데이터 스키핑 인덱스는 이전에 제시한 모범 사례(예: 타입 최적화, 적절한 기본 키(primary key) 선택, materialized view 활용 등)가 충실히 적용된 이후에 고려하는 것이 좋습니다. 스키핑 인덱스를 처음 사용하는 경우에는 이 가이드부터 시작하는 것이 좋습니다.
이러한 유형의 인덱스는 동작 방식에 대한 이해를 바탕으로 주의 깊게 사용하면 쿼리 성능을 가속하는 데 활용할 수 있습니다.
ClickHouse는 데이터 스키핑 인덱스(data skipping indices) 라는 강력한 메커니즘을 제공하여 쿼리 실행 시 스캔해야 하는 데이터 양을 극적으로 줄일 수 있습니다. 이는 특히 특정 필터 조건에 대해 기본 키가 유용하지 않을 때 효과적입니다. row 기반 보조 인덱스(B-tree 등)에 의존하는 전통적인 데이터베이스와 달리, ClickHouse는 컬럼 스토어이며 이러한 구조를 지원하는 방식으로 row 위치를 저장하지 않습니다. 대신, 쿼리의 필터링 조건과 일치하지 않는 것이 보장되는 데이터 블록을 읽지 않도록 도와주는 스킵 인덱스를 사용합니다.
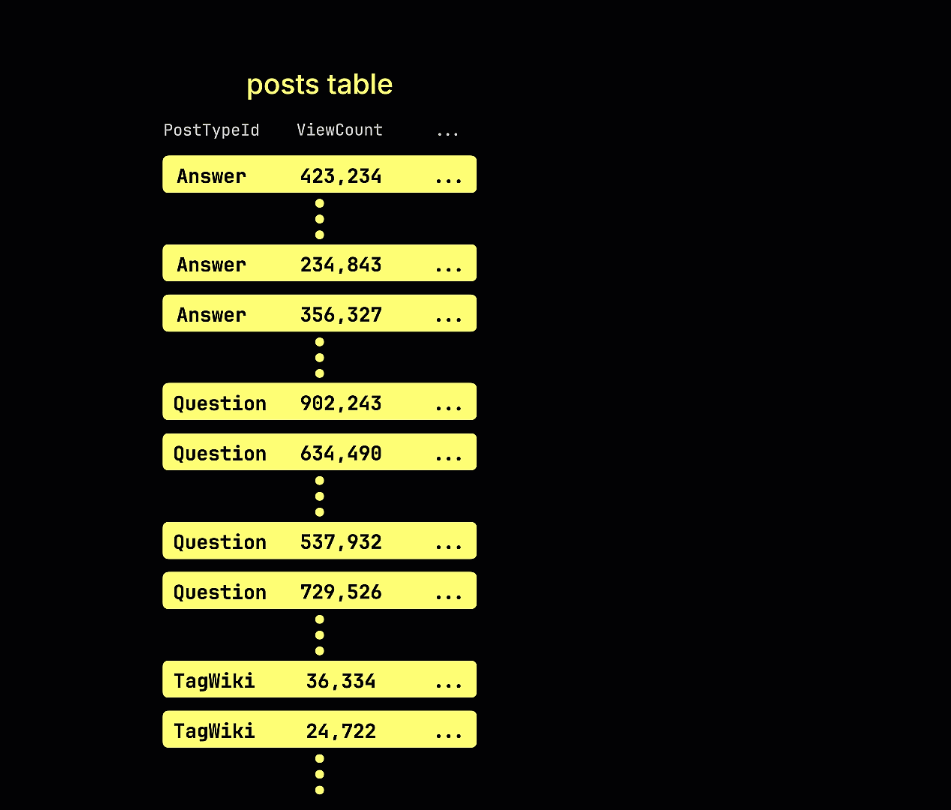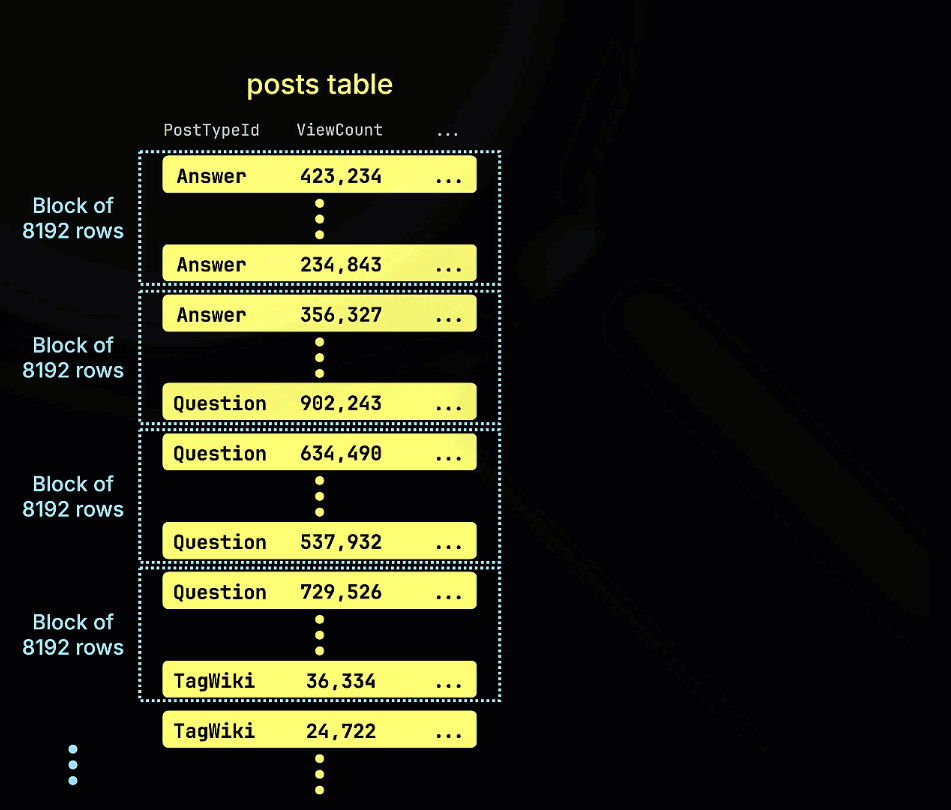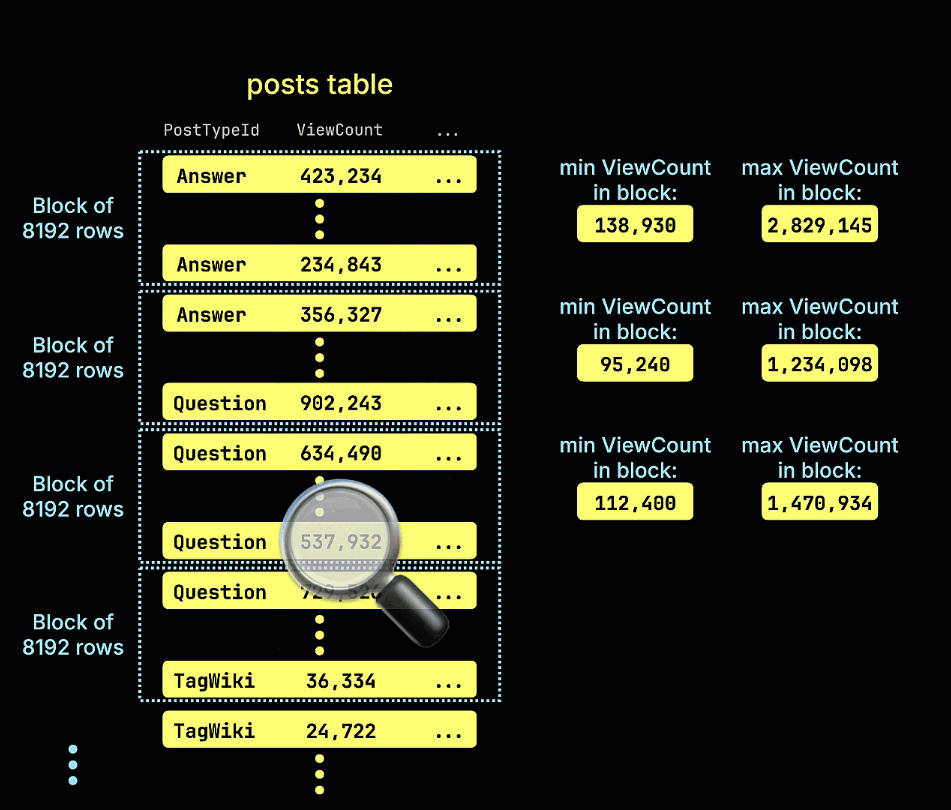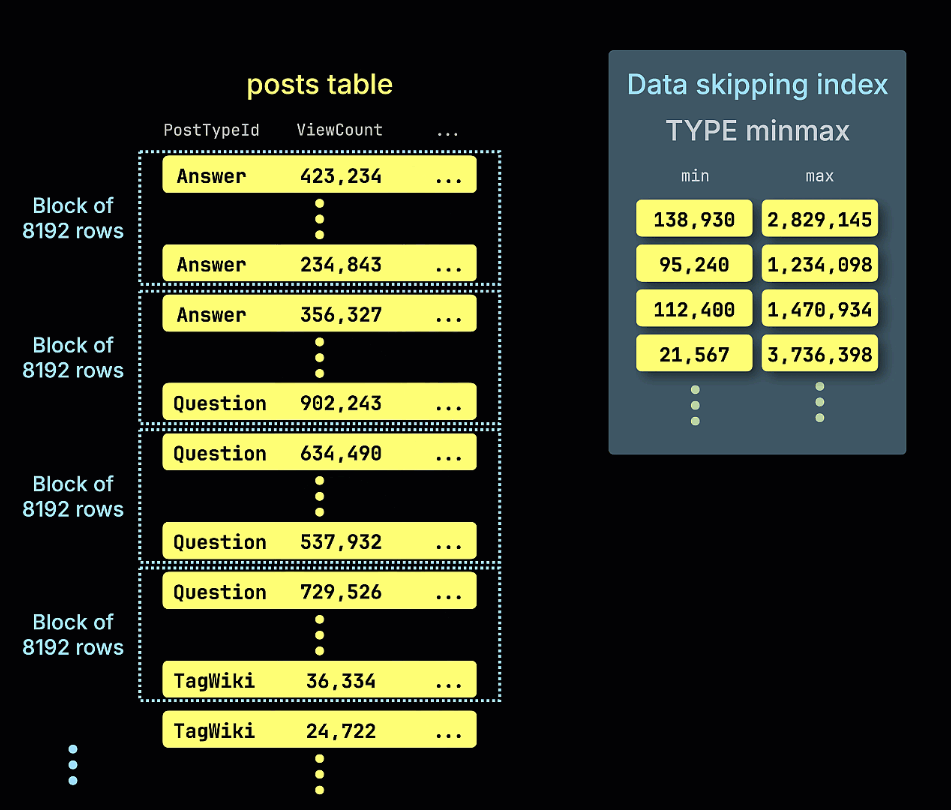
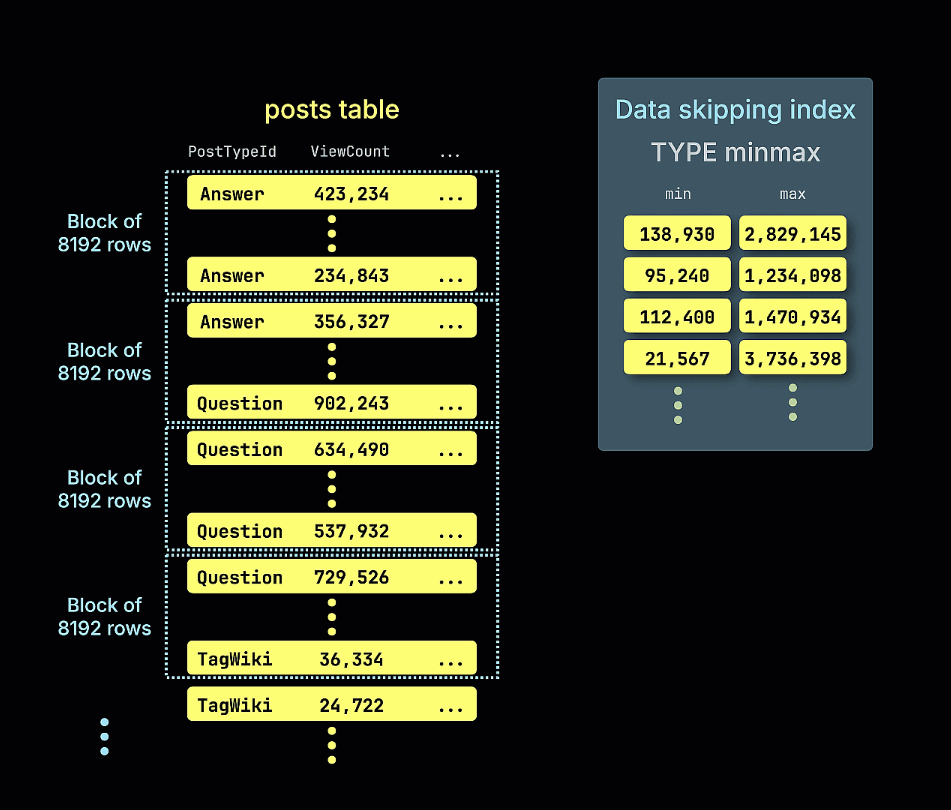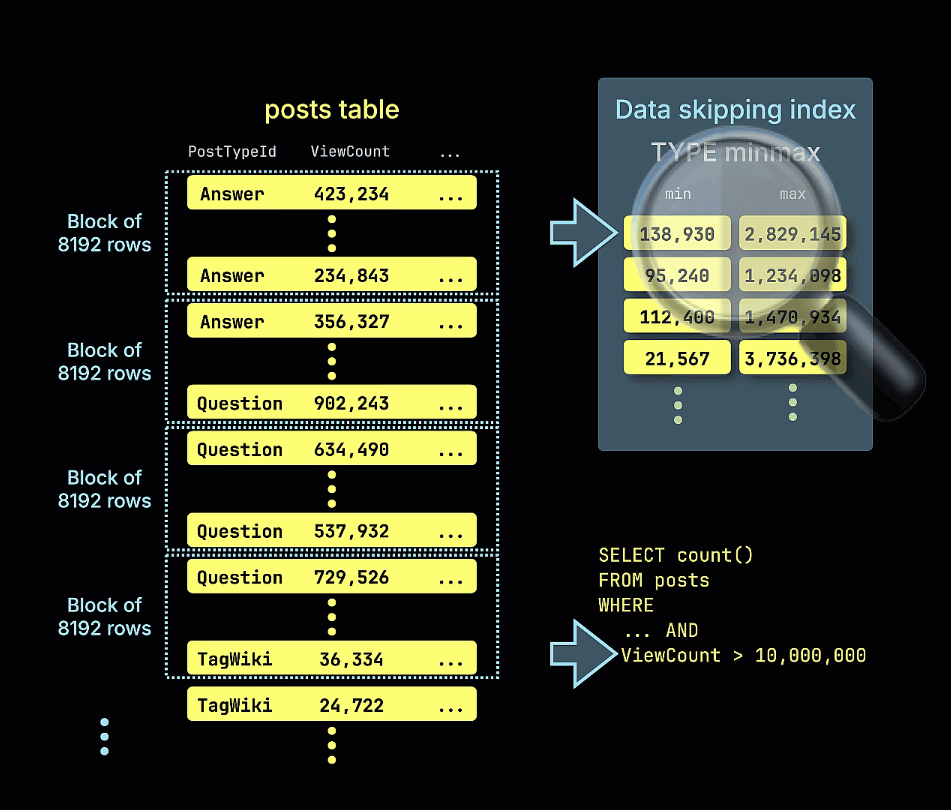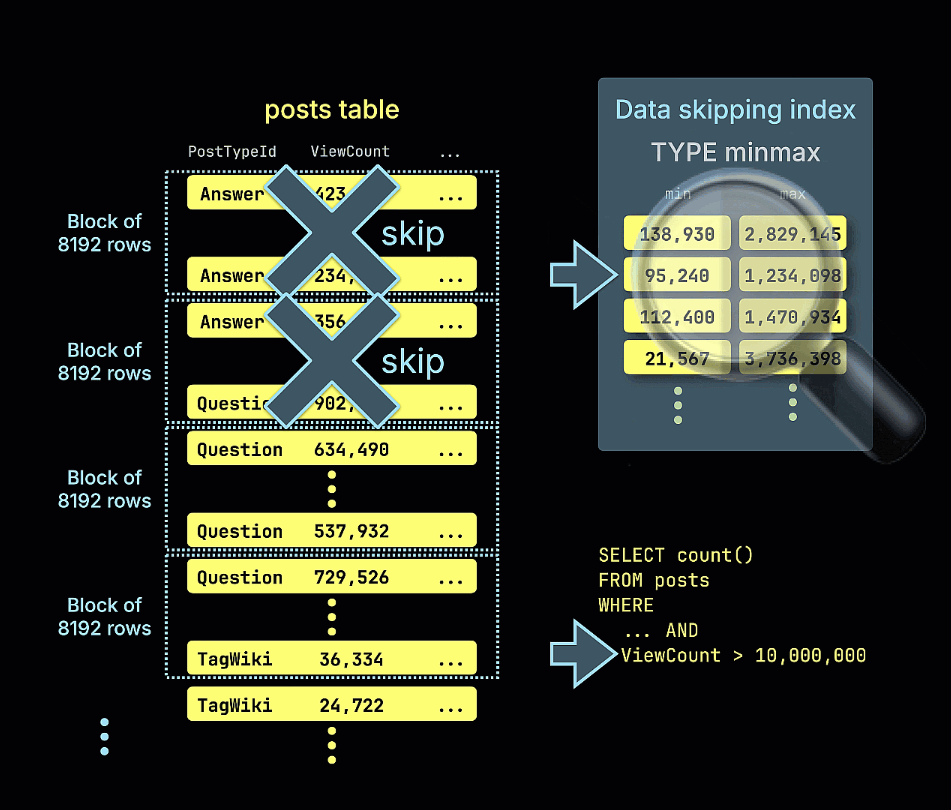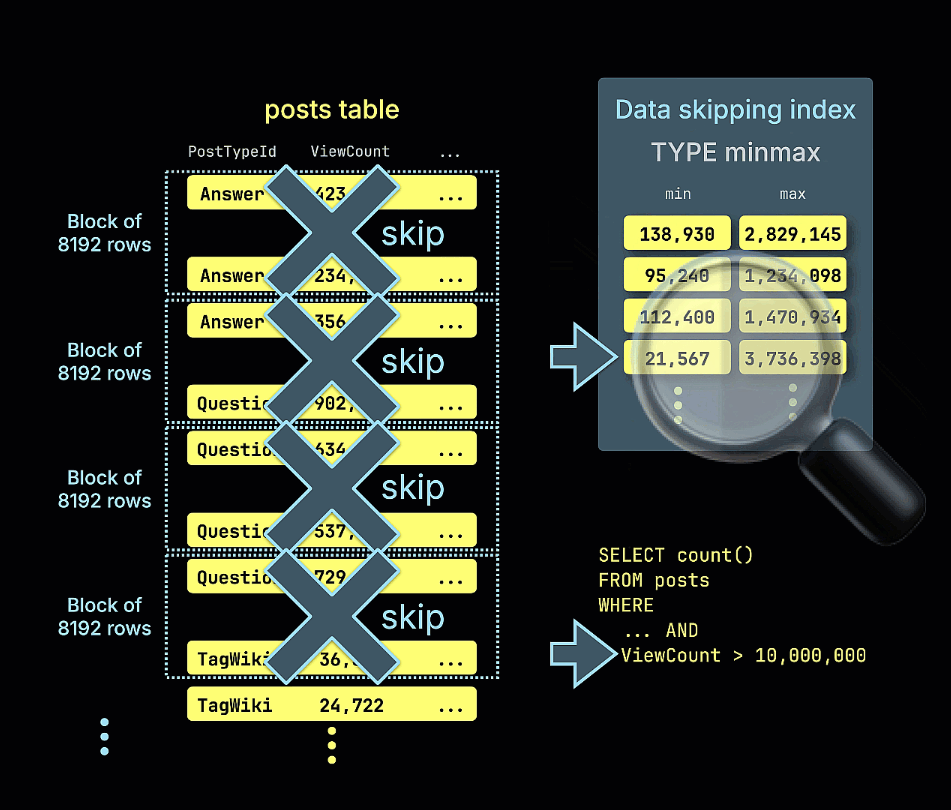
스킵 인덱스는 각 데이터 블록에 대한 메타데이터(예: 최소/최대 값, 값 집합, 블룸 필터 표현 등)를 저장하고, 쿼리 실행 시 이 메타데이터를 사용하여 어떤 데이터 블록을 완전히 건너뛸 수 있는지 판단하는 방식으로 동작합니다. 이 인덱스는 MergeTree 패밀리 테이블 엔진에만 적용되며, 표현식(expression), 인덱스 타입, 이름, 그리고 각 인덱싱 블록의 크기를 정의하는 granularity로 정의됩니다. 이 인덱스는 테이블 데이터와 함께 저장되며, 쿼리의 필터가 인덱스 표현식과 일치할 때 참조됩니다.
데이터 스키핑 인덱스에는 여러 유형이 있으며, 각각 서로 다른 종류의 쿼리와 데이터 분포에 적합합니다:
- minmax: 블록당 표현식의 최소값과 최대값을 추적합니다. 느슨하게 정렬된 데이터에서 범위 쿼리에 적합합니다.
- set(N): 각 블록에 대해 최대 N개까지의 값 집합을 추적합니다. 블록 내 낮은 카디널리티(low cardinality)를 가진 컬럼에 효과적입니다.
- bloom_filter: 값이 블록 내에 존재하는지를 확률적으로 판별하여 집합 포함 여부에 대한 빠른 근사 필터링을 제공합니다. 양의 일치가 필요한, 「건초 더미에서 바늘 찾기」 유형의 쿼리 최적화에 효과적입니다.
- tokenbf_v1 / ngrambf_v1: 문자열 내 토큰 또는 문자 시퀀스를 검색하도록 설계된 특수한 블룸 필터 변형입니다. 특히 로그 데이터나 텍스트 검색 사용 사례에 유용합니다.
스킵 인덱스는 강력하지만 주의해서 사용해야 합니다. 의미 있는 수의 데이터 블록을 제거할 때에만 이점이 있으며, 쿼리나 데이터 구조가 이에 부합하지 않으면 오히려 오버헤드를 초래할 수 있습니다. 블록 내에 단 하나의 일치하는 값만 존재하더라도 해당 블록 전체는 여전히 읽어야 합니다.
효과적인 스킵 인덱스 사용은 인덱싱된 컬럼과 테이블의 기본 키 간의 강한 상관관계가 있거나, 유사한 값이 서로 모이도록 데이터를 삽입하는 방식에 크게 의존하는 경우가 많습니다.
일반적으로 데이터 스키핑 인덱스는 적절한 기본 키 설계와 타입 최적화를 먼저 보장한 이후에 적용하는 것이 가장 좋습니다. 특히 다음과 같은 경우에 유용합니다:
- 전체적으로는 카디널리티가 높지만 블록 내 카디널리티는 낮은 컬럼.
- 검색에 중요하지만 발생 빈도가 낮은 값(예: 오류 코드, 특정 ID).
- 로컬라이즈된 분포를 가진 비-기본 키 컬럼에 대해 필터링이 수행되는 경우.
다음 사항을 항상 수행하십시오:
- 실제 데이터와 현실적인 쿼리로 스킵 인덱스를 테스트하십시오. 서로 다른 인덱스 타입과 granularity 값을 시도해 보십시오.
send_logs_level='trace' 및 EXPLAIN indexes=1 과 같은 도구를 사용하여 인덱스 효과를 확인하고 영향을 평가하십시오.- 항상 인덱스 크기와 granularity에 따른 영향을 평가하십시오. granularity 크기를 줄이면 일반적으로 어느 정도까지는 더 많은 그래뉼을 필터링하여 스캔 대상에서 제외함으로써 성능이 향상됩니다. 그러나 granularity가 낮아져 인덱스 크기가 커지면 성능이 저하될 수도 있습니다. 다양한 granularity 값에 대해 성능과 인덱스 크기를 측정하십시오. 이는 특히 블룸 필터 인덱스에서 중요합니다.
적절히 사용하면 스킵 인덱스는 상당한 성능 향상을 제공할 수 있지만, 맹목적으로 사용하면 불필요한 비용을 추가할 수 있습니다.
데이터 스키핑 인덱스에 대한 보다 자세한 가이드는 여기에서 확인할 수 있습니다.
다음은 최적화된 테이블 예시입니다. 이 테이블에는 Stack Overflow 데이터가 저장되어 있으며, 게시물 하나당 행 하나가 있습니다.
CREATE TABLE stackoverflow.posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`Score` Int32,
`ViewCount` UInt32 CODEC(Delta(4), ZSTD(1)),
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`LastActivityDate` DateTime64(3, 'UTC'),
`Title` String,
`Tags` String,
`AnswerCount` UInt16 CODEC(Delta(2), ZSTD(1)),
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime64(3, 'UTC'),
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = MergeTree
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate))
이 테이블은 게시물 유형과 날짜별로 필터링하고 집계하는 쿼리에 최적화되어 있습니다. 2009년 이후에 게시된 게시물 중 조회 수가 10,000,000회를 넘는 게시물의 개수를 세고자 한다고 가정해 보겠습니다.
SELECT count()
FROM stackoverflow.posts
WHERE (CreationDate > '2009-01-01') AND (ViewCount > 10000000)
┌─count()─┐
│ 5 │
└─────────┘
1 row in set. Elapsed: 0.720 sec. Processed 59.55 million rows, 230.23 MB (82.66 million rows/s., 319.56 MB/s.)
이 쿼리는 기본 인덱스를 사용해 일부 행(및 그래뉼)을 제외할 수 있습니다. 그러나 위의 응답과 아래의 EXPLAIN indexes = 1에서 볼 수 있듯이, 대부분의 행은 여전히 읽어야 합니다.
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts
WHERE (CreationDate > '2009-01-01') AND (ViewCount > 10000000)
LIMIT 1
┌─explain──────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Limit (preliminary LIMIT (without OFFSET)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts) │
│ Indexes: │
│ MinMax │
│ Keys: │
│ CreationDate │
│ Condition: (CreationDate in ('1230768000', +Inf)) │
│ Parts: 123/128 │
│ Granules: 8513/8545 │
│ Partition │
│ Keys: │
│ toYear(CreationDate) │
│ Condition: (toYear(CreationDate) in [2009, +Inf)) │
│ Parts: 123/123 │
│ Granules: 8513/8513 │
│ PrimaryKey │
│ Keys: │
│ toDate(CreationDate) │
│ Condition: (toDate(CreationDate) in [14245, +Inf)) │
│ Parts: 123/123 │
│ Granules: 8513/8513 │
└──────────────────────────────────────────────────────────────────┘
25 rows in set. Elapsed: 0.070 sec.
간단한 분석을 통해 ViewCount가 기본 키인 CreationDate와 상관관계가 있음을 알 수 있습니다. 게시물이 존재하는 기간이 길수록 조회될 수 있는 시간도 더 길어지기 때문입니다.
SELECT toDate(CreationDate) AS day, avg(ViewCount) AS view_count FROM stackoverflow.posts WHERE day > '2009-01-01' GROUP BY day
따라서 이는 데이터 스키핑 인덱스로 활용하기에 논리적으로도 적절한 선택입니다. 숫자 타입이므로 minmax 인덱스를 사용하는 것이 합리적입니다. 다음 ALTER TABLE 명령으로 인덱스를 추가합니다. 먼저 인덱스를 추가한 다음, 이어서 이를 「구체화(materialize)」합니다.
ALTER TABLE stackoverflow.posts
(ADD INDEX view_count_idx ViewCount TYPE minmax GRANULARITY 1);
ALTER TABLE stackoverflow.posts MATERIALIZE INDEX view_count_idx;
이 인덱스는 테이블을 처음 생성할 때 함께 추가할 수도 있습니다. DDL의 일부로 minmax 인덱스가 정의된 스키마는 다음과 같습니다:
CREATE TABLE stackoverflow.posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`Score` Int32,
`ViewCount` UInt32 CODEC(Delta(4), ZSTD(1)),
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`LastActivityDate` DateTime64(3, 'UTC'),
`Title` String,
`Tags` String,
`AnswerCount` UInt16 CODEC(Delta(2), ZSTD(1)),
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime64(3, 'UTC'),
`ClosedDate` DateTime64(3, 'UTC'),
INDEX view_count_idx ViewCount TYPE minmax GRANULARITY 1 --index here
)
ENGINE = MergeTree
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate))
다음 애니메이션은 예시 테이블에 대해 minmax 스키핑 인덱스를 구축하는 과정을 보여주며, 테이블의 각 행 블록(granule)에 대해 ViewCount의 최소값과 최대값을 추적하는 방식을 설명합니다:
앞에서 실행했던 쿼리를 다시 실행해 보면 성능이 크게 향상된 것을 확인할 수 있습니다. 스캔된 행 수가 줄어든 점에 주목하십시오:
SELECT count()
FROM stackoverflow.posts
WHERE (CreationDate > '2009-01-01') AND (ViewCount > 10000000)
┌─count()─┐
│ 5 │
└─────────┘
1 row in set. Elapsed: 0.012 sec. Processed 39.11 thousand rows, 321.39 KB (3.40 million rows/s., 27.93 MB/s.)
EXPLAIN indexes = 1을 실행하면 인덱스가 사용되고 있음을 확인할 수 있습니다.
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts
WHERE (CreationDate > '2009-01-01') AND (ViewCount > 10000000)
┌─explain────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts) │
│ Indexes: │
│ MinMax │
│ Keys: │
│ CreationDate │
│ Condition: (CreationDate in ('1230768000', +Inf)) │
│ Parts: 123/128 │
│ Granules: 8513/8545 │
│ Partition │
│ Keys: │
│ toYear(CreationDate) │
│ Condition: (toYear(CreationDate) in [2009, +Inf)) │
│ Parts: 123/123 │
│ Granules: 8513/8513 │
│ PrimaryKey │
│ Keys: │
│ toDate(CreationDate) │
│ Condition: (toDate(CreationDate) in [14245, +Inf)) │
│ Parts: 123/123 │
│ Granules: 8513/8513 │
│ Skip │
│ Name: view_count_idx │
│ Description: minmax GRANULARITY 1 │
│ Parts: 5/123 │
│ Granules: 23/8513 │
└────────────────────────────────────────────────────────────────────┘
29 rows in set. Elapsed: 0.211 sec.
예제 쿼리에서 ViewCount > 10,000,000 조건에 대해 minmax 스키핑 인덱스가 일치할 수 없는 모든 행 블록을 어떻게 제거(prune)하는지를 보여주는 애니메이션도 제공합니다: