관측성을 위한 ClickHouse 활용
소개
이 가이드는 ClickHouse를 사용해 SQL 기반 관측성(Observability) 솔루션을 직접 구축하려는 사용자를 대상으로 하며, 특히 로그와 트레이스에 중점을 둡니다. 수집(ingestion)에 대한 고려 사항, 액세스 패턴에 최적화된 스키마 설계, 비정형 로그에서 구조를 추출하는 방법까지 자체 솔루션 구축의 모든 측면을 다룹니다.
ClickHouse만으로는 관측성을 위한 바로 사용할 수 있는(out-of-the-box) 솔루션이 되지 않습니다. 그러나 관측성 데이터에 대해 매우 효율적인 스토리지 엔진으로 사용할 수 있으며, 타의 추종을 불허하는 압축률과 매우 빠른 쿼리 응답 시간을 제공합니다. ClickHouse를 관측성 솔루션 내에서 사용하려면, 사용자 인터페이스와 데이터 수집 프레임워크가 모두 필요합니다. 현재 관측성 시그널의 시각화에는 Grafana를, 데이터 수집에는 OpenTelemetry를 사용할 것을 권장하며, 두 가지 모두 공식적으로 지원되는 통합 옵션입니다.

데이터 수집에는 OpenTelemetry(OTel) 프로젝트 사용을 권장하지만, Vector와 Fluentd와 같은 다른 프레임워크 및 도구를 사용해도 유사한 아키텍처를 구성할 수 있습니다(Fluent Bit를 사용한 예시 참고). Superset과 Metabase를 포함한 대체 시각화 도구도 존재합니다.
왜 ClickHouse를 사용해야 할까요?
중앙집중형 관측성(Observability) 저장소에서 가장 중요한 기능은 다양한 소스에서 수집된 방대한 로그 데이터를 빠르게 집계·분석·검색할 수 있는 능력입니다. 이러한 중앙집중화는 문제 해결 과정을 간소화하여 서비스 장애의 근본 원인을 더 쉽게 파악할 수 있게 합니다.
사용자가 점점 비용에 민감해지고, 기성 관측성 솔루션의 비용이 제공 가치에 비해 높고 예측하기 어렵다고 인식함에 따라, 쿼리 성능이 허용 가능한 수준이면서 비용 효율적이고 예측 가능한 로그 스토리지는 그 어느 때보다 중요해졌습니다.
성능과 비용 효율성 덕분에 ClickHouse는 관측성 제품에서 로그 및 트레이스 스토리지 엔진의 사실상 표준(de facto standard)이 되었습니다.
보다 구체적으로, 다음과 같은 이유로 ClickHouse는 관측성 데이터 저장에 이상적입니다:
- 압축(Compression) - 관측성 데이터에는 일반적으로 HTTP 코드나 서비스 이름처럼 제한된 집합(set)에서 값이 선택되는 필드가 포함됩니다. 값이 정렬된 상태로 저장되는 ClickHouse의 컬럼 지향 스토리지는, 특히 시계열 데이터용 특수 코덱과 결합될 때, 이러한 데이터를 매우 높은 비율로 압축할 수 있습니다. 일반적으로 JSON 형식으로 원본 데이터 크기만큼의 스토리지를 요구하는 다른 데이터 스토어와 달리, ClickHouse는 로그와 트레이스를 평균적으로 최대 14배까지 압축합니다. 이는 대규모 관측성 배포 환경에서 상당한 스토리지 절감을 제공할 뿐 아니라, 디스크에서 읽어야 하는 데이터 양을 줄여 쿼리 속도 향상에도 기여합니다.
- 빠른 집계(Fast Aggregations) - 관측성 솔루션은 일반적으로 오류율을 보여주는 선 그래프나 트래픽 소스를 보여주는 막대 그래프처럼 차트를 통한 데이터 시각화를 많이 활용합니다. 이러한 차트를 구동하는 데 필수적인 것이 집계, 즉
GROUP BY이며, 이는 문제 진단 워크플로에서 필터를 적용할 때도 빠르고 반응성이 좋아야 합니다. ClickHouse의 컬럼 지향 포맷과 벡터화된 쿼리 실행(vectorized query execution) 엔진은 빠른 집계에 최적화되어 있으며, 희소 인덱스를 통해 사용자 작업에 따라 데이터를 신속하게 필터링할 수 있습니다. - 빠른 선형 스캔(Fast Linear scans) - 다른 기술들은 로그를 빠르게 쿼리하기 위해 역색인(inverted index)에 의존하지만, 이는 필연적으로 높은 디스크 및 리소스 사용량을 초래합니다. ClickHouse도 추가적인 선택적 인덱스 유형으로 역색인을 제공하지만, 선형 스캔은 고도로 병렬화되어 (별도로 설정하지 않는 한) 머신의 사용 가능한 모든 코어를 활용합니다. 이를 통해 (압축 기준) 초당 수십 GB 수준의 데이터를 고도로 최적화된 텍스트 매칭 연산자를 사용해 매칭을 위해 스캔할 수 있습니다.
- 익숙한 SQL - SQL은 대부분의 엔지니어가 익숙한 보편적 언어입니다. 50년이 넘는 기간 동안 발전해 오면서 데이터 분석을 위한 사실상의 표준 언어로 자리 잡았고, 여전히 3번째로 인기 있는 프로그래밍 언어입니다. 관측성은 SQL이 특히 적합한 또 다른 데이터 문제일 뿐입니다.
- 분석 함수(Analytical functions) - ClickHouse는 SQL 쿼리를 더 간단하고 작성하기 쉽게 만들기 위해 ANSI SQL을 확장한 분석 함수를 제공합니다. 이는 데이터를 다양한 방식으로 분할·가공해야 하는 근본 원인 분석을 수행할 때 필수적입니다.
- 세컨더리 인덱스(Secondary indices) - ClickHouse는 특정 쿼리 프로파일을 가속화하기 위해 블룸 필터(bloom filters)와 같은 세컨더리 인덱스를 지원합니다. 이러한 인덱스는 컬럼 단위에서 선택적으로 활성화할 수 있어, 사용자가 세밀하게 제어하고 비용 대비 성능 이점을 평가할 수 있습니다.
- 오픈 소스 & 오픈 표준(Open-source & Open standards) - 오픈 소스 데이터베이스로서 ClickHouse는 OpenTelemetry와 같은 오픈 표준을 수용합니다. 프로젝트에 기여하고 적극적으로 참여할 수 있다는 점은 매력적이며, 동시에 벤더 종속성 문제를 피할 수 있게 합니다.
언제 관측성에 ClickHouse를 사용해야 할까요
관측성 데이터에 ClickHouse를 사용하려면 SQL 기반 관측성을 채택해야 합니다. SQL 기반 관측성의 역사에 대해서는 이 블로그 게시물을 참고할 것을 권장합니다. 요약하면 다음과 같습니다.
SQL 기반 관측성이 적합한 경우:
- 사용자 또는 팀이 SQL에 익숙하거나 SQL을 학습하고자 하는 경우
- 잠금(lock-in)을 피하고 확장성을 달성하기 위해 OpenTelemetry와 같은 개방형 표준을 준수하는 것을 선호하는 경우
- 수집부터 저장, 시각화까지 오픈 소스 혁신을 기반으로 한 생태계를 운영할 의사가 있는 경우
- 관리 중인 관측성 데이터 볼륨이 중간 또는 대규모(또는 매우 대규모)로 성장할 것으로 예상되는 경우
- TCO(total cost of ownership, 총 소유 비용)를 직접 통제하고 관측성 비용이 통제 불능으로 증가하는 것을 피하고 싶은 경우
- 비용 관리를 위해 관측성 데이터의 보존 기간을 짧게 가져가야만 하는 상황에 묶이고 싶지 않은 경우
SQL 기반 관측성이 적합하지 않을 수 있는 경우:
- 사용자 또는 팀이 SQL을 학습하거나(또는 생성하는 것조차) 매력적으로 느끼지 못하는 경우
- 완전히 패키지된 엔드 투 엔드 관측성 경험을 찾고 있는 경우
- 관측성 데이터 볼륨이 매우 작아서(예: <150 GiB) 의미 있는 차이를 만들지 못하고, 앞으로도 성장할 것으로 예상되지 않는 경우
- 사용 사례가 메트릭 중심이며 PromQL이 필요한 경우. 이때는 여전히 메트릭에는 Prometheus를, 로그와 트레이싱에는 ClickHouse를 사용하고, Grafana의 프레젠테이션 계층에서 이를 통합할 수 있습니다.
- 생태계가 더 성숙해지고 SQL 기반 관측성이 보다 손쉽게 사용할 수 있는 형태가 될 때까지 기다리는 것을 선호하는 경우
로그와 트레이스
관측성(observability) 활용 사례는 로깅(Logging), 트레이싱(Tracing), 메트릭(Metrics)이라는 세 가지 뚜렷한 축으로 구성됩니다. 각 축은 서로 다른 데이터 유형과 접근 방식이 있습니다.
현재 관측성 데이터 유형 가운데 다음 두 가지를 저장하는 용도로 ClickHouse 사용을 권장합니다:
- Logs - 로그는 시스템 내에서 발생하는 이벤트를 타임스탬프와 함께 기록한 것으로, 소프트웨어 운영의 다양한 측면에 대한 상세 정보를 포착합니다. 로그 데이터는 일반적으로 비정형 또는 반정형 구조를 가지며, 오류 메시지, 사용자 활동 로그, 시스템 변경, 기타 이벤트 등을 포함할 수 있습니다. 로그는 문제 해결, 이상 탐지, 그리고 시스템 내에서 어떤 구체적인 이벤트들이 문제로 이어졌는지를 이해하는 데 매우 중요합니다.
- Traces - Traces는 분산 시스템에서 요청이 여러 서비스를 통과하는 과정을 캡처하여, 해당 요청의 경로와 성능을 자세히 보여 줍니다. Traces 데이터는 매우 구조화되어 있으며, 각 요청이 거치는 모든 단계를 타이밍 정보와 함께 매핑하는 스팬(span)과 트레이스로 구성됩니다. Traces는 시스템 성능에 대한 유용한 인사이트를 제공하여 병목 구간과 지연(latency) 문제를 식별하고 마이크로서비스 효율성을 최적화하는 데 도움이 됩니다.
ClickHouse는 메트릭 데이터를 저장하는 데 사용할 수 있지만, Prometheus 데이터 형식 및 PromQL 지원과 같은 기능이 아직 지원 준비 중이므로 메트릭 영역은 ClickHouse에서 상대적으로 성숙도가 낮은 편입니다.
분산 트레이싱
분산 트레이싱은 관측성의 핵심 기능입니다. 분산 트레이스(간단히 트레이스)는 시스템을 통과하는 요청의 이동 경로를 추적합니다. 요청은 최종 사용자나 애플리케이션에서 시작되어 시스템 전체로 퍼져 나가며, 일반적으로 마이크로서비스 간의 일련의 동작 흐름으로 이어집니다. 이 순서를 기록하고 이후 발생하는 이벤트를 서로 연관시킬 수 있게 함으로써, 관측성 사용자나 SRE가 아키텍처가 얼마나 복잡하거나 서버리스인지와 관계없이 애플리케이션 플로우상의 문제를 진단할 수 있도록 합니다.
각 트레이스는 여러 개의 스팬으로 구성되며, 요청과 연결된 최초의 스팬을 루트 스팬(root span)이라 합니다. 루트 스팬은 시작부터 종료까지 전체 요청을 캡처합니다. 루트 아래의 후속 스팬들은 요청 처리 과정에서 발생하는 다양한 단계나 작업에 대한 상세한 통찰을 제공합니다. 트레이싱이 없으면 분산 시스템에서 성능 문제를 진단하기가 매우 어렵습니다. 트레이싱은 요청이 시스템을 통과하면서 발생하는 이벤트의 순서를 자세히 보여줌으로써 분산 시스템을 디버깅하고 이해하는 과정을 수월하게 만듭니다.
대부분의 관측성 벤더는 이 정보를 워터폴(waterfall) 형태로 시각화하며, 비례적인 크기의 가로 막대를 사용하여 상대적인 타이밍을 표시합니다. 예를 들어 Grafana에서는 다음과 같습니다.
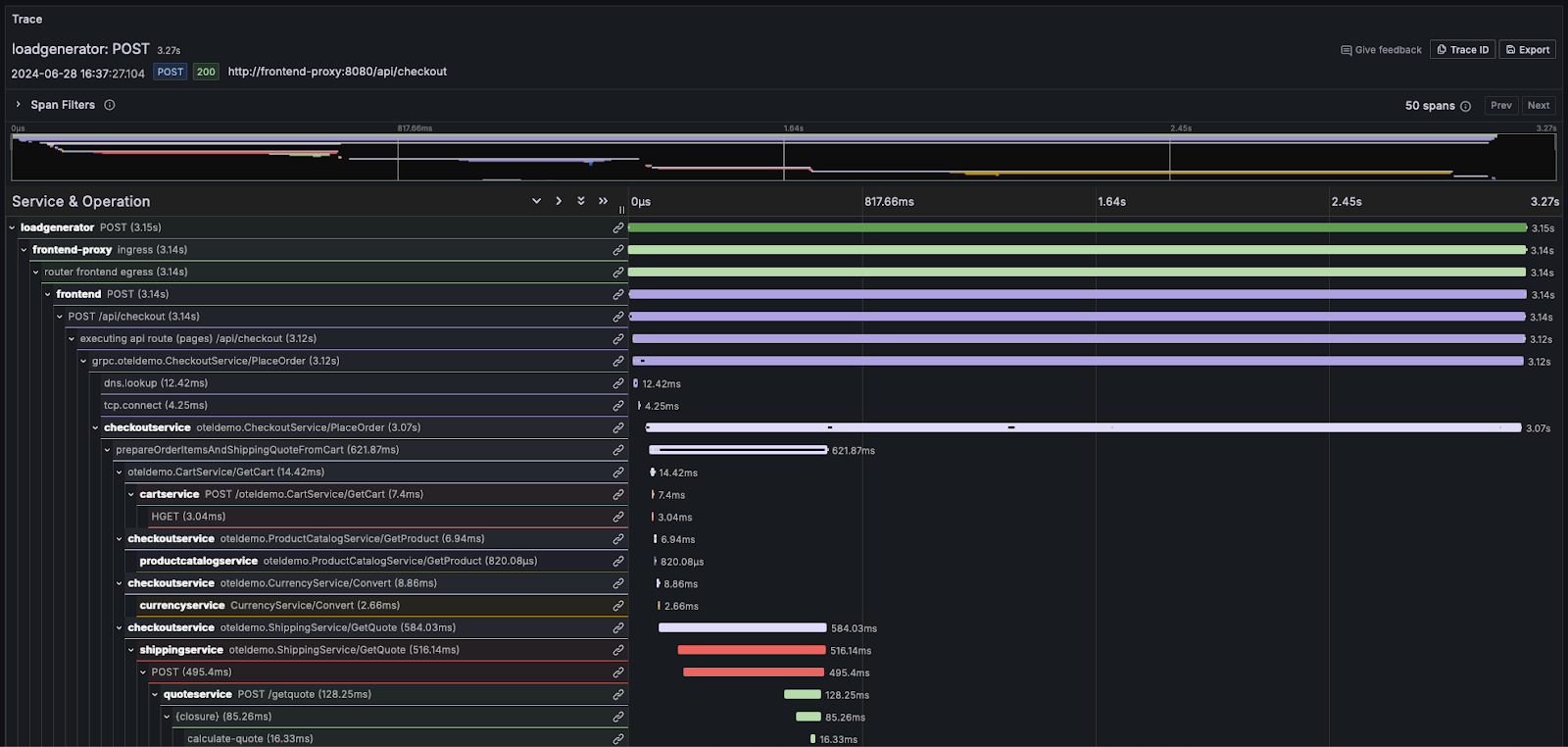
로그와 트레이스 개념을 더 깊이 익혀야 하는 사용자는 OpenTelemetry 문서를 참고할 것을 강력히 권장합니다.
