데이터 백필(Backfill)
ClickHouse를 처음 사용하는 경우든 기존 배포를 운영하는 경우든, 과거 데이터로 테이블을 백필해야 하는 상황이 필연적으로 발생합니다. 어떤 경우에는 비교적 간단하지만, materialized view를 채워야 하는 경우에는 더 복잡해질 수 있습니다. 이 가이드는 이러한 작업을 위한 몇 가지 절차를 설명하며, 각자의 사용 사례에 맞게 적용할 수 있습니다.
이 가이드는 사용자가 이미 증분형 materialized view 개념과 S3 및 GCS와 같은 table function을 사용한 데이터 로딩에 익숙하다고 가정합니다. 또한 객체 스토리지에서 INSERT 성능 최적화에 대한 가이드를 읽을 것을 권장하며, 여기서 제시하는 권장 사항은 이 가이드 전반에 걸친 INSERT 작업에도 적용할 수 있습니다.
예제 데이터셋
이 가이드 전반에서 PyPI 데이터셋을 사용합니다. 이 데이터셋의 각 행은 pip과 같은 도구를 사용해 다운로드된 Python 패키지를 나타냅니다.
예를 들어, 이 부분 데이터셋은 2024-12-17 하루에 해당하며, https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/에서 공개적으로 제공됩니다. 다음과 같이 쿼리할 수 있습니다.
이 버킷의 전체 데이터셋에는 320 GB가 넘는 Parquet 파일이 포함되어 있습니다. 아래 예시에서는 glob 패턴을 사용하여 의도적으로 일부 하위 집합만을 대상으로 합니다.
사용자가 이 날짜 이후의 데이터를 Kafka 또는 객체 스토리지 등에서 스트림 형태로 수신하고 있다고 가정합니다. 이 데이터의 스키마는 아래와 같습니다:
1조 개가 넘는 행으로 구성된 전체 PyPI 데이터세트는 공개 데모 환경인 clickpy.clickhouse.com에서 이용할 수 있습니다. 이 데이터세트에 대한 자세한 내용(데모에서 성능 향상을 위해 구체화된 뷰(materialized view)를 어떻게 활용하는지, 그리고 데이터가 매일 어떻게 채워지는지 등)은 GitHub 저장소를 참고하십시오.
백필 시나리오
백필은 일반적으로 데이터 스트림을 특정 시점부터 읽기 시작한 경우에 필요합니다. 이 데이터는 증분형 materialized view를 통해 ClickHouse 테이블에 삽입되며, 블록이 삽입될 때마다 트리거됩니다. 이러한 뷰는 삽입 이전에 데이터를 변환하거나 집계를 계산하고, 그 결과를 이후 다운스트림 애플리케이션에서 사용할 대상 테이블로 전송할 수 있습니다.
다음 시나리오를 다룹니다:
- 기존 데이터 수집과 함께 데이터 백필 - 새로운 데이터는 계속 로드되는 동시에, 과거 데이터는 백필이 필요합니다. 이 과거 데이터는 이미 식별된 상태입니다.
- 기존 테이블에 materialized view 추가 - 과거 데이터가 이미 적재되어 있고 데이터 스트리밍이 진행 중인 구성에 새 materialized view를 추가해야 합니다.
데이터는 객체 스토리지에서 백필된다고 가정합니다. 모든 경우에 데이터 삽입이 중단되지 않도록 하는 것을 목표로 합니다.
과거 데이터 백필에는 객체 스토리지를 사용할 것을 권장합니다. 최적의 읽기 성능과 압축률(네트워크 전송 감소)을 위해, 가능한 경우 데이터를 Parquet 형식으로 내보내야 합니다. 약 150MB 정도의 파일 크기가 일반적으로 선호되지만, ClickHouse는 70개 이상의 파일 포맷을 지원하며 모든 크기의 파일을 처리할 수 있습니다.
복제 테이블과 뷰 사용하기
모든 시나리오에서 「duplicate tables and views」 개념을 사용합니다. 이러한 테이블과 뷰는 실시간 스트리밍 데이터에 사용되는 테이블과 뷰의 복제본으로, 장애가 발생했을 때 손쉽게 복구할 수 있도록 백필 작업을 독립적으로 수행할 수 있게 합니다. 예를 들어, 다음과 같은 메인 pypi 테이블과 materialized view가 있으며, Python 프로젝트별 다운로드 수를 계산합니다:
메인 테이블과 관련된 뷰를 데이터의 부분 집합으로 채웁니다.
{101..200}이라는 또 다른 하위 집합을 적재하려 한다고 가정합니다. 직접 pypi에 삽입할 수도 있지만, 복제 테이블을 생성하여 이 백필(backfill) 작업을 별도로 수행할 수 있습니다.
백필이 실패하더라도 메인 테이블에는 영향을 주지 않으며, 복제 테이블을 단순히 truncate한 후 다시 시도하면 됩니다.
이러한 뷰의 새 복사본을 만들려면, _v2 접미사를 붙여 CREATE TABLE AS 절을 사용할 수 있습니다:
대략 동일한 크기의 두 번째 하위 집합으로 데이터를 채운 뒤, 로드가 성공적으로 완료되었는지 확인합니다.
두 번째 로드 과정 중 어느 시점에서든 장애가 발생했다면, pypi_v2와 pypi_downloads_v2를 truncate하고 데이터 로드를 다시 수행하면 됩니다.
데이터 로드가 완료되면, ALTER TABLE MOVE PARTITION 절을 사용하여 복제 테이블의 데이터를 메인 테이블로 이동할 수 있습니다.
위의 MOVE PARTITION 호출은 파티션 이름 ()을 사용합니다. 이는 (파티션이 나뉘어 있지 않은) 이 테이블의 단일 파티션을 나타냅니다. 파티션이 있는 테이블에서는 각 파티션마다 한 번씩 여러 번 MOVE PARTITION을 호출해야 합니다. 현재 파티션 이름은 system.parts 테이블에서 확인할 수 있습니다. 예를 들어 SELECT DISTINCT partition FROM system.parts WHERE (table = 'pypi_v2')와 같습니다.
이제 pypi와 pypi_downloads가 전체 데이터를 포함하고 있음을 확인할 수 있습니다. pypi_downloads_v2와 pypi_v2는 안전하게 삭제할 수 있습니다.
중요한 점은 MOVE PARTITION 연산이 하드 링크를 활용하여 가볍게 동작하면서도, 중간 상태 없이 실패하거나 성공하는 원자적(atomic) 연산이라는 점입니다.
아래의 백필링(backfilling) 시나리오에서 이 과정을 적극적으로 활용합니다.
이 과정에서는 각 insert 연산의 크기를 사용자가 선택해야 한다는 점에 유의하십시오.
더 많은 행을 포함하는 큰 insert일수록 필요한 MOVE PARTITION 연산의 횟수가 줄어듭니다. 그러나 네트워크 중단 등으로 insert가 실패했을 때의 복구 비용과의 균형을 맞춰야 합니다. 이 과정은 파일을 배치(batch) 단위로 처리하여 위험을 줄이는 방식으로 보완할 수 있습니다. 이는 범위 쿼리(예: WHERE timestamp BETWEEN 2024-12-17 09:00:00 AND 2024-12-17 10:00:00)나 glob 패턴을 사용하여 수행할 수 있습니다. 예를 들면 다음과 같습니다.
ClickPipes는 객체 스토리지에서 데이터를 로드할 때 이 접근 방식을 사용하며, 대상 테이블과 해당 materialized view의 복제본을 자동으로 생성하여 사용자가 위 단계를 직접 수행할 필요가 없도록 합니다. 또한 여러 워커 스레드를 사용하여, 각 스레드가 서로 다른 하위 집합(글롭 패턴을 통해)을 처리하고 자체 복제 테이블을 사용하도록 함으로써, 데이터를 정확히 한 번만 처리하는 의미 체계(exactly-once semantics)를 유지하면서 빠르게 로드할 수 있습니다. 자세한 내용은 이 블로그를 참고하십시오.
시나리오 1: 기존 데이터 수집을 활용한 데이터 백필
이 시나리오에서는 백필해야 하는 데이터가 별도의 버킷에만 존재하는 것이 아니므로 필터링이 필요하다고 가정합니다. 데이터는 이미 수집·삽입되고 있으며, 과거 데이터를 백필해야 하는 기준이 되는 타임스탬프나 단조 증가하는 컬럼을 식별할 수 있습니다.
이 프로세스는 다음 단계를 따릅니다:
- 체크포인트를 식별합니다. 과거 데이터를 복원해야 하는 기준이 되는 타임스탬프 또는 컬럼 값을 찾습니다.
- 메인 테이블과 구체화된 뷰(Materialized View)의 대상 테이블 복제본을 생성합니다.
- 2단계에서 생성한 대상 테이블을 가리키도록 하는 모든 materialized view의 복사본을 생성합니다.
- 2단계에서 생성한 메인 테이블 복제본에 데이터를 삽입합니다.
- 복제본 테이블의 모든 파티션을 원본 테이블로 이동한 뒤, 복제본 테이블을 삭제합니다.
예를 들어, PyPI 데이터가 적재되어 있다고 가정해 보겠습니다. 이 경우 최소 타임스탬프를 식별할 수 있고, 이를 「체크포인트」로 사용할 수 있습니다.
위 내용을 통해 2024-12-17 09:00:00 이전의 데이터를 적재해야 한다는 것을 알 수 있습니다. 이전에 사용한 프로세스를 활용하여 테이블과 뷰를 복제하고, 타임스탬프를 조건으로 하는 필터를 사용해 해당 서브셋을 적재합니다.
Parquet에서 타임스탬프 컬럼을 기준으로 필터링하면 매우 효율적일 수 있습니다. ClickHouse는 로드할 전체 데이터 범위를 결정하기 위해 타임스탬프 컬럼만 읽으므로 네트워크 트래픽이 최소화됩니다. min-max와 같은 Parquet 인덱스도 ClickHouse 쿼리 엔진에서 활용할 수 있습니다.
이 INSERT 작업이 완료되면 관련된 파티션을 이동할 수 있습니다.
과거 데이터가 분리된 단일 버킷에 있는 경우에는 위의 시간 필터가 필요하지 않습니다. 시간 컬럼이나 단조 증가 컬럼을 사용할 수 없다면, 과거 데이터를 별도의 버킷으로 분리하십시오.
ClickHouse Cloud를 사용하는 경우, 데이터가 자체 버킷으로 분리되어 있어 필터가 필요하지 않다면 과거 백업 데이터를 복원하는 데 ClickPipes를 사용해야 합니다. 여러 워커를 사용하여 적재를 병렬화함으로써 적재 시간을 줄일 뿐만 아니라, ClickPipes는 위의 과정을 자동화하고 메인 테이블과 구체화된 뷰(Materialized View) 모두에 대해 별도의 테이블을 생성합니다.
시나리오 2: 기존 테이블에 materialized view 추가
이미 상당한 데이터가 적재되어 있고 데이터가 계속 삽입되고 있는 구성 환경에 새 materialized view를 추가해야 하는 일은 드문 일이 아닙니다. 스트림에서 특정 지점을 식별하는 데 사용할 수 있는 타임스탬프 또는 단조 증가 컬럼이 있으면 도움이 되며, 데이터 수집이 중단되는 상황을 피할 수 있습니다. 아래 예시에서는 두 경우 모두를 가정하며, 수집 중단을 피하는 접근 방식을 우선합니다.
POPULATE 명령은 수집이 중단된 작은 데이터셋이 아닌 이상 materialized view를 백필(backfill)하는 용도로 사용하는 것을 권장하지 않습니다. 이 연산자는 POPULATE 해시가 완료된 이후에 생성된 materialized view의 소스 테이블에 삽입된 행을 놓칠 수 있습니다. 또한 이 POPULATE 작업은 전체 데이터에 대해 실행되며, 대용량 데이터셋에서는 중단이나 메모리 한계에 취약합니다.
Timestamp 또는 단조 증가하는 컬럼 사용 가능
이 경우 새 materialized view 에는 미래의 임의 시점 이후의 행만 포함하도록 하는 필터를 추가할 것을 권장합니다. 그런 다음 이 materialized view 는 메인 테이블의 이력 데이터를 사용하여 해당 날짜부터 백필(backfill)할 수 있습니다. 백필 방법은 데이터 크기와 관련 쿼리의 복잡도에 따라 달라집니다.
가장 단순한 접근 방식은 다음 단계로 구성됩니다.
- 가까운 미래의 임의 시점 이후의 행만 고려하는 필터를 포함하여 materialized view 를 생성합니다.
- 소스 테이블에 대해 뷰의 집계 쿼리를 사용해 데이터를 읽어 오면서, materialized view 의 대상 테이블에 데이터를 삽입하는
INSERT INTO SELECT쿼리를 실행합니다.
이는 2단계에서 특정 데이터 하위 집합만을 대상으로 하도록 확장하거나, 장애 발생 후 더 쉽게 복구할 수 있도록 materialized view 용 별도의 대상 테이블을 사용한 뒤(삽입이 완료되면 원본 테이블에 파티션을 attach) 활용하도록 구성할 수 있습니다.
다음 예시는 시간당 가장 인기 있는 프로젝트를 계산하는 materialized view 입니다.
대상 테이블은 추가할 수 있지만, materialized view를 추가하기 전에 SELECT 절을 수정하여 가까운 미래의 임의 시점 이후의 행만 대상으로 하는 필터를 포함하도록 합니다. 이 경우 2024-12-17 09:00:00이 몇 분 뒤의 시각이라고 가정합니다.
이 view를 추가하면 이 데이터 이전 시점에 대한 materialized view의 모든 데이터를 백필(backfill)할 수 있습니다.
가장 간단한 방법은 materialized view에 정의된 쿼리를, 최근에 추가된 데이터를 제외하는 필터를 사용하여 기본 테이블에서 실행한 다음 INSERT INTO SELECT를 통해 결과를 view의 대상 테이블에 삽입하는 것입니다. 예를 들어, 위의 view에 대해 살펴보면 다음과 같습니다.
위 예시에서 대상 테이블은 SummingMergeTree입니다. 이 경우 원래의 집계 쿼리를 그대로 사용할 수 있습니다. AggregatingMergeTree를 활용하는 더 복잡한 사용 사례에서는 집계를 위해 -State 함수들을 사용합니다. 이에 대한 예시는 이 integration guide에서 확인할 수 있습니다.
이 경우 비교적 가벼운 집계 작업으로, 3초 이내에 완료되며 600MiB 미만의 메모리를 사용합니다. 더 복잡하거나 오래 실행되는 집계의 경우, 앞에서 설명한 중복 테이블 방식을 사용해 이 프로세스를 더 견고하게 만들 수 있습니다. 즉, pypi_downloads_per_day_v2와 같은 그림자 대상(shadow target) 테이블을 생성하고 여기에 데이터를 INSERT한 다음, 결과 파티션을 pypi_downloads_per_day에 ATTACH합니다.
materialized view의 쿼리는 종종 더 복잡할 수 있으며(그렇지 않다면 사용자가 굳이 view를 사용하지 않을 것이므로 흔한 일입니다) 리소스를 많이 소모합니다. 드문 경우이긴 하지만, 쿼리에 필요한 리소스가 서버가 감당할 수 있는 범위를 넘어설 수도 있습니다. 이는 ClickHouse materialized view의 장점 중 하나를 잘 보여 줍니다. materialized view는 증분 방식으로 동작하며 전체 데이터셋을 한 번에 처리하지 않습니다.
이러한 경우, 사용자에게는 여러 가지 선택지가 있습니다.
WHERE timestamp BETWEEN 2024-12-17 08:00:00 AND 2024-12-17 09:00:00,WHERE timestamp BETWEEN 2024-12-17 07:00:00 AND 2024-12-17 08:00:00등과 같이 해당 구간을 채우도록 쿼리를 수정합니다.- Null table engine을 사용하여 materialized view를 채웁니다. 이는 materialized view의 일반적인 점진적 채우기 방식과 동일하게 동작하며, 설정 가능한 크기의 데이터 블록에 대해 해당 뷰의 쿼리를 실행합니다.
(1)은 가장 단순한 접근 방식으로, 대부분의 경우에 충분합니다. 간결성을 위해 예시는 포함하지 않습니다.
(2)에 대해서는 아래에서 더 자세히 설명합니다.
materialized view를 채우기 위한 Null 테이블 엔진 사용
Null table engine은 데이터를 영구 저장(persist)하지 않는 스토리지 엔진을 제공합니다(테이블 엔진 세계의 /dev/null이라고 생각하면 됩니다). 모순적으로 보일 수 있지만, 이 테이블 엔진에 데이터가 삽입되면 materialized view는 여전히 실행됩니다. 이를 통해 원본 데이터를 영구 저장하지 않고 materialized view를 구성할 수 있어 I/O와 이에 따른 스토리지 사용을 피할 수 있습니다.
중요한 점은, 해당 테이블 엔진에 연결된 모든 materialized view가 데이터가 삽입될 때 여전히 데이터 블록 단위로 실행되며, 그 결과를 대상 테이블로 전송한다는 것입니다. 이 블록의 크기는 설정으로 조정할 수 있습니다. 더 큰 블록은 잠재적으로 더 효율적일 수 있고(처리 속도도 더 빠를 수 있음), 대신 더 많은 리소스(주로 메모리)를 소비합니다. 이 테이블 엔진을 사용하면 materialized view를 점진적으로, 즉 한 번에 하나의 블록씩 구축할 수 있으므로 전체 집계를 메모리에 모두 유지할 필요가 없습니다.
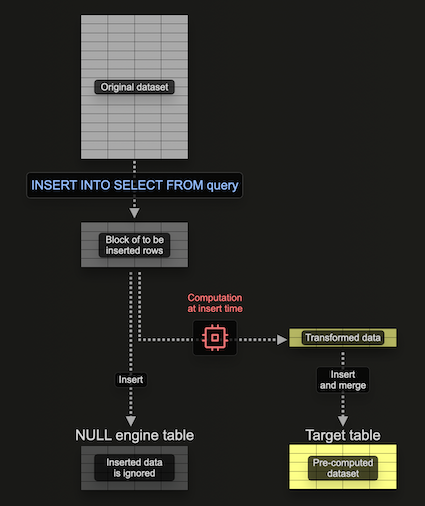
다음 예제를 살펴보십시오:
여기서는 Null 테이블 pypi_v2를 생성하여 구체화된 뷰(Materialized View)를 구축하는 데 사용할 행을 받습니다. 필요한 컬럼만 포함하도록 스키마를 제한한다는 점에 유의하십시오. 이 구체화된 뷰는 이 테이블에 삽입되는 행(한 번에 하나의 블록)에 대해 집계를 수행하고, 그 결과를 대상 테이블 pypi_downloads_per_day로 전송합니다.
여기서는 pypi_downloads_per_day를 대상 테이블로 사용했습니다. 추가적인 복원력을 위해 사용자는 이전 예시에서와 같이 pypi_downloads_per_day_v2라는 테이블을 하나 더 생성하고, 이를 뷰의 대상 테이블로 사용할 수 있습니다. INSERT가 완료되면 pypi_downloads_per_day_v2의 파티션을 pypi_downloads_per_day로 이동할 수 있습니다. 이렇게 하면 메모리 문제나 서버 중단으로 인해 INSERT가 실패하는 경우에도 복구할 수 있습니다. 즉, pypi_downloads_per_day_v2를 TRUNCATE한 뒤 설정을 조정하고 다시 시도하면 됩니다.
이 구체화된 뷰를 채우기 위해, pypi에서 pypi_v2로 백필할 관련 데이터를 간단히 INSERT합니다.
여기에서 메모리 사용량은 639.47 MiB입니다.
성능 및 리소스 튜닝
위 시나리오에서 성능과 사용되는 리소스는 여러 요소에 의해 좌우됩니다. 튜닝을 시도하기 전에, S3 Insert 및 Read 성능 최적화 가이드의 Using Threads for Reads 섹션에 자세히 문서화된 insert 메커니즘을 이해할 것을 권장합니다. 요약하면:
- 읽기 병렬성(Read Parallelism) - 읽기에 사용되는 스레드 수입니다.
max_threads를 통해 제어합니다. ClickHouse Cloud에서는 인스턴스 크기에 의해 결정되며, 기본값은 vCPU 개수입니다. 이 값을 늘리면 메모리 사용량 증가를 대가로 읽기 성능이 향상될 수 있습니다. - Insert 병렬성(Insert Parallelism) - insert에 사용되는 insert 스레드 수입니다.
max_insert_threads를 통해 제어합니다. 참고: 이 값은max_threads로 상한이 설정되므로, 실제 insert 병렬성은min(max_insert_threads, max_threads)가 됩니다. ClickHouse Cloud에서는 인스턴스 크기(2~4 사이)에 의해 결정되며, OSS에서는 1로 설정됩니다. 이 값을 늘리면 메모리 사용량 증가를 대가로 성능이 향상될 수 있습니다. - Insert 블록 크기(Insert Block Size) - 데이터는 파티셔닝 키(partitioning key)를 기준으로 메모리 내 insert 블록으로 가져와 파싱하고 구성하는 루프에서 처리됩니다. 이 블록들은 정렬, 최적화, 압축 후 새로운 데이터 파트로 스토리지에 기록됩니다. insert 블록 크기는
min_insert_block_size_rows및min_insert_block_size_bytes(비압축) 설정으로 제어되며, 메모리 사용량과 디스크 I/O에 영향을 줍니다. 더 큰 블록은 더 많은 메모리를 사용하지만 생성되는 파트 수를 줄여 I/O 및 백그라운드 머지를 감소시킵니다. 이 설정들은 최소 임계값을 의미하며, 둘 중 하나가 먼저 도달하면 flush가 트리거됩니다. - materialized view 블록 크기(Materialized view block size) - 위의 메인 insert 메커니즘과 더불어, materialized view에 insert하기 전에 블록도 더 효율적인 처리를 위해 합쳐집니다. 이러한 블록의 크기는
min_insert_block_size_bytes_for_materialized_views및min_insert_block_size_rows_for_materialized_views설정에 의해 결정됩니다. 더 큰 블록은 메모리 사용량 증가를 대가로 보다 효율적인 처리를 가능하게 합니다. 기본적으로 이 설정들은 각각 소스 테이블 설정인min_insert_block_size_rows및min_insert_block_size_bytes의 값을 기본값으로 사용합니다.
단순한 INSERT SELECT 쿼리를 위한 팁: INSERT INTO t1 SELECT * FROM t2와 같이 복잡한 변환이 없는 단순한 쿼리의 경우, optimize_trivial_insert_select=1을 활성화하는 것을 고려하십시오. 이 설정은(버전 24.7부터 기본적으로 비활성화) max_insert_threads에 맞추어 SELECT 병렬성을 자동으로 조정하여 리소스 사용량과 생성되는 파트 수를 줄입니다. 특히 테이블 간 대용량 데이터 마이그레이션에 유용합니다.
성능을 향상시키기 위해서는, S3 Insert 및 Read 성능 최적화 가이드의 Tuning Threads and Block Size for Inserts 섹션에 설명된 지침을 따를 수 있습니다. 대부분의 경우 성능을 개선하기 위해 min_insert_block_size_bytes_for_materialized_views 및 min_insert_block_size_rows_for_materialized_views를 추가로 수정할 필요는 없습니다. 이러한 값을 수정하는 경우, min_insert_block_size_rows 및 min_insert_block_size_bytes에 대해 논의된 것과 동일한 모범 사례를 적용하십시오.
메모리를 최소화하기 위해서는 이러한 설정을 조정해 볼 수 있습니다. 이는 필연적으로 성능을 낮추게 됩니다. 앞서 사용한 쿼리를 기준으로 아래에 예시를 보여 줍니다.
max_insert_threads를 1로 낮추면 메모리 오버헤드가 줄어듭니다.
max_threads 설정값을 1로 줄이면 메모리 사용량을 더 줄일 수 있습니다.
마지막으로, min_insert_block_size_rows를 0으로 설정하여 블록 크기를 결정하는 요소에서 제외하고, min_insert_block_size_bytes를 10485760(10MiB)으로 설정하면 메모리 사용량을 더 줄일 수 있습니다.
마지막으로, 블록 크기를 줄이면 더 많은 파트가 생성되어 머지(merge) 작업 부하가 커진다는 점에 유의해야 합니다. 여기에 설명된 대로, 이러한 설정은 신중하게 변경해야 합니다.
타임스탬프나 단조 증가 컬럼 없음
위의 프로세스는 타임스탬프 또는 단조 증가 컬럼이 있다고 가정합니다. 일부 경우에는 이러한 컬럼이 아예 없을 수 있습니다. 이런 경우에는, 앞에서 설명한 여러 단계를 활용하되 수집을 일시 중지해야 하는 다음 프로세스를 권장합니다.
- 메인 테이블로의 INSERT를 일시 중지합니다.
CREATE AS구문을 사용하여 메인 대상 테이블과 동일한 복제 테이블을 생성합니다.- 원본 대상 테이블의 파티션을
ALTER TABLE ATTACH를 사용하여 복제 테이블에 ATTACH 합니다. 참고: 이 ATTACH 연산은 앞에서 사용한 MOVE 연산과는 다릅니다. 하드 링크에 의존하지만, 원본 테이블의 데이터는 그대로 보존됩니다. - 새로운 materialized view를 생성합니다.
- INSERT를 다시 시작합니다. 참고: INSERT는 대상 테이블만 업데이트하며, 복제본은 업데이트하지 않습니다. 복제본은 원본 데이터만을 참조합니다.
- 타임스탬프가 있는 데이터에 대해 위에서 사용한 것과 동일한 프로세스를 적용하여 materialized view를 백필(backfill)하며, 복제 테이블을 소스로 사용합니다.
PyPI와 앞에서 만든 새로운 materialized view pypi_downloads_per_day를 사용하는 다음 예시를 고려하십시오(타임스탬프를 사용할 수 없다고 가정합니다).
끝에서 두 번째 단계에서는 앞에서 설명한 단순한 INSERT INTO SELECT 방식을 사용하여 pypi_downloads_per_day를 백필합니다. 이는 위에 문서화된 Null 테이블 방식을 사용해 개선할 수도 있으며, 선택적으로 별도의 테이블을 사용해 내결함성을 더 높일 수 있습니다.
이 작업에는 INSERT 작업을 일시 중지해야 하지만, 중간 작업은 일반적으로 빠르게 완료되므로 데이터 유입 중단을 최소화할 수 있습니다.
