조인을 최소화하고 최적화하기
ClickHouse는 다양한 유형과 알고리즘의 JOIN을 지원하며, 최근 릴리스에서 JOIN 성능이 크게 향상되었습니다. 그러나 JOIN은 본질적으로 단일 비정규화된 테이블에서 쿼리하는 것보다 비용이 더 큽니다. 비정규화는 계산 작업을 쿼리 시점에서 INSERT 또는 사전 처리(pre-processing) 시점으로 이전하여, 런타임 지연 시간을 크게 줄이는 결과를 가져오는 경우가 많습니다. 실시간 또는 지연 시간에 민감한 분석 쿼리에는 비정규화를 강력히 권장합니다.
일반적으로 다음과 같은 경우 비정규화를 수행하는 것이 좋습니다:
- 테이블 변경이 드물거나 배치 단위 갱신이 허용 가능한 경우.
- 관계가 다대다(many-to-many)가 아니거나 카디널리티가 지나치게 높지 않은 경우.
- 쿼리되는 컬럼의 제한된 부분 집합만 필요한 경우, 즉 특정 컬럼은 비정규화에서 제외할 수 있는 경우.
- ClickHouse 외부의 Flink와 같은 상위(upstream) 시스템으로 처리를 이전하여 실시간 보강(enrichment)이나 평탄화(flattening)를 관리할 수 있는 역량이 있는 경우.
모든 데이터를 비정규화할 필요는 없으며, 자주 쿼리되는 속성에 집중하면 됩니다. 또한 전체 서브 테이블을 중복하는 대신 집계를 점진적으로 계산하기 위해 materialized view를 사용하는 것도 고려하십시오. 스키마 변경이 드물고 지연 시간이 중요한 경우, 비정규화는 가장 우수한 성능 트레이드오프를 제공합니다.
ClickHouse에서 데이터를 비정규화하는 전체 가이드는 여기를 참고하십시오.
When JOINs are required
JOIN이 필요한 경우 최소 24.12 버전, 가능하면 최신 버전을 사용해야 합니다. JOIN 성능은 각 릴리스마다 계속 개선되고 있습니다. ClickHouse 24.12부터는 쿼리 플래너가 자동으로 더 작은 테이블을 JOIN의 오른쪽에 배치하여 최적의 성능을 제공합니다. 이전에는 이 작업을 수동으로 수행해야 했습니다. 앞으로는 더욱 적극적인 필터 푸시다운과 다중 JOIN의 자동 재정렬 등 추가적인 개선 사항도 도입될 예정입니다.
JOIN 성능을 향상시키기 위한 모범 사례는 다음과 같습니다:
- 카테시안 곱을 피하십시오: 왼쪽의 값 하나가 오른쪽의 여러 값과 일치하면, JOIN은 이른바 카테시안 곱이라 불리는 여러 행을 반환합니다. 사용 사례에서 오른쪽의 모든 일치 항목이 아니라 임의의 하나만 있으면 되는 경우에는
ANYJOIN(예:LEFT ANY JOIN)을 사용할 수 있습니다. 일반적인 JOIN보다 더 빠르고 메모리 사용량도 적습니다. - JOIN에 사용되는 테이블의 크기를 줄이십시오: JOIN의 실행 시간과 메모리 사용량은 왼쪽 테이블과 오른쪽 테이블의 크기에 비례하여 증가합니다. JOIN이 처리하는 데이터 양을 줄이기 위해, 쿼리의
WHERE또는JOIN ON절에 추가 필터 조건을 추가하십시오. ClickHouse는 일반적으로 JOIN 이전에, 쿼리 플랜 내에서 가능한 한 깊은 단계까지 필터 조건을 푸시다운합니다. 필터가 어떤 이유로든 자동으로 푸시다운되지 않는 경우, JOIN의 한쪽을 서브쿼리로 다시 작성하여 푸시다운을 강제할 수 있습니다. - 적절한 경우 딕셔너리를 통한 직접 JOIN을 사용하십시오: ClickHouse의 표준 JOIN은 두 단계로 실행됩니다. 먼저 오른쪽을 순회하며 해시 테이블을 생성하는 build 단계, 이어서 왼쪽을 순회하며 해시 테이블 조회를 통해 일치하는 조인 파트너를 찾는 probe 단계입니다. 오른쪽이 딕셔너리이거나 EmbeddedRocksDB 또는 Join table engine처럼 키-값 특성을 가진 다른 테이블 엔진인 경우, ClickHouse는 사실상 해시 테이블을 생성할 필요를 제거하는 「direct」 JOIN 알고리즘을 사용하여 쿼리 처리를 가속화할 수 있습니다. 이는
INNER및LEFT OUTERJOIN에서 동작하며, 실시간 분석 워크로드에 권장됩니다. - JOIN에서 테이블 정렬을 활용하십시오: ClickHouse의 각 테이블은 테이블의 기본 키 컬럼 기준으로 정렬되어 있습니다.
full_sorting_merge및partial_merge와 같은 소위 sort-merge JOIN 알고리즘을 사용하여 이 정렬을 활용할 수 있습니다. 해시 테이블에 기반한 표준 JOIN 알고리즘(parallel_hash,hash,grace_hash등, 아래 참조)과 달리, sort-merge JOIN 알고리즘은 두 테이블을 먼저 정렬한 후 병합합니다. 쿼리가 양쪽 테이블을 각각의 기본 키 컬럼으로 JOIN하는 경우, sort-merge JOIN 알고리즘에는 정렬 단계를 생략하는 최적화가 적용되어 처리 시간과 오버헤드를 절감합니다. - 디스크로 스필(spill)되는 JOIN을 피하십시오: JOIN의 중간 상태(예: 해시 테이블)가 너무 커져서 메인 메모리에 더 이상 들어가지 않을 수 있습니다. 이 경우 기본적으로 ClickHouse는 메모리 부족 오류를 반환합니다. 일부 JOIN 알고리즘(예:
grace_hash,partial_merge,full_sorting_merge; 아래 참조)은 중간 상태를 디스크로 스필하면서 쿼리 실행을 계속할 수 있습니다. 그러나 디스크 접근은 JOIN 처리를 크게 느리게 만들 수 있으므로, 이러한 JOIN 알고리즘은 신중하게 사용해야 합니다. 대신, 중간 상태의 크기를 줄이기 위해 JOIN 쿼리를 다른 방식으로 최적화하는 것을 권장합니다. - 외부 JOIN에서 매칭 실패 마커로 기본값 사용:
LEFT/RIGHT/FULLOUTER JOIN은 각각 왼쪽/오른쪽/양쪽 테이블의 모든 값을 포함합니다. 어떤 값에 대해 다른 테이블에서 JOIN 파트너를 찾지 못하는 경우, ClickHouse는 JOIN 파트너를 특수 마커로 대체합니다. SQL 표준은 데이터베이스가 이러한 마커로 NULL을 사용하도록 규정합니다. ClickHouse에서는 결과 컬럼을 널 허용(Nullable)로 감싸야 하며, 이로 인해 추가적인 메모리 및 성능 오버헤드가 발생합니다. 대안으로join_use_nulls = 0설정을 구성하고, 결과 컬럼 데이터 타입의 기본값을 마커로 사용할 수 있습니다.
ClickHouse에서 JOIN을 위해 딕셔너리를 사용할 때는, 설계상 딕셔너리는 중복 키를 허용하지 않는다는 점을 이해하는 것이 중요합니다. 데이터 로딩 시 중복 키는 별도 경고 없이 자동으로 중복 제거되며, 특정 키에 대해 마지막으로 로드된 값만 유지됩니다. 이러한 동작 방식 때문에 딕셔너리는 최신 값 또는 신뢰할 수 있는 기준 값만 필요로 하는 일대일 또는 다대일 관계에 이상적입니다. 그러나 일대다 또는 다대다 관계(예: 한 배우가 여러 역할을 가질 수 있는 경우, 배우와 역할을 조인하는 상황)에 딕셔너리를 사용할 경우, 일치하는 행 중 하나를 제외한 나머지가 모두 버려져 눈에 띄지 않게 데이터가 손실됩니다. 따라서 딕셔너리는 여러 건의 매칭에 대해 완전한 관계형 정합성이 필요한 시나리오에는 적합하지 않습니다.
올바른 JOIN 알고리즘 선택
ClickHouse는 속도와 메모리 사용량 간에 트레이드오프가 있는 여러 JOIN 알고리즘을 지원합니다.
- Parallel Hash JOIN(기본값): 메모리에 적재될 수 있는 소규모에서 중간 규모의 오른쪽 테이블에 대해 빠릅니다.
- Direct JOIN: 딕셔너리(또는 키-값 특성을 가진 다른 테이블 엔진)를
INNER또는LEFT ANY JOIN과 함께 사용할 때 이상적입니다. 해시 테이블을 구성할 필요가 없어 포인트 조회에 가장 빠른 방식입니다. - Full Sorting Merge JOIN: 두 테이블이 조인 키로 정렬되어 있을 때 효율적입니다.
- Partial Merge JOIN: 메모리 사용량을 최소화하지만 더 느립니다. 제한된 메모리로 대용량 테이블을 조인할 때 가장 적합합니다.
- Grace Hash JOIN: 유연하고 메모리 튜닝이 가능하여, 성능 특성을 조정할 수 있는 대용량 데이터셋에 적합합니다.
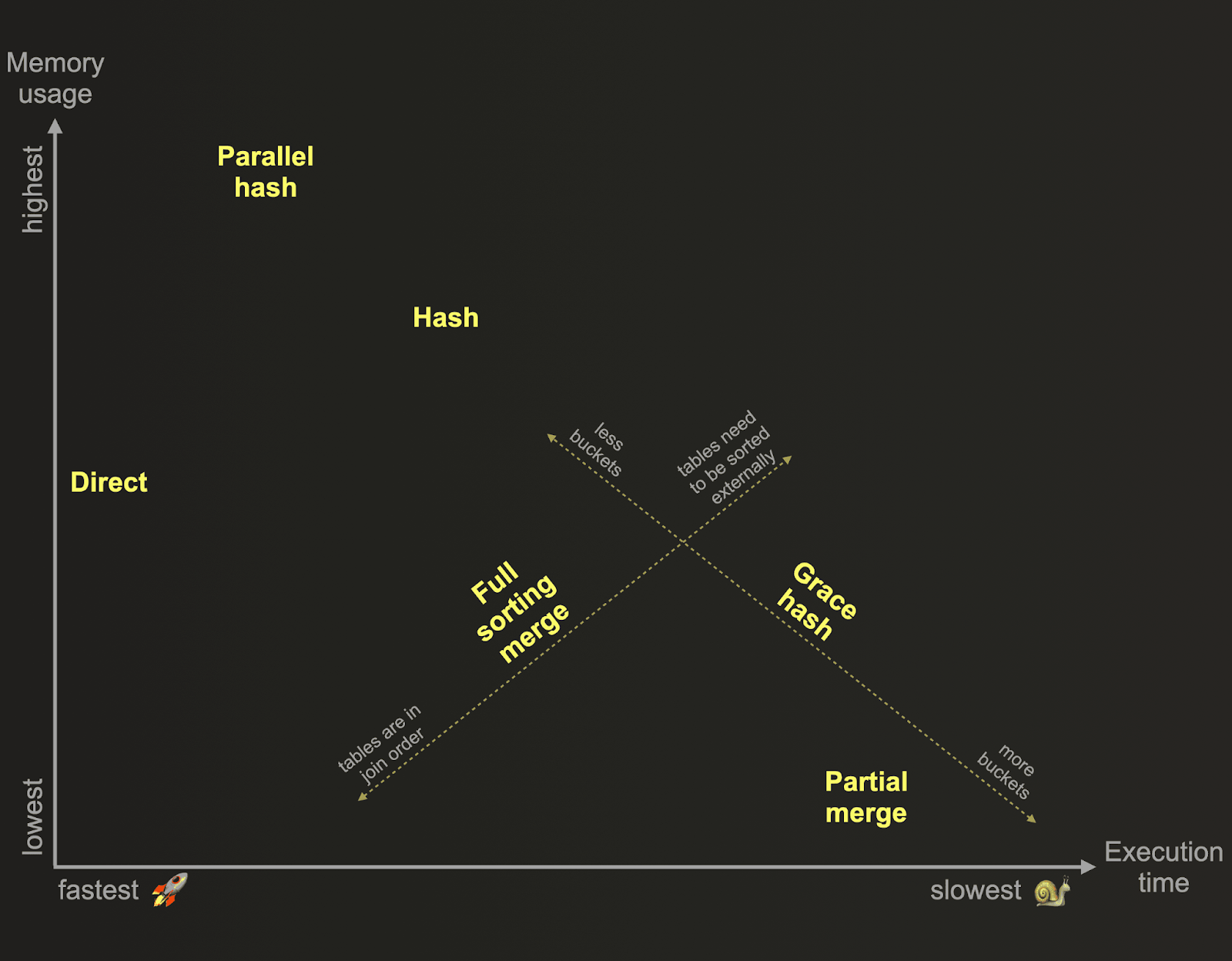
각 알고리즘은 지원하는 JOIN 타입이 다릅니다. 알고리즘별로 지원되는 조인 타입의 전체 목록은 여기에서 확인할 수 있습니다.
join_algorithm = 'auto'(기본값)로 설정하여 ClickHouse가 최적의 알고리즘을 선택하도록 하거나, 워크로드에 따라 명시적으로 제어할 수 있습니다. 성능 또는 메모리 오버헤드를 최적화하기 위해 조인 알고리즘을 선택해야 하는 경우 이 가이드를 참고하는 것이 좋습니다.
최적의 성능을 위해서는 다음을 권장합니다.
- 고성능 워크로드에서는 JOIN 사용을 최소화합니다.
- 쿼리당 3–4개를 초과하는 조인은 피합니다.
- 실제 데이터에서 서로 다른 알고리즘을 벤치마크하십시오. 성능은 JOIN 키 분포와 데이터 크기에 따라 달라집니다.
JOIN 최적화 전략, JOIN 알고리즘, 그리고 튜닝 방법에 대한 자세한 내용은 ClickHouse 문서 및 이 블로그 시리즈를 참고하십시오.
