파트 병합
ClickHouse에서 파트 병합이란 무엇입니까?
ClickHouse는 쿼리뿐만 아니라 삽입에도 매우 빠르게 동작합니다. 이는 저장 계층 덕분이며, 이 계층은 LSM 트리와 유사하게 동작합니다:
① (MergeTree 엔진 계열의) 테이블에 대한 삽입은 정렬된, 불변의 데이터 파트를 생성합니다.
② 모든 데이터 처리는 백그라운드 파트 병합으로 오프로드됩니다.
이는 데이터 쓰기 작업을 가볍게 하고 매우 효율적이 되게 합니다.
테이블당 ^^파트^^ 개수를 제어하고 위의 ②를 구현하기 위해, ClickHouse는 백그라운드에서 파티션별로 더 작은 ^^파트^^를 계속해서 더 큰 파트로 병합하며, 이 파트들이 압축된 크기가 대략 ~150 GB에 도달할 때까지 진행합니다.
다음 다이어그램은 이 백그라운드 병합 프로세스를 개략적으로 보여 줍니다:
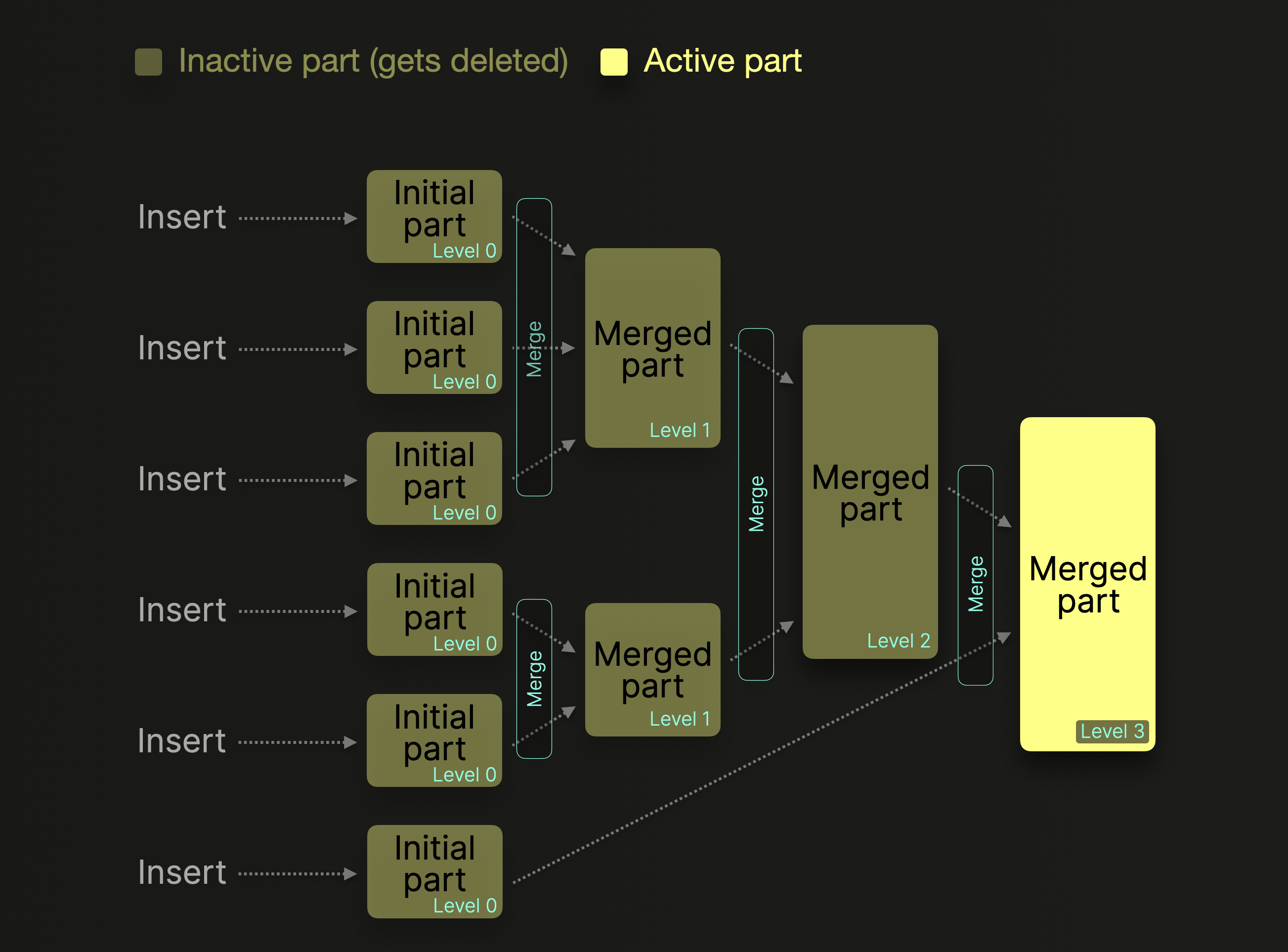
하나의 파트에 대해 병합이 한 번 수행될 때마다 해당 파트의 merge level은 1씩 증가합니다. 0 레벨은 해당 파트가 새로 생성되었고 아직 병합되지 않았음을 의미합니다. 더 큰 ^^파트^^로 병합된 ^^파트^^는 비활성 상태로 표시되며, 이후 구성 가능한 시간(기본값 8분)이 지나면 최종적으로 삭제됩니다. 시간이 지나면서 이렇게 병합된 ^^파트^^로 구성된 트리가 만들어집니다. 이 때문에 MergeTree 테이블이라는 이름이 붙었습니다.
머지 모니터링
테이블 파트란 무엇인가 예제에서 ClickHouse가 parts 시스템 테이블에서 모든 테이블 ^^파트^^를 추적함을 보였습니다. 예제 테이블의 활성 파트마다 머지 레벨과 저장된 행 수를 조회하기 위해 다음 쿼리를 사용했습니다:
앞에서 설명한 쿼리 결과는 예제 테이블에 활성 ^^파트^^가 네 개 있으며, 각각은 처음에 삽입된 ^^파트^^를 한 번 병합해 생성된 것임을 보여 줍니다.
이제 쿼리를 실행하면, 네 개의 ^^parts^^가 병합되어 하나의 최종 파트가 되었음을 확인할 수 있습니다(테이블에 추가 insert가 발생하지 않은 경우).
ClickHouse 24.10에서는 기본 제공 모니터링 대시보드에 새로운 merges 대시보드가 추가되었습니다. OSS 및 Cloud에서 모두 /merges HTTP 핸들러를 통해 제공되며, 이를 사용하여 예제 테이블에서 발생하는 모든 파트 병합을 시각화할 수 있습니다:
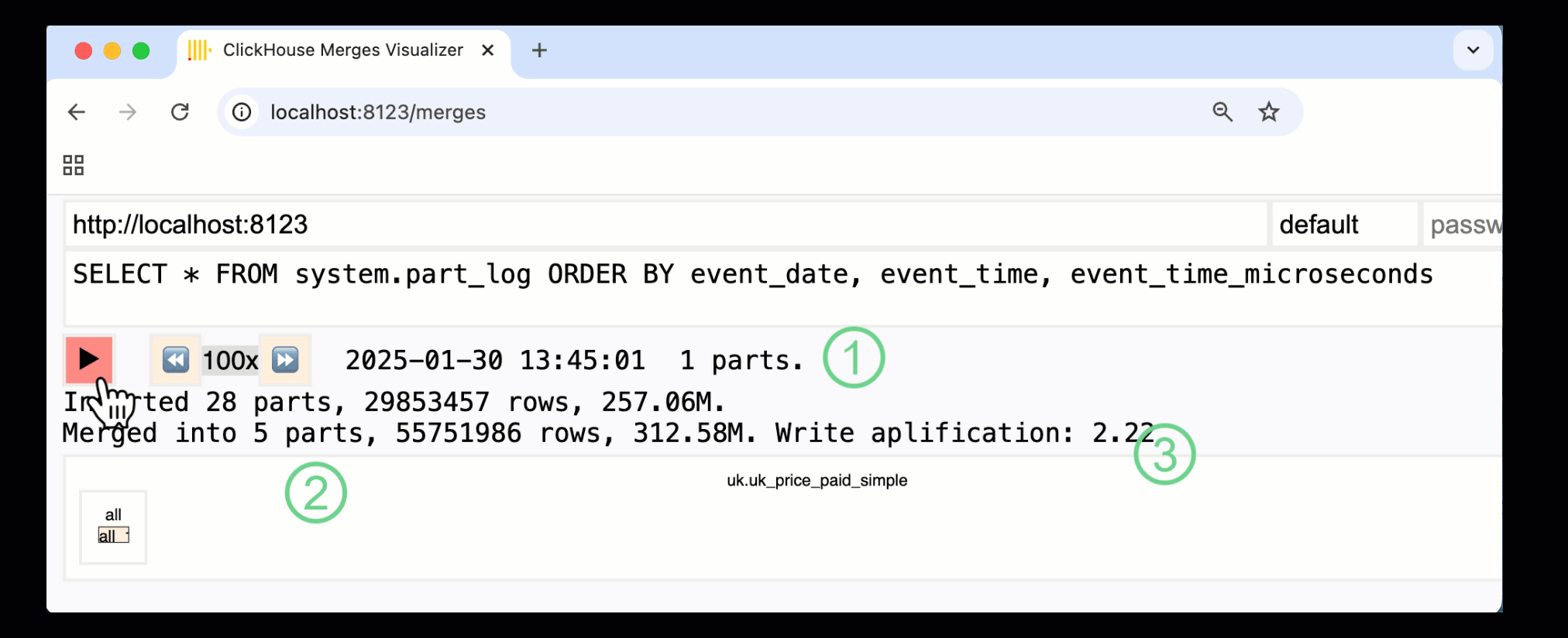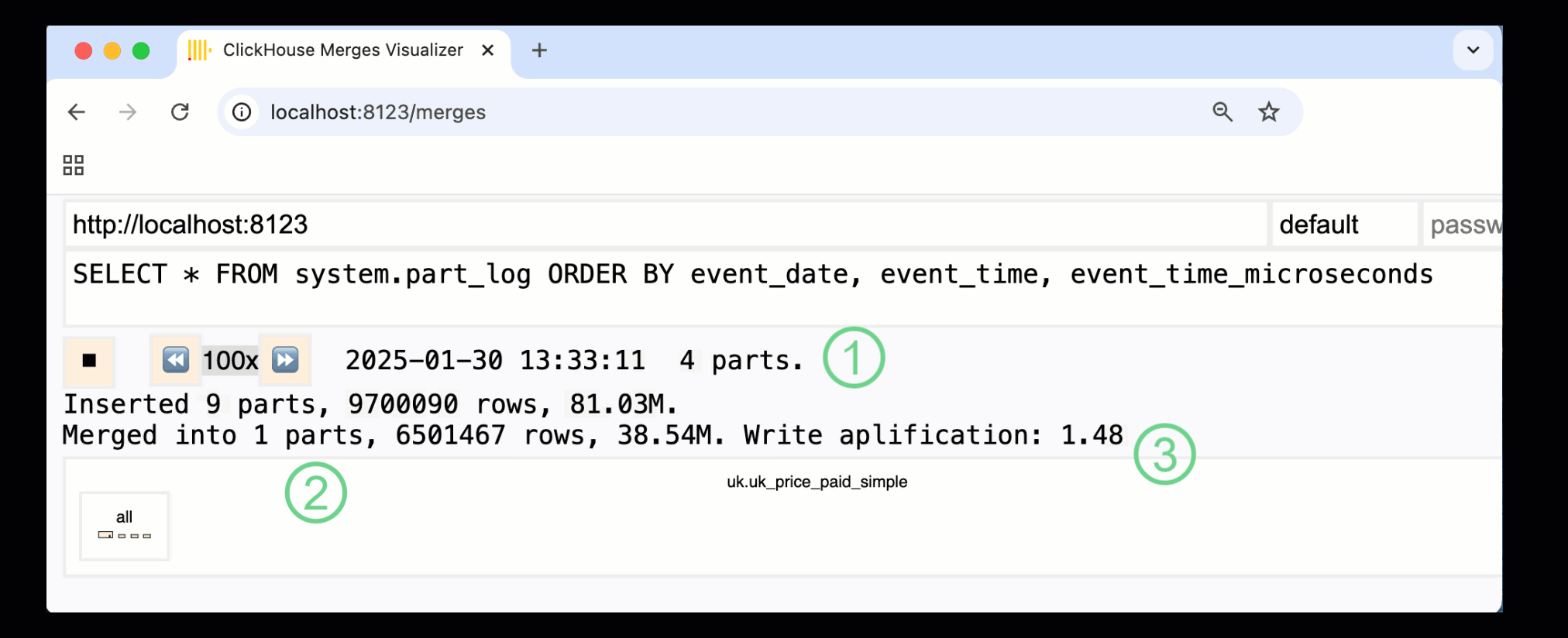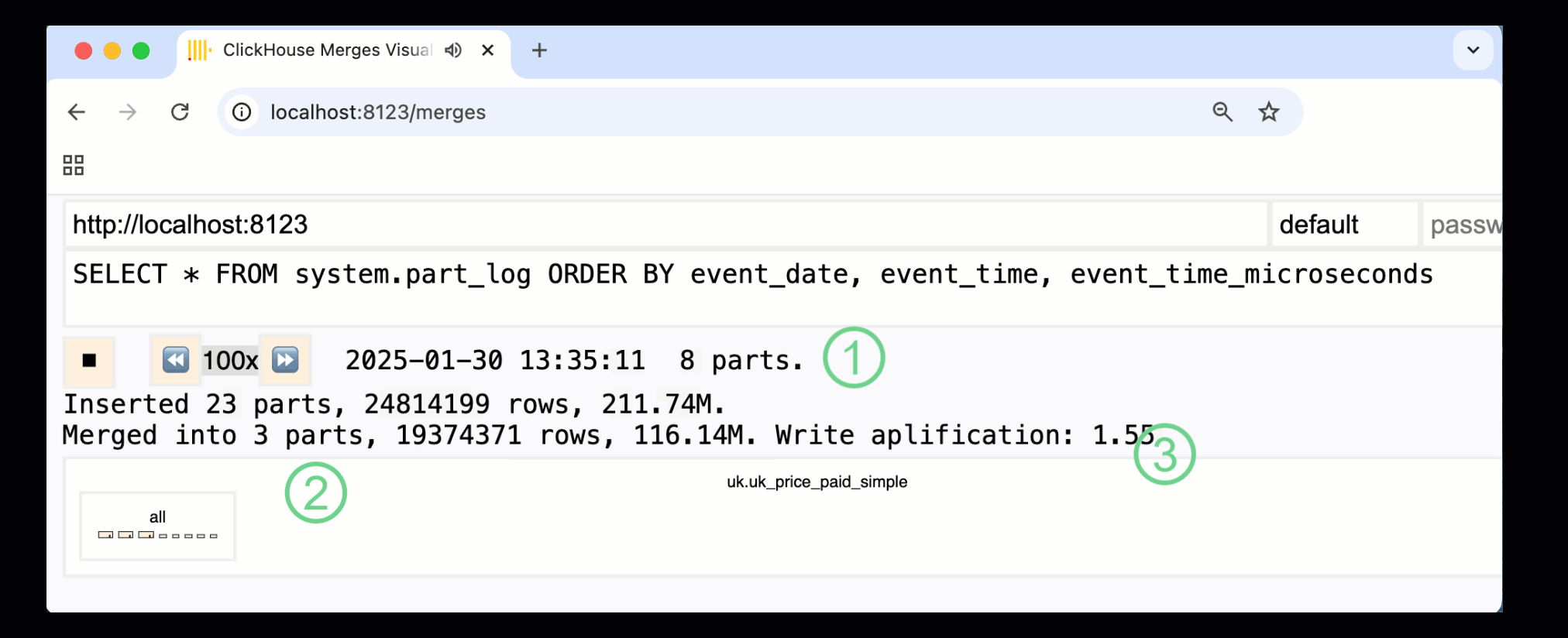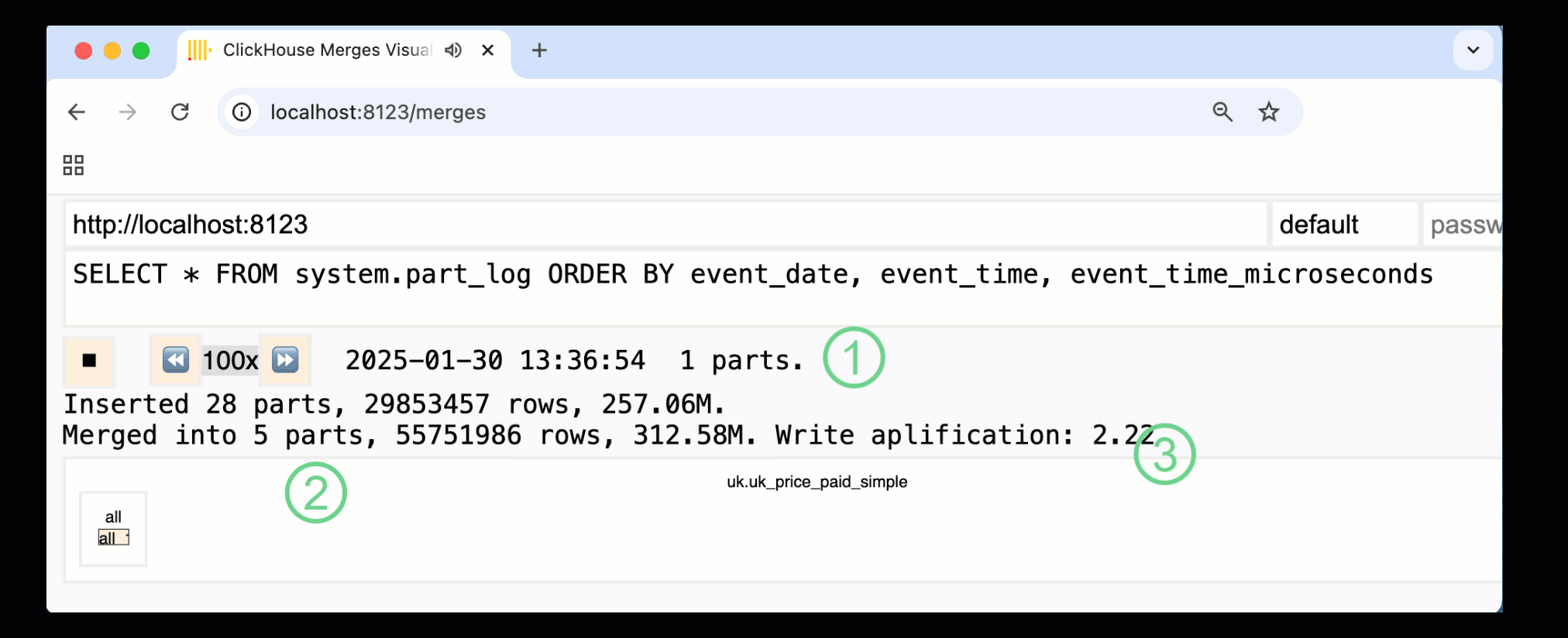
위에 표시된 대시보드는 초기 데이터 삽입부터 단일 파트로의 최종 병합까지 전체 과정을 보여 줍니다:
① 활성 ^^parts^^ 수.
② 상자로 시각적으로 표현된 파트 병합(크기는 파트 크기를 반영).
동시 병합
단일 ClickHouse 서버는 여러 백그라운드 병합 스레드를 사용하여 동시 파트 병합을 수행합니다:
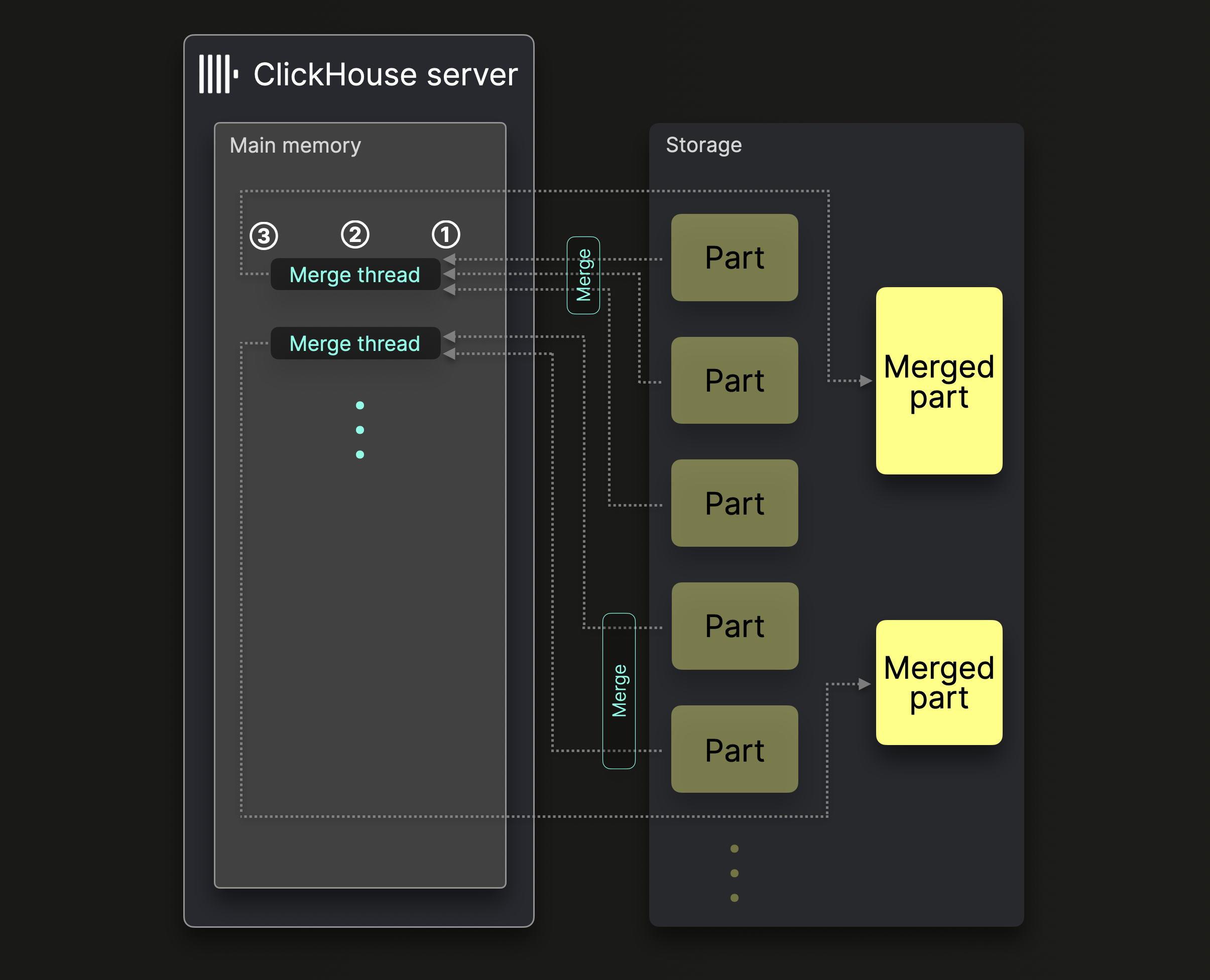
각 병합 스레드는 다음과 같은 루프를 실행합니다:
① 다음에 병합할 ^^파트^^를 결정하고, 해당 ^^파트^^를 메모리에 적재합니다.
② 메모리에서 ^^파트^^를 병합하여 더 큰 파트로 만듭니다.
③ 병합된 파트를 디스크에 기록합니다.
① 단계로 돌아갑니다.
CPU 코어 수와 RAM 용량을 늘리면 백그라운드 병합 처리량을 높일 수 있습니다.
메모리 최적화 머지
ClickHouse는 이전 예시에 개략적으로 나타난 것처럼, 머지 대상인 모든 ^^parts^^를 한 번에 메모리에 적재하지는 않습니다. 여러 요인에 따라, 그리고 메모리 사용량을 줄이기 위해(머지 속도를 희생하면서), 이른바 vertical merging은 한 번에 모두 처리하는 대신 블록의 청크 단위로 ^^parts^^를 적재하고 머지합니다.
병합 메커니즘
아래 다이어그램은 ClickHouse에서 단일 백그라운드 merge thread가 ^^파트^^를 병합하는 방식을 보여줍니다(기본적으로 vertical merging 없이 수행됨):
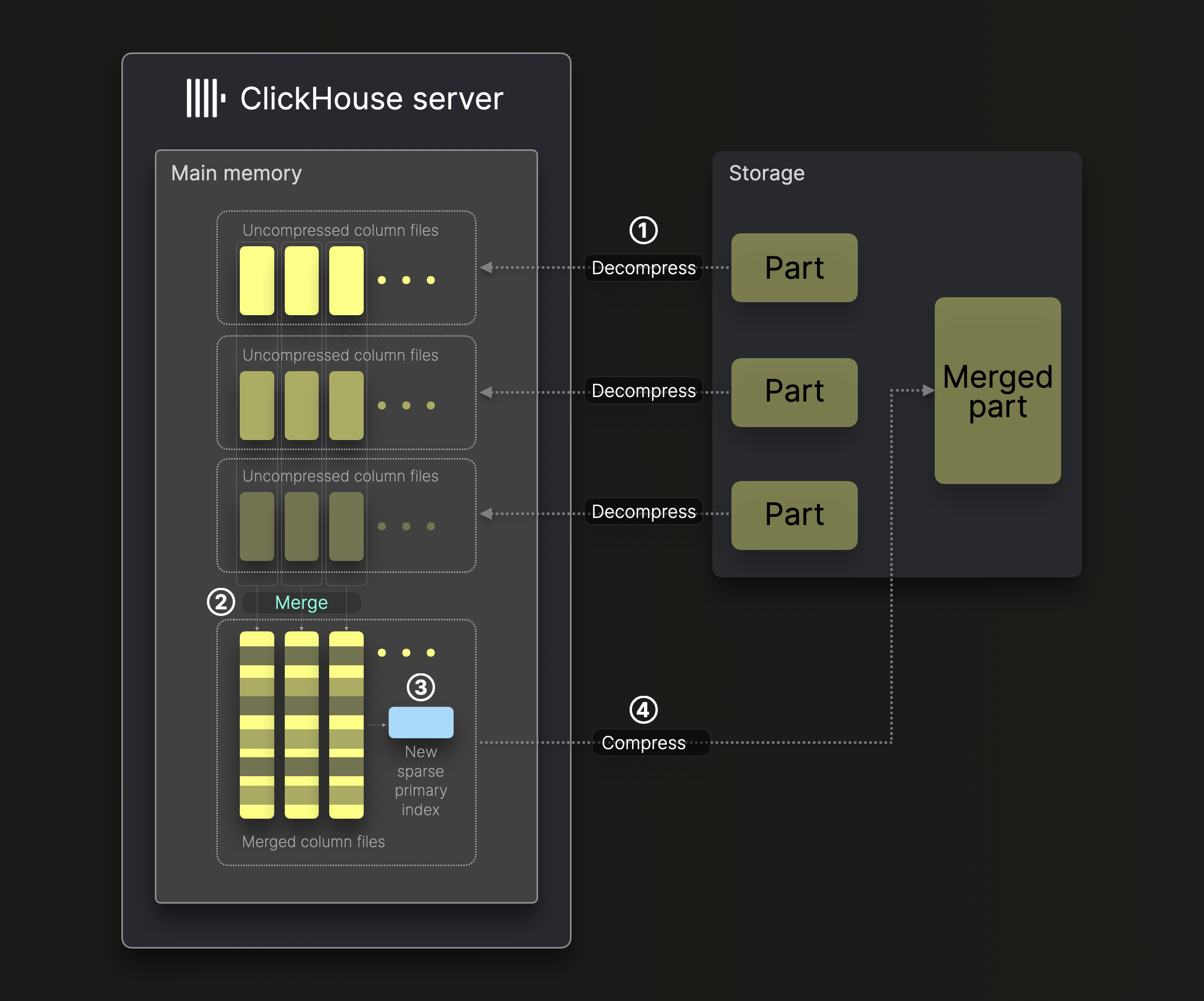
파트 병합은 다음과 같은 여러 단계로 수행됩니다:
① 압축 해제 및 로딩: 병합 대상 ^^파트^^의 압축된 바이너리 컬럼 파일의 압축을 해제해 메모리에 로드합니다.
② 병합(Merging): 데이터를 더 큰 컬럼 파일로 병합합니다.
③ 인덱싱(Indexing): 병합된 컬럼 파일에 대해 새로운 희소 기본 인덱스를 생성합니다.
④ 압축 및 저장(Compression & Storage): 새로운 컬럼 파일과 인덱스를 압축하고, 병합된 데이터 파트를 나타내는 새로운 디렉터리에 저장합니다.
보조 데이터 스키핑 인덱스, 컬럼 통계, 체크섬, min-max 인덱스와 같은 데이터 파트의 추가 메타데이터도 병합된 컬럼 파일을 기반으로 다시 생성됩니다. 단순화를 위해 이러한 세부 내용은 생략했습니다.
② 단계의 동작 방식은 사용 중인 특정 MergeTree 엔진에 따라 달라지며, 엔진마다 병합을 처리하는 방식이 다릅니다. 예를 들어, 행이 집계되거나, 오래된 경우 대체될 수 있습니다. 앞에서 언급했듯이 이 접근 방식은 모든 데이터 처리 작업을 백그라운드 병합으로 넘겨, 쓰기 작업을 가볍고 효율적으로 유지함으로써 매우 빠른 insert 작업을 가능하게 합니다.
다음으로 ^^MergeTree^^ 패밀리에 속한 특정 엔진의 병합 메커니즘을 간략히 살펴보겠습니다.
표준 병합
아래 다이어그램은 표준 MergeTree 테이블에서 ^^파트^^가 어떻게 병합되는지 보여 줍니다:
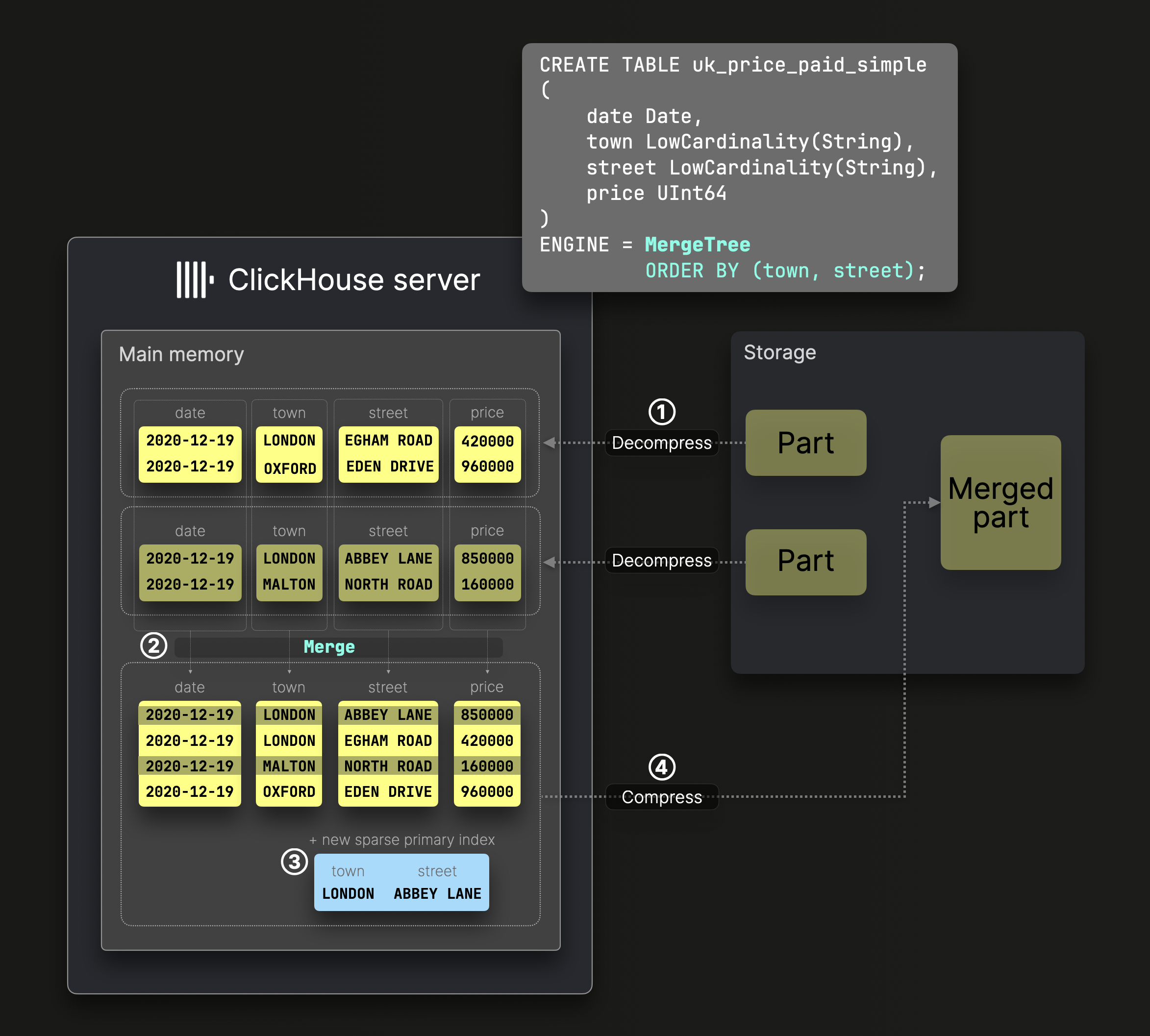
위 다이어그램의 DDL 문은 ^^정렬 키^^ (town, street)를 가진 MergeTree 테이블을 생성하며, 이는 디스크의 데이터가 이 컬럼들로 정렬되고 그에 따라 희소 기본 키 인덱스가 생성된다는 의미입니다.
① 압축 해제되고 사전 정렬된 테이블 컬럼들이 테이블의 ^^정렬 키^^로 정의된 전역 정렬 순서를 유지한 채 ② 병합되고, ③ 새로운 희소 기본 키 인덱스가 생성되며, ④ 병합된 컬럼 파일과 인덱스가 압축되어 디스크에 새로운 데이터 파트로 저장됩니다.
Replacing 병합
ReplacingMergeTree 테이블에서의 파트 병합은 표준 병합과 비슷하게 동작하지만, 각 행의 가장 최신 버전만 유지하고 이전 버전은 삭제됩니다:
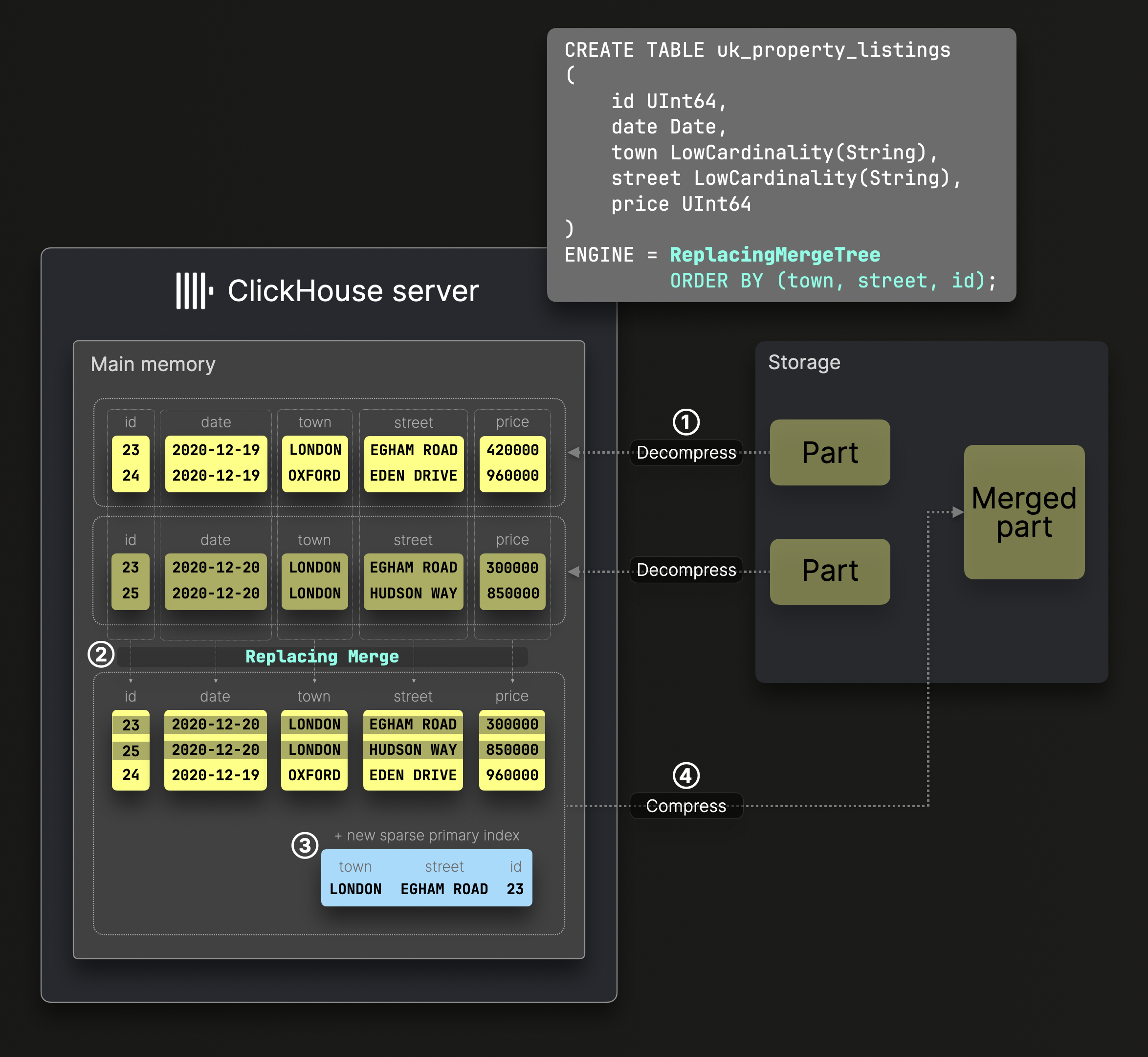
위 다이어그램의 DDL 문장은 ^^정렬 키^^ (town, street, id)를 사용하는 ReplacingMergeTree 테이블을 생성하며, 이는 디스크의 데이터가 이 컬럼들로 정렬되고, 이에 따라 희소 기본 인덱스가 생성된다는 의미입니다.
② 병합 과정은 표준 MergeTree 테이블과 유사하게 동작하여, 전역 정렬 순서를 유지하면서 압축 해제된 사전 정렬 컬럼들을 결합합니다.
그러나 ReplacingMergeTree는 동일한 ^^정렬 키^^를 가진 중복 행을 제거하고, 해당 파트의 생성 타임스탬프를 기준으로 가장 최신 행만 유지합니다.
Summing merges
숫자 데이터는 SummingMergeTree 테이블에서 ^^파트^^가 병합될 때 자동으로 집계됩니다:
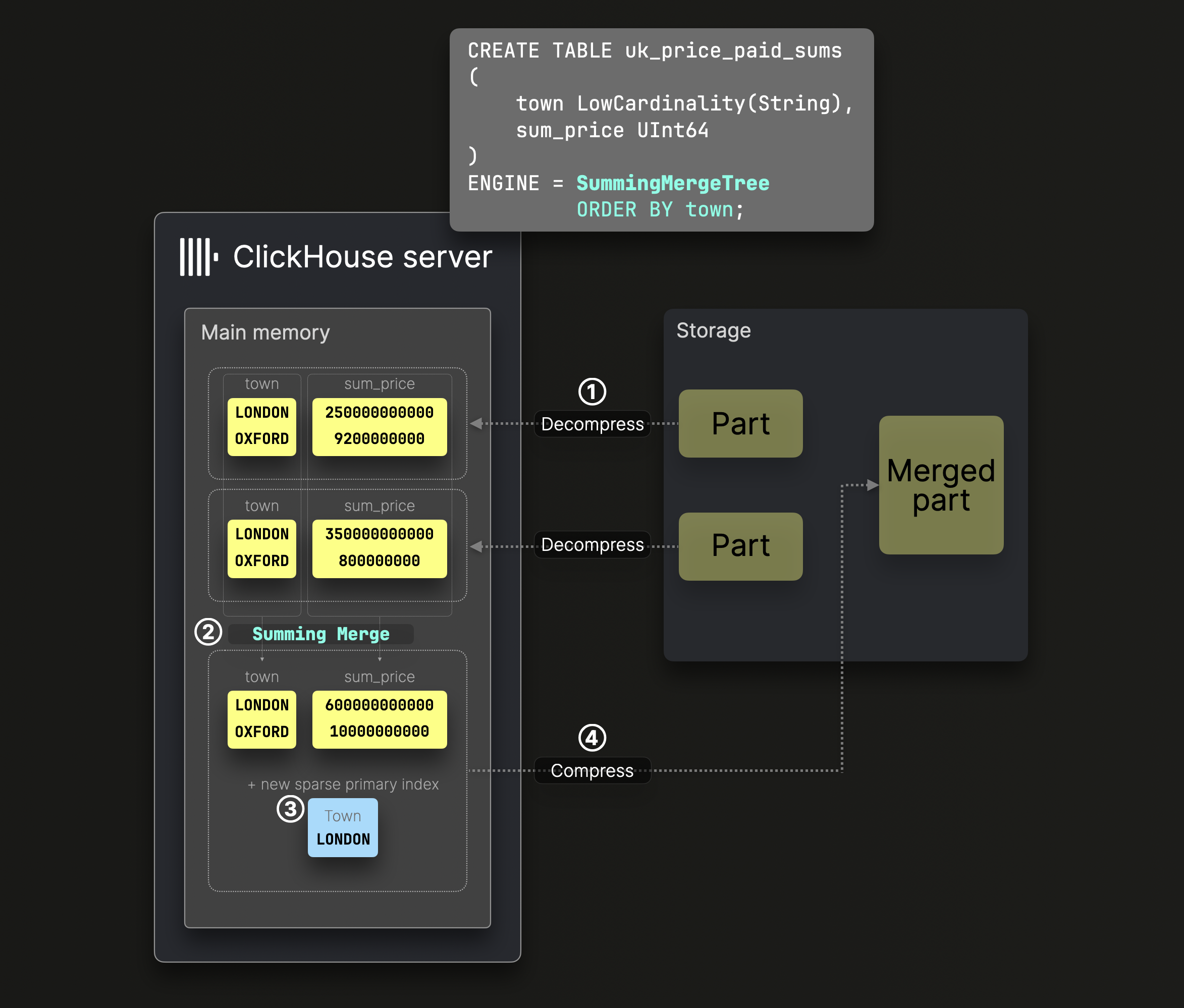
위 다이어그램의 DDL 문은 ^^정렬 키^^가 town인 SummingMergeTree 테이블을 정의합니다. 이는 디스크의 데이터가 이 컬럼을 기준으로 정렬되며, 그에 따라 희소 기본 인덱스가 생성된다는 의미입니다.
② 병합 단계에서 ClickHouse는 같은 ^^정렬 키^^를 가진 모든 행을 하나의 행으로 대체하고, 숫자형 컬럼 값들을 합산합니다.
Aggregating merges
위에서 사용한 SummingMergeTree 테이블 예시는 AggregatingMergeTree 테이블의 특수한 변형으로, 파트 병합 동안 90개가 넘는 집계 함수 가운데 어떤 것이든 적용하여 자동 증분 데이터 변환을 수행할 수 있습니다:
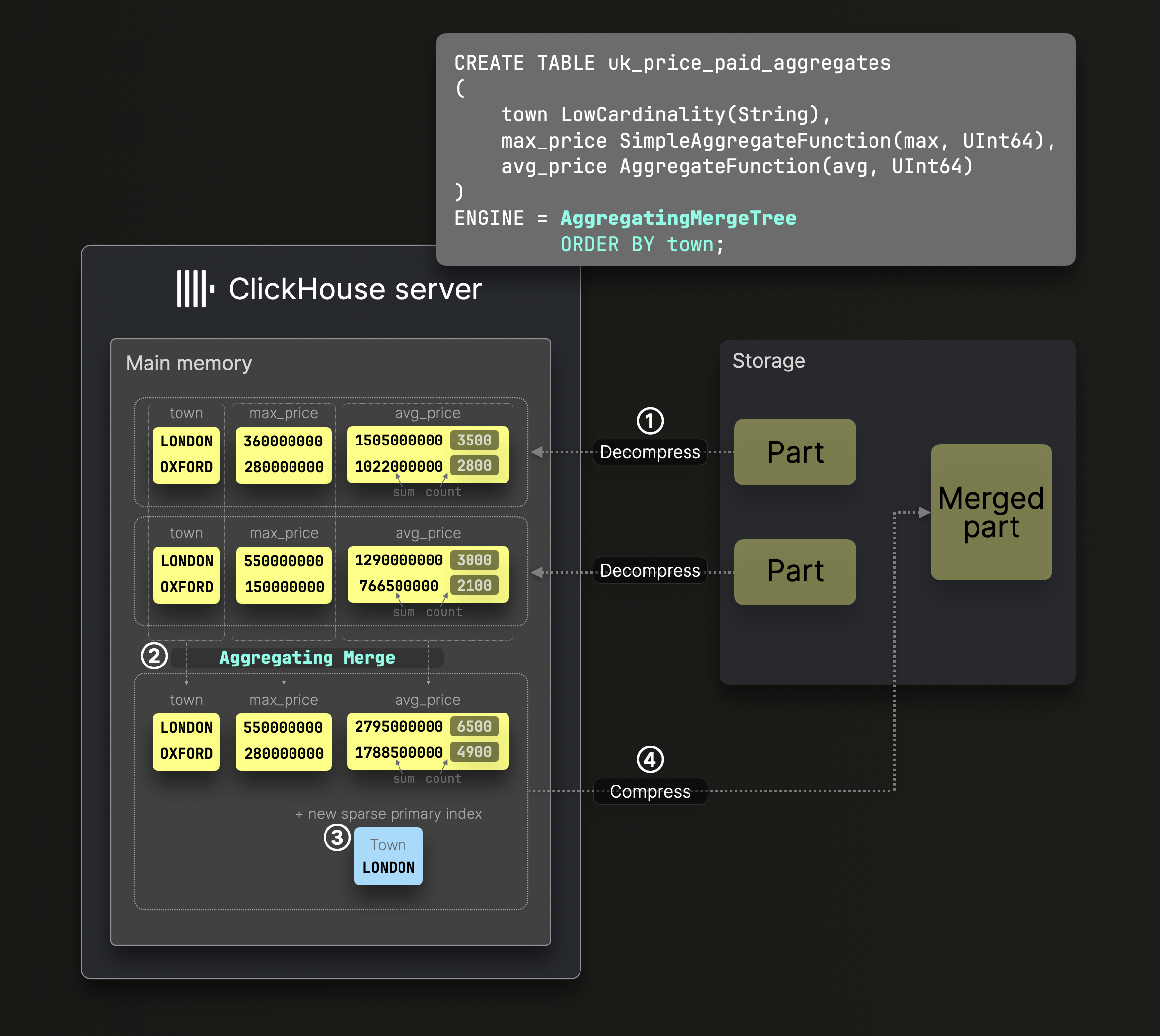
위 다이어그램의 DDL 문은 town을 ^^정렬 키(sorting key)^^로 사용하는 AggregatingMergeTree 테이블을 생성하고, 디스크에서 데이터가 이 컬럼을 기준으로 정렬되도록 하며, 그에 대응하는 희소 기본 인덱스가 생성되도록 합니다.
② 병합 동안 ClickHouse는 동일한 ^^정렬 키(sorting key)^^를 가진 모든 행을 하나의 행으로 대체하고, 그 안에 부분 집계 상태(예: avg()를 위한 sum과 count)를 저장합니다. 이러한 상태를 통해 배경에서 수행되는 증분 파트 병합 시에도 정확한 결과가 보장됩니다.
