materialized view 활용하기
ClickHouse는 두 가지 유형의 materialized view를 지원합니다: incremental 및 refreshable. 두 유형 모두 결과를 미리 계산하여 저장함으로써 쿼리를 가속화하도록 설계되었지만, 기본 쿼리가 실행되는 방식과 시점, 적합한 워크로드, 데이터 최신성을 처리하는 방식에서 크게 다릅니다.
materialized view는 가속이 필요한 특정 쿼리 패턴에 대해 사용하는 것이 좋으며, 그에 앞서 데이터 타입 선택과 관련된 모범 사례와 프라이머리 키 최적화를 이미 적용했다고 가정합니다.
증분형 materialized view는 실시간으로 갱신됩니다. 새 데이터가 소스 테이블에 삽입되면 ClickHouse는 materialized view의 쿼리를 새 데이터 블록에 자동으로 적용하고, 결과를 별도의 대상 테이블에 기록합니다. 시간이 지나면서 ClickHouse는 이러한 부분 결과를 병합하여 완전하고 최신 상태의 뷰를 생성합니다. 이 접근 방식은 계산 비용을 삽입 시점으로 옮기고 새 데이터만 처리하므로 매우 효율적입니다. 그 결과, 대상 테이블에 대한 SELECT 쿼리는 빠르고 가볍게 실행됩니다. 증분형 뷰는 모든 집계 함수를 지원하며, 각 쿼리가 삽입 중인 데이터셋의 최근 작은 부분 집합에 대해서만 동작하므로 페타바이트 규모의 데이터까지도 잘 확장됩니다.

갱신 가능 구체화 뷰, 즉 refreshable materialized view는 이에 반해 일정에 따라 갱신됩니다. 이러한 뷰는 전체 쿼리를 주기적으로 다시 실행하고, 그 결과로 대상 테이블의 내용을 덮어씁니다. 이는 Postgres와 같은 전통적인 OLTP 데이터베이스의 materialized view와 유사합니다.
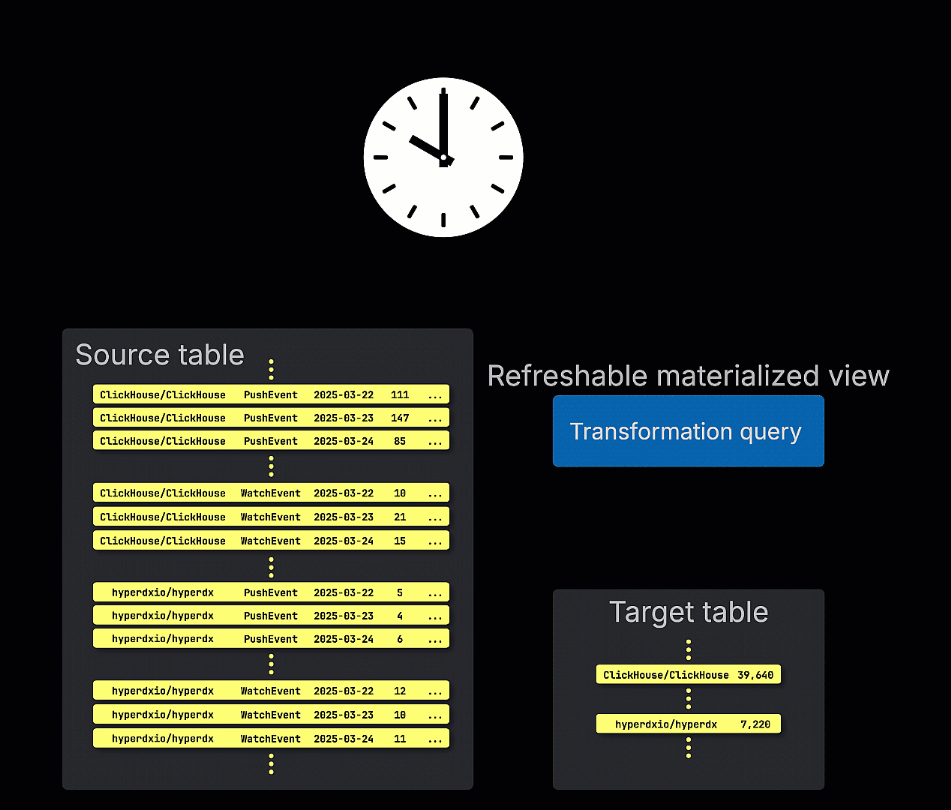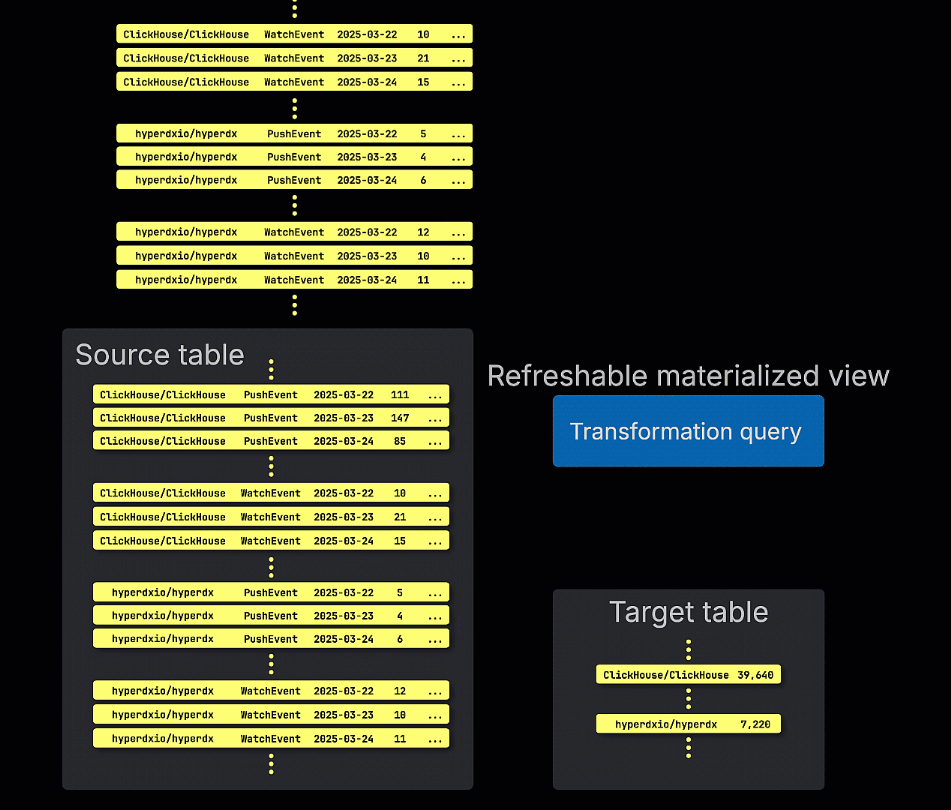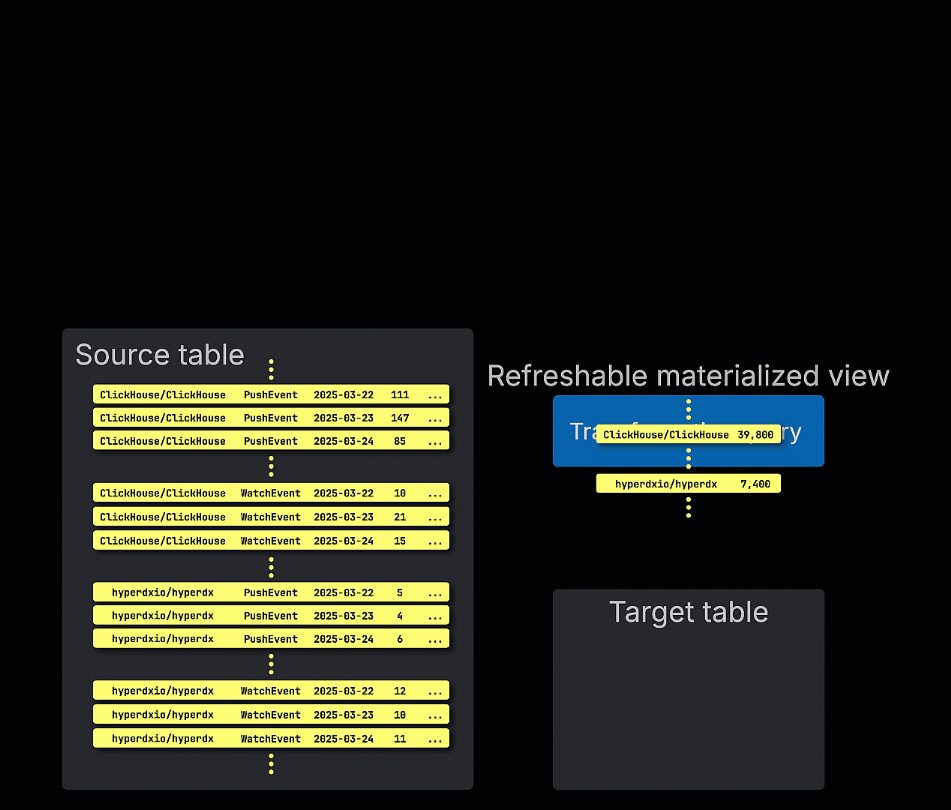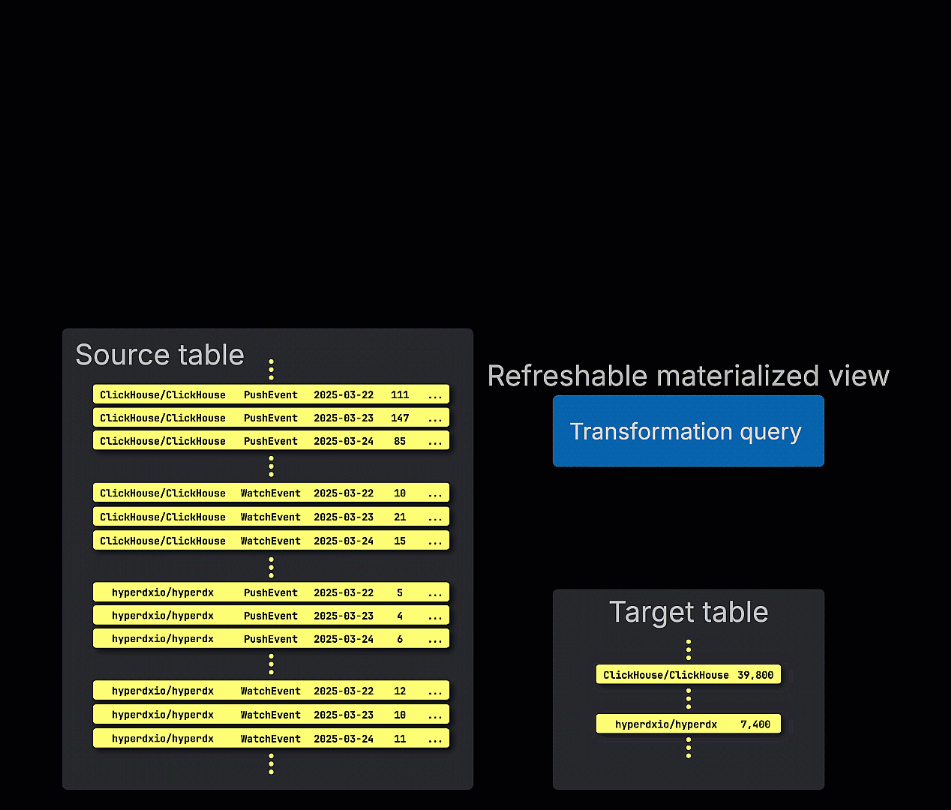
증분형 및 갱신 가능 구체화 뷰 중 어떤 방식을 선택할지는 쿼리의 특성, 데이터 변경 빈도, 삽입 시점마다 뷰가 모든 행을 즉시 반영해야 하는지, 아니면 주기적인 갱신으로 충분한지에 크게 좌우됩니다. 이러한 트레이드오프를 이해하는 것이 ClickHouse에서 성능이 뛰어나고 확장 가능한 materialized view를 설계하는 핵심입니다.
증분형 materialized view를 사용해야 하는 경우
증분형 materialized view는 일반적으로 권장되며, 소스 테이블에 새 데이터가 삽입될 때마다 실시간으로 자동 업데이트됩니다. 모든 집계 함수(aggregation function)를 지원하며, 특히 단일 테이블에 대한 집계에서 매우 효과적입니다. 결과를 삽입 시점에 증분 방식으로 계산하므로, 쿼리는 훨씬 더 작은 데이터 부분 집합에 대해 수행되며, 이를 통해 이 뷰는 데이터가 페타바이트 규모로 증가하더라도 손쉽게 확장됩니다. 대부분의 경우 전체 클러스터 성능에 눈에 띄는 영향을 주지 않습니다.
다음과 같은 경우 증분형 materialized view를 사용하십시오:
- 매번 insert 시점에 실시간으로 업데이트되는 쿼리 결과가 필요한 경우
- 대량의 데이터를 자주 집계하거나 필터링해야 하는 경우
- 쿼리가 단일 테이블에 대한 단순한 변환 또는 집계를 포함하는 경우
증분형 materialized view의 예시는 여기를 참고하십시오.
갱신 가능 구체화 뷰를 사용할 때
갱신 가능 구체화 뷰는 쿼리를 점진적으로 실행하는 대신 주기적으로 실행하며, 빠른 조회를 위해 쿼리 결과 집합을 저장합니다.
쿼리 성능이 매우 중요하고(예: 서브 밀리초 지연 시간), 약간 오래된 결과를 허용할 수 있을 때 가장 유용합니다. 쿼리가 전체를 다시 실행하므로, 갱신 가능 뷰는 상대적으로 빠르게 계산할 수 있는 쿼리이거나, 「상위 N개」 결과 캐싱이나 룩업 테이블과 같이 비교적 긴 주기(예: 1시간 간격)로만 계산해도 되는 쿼리에 가장 적합합니다.
실행 주기는 시스템에 과도한 부하가 걸리지 않도록 주의 깊게 조정해야 합니다. 많은 리소스를 사용하는 매우 복잡한 쿼리는 신중하게 스케줄링해야 합니다. 이러한 쿼리는 캐시에 영향을 주고 CPU 및 메모리를 소모하여 클러스터 전체 성능을 저하시킬 수 있습니다. 클러스터 과부하를 방지하려면 쿼리가 갱신 주기에 비해 상대적으로 빠르게 실행되어야 합니다. 예를 들어, 쿼리 자체 실행에 최소 10초가 걸린다면 해당 뷰를 10초마다 갱신하도록 스케줄링해서는 안 됩니다.
요약
정리하면, 다음과 같은 경우 갱신 가능 구체화 뷰를 사용합니다:
- 캐시된 쿼리 결과를 즉시 사용할 수 있어야 하고, 신선도에 약간의 지연은 허용되는 경우
- 쿼리 결과 집합에서 상위 N개가 필요한 경우
- 결과 집합의 크기가 시간이 지나도 무한히 증가하지 않는 경우. 그렇지 않으면 대상 뷰의 성능이 저하됩니다.
- 여러 테이블이 관련된 복잡한 조인 또는 비정규화를 수행하며, 어느 소스 테이블이 변경되더라도 갱신이 필요한 경우
- 배치 워크플로우, 비정규화 작업을 구축하거나 DBT DAG와 유사한 뷰 의존성을 생성하는 경우
갱신 가능 구체화 뷰의 예시는 여기를 참조하십시오.
APPEND vs REPLACE mode
갱신 가능 구체화 뷰(refreshable materialized view)는 대상 테이블에 데이터를 기록하는 두 가지 모드인 APPEND와 REPLACE를 지원합니다. 이 모드들은 뷰의 쿼리 결과가 뷰가 갱신될 때 어떤 방식으로 기록될지를 정의합니다.
REPLACE가 기본 동작입니다. 뷰가 갱신될 때마다 대상 테이블의 이전 내용은 최신 쿼리 결과로 완전히 덮어씌워집니다. 이는 결과 집합을 캐시하는 경우처럼, 뷰가 항상 최신 상태를 반영해야 하는 사용 사례에 적합합니다.
반면 APPEND는 대상 테이블의 내용을 교체하는 대신, 새로운 행을 테이블의 끝에 추가합니다. 이를 통해 주기적인 스냅샷을 수집하는 등 추가적인 사용 사례를 구현할 수 있습니다. 각 갱신이 서로 다른 시점(point-in-time)을 나타내거나, 결과를 시간에 따라 누적해서 저장하고자 할 때 APPEND 모드는 특히 유용합니다.
다음과 같은 경우에는 APPEND 모드를 사용하십시오:
- 과거 갱신 이력을 보존하고자 할 때
- 주기적인 스냅샷이나 보고서를 구축할 때
- 시간이 지나면서 갱신된 결과를 점진적으로 수집해야 할 때
다음과 같은 경우에는 REPLACE 모드를 사용하십시오:
- 가장 최근 결과만 필요할 때
- 오래된 데이터를 완전히 폐기해야 할 때
- 뷰가 현재 상태나 조회(lookup)를 표현할 때
Medallion architecture를 구축하는 경우 APPEND 기능의 활용 예를 확인할 수 있습니다.
