Apache NiFi를 ClickHouse에 연결하기
Apache NiFi는 소프트웨어 시스템 간 데이터 흐름을 자동화하도록 설계된 오픈 소스 워크플로 관리 소프트웨어입니다. ETL 데이터 파이프라인을 생성할 수 있으며, 300개가 넘는 데이터 프로세서를 기본으로 제공합니다. 이 단계별 튜토리얼에서는 Apache NiFi를 ClickHouse의 데이터 소스와 목적지(destination)로 구성하고 샘플 데이터 세트를 로드하는 방법을 설명합니다.
연결 정보 수집하기
HTTP(S)로 ClickHouse에 연결하려면 다음 정보가 필요합니다:
| Parameter(s) | Description |
|---|---|
HOST and PORT | 일반적으로 TLS를 사용할 때는 포트가 8443이고, TLS를 사용하지 않을 때는 8123입니다. |
DATABASE NAME | 기본적으로 default라는 데이터베이스가 있으며, 연결하려는 데이터베이스의 이름을 사용합니다. |
USERNAME and PASSWORD | 기본값으로 사용자 이름은 default입니다. 사용하려는 용도에 적합한 사용자 이름을 사용합니다. |
ClickHouse Cloud 서비스에 대한 세부 정보는 ClickHouse Cloud 콘솔에서 확인할 수 있습니다. 서비스를 선택한 다음 Connect를 클릭하십시오:
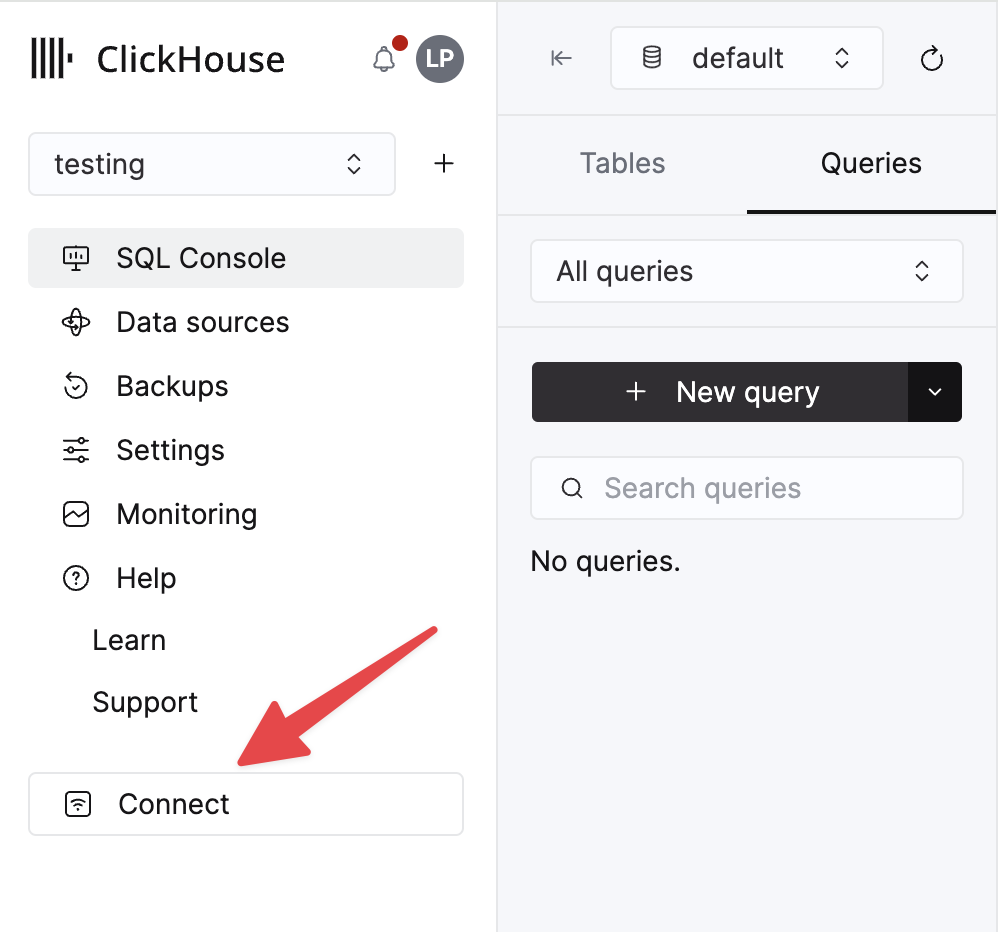
HTTPS를 선택하십시오. 연결 정보는 예제 curl 명령에 표시됩니다.
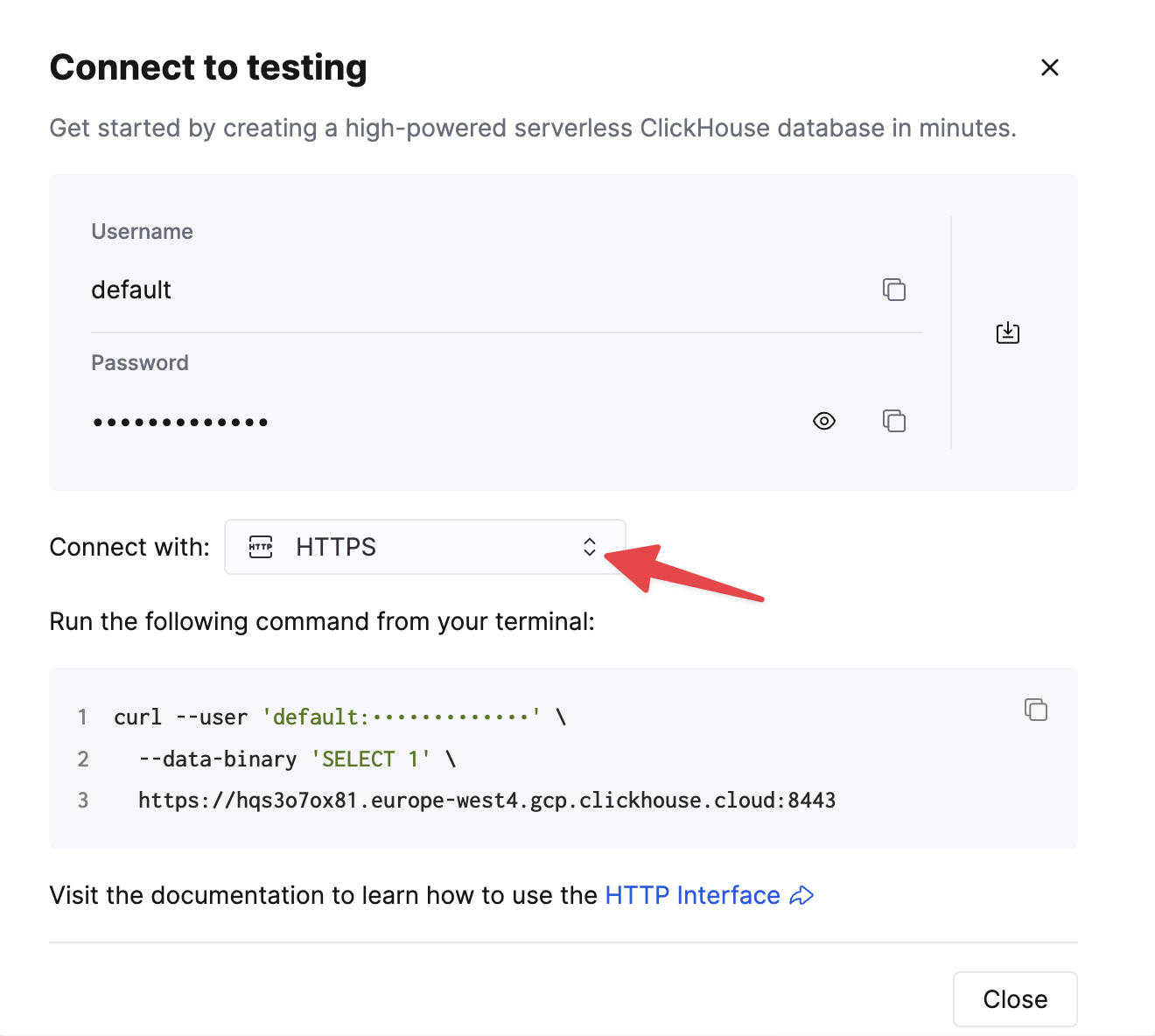
자가 관리형 ClickHouse를 사용하는 경우, 연결 정보는 ClickHouse 관리자가 설정합니다.
Apache NiFi 다운로드 및 실행
새로운 설정을 위해 https://nifi.apache.org/download.html 에서 바이너리를 다운로드하고 ./bin/nifi.sh start를 실행하여 시작하세요
ClickHouse JDBC 드라이버 다운로드하기
- GitHub에서 ClickHouse JDBC 드라이버 릴리스 페이지를 방문하여 최신 JDBC 릴리스 버전을 확인하십시오
- 릴리스 버전에서 "Show all xx assets"를 클릭한 다음 "shaded" 또는 "all" 키워드를 포함한 JAR 파일을 찾습니다. 예를 들어
clickhouse-jdbc-0.5.0-all.jar입니다. - JAR 파일을 Apache NiFi에서 액세스할 수 있는 폴더에 배치하고, 해당 절대 경로를 메모해 둡니다
DBCPConnectionPool Controller Service 추가 및 속성 구성
-
Apache NiFi에서 Controller Service를 구성하려면 「톱니바퀴」 버튼을 클릭하여 NiFi Flow Configuration 페이지로 이동합니다.
-
Controller Services 탭을 선택한 다음 오른쪽 상단의
+버튼을 클릭하여 새 Controller Service를 추가합니다.
-
DBCPConnectionPool을(를) 검색하고 "Add" 버튼을 클릭합니다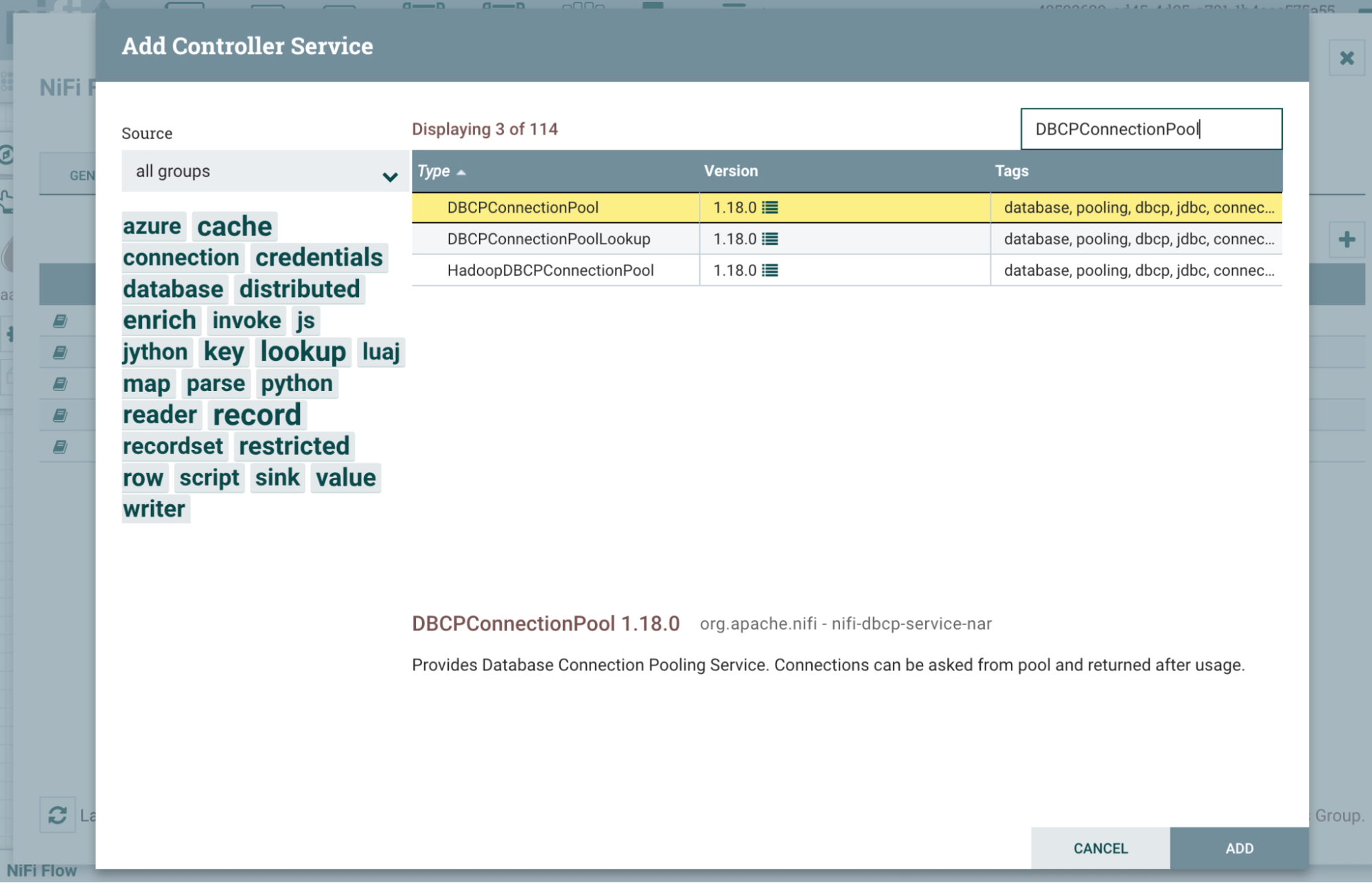
-
새로 추가된
DBCPConnectionPool은 기본적으로 Invalid 상태로 생성됩니다. 설정을 시작하려면 "gear" 버튼을 클릭하십시오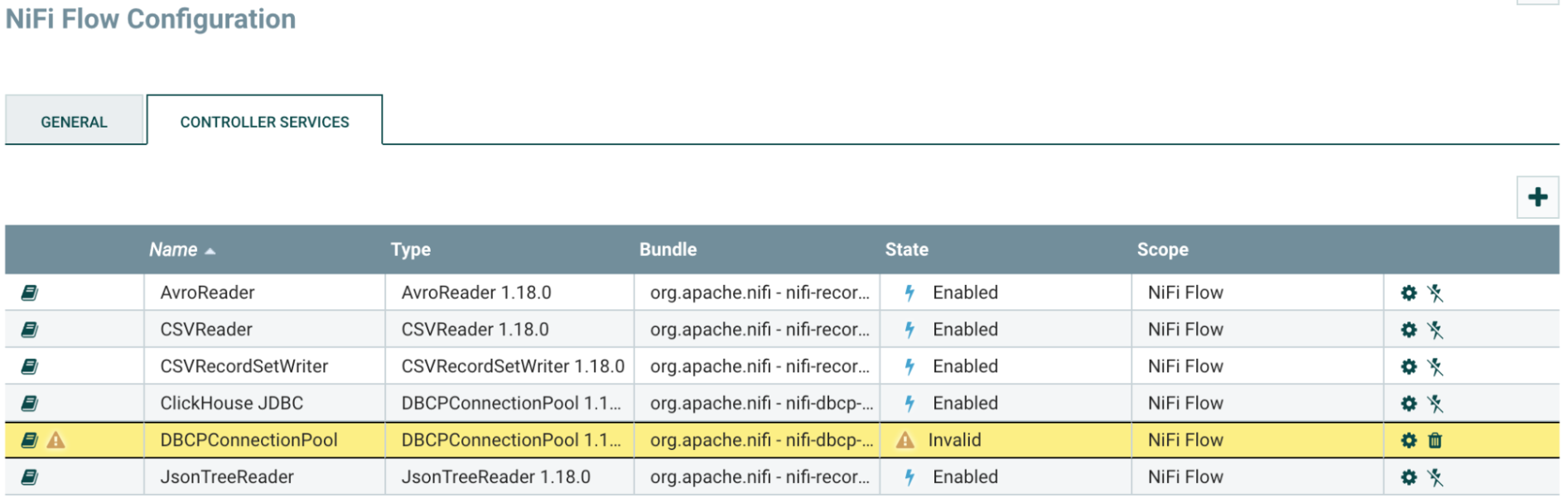
-
「Properties」 섹션에서 다음 값을 입력합니다.
| 속성 | 값 | 비고 |
|---|---|---|
| 데이터베이스 연결 URL | jdbc:ch:https://HOSTNAME:8443/default?ssl=true | 연결 URL의 HOSTNAME을 환경에 맞는 값으로 교체합니다 |
| 데이터베이스 드라이버 클래스 이름 | com.clickhouse.jdbc.ClickHouseDriver | |
| 데이터베이스 드라이버 경로 | /etc/nifi/nifi-X.XX.X/lib/clickhouse-jdbc-0.X.X-patchXX-shaded.jar | ClickHouse JDBC 드라이버 JAR 파일의 절대 경로 |
| 데이터베이스 사용자 이름 | default | ClickHouse 사용자 이름 |
| 비밀번호 | password | ClickHouse 비밀번호 |
-
Settings 섹션에서 Controller Service의 이름을 추후 쉽게 식별할 수 있도록 "ClickHouse JDBC"로 변경합니다.
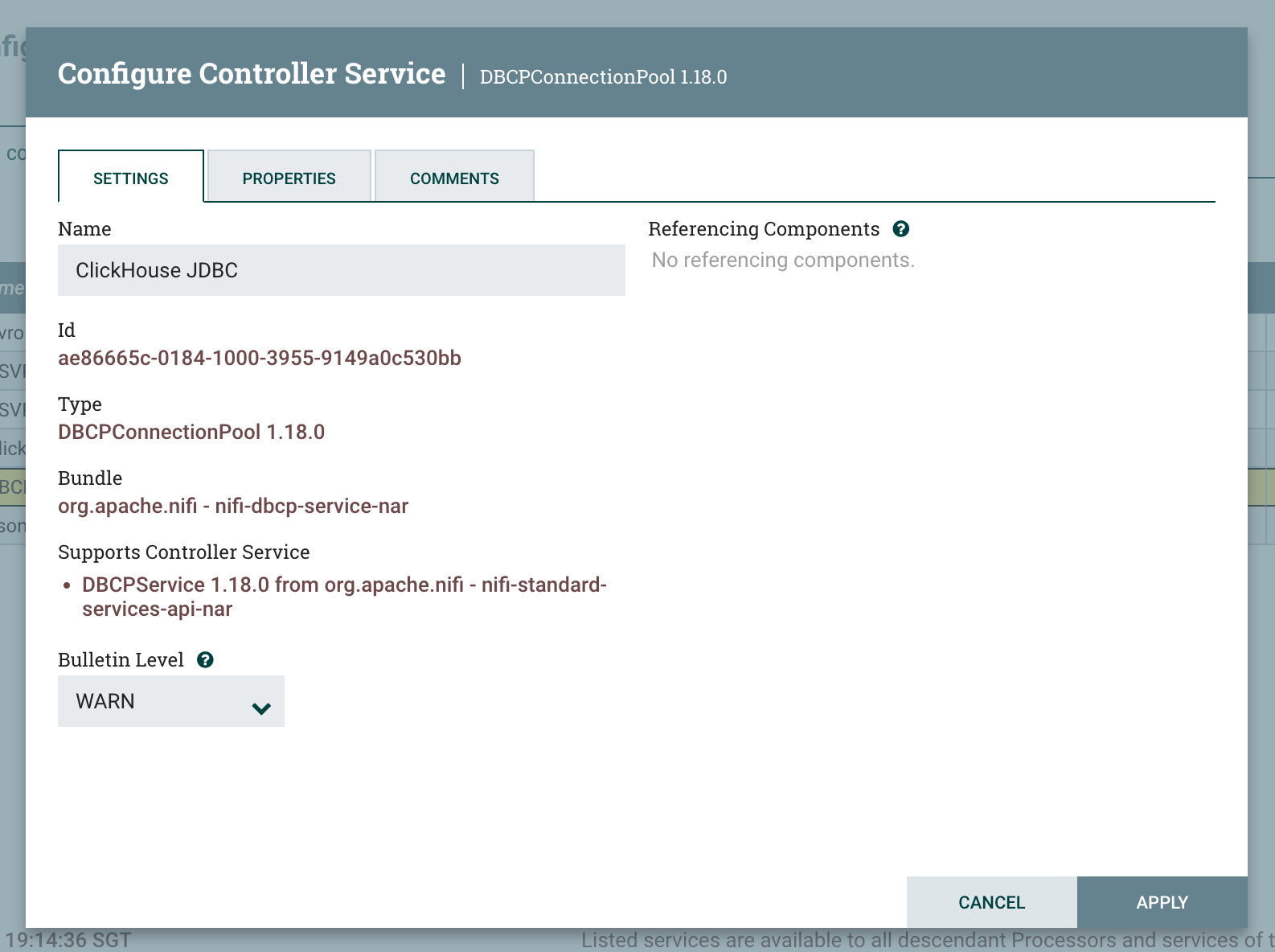
-
"번개" 모양 아이콘을 클릭한 다음 "Enable" 버튼을 클릭하여
DBCPConnectionPoolController Service를 활성화합니다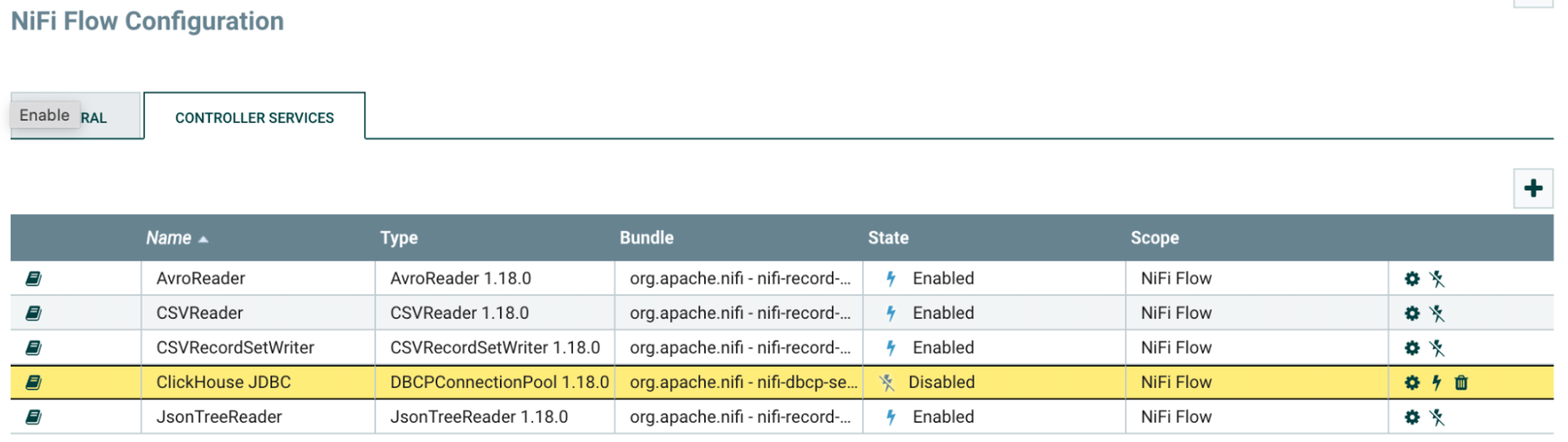
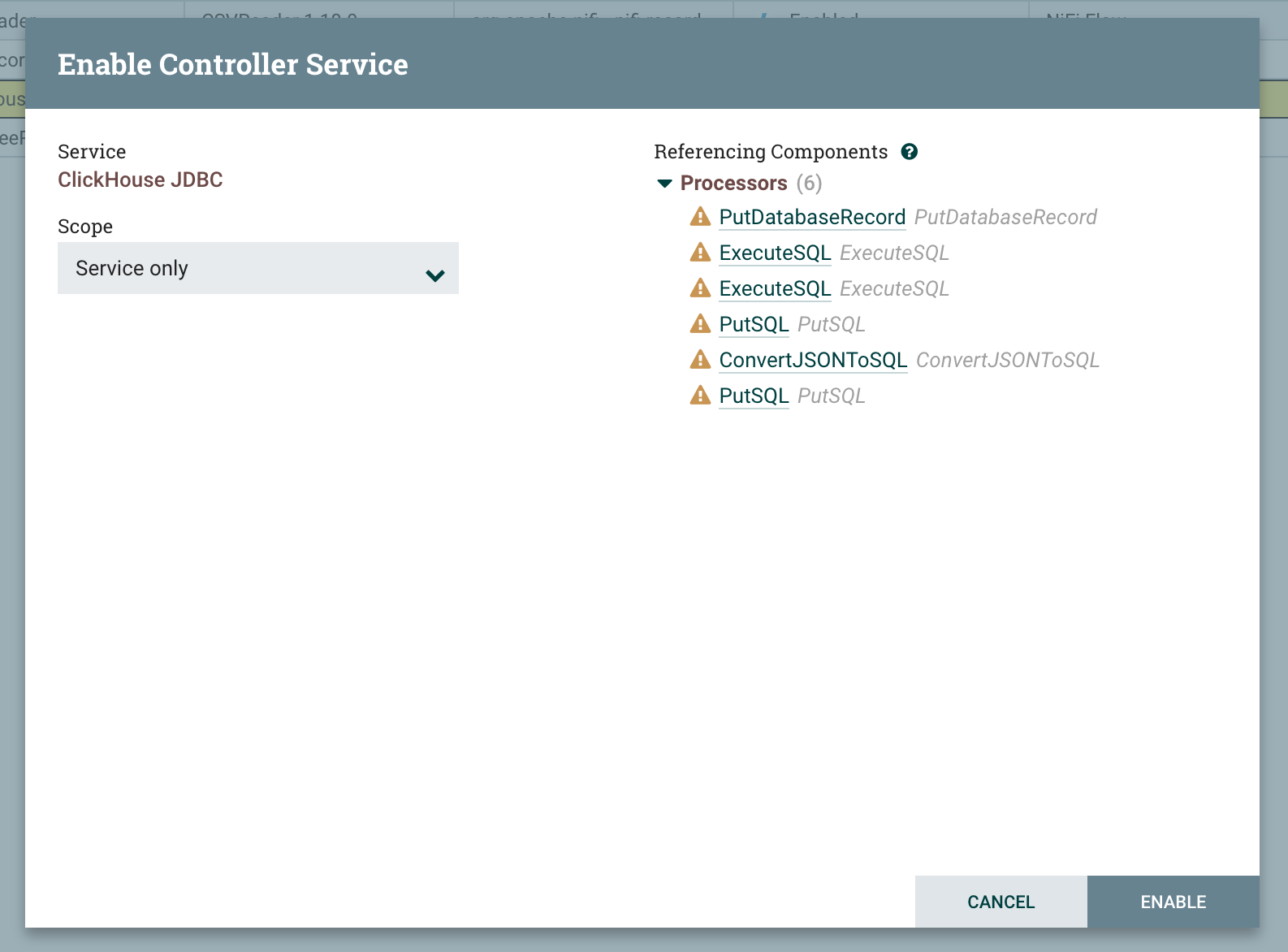
-
Controller Services 탭을 열어 Controller Service가 활성화되어 있는지 확인합니다

ExecuteSQL 프로세서를 사용하여 테이블에서 데이터 읽기
-
적절한 업스트림 및 다운스트림 프로세서와 함께
ExecuteSQL프로세서를 추가합니다
-
ExecuteSQL프로세서의 「Properties」 섹션에서 다음 값을 입력합니다.Property Value Remark Database Connection Pooling Service ClickHouse JDBC ClickHouse용으로 구성된 Controller Service를 선택하십시오 SQL select query SELECT * FROM system.metrics 여기에 쿼리를 입력하십시오 -
ExecuteSQL프로세서를 시작하십시오
-
쿼리가 성공적으로 처리되었는지 확인하려면 출력 큐에 있는
FlowFile중 하나를 확인하십시오.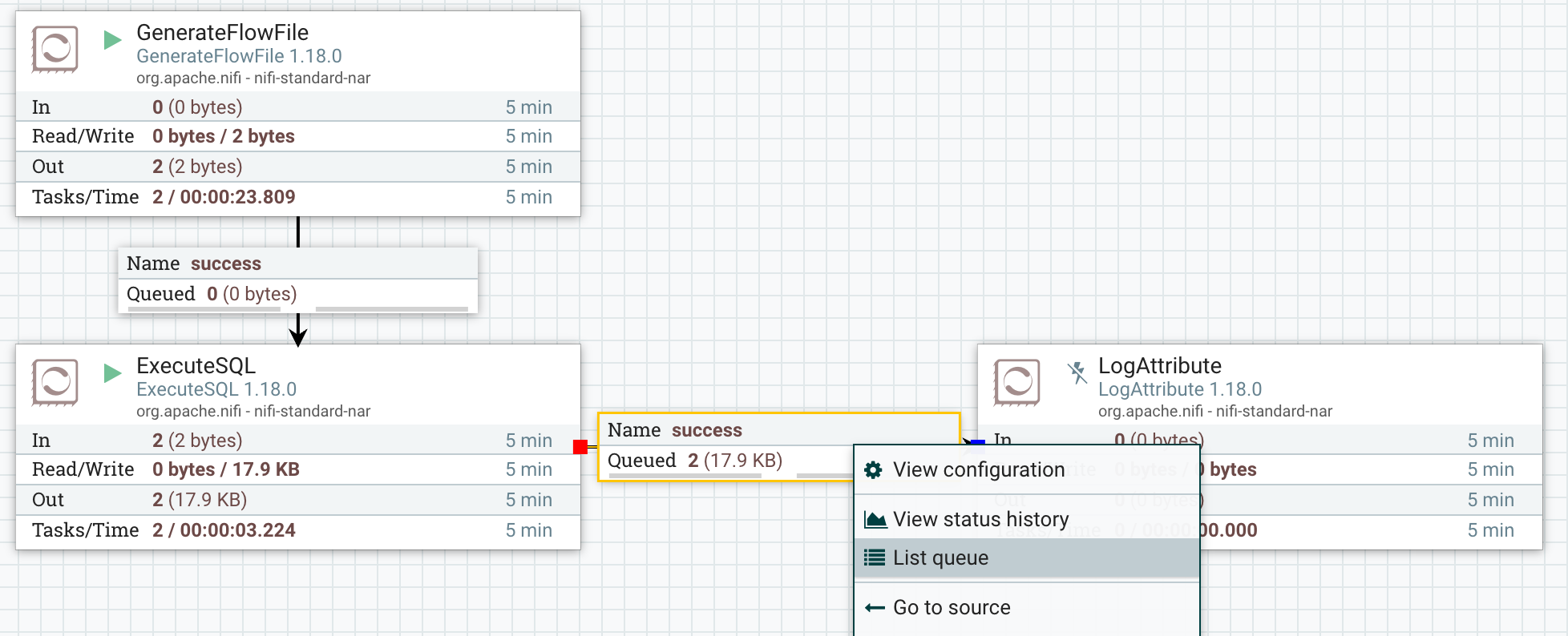
-
보기 모드를 "formatted"로 전환하여 출력된
FlowFile의 결과를 확인합니다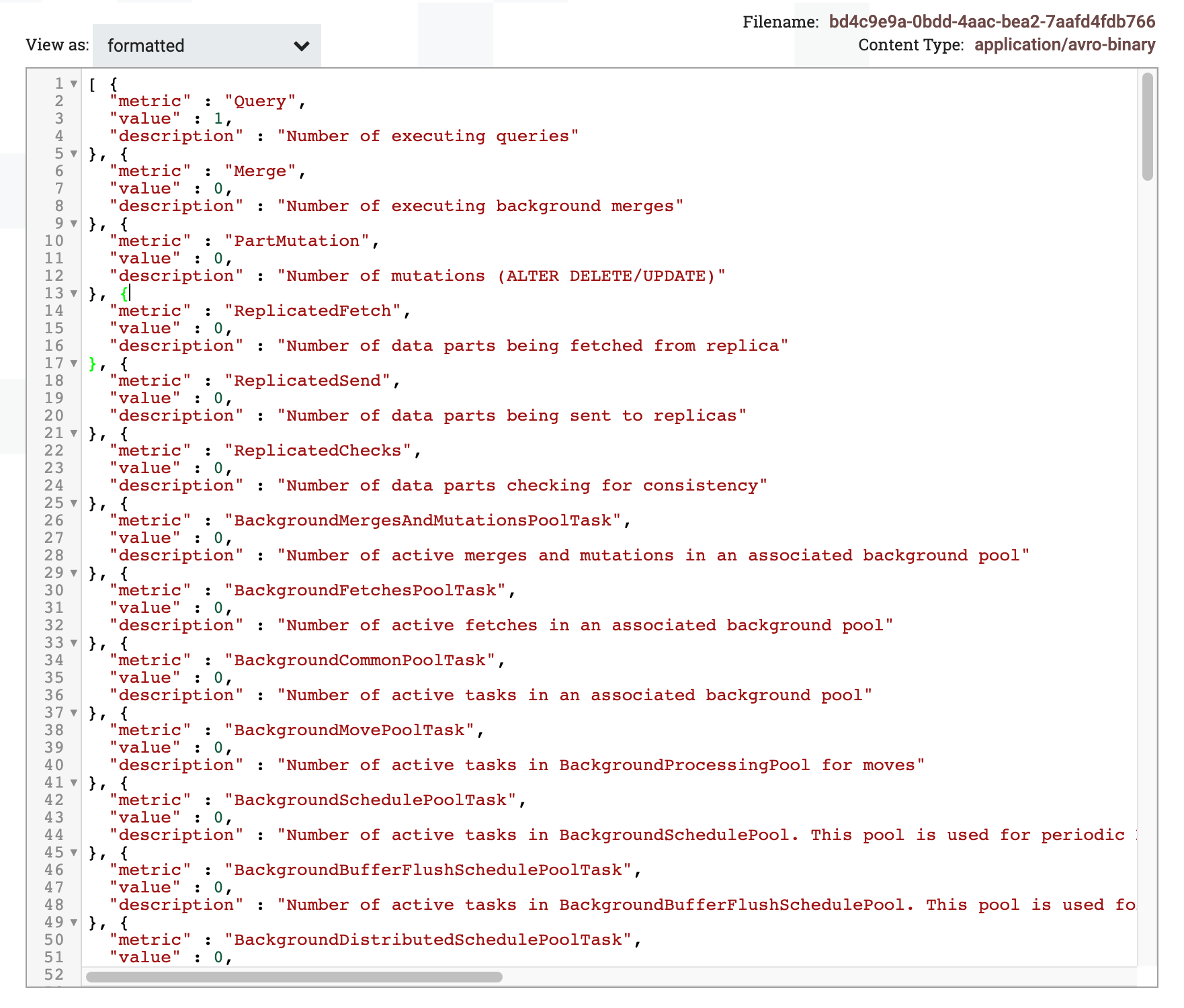
MergeRecord 및 PutDatabaseRecord 프로세서를 사용하여 테이블에 쓰기
-
단일 INSERT 문으로 여러 행을 삽입하려면, 먼저 여러 레코드를 하나의 레코드로 병합해야 합니다. 이는
MergeRecord프로세서를 사용하여 수행할 수 있습니다. -
MergeRecord프로세서의 「Properties」 섹션에서 다음 값을 입력합니다.Property Value Remark Record Reader JSONTreeReader사용할 레코드 리더를 선택합니다 Record Writer JSONReadSetWriter사용할 레코드 라이터를 선택합니다 Minimum Number of Records 1000 최소 행 수가 병합되어 하나의 레코드를 이루도록 더 큰 값으로 변경합니다. 기본값은 1행입니다 Maximum Number of Records 10000 "Minimum Number of Records"보다 더 큰 값으로 변경합니다. 기본값은 1,000행입니다 -
여러 레코드가 하나로 병합되었는지 확인하려면
MergeRecord프로세서의 입력과 출력을 확인하십시오. 출력은 여러 입력 레코드를 요소로 갖는 배열이라는 점에 유의하십시오.입력
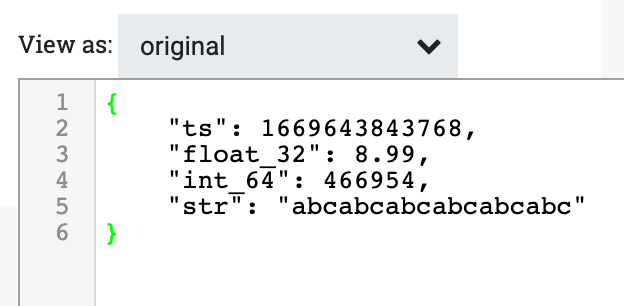
출력
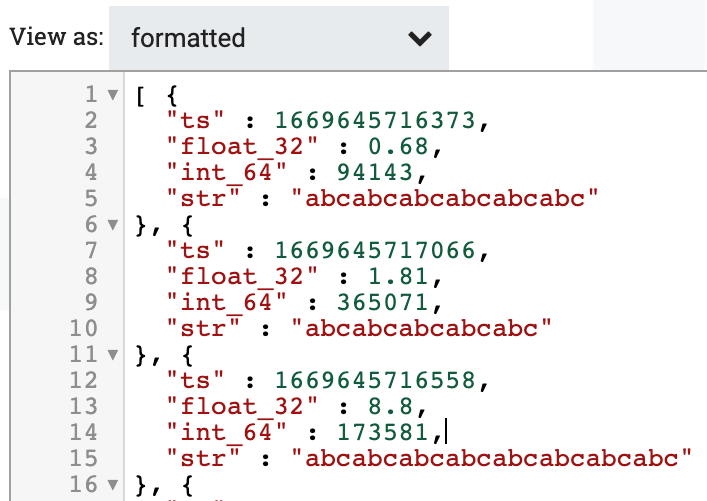
-
PutDatabaseRecord프로세서의 「Properties」 섹션에서 다음 값을 입력하십시오속성 값 비고 Record Reader JSONTreeReader적절한 record reader를 선택합니다 Database Type Generic 기본값으로 둡니다 Statement Type INSERT Database Connection Pooling Service ClickHouse JDBC ClickHouse controller service를 선택합니다 Table Name tbl 여기에서 테이블 이름을 입력합니다 Translate Field Names false 삽입되는 필드 이름이 컬럼 이름과 반드시 일치하도록 값은 "false"로 설정합니다 Maximum Batch Size 1000 삽입당 최대 행 수입니다. 이 값은 MergeRecord프로세서의 "Minimum Number of Records" 값보다 작지 않아야 합니다 -
각 insert 작업에 여러 행이 포함되는지 확인하려면, 테이블의 행 수가
MergeRecord에 정의된 「Minimum Number of Records」 값 이상씩 증가하는지 확인합니다.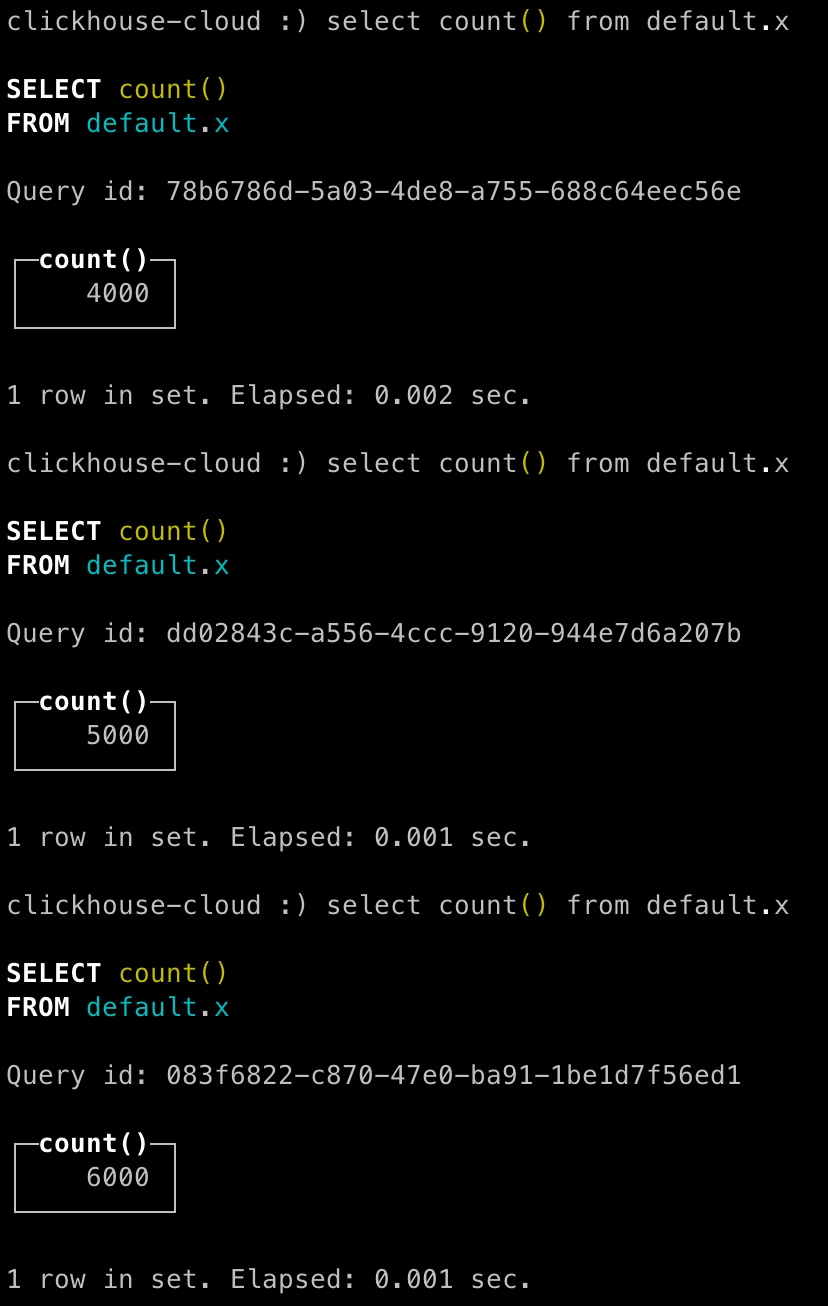
-
축하합니다! Apache NiFi를 사용하여 ClickHouse에 데이터를 성공적으로 로드했습니다!
