ClickStack - Materialized Views
소개
ClickStack는 증분형 materialized view(Incremental Materialized View, IMV)를 활용하여, 시간 경과에 따른 분(minute) 단위 평균 요청 지연 시간 계산처럼 집계 중심의 쿼리에 의존하는 시각화를 가속화할 수 있습니다. 이 기능은 쿼리 성능을 극적으로 향상시킬 수 있으며, 일반적으로 일일 10 TB 이상 수준의 대규모 배포 환경에서 가장 큰 효과를 제공하고, 일일 수 페타바이트 수준으로의 확장도 가능하게 합니다. 증분형 materialized view는 현재 Beta 단계이므로 신중하게 사용해야 합니다.
경보(Alerts) 역시 materialized view의 이점을 누릴 수 있으며, 자동으로 이를 활용합니다. 이는 특히 매우 자주 실행되는 여러 경보를 운영할 때의 계산 부담을 줄여 줍니다. 실행 시간을 줄이면 응답성 측면과 리소스 사용 측면 모두에서 유리할 수 있습니다.
What are incremental materialized views
증분형 materialized view는 계산 비용을 쿼리 시점에서 삽입 시점으로 이동시켜 SELECT 쿼리를 상당히 빠르게 실행할 수 있게 합니다.
Postgres와 같은 트랜잭션 데이터베이스와 달리 ClickHouse materialized view는 저장된 스냅샷이 아닙니다. 대신 소스 테이블에 데이터 블록이 삽입될 때마다 쿼리를 실행하는 트리거처럼 동작합니다. 이 쿼리의 출력 결과는 별도의 타깃 테이블에 기록됩니다. 추가 데이터가 삽입되면 새로운 부분 결과가 타깃 테이블에 추가되고 머지됩니다. 이렇게 머지된 결과는 원본 전체 데이터셋에 대해 집계를 수행한 것과 동일한 결과가 됩니다.
materialized view를 사용하는 주된 이유는 타깃 테이블에 기록되는 데이터가 집계, 필터링, 변환의 결과를 나타내기 때문입니다. ClickStack에서는 집계에만 사용됩니다. 이러한 결과는 일반적으로 원시 입력 데이터보다 훨씬 작으며, 종종 부분 집계 상태를 나타냅니다. 사전 집계된 타깃 테이블을 단순하게 쿼리할 수 있다는 점까지 더해지면, 원시 데이터에 대해 쿼리 시점에 동일한 계산을 수행하는 것과 비교하여 쿼리 지연 시간을 크게 줄일 수 있습니다.
ClickHouse의 materialized view는 데이터가 소스 테이블로 유입될 때 지속적으로 업데이트되며, 항상 최신 상태로 유지되는 인덱스에 더 가깝게 동작합니다. 이는 materialized view가 정적 스냅샷이며, ClickHouse의 Refreshable Materialized Views와 유사하게 주기적으로 갱신해야 하는 많은 다른 데이터베이스와는 다릅니다.
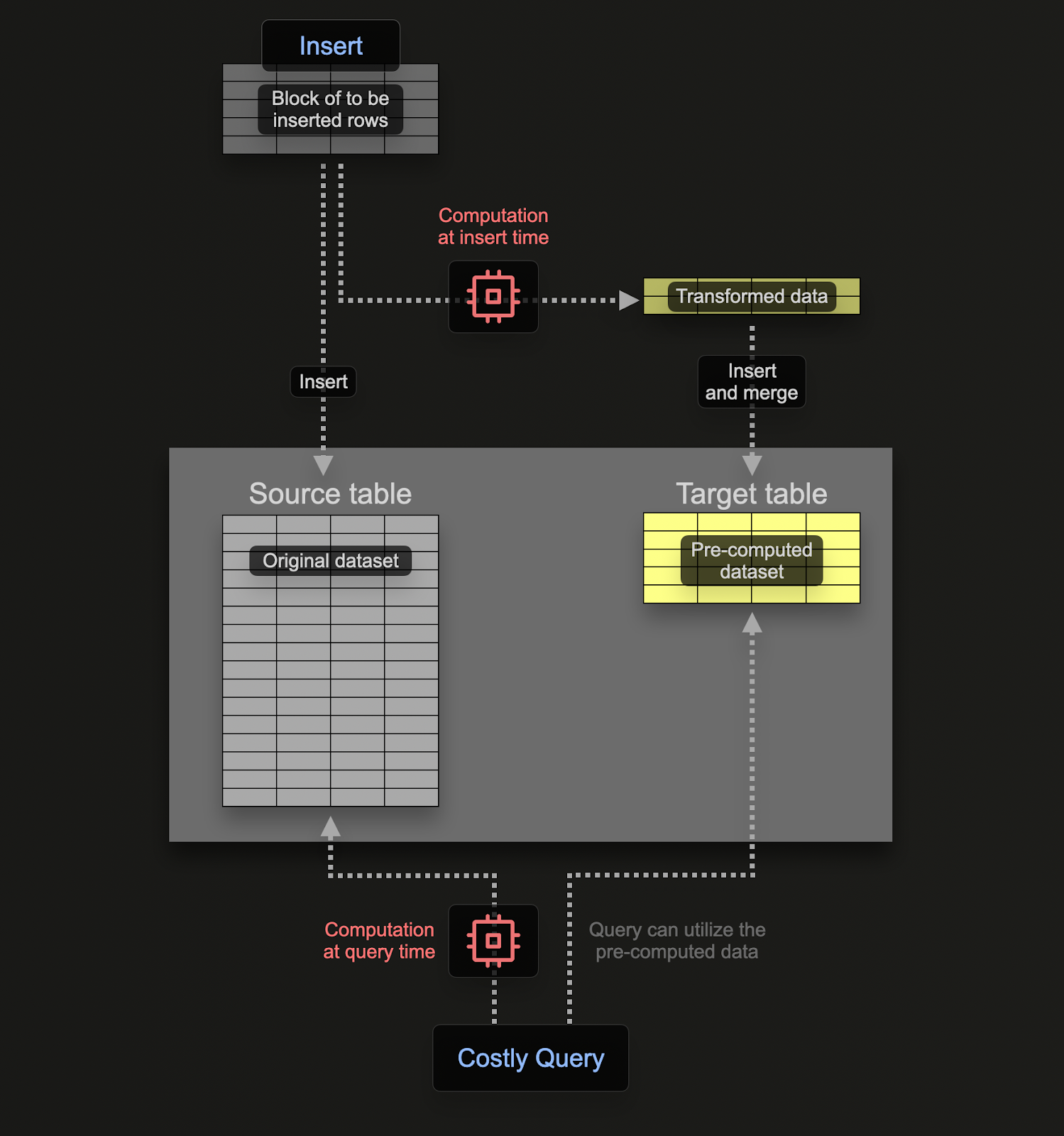
증분형 materialized view는 새로운 데이터가 도착할 때 view의 변경분만 계산하여, 계산을 삽입 시점으로 미룹니다. ClickHouse는 수집에 고도로 최적화되어 있으므로, 각 삽입 블록마다 view를 유지하는 추가 비용은 쿼리 실행 시 얻는 절감 효과에 비해 작습니다. 집계 계산 비용은 매번 읽기 시점에 반복해서 지불되는 대신, 삽입 전반에 걸쳐 분산(상각)됩니다. 따라서 사전 집계된 결과에 대해 쿼리하는 것이 이를 다시 계산하는 것보다 훨씬 비용이 적게 들며, 그 결과 운영 비용이 낮아지고 페타바이트 규모에서도 후속 시각화에 대해 거의 실시간에 가까운 성능을 제공합니다.
이 모델은 각 업데이트마다 전체 view를 다시 계산하거나 예약된 갱신에 의존하는 시스템과는 근본적으로 다릅니다. materialized view의 동작 방식과 생성 방법에 대한 보다 심층적인 설명은 위에 링크된 가이드를 참고하십시오.
각 materialized view는 삽입 시점에 추가 오버헤드를 유발하므로, 선별적으로 사용하는 것이 좋습니다.
가장 자주 사용하는 대시보드와 시각화를 위한 view만 생성하십시오. 기능이 베타인 동안에는 view 사용을 20개 미만으로 제한하십시오. 이 임계값은 향후 릴리스에서 증가할 것으로 예상됩니다.
단일 materialized view로 서로 다른 그룹핑에 대한 여러 메트릭(예: 1분 버킷 단위 서비스 이름별 최소, 최대, p95 duration)을 계산할 수 있습니다. 이를 통해 하나의 view가 단일 시각화가 아니라 여러 시각화를 지원할 수 있습니다. 메트릭을 공용 view로 통합하는 것은 각 view의 가치를 극대화하고, 대시보드와 워크플로 전반에서 재사용되도록 하는 데 중요합니다.
다음 단계로 진행하기 전에 ClickHouse의 materialized view에 대해 더 깊이 익혀 두는 것이 좋습니다. 추가 내용은 Incremental materialized views 가이드를 참고하십시오.
가속할 시각화 선택하기
materialized view를 생성하기 전에 어떤 시각화를 가속할 것인지와 어떤 워크플로우가 사용자에게 가장 중요한지 파악하는 것이 중요합니다.
ClickStack에서 materialized view는 집계 연산 비중이 높은 시각화를 가속하도록 설계되며, 이는 시간 경과에 따라 하나 이상의 지표를 계산하는 쿼리를 의미합니다. 예로는 분당 평균 요청 지연 시간, 서비스별 요청 수, 시간 경과에 따른 오류율 등이 있습니다. materialized view는 시계열 시각화를 제공하도록 설계되었기 때문에 항상 집계와 시간 기반 그룹화를 포함해야 합니다.
일반적으로 다음을 권장합니다.
영향이 큰 시각화 식별하기
가속화 대상으로 가장 적합한 시각화는 일반적으로 다음 범주에 속합니다.
- 벽걸이 디스플레이에 표시되는 상위 수준 모니터링 대시보드처럼, 자주 새로 고침되며 지속적으로 표시되는 대시보드 시각화
- 런북에서 사용되는 진단 워크플로로, 인시던트 대응 중 특정 차트를 반복적으로 참고해야 하며 결과를 신속하게 반환해야 하는 경우
- 다음을 포함한 핵심 HyperDX 사용 경험:
- 검색 페이지의 히스토그램 뷰
- APM, Services, Kubernetes 뷰와 같은 사전 설정 대시보드에서 사용되는 시각화
이러한 시각화는 여러 사용자와 다양한 기간에 걸쳐 반복적으로 실행되는 경우가 많으므로, 쿼리 시점의 연산을 삽입 시점으로 이전하기에 이상적인 대상입니다.
삽입 시점 비용과 이점을 균형 있게 따지기
materialized view는 삽입 시점에 추가 작업을 발생시키므로 선별적으로, 신중하게 생성해야 합니다. 모든 시각화가 사전 집계의 이점을 얻는 것은 아니며, 거의 사용되지 않는 차트를 가속하는 것은 대개 오버헤드에 비해 가치가 크지 않습니다. materialized view의 총 개수는 20개 이하로 유지하는 것이 좋습니다.
프로덕션으로 이전하기 전에 항상 materialized view가 도입하는 리소스 오버헤드를 검증해야 합니다. 특히 CPU 사용량, 디스크 I/O, 그리고 merge 활동을 확인하십시오. 각 materialized view는 삽입 시점의 작업을 증가시키고 추가 파트를 생성하므로, 머지 작업이 이를 감당할 수 있고 파트 수가 안정적으로 유지되는지 확인하는 것이 중요합니다. 이는 오픈소스 ClickHouse의 system tables와 내장 관측성 대시보드, 또는 ClickHouse Cloud의 내장 메트릭 및 모니터링 대시보드를 통해 모니터링할 수 있습니다. 과도한 파트 수를 진단하고 완화하는 방법은 Too many parts를 참고하십시오.
가장 중요한 시각화를 식별했다면, 다음 단계는 이를 통합하는 것입니다.
시각화를 공유 뷰로 통합하기
ClickStack의 모든 materialized view는 toStartOfMinute와 같은 함수를 사용하여 일정 시간 간격으로 데이터를 그룹화해야 합니다. 하지만 많은 시각화는 서비스 이름, 스팬(span) 이름, 상태 코드와 같은 추가적인 그룹화 키도 함께 사용합니다. 여러 시각화가 동일한 그룹화 차원을 사용하는 경우, 하나의 materialized view로 함께 처리할 수 있을 때가 많습니다.
예를 들어(트레이스의 경우):
- 시간 경과에 따른 서비스 이름별 평균 지속 시간 -
SELECT avg(Duration), toStartOfMinute(Timestamp) as time, ServiceName FROM otel_traces GROUP BY ServiceName, time - 시간 경과에 따른 서비스 이름별 요청 수 -
SELECT count() count, toStartOfMinute(Timestamp) as time, ServiceName FROM otel_traces GROUP BY ServiceName, time - 시간 경과에 따른 상태 코드별 평균 지속 시간 -
SELECT avg(Duration), toStartOfMinute(Timestamp) as time, StatusCode FROM otel_traces GROUP BY StatusCode, time - 시간 경과에 따른 상태 코드별 요청 수 -
SELECT count() count, toStartOfMinute(Timestamp) as time, StatusCode FROM otel_traces GROUP BY StatusCode, time
각 쿼리와 차트마다 별도의 materialized view를 생성하는 대신, 서비스 이름과 상태 코드로 집계하는 단일 materialized view로 이를 통합할 수 있습니다. 이 단일 뷰는 count, 평균 지속 시간, 최대 지속 시간뿐만 아니라 백분위수(percentile)와 같은 여러 메트릭도 함께 계산할 수 있으며, 이렇게 계산된 값은 여러 시각화에서 재사용할 수 있습니다. 위 예시를 결합한 예제 쿼리는 아래와 같습니다:
이와 같은 방식으로 VIEW를 통합하면 삽입 시점의 오버헤드를 줄이고, 전체 materialized view 개수를 제한하며, 파트(part) 수와 관련된 문제를 줄이고, 지속적인 유지 관리를 단순화할 수 있습니다.
이 단계에서는 가속하려는 시각화에서 실행되는 쿼리에 집중하십시오. 다음 섹션에서는 여러 집계 쿼리를 단일 materialized view로 통합하는 방법을 보여 주는 예제를 확인할 수 있습니다.
materialized view 생성
가속하려는 시각화(또는 시각화 집합)를 정했다면, 다음 단계는 그 기반이 되는 쿼리를 파악하는 일입니다. 이를 위해 시각화 설정을 확인하고 생성된 SQL을 검토하면서, 사용된 집계 지표와 적용된 함수에 특히 주의를 기울여야 합니다.
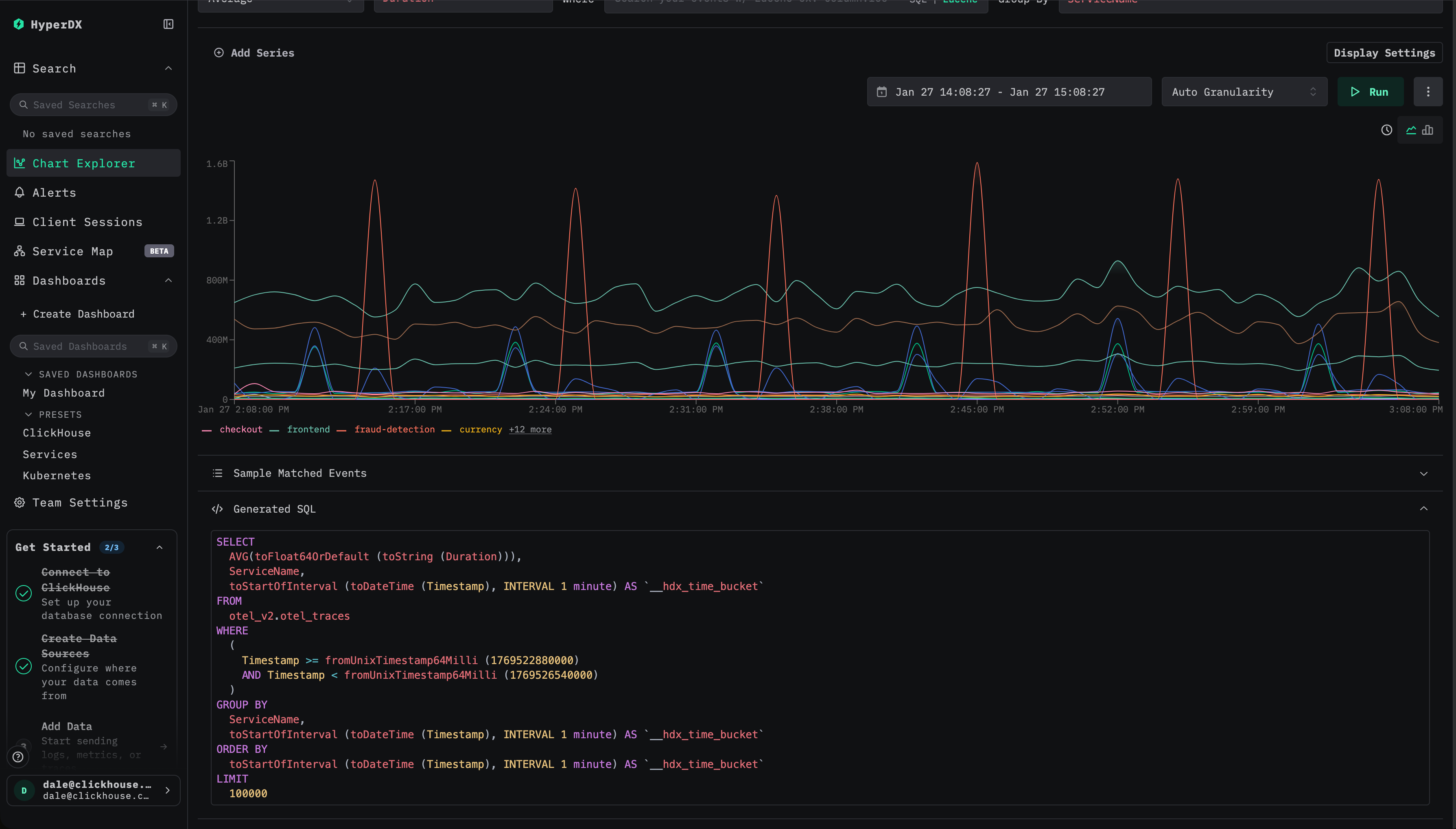
HyperDX 내에서 특정 컴포넌트에 디버그 패널을 사용할 수 없는 경우, 브라우저 콘솔에서 모든 쿼리가 로그로 기록되므로 이를 통해 확인할 수 있습니다.
필요한 쿼리를 정리한 후에는 ClickHouse의 aggregate state 함수에 익숙해져야 합니다. materialized view는 쿼리 시점의 계산을 입력(insert) 시점으로 옮기기 위해 이러한 함수에 의존합니다. 최종 집계 값을 저장하는 대신, materialized view는 중간 집계 상태를 계산하여 저장하고, 이후 쿼리 시점에 이를 병합하고 최종화합니다. 이러한 상태는 일반적으로 원본 테이블보다 훨씬 작습니다. 이 상태는 전용 데이터 타입을 가지며, 대상 테이블의 스키마에 명시적으로 정의되어야 합니다.
참고로, ClickHouse 문서에서는 aggregate state 함수와 이를 저장하는 데 사용되는 테이블 엔진인 AggregatingMergeTree에 대해 자세한 개요와 예제를 제공합니다:
아래 동영상에서 AggregatingMergeTree와 aggregate 함수를 사용하는 예제를 확인할 수 있습니다:
다음 단계로 진행하기 전에 이러한 개념을 충분히 숙지하기를 강력히 권장합니다.
materialized view 예시
다음은 서비스 이름과 상태 코드를 기준으로 분(minute) 단위로 그룹화하여 평균 duration, 최대 duration, 이벤트 개수 및 백분위수(percentile)를 계산하는 원본 쿼리 예시입니다.
이 쿼리의 성능을 높이기 위해, 대응되는 집계 상태를 저장하는 대상 테이블 otel_traces_1m을 생성합니다.
materialized view인 otel_traces_1m_mv의 정의는 새로운 데이터가 삽입될 때 이러한 상태를 계산하고 기록합니다.
이 materialized view는 두 부분으로 구성됩니다.
- 중간 결과를 저장하는 데 사용되는 스키마와 집계 상태 타입을 정의하는 대상 테이블입니다. 이러한 상태가 백그라운드에서 올바르게 병합되도록 AggregatingMergeTree 엔진이 필요합니다.
- materialized view 쿼리는 데이터 insert 시 자동으로 실행됩니다. 원래 쿼리와 비교하면 최종 집계 함수 대신
avgState,quantilesState와 같은 상태 함수들을 사용합니다.
그 결과, 각 서비스 이름과 상태 코드에 대해 분 단위 집계 상태를 저장하는 컴팩트한 테이블이 생성됩니다. 이 테이블의 크기는 시간 경과와 카디널리티에 따라 예측 가능하게 증가하며, 백그라운드 병합 이후에는 원시 데이터에 대해 원래 집계를 실행했을 때와 동일한 결과를 나타냅니다. 이 테이블에 대한 쿼리는 소스 traces 테이블에서 직접 집계하는 것보다 훨씬 비용이 적게 들며, 대규모 환경에서 빠르고 일관된 시각화 성능을 제공합니다.
ClickStack에서 materialized view 사용하기
ClickHouse에서 materialized view를 생성한 후에는 시각화, 대시보드, 알림에서 자동으로 사용되도록 ClickStack에 등록해야 합니다.
Materialized view 사용을 위한 등록
Materialized view는 뷰가 생성된 원본 소스 테이블에 해당하는 HyperDX의 source에 등록해야 합니다.
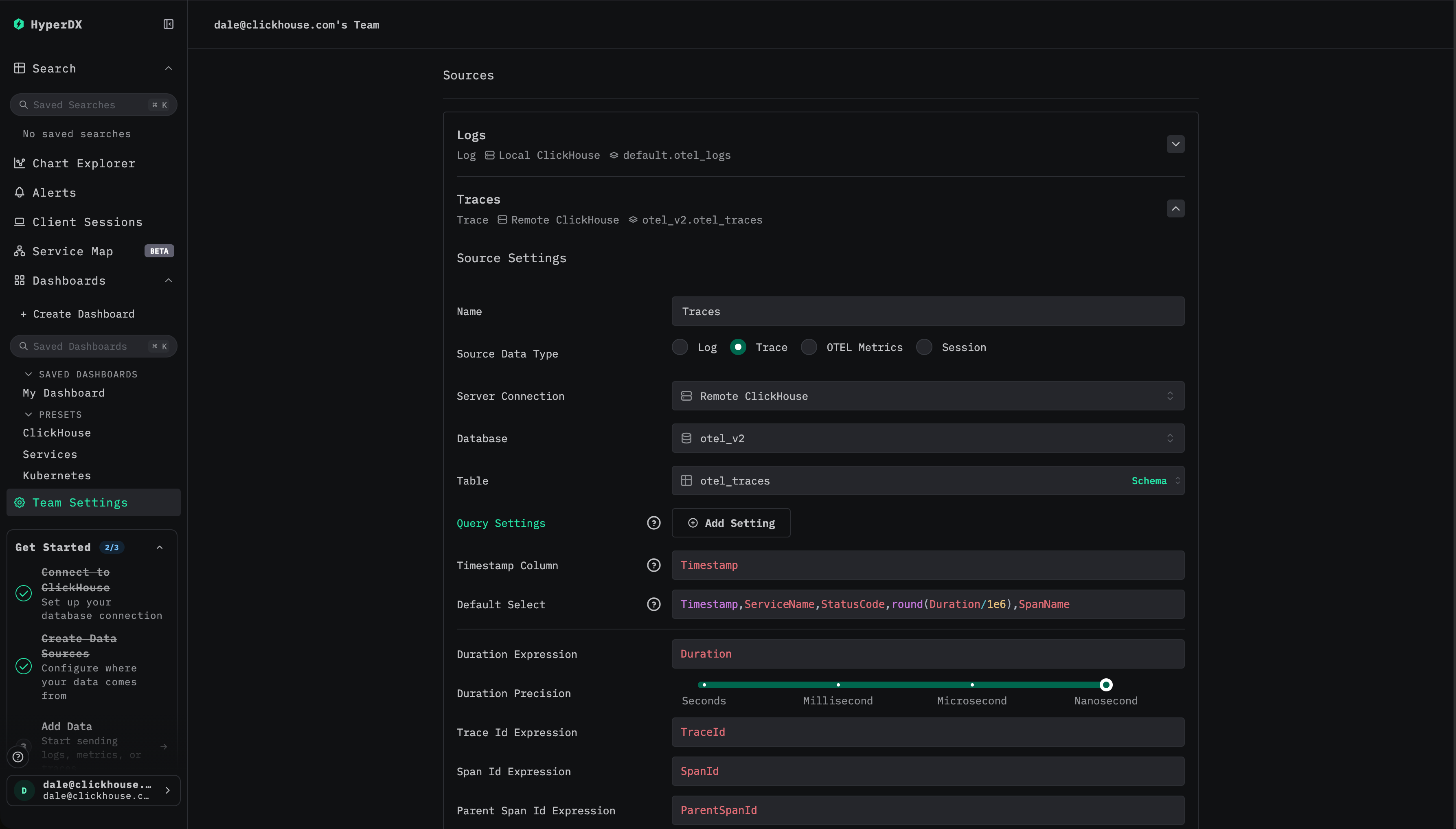
materialized view 추가
Add materialized view를 선택한 다음, 해당 materialized view의 기반이 되는 데이터베이스와 대상 테이블을 선택합니다.
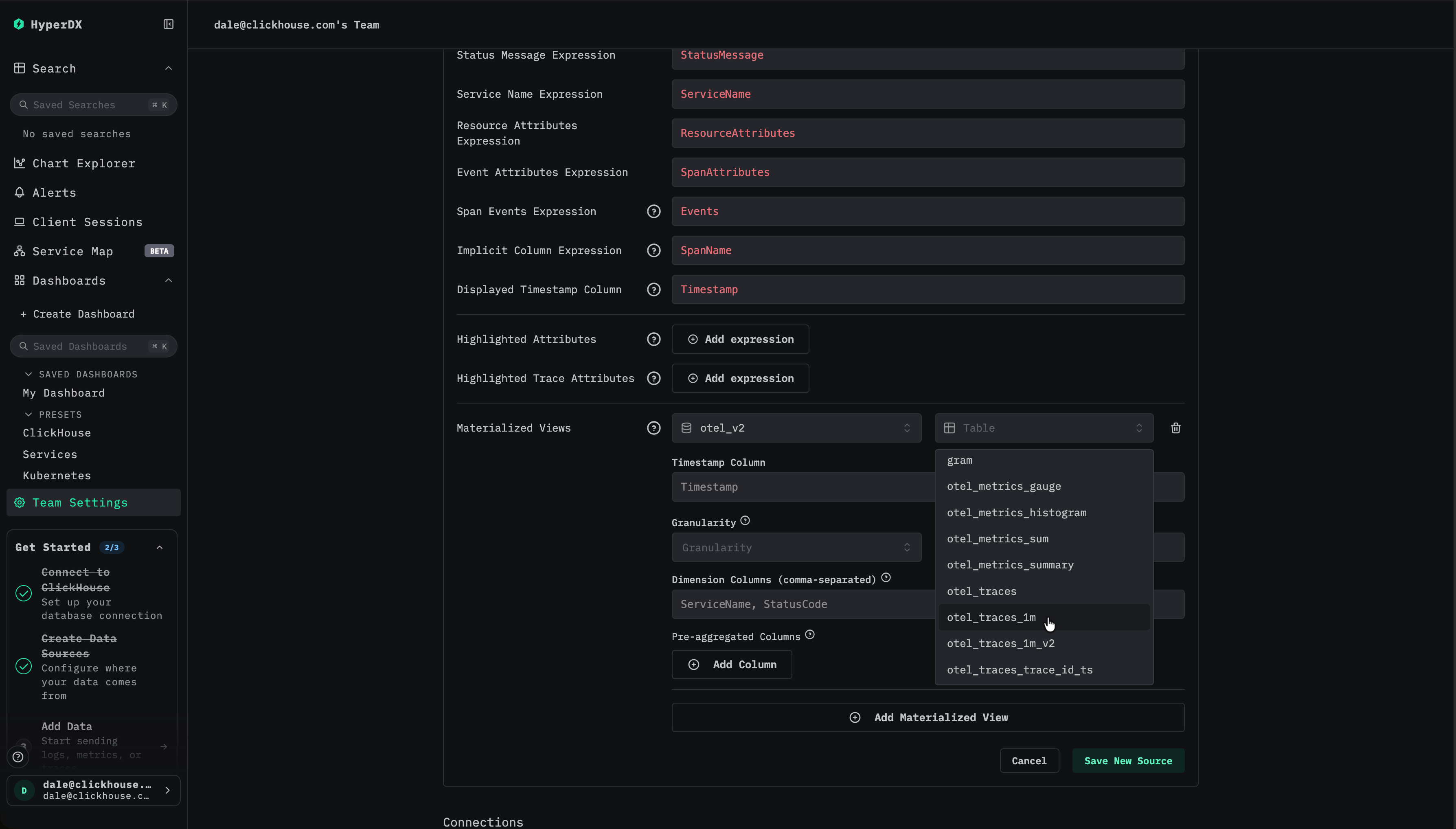
메트릭 선택
대부분의 경우 타임스탬프, 차원, 메트릭 컬럼은 자동으로 추론됩니다. 그렇지 않은 경우 수동으로 지정합니다.
메트릭의 경우 다음을 매핑해야 합니다:
- 예를 들어
Duration과 같은 원본 컬럼 이름을 - materialized view에서 이에 해당하는 집계 컬럼, 예를 들어
avg__Duration으로 매핑합니다.
차원의 경우 타임스탬프를 제외하고, 뷰에서 GROUP BY에 사용되는 모든 컬럼을 지정합니다.
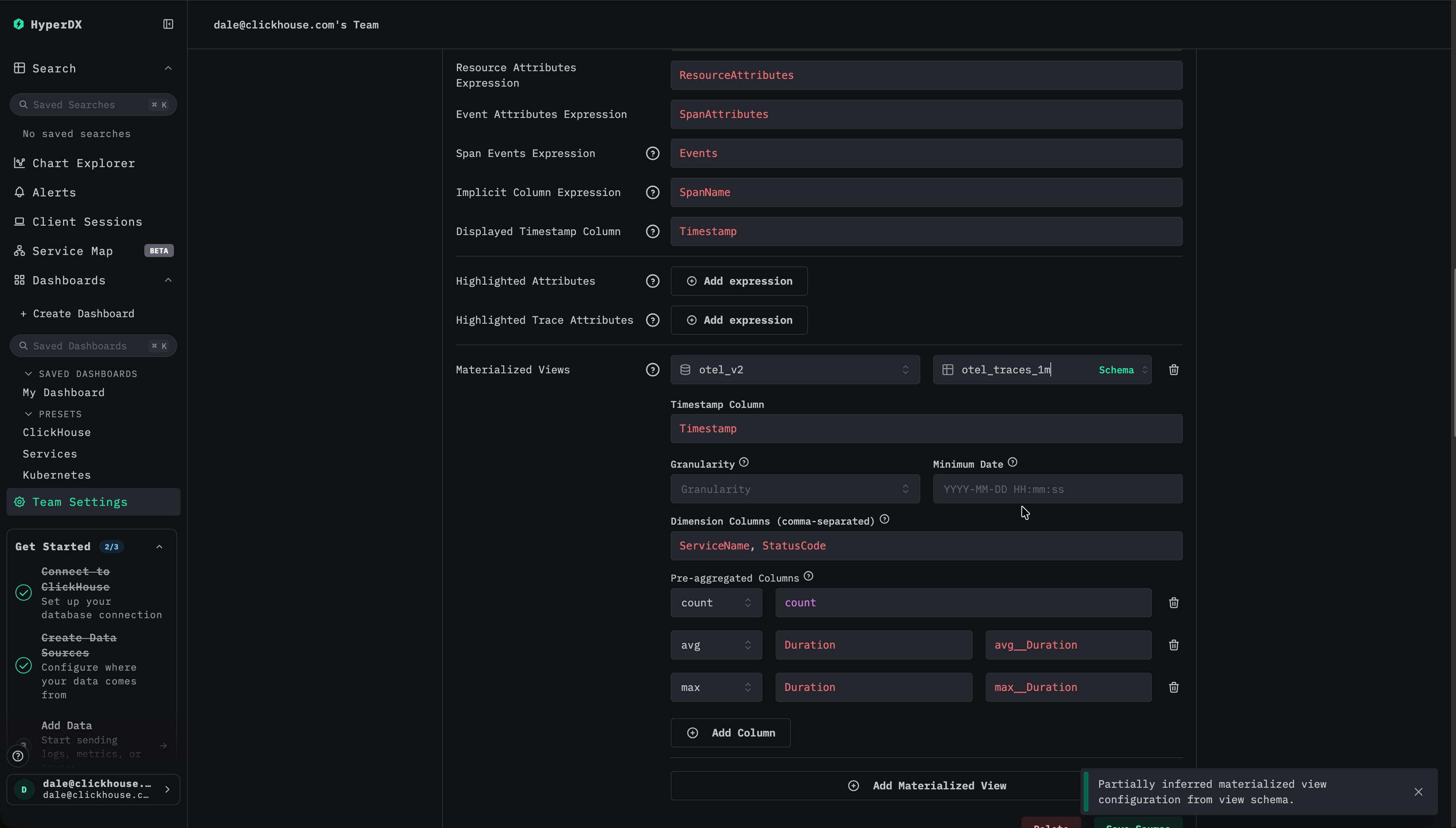
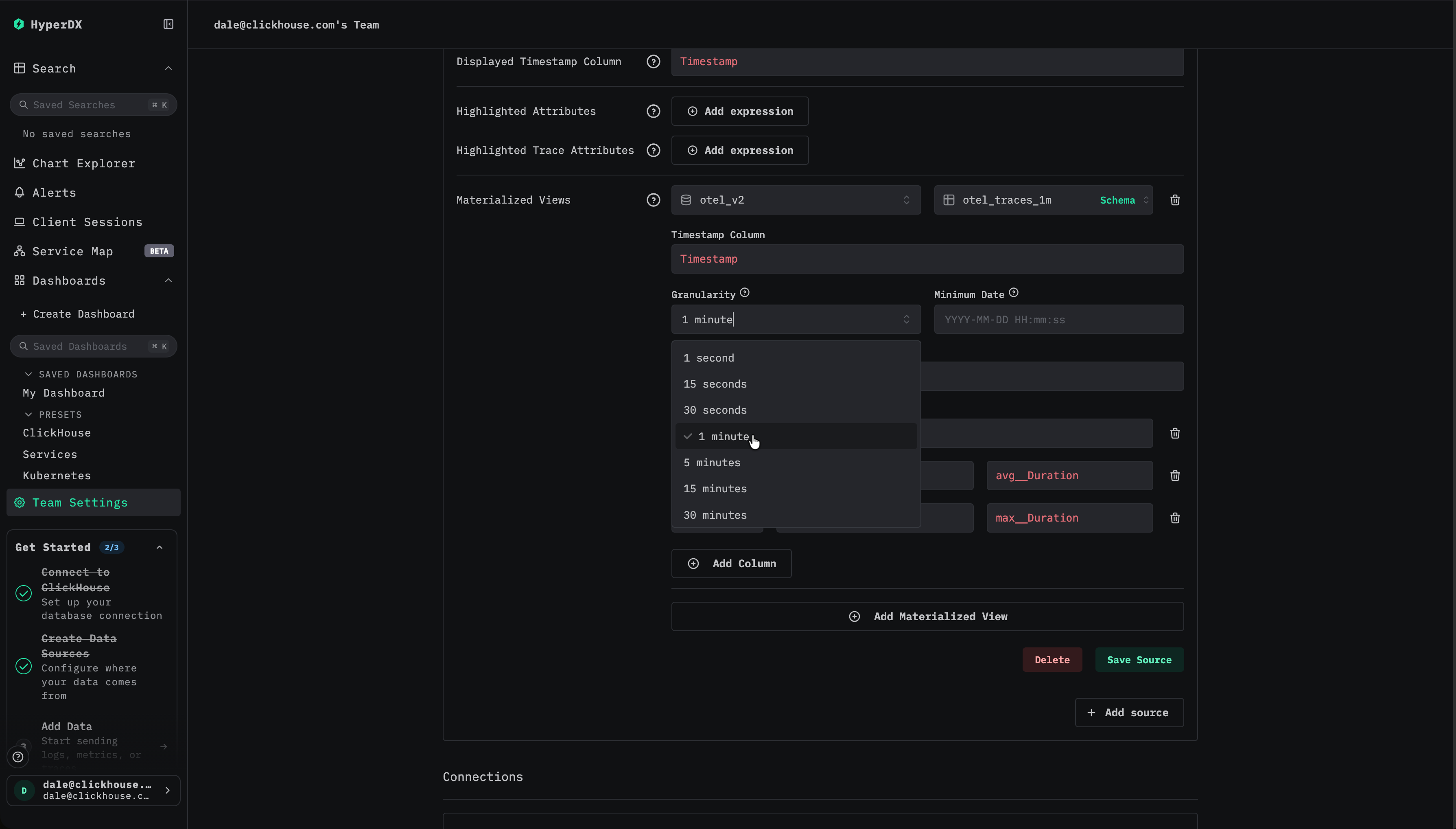
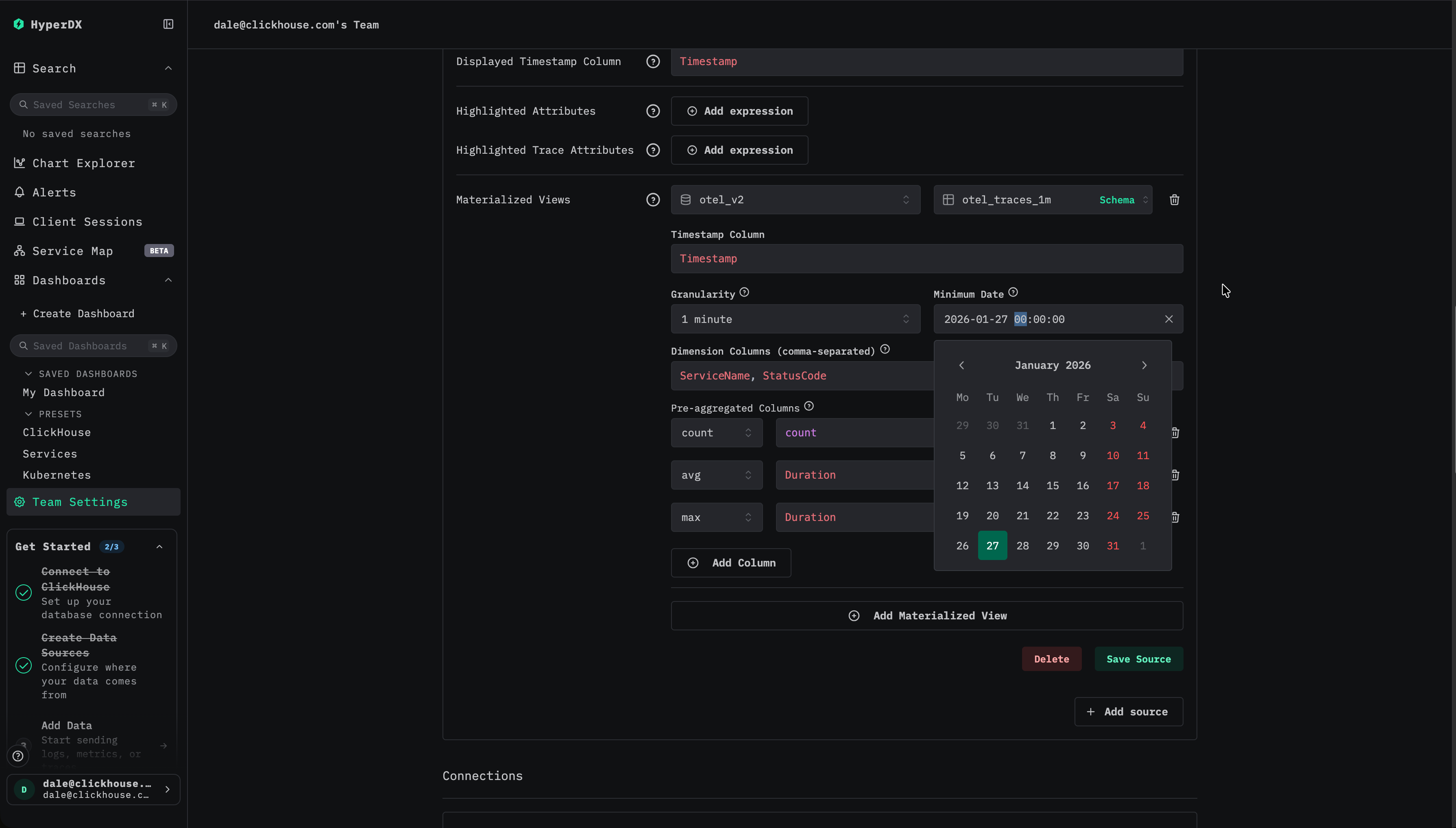
최소 날짜 선택
materialized view에 데이터가 포함된 최소 날짜를 지정합니다. 이는 뷰에서 사용 가능한 가장 이른 타임스탬프를 나타내며, 수집이 계속되었다고 가정하면 일반적으로 뷰가 생성된 시점입니다.
materialized view는 생성 시 자동으로 백필(backfill)되지 않으므로, 생성 이후에 삽입된 데이터에서 생성된 행만 포함합니다. materialized view 백필에 대한 전체 가이드는 "Backfilling Data"에서 확인할 수 있습니다.
정확한 시작 시간이 불명확한 경우, 예를 들어 다음과 같이 대상 테이블에서 최소 타임스탬프를 쿼리하여 확인할 수 있습니다:
materialized view가 한 번 등록되면, 쿼리가 조건을 충족하는 경우 대시보드, 시각화, 알림을 변경하지 않아도 ClickStack에서 자동으로 사용됩니다. ClickStack은 각 쿼리를 실행 시점에 평가하고 materialized view를 적용할 수 있는지 결정합니다.
대시보드와 시각화에서 가속 여부 확인하기
증분형 materialized view에는 해당 view가 생성된 이후에 삽입된 데이터만 포함된다는 점을 기억해야 합니다. 과거 데이터가 자동으로 채워지지(backfill) 않으므로 가볍게 유지되며, 유지 비용도 낮습니다. 이러한 이유로, view를 등록할 때는 해당 view가 유효한 시간 범위를 명시적으로 지정해야 합니다.
ClickStack은 materialized view의 최소 타임스탬프가 쿼리 시간 범위의 시작보다 작거나 같을 때에만 해당 materialized view를 사용하여, view에 필요한 데이터가 모두 포함되도록 합니다. 내부적으로 쿼리가 시간 기반 서브쿼리로 분할되더라도, materialized view는 전체 쿼리에 적용되거나 전혀 적용되지 않습니다. 향후에는 자격을 충족하는 서브쿼리에만 선택적으로 view를 적용하는 기능이 추가될 수 있습니다.
ClickStack은 materialized view 사용 여부를 확인할 수 있도록 명확한 시각적 표시를 제공합니다.
- 최적화 상태 확인 대시보드나 시각화를 볼 때 번개 모양 또는
Accelerated아이콘을 확인합니다.
- 초록색 번개 아이콘은 쿼리가 materialized view에 의해 가속되고 있음을 의미합니다.
- 주황색 번개 아이콘은 쿼리가 소스 테이블에 대해 직접 실행되고 있음을 의미합니다.
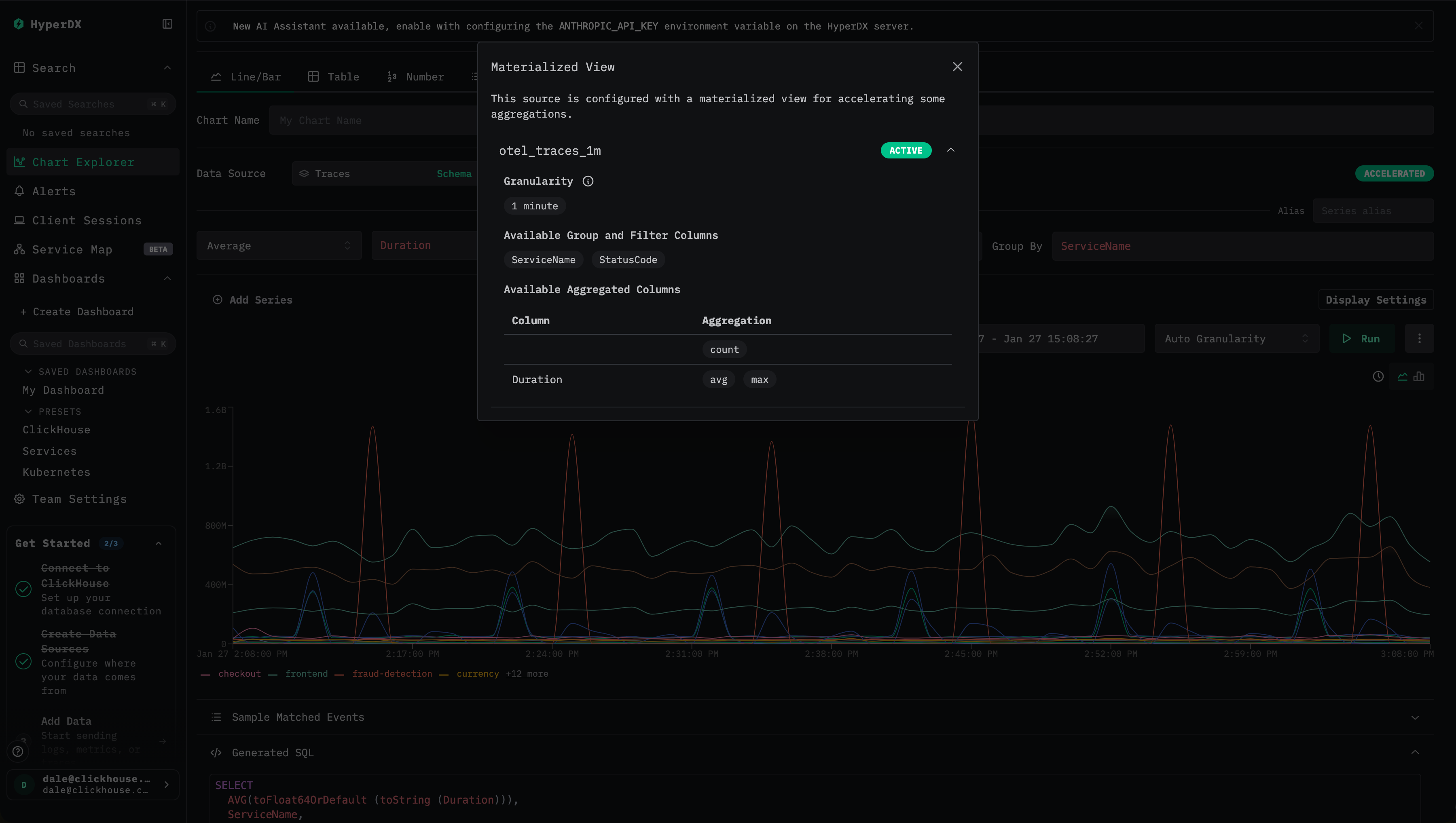
- 최적화 세부 정보 확인 번개 아이콘을 클릭하면 다음 내용을 보여주는 세부 정보 패널이 열립니다.
- 활성 materialized view: 쿼리에 대해 선택된 view와, 해당 view의 추정 행(row) 개수.
- 건너뛴 materialized view: 호환 가능하지만 선택되지 않은 view와, 각 view의 추정 스캔 크기.
- 호환되지 않는 materialized view: 사용할 수 없었던 view와 그 구체적인 이유.
- 일반적인 비호환 이유 이해하기 materialized view가 사용되지 않을 수 있는 경우는 다음과 같습니다.
- 쿼리 시간 범위의 시작이 view의 최소 타임스탬프보다 이전인 경우
- **시각화 세분화 단위(granularity)**가 view의 세분화 단위의 배수가 아닌 경우
- 쿼리에서 요청한 집계 함수가 view에 존재하지 않는 경우
- 쿼리가
count(if(...))와 같이 view의 집계 상태로부터 도출할 수 없는 사용자 정의 count 표현식을 사용하는 경우
이러한 표시를 통해 시각화가 가속되었는지 쉽게 확인하고, 특정 view가 선택된 이유를 이해하며, 어떤 이유로 view가 사용될 수 없었는지 진단할 수 있습니다.
시각화를 위해 materialized view가 선택되는 방식
시각화를 실행할 때 ClickStack에는 기본 테이블뿐만 아니라 여러 개의 materialized view 후보가 있을 수 있습니다. 최적의 성능을 보장하기 위해 ClickStack은 ClickHouse의 EXPLAIN ESTIMATE 메커니즘을 사용하여 가장 효율적인 옵션을 자동으로 평가하고 선택합니다.
선택 과정은 다음과 같은 명확한 순서를 따릅니다.
-
호환성 검증
ClickStack은 다음을 확인하여 materialized view가 해당 쿼리에 사용할 수 있는지 먼저 판별합니다.- 시간 범위 충족: 쿼리의 시간 범위가 materialized view의 사용 가능한 데이터 범위 안에 완전히 포함되어야 합니다.
- 세분도: 시각화의 시간 버킷이 view의 세분도와 같거나 더 거친 수준이어야 합니다.
- 집계: 요청된 메트릭이 view에 존재해야 하며, view의 집계 상태로부터 계산 가능해야 합니다.
-
쿼리 변환
호환 가능한 view에 대해서는 ClickStack이 쿼리를 재작성하여 해당 materialized view의 테이블을 대상으로 합니다.- 집계 함수는 해당 materialized 컬럼에 매핑됩니다.
- 집계 상태에
-Merge조합자(combinator)가 적용됩니다. - 시간 버킷이 view의 세분도에 맞도록 조정됩니다.
-
최적 후보 선택
호환 가능한 materialized view가 여러 개 있을 경우, ClickStack은 각 후보에 대해EXPLAIN ESTIMATE쿼리를 실행하고, 스캔될 행과 그래뉼의 예상 개수를 비교합니다. 예상 스캔 비용이 가장 낮은 view가 선택됩니다. -
자동 폴백(fallback)
호환 가능한 materialized view가 없으면 ClickStack은 자동으로 원본 테이블을 대상으로 쿼리를 실행하도록 폴백합니다.
이 접근 방식은 스캔되는 데이터 양을 지속적으로 최소화하면서, 시각화 정의를 변경할 필요 없이 예측 가능하고 지연 시간이 낮은 성능을 제공합니다.
필요한 모든 차원(dimension)이 view에 포함되어 있는 한, 시각화에 필터, 검색 제약 조건, 시간 버킷 처리가 포함되어 있어도 materialized view는 계속 사용 가능합니다. 이를 통해 시각화 정의를 변경하지 않고도 대시보드, 히스토그램, 필터링된 차트를 가속할 수 있습니다.
materialized view 선택 예시
동일한 trace 소스에 대해 생성된 두 개의 materialized view가 있다고 가정합니다:
- 분 단위로,
ServiceName,StatusCode로 그룹화한otel_traces_1m - 분 단위로,
ServiceName,StatusCode,SpanName로 그룹화한otel_traces_1m_v2
두 번째 view에는 추가 그룹화 키가 포함되므로 더 많은 행을 생성하고 더 많은 데이터를 스캔합니다.
시각화에서 시간 경과에 따른 서비스별 평균 duration을 요청하는 경우, 두 view 모두 기술적으로는 유효합니다. ClickStack은 각 후보에 대해 EXPLAIN ESTIMATE 쿼리를 실행하고, 추정된 그래뉼(granule) 개수를 비교합니다. 즉, 다음과 같습니다:
otel_traces_1m 테이블은 크기가 더 작고 스캔하는 그래뉼 수가 적기 때문에 자동으로 선택됩니다.
두 materialized view 모두 기본 테이블을 직접 쿼리하는 것보다 성능이 우수하지만, 필요한 조건을 충족하는 가장 작은 view를 선택하는 것이 최상의 성능을 발휘합니다.
알림
알림 쿼리는 호환되는 경우 materialized view를 자동으로 사용합니다. 동일한 최적화 로직이 적용되어 알림 평가가 더 빠르게 이루어집니다.
materialized view 백필(backfilling)
앞에서 언급했듯이, 증분형 materialized view에는 뷰가 생성된 이후에 삽입된 데이터만 포함되며, 자동으로 백필되지 않습니다. 이러한 설계 덕분에 뷰를 가볍고 유지 비용이 낮게 유지할 수 있지만, 동시에 해당 뷰의 최소 타임스탬프보다 이전 데이터를 필요로 하는 쿼리에는 사용할 수 없다는 의미이기도 합니다.
대부분의 경우에는 이것으로 충분합니다. 일반적인 ClickStack 워크로드는 최근 24시간과 같은 최신 데이터에 초점을 맞추므로, 새로 생성된 뷰는 생성 후 하루 이내에 완전히 활용 가능해집니다. 그러나 더 긴 기간에 걸친 쿼리에서는 충분한 시간이 흐를 때까지 뷰를 사용할 수 없는 상태로 남을 수 있습니다.
이러한 경우에는 materialized view를 과거 데이터로 백필(backfilling) 하는 것을 고려할 수 있습니다.
백필은 연산 비용이 매우 많이 들 수 있습니다. 정상적으로 운영될 때에는 데이터가 도착할 때마다 materialized view가 증분적으로 채워지므로, 연산 비용이 시간에 따라 고르게 분산됩니다.
반면 백필은 이 작업을 훨씬 짧은 기간으로 압축하여, 단위 시간당 CPU와 메모리 사용량을 크게 증가시킵니다.
데이터셋 크기와 보존 기간(retention window)에 따라, 합리적인 시간 안에 백필을 완료하려면 ClickHouse Cloud에서 클러스터를 수직 또는 수평으로 일시적으로 확장해야 할 수 있습니다.
추가 리소스를 프로비저닝하지 않으면, 백필로 인해 쿼리 지연 시간 및 수집 처리량을 포함한 프로덕션 워크로드에 부정적인 영향이 발생할 수 있습니다. 매우 큰 데이터셋이나 긴 과거 기간의 경우, 백필은 비현실적이거나 아예 불가능할 수도 있습니다.
정리하면, 백필은 비용과 운영상의 위험을 고려할 때 종종 그만한 가치가 없습니다. 과거 데이터 가속이 정말로 중요한 예외적인 경우에만 검토해야 합니다. 진행하기로 결정했다면, 성능, 비용, 프로덕션 영향 사이의 균형을 맞추기 위해 아래에 설명된 통제된 접근 방식을 따르는 것이 좋습니다.
materialized view 백필 방법
POPULATE 명령은 수집이 일시 중지된 소규모 데이터 세트에만 사용하는 것이 좋으며, 그 외 materialized view를 백필하는 용도로는 권장되지 않습니다. populate 해시가 완료된 이후에 materialized view를 생성하는 경우, 이 연산자는 그 사이에 소스 테이블에 삽입된 일부 행을 놓칠 수 있습니다. 또한 이 populate 작업은 전체 데이터에 대해 실행되므로, 대규모 데이터 세트에서는 중단이나 메모리 제한에 취약합니다.
다음과 같은 집계를 기반으로 하는 materialized view를 백필하려 한다고 가정합니다. 이 집계는 서비스 이름과 상태 코드별로 그룹화된 분 단위 메트릭을 계산합니다.
앞서 설명했듯이, 증분형 materialized view는 자동으로 백필되지 않습니다. 신규 데이터에 대한 증분 방식을 유지하면서 과거 데이터를 안전하게 백필하기 위해 다음과 같은 절차를 권장합니다.
INSERT INTO SELECT를 사용한 직접 백필(direct backfill)
이 방법은 전체 백필을 수행하더라도 클러스터 리소스를 소진하지 않고 합리적인 시간 안에 완료할 수 있는 소규모 데이터셋 또는 상대적으로 가벼운 집계 쿼리에 가장 적합합니다. 일반적으로 백필 쿼리가 수분, 길어도 수시간 이내에 완료될 수 있고 CPU 및 I/O 사용량의 일시적인 증가가 허용되는 경우에 적절합니다. 더 큰 데이터셋이나 비용이 큰 집계가 필요한 경우에는 아래에 설명된 점진적(backfilling) 또는 블록 기반 백필 방식을 고려하는 것이 좋습니다.
뷰의 현재 적용 범위 확인
백필을 시도하기 전에 먼저 materialized view에 이미 포함되어 있는 데이터가 무엇인지 확인해야 합니다. 이는 대상 테이블에 존재하는 최소 타임스탬프를 쿼리하여 수행합니다:
이 타임스탬프는 뷰가 쿼리를 만족할 수 있는 가장 이른 시점을 나타냅니다. 이 타임스탬프보다 이전 데이터를 요청하는 ClickStack의 모든 쿼리는 기본 테이블을 조회하게 됩니다.
백필 필요 여부 결정
대부분의 ClickStack 배포 환경에서는 최근 24시간과 같은 최신 데이터에 초점을 맞춰 쿼리를 수행합니다. 이러한 경우 새로 생성된 뷰는 생성 직후 곧바로 완전히 사용 가능해지며, 백필이 필요하지 않습니다.
이전 단계에서 반환된 타임스탬프가 사용 사례에 충분히 오래된 시점이라면 별도의 백필은 필요하지 않습니다. 백필은 다음과 같은 경우에만 고려해야 합니다:
- 쿼리가 자주 장기간의 과거 범위를 포함하는 경우
- 해당 범위 전체에 걸쳐 성능을 위해 뷰가 중요한 경우
- 데이터셋 크기와 집계 비용 측면에서 백필을 수행하는 것이 실질적으로 가능할 경우
누락된 과거 데이터 백필
백필이 필요한 경우, 위에서 기록한 타임스탬프보다 이른 타임스탬프에 대해 materialized view의 대상 테이블을 채워야 합니다. 이를 위해 뷰에서 사용되는 쿼리를 수정하여 해당 타임스탬프보다 오래된 데이터만 읽도록 합니다. 대상 테이블은 AggregatingMergeTree를 사용하므로, 백필 쿼리는 최종 값이 아니라 집계 상태를 삽입해야 합니다.
이 쿼리는 대량의 데이터를 처리할 수 있으며 리소스를 많이 사용할 수 있습니다. 백필을 실행하기 전에 항상 사용 가능한 CPU, 메모리, I/O 용량을 확인해야 합니다. 유용한 방법으로, 먼저 FORMAT Null을 사용해 쿼리를 실행하여 예상 실행 시간과 리소스 사용량을 추정할 수 있습니다.
쿼리 자체가 여러 시간 동안 실행될 것으로 예상되는 경우에는 이 방법을 권장하지 않습니다.
다음 쿼리는 WHERE 절을 추가하여 뷰에 존재하는 가장 이른 타임스탬프보다 오래된 데이터로만 집계를 제한하는 방식을 보여 줍니다:
Null 테이블을 사용한 증분형 백필링
대용량 데이터 세트나 리소스를 많이 사용하는 집계 쿼리의 경우, 단일 INSERT INTO SELECT를 사용하는 직접 백필링은 비현실적이거나 안전하지 않을 수 있습니다. 이러한 상황에서는 증분형 백필링 방식을 권장합니다. 이 방법은 전체 과거 데이터 세트를 한 번에 집계하는 대신, 처리 가능한 블록 단위로 데이터를 처리한다는 점에서 증분형 materialized view가 일반적으로 동작하는 방식을 더 가깝게 반영합니다.
이 접근 방식은 다음과 같은 경우에 적합합니다:
- 백필링 쿼리가 그렇지 않으면 여러 시간 동안 실행되는 경우
- 전체 집계 시 피크 메모리 사용량이 지나치게 높은 경우
- 백필링 동안 CPU와 메모리 사용량을 엄격하게 제어하려는 경우
- 중단되었을 때 안전하게 재시작할 수 있는, 보다 견고한 프로세스가 필요한 경우
핵심 아이디어는 Null 테이블을 수집 버퍼로 사용하는 것입니다. Null 테이블은 데이터를 저장하지 않지만, 여기에 연결된 모든 materialized view는 여전히 실행되므로, 데이터가 흘러가면서 집계 상태를 증분 방식으로 계산할 수 있습니다.
백필링용 Null 테이블 생성
materialized view의 집계에 필요한 컬럼만 포함하는 경량 Null 테이블을 생성합니다. 이렇게 하면 I/O와 메모리 사용량을 최소화할 수 있습니다.
Null 테이블에 materialized view 연결
다음으로, 기본 materialized view에서 사용 중인 것과 동일한 집계 테이블을 대상으로 하는 materialized view를 Null 테이블 위에 생성합니다.
이 materialized view는 Null 테이블에 행이 삽입될 때마다 증분 방식으로 실행되며, 작은 블록 단위로 집계 상태를 생성합니다.
데이터를 점진적으로 백필링
마지막으로, 과거 데이터를 Null 테이블에 삽입합니다. materialized view는 데이터를 블록 단위로 처리하여, 원시 행을 영구 저장하지 않고 대상 테이블로 집계 상태를 내보냅니다.
데이터가 증분 방식으로 처리되므로, 메모리 사용량은 제한적이고 예측 가능하게 유지되며, 일반적인 수집 동작과 매우 비슷해집니다.
추가적인 안전성을 위해, 백필링 materialized view의 출력을 임시 대상 테이블(예: otel_traces_1m_v2)로 보내는 방안을 고려하십시오. 백필링이 성공적으로 완료되면, 파티션을 이동하여 기본 대상 테이블로 옮길 수 있습니다(예: ALTER TABLE otel_traces_1m_v2 MOVE PARTITION '2026-01-02' TO otel_traces_1m). 이렇게 하면, 백필링이 중단되거나 리소스 한도로 인해 실패하더라도 쉽게 복구할 수 있습니다.
이 프로세스를 튜닝하는 방법(삽입 성능 개선, 리소스 사용량 절감 및 제어 포함)에 대한 더 자세한 내용은 백필링을 참조하십시오.
권장 사항
다음 권장 사항은 ClickStack에서 materialized view를 설계하고 운영할 때의 모범 사례를 요약합니다. 이러한 지침을 따르면 materialized view를 효과적이고 예측 가능하며 비용 효율적으로 운영하는 데 도움이 됩니다.
세분성 선택 및 정렬
materialized view는 시각화나 알림의 세분성이 해당 view 세분성의 정확한 배수인 경우에만 사용됩니다. 세분성이 어떻게 결정되는지는 차트 유형에 따라 다음과 같이 달라집니다.
-
시간 차트(x축에 시간이 있는 선형 또는 막대 차트): 차트에 명시된 세분성은 materialized view 세분성의 배수여야 합니다. 예를 들어, 10분 차트는 10, 5, 2, 또는 1분 세분성을 가진 materialized view는 사용할 수 있지만, 20분 또는 3분 세분성의 view는 사용할 수 없습니다.
-
비시간 차트(숫자, 테이블, 요약 차트): 실제 적용되는 세분성은
(time range / 80)에서 계산되며, HyperDX에서 지원하는 가장 가까운 세분성으로 올림됩니다. 이렇게 계산된 세분성 역시 materialized view 세분성의 배수여야 합니다.
이러한 규칙 때문에 다음 사항을 권장합니다.
- 10분 세분성의 materialized view는 생성하지 마십시오. ClickStack은 차트와 알림에 대해 15분 세분성은 지원하지만 10분 세분성은 지원하지 않습니다. 따라서 10분 materialized view는 일반적인 15분 시각화 및 알림과 호환되지 않습니다.
- 대부분의 차트 및 알림 구성과 깔끔하게 조합되는 1분 또는 1시간 세분성을 사용하는 것이 좋습니다.
더 큰(거친) 세분성(예: 1시간 단위)을 사용하면 view 크기가 작아지고 스토리지 오버헤드가 줄어들며, 더 작은(세밀한) 세분성(예: 1분 단위)을 사용하면 세밀한 분석을 위한 유연성이 향상됩니다. 중요한 워크플로우를 지원할 수 있는 범위 내에서 가능한 한 가장 작은 세분성을 선택하십시오.
materialized view 개수 제한 및 통합
각 materialized view는 추가적인 삽입 시점 오버헤드를 유발하고 part 및 merge 작업에 대한 부하를 증가시킵니다. 다음과 같은 지침을 권장합니다.
- 소스별 materialized view는 최대 20개를 넘기지 않는 것이 좋습니다.
- 약 10개의 materialized view가 일반적으로 최적입니다.
- 공통 차원을 공유하는 경우 여러 시각화를 하나의 view로 통합합니다.
가능한 경우 하나의 materialized view에서 여러 메트릭을 계산하고, 동일한 materialized view로 여러 차트를 지원하도록 구성하십시오.
차원은 신중하게 선택하기
그룹화나 필터링에 자주 사용되는 차원만 포함합니다.
- 그룹화 컬럼을 하나 추가할 때마다 뷰 크기가 커집니다.
- 쿼리 유연성과 저장 공간 및 삽입 시점 비용을 균형 있게 고려합니다.
- 뷰에 존재하지 않는 컬럼에 대한 필터는 ClickStack이 원본 테이블로 되돌아가 처리하게 만듭니다.
일반적이면서도 거의 항상 유용한 기준선은 서비스 이름 기준으로 그룹화하고 count 메트릭을 사용하는 materialized view입니다. 이렇게 하면 검색과 대시보드에서 빠른 히스토그램과 서비스 수준 개요를 제공할 수 있습니다.
집계 컬럼 이름 규칙
구체화된 뷰(Materialized View) 집계 컬럼은 자동 추론이 가능하도록 엄격한 이름 규칙을 따라야 합니다.
- 패턴:
<aggFn>__<sourceColumn> - 예:
avg__Durationmax__Durationcount__(행 개수용)
ClickStack은 이 규칙을 기반으로 쿼리를 구체화된 뷰 컬럼에 올바르게 매핑합니다.
분위수와 스케치 선택
서로 다른 분위수 함수는 성능과 저장 공간 측면에서 서로 다른 특성을 가집니다.
quantiles는 디스크에 더 큰 스케치를 생성하지만, 삽입(INSERT) 시점의 계산 비용이 더 적게 듭니다.quantileTDigest는 삽입 시점의 계산 비용이 더 높지만 더 작은 스케치를 생성하며, 이로 인해 뷰 조회가 더 빠른 경우가 많습니다.
두 함수 모두에 대해 삽입 시점에 스케치 크기(예: quantile(0.5))를 지정할 수 있습니다. 이렇게 생성된 스케치는 이후에 다른 분위수 값(예: quantile(0.95))을 조회하는 데에도 계속 사용할 수 있습니다. 워크로드에 가장 잘 맞는 균형을 찾기 위해 실험해 보는 것을 권장합니다.
효과를 지속적으로 검증하기
항상 materialized view가 실제로 이점을 제공하는지 검증해야 합니다.
- UI의 가속화 지표를 통해 사용 여부를 확인합니다.
- 해당 view를 활성화하기 전후의 쿼리 성능을 비교합니다.
- 리소스 사용량과 머지(merge) 동작을 모니터링합니다.
materialized view는 쿼리 패턴이 변화함에 따라 주기적인 검토와 조정이 필요한 성능 최적화 수단으로 간주해야 합니다.
고급 구성
더 복잡한 워크로드에서는 다양한 액세스 패턴을 지원하기 위해 여러 개의 materialized view를 사용할 수 있습니다. 예를 들면 다음과 같습니다:
- 고해상도 최신 데이터와 저해상도(거친) 과거 데이터 뷰
- 개요를 위한 서비스 수준 VIEW와 심층 진단을 위한 엔드포인트 수준 VIEW
이러한 패턴은 선별적으로 적용하면 성능을 크게 향상시킬 수 있지만, 더 단순한 구성을 먼저 검증한 후에만 도입해야 합니다.
이 권장 사항을 따르면 materialized view가 효과적이고 유지 관리 가능하며 ClickStack의 실행 모델에 부합하도록 유지하는 데 도움이 됩니다.
제한 사항
일반적인 비호환성 원인
다음 조건 중 하나라도 해당하면 materialized view는 사용되지 않습니다:
-
쿼리 시간 범위
쿼리의 시간 범위 시작 시점이 materialized view의 최소 타임스탬프보다 이전인 경우입니다. 뷰는 자동으로 과거 데이터가 채워지지 않으므로, 자신이 완전히 포함하고 있는 시간 범위에 대해서만 쿼리를 만족시킬 수 있습니다. -
세분화 단위 불일치
시각화의 유효 세분화 단위는 materialized view의 세분화 단위의 정확한 배수여야 합니다. 구체적으로:- 시간 차트(x축이 시간인 선형/막대 차트)의 경우, 차트에서 선택한 세분화 단위는 뷰의 세분화 단위의 배수여야 합니다. 예를 들어, 10분 차트에서는 10분, 5분, 2분, 1분 materialized view를 사용할 수 있지만, 20분 또는 3분 materialized view는 사용할 수 없습니다.
- 비시간 차트(숫자 또는 테이블 차트)의 경우, 유효 세분화 단위는
(time range / 80)으로 계산한 뒤 HyperDX에서 지원하는 가장 가까운 세분화 단위로 올림 처리되며, 이 값 역시 뷰의 세분화 단위의 배수여야 합니다.
-
미지원 집계 함수
쿼리가 materialized view에 존재하지 않는 집계를 요청하는 경우입니다. 뷰에서 명시적으로 계산되어 저장된 집계만 사용할 수 있습니다. -
사용자 정의 count 표현식
count(if(...))와 같은 표현식이나 기타 조건부 count를 사용하는 쿼리는 표준 집계 상태로부터 도출할 수 없으므로, materialized view를 사용할 수 없습니다.
설계 및 운영 제약 사항
-
자동 백필 없음 증분형 materialized view에는 생성 이후에 삽입된 데이터만 포함됩니다. 과거 데이터에 대한 쿼리 가속을 위해서는 명시적으로 백필(backfill) 작업을 수행해야 하며, 대규모 데이터셋에서는 비용이 많이 들거나 비실용적일 수 있습니다.
-
세분성(Granularity) 트레이드오프 매우 세밀한 세분성을 갖는 뷰는 저장 공간과 삽입 시점 오버헤드를 증가시키는 반면, 세분성이 거친 뷰는 유연성을 떨어뜨립니다. 예상되는 쿼리 패턴에 맞도록 세분성을 신중하게 선택해야 합니다.
-
차원 폭증(Dimension Explosion) 많은 그룹화 차원을 추가하면 뷰의 크기가 크게 증가하고 효율성이 떨어질 수 있습니다. 뷰에는 일반적으로 자주 사용되는 그룹화 및 필터링 컬럼만 포함하는 것이 좋습니다.
-
뷰 개수 확장성 제한 각 materialized view는 삽입 시점 오버헤드를 추가하고 머지(merge) 압력을 증가시킵니다. 뷰를 너무 많이 생성하면 수집 성능과 백그라운드 머지 작업에 부정적인 영향을 줄 수 있습니다.
이러한 한계를 인지하면 materialized view를 실제로 이점이 있는 곳에만 적용하고, 눈치채지 못한 채 느린 소스 테이블 쿼리로 되돌아가는 구성을 피하는 데 도움이 됩니다.
문제 해결
materialized view가 사용되지 않는 경우
확인 1: 날짜 범위
- 최적화 모달을 열어 「Date range not supported.」가 표시되는지 확인합니다.
- 쿼리 날짜 범위가 materialized view의 최소 날짜보다 이후 시점인지 확인합니다.
- materialized view가 모든 과거 데이터를 포함하는 경우 최소 날짜를 제거합니다.
확인 2: 그라뉼러리티(granularity)
- 차트 그라뉼러리티가 MV 그라뉼러리티의 배수인지 확인합니다.
- 차트를 「Auto」로 설정하거나 호환되는 그라뉼러리티를 수동으로 선택해 봅니다.
확인 3: 집계(aggregations)
- 차트에서 MV에 포함된 집계를 사용하는지 확인합니다.
- 최적화 모달에서 「Available aggregated columns」를 검토합니다.
확인 4: 차원(dimensions)
- GROUP BY 컬럼이 MV의 차원 컬럼에 포함되어 있는지 확인합니다.
- 최적화 모달에서 「Available group/filter columns」를 확인합니다.
materialized view 쿼리가 느림
문제 1: materialized view의 세분화 단위가 너무 작음
- 세분화 단위가 너무 작아(예: 1초) MV의 행 수가 과도하게 많습니다.
- 해결 방법: 더 큰 세분화 단위를 사용하는 MV를 만듭니다(예: 1분 또는 1시간).
문제 2: 차원이 너무 많음
- 차원 컬럼이 많아 MV의 카디널리티가 높습니다.
- 해결 방법: 가장 자주 사용하는 컬럼 위주로 차원 컬럼 수를 줄입니다.
문제 3: 행 수가 많은 MV가 여러 개 존재
- 시스템에서 각 MV에 대해
EXPLAIN을 실행합니다. - 해결 방법: 거의 사용하지 않거나 항상 건너뛰는 MV는 제거합니다.
Configuration errors
Error: 「집계 컬럼이 최소 한 개 이상 필요합니다」
- MV 설정에 집계 컬럼을 최소 한 개 이상 추가하십시오.
Error: 「count 이외의 집계에는 소스 컬럼이 필요합니다」
- 어떤 컬럼을 집계할지 지정하십시오(count만 소스 컬럼을 생략할 수 있습니다).
Error: 「잘못된 granularity 형식입니다」
- 드롭다운에서 미리 설정된 granularity 중 하나를 사용하십시오.
- 형식은 유효한 SQL interval이어야 합니다(예:
1 h가 아니라1 hour).
