백업 명령을 사용하여 자가 관리형 ClickHouse를 ClickHouse Cloud로 마이그레이션하기
개요
자가 관리형 ClickHouse(OSS)에서 ClickHouse Cloud로 데이터를 마이그레이션하는 주요 방법은 두 가지입니다.
- 데이터를 직접 가져오고 전송하는
remoteSecure()함수 사용 - 클라우드 객체 스토리지를 통한
BACKUP/RESTORE명령 사용
이 마이그레이션 가이드는
BACKUP/RESTORE방식을 중심으로 설명하며, 오픈 소스 ClickHouse의 데이터베이스 또는 전체 서비스를 S3 버킷을 통해 Cloud로 마이그레이션하는 실용적인 예제를 제공합니다.
사전 준비 사항
- Docker가 설치되어 있어야 합니다.
- S3 버킷과 IAM 사용자가 있어야 합니다.
- 새 ClickHouse Cloud 서비스를 생성할 수 있어야 합니다.
이 가이드의 절차를 따라 하기 쉽고 재현 가능하게 만들기 위해, 세그먼트 2개와 레플리카 2개로 구성된 ClickHouse 클러스터용 Docker Compose 레시피 중 하나를 사용합니다.
이 백업 방법은 MergeTree 엔진에서 ReplicatedMergeTree로 테이블을 변환해야 하므로 ClickHouse 클러스터가 필요합니다.
단일 인스턴스를 실행 중인 경우, 대신 "remoteSecure()를 사용하여 자가 관리형 ClickHouse와 ClickHouse Cloud 간 마이그레이션"의 단계를 따르십시오.
OSS 준비
먼저 예제 저장소에 있는 Docker Compose 설정을 사용하여 ClickHouse 클러스터를 기동합니다. 이미 실행 중인 ClickHouse 클러스터가 있다면 이 단계는 건너뛰어도 됩니다.
- examples 저장소를 로컬 머신으로 클론합니다.
- 터미널에서
examples/docker-compose-recipes/recipes/cluster_2S_2R디렉터리로cd명령을 사용해 이동합니다. - Docker가 실행 중인지 확인한 다음, ClickHouse 클러스터를 시작합니다:
다음과 같은 결과가 표시됩니다:
폴더의 루트에서 새 터미널 창을 열고 클러스터의 첫 번째 노드에 연결하려면 다음 명령을 실행하십시오:
샘플 데이터 생성
ClickHouse Cloud는 SharedMergeTree를 사용합니다.
백업을 복원할 때 ClickHouse는 ReplicatedMergeTree 테이블을 자동으로 SharedMergeTree 테이블로 변환합니다.
클러스터를 실행 중이라면 테이블이 이미 ReplciatedMergeTree 엔진을 사용하고 있을 가능성이 높습니다.
그렇지 않다면 백업하기 전에 모든 MergeTree 테이블을 ReplicatedMergeTree로 변환해야 합니다.
MergeTree 테이블을 ReplicatedMergeTree로 변환하는 방법을 보여 주기 위해, 우선 MergeTree 테이블로 시작한 후 나중에 이를 ReplicatedMergeTree로 변환하겠습니다.
샘플 테이블을 생성하고 데이터를 적재하기 위해 New York taxi data guide의 처음 두 단계를 따르겠습니다.
편의를 위해 해당 단계를 아래에 포함했습니다.
다음 명령을 실행하여 새 데이터베이스를 만들고 S3 버킷에서 새 테이블로 데이터를 삽입하십시오:
테이블을 DETACH하기 위해 다음 명령을 실행합니다.
그런 다음 이를 레플리카로 추가합니다:
마지막으로 레플리카 메타데이터를 복원하십시오:
ReplicatedMergeTree로 변환되었는지 확인하십시오:
이제 이후에 S3 버킷에서 백업을 복원할 수 있도록 Cloud 서비스를 설정할 준비가 되었습니다.
Cloud 준비
데이터를 새 Cloud 서비스로 복원하게 됩니다. 아래 단계에 따라 새 Cloud 서비스를 생성합니다.
Cloud Console 열기
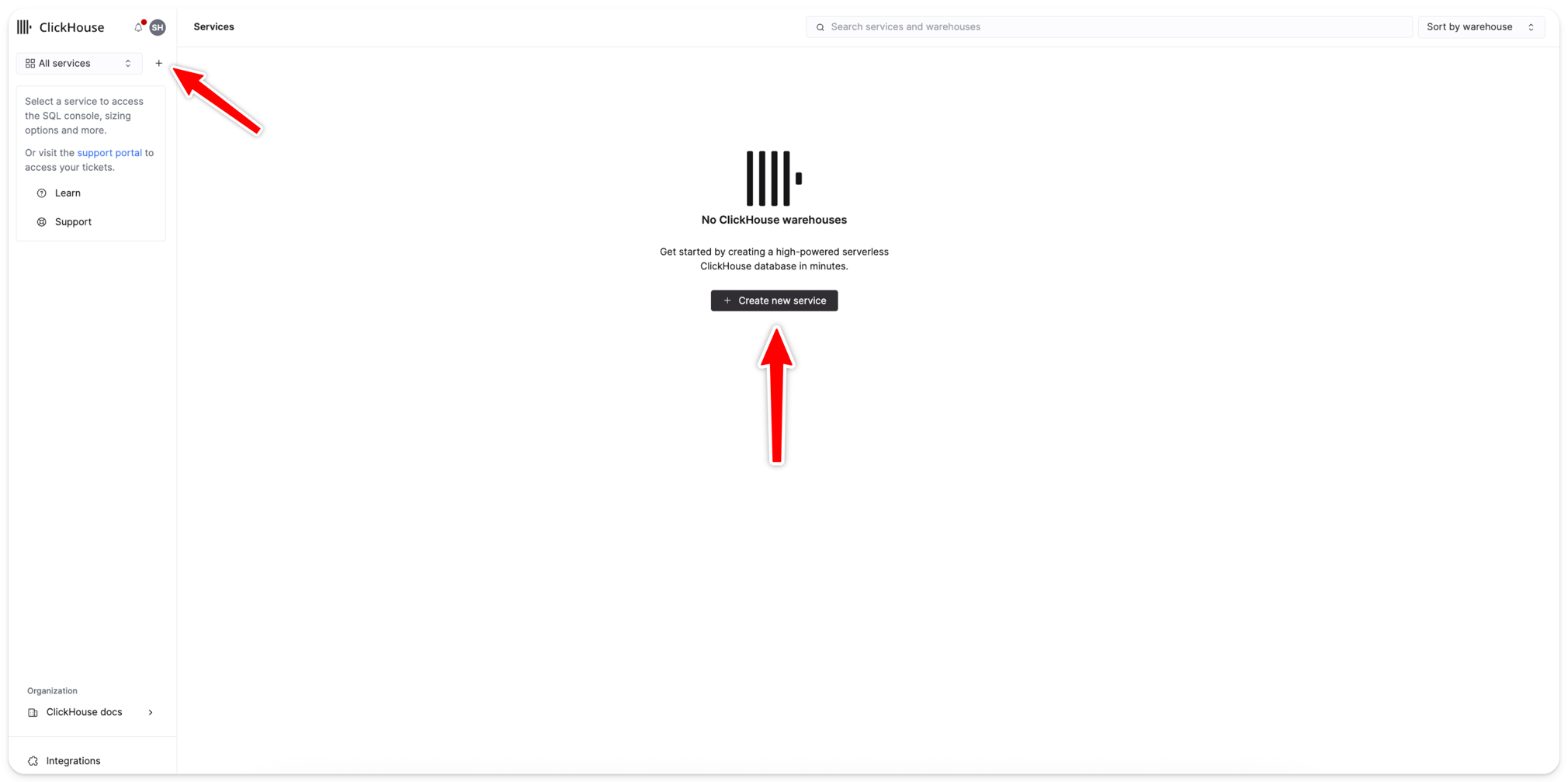
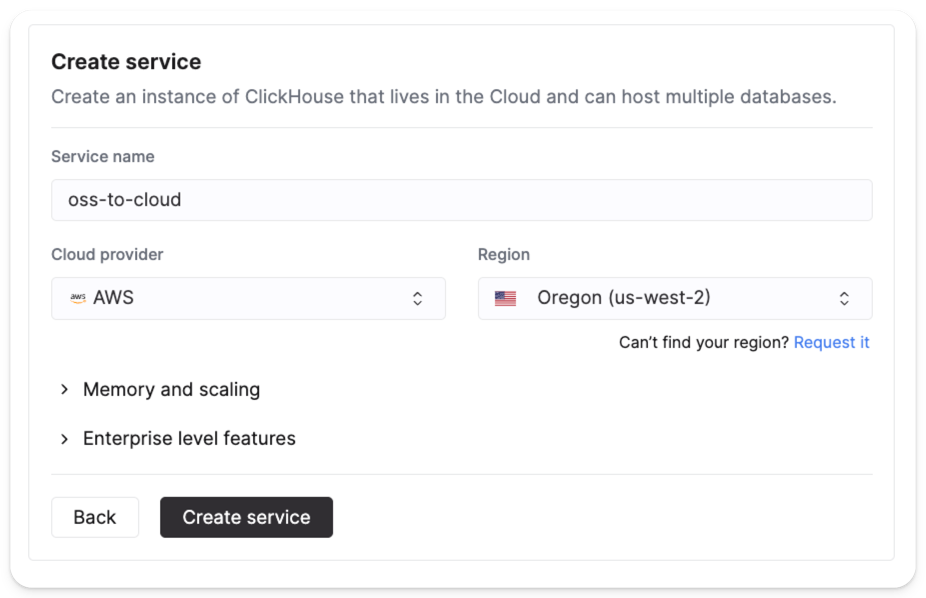
새 서비스 생성
액세스 역할 생성
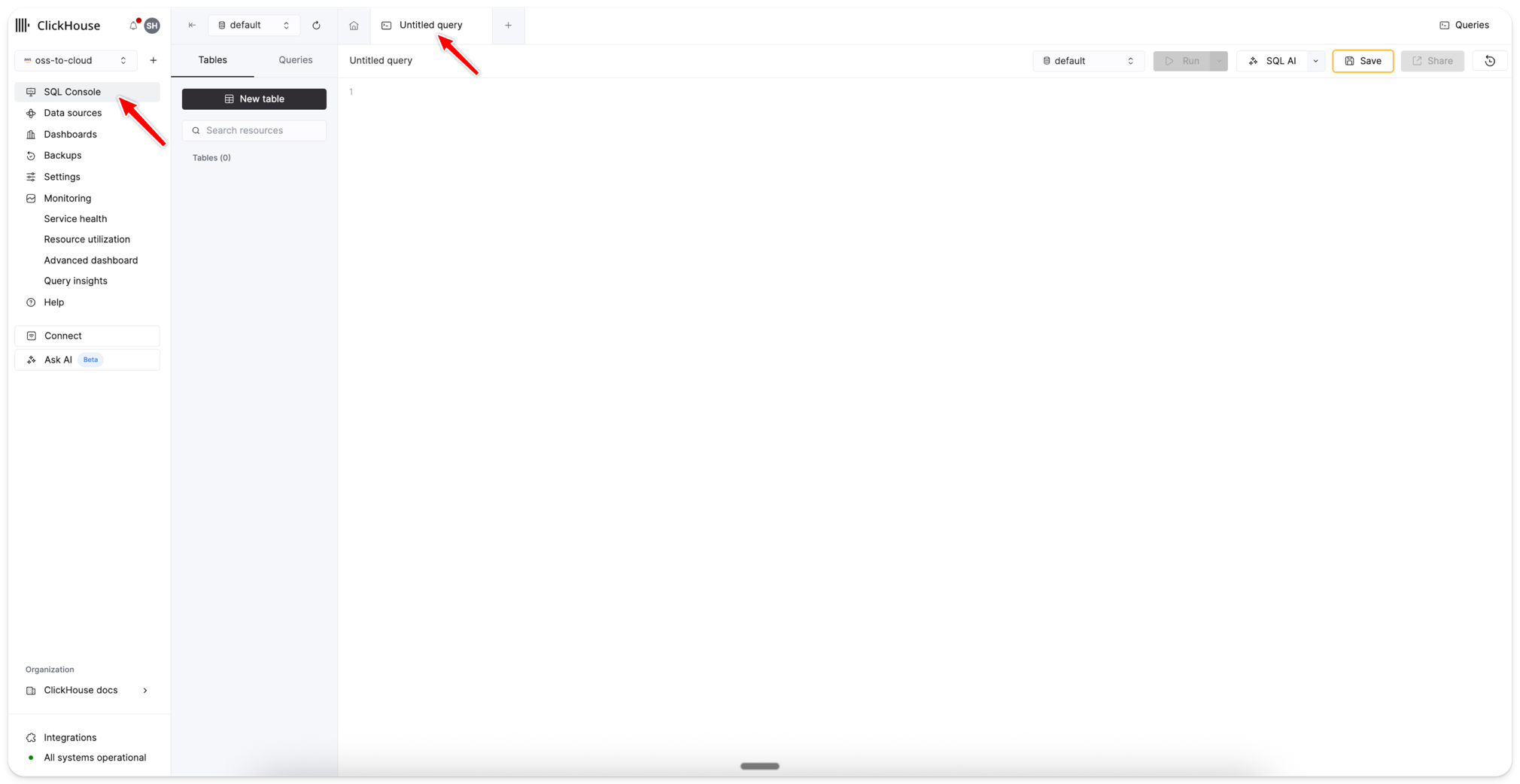
Open SQL console
S3 액세스 설정
S3에서 백업을 복원하려면 ClickHouse Cloud와 S3 버킷 간의 보안 액세스를 구성해야 합니다.
-
"S3 데이터에 안전하게 액세스하기"의 단계에 따라 액세스 역할을 생성하고 역할 ARN을 가져옵니다.
-
"S3 버킷 및 IAM 역할 생성 방법"에서 생성한 S3 버킷 정책에 이전 단계에서 얻은 역할 ARN을 추가하여 업데이트합니다.
업데이트된 S3 버킷 정책은 다음과 비슷한 형태입니다:
이 정책에는 두 개의 ARN이 모두 포함됩니다:
- IAM user (
docs-s3-user): 자가 관리형 ClickHouse 클러스터가 S3에 백업할 수 있도록 허용합니다. - ClickHouse Cloud role (
ClickHouseAccess-001): Cloud 서비스가 S3에서 복원할 수 있도록 허용합니다.
백업 수행(자가 관리형 배포 환경에서)
단일 데이터베이스를 백업하려면 OSS 자가 관리형 배포에 연결된 clickhouse-client에서
다음 명령을 실행합니다.
BUCKET_URL, KEY_ID, SECRET_KEY를 본인의 AWS 자격 증명으로 바꾸십시오.
가이드 "How to create an S3 bucket and IAM role"에서는
아직 해당 정보를 가지고 있지 않은 경우 이를 얻는 방법을 설명합니다.
모든 구성이 올바르게 완료되었다면, 백업에 할당된 고유 ID와 백업 상태가 포함된 아래와 유사한 응답이 표시됩니다.
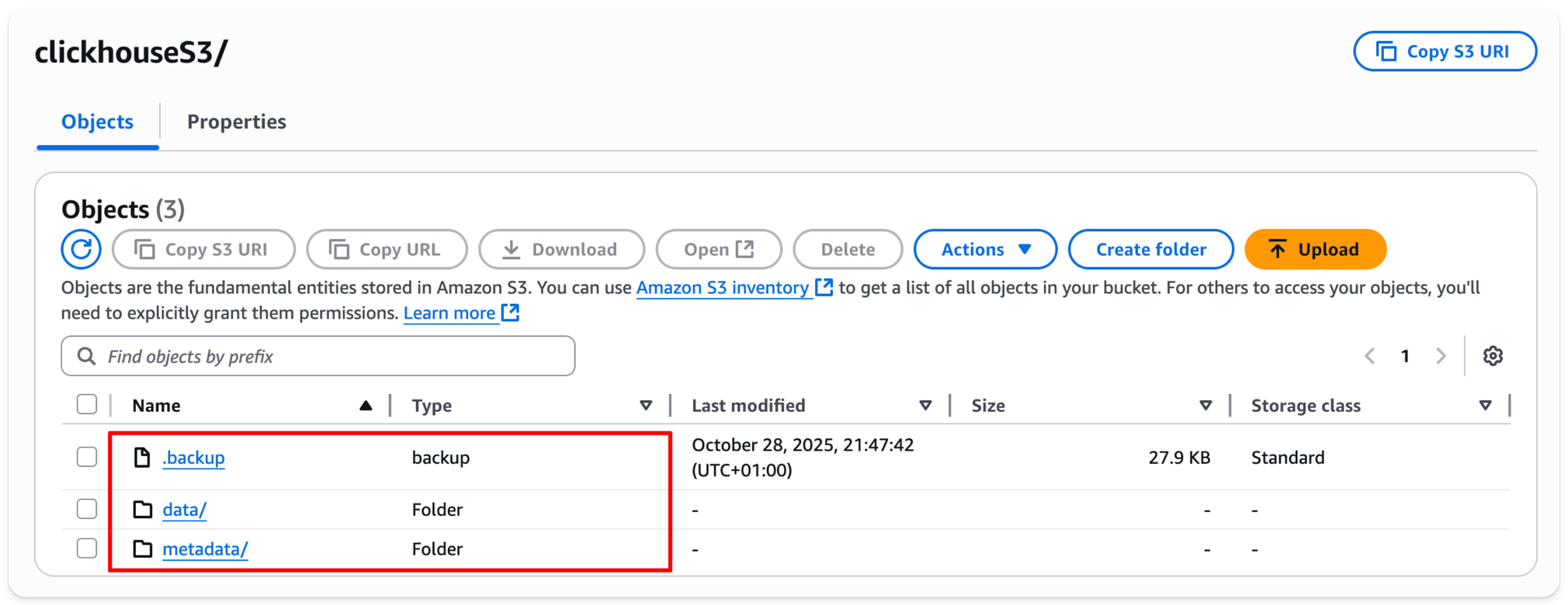
이전에 비어 있던 S3 버킷을 확인하면 이제 몇 개의 폴더가 생성된 것을 확인할 수 있습니다:
전체 마이그레이션을 수행 중이라면 다음 명령을 실행하여 서버 전체를 백업할 수 있습니다:
위 명령은 다음을 백업합니다:
- 모든 사용자 데이터베이스와 테이블
- 사용자 계정과 비밀번호
- 역할과 권한
- 설정 프로필(Settings profiles)
- 행 정책(Row policies)
- 쿼터(Quotas)
- 사용자 정의 함수(User-Defined Functions)
다른 클라우드 서비스 제공자(Cloud Service Provider, CSP)를 사용하는 경우, TO S3()(AWS와 GCP 모두에서 사용 가능)와 TO AzureBlobStorage() 구문을 사용할 수 있습니다.
매우 큰 데이터베이스의 경우, ASYNC를 사용하여 백그라운드에서 백업을 실행하도록 하는 것을 고려하십시오:
이제 이 백업 ID를 사용하여 백업 진행 상황을 모니터링할 수 있습니다:
증분 백업을 수행할 수도 있습니다. 백업 전반에 대한 자세한 내용은 backup and restore 문서를 참조하십시오.
ClickHouse Cloud로 복원
단일 데이터베이스를 복원하려면 Cloud 서비스에서 아래 쿼리를 실행하십시오. 이때 아래에 AWS 자격 증명을 입력하고,
ROLE_ARN을 "Accessing S3 data securely"에 자세히 설명된 단계의 출력으로 얻은 값과 동일하게 설정합니다.
마찬가지로 전체 서비스를 복원할 수 있습니다.
이제 Cloud에서 다음 쿼리를 실행하면 데이터베이스와 테이블이 Cloud에 성공적으로 복원된 것을 확인할 수 있습니다:
