DataStore: SQL 최적화가 적용된 Pandas 호환 API
DataStore는 익숙한 pandas DataFrame 인터페이스에 SQL 쿼리 최적화 기능을 결합한 chDB의 pandas 호환 API로, pandas 스타일 코드로 작성하면서도 ClickHouse급 성능을 제공합니다.
주요 기능
- Pandas 호환성: 209개의 pandas DataFrame 메서드, 56개의
.str메서드, 42개 이상의.dt메서드 - SQL 최적화: 연산이 자동으로 최적화된 SQL 쿼리로 컴파일됩니다
- 지연 평가(Lazy Evaluation): 결과가 필요할 때까지 연산이 지연됩니다
- 630개 이상 API 메서드: 데이터 조작을 위한 포괄적인 API를 제공합니다
- ClickHouse 확장 기능: pandas에는 없는 추가 접근자(
.arr,.json,.url,.ip,.geo)를 제공합니다
아키텍처
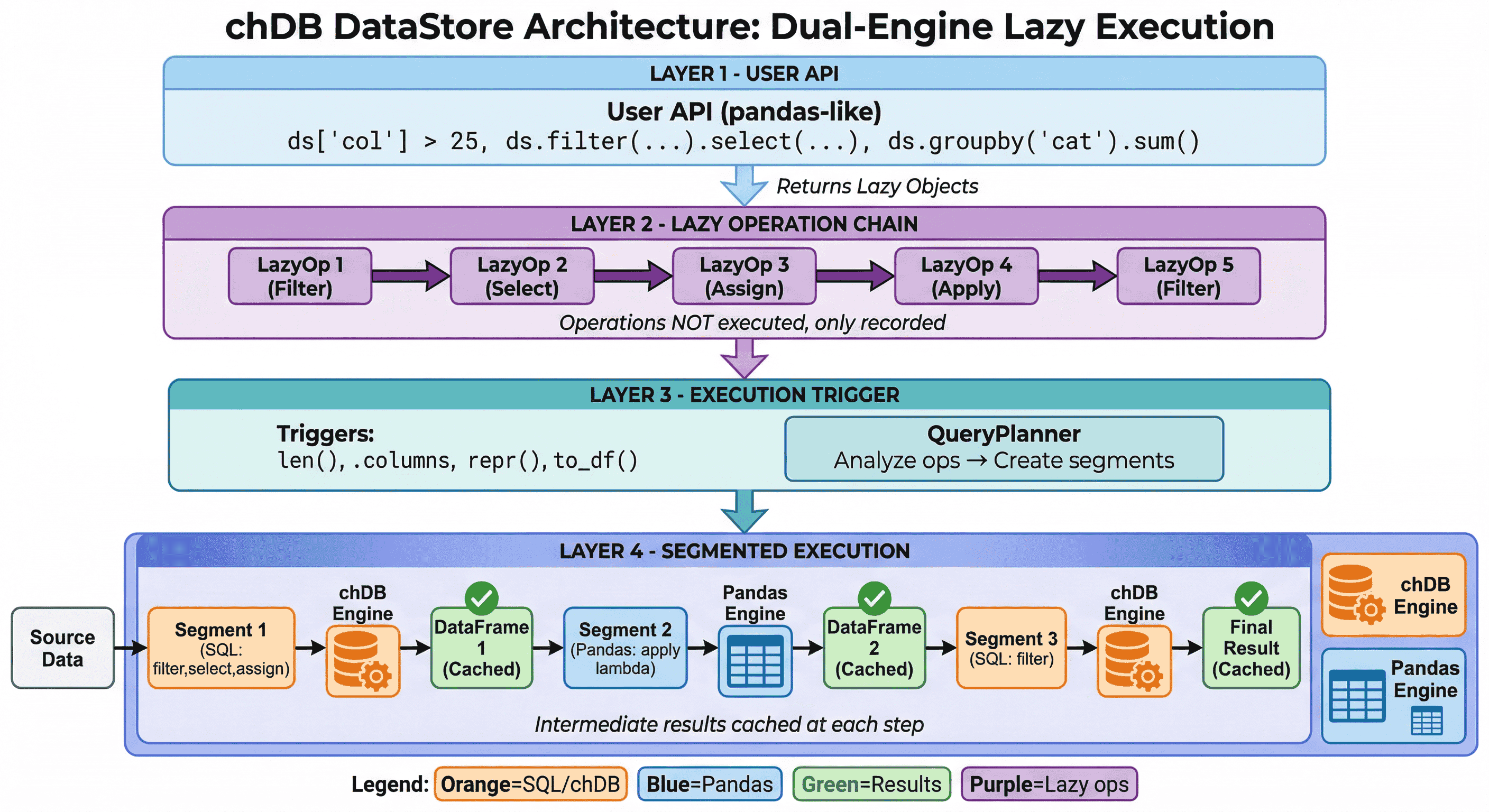
DataStore는 지연 평가(lazy evaluation) 와 이중 엔진 실행(dual-engine execution) 을 사용합니다.
- 지연 연산 체인(Lazy Operation Chain): 연산을 즉시 실행하지 않고 기록해 둡니다
- 스마트 엔진 선택(Smart Engine Selection):
QueryPlanner가 각 세그먼트를 최적의 엔진으로 라우팅합니다(chDB는 SQL용, Pandas는 복잡한 연산용) - 중간 캐싱(Intermediate Caching): 빠른 반복 탐색을 위해 각 단계의 결과를 캐시합니다
자세한 내용은 실행 모델을 참고하십시오.
Pandas에서 한 줄로 마이그레이션하기
기존 pandas 코드는 아무런 수정 없이 그대로 동작하지만, 이제 ClickHouse 엔진에서 실행됩니다.
성능 비교
DataStore는 특히 집계 및 복잡한 파이프라인에서 pandas보다 상당한 성능 향상을 제공합니다:
| Operation | Pandas | DataStore | Speedup |
|---|---|---|---|
| GroupBy count | 347ms | 17ms | 19.93x |
| Complex pipeline | 2,047ms | 380ms | 5.39x |
| Filter+Sort+Head | 1,537ms | 350ms | 4.40x |
| GroupBy agg | 406ms | 141ms | 2.88x |
1,000만 행 기준 벤치마크입니다. 자세한 내용은 벤치마크 스크립트 및 성능 가이드를 참조하십시오.
DataStore를 언제 사용해야 하는가
다음과 같은 경우 DataStore를 사용합니다.
- 대규모 데이터셋(수백만 개의 행)을 다루는 경우
- 집계 및 groupby 작업을 수행하는 경우
- 파일, 데이터베이스 또는 Cloud 스토리지에서 데이터를 쿼리하는 경우
- 복잡한 데이터 파이프라인을 구축하는 경우
- 더 높은 성능의 pandas API가 필요한 경우
다음과 같은 경우 raw SQL API를 사용합니다.
- SQL을 직접 작성하는 방식을 선호하는 경우
- 쿼리 실행을 세밀하게 제어해야 하는 경우
- pandas API에서 제공하지 않는 ClickHouse 고유 기능을 사용하는 경우
기능 비교
| 기능 | Pandas | Polars | DuckDB | DataStore |
|---|---|---|---|---|
| Pandas API 호환성 | - | 부분 호환 | 아니요 | 완전 호환 |
| 지연 평가(Lazy evaluation) | 아니요 | 예 | 예 | 예 |
| SQL 쿼리 지원 | 아니요 | 예 | 예 | 예 |
| ClickHouse 함수 | 아니요 | 아니요 | 아니요 | 예 |
| String/DateTime 접근자 | 예 | 예 | 아니요 | 예 + 추가 기능 |
| Array/JSON/URL/IP/Geo | 아니요 | 부분 지원 | 아니요 | 예 |
| 파일에 대한 직접 쿼리 | 아니요 | 예 | 예 | 예 |
| Cloud 스토리지 지원 | 아니요 | 제한적 | 예 | 예 |
API 통계
| 범주 | 개수 | 지원 범위 |
|---|---|---|
| DataFrame 메서드 | 209 | pandas의 100% |
| Series.str 접근자 | 56 | pandas의 100% |
| Series.dt 접근자 | 42+ | 100%+ (ClickHouse 추가 기능 포함) |
| Series.arr 접근자 | 37 | ClickHouse 전용 |
| Series.json 접근자 | 13 | ClickHouse 전용 |
| Series.url 접근자 | 15 | ClickHouse 전용 |
| Series.ip 접근자 | 9 | ClickHouse 전용 |
| Series.geo 접근자 | 14 | ClickHouse 전용 |
| 총 API 메서드 수 | 630+ | - |
문서 안내
시작하기
- 빠른 시작 - 설치 및 기본 사용법
- Pandas에서 마이그레이션 - 단계별 마이그레이션 가이드
API reference
- Factory Methods - 다양한 소스로부터 DataStore 생성
- Query Building - SQL 스타일 쿼리 구성 연산
- Pandas Compatibility - pandas와 호환되는 209개 메서드
- Accessors - String, DateTime, Array, JSON, URL, IP, Geo 접근자
- Aggregation - 집계 및 윈도우 함수
- I/O Operations - 데이터 입출력 작업
고급 주제
- Execution Model - 지연 평가 및 캐싱
- Class Reference - 전체 API 참조
구성 & 디버깅
Pandas 사용자 가이드
- Pandas Cookbook - 자주 사용하는 패턴
- Key Differences - pandas와의 핵심 차이점
- Performance Guide - 성능 최적화 팁
- SQL for Pandas Users - pandas 연산 이면의 SQL 이해
간단한 예
다음 단계
- DataStore가 처음이라면 빠른 시작 가이드부터 시작하십시오.
- pandas에서 이전하려는 경우 마이그레이션 가이드를 읽으십시오.
- 더 자세히 알고 싶다면 API 참조 문서를 살펴보십시오.
