이 섹션에서는 dbt 및 ClickHouse 어댑터 설정 방법과 공개 IMDB 데이터셋을 사용하여 ClickHouse에서 dbt를 활용하는 예제를 제공합니다. 이 예제에서는 다음 단계를 다룹니다.
- dbt 프로젝트를 생성하고 ClickHouse 어댑터를 설정합니다.
- 모델을 정의합니다.
- 모델을 업데이트합니다.
- 증분 모델을 생성합니다.
- 스냅샷 모델을 생성합니다.
- materialized view를 사용합니다.
이 가이드는 나머지 문서, 기능 및 설정, materializations 레퍼런스와 함께 사용되도록 설계되었습니다.
환경을 준비하려면 dbt 및 ClickHouse 어댑터 설정 섹션의 지침을 따르십시오.
중요: 다음 내용은 Python 3.9에서 테스트되었습니다.
ClickHouse 준비
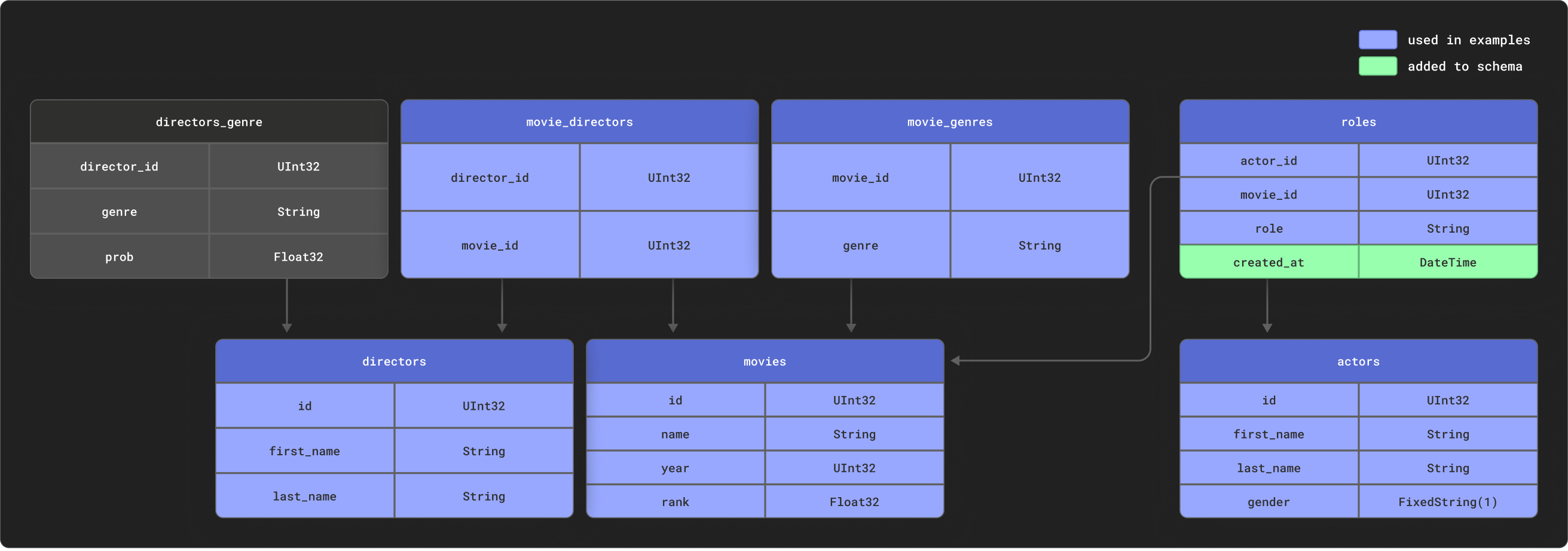
dbt는 관계형 특성이 강한 데이터를 모델링할 때 뛰어난 성능을 발휘합니다. 예제를 위해, 아래와 같은 관계형 스키마를 가진 작은 IMDB 데이터셋을 제공합니다. 이 데이터셋은 relational dataset repository에서 가져왔습니다. dbt에서 일반적으로 사용하는 스키마에 비해 매우 단순하지만, 다루기 쉬운 샘플을 나타냅니다.
아래에 표시된 것처럼 이 테이블들 중 일부만 사용합니다.
다음 테이블들을 생성하십시오.
CREATE DATABASE imdb;
CREATE TABLE imdb.actors
(
id UInt32,
first_name String,
last_name String,
gender FixedString(1)
) ENGINE = MergeTree ORDER BY (id, first_name, last_name, gender);
CREATE TABLE imdb.directors
(
id UInt32,
first_name String,
last_name String
) ENGINE = MergeTree ORDER BY (id, first_name, last_name);
CREATE TABLE imdb.genres
(
movie_id UInt32,
genre String
) ENGINE = MergeTree ORDER BY (movie_id, genre);
CREATE TABLE imdb.movie_directors
(
director_id UInt32,
movie_id UInt64
) ENGINE = MergeTree ORDER BY (director_id, movie_id);
CREATE TABLE imdb.movies
(
id UInt32,
name String,
year UInt32,
rank Float32 DEFAULT 0
) ENGINE = MergeTree ORDER BY (id, name, year);
CREATE TABLE imdb.roles
(
actor_id UInt32,
movie_id UInt32,
role String,
created_at DateTime DEFAULT now()
) ENGINE = MergeTree ORDER BY (actor_id, movie_id);
참고
roles 테이블의 created_at 컬럼은 기본값이 now()로 설정되어 있습니다. 이후에 이 값을 사용하여 모델의 증분 업데이트를 식별합니다. 자세한 내용은 증분 모델(Incremental Models)을 참고하십시오.
공개 엔드포인트의 소스 데이터를 읽어 테이블에 삽입하기 위해 s3 함수를 사용합니다. 다음 명령을 실행하여 테이블에 데이터를 채우십시오:
INSERT INTO imdb.actors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_actors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.genres
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_genres.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movie_directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movies
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.roles(actor_id, movie_id, role)
SELECT actor_id, movie_id, role
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_roles.tsv.gz',
'TSVWithNames');
실행 시간은 네트워크 대역폭에 따라 달라질 수 있지만, 각각은 몇 초 안에 완료되어야 합니다. 다음 쿼리를 실행하여 영화 출연 횟수가 많은 순으로 정렬된 배우별 요약을 계산하고, 데이터가 성공적으로 로드되었는지 확인하십시오:
SELECT id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM (
SELECT imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 5;
응답은 다음과 같습니다:
+------+------------+----------+------------------+-------------+--------------+-------------------+
|id |name |num_movies|avg_rank |unique_genres|uniq_directors|updated_at |
+------+------------+----------+------------------+-------------+--------------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 14:01:45|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 14:01:46|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 14:01:46|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 14:01:46|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 14:01:46|
+------+------------+----------+------------------+-------------+--------------+-------------------+
후속 가이드에서는 이 쿼리를 모델로 변환하여 ClickHouse에서 dbt 뷰와 테이블로 구체화할 것입니다.
ClickHouse에 연결하기
-
dbt 프로젝트를 생성합니다. 여기서는 소스 imdb의 이름을 그대로 사용합니다. 프롬프트가 표시되면 데이터베이스 소스로 clickhouse를 선택합니다.
clickhouse-user@clickhouse:~$ dbt init imdb
16:52:40 Running with dbt=1.1.0
Which database would you like to use?
[1] clickhouse
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
16:53:21 No sample profile found for clickhouse.
16:53:21
Your new dbt project "imdb" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profile
-
cd 명령으로 프로젝트 폴더로 이동합니다:
-
이 시점부터는 선호하는 텍스트 편집기가 필요합니다. 아래 예시에서는 널리 사용되는 VS Code를 사용합니다. IMDB 디렉터리를 열면 yml 파일과 sql 파일들의 모음을 볼 수 있습니다:
-
dbt_project.yml 파일을 수정하여 첫 번째 모델인 actor_summary를 지정하고 profile을 clickhouse_imdb로 설정합니다.
-
다음으로 ClickHouse 인스턴스에 대한 연결 정보를 dbt에 제공해야 합니다. 다음 내용을 ~/.dbt/profiles.yml에 추가합니다.
clickhouse_imdb:
target: dev
outputs:
dev:
type: clickhouse
schema: imdb_dbt
host: localhost
port: 8123
user: default
password: ''
secure: False
user와 password를 수정해야 한다는 점에 유의하십시오. 추가로 사용 가능한 설정은 여기에 문서화되어 있습니다.
-
IMDB 디렉터리에서 dbt debug 명령을 실행하여 dbt가 ClickHouse에 연결할 수 있는지 확인합니다.
clickhouse-user@clickhouse:~/imdb$ dbt debug
17:33:53 Running with dbt=1.1.0
dbt version: 1.1.0
python version: 3.10.1
python path: /home/dale/.pyenv/versions/3.10.1/bin/python3.10
os info: Linux-5.13.0-10039-tuxedo-x86_64-with-glibc2.31
Using profiles.yml file at /home/dale/.dbt/profiles.yml
Using dbt_project.yml file at /opt/dbt/imdb/dbt_project.yml
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
host: localhost
port: 8123
user: default
schema: imdb_dbt
secure: False
verify: False
Connection test: [OK connection ok]
All checks passed!
응답에 Connection test: [OK connection ok]가 포함되어 있으면 연결이 성공적으로 이루어졌음을 나타냅니다.
간단한 뷰 머티리얼라이제이션 생성
뷰 머티리얼라이제이션을 사용할 경우, 모델은 실행될 때마다 ClickHouse에서 CREATE VIEW AS 구문을 통해 뷰로 다시 생성됩니다. 이는 데이터를 추가로 저장할 필요는 없지만, 테이블 머티리얼라이제이션보다 쿼리 성능이 더 느립니다.
-
imdb 폴더에서 models/example 디렉터리를 삭제하십시오:
clickhouse-user@clickhouse:~/imdb$ rm -rf models/example
-
models 폴더의 actors 디렉터리 안에 새 파일을 만듭니다. 여기에서는 각 파일이 하나의 actor 모델을 나타내도록 합니다:
clickhouse-user@clickhouse:~/imdb$ mkdir models/actors
-
models/actors 폴더에 schema.yml와 actor_summary.sql 파일을 생성합니다.
clickhouse-user@clickhouse:~/imdb$ touch models/actors/actor_summary.sql
clickhouse-user@clickhouse:~/imdb$ touch models/actors/schema.yml
schema.yml 파일은 사용할 테이블을 정의합니다. 이렇게 정의된 테이블은 이후 매크로에서 사용할 수 있습니다. models/actors/schema.yml 파일을 편집하여 다음 내용을 포함하도록 하십시오:
version: 2
sources:
- name: imdb
tables:
- name: directors
- name: actors
- name: roles
- name: movies
- name: genres
- name: movie_directors
actors_summary.sql 파일은 실제 모델을 정의합니다. 또한 config 함수에서 ClickHouse에서 해당 모델이 VIEW로 구체화(materialize)되도록 요청하는 것도 확인할 수 있습니다. 테이블은 schema.yml 파일에서 source 함수, 예를 들어 source('imdb', 'movies')와 같이 참조되며, 이는 imdb 데이터베이스의 movies 테이블을 의미합니다. models/actors/actors_summary.sql 파일을 수정하여 다음 내용이 포함되도록 하십시오:
{{ config(materialized='view') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
최종 actor_summary에 updated_at 컬럼이 포함되어 있음을 유의하십시오. 이 값은 이후 증분 머터리얼라이제이션(incremental materialization)에 사용합니다.
-
imdb 디렉터리에서 dbt run 명령을 실행하십시오.
clickhouse-user@clickhouse:~/imdb$ dbt run
15:05:35 Running with dbt=1.1.0
15:05:35 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:05:35
15:05:36 Concurrency: 1 threads (target='dev')
15:05:36
15:05:36 1 of 1 START view model imdb_dbt.actor_summary.................................. [RUN]
15:05:37 1 of 1 OK created view model imdb_dbt.actor_summary............................. [OK in 1.00s]
15:05:37
15:05:37 Finished running 1 view model in 1.97s.
15:05:37
15:05:37 Completed successfully
15:05:37
15:05:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
-
dbt는 요청한 대로 ClickHouse에서 해당 모델을 뷰(view)로 생성합니다. 이제 이 뷰에 직접 쿼리를 실행할 수 있습니다. 이 뷰는 ~/.dbt/profiles.yml 파일의 clickhouse_imdb 프로필 아래에 있는 schema 매개변수에 따라 imdb_dbt 데이터베이스에 생성됩니다.
+------------------+
|name |
+------------------+
|INFORMATION_SCHEMA|
|default |
|imdb |
|imdb_dbt | <---created by dbt!
|information_schema|
|system |
+------------------+
이 VIEW를 조회하면 더 간단한 문법으로 앞서 사용한 쿼리의 결과를 재현할 수 있습니다:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
테이블 구체화 생성하기
이전 예시에서는 모델이 뷰로 구체화되었습니다. 이는 일부 쿼리에는 충분한 성능을 제공할 수 있지만, 더 복잡한 SELECT나 자주 실행되는 쿼리는 테이블로 구체화하는 것이 더 적합할 수 있습니다. 이러한 구체화는 BI 도구에서 쿼리되는 모델에 유용하며, 사용자에게 더 빠른 사용 경험을 제공하는 데 도움이 됩니다. 이는 사실상 쿼리 결과를 새로운 테이블로 저장하는 것이며, 그에 따른 스토리지 오버헤드가 발생합니다. 즉, INSERT TO SELECT가 실행되는 것과 같습니다. 이 테이블은 매번 다시 생성되며, 증분 방식은 아니라는 점에 유의하십시오. 결과 집합이 큰 경우 실행 시간이 길어질 수 있습니다. 자세한 내용은 dbt 제한 사항을 참고하십시오.
-
materialized 파라미터가 table로 설정되도록 actors_summary.sql 파일을 수정합니다. ORDER BY가 어떻게 정의되어 있는지, 그리고 MergeTree 테이블 엔진을 사용하고 있음을 확인하십시오:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='table') }}
-
imdb 디렉터리에서 dbt run 명령을 실행합니다. 이 실행은 대부분의 머신에서 약 10초 정도 소요될 수 있습니다.
clickhouse-user@clickhouse:~/imdb$ dbt run
15:13:27 Running with dbt=1.1.0
15:13:27 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:13:27
15:13:28 Concurrency: 1 threads (target='dev')
15:13:28
15:13:28 1 of 1 START table model imdb_dbt.actor_summary................................. [RUN]
15:13:37 1 of 1 OK created table model imdb_dbt.actor_summary............................ [OK in 9.22s]
15:13:37
15:13:37 Finished running 1 table model in 10.20s.
15:13:37
15:13:37 Completed successfully
15:13:37
15:13:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
-
테이블 imdb_dbt.actor_summary가 생성되었는지 확인합니다:
SHOW CREATE TABLE imdb_dbt.actor_summary;
적절한 데이터 타입으로 생성된 테이블을 확인할 수 있습니다:
+----------------------------------------
|statement
+----------------------------------------
|CREATE TABLE imdb_dbt.actor_summary
|(
|`id` UInt32,
|`first_name` String,
|`last_name` String,
|`num_movies` UInt64,
|`updated_at` DateTime
|)
|ENGINE = MergeTree
|ORDER BY (id, first_name, last_name)
+----------------------------------------
-
이 테이블의 결과가 이전 결과와 일치하는지 확인합니다. 이제 모델이 테이블이 되었기 때문에 응답 시간이 상당히 개선된 점에 주목하십시오:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
이 모델에 대해 다른 쿼리를 실행해도 됩니다. 예를 들어, 5편 이상에 출연한 배우들 중에서 가장 순위가 높은 영화를 가진 배우는 누구입니까?
SELECT * FROM imdb_dbt.actor_summary WHERE num_movies > 5 ORDER BY avg_rank DESC LIMIT 10;
증분 구체화 생성하기
이전 예제에서는 모델을 구체화하기 위한 테이블을 생성했습니다. 이 테이블은 dbt가 실행될 때마다 다시 생성됩니다. 결과 집합이 크거나 변환이 복잡한 경우 이 방식은 실용적이지 않거나 비용이 매우 많이 들 수 있습니다. 이러한 문제를 해결하고 빌드 시간을 줄이기 위해 dbt는 증분(Incremental) 구체화를 제공합니다. 이를 사용하면 dbt가 마지막 실행 이후 변경된 레코드만 테이블에 삽입하거나 업데이트하므로, 이벤트 스타일 데이터에 적합합니다. 내부적으로는 모든 업데이트된 레코드를 포함하는 임시 테이블을 만든 다음, 변경되지 않은 레코드와 업데이트된 레코드를 모두 새로운 대상 테이블에 삽입합니다. 이로 인해 큰 결과 집합에 대해서는 테이블 모델과 유사한 제한 사항이 발생합니다.
대규모 결과 집합에서 이러한 제한을 극복하기 위해 어댑터는 'inserts_only' 모드를 지원합니다. 이 모드에서는 임시 테이블을 생성하지 않고 모든 업데이트를 대상 테이블에 그대로 삽입합니다(아래에서 자세히 설명합니다).
이 예제를 설명하기 위해 배우 "Clicky McClickHouse"를 추가합니다. 그는 무려 910편의 영화에 출연하여, Mel Blanc보다 더 많은 영화에 출연하게 됩니다.
-
먼저 모델을 incremental 유형으로 변경합니다. 이 변경을 위해서는 다음이 필요합니다:
- unique_key - 어댑터가 행을 고유하게 식별할 수 있도록 하려면 unique_key를 제공해야 합니다. 이 경우 쿼리의
id 필드로 충분합니다. 이렇게 하면 구체화된 테이블에 행 중복이 발생하지 않습니다. 고유성 제약 조건에 대한 자세한 내용은 여기를 참조하십시오.
- Incremental filter - 또한 증분 실행 시 어떤 행이 변경되었는지 dbt에 알려야 합니다. 이는 델타 표현식(delta expression)을 제공하여 구현합니다. 일반적으로 이벤트 데이터에는 타임스탬프가 사용되므로
updated_at 타임스탬프 필드를 사용합니다. 이 컬럼은 행이 삽입될 때 기본값이 now()로 설정되며, 이를 통해 새로운 행을 식별할 수 있습니다. 또한 새로운 actor가 추가되는 또 다른 경우도 식별해야 합니다. 기존 구체화된 테이블을 나타내는 {{this}} 변수를 사용하면 where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})라는 표현식을 얻을 수 있습니다. 이 표현식을 {% if is_incremental() %} 조건 내부에 포함하여, 테이블이 처음 생성될 때가 아니라 증분 실행에서만 사용되도록 합니다. 증분 모델에서 행을 필터링하는 방법에 대한 자세한 내용은 dbt 문서의 이 논의를 참조하십시오.
actor_summary.sql 파일을 다음과 같이 업데이트하십시오:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
roles 및 actors 테이블에 대한 업데이트 및 추가에만 이 모델이 반응한다는 점에 유의하십시오. 모든 테이블의 변경에 대응하도록 하려면, 이 모델을 여러 개의 하위 모델로 분리하고 각 하위 모델에 고유한 증분 처리 기준을 두는 구성이 권장됩니다. 이렇게 만든 모델들은 다시 서로를 참조하고 연결할 수 있습니다. 모델 간 상호 참조에 대한 자세한 내용은 여기를 참조하십시오.
-
dbt run을 실행하고 생성된 테이블의 내용을 확인합니다.
clickhouse-user@clickhouse:~/imdb$ dbt run
15:33:34 Running with dbt=1.1.0
15:33:34 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:33:34
15:33:35 Concurrency: 1 threads (target='dev')
15:33:35
15:33:35 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
15:33:41 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.33s]
15:33:41
15:33:41 Finished running 1 incremental model in 7.30s.
15:33:41
15:33:41 Completed successfully
15:33:41
15:33:41 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
-
이제 증분 업데이트를 예시하기 위해 모델에 데이터를 추가합니다. 배우 「Clicky McClickHouse」를 actors 테이블에 추가하십시오:
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
-
「Clicky」가 무작위로 선택한 영화 910편에 주연으로 등장하도록 해 보겠습니다.
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 910 OFFSET 10000;
-
기본 소스 테이블에 직접 쿼리를 실행하여 dbt 모델을 거치지 않고, 그가 실제로 이제 출연 횟수가 가장 많은 배우인지 확인하십시오.
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 2;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
-
dbt run을 실행한 후, 모델이 업데이트되어 위의 결과와 일치하는지 확인하십시오:
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.82s]
16:12:24
16:12:24 Finished running 1 incremental model in 7.79s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 2;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
내부 동작
위 증분 업데이트를 수행할 때 실행되는 SQL 문은 ClickHouse의 쿼리 로그를 조회하여 식별할 수 있습니다.
SELECT event_time, query FROM system.query_log WHERE type='QueryStart' AND query LIKE '%dbt%'
AND event_time > subtractMinutes(now(), 15) ORDER BY event_time LIMIT 100;
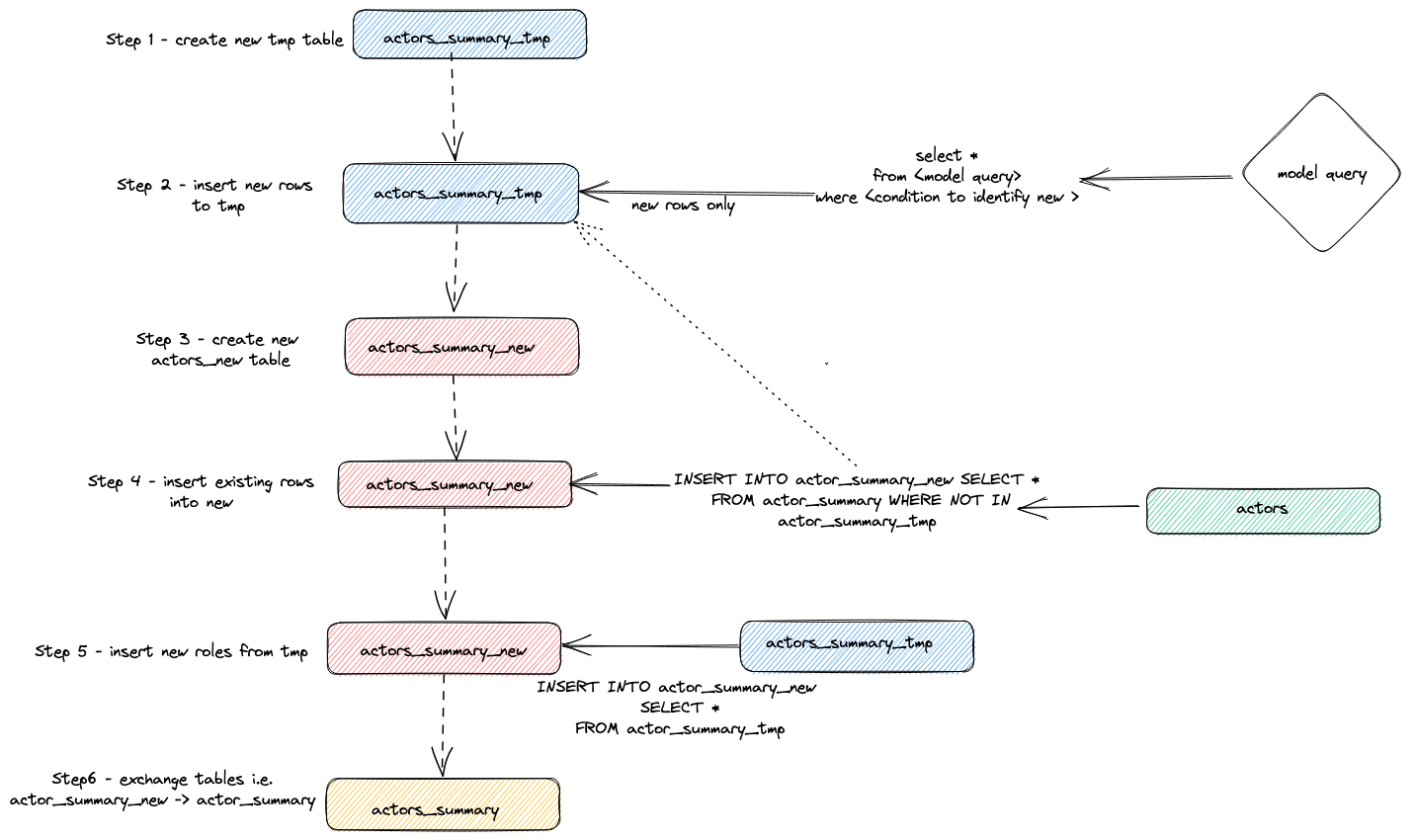
위 쿼리를 실행하려는 기간에 맞게 조정합니다. 결과 확인은 사용자에게 맡기되, 어댑터가 증분 업데이트를 수행하기 위해 사용하는 일반적인 전략은 다음과 같습니다:
- 어댑터는 임시 테이블
actor_sumary__dbt_tmp를 생성합니다. 변경된 행은 이 테이블로 스트리밍됩니다.
- 새 테이블
actor_summary_new가 생성됩니다. 기존 테이블의 행은 해당 행 ID가 임시 테이블에 존재하지 않는지 확인하면서, 순차적으로 기존 테이블에서 새 테이블로 스트리밍됩니다. 이를 통해 업데이트 및 중복을 효과적으로 처리합니다.
- 임시 테이블의 데이터를 새
actor_summary 테이블로 스트리밍합니다.
- 마지막으로
EXCHANGE TABLES 문을 통해 새 테이블을 기존 버전과 원자적으로 교환합니다. 기존 테이블과 임시 테이블은 이후 삭제(drop)됩니다.
이는 아래와 같이 시각화됩니다:
이 전략은 매우 큰 모델에서는 한계에 부딪힐 수 있습니다. 자세한 내용은 제한 사항을 참조하십시오.
Append Strategy (inserts-only mode)
증분 모델에서 대규모 데이터셋으로 인한 한계를 극복하기 위해 어댑터는 dbt 설정 매개변수 incremental_strategy를 사용합니다. 이 값은 append로 설정할 수 있습니다. 이렇게 설정하면 갱신된 행은 대상 테이블(즉, imdb_dbt.actor_summary)에 직접 삽입되며 임시 테이블은 생성되지 않습니다.
참고: Append 전용 모드에서는 데이터가 변경 불가능(immutable)하거나, 중복을 허용할 수 있어야 합니다. 변경된 행을 지원하는 증분 테이블 모델이 필요하다면 이 모드를 사용하지 마십시오.
이 모드를 설명하기 위해, 새로운 배우를 하나 더 추가한 뒤 incremental_strategy='append' 설정으로 dbt run을 다시 실행합니다.
-
actor_summary.sql에서 append 전용 모드를 설정합니다:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='append') }}
-
유명 배우를 하나 더 추가합니다 - Danny DeBito
INSERT INTO imdb.actors VALUES (845467, 'Danny', 'DeBito', 'M');
-
Danny가 임의의 920편 영화에 출연하도록 합니다.
INSERT INTO imdb.roles
SELECT now() as created_at, 845467 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 920 OFFSET 10000;
-
dbt run을 실행하고, Danny가 actor-summary 테이블에 추가되었는지 확인합니다.
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 186 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 0.17s]
16:12:24
16:12:24 Finished running 1 incremental model in 0.19s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 3;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845467|Danny DeBito |920 |1.4768987303293204|21 |670 |2022-04-26 16:22:06|
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
이 증분 실행이 "Clicky"를 삽입했을 때보다 훨씬 빨라졌음을 확인할 수 있습니다.
query_log 테이블을 다시 확인하면 두 번의 증분 실행 사이의 차이점을 확인할 수 있습니다.
INSERT INTO imdb_dbt.actor_summary ("id", "name", "num_movies", "avg_rank", "genres", "directors", "updated_at")
WITH actor_summary AS (
SELECT id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS genres,
uniqExact(director_name) AS directors,
max(created_at) AS updated_at
FROM (
SELECT imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
)
SELECT *
FROM actor_summary
-- this filter will only be applied on an incremental run
WHERE id > (SELECT max(id) FROM imdb_dbt.actor_summary) OR updated_at > (SELECT max(updated_at) FROM imdb_dbt.actor_summary)
이번 실행에서는 새 행만 바로 imdb_dbt.actor_summary 테이블에 추가되며, 테이블을 새로 생성하지 않습니다.
Delete and insert 모드(실험적)
기존에는 ClickHouse가 비동기 Mutations 형태로만 제한적인 업데이트와 삭제를 지원했습니다. 이러한 뮤테이션은 I/O 집약적일 수 있으며, 일반적으로는 사용을 피하는 것이 좋습니다.
ClickHouse 22.8에서는 경량한 삭제가, ClickHouse 25.7에서는 경량 업데이트가 도입되었습니다. 이러한 기능의 도입으로, 비동기적으로 구체화되는 경우에도 단일 업데이트 쿼리에서 발생하는 변경 사항은 사용자 관점에서 즉시 반영됩니다.
이 모드는 incremental_strategy 파라미터를 통해 모델에 대해 구성할 수 있습니다. 예:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='delete+insert') }}
이 전략은 대상 모델의 테이블에서 직접 동작하므로, 작업 도중 문제가 발생하면 증분 모델의 데이터가 유효하지 않은 상태가 될 가능성이 큽니다. 원자적 업데이트는 제공되지 않습니다.
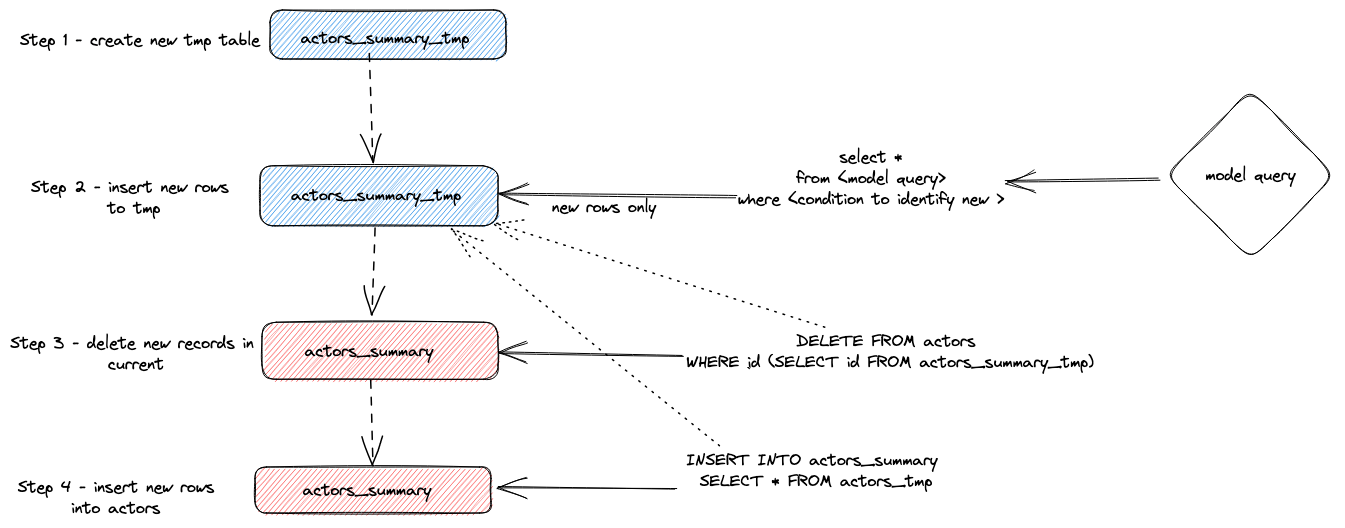
요약하면, 이 접근 방식은 다음과 같습니다.
- 어댑터가 임시 테이블
actor_sumary__dbt_tmp를 생성합니다. 변경된 행은 이 테이블로 스트리밍됩니다.
- 현재
actor_summary 테이블에 대해 DELETE가 실행됩니다. actor_sumary__dbt_tmp에 있는 id를 기준으로 actor_summary의 행이 삭제됩니다.
actor_sumary__dbt_tmp의 행이 INSERT INTO actor_summary SELECT * FROM actor_sumary__dbt_tmp를 사용해 actor_summary에 삽입됩니다.
이 과정은 아래 그림과 같습니다.
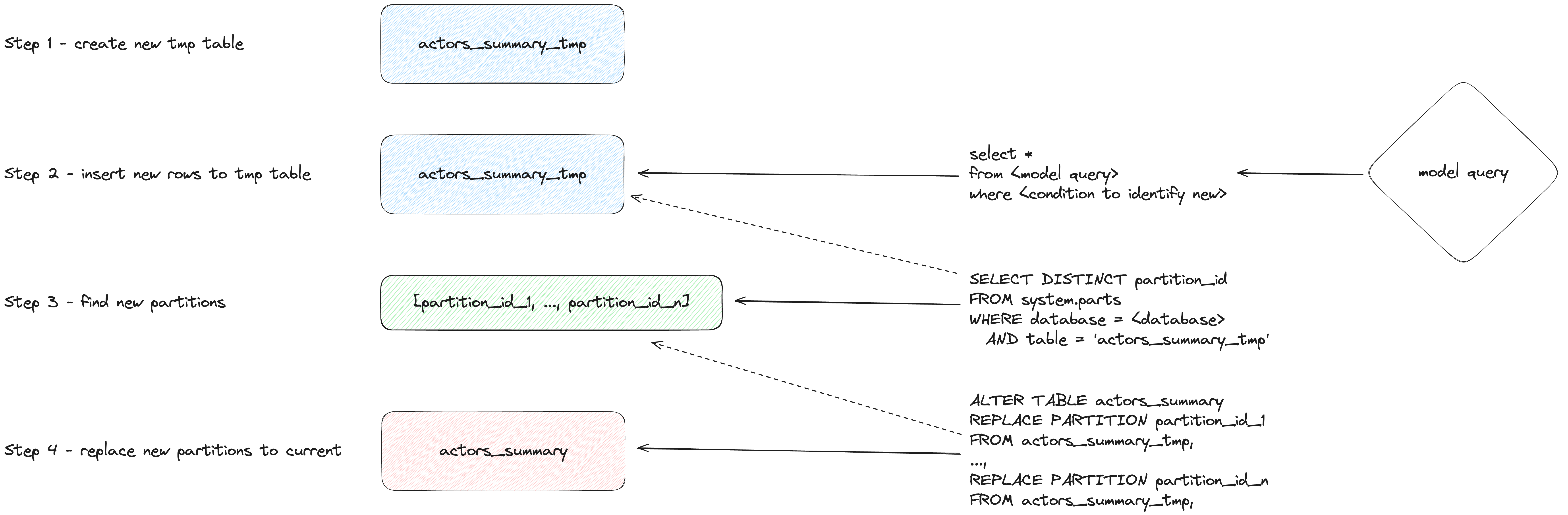
insert_overwrite 모드(실험적)
다음 단계를 수행합니다.
- 증분 모델 릴레이션과 동일한 구조를 가진 스테이징(임시) 테이블을 생성합니다:
CREATE TABLE {staging} AS {target}.
- 새 레코드(SELECT로 생성된 결과)만 스테이징 테이블에 삽입합니다.
- 스테이징 테이블에 존재하는 새 파티션만 대상 테이블의 해당 파티션과 교체합니다.
이 방식에는 다음과 같은 장점이 있습니다.
- 전체 테이블을 복사하지 않기 때문에 기본 전략보다 더 빠르게 동작합니다.
- INSERT 작업이 성공적으로 완료될 때까지 원본 테이블을 수정하지 않으므로 다른 전략보다 더 안전합니다. 중간에 실패가 발생해도 원본 테이블은 변경되지 않습니다.
- 데이터 엔지니어링 모범 사례인 「파티션 불변성(partitions immutability)」 원칙을 구현합니다. 이를 통해 증분 및 병렬 데이터 처리, 롤백 등을 단순화할 수 있습니다.
스냅샷 생성
dbt 스냅샷을 사용하면 시간이 지남에 따라 변경 가능한 모델의 변경 사항을 기록할 수 있습니다. 이를 통해 분석가는 모델의 이전 상태를 「과거로 돌아가」 확인할 수 있는 시점별(point-in-time) 쿼리를 모델에 대해 실행할 수 있습니다. 이는 type-2 Slowly Changing Dimensions을 사용하여 구현되며, from 및 to 날짜 컬럼에 행이 유효했던 기간이 기록됩니다. 이 기능은 ClickHouse 어댑터에서 지원되며, 아래 예시에서 확인할 수 있습니다.
이 예시는 이미 증분 테이블 모델 생성을 완료했다는 것을 전제로 합니다. actor_summary.sql에서 inserts_only=True를 설정하지 않았는지 확인하십시오. models/actor_summary.sql은 다음과 같이 되어 있어야 합니다:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
-
스냅샷 디렉터리에 actor_summary 파일을 생성합니다.
touch snapshots/actor_summary.sql
-
actor_summary.sql 파일의 내용을 다음과 같이 수정합니다:
{% snapshot actor_summary_snapshot %}
{{
config(
target_schema='snapshots',
unique_key='id',
strategy='timestamp',
updated_at='updated_at',
)
}}
select * from {{ref('actor_summary')}}
{% endsnapshot %}
이 내용과 관련하여 몇 가지를 살펴보면 다음과 같습니다:
- select 쿼리는 시간에 따라 스냅샷으로 저장하려는 결과를 정의합니다.
ref 함수는 앞에서 생성한 actor_summary 모델을 참조하는 데 사용됩니다.
- 레코드 변경을 나타내기 위한 타임스탬프 컬럼이 필요합니다. 여기서는
updated_at 컬럼(증분 테이블 모델 생성 참고)을 사용할 수 있습니다. strategy 파라미터는 업데이트를 나타내는 데 타임스탬프를 사용함을 의미하며, updated_at 파라미터는 사용할 컬럼을 지정합니다. 모델에 이 컬럼이 없다면 check 전략을 대신 사용할 수 있습니다. 이 방식은 훨씬 비효율적이며, 사용자가 비교할 컬럼 목록을 지정해야 합니다. dbt는 이러한 컬럼들의 현재 값과 과거 값을 비교하여 변경 사항이 있으면 기록하고, 동일하면 아무 작업도 하지 않습니다.
-
dbt snapshot 명령을 실행합니다.
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:26:23 Running with dbt=1.1.0
13:26:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:26:23
13:26:25 Concurrency: 1 threads (target='dev')
13:26:25
13:26:25 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:26:25 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 0.79s]
13:26:25
13:26:25 Finished running 1 snapshot in 2.11s.
13:26:25
13:26:25 Completed successfully
13:26:25
13:26:25 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
target_schema 매개변수로 결정되는 snapshots 데이터베이스에 actor_summary_snapshot라는 테이블이 생성된 것을 확인할 수 있습니다.
-
이 데이터를 샘플링하면 dbt가 dbt_valid_from과 dbt_valid_to 컬럼을 포함했음을 확인할 수 있습니다. 후자의 값은 null로 설정되어 있으며, 이후 실행 시 업데이트됩니다.
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;
+------+----------+------------+----------+-------------------+------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to|
+------+----------+------------+----------+-------------------+------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|NULL |
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
|283127|Tom |London |549 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+------------+
-
가장 좋아하는 배우 Clicky McClickHouse가 추가로 영화 10편에 출연하도록 하십시오.
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, rand(number) % 412320 as movie_id, 'Himself' as role
FROM system.numbers
LIMIT 10;
-
imdb 디렉터리에서 dbt run 명령을 다시 실행합니다. 이렇게 하면 증분 모델이 업데이트됩니다. 완료되면 변경 사항을 캡처하기 위해 dbt snapshot 명령을 실행합니다.
clickhouse-user@clickhouse:~/imdb$ dbt run
13:46:14 Running with dbt=1.1.0
13:46:14 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:14
13:46:15 Concurrency: 1 threads (target='dev')
13:46:15
13:46:15 1 of 1 START incremental model imdb_dbt.actor_summary....................... [RUN]
13:46:18 1 of 1 OK created incremental model imdb_dbt.actor_summary.................. [OK in 2.76s]
13:46:18
13:46:18 Finished running 1 incremental model in 3.73s.
13:46:18
13:46:18 Completed successfully
13:46:18
13:46:18 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:46:26 Running with dbt=1.1.0
13:46:26 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:26
13:46:27 Concurrency: 1 threads (target='dev')
13:46:27
13:46:27 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:46:31 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 4.05s]
13:46:31
13:46:31 Finished running 1 snapshot in 5.02s.
13:46:31
13:46:31 Completed successfully
13:46:31
13:46:31 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
-
이제 스냅샷을 다시 쿼리해 보면, Clicky McClickHouse에 대한 행이 2개 존재함을 확인할 수 있습니다. 기존 레코드에는 이제 dbt_valid_to 값이 있습니다. 새로운 값은 dbt_valid_from 컬럼에 동일한 값으로 기록되고, dbt_valid_to 값은 null로 기록됩니다. 새로운 행이 있었다면, 이들도 스냅샷에 함께 추가되었을 것입니다.
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;
+------+----------+------------+----------+-------------------+-------------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to |
+------+----------+------------+----------+-------------------+-------------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|920 |2022-05-25 19:34:37|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|2022-05-25 19:34:37|
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+-------------------+
dbt 스냅샷에 대한 자세한 내용은 여기 문서를 참고하십시오.
시드 사용하기
dbt는 CSV 파일에서 데이터를 로드하는 기능을 제공합니다. 이 기능은 데이터베이스의 대규모 내보내기를 로드하는 데에는 적합하지 않고, 일반적으로 코드 테이블이나 딕셔너리처럼 국가 코드를 국가 이름에 매핑하는 등의 용도로 사용하는 작은 파일에 더 적합합니다. 간단한 예로, 시드 기능을 사용해 장르 코드 목록을 생성한 후 업로드합니다.
-
기존 데이터셋에서 장르 코드 목록을 생성합니다. dbt 디렉터리에서 clickhouse-client를 사용해 seeds/genre_codes.csv 파일을 생성합니다:
clickhouse-user@clickhouse:~/imdb$ clickhouse-client --password <password> --query
"SELECT genre, ucase(substring(genre, 1, 3)) as code FROM imdb.genres GROUP BY genre
LIMIT 100 FORMAT CSVWithNames" > seeds/genre_codes.csv
-
dbt seed 명령을 실행합니다. 그러면 스키마 설정에서 정의한 대로 데이터베이스 imdb_dbt에 새로운 테이블 genre_codes가 생성되고, CSV 파일의 행이 여기에 로드됩니다.
clickhouse-user@clickhouse:~/imdb$ dbt seed
17:03:23 Running with dbt=1.1.0
17:03:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 1 seed file, 6 sources, 0 exposures, 0 metrics
17:03:23
17:03:24 Concurrency: 1 threads (target='dev')
17:03:24
17:03:24 1 of 1 START seed file imdb_dbt.genre_codes..................................... [RUN]
17:03:24 1 of 1 OK loaded seed file imdb_dbt.genre_codes................................. [INSERT 21 in 0.65s]
17:03:24
17:03:24 Finished running 1 seed in 1.62s.
17:03:24
17:03:24 Completed successfully
17:03:24
17:03:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
-
데이터가 로드되었는지 확인합니다:
SELECT * FROM imdb_dbt.genre_codes LIMIT 10;
+-------+----+
|genre |code|
+-------+----+
|Drama |DRA |
|Romance|ROM |
|Short |SHO |
|Mystery|MYS |
|Adult |ADU |
|Family |FAM |
|Action |ACT |
|Sci-Fi |SCI |
|Horror |HOR |
|War |WAR |
+-------+----+=
이전 가이드에서는 dbt 기능의 일부만 간략히 다루었습니다. 보다 심화된 내용은 잘 정리된 dbt 문서를 참고하시기 바랍니다.