권장하지 않습니다. 이때 ReplacingMergeTree가 특히 강력합니다.
ReplacingMergeTree에서는 업데이트가 해당 행의 더 최신 버전(_peerdb_version)을 가진 INSERT로 표현되며, 삭제는 더 최신 버전과 true로 설정된 _peerdb_is_deleted를 가진 INSERT로 표현됩니다. ReplacingMergeTree 엔진은 백그라운드에서 데이터를 중복 제거 및 병합하고, 특정 기본 키(id)에 대해 해당 행의 최신 버전을 유지하여 UPDATE와 DELETE를 버전 관리된 INSERT로 효율적으로 처리할 수 있도록 합니다.
아래는 ClickPipes가 ClickHouse에 테이블을 생성하기 위해 실행하는 CREATE Table 구문 예시입니다.
예시를 통한 설명
아래 그림은 ClickPipes를 사용하여 PostgreSQL과 ClickHouse 간에 users 테이블을 동기화하는 기본 예시를 단계별로 보여줍니다.
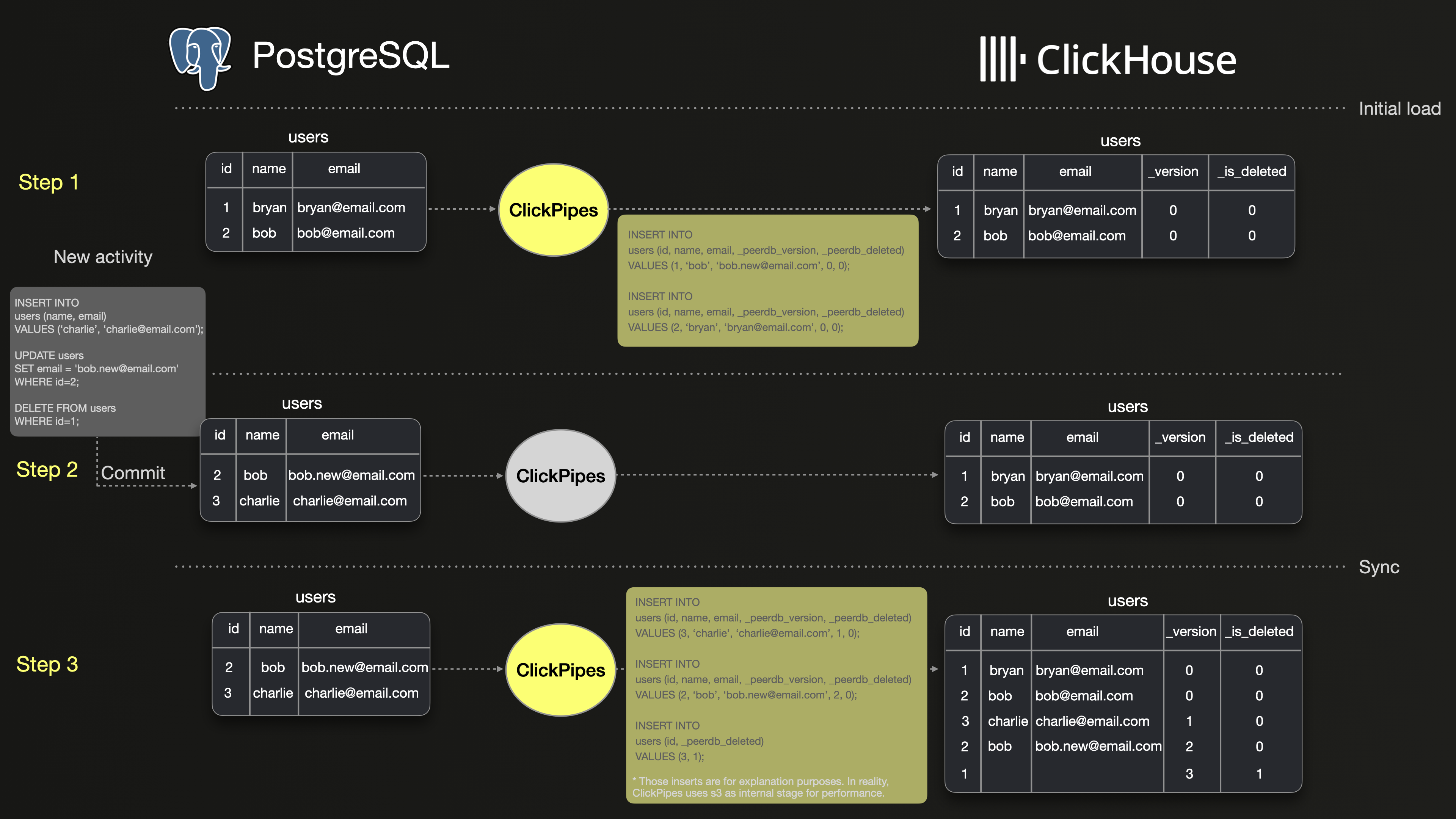
1단계는 PostgreSQL에 있는 2개의 행에 대한 초기 스냅샷과, ClickPipes가 해당 2개의 행을 ClickHouse로 초기 로드하는 과정을 보여줍니다. 보시는 것처럼 두 행 모두 ClickHouse로 그대로 복사됩니다.
2단계는 users 테이블에서 수행되는 세 가지 작업을 보여줍니다: 새로운 행 삽입, 기존 행 업데이트, 다른 행 삭제입니다.
3단계는 ClickPipes가 INSERT, UPDATE, DELETE 작업을 버전이 매겨진 INSERT 형태로 ClickHouse에 어떻게 복제하는지 보여줍니다. UPDATE는 ID 2를 가진 행의 새로운 버전으로 나타나고, DELETE는 _is_deleted가 true로 표시된 ID 1의 새로운 버전으로 나타납니다. 이로 인해 ClickHouse에는 PostgreSQL보다 3개의 행이 더 많아집니다.
그 결과 SELECT count(*) FROM users;와 같은 단순한 쿼리를 실행하면 ClickHouse와 PostgreSQL에서 서로 다른 결과가 반환될 수 있습니다. ClickHouse 머지 관련 문서에 따르면, 오래된 행 버전은 머지 과정에서 결국 폐기됩니다. 그러나 이 머지가 언제 발생할지는 예측할 수 없으므로, 머지가 일어나기 전까지는 ClickHouse에서 실행되는 쿼리가 일관되지 않은 결과를 반환할 수 있습니다.
ClickHouse와 PostgreSQL에서 동일한 쿼리 결과를 어떻게 보장할 수 있을까요?
FINAL 키워드를 사용한 중복 제거
ClickHouse 쿼리에서 데이터를 중복 제거하는 권장 방법은 FINAL 수정자를 사용하는 것입니다. 이렇게 하면 중복 제거된 행만 반환됩니다.
이제 서로 다른 세 가지 쿼리에 어떻게 적용하는지 살펴보겠습니다.
다음 쿼리에서 삭제된 행을 걸러내는 데 사용하는 WHERE 절에 주목하십시오.
- 단순 count 쿼리: 게시물 개수를 계산합니다.
이는 동기화가 정상적으로 이루어졌는지 확인하기 위해 실행할 수 있는 가장 간단한 쿼리입니다. 두 쿼리는 동일한 개수를 반환해야 합니다.
- JOIN을 사용한 간단한 집계: 가장 많은 조회수를 기록한 상위 10명 사용자.
단일 테이블에 대한 집계 예입니다. 여기에서 데이터 중복이 있으면 sum 함수 결과가 크게 왜곡될 수 있습니다.
FINAL 설정
쿼리에서 각 테이블 이름에 FINAL 수정자를 추가하는 대신, FINAL 설정을 사용하여 쿼리에 포함된 모든 테이블에 자동으로 적용되도록 할 수 있습니다.
이 설정은 쿼리별로 또는 전체 세션에 적용할 수 있습니다.
ROW policy
불필요한 _peerdb_is_deleted = 0 필터를 숨기는 간단한 방법은 ROW policy를 사용하는 것입니다. 아래 예시는 votes 테이블에 대한 모든 쿼리에서 삭제된 행을 제외하도록 하는 ROW policy를 생성하는 방법을 보여줍니다.
행 정책은 사용자와 역할 목록에 적용됩니다. 이 예제에서는 모든 사용자와 역할에 적용됩니다. 특정 사용자나 역할에만 적용되도록 조정할 수 있습니다.
Postgres처럼 쿼리하기
PostgreSQL에서 ClickHouse로 분석용 데이터셋을 마이그레이션하는 과정에서는 데이터 처리 방식과 쿼리 실행 방식의 차이를 반영하기 위해 애플리케이션 쿼리를 수정해야 하는 경우가 많습니다.
이 섹션에서는 원래 쿼리를 변경하지 않고 유지하면서 데이터 중복을 제거하는 방법을 살펴봅니다.
뷰(Views)
뷰(Views)는 쿼리에서 FINAL 키워드를 감추는 데 매우 유용합니다. 이는 뷰가 어떤 데이터도 저장하지 않고, 매번 접근할 때마다 다른 테이블에서 읽기만 수행하기 때문입니다.
아래는 ClickHouse에서 데이터베이스의 각 테이블에 대해 FINAL 키워드를 사용하고 삭제된 행을 걸러내는 필터를 포함한 뷰를 생성하는 예시입니다.
그러면 이제 PostgreSQL에서와 마찬가지로 동일한 쿼리를 사용하여 VIEW를 조회할 수 있습니다.
갱신 가능 구체화 뷰
또 다른 방법은 갱신 가능 구체화 뷰를 사용하는 것입니다. 이를 통해 쿼리를 일정 주기로 실행하여 행을 중복 제거한 뒤, 결과를 대상 테이블에 저장하도록 할 수 있습니다. 각 예약된 갱신 시마다 대상 테이블은 최신 쿼리 결과로 완전히 대체됩니다.
이 방법의 핵심 장점은 FINAL 키워드를 사용하는 쿼리가 갱신 시점에 한 번만 실행되므로, 이후 대상 테이블에 대한 쿼리에서는 FINAL을 사용할 필요가 없다는 점입니다.
반면 단점은 대상 테이블의 데이터가 가장 최근 갱신 시점까지만 최신 상태로 유지된다는 점입니다. 다만 많은 사용 사례에서는 수분에서 수시간 정도의 갱신 주기면 충분한 경우가 많습니다.
그런 다음 deduplicated_posts 테이블에 평소처럼 쿼리를 실행하면 됩니다.
