Amazon Redshift에서 ClickHouse로 마이그레이션하는 가이드
소개
Amazon Redshift는 Amazon Web Services 제품군에 속한 널리 사용되는 클라우드 데이터 웨어하우징 솔루션입니다. 이 가이드는 Redshift 인스턴스에서 ClickHouse로 데이터를 마이그레이션하는 다양한 접근 방식을 제시합니다. 여기에서는 세 가지 옵션을 다룹니다:
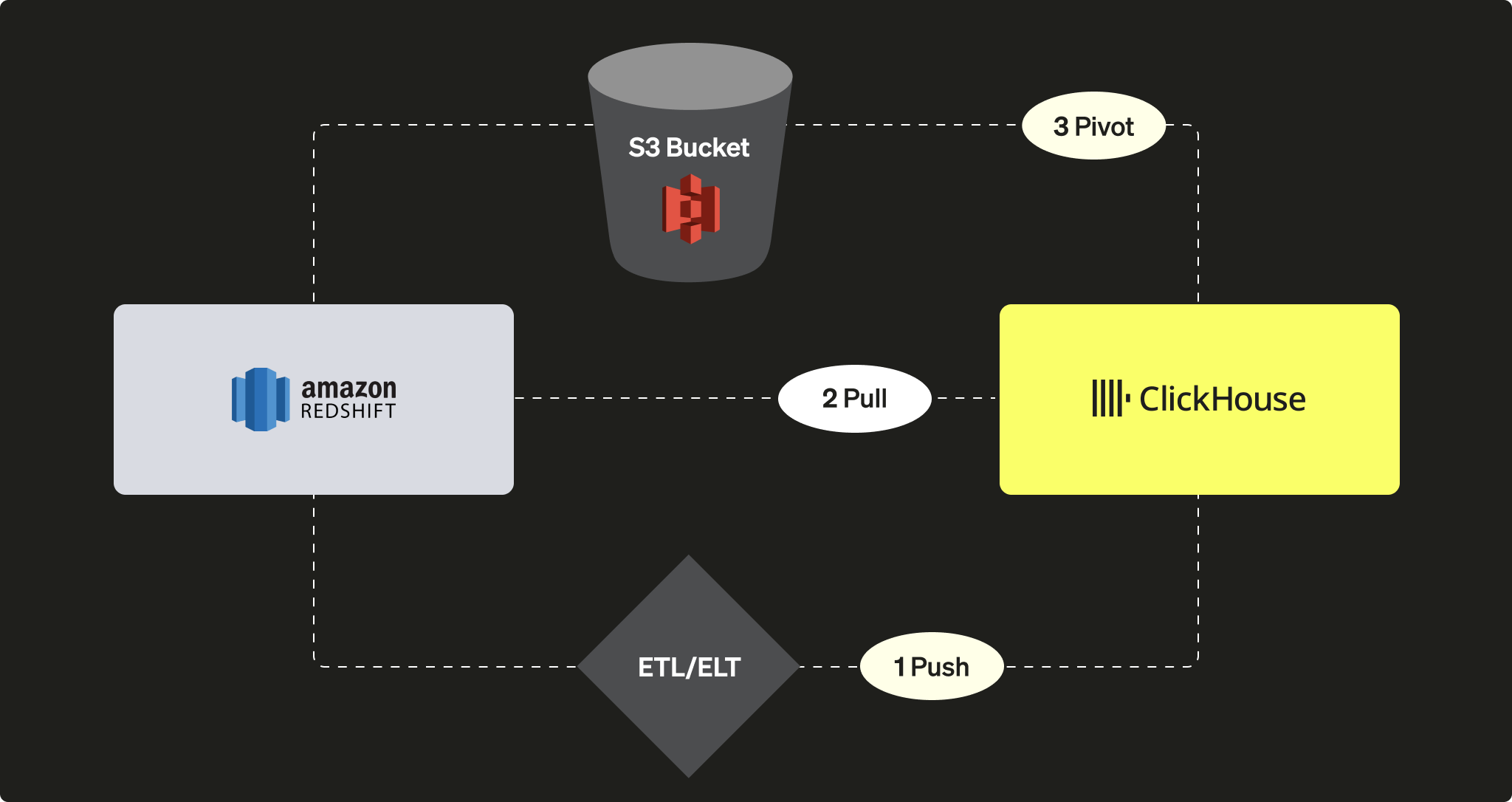
ClickHouse 인스턴스 관점에서 보면 다음과 같은 방식으로 수행할 수 있습니다:
-
서드파티 ETL/ELT 도구 또는 서비스를 사용하여 ClickHouse로 데이터를 PUSH 하는 방식
-
ClickHouse JDBC Bridge를 활용하여 Redshift에서 데이터를 PULL 해 오는 방식
-
S3 객체 스토리지를 활용해 "언로드 후 로드(Unload then load)" 로직을 사용하는 PIVOT 방식
이 튜토리얼에서는 데이터 소스로 Redshift를 사용했습니다. 그러나 여기에서 제시하는 마이그레이션 방식은 Redshift에만 국한되지 않으며, 호환되는 다른 데이터 소스에도 유사한 단계를 적용할 수 있습니다.
Redshift에서 ClickHouse로 데이터 Push
PUSH 시나리오에서는 타사 도구나 서비스(사용자 정의 코드 또는 ETL/ELT)를 활용하여 데이터를 ClickHouse 인스턴스로 전송합니다. 예를 들어 Airbyte와 같은 소프트웨어를 사용하여 Redshift 인스턴스(소스)에서 ClickHouse 인스턴스(대상)로 데이터를 전송할 수 있습니다(Airbyte 연동 가이드를 참조하십시오).

Pros
- 기존 ETL/ELT 소프트웨어의 커넥터 카탈로그를 그대로 활용할 수 있습니다.
- 데이터 동기화를 위한 기능(append/overwrite/increment 로직)이 내장되어 있습니다.
- 데이터 변환 시나리오를 구현할 수 있습니다(예: dbt 연동 가이드 참조).
단점
- ETL/ELT 인프라를 구축하고 유지 관리해야 합니다.
- 아키텍처에 서드파티 구성 요소가 도입되어 확장성 측면에서 잠재적인 병목 요인이 될 수 있습니다.
Redshift에서 ClickHouse로 데이터 끌어오기
이 끌어오기 시나리오에서는 ClickHouse 인스턴스에서 Redshift 클러스터에 직접 연결하기 위해 ClickHouse JDBC Bridge를 활용하고, INSERT INTO ... SELECT 쿼리를 수행합니다.

장점
- 모든 JDBC 호환 도구에서 범용적으로 사용할 수 있습니다.
- ClickHouse 내에서 여러 외부 데이터 소스를 쿼리할 수 있게 해 주는 세련된 솔루션입니다.
단점
- 확장성 측면에서 병목 지점이 될 수 있는 ClickHouse JDBC Bridge 인스턴스가 필요합니다.
Redshift는 PostgreSQL을 기반으로 하지만, ClickHouse에서는 PostgreSQL 테이블 함수나 테이블 엔진을 사용할 수 없습니다. ClickHouse는 PostgreSQL 9 이상을 요구하는 반면, Redshift API는 더 낮은 버전(8.x)을 기반으로 하기 때문입니다.
튜토리얼
이 옵션을 사용하려면 ClickHouse JDBC Bridge를 설정해야 합니다. ClickHouse JDBC Bridge는 JDBC 연결을 처리하고 ClickHouse 인스턴스와 데이터 소스 사이에서 프록시 역할을 하는 독립 실행형 Java 애플리케이션입니다. 이 튜토리얼에서는 샘플 데이터베이스에 데이터가 미리 채워진 Redshift 인스턴스를 사용합니다.
ClickHouse JDBC Bridge 배포
ClickHouse JDBC Bridge를 배포합니다. 자세한 내용은 JDBC for External Data sources 사용자 가이드를 참고하십시오.
ClickHouse Cloud를 사용하는 경우 별도의 환경에서 ClickHouse JDBC Bridge를 실행한 후 remoteSecure 함수를 사용하여 ClickHouse Cloud에 연결해야 합니다.
Redshift 데이터 소스 구성
ClickHouse JDBC Bridge용 Redshift 데이터 소스를 구성합니다. 예를 들어 /etc/clickhouse-jdbc-bridge/config/datasources/redshift.json 파일을 사용할 수 있습니다.
ClickHouse에서 Redshift 인스턴스 쿼리하기
ClickHouse JDBC Bridge가 배포되어 실행 중이면 ClickHouse에서 Redshift 인스턴스를 대상으로 쿼리를 실행할 수 있습니다.
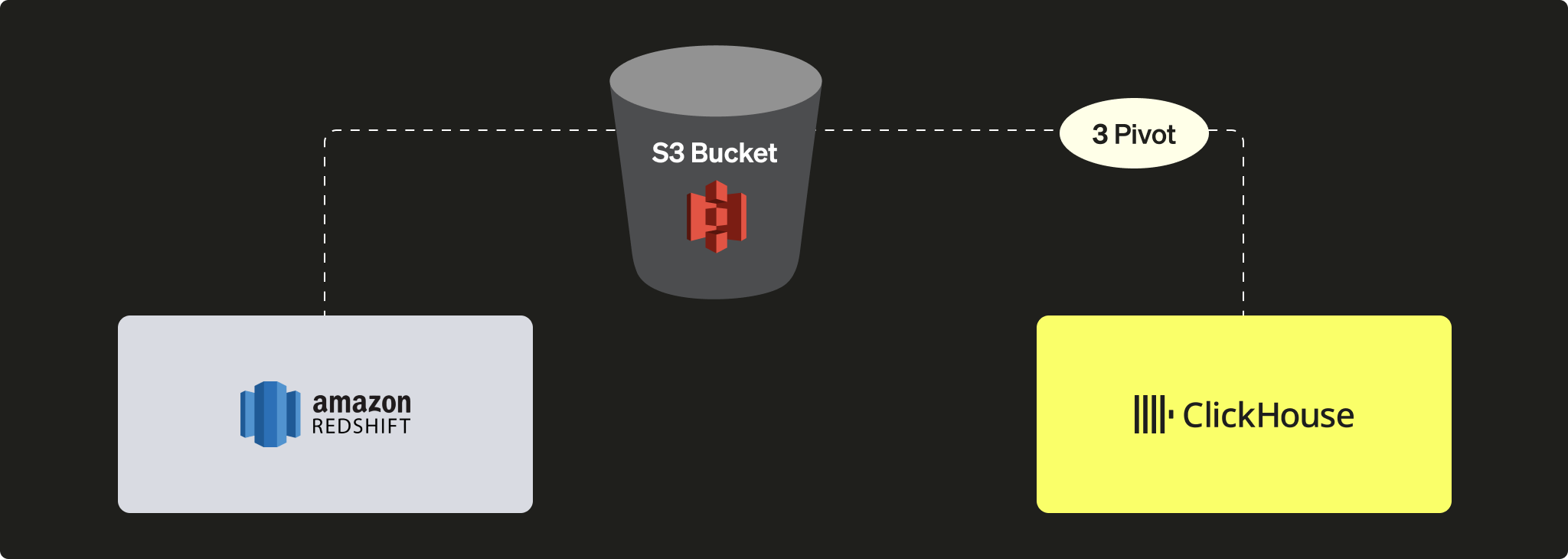
S3를 사용하여 Redshift 데이터를 ClickHouse로 피벗하기
이 시나리오에서는 중간 피벗 형식으로 데이터를 S3로 내보낸 뒤, 다음 단계에서 S3의 데이터를 ClickHouse로 로드합니다.
장점
- Redshift와 ClickHouse 모두 강력한 S3 통합 기능을 제공합니다.
- Redshift의
UNLOAD명령과 ClickHouse의 S3 테이블 함수 / 테이블 엔진 등 기존 기능을 활용합니다. - ClickHouse에서 S3로부터의 / S3로의 병렬 읽기와 높은 처리량 덕분에 매끄럽게 확장할 수 있습니다.
- Apache Parquet과 같은 고급 압축 포맷을 활용할 수 있습니다.
단점
- 프로세스가 두 단계로 이루어져 있습니다(Redshift에서 데이터를 언로드한 뒤 ClickHouse로 로드해야 합니다).
튜토리얼
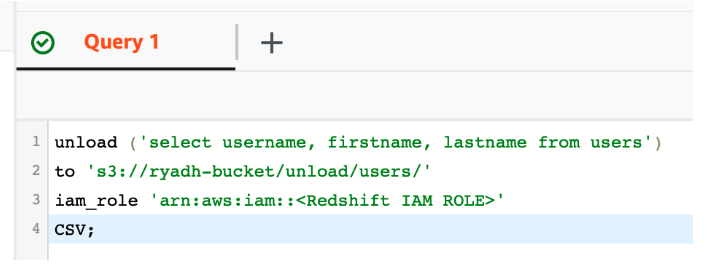

ClickHouse에 테이블 생성
ClickHouse에 테이블을 생성합니다:
또는, ClickHouse에서 CREATE TABLE ... EMPTY AS SELECT를 사용해 테이블 구조를 자동으로 추론하도록 할 수도 있습니다:
이는 Parquet처럼 데이터 타입 정보가 포함된 형식의 데이터를 사용할 때 특히 효과적입니다.
S3 파일을 ClickHouse로 적재
INSERT INTO ... SELECT 구문을 사용하여 S3 파일을 ClickHouse로 적재합니다:
이 예제에서는 피벗 포맷(pivot format)으로 CSV를 사용했습니다. 그러나 운영 환경에서의 대규모 마이그레이션 워크로드에는 Apache Parquet을 가장 좋은 옵션으로 권장하며, 압축을 지원하여 스토리지 비용을 절감하고 전송 시간을 줄일 수 있습니다. (기본적으로 각 row group은 SNAPPY로 압축됩니다.) 또한 ClickHouse는 Parquet의 컬럼 지향 특성을 활용하여 데이터 수집 속도를 높입니다.
