ClickHouse 프라이머리 인덱스에 대한 실용적인 소개
소개
이 가이드에서는 ClickHouse 인덱싱을 심층적으로 살펴봅니다. 다음 주제를 예시와 함께 자세히 설명합니다:
- ClickHouse의 인덱싱이 전통적인 관계형 데이터베이스 관리 시스템과 어떻게 다른지
- ClickHouse가 테이블의 희소 기본 인덱스(primary index)를 어떻게 생성하고 사용하는지
- ClickHouse에서 인덱싱을 할 때 활용할 수 있는 몇 가지 모범 사례
이 가이드에 제시된 모든 ClickHouse SQL 문과 쿼리는 원한다면 로컬 환경에서 직접 실행할 수 있습니다. ClickHouse 설치 및 시작 방법은 빠른 시작을 참조하십시오.
이 가이드는 ClickHouse의 희소 기본 인덱스(primary index)에 초점을 맞춥니다.
ClickHouse의 보조 데이터 스키핑 인덱스에 대해서는 튜토리얼을 참조하십시오.
Data set
이 가이드 전반에서 익명화된 웹 트래픽 데이터 세트를 예제로 사용합니다.
- 샘플 데이터 세트에서 887만 개 행(이벤트)으로 구성된 서브셋을 사용합니다.
- 비압축 데이터 크기는 887만 개 이벤트에 약 700MB이며, ClickHouse에 저장하면 약 200MB로 압축됩니다.
- 이 서브셋에서 각 행은 인터넷 사용자(
UserID컬럼)가 특정 시점(EventTime컬럼)에 특정 URL(URL컬럼)을 클릭했다는 정보를 나타내는 세 개의 컬럼으로 구성됩니다.
이 세 개의 컬럼만으로도 다음과 같은 전형적인 웹 분석 쿼리를 작성할 수 있습니다.
- "특정 사용자가 가장 많이 클릭한 URL 상위 10개는 무엇입니까?"
- "특정 URL을 가장 자주 클릭한 사용자 상위 10명은 누구입니까?"
- "사용자가 특정 URL을 클릭하는 가장 인기 있는 시간대(예: 요일별)는 언제입니까?"
테스트 머신
이 문서에 제시된 모든 런타임 수치는 Apple M1 Pro 칩과 RAM 16GB가 장착된 MacBook Pro에서 ClickHouse 22.2.1을 로컬로 실행했을 때의 결과를 기반으로 합니다.
전체 테이블 스캔
프라이머리 키 없이 데이터 집합에서 쿼리가 어떻게 실행되는지 확인하기 위해 다음 SQL DDL 문을 실행하여 MergeTree 테이블 엔진을 사용하는 테이블을 생성합니다.
다음으로, 다음 SQL INSERT 문을 사용하여 hits 데이터 세트의 일부를 테이블에 삽입합니다. 이 구문은 URL table function을 사용하여 clickhouse.com에 원격으로 호스팅된 전체 데이터 세트의 부분 집합을 로드합니다.
응답은 다음과 같습니다:
ClickHouse 클라이언트의 결과 출력을 통해 위 SQL 문이 테이블에 887만 행을 삽입했음을 알 수 있습니다.
마지막으로, 이 가이드에서 이후 논의를 단순화하고 다이어그램과 결과를 재현 가능하게 만들기 위해 FINAL 키워드를 사용하여 optimize 문으로 테이블을 최적화합니다.
일반적으로 데이터 로드 직후에 테이블을 즉시 최적화할 필요도 없고, 그렇게 하는 것은 권장되지도 않습니다. 이 예제에서 왜 최적화가 필요한지는 곧 분명해집니다.
이제 첫 번째 웹 분석 쿼리를 실행합니다. 다음 예제는 UserID 749927693인 인터넷 사용자의 가장 많이 클릭된 URL 상위 10개를 계산합니다.
응답은 다음과 같습니다:
ClickHouse client의 결과 출력은 ClickHouse가 전체 테이블 스캔을 수행했음을 보여 줍니다! 테이블에 있는 887만 개의 행 각각이 모두 ClickHouse로 스트리밍된 것입니다. 이렇게 해서는 확장성이 떨어집니다.
이를 훨씬 더 효율적이고 훨씬 더 빠르게 만들려면 적절한 기본 키(primary key)를 가진 테이블을 사용해야 합니다. 그러면 ClickHouse가 기본 키 컬럼(column)을 기준으로 희소 기본 인덱스(primary index)를 자동으로 생성하며, 이 인덱스를 사용해 예제 쿼리의 실행 속도를 크게 높일 수 있습니다.
ClickHouse 인덱스 설계
대규모 데이터 스케일을 위한 인덱스 설계
전통적인 관계형 데이터베이스 관리 시스템에서는 기본(primary) 인덱스가 테이블의 각 행마다 하나의 엔트리를 가집니다. 이 경우, 이 데이터 세트에 대해 기본 인덱스는 887만 개의 엔트리를 갖게 됩니다. 이러한 인덱스는 특정 행을 빠르게 찾을 수 있게 해 주며, 조회 쿼리와 포인트 업데이트에 대해 높은 효율을 제공합니다. B(+)-Tree 데이터 구조에서 하나의 엔트리를 검색하는 시간 복잡도는 평균적으로 O(log n)이며, 보다 정확히는 log_b n = log_2 n / log_2 b입니다. 여기서 b는 B(+)-Tree의 분기 계수(branching factor)이고 n은 인덱싱된 행의 개수입니다. b는 일반적으로 수백에서 수천 사이이므로, B(+)-Tree는 매우 얕은 구조를 가지며 레코드를 찾기 위해 필요한 디스크 탐색(disk seek)은 많지 않습니다. 887만 개의 행과 분기 계수 1000을 가정하면 평균 2.3회의 디스크 탐색이 필요합니다. 이러한 성능은 비용을 수반합니다. 추가적인 디스크 및 메모리 오버헤드, 테이블에 새로운 행과 인덱스 엔트리를 추가할 때 더 높은 삽입 비용, 그리고 때때로 B-Tree 재균형(rebalancing)이 필요합니다.
B-Tree 인덱스와 관련된 이러한 과제를 고려하여, ClickHouse의 테이블 엔진은 다른 접근 방식을 사용합니다. ClickHouse의 MergeTree Engine Family는 대규모 데이터 볼륨을 처리하도록 설계되고 최적화되었습니다. 이 테이블들은 초당 수백만 행을 삽입받고, 매우 큰(수백 페타바이트) 규모의 데이터를 저장하도록 설계되었습니다. 데이터는 파트 단위로 테이블에 빠르게 기록되며, 백그라운드에서 파트를 병합하는 규칙이 적용됩니다. ClickHouse에서는 각 파트가 자체 기본 인덱스를 가집니다. 파트가 병합될 때, 병합된 파트의 기본 인덱스도 함께 병합됩니다. ClickHouse가 목표로 하는 매우 큰 규모에서는 디스크와 메모리를 매우 효율적으로 사용하는 것이 필수적입니다. 따라서 모든 행을 인덱싱하는 대신, 하나의 파트에 대한 기본 인덱스는 여러 행 그룹(「그래뉼(granule)」이라고 부름)당 하나의 인덱스 엔트리(「마크(mark)」라고 부름)를 갖습니다. 이러한 기법을 **희소 인덱스(sparse index)**라고 합니다.
희소 인덱싱이 가능한 이유는 ClickHouse가 하나의 파트에 속하는 행들을 기본 키 컬럼(primary key column) 값 순서대로 디스크에 저장하기 때문입니다. 개별 행을 직접 찾는 방식(B-Tree 기반 인덱스처럼) 대신, 희소 기본 인덱스는 인덱스 엔트리에 대한 이진 검색을 통해 쿼리와 일치할 가능성이 있는 행 그룹을 빠르게 식별할 수 있게 합니다. 이렇게 식별된 잠재적으로 일치하는 행 그룹(그래뉼)은 이후 병렬로 ClickHouse 엔진에 스트리밍되어 실제 일치 항목을 찾습니다. 이 인덱스 설계는 기본 인덱스를 작게 유지할 수 있게 합니다(기본 인덱스는 완전히 메인 메모리에 상주할 수 있어야 하며 실제로 그래야 합니다). 동시에, 특히 데이터 분석 사용 사례에서 일반적인 범위 쿼리에 대해 쿼리 실행 시간을 크게 단축시킵니다.
다음 내용에서는 ClickHouse가 희소 기본 인덱스를 어떻게 구축하고 사용하는지에 대해 자세히 설명합니다. 이후 본 문서에서 인덱스를 구축하는 데 사용되는 테이블 컬럼(기본 키 컬럼)을 선택하고 제거하며 순서를 지정하는 최선의 방법에 대해서도 논의합니다.
기본 키가 있는 테이블
키 컬럼인 UserID와 URL로 구성된 복합 기본 키를 갖는 테이블을 생성합니다:
DDL 구문 상세
이 가이드의 이후 설명을 단순화하고 다이어그램과 결과를 재현 가능하게 하기 위해, DDL 구문은 다음과 같은 역할을 합니다:
ORDER BY절을 통해 테이블에 대한 복합 정렬 키를 지정합니다.다음 설정을 통해 기본 인덱스가 갖게 될 인덱스 항목 개수를 명시적으로 제어합니다:
index_granularity: 기본값인 8192로 명시적으로 설정합니다. 이는 8192개의 행 그룹마다 기본 인덱스가 하나의 인덱스 항목을 갖게 됨을 의미합니다. 예를 들어, 테이블에 16384개의 행이 포함되어 있으면 인덱스에는 두 개의 인덱스 항목이 있게 됩니다.index_granularity_bytes: adaptive index granularity를 비활성화하기 위해 0으로 설정합니다. adaptive index granularity란, 다음 중 하나라도 참이면 ClickHouse가 자동으로 n개의 행 그룹에 대해 하나의 인덱스 항목을 생성하는 동작을 의미합니다:n이 8192보다 작고, 해당n개의 행에 대한 전체 행 데이터 크기가 10 MB 이상(index_granularity_bytes의 기본값)인 경우.n개의 행에 대한 전체 행 데이터 크기가 10 MB보다 작지만n이 8192인 경우.
compress_primary_key: 기본 인덱스 압축을 비활성화하기 위해 0으로 설정합니다. 이렇게 하면 이후에 필요할 경우 해당 내용을 확인할 수 있습니다.
위의 DDL 구문에 포함된 기본 키는 지정된 두 개의 키 컬럼을 기반으로 기본 인덱스를 생성하게 합니다.
이제 데이터를 삽입합니다:
응답은 다음과 같습니다:
그리고 테이블을 최적화합니다:
다음 쿼리를 사용하여 해당 테이블의 메타데이터를 조회할 수 있습니다:
응답은 다음과 같습니다:
ClickHouse 클라이언트 출력은 다음과 같습니다:
- 테이블의 데이터는 디스크의 특정 디렉터리에 wide format으로 저장되며, 이 디렉터리 안에는 각 테이블 컬럼마다 하나의 데이터 파일(및 하나의 마크 파일)이 존재합니다.
- 테이블에는 887만 개의 행이 있습니다.
- 모든 행을 합친 비압축 데이터 크기는 733.28 MB입니다.
- 모든 행을 합친 디스크 상의 압축 크기는 206.94 MB입니다.
- 테이블에는 1083개의 엔트리(「마크」라고 부름)를 가진 기본 인덱스가 있으며, 인덱스 크기는 96.93 KB입니다.
- 전체적으로, 테이블의 데이터 및 마크 파일과 기본 인덱스 파일을 모두 합친 디스크 사용량은 207.07 MB입니다.
데이터는 프라이머리 키 컬럼의 순서로 디스크에 저장됩니다
위에서 생성한 테이블에는
-
정렬 키만 지정했더라면 프라이머리 키는 정렬 키와 동일하게 암묵적으로 정의되었을 것입니다.
-
메모리를 효율적으로 사용하기 위해 쿼리가 필터링에 사용하는 컬럼만 포함하는 프라이머리 키를 명시적으로 지정했습니다. 프라이머리 키를 기반으로 하는 프라이머리 인덱스는 전부 메인 메모리에 적재됩니다.
-
본 가이드의 다이어그램에서 일관성을 유지하고 압축률을 최대화하기 위해 테이블의 모든 컬럼을 포함하는 별도의 정렬 키를 정의했습니다(비슷한 데이터가 정렬 등을 통해 서로 가깝게 배치되면 더 잘 압축됩니다).
-
프라이머리 키와 정렬 키를 모두 지정하는 경우 프라이머리 키는 정렬 키의 접두사(prefix)가 되어야 합니다.
삽입된 행은 프라이머리 키 컬럼(및 정렬 키에 포함된 추가 EventTime 컬럼)을 기준으로 사전식(lexicographical) 오름차순으로 디스크에 저장됩니다.
ClickHouse는 동일한 프라이머리 키 컬럼 값을 가진 여러 행을 삽입하는 것을 허용합니다. 이 경우(아래 다이어그램의 행 1과 행 2 참조), 최종 순서는 지정된 정렬 키, 따라서 EventTime 컬럼의 값에 의해 결정됩니다.
ClickHouse는 컬럼 지향 데이터베이스 관리 시스템입니다. 아래 다이어그램에서 볼 수 있듯이
- 디스크 상의 표현에서는 각 테이블 컬럼마다 해당 컬럼의 모든 값이 압축된 형태로 저장되는 단일 데이터 파일(*.bin)이 있으며,
- 887만 개의 행은 프라이머리 키 컬럼(및 추가 정렬 키 컬럼)을 기준으로 사전식 오름차순으로 디스크에 저장됩니다. 즉, 이 경우
- 먼저
UserID, - 그다음
URL, - 마지막으로
EventTime순서입니다:
- 먼저
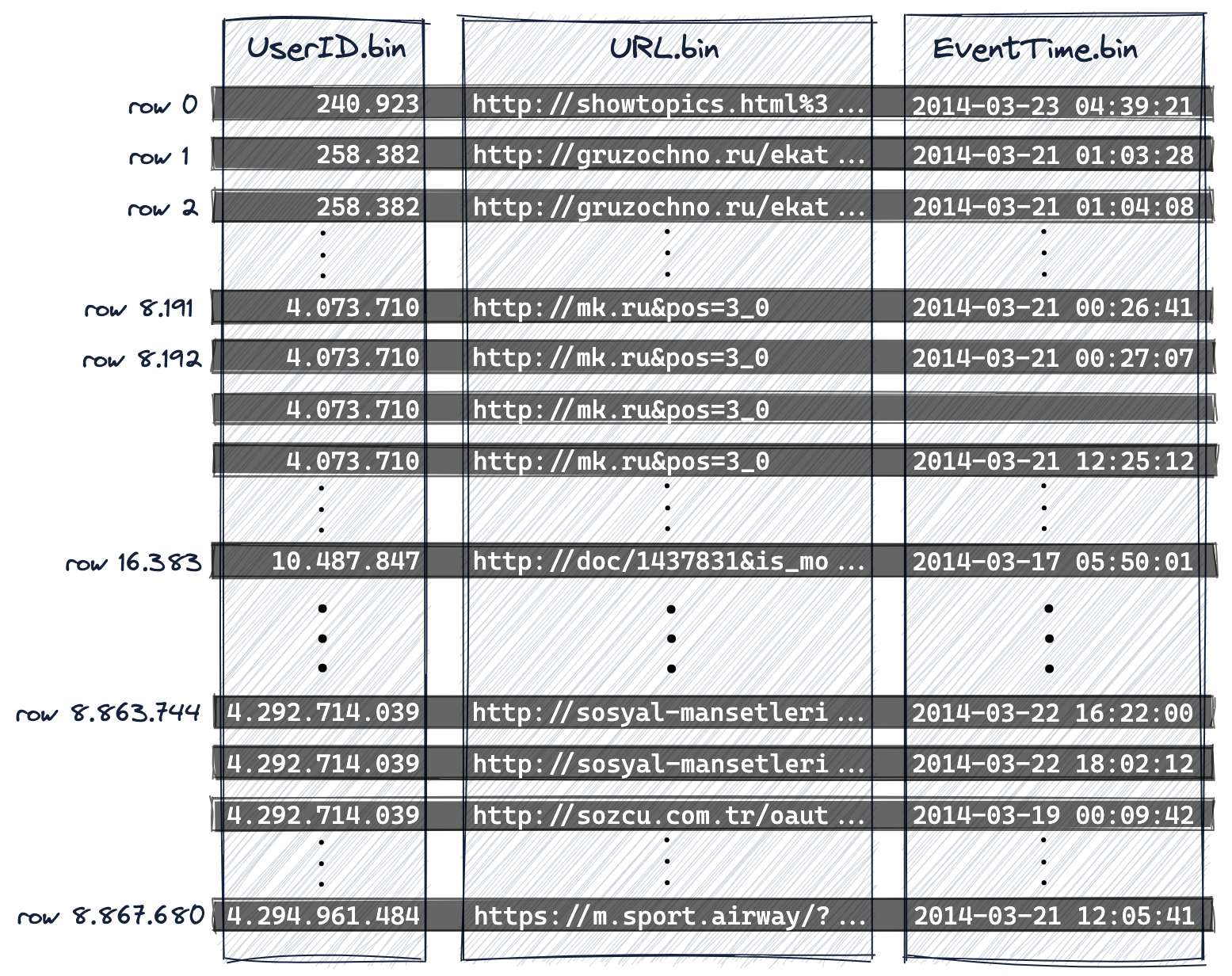
UserID.bin, URL.bin, EventTime.bin은 UserID, URL, EventTime 컬럼의 값이 저장되는 디스크 상의 데이터 파일입니다.
-
프라이머리 키가 디스크 상의 행의 사전식 순서를 정의하므로 테이블은 하나의 프라이머리 키만 가질 수 있습니다.
-
ClickHouse 내부의 행 번호 체계(로그 메시지에도 사용됨)에 맞추기 위해 행 번호는 0부터 시작합니다.
병렬 데이터 처리를 위해 데이터는 그래뉼로 구성됩니다
데이터 처리 목적을 위해 테이블의 컬럼 값은 논리적으로 그래뉼 단위로 나뉩니다. 그래뉼은 ClickHouse로 스트리밍되어 데이터 처리를 수행하는 가장 작은 불가분 데이터 집합입니다. 이는 개별 행을 읽는 대신, ClickHouse가 항상 (스트리밍 방식으로, 그리고 병렬로) 전체 행 그룹(그래뉼)을 읽는다는 의미입니다.
컬럼 값은 실제로 그래뉼 내부에 저장되는 것이 아니라, 그래뉼은 쿼리 처리를 위한 컬럼 값의 논리적 구성 단위입니다.
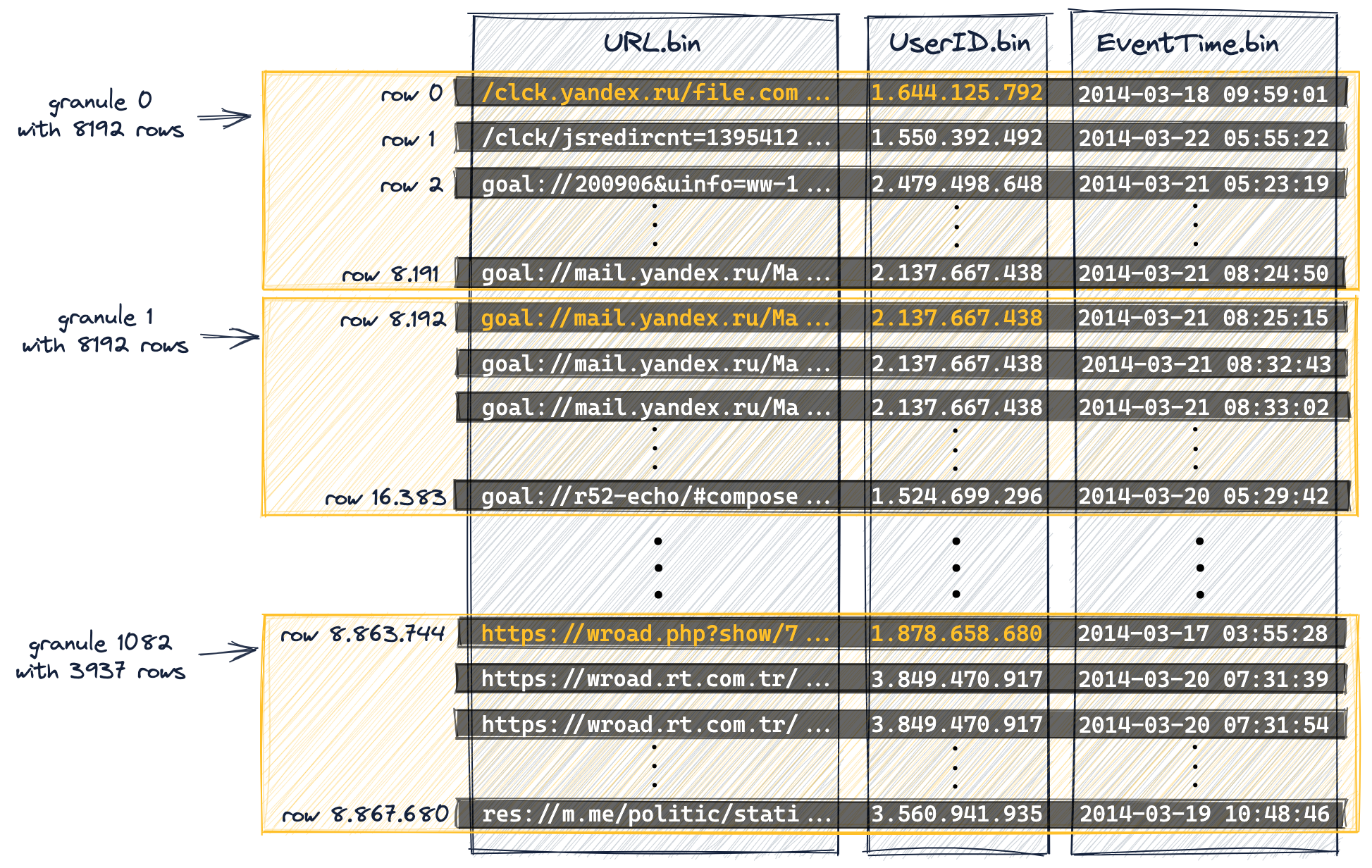
다음 다이어그램은 테이블의 887만 행(의 컬럼 값)이
테이블의 DDL 문에서 index_granularity 설정(기본값 8192)으로 인해 1083개의 그래뉼로 구성되는 방식을 보여줍니다.
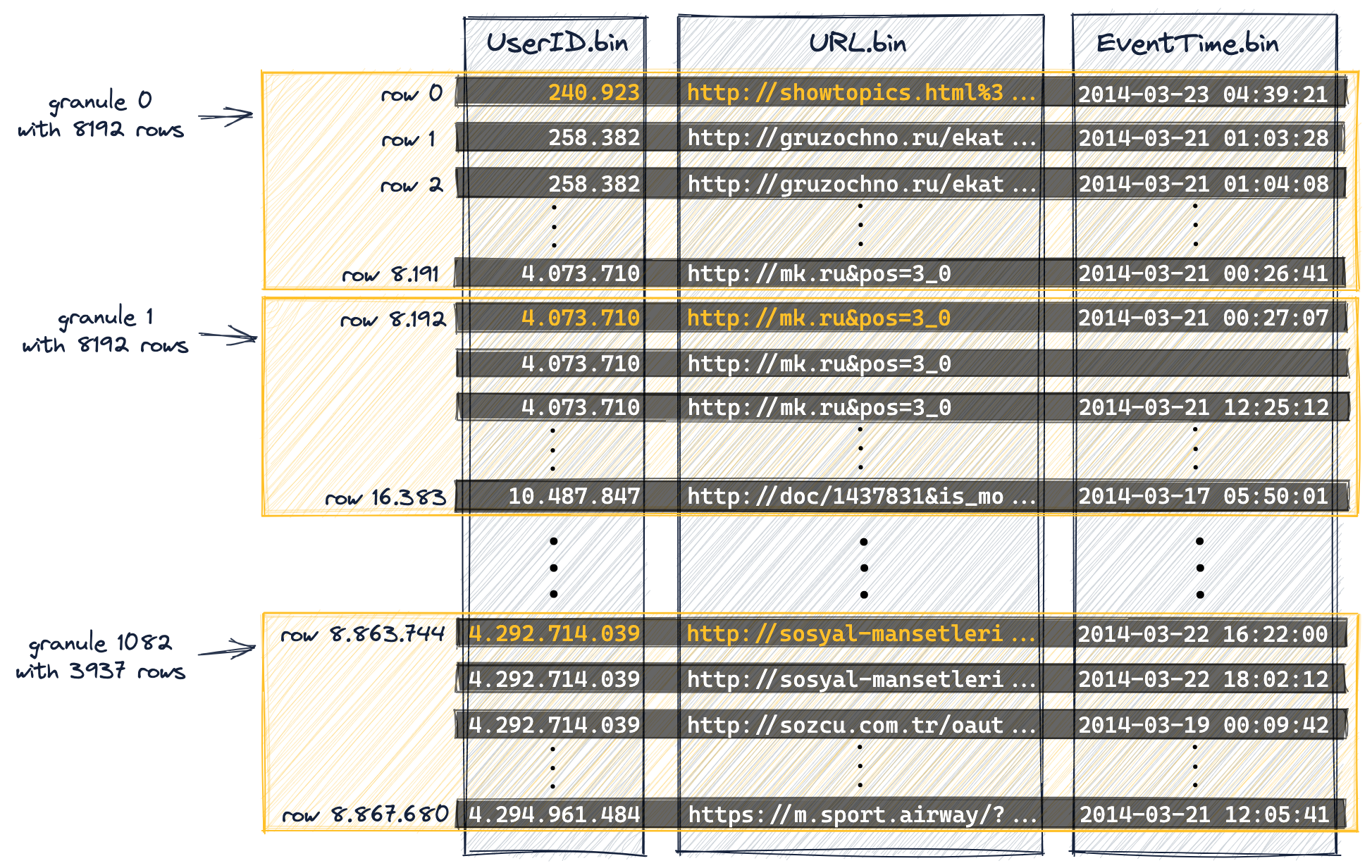
디스크 상의 물리적 순서를 기준으로 처음 8192개의 행(및 해당 컬럼 값)은 논리적으로 그래뉼 0에 속하고, 그다음 8192개의 행(및 해당 컬럼 값)은 그래뉼 1에 속하는 식으로 계속됩니다.
-
마지막 그래뉼(그래뉼 1082)은 8192개보다 적은 행을 「포함」합니다.
-
이 가이드의 처음 「DDL Statement Details」에서, 이 가이드의 설명을 단순화하고 다이어그램과 결과를 재현 가능하게 만들기 위해 adaptive index granularity를 비활성화했다고 언급했습니다.
따라서 이 예제 테이블의 모든 그래뉼(마지막 그래뉼 제외)은 동일한 크기를 가집니다.
-
adaptive index granularity가 활성화된 테이블(인덱스 그래뉼은 기본적으로 adaptive임)의 경우, 일부 그래뉼의 크기는 행 데이터 크기에 따라 8192개 행보다 작을 수 있습니다.
-
프라이머리 키 컬럼(
UserID,URL)의 일부 컬럼 값을 주황색으로 표시했습니다. 이 주황색으로 표시된 컬럼 값은 각 그래뉼의 첫 번째 행에 대한 프라이머리 키 컬럼 값입니다. 아래에서 보겠지만, 이 주황색으로 표시된 컬럼 값이 테이블 프라이머리 인덱스의 엔트리가 됩니다. -
ClickHouse 내부 번호 매김 방식(로그 메시지에도 사용됨)에 맞추기 위해 그래뉼 번호는 0부터 시작합니다.
The primary index has one entry per granule
프라이머리 인덱스는 위 다이어그램에 표시된 그래뉼을 기반으로 생성됩니다. 이 인덱스는 압축되지 않은 단순 배열 파일(primary.idx)이며, 0부터 시작하는 숫자 마크(마크)를 포함합니다.
아래 다이어그램에서 볼 수 있듯이, 인덱스는 각 그래뉼마다 첫 번째 행에 대한 프라이머리 키 컬럼 값(위 다이어그램에서 주황색으로 표시된 값들)을 저장합니다. 다르게 표현하면, 프라이머리 인덱스는 테이블의 각 8192번째 행(프라이머리 키 컬럼이 정의하는 물리적 행 순서를 기준으로)의 프라이머리 키 컬럼 값을 저장합니다. 예를 들어,
- 첫 번째 인덱스 엔트리(아래 다이어그램의 'mark 0')는 위 다이어그램에서 그래뉼 0의 첫 번째 행의 키 컬럼 값을 저장하고,
- 두 번째 인덱스 엔트리(아래 다이어그램의 'mark 1')는 위 다이어그램에서 그래뉼 1의 첫 번째 행의 키 컬럼 값을 저장하며, 이런 식으로 계속됩니다.
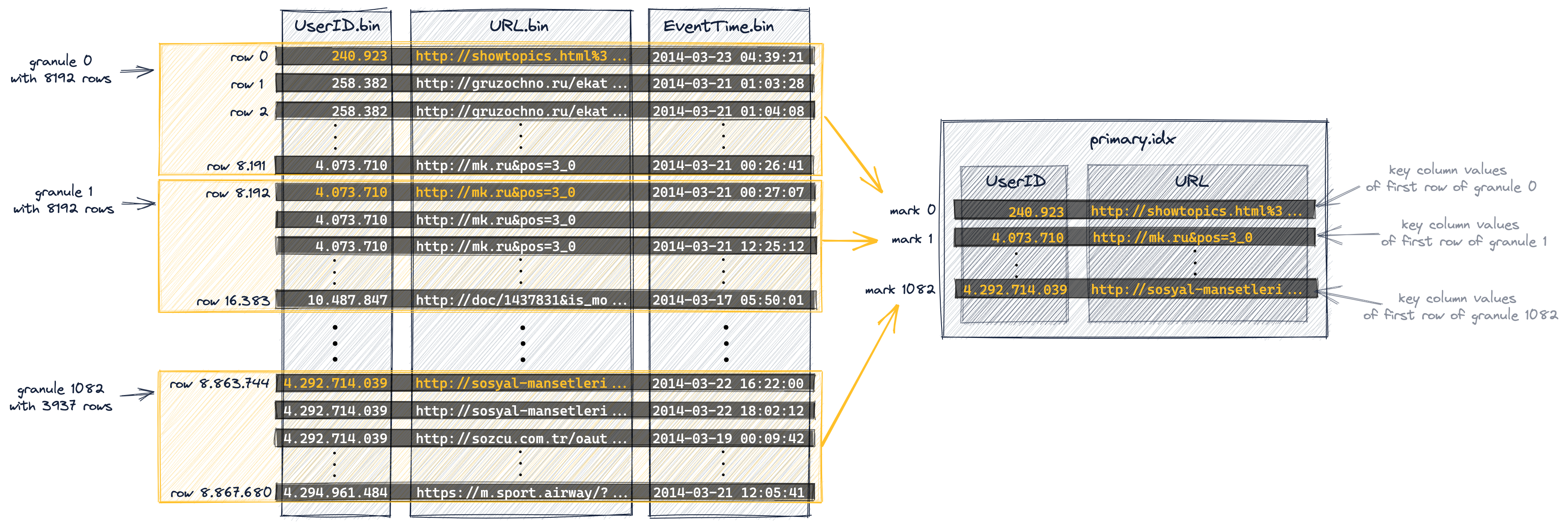
전체적으로, 이 인덱스는 8.87 million 개의 행과 1083개의 그래뉼을 가진 테이블에 대해 총 1083개의 엔트리를 가집니다:

-
adaptive index granularity를 사용하는 테이블의 경우, 프라이머리 인덱스에는 마지막 테이블 행의 프라이머리 키 컬럼 값을 기록하는 하나의 "최종(final)" 추가 마크도 저장됩니다. 그러나 이 가이드에서 논의를 단순화하고, 다이어그램과 결과를 재현 가능하게 만들기 위해 adaptive index granularity를 비활성화했기 때문에, 예제 테이블의 인덱스에는 이 최종 마크가 포함되지 않습니다.
-
프라이머리 인덱스 파일은 전부 메인 메모리에 로드됩니다. 파일이 사용 가능한 여유 메모리 공간보다 크면 ClickHouse는 오류를 발생시킵니다.
기본 인덱스 내용을 살펴보기
자가 관리형 ClickHouse 클러스터에서는 예제 테이블의 기본 인덱스 내용을 살펴보기 위해 file 테이블 함수를 사용할 수 있습니다.
이를 위해 먼저 실행 중인 클러스터의 노드 중 하나의 user_files_path로 기본 인덱스 파일을 복사해야 합니다:
- Step 1: 기본 인덱스 파일을 포함하는 파트 경로 가져오기
- Step 2: user_files_path 가져오기 Linux의 기본 user_files_path는
- Step 3: 기본 인덱스 파일을 user_files_path로 복사
SELECT path FROM system.parts WHERE table = 'hits_UserID_URL' AND active = 1테스트 머신에서는 /Users/tomschreiber/Clickhouse/store/85f/85f4ee68-6e28-4f08-98b1-7d8affa1d88c/all_1_9_4 를 반환합니다.
/var/lib/clickhouse/user_files/이며, Linux에서는 다음 명령으로 변경되었는지 확인할 수 있습니다: $ grep user_files_path /etc/clickhouse-server/config.xml
테스트 머신의 경로는 /Users/tomschreiber/Clickhouse/user_files/ 입니다.
cp /Users/tomschreiber/Clickhouse/store/85f/85f4ee68-6e28-4f08-98b1-7d8affa1d88c/all_1_9_4/primary.idx /Users/tomschreiber/Clickhouse/user_files/primary-hits_UserID_URL.idx
이제 SQL을 통해 기본 인덱스의 내용을 살펴볼 수 있습니다:
- 항목 개수 확인
- 처음 두 개의 인덱스 마크 가져오기
- 마지막 인덱스 마크 가져오기
SELECT count( )<br/>FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String');
1083 을(를) 반환합니다.SELECT UserID, URL<br/>FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String')<br/>LIMIT 0, 2;결과는 다음과 같습니다.
240923, http://showtopics.html%3...<br/> 4073710, http://mk.ru&pos=3_0
SELECT UserID, URL FROM file('primary-hits_UserID_URL.idx', 'RowBinary', 'UserID UInt32, URL String')<br/>LIMIT 1082, 1;
다음 값을 반환합니다.
4292714039 │ http://sosyal-mansetleri...이는 예제 테이블에 대한 기본 인덱스 내용의 다이어그램과 정확히 일치합니다.
기본 키 엔트리는 각 인덱스 엔트리가 특정 데이터 범위의 시작을 표시하기 때문에 인덱스 마크(index marks)라고 불립니다. 예제 테이블에서는 구체적으로 다음과 같습니다.
-
UserID 인덱스 마크:
기본 인덱스에 저장된
UserID값은 오름차순으로 정렬됩니다.
위 다이어그램에서 'mark 1'은 그래뉼 1에 있는 모든 테이블 행의UserID값과 이후 모든 그래뉼의 값이 4.073.710 이상이라는 것이 보장됨을 나타냅니다.
나중에 보겠지만, 이러한 전역 순서는 쿼리가 기본 키의 첫 번째 컬럼을 기준으로 필터링할 때 ClickHouse가 첫 번째 키 컬럼에 대한 인덱스 마크에 대해 이진 검색 알고리즘을 사용할 수 있게 해 줍니다.
-
URL 인덱스 마크:
기본 키 컬럼
UserID와URL의 카디널리티가 상당히 비슷하다는 것은, 일반적으로 첫 번째 컬럼 이후의 모든 키 컬럼에 대한 인덱스 마크가, 최소한 현재 그래뉼(granule) 내의 모든 테이블 행에서 앞선 키 컬럼 값이 동일하게 유지되는 동안에만 해당 데이터 범위를 나타낸다는 것을 의미합니다.
예를 들어, 위 다이어그램에서 마크 0과 마크 1의 UserID 값이 서로 다르기 때문에, ClickHouse는 그래뉼 0에 있는 모든 테이블 행의 URL 값이 모두'http://showtopics.html%3...'이상이라고 가정할 수 없습니다. 그러나 위 다이어그램에서 마크 0과 마크 1의 UserID 값이 동일하다면 (즉, 그래뉼 0 내의 모든 테이블 행에서 UserID 값이 동일하게 유지된다는 의미), ClickHouse는 그래뉼 0에 있는 모든 테이블 행의 URL 값이 모두'http://showtopics.html%3...'이상이라고 가정할 수 있습니다.이에 따른 쿼리 실행 성능상의 영향에 대해서는 이후에 더 자세히 설명합니다.
기본 인덱스는 그래뉼을 선택하는 데 사용됩니다
이제 기본 인덱스의 지원을 받아 쿼리를 실행할 수 있습니다.
다음 예제에서는 UserID 749927693에 대해 클릭 수가 가장 많은 URL 상위 10개를 계산합니다.
응답은 다음과 같습니다:
ClickHouse 클라이언트 출력은 이제 전체 테이블 스캔 대신 8.19천 개의 행만 ClickHouse로 스트리밍된 것을 보여 줍니다.
trace 로깅이 활성화된 경우 ClickHouse 서버 로그 파일에는 ClickHouse가 1083개의 UserID 인덱스 마크에 대해 이진 검색을 수행하여, UserID 컬럼 값이 749927693일 수 있는 행을 포함할 가능성이 있는 그래뉼을 식별한 것으로 나타납니다. 이는 평균 시간 복잡도가 O(log2 n)인 19단계로 이루어집니다:
위의 trace log에서 1083개의 기존 마크 중 단 하나만이 쿼리를 만족했음을 확인할 수 있습니다.
Trace Log 세부 정보
마크 176이 식별되었습니다. 여기서 'found left boundary mark'는 포함되고, 'found right boundary mark'는 제외됩니다. 따라서 granule 176의 모든 8192개 행(이 granule은 행 1.441.792에서 시작하며, 이에 대해서는 이 가이드의 뒷부분에서 다시 살펴보겠습니다)이 ClickHouse로 스트리밍되어, UserID 컬럼 값이 749927693인 실제 행을 찾게 됩니다.
또한 예제 쿼리에서 EXPLAIN 절을 사용하여 이를 재현할 수 있습니다.
응답은 다음과 같습니다:
클라이언트 출력 결과를 보면, 총 1083개의 그래뉼 중 1개가 UserID 컬럼 값이 749927693인 행을 포함할 수 있는 그래뉼로 선택되었음을 알 수 있습니다.
쿼리가 복합 키를 구성하는 첫 번째 키 컬럼을 기준으로 필터링될 때, ClickHouse는 해당 키 컬럼의 인덱스 마크에 대해 이진 검색 알고리즘을 수행합니다.
위에서 설명했듯이, ClickHouse는 희소 기본 인덱스(sparse primary index)를 사용하여 이진 검색을 통해 쿼리와 일치할 수 있는 행을 포함할 가능성이 있는 그래뉼을 빠르게 선택합니다.
이는 ClickHouse 쿼리 실행의 **첫 번째 단계(그래뉼 선택)**입니다.
**두 번째 단계(데이터 읽기)**에서는 ClickHouse가 선택된 그래뉼의 위치를 찾아 해당 그래뉼의 모든 행을 ClickHouse 엔진으로 스트리밍하여, 실제로 쿼리와 일치하는 행을 찾습니다.
다음 섹션에서 이 두 번째 단계를 더 자세히 설명합니다.
그래뉼을 찾는 데 사용되는 마크 파일
아래 다이어그램은 우리 테이블의 프라이머리 인덱스 파일의 일부를 보여 줍니다.

위에서 설명했듯이, 인덱스의 1083개 UserID 마크에 대해 이진 검색을 수행하여 마크 176이 식별되었습니다. 따라서 해당 그래뉼 176에는 UserID 컬럼 값이 749.927.693인 행이 포함될 가능성이 있습니다.
Granule Selection Details
위 다이어그램은, 관련된 그래뉼 176의 최소 UserID 값이 749.927.693보다 작고, 다음 마크(마크 177)에 해당하는 그래뉼 177의 최소 UserID 값은 이 값보다 크기 때문에, 마크 176이 이러한 조건을 처음으로 만족하는 인덱스 엔트리임을 보여 줍니다. 따라서 마크 176에 해당하는 그래뉼 176만이 UserID 컬럼 값이 749.927.693인 행을 포함할 가능성이 있습니다.
그래뉼 176의 일부 행에 UserID 컬럼 값이 749.927.693이 실제로 존재하는지(또는 존재하지 않는지) 확인하려면, 이 그래뉼에 속한 8192개의 모든 행을 ClickHouse로 스트리밍해야 합니다.
이를 위해서는 ClickHouse가 그래뉼 176의 물리적 위치를 알아야 합니다.
ClickHouse에서는 우리 테이블의 모든 그래뉼의 물리적 위치가 마크 파일에 저장됩니다. 데이터 파일과 마찬가지로, 테이블의 각 컬럼마다 하나의 마크 파일이 있습니다.
아래 다이어그램은 테이블의 UserID, URL, EventTime 컬럼에 대한 그래뉼의 물리적 위치를 저장하는 세 개의 마크 파일 UserID.mrk, URL.mrk, EventTime.mrk를 보여 줍니다.
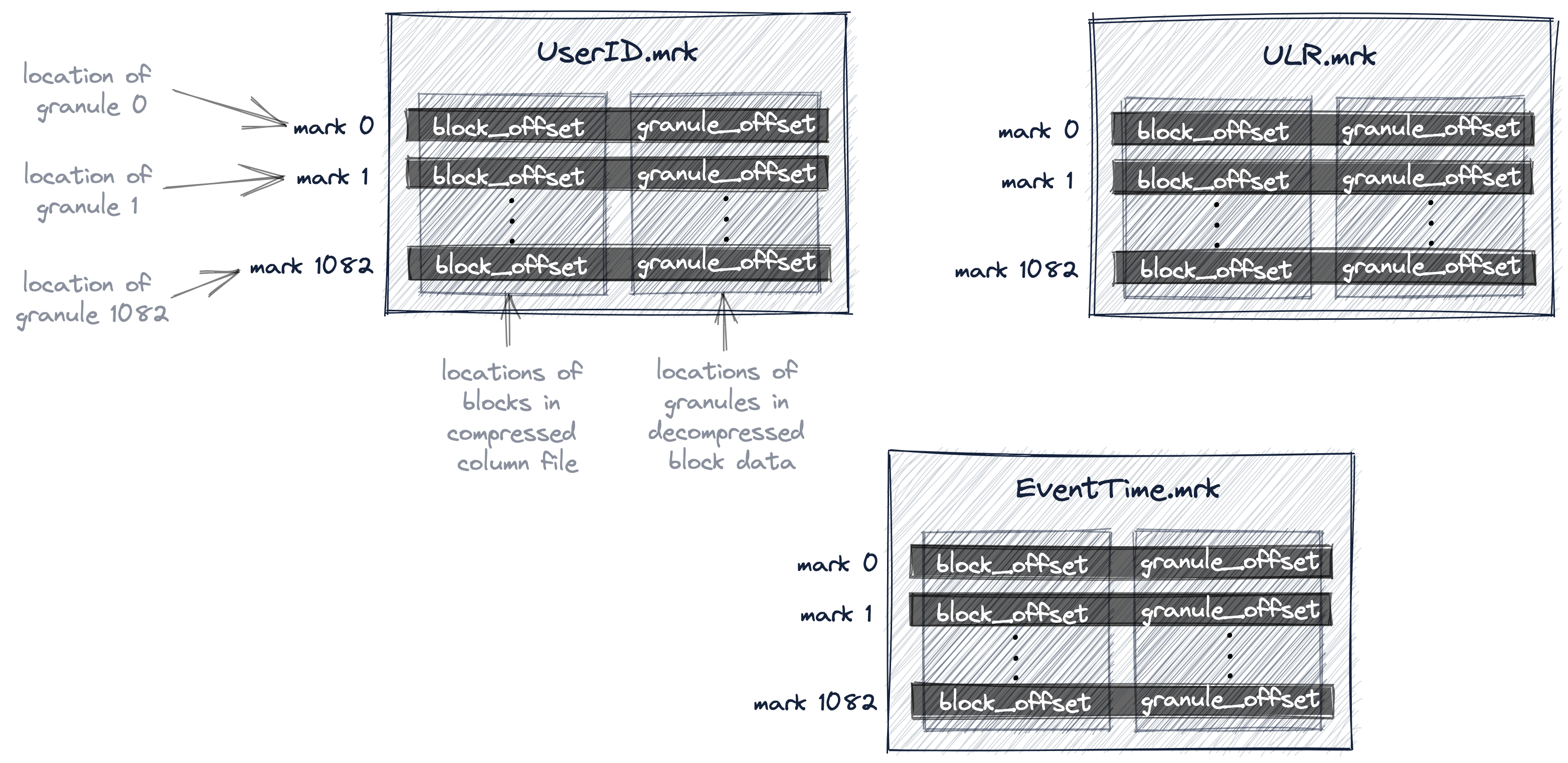
앞서 프라이머리 인덱스가 인덱스 마크를 0부터 번호를 매겨 저장하는 평면적인 비압축 배열 파일(primary.idx)임을 설명했습니다.
마찬가지로, 마크 파일도 마크를 0부터 번호를 매겨 저장하는 평면적인 비압축 배열 파일(*.mrk)입니다.
ClickHouse가 쿼리에 대해 일치하는 행을 포함할 가능성이 있는 그래뉼의 인덱스 마크를 식별하고 선택하면, 해당 그래뉼의 물리적 위치를 얻기 위해 마크 파일에서 위치 기반 배열 조회를 수행할 수 있습니다.
특정 컬럼에 대한 각 마크 파일 엔트리는 오프셋 형태로 두 개의 위치를 저장합니다.
-
첫 번째 오프셋(위 다이어그램의 'block_offset')은 선택된 그래뉼의 압축 버전을 포함하는, 블록을 압축된 컬럼 데이터 파일 내에서 가리킵니다. 이 압축 블록에는 여러 개의 압축된 그래뉼이 포함되어 있을 수 있습니다. 찾아낸 압축 파일 블록은 읽을 때 메인 메모리로 비압축됩니다.
-
두 번째 오프셋(위 다이어그램의 'granule_offset')은 마크 파일에서, 비압축된 블록 데이터 내에서 그래뉼의 위치를 제공합니다.
그 후, 찾아낸 비압축 그래뉼에 속한 8192개의 모든 행이 추가 처리를 위해 ClickHouse로 스트리밍됩니다.
- 와이드 포맷(wide format)을 사용하고 adaptive index granularity를 사용하지 않는 테이블의 경우, ClickHouse는 위에서 시각화한 것처럼
.mrk마크 파일을 사용합니다. 이 파일에는 각 엔트리마다 8바이트 길이의 주소 두 개를 포함하는 엔트리가 들어 있습니다. 이러한 엔트리는 모두 동일한 크기를 갖는 그래뉼의 물리적 위치입니다.
인덱스 granularity(index granularity)는 기본값으로 adaptive이지만, 이 가이드에서 논의를 단순화하고 다이어그램과 결과를 재현 가능하게 만들기 위해 예제 테이블에서는 adaptive index granularity를 비활성화했습니다. 또한 데이터 크기가 min_bytes_for_wide_part보다 크기 때문에(자가 관리형 클러스터의 기본값은 10 MB) 우리 테이블은 와이드 포맷을 사용하고 있습니다.
-
와이드 포맷이며 adaptive index granularity를 사용하는 테이블의 경우, ClickHouse는
.mrk2마크 파일을 사용합니다. 이 파일은.mrk마크 파일과 유사한 엔트리를 갖지만, 각 엔트리에 현재 엔트리와 연결된 그래뉼의 행 수를 나타내는 세 번째 값이 추가됩니다. -
컴팩트 포맷(compact format)을 사용하는 테이블의 경우, ClickHouse는
.mrk3마크 파일을 사용합니다.
왜 프라이머리 인덱스는 인덱스 마크에 대응하는 그래뉼의 물리적 위치를 직접 포함하지 않을까요?
ClickHouse가 설계된 아주 대규모 규모에서는 디스크와 메모리를 매우 효율적으로 사용하는 것이 중요하기 때문입니다.
프라이머리 인덱스 파일은 메인 메모리에 적재될 수 있어야 합니다.
예시 쿼리의 경우, ClickHouse는 프라이머리 인덱스를 사용하여 쿼리와 일치할 수 있는 행을 포함할 가능성이 있는 하나의 그래뉼만 선택했습니다. 그 단일 그래뉼에 대해서만, ClickHouse는 이후 처리를 위해 해당하는 행을 스트리밍하기 위한 물리적 위치 정보가 필요합니다.
또한 이러한 오프셋 정보는 UserID와 URL 컬럼에 대해서만 필요합니다.
오프셋 정보는 쿼리에 사용되지 않는 컬럼, 예를 들어 EventTime 컬럼에는 필요하지 않습니다.
예시 쿼리에서는, ClickHouse는 UserID 데이터 파일(UserID.bin)의 그래뉼 176에 대한 두 개의 물리적 위치 오프셋과, URL 데이터 파일(URL.bin)의 그래뉼 176에 대한 두 개의 물리적 위치 오프셋만 필요로 합니다.
마크 파일이 제공하는 간접 참조 덕분에, 프라이머리 인덱스 내부에 세 개의 컬럼 각각에 대한 1083개 모든 그래뉼의 물리적 위치 엔트리를 직접 저장하지 않아도 됩니다. 따라서 메인 메모리에 불필요한(잠재적으로 사용되지 않을) 데이터를 두는 일을 피할 수 있습니다.
아래 다이어그램과 이어지는 설명은 예시 쿼리에서 ClickHouse가 UserID.bin 데이터 파일 내에서 그래뉼 176을 어떻게 찾는지를 보여줍니다.
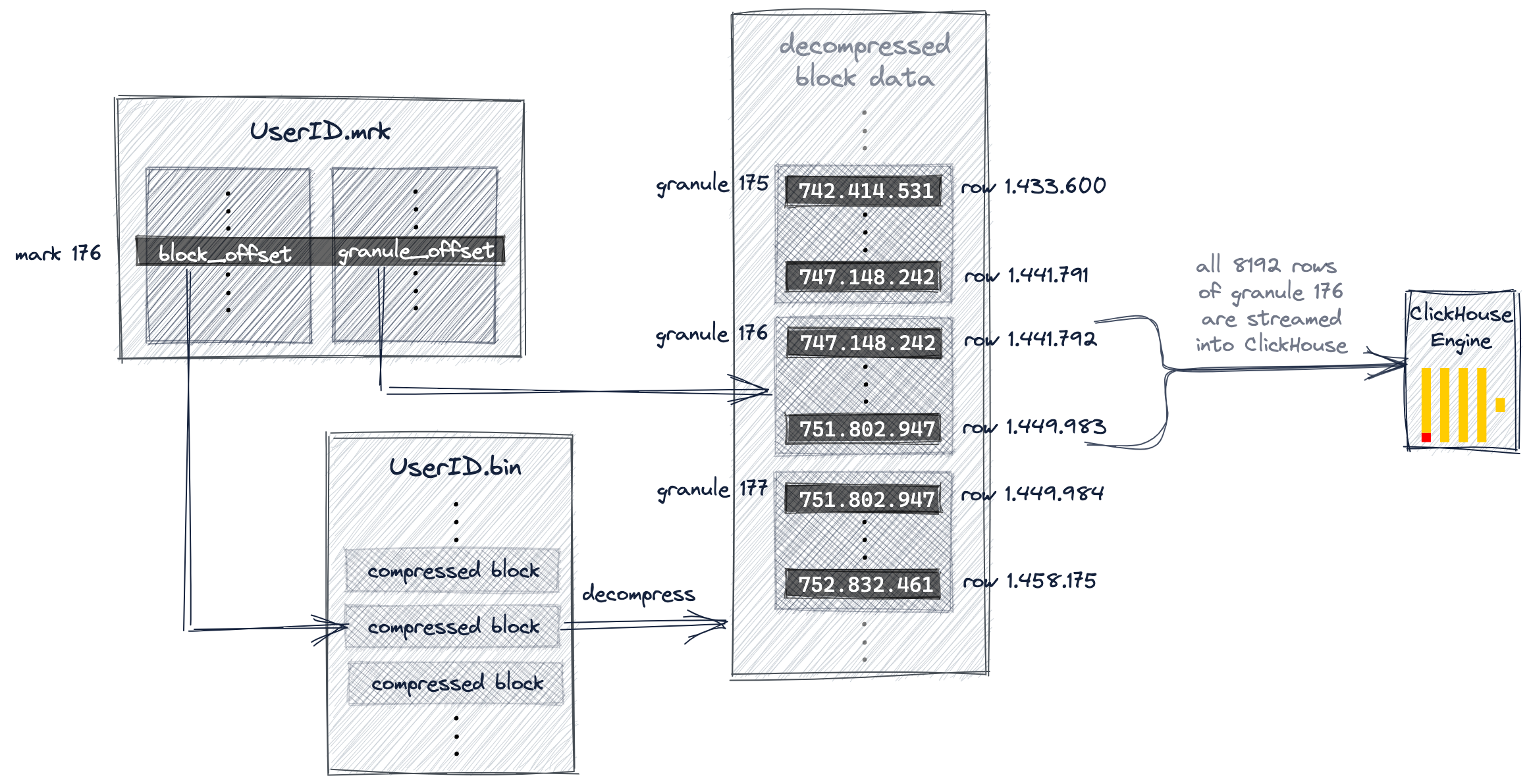
앞서 이 가이드에서 설명했듯이, ClickHouse는 프라이머리 인덱스 마크 176을 선택했고, 따라서 그래뉼 176을 쿼리와 일치할 수 있는 행을 포함할 가능성이 있는 그래뉼로 선택했습니다.
이제 ClickHouse는 선택된 마크 번호(176)를 사용하여 UserID.mrk 마크 파일에서 위치 배열(positional array)을 조회하고, 그래뉼 176을 찾기 위한 두 개의 오프셋을 가져옵니다.
도표에서 보이듯이, 첫 번째 오프셋은 UserID.bin 데이터 파일 내에서 압축된 그래뉼 176을 포함하고 있는 압축 파일 블록을 찾는 데 사용됩니다.
해당 파일 블록을 메인 메모리로 압축 해제한 후에는, 마크 파일의 두 번째 오프셋을 사용하여 압축 해제된 데이터 안에서 그래뉼 176을 찾을 수 있습니다.
ClickHouse는 예시 쿼리(UserID가 749.927.693인 인터넷 사용자가 가장 많이 클릭한 URL 상위 10개)를 실행하기 위해, UserID.bin 데이터 파일과 URL.bin 데이터 파일 양쪽에서 그래뉼 176을 찾아 그 안의 모든 값을 스트리밍해야 합니다.
위의 다이어그램은 ClickHouse가 UserID.bin 데이터 파일의 그래뉼을 찾는 방식을 보여줍니다.
병렬로, ClickHouse는 URL.bin 데이터 파일의 그래뉼 176에 대해서도 동일한 작업을 수행합니다. 각각의 두 그래뉼은 서로 정렬된 상태로 ClickHouse 엔진으로 스트리밍되어 추가 처리를 수행합니다. 즉, UserID가 749.927.693인 모든 행에 대해 URL 값을 그룹별로 집계하고 개수를 센 후, 최종적으로 개수가 큰 순서대로 내림차순 정렬된 상위 10개의 URL 그룹을 출력합니다.
여러 개의 기본 인덱스 사용
보조 키 컬럼은 비효율적일 수도 있고 아닐 수도 있습니다
쿼리가 복합 키의 일부이면서 첫 번째 키 컬럼인 컬럼을 기준으로 필터링할 때, ClickHouse는 해당 키 컬럼의 인덱스 마크에 대해 이진 검색 알고리즘을 실행합니다.
그러나 쿼리가 복합 키의 일부이지만 첫 번째 키 컬럼이 아닌 컬럼을 기준으로 필터링할 때는 어떻게 될까요?
쿼리가 첫 번째 키 컬럼이 아니라 보조 키 컬럼을 기준으로만 명시적으로 필터링하는 시나리오를 다룹니다.
쿼리가 첫 번째 키 컬럼과 그 이후의 임의의 키 컬럼(들)을 모두 기준으로 필터링하는 경우에는 ClickHouse가 첫 번째 키 컬럼의 인덱스 마크에 대해 이진 검색을 수행합니다.
다음은 URL "http://public_search"를 가장 자주 클릭한 상위 10명의 사용자를 계산하는 쿼리입니다:
클라이언트 출력에 따르면 URL 컬럼이 복합 기본 키의 일부임에도 불구하고 ClickHouse가 사실상 전체 테이블 스캔에 가까운 처리를 수행했습니다. ClickHouse는 테이블의 887만 행 가운데 881만 행을 읽습니다.
trace_logging이 활성화되어 있으면 ClickHouse 서버 로그 파일에, ClickHouse가 URL 인덱스 마크 1083개에 대해 일반 제외 검색(generic exclusion search)을 사용하여 URL 컬럼 값이 "http://public_search"일 수 있는 행을 포함하고 있을 가능성이 있는 그래뉼을 식별한 것이 기록됩니다:
위의 샘플 트레이스 로그에서 알 수 있듯이, 1083개의 그래뉼 가운데 1076개가 (마크를 통해) URL 값이 일치하는 행을 포함하고 있을 가능성이 있는 것으로 선택되었습니다.
그 결과 실제로 URL 값 "http://public_search"를 포함하는 행을 식별하기 위해, 10개의 스트림을 사용하여 병렬로 881만 개의 행이 ClickHouse 엔진으로 스트리밍됩니다.
그러나 이후에 보게 되겠지만, 선택된 1076개의 그래뉼 가운데 실제로 일치하는 행을 포함하는 것은 39개의 그래뉼뿐입니다.
복합 기본 키 (UserID, URL)를 기반으로 하는 기본 인덱스는 특정 UserID 값으로 필터링하는 쿼리를 빠르게 수행하는 데에는 매우 유용했지만, 특정 URL 값으로 행을 필터링하는 쿼리를 빠르게 실행하는 데에는 인덱스가 큰 도움을 주지 못하고 있습니다.
그 이유는 URL 컬럼이 첫 번째 키 컬럼이 아니기 때문에 ClickHouse가 URL 컬럼의 인덱스 마크에 대해 이진 검색 대신 일반적인 제외 검색 알고리즘(generic exclusion search algorithm)을 사용하고 있으며, 이 알고리즘의 효율성은 URL 컬럼과 그 앞의 키 컬럼인 UserID 사이의 카디널리티 차이에 좌우되기 때문입니다.
이를 설명하기 위해, 일반적인 제외 검색이 어떻게 동작하는지에 대한 몇 가지 세부 내용을 살펴봅니다.
Generic exclusion search algorithm
다음 내용은 선행 키 컬럼이 낮은(또는 높은) 카디널리티를 가질 때, 보조 컬럼을 통해 그래뉼이 선택되는 경우 ClickHouse generic exclusion search algorithm 이 어떻게 동작하는지를 설명합니다.
두 가지 경우 모두에 대한 예시로 다음을 가정합니다:
- URL 값이 "W3"인 행을 검색하는 쿼리
- UserID와 URL에 대해 단순화된 값을 가진 hits 테이블의 추상화된 버전
- 인덱스를 위한 동일한 복합 프라이머리 키 (UserID, URL). 이는 행이 먼저 UserID 값으로 정렬되고, 동일한 UserID 값을 가진 행들은 URL 기준으로 정렬된다는 의미입니다.
- 그래뉼 크기가 2, 즉 각 그래뉼은 2개의 행을 포함합니다.
아래 다이어그램에서 각 그래뉼의 첫 번째 테이블 행에 해당하는 키 컬럼 값은 주황색으로 표시했습니다.
UserID의 카디널리티가 낮다고 가정해 보겠습니다. 이 경우 동일한 UserID 값이 여러 테이블 행과 그래뉼, 그리고 인덱스 마크 전반에 걸쳐 분포할 가능성이 높습니다. 동일한 UserID를 가진 인덱스 마크들에 대해서는, 인덱스 마크의 URL 값이 오름차순으로 정렬됩니다(테이블 행이 먼저 UserID, 그다음 URL 순으로 정렬되기 때문입니다). 이는 아래에 설명된 것처럼 효율적인 필터링을 가능하게 합니다:
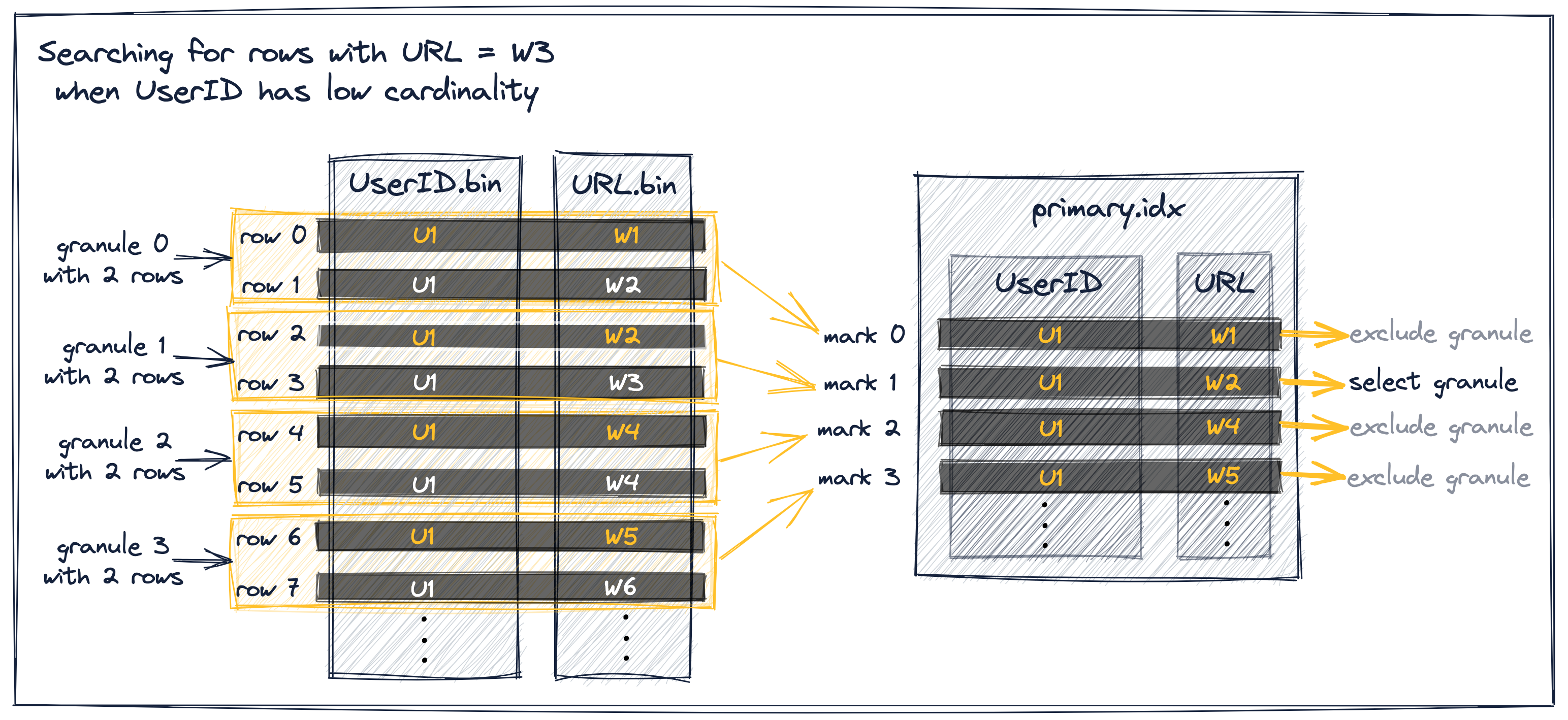
위 다이어그램에 있는 추상 샘플 데이터에서 그래뉼 선택 과정에는 세 가지 다른 시나리오가 있습니다:
-
URL 값이 W3보다 작고, 바로 뒤따르는 인덱스 마크의 URL 값도 W3보다 작은 인덱스 마크 0은 제외할 수 있습니다. 이는 마크 0과 1이 동일한 UserID 값을 갖기 때문입니다. 이 배제 전제조건은 그래뉼 0이 전적으로 U1 UserID 값으로만 구성된다는 것을 보장하므로, ClickHouse가 그래뉼 0의 최대 URL 값도 W3보다 작다고 가정하고 그래뉼을 제외할 수 있게 해줍니다.
-
URL 값이 W3보다 작거나 같고, 바로 뒤따르는 인덱스 마크의 URL 값이 W3보다 크거나 같은 인덱스 마크 1은 선택됩니다. 이는 그래뉼 1이 URL 값이 W3인 행을 포함할 가능성이 있음을 의미합니다.
-
URL 값이 W3보다 큰 인덱스 마크 2와 3은 제외할 수 있습니다. 프라이머리 인덱스의 인덱스 마크는 각 그래뉼의 첫 번째 테이블 행에 대한 키 컬럼 값을 저장하고, 테이블 행은 키 컬럼 값 기준으로 디스크에 정렬되어 있으므로, 그래뉼 2와 3은 URL 값 W3를 포함할 수 없습니다.
UserID의 카디널리티가 높은 경우, 동일한 UserID 값이 여러 테이블 행과 그래뉼에 분산될 가능성은 낮습니다. 이는 인덱스 마크에 대한 URL 값이 단조 증가하지 않음을 의미합니다:
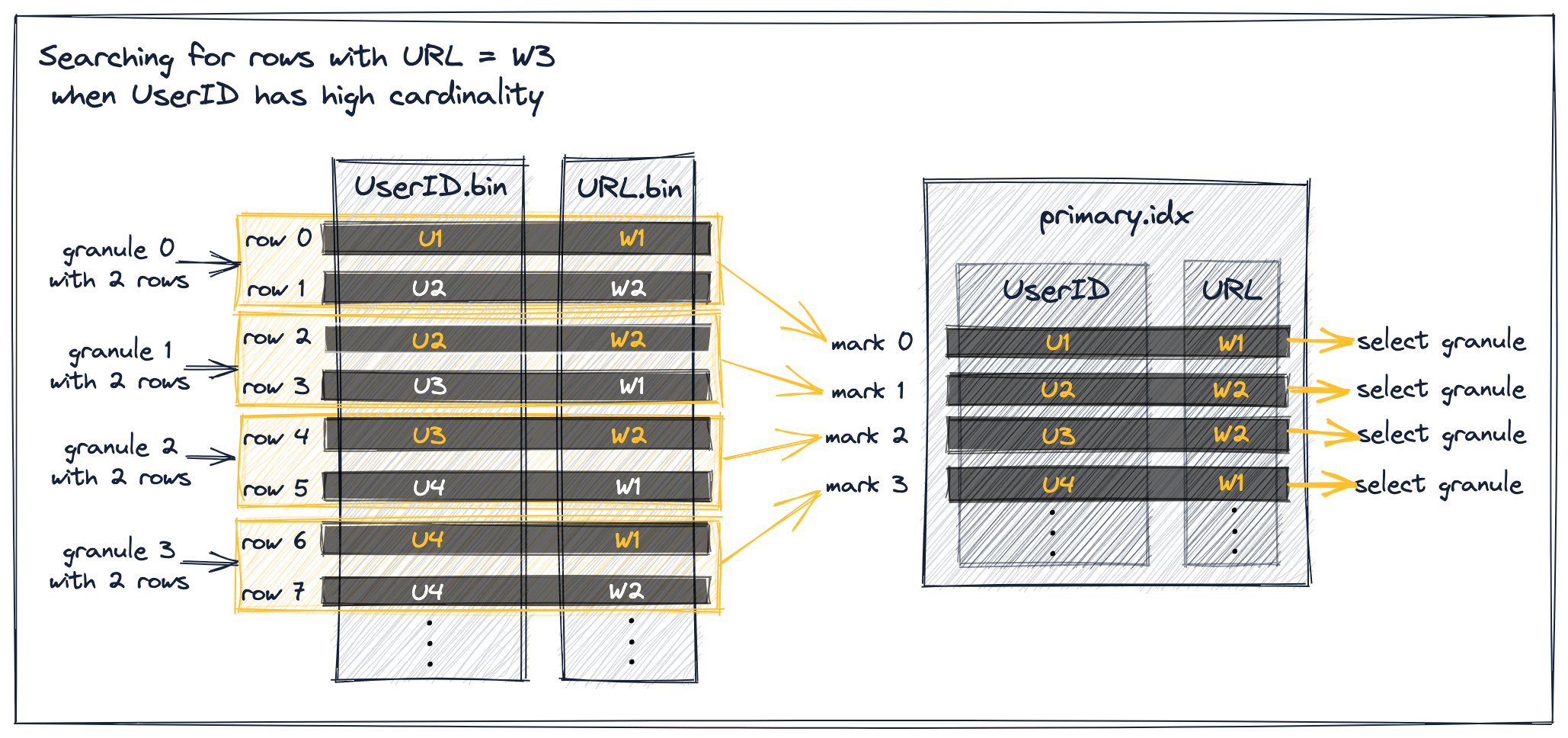
위 다이어그램에서 볼 수 있듯이, URL 값이 W3보다 작은 모든 마크는 해당 그래뉼의 행을 ClickHouse 엔진으로 스트리밍하기 위해 선택됩니다.
이는 다이어그램에 있는 모든 인덱스 마크가 앞서 설명한 시나리오 1에 해당하지만, 바로 뒤따르는 인덱스 마크가 현재 마크와 동일한 UserID 값을 가져야 한다는 배제 전제조건을 만족하지 못하기 때문에 제외할 수 없기 때문입니다.
예를 들어, URL 값이 W3보다 작고, 바로 뒤따르는 인덱스 마크의 URL 값도 W3보다 작은 인덱스 마크 0을 생각해 보면, 바로 뒤따르는 인덱스 마크 1이 현재 마크 0과 동일한 UserID 값을 갖지 않기 때문에 이는 제외될 수 없습니다.
결과적으로 ClickHouse는 그래뉼 0의 최대 URL 값에 대해 어떤 가정도 할 수 없습니다. 대신 그래뉼 0이 URL 값 W3를 가진 행을 잠재적으로 포함한다고 가정해야 하며, 마크 0을 선택할 수밖에 없습니다.
동일한 시나리오는 마크 1, 2, 3에도 해당됩니다.
ClickHouse는 복합 키(compound key)에 포함되어 있지만 첫 번째 키 컬럼이 아닌 컬럼을 기준으로 쿼리를 필터링하는 경우, generic exclusion search algorithm을 binary search algorithm 대신 사용하며, 이 알고리즘은 앞에 오는 키 컬럼의 카디널리티가 더 낮을수록 가장 효과적입니다.
예제 데이터 세트에서는 두 키 컬럼(UserID, URL)의 카디널리티가 모두 비슷하게 높으며, 앞에서 설명했듯이 URL 컬럼 앞에 오는 키 컬럼의 카디널리티가 높거나 비슷하게 높은 경우에는 generic exclusion search algorithm이 그다지 효과적이지 않습니다.
데이터 스키핑 인덱스에 대한 참고 사항
UserID와 URL의 카디널리티가 비슷하게 높으므로, URL에 대한 쿼리 필터링 역시 URL 컬럼에 보조 데이터 스키핑 인덱스를 생성하더라도 복합 기본 키(UserID, URL)를 가진 테이블에 대해 큰 이점을 얻지 못합니다.
예를 들어, 다음 두 SQL 문은 테이블의 URL 컬럼에 minmax 데이터 스키핑 인덱스를 생성하고 데이터를 적재합니다:
ClickHouse는 이제 추가 인덱스를 생성하여, 연속된 4개의 그래뉼 그룹마다(ALTER TABLE 문에서 GRANULARITY 4 절을 참고하십시오) 최소 및 최대 URL 값을 저장합니다:

첫 번째 인덱스 엔트리(위 다이어그램의 'mark 0')는 테이블의 첫 4개 그래뉼에 속하는 행에 대한 최소 및 최대 URL 값을 저장합니다.
두 번째 인덱스 엔트리('mark 1')는 테이블의 다음 4개 그래뉼에 속하는 행에 대한 최소 및 최대 URL 값을 저장하며, 이후도 같은 방식으로 계속됩니다.
(ClickHouse는 또한 인덱스 마크와 연관된 그래뉼 그룹을 찾기 위한 데이터 스키핑 인덱스를 위해 사용할 별도의 마크 파일도 생성합니다.)
UserID와 URL의 카디널리티가 비슷하게 높기 때문에, 이 보조 데이터 스키핑 인덱스는 URL을 기준으로 필터링하는 쿼리가 실행될 때 선택 대상에서 그래뉼을 제외하는 데 실질적으로 도움이 되지 않습니다.
쿼리가 찾고 있는 특정 URL 값(즉, 'http://public_search')은 인덱스가 각 그래뉼 그룹에 대해 저장하는 최소값과 최대값 사이에 있을 가능성이 매우 높습니다. 그 결과 ClickHouse는 해당 그래뉼 그룹에 쿼리와 일치하는 행이 포함되어 있을 수 있으므로, 그 그래뉼 그룹을 선택할 수밖에 없습니다.
여러 개의 기본(primary) 인덱스를 사용해야 하는 경우
그 결과, 특정 URL을 기준으로 행을 필터링하는 샘플 쿼리의 속도를 크게 높이려면 해당 쿼리에 최적화된 기본(primary) 인덱스를 사용해야 합니다.
또한 특정 UserID를 기준으로 행을 필터링하는 샘플 쿼리의 우수한 성능을 유지하려면 여러 개의 기본(primary) 인덱스를 사용해야 합니다.
아래에서는 이를 구현하는 여러 가지 방법을 보여줍니다.
Options for creating additional primary indexes
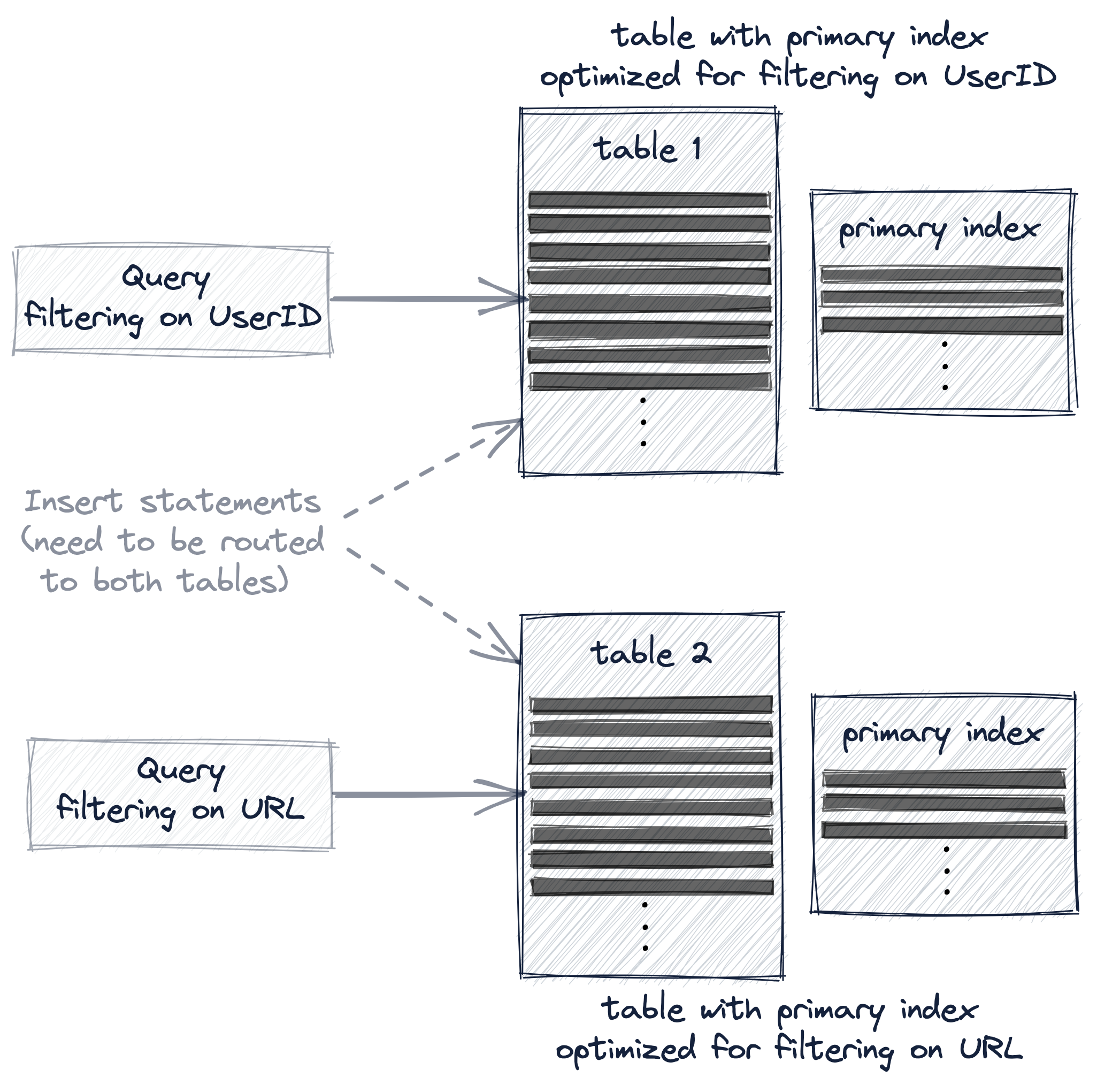
예시 쿼리 두 개(특정 UserID 값을 갖는 행을 필터링하는 쿼리와 특정 URL 값을 갖는 행을 필터링하는 쿼리)의 성능을 모두 대폭 향상하려면, 다음 세 가지 옵션 중 하나를 사용하여 여러 개의 프라이머리 인덱스를 사용해야 합니다:
- 다른 프라이머리 키를 가진 두 번째 테이블을 생성합니다.
- 기존 테이블에 materialized view를 생성합니다.
- 기존 테이블에 projection을 추가합니다.
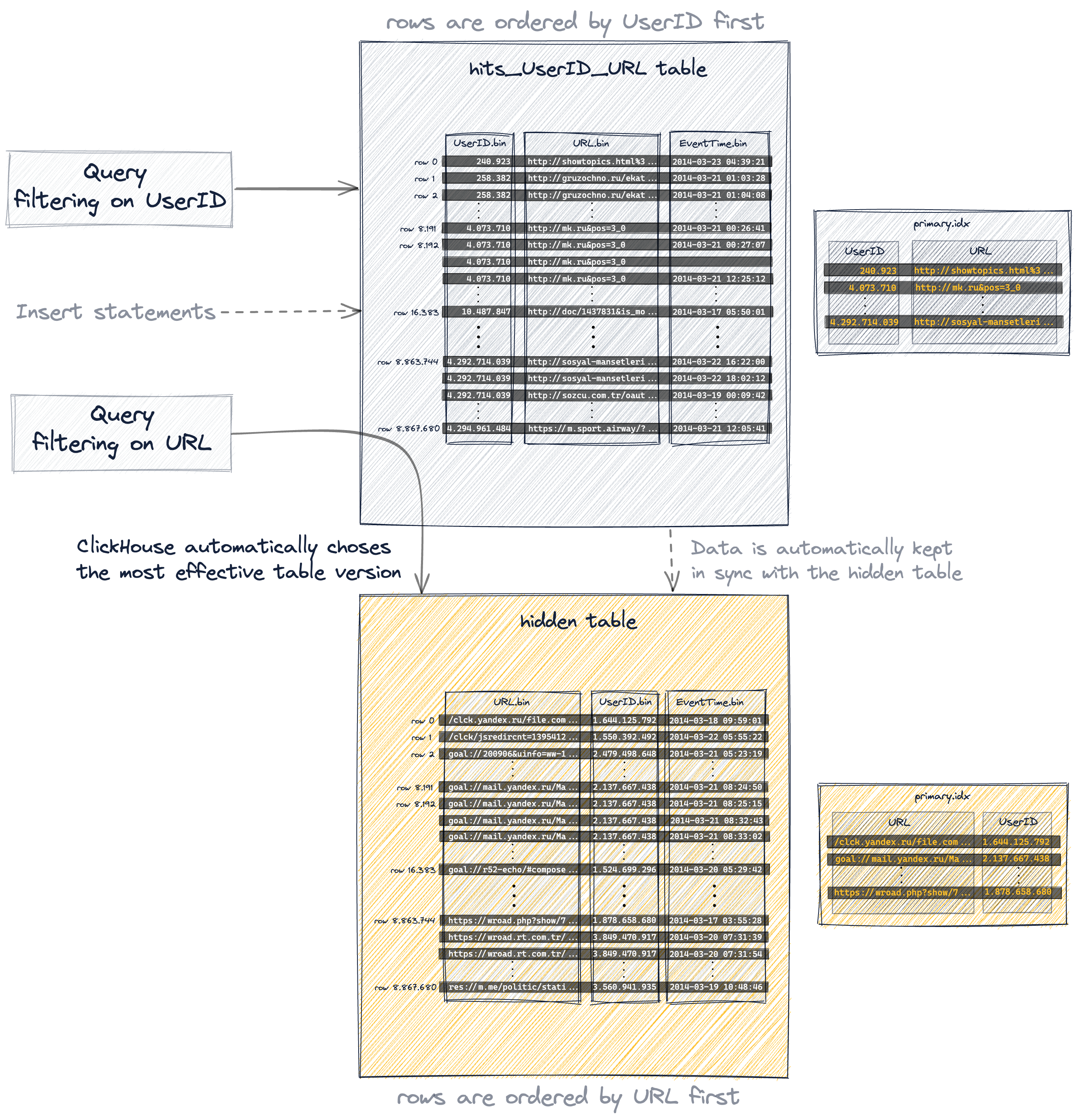
세 가지 옵션 모두, 테이블의 프라이머리 인덱스와 행 정렬 순서를 재구성하기 위해 예시 데이터가 추가 테이블에 사실상 복제됩니다.
하지만 이 세 가지 옵션은 쿼리와 INSERT SQL 문 라우팅과 관련해, 그 추가 테이블이 사용자에게 얼마나 투명한지에 따라 차이가 있습니다.
다른 프라이머리 키를 가진 두 번째 테이블을 생성하는 경우, 쿼리는 해당 쿼리에 가장 적합한 테이블 버전으로 명시적으로 보내야 하며, 두 테이블을 동기 상태로 유지하기 위해 새 데이터는 두 테이블 모두에 명시적으로 INSERT해야 합니다:
materialized view의 경우, 추가 테이블은 암시적으로 생성되며 두 테이블 간의 데이터 동기화는 자동으로 유지됩니다:
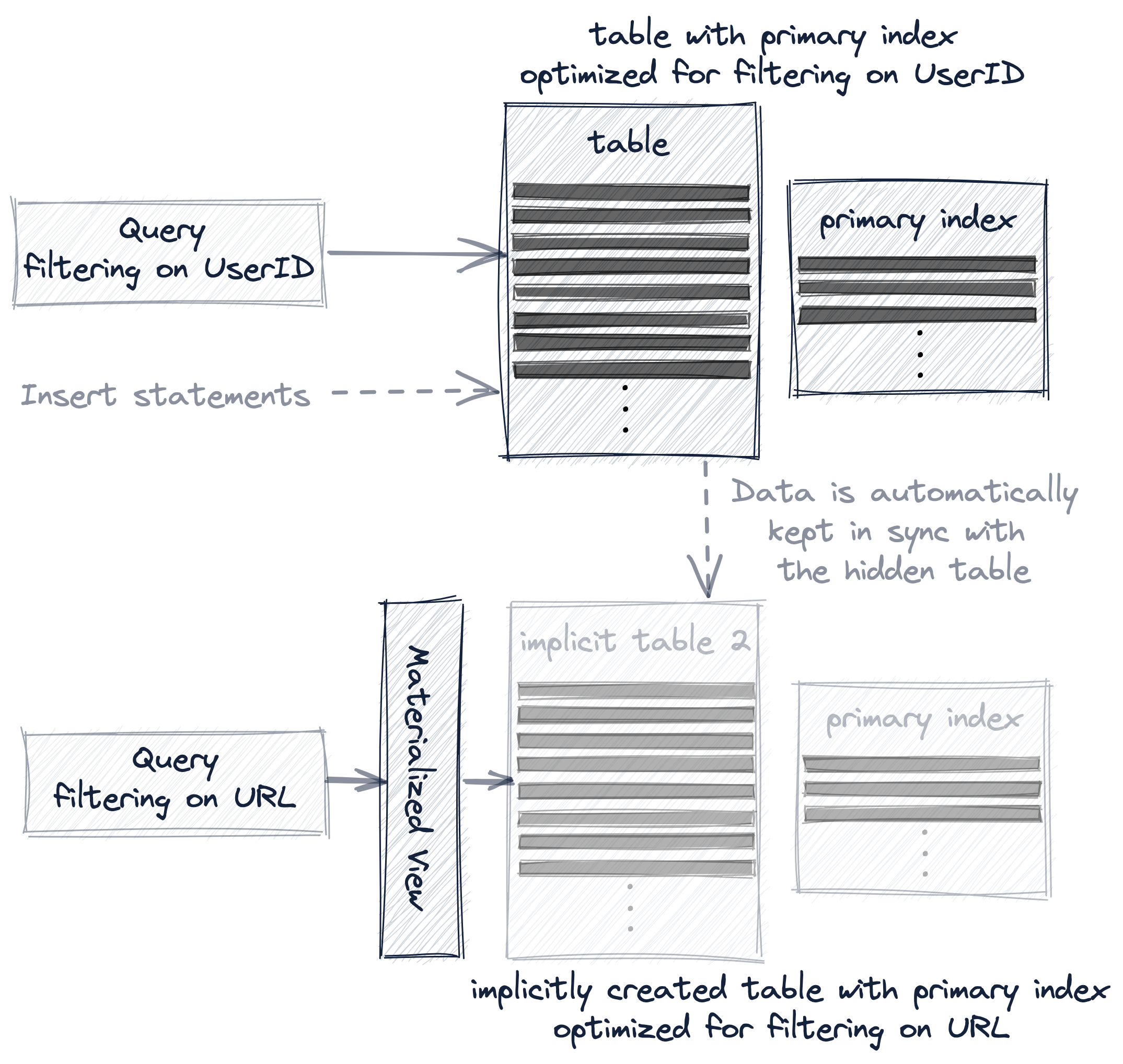
그리고 projection은 가장 투명한 옵션입니다. 암시적으로 생성되고 숨겨진 추가 테이블을 데이터 변경과 함께 자동으로 동기화할 뿐만 아니라, ClickHouse가 쿼리에 대해 가장 효율적인 테이블 버전을 자동으로 선택하기 때문입니다:
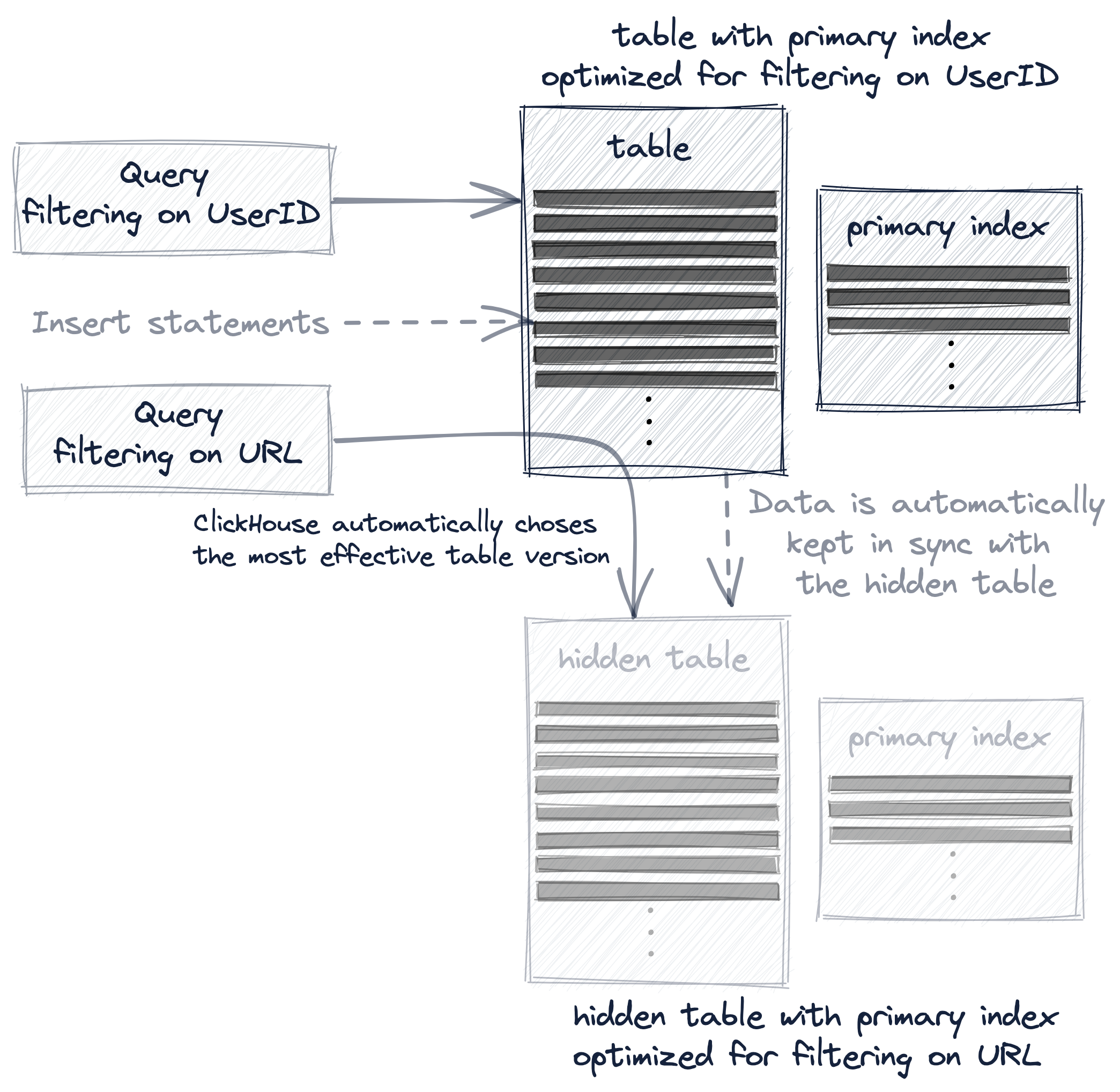
다음에서는 여러 개의 프라이머리 인덱스를 생성하고 사용하는 이러한 세 가지 옵션을 실제 예제와 함께 좀 더 자세히 설명합니다.
옵션 1: 보조 테이블
기본 키에서 (기존 테이블과 비교하여) 키 컬럼의 순서를 바꾼 새로운 보조 테이블을 생성합니다:
원본 테이블에서 887만 개의 모든 행을 보조 테이블에 삽입합니다:
응답은 다음과 같습니다:
마지막으로 테이블을 최적화합니다:
프라이머리 키에서 컬럼 순서를 변경했기 때문에 이제 삽입된 행은 원래 테이블과 비교했을 때 디스크에 다른 사전식 순서로 저장되며, 따라서 해당 테이블의 1083개 그래뉼 역시 이전과는 다른 값을 포함하게 됩니다:
다음은 그 결과로 생성된 프라이머리 키입니다:

이제 이를 사용하여 URL 컬럼을 기준으로 필터링하는 예제 쿼리의 실행 속도를 크게 향상시키고, URL 「http://public_search」을 가장 자주 클릭한 상위 10명의 사용자를 계산할 수 있습니다:
응답은 다음과 같습니다:
이제 ClickHouse는 거의 전체 테이블 스캔을 수행하는 대신 그 쿼리를 훨씬 더 효율적으로 실행했습니다.
UserID가 첫 번째, URL이 두 번째 키 컬럼이었던 원본 테이블의 기본 인덱스를 사용할 때에는, ClickHouse가 그 쿼리를 실행하기 위해 인덱스 마크에 대해 generic exclusion search를 수행했으며, UserID와 URL의 카디널리티가 둘 다 비슷하게 높았기 때문에 그다지 효율적이지 않았습니다.
기본 인덱스에서 URL을 첫 번째 컬럼으로 두면서, 이제 ClickHouse는 인덱스 마크에 대해 binary search를 실행합니다. 이에 해당하는 트레이스 로그는 ClickHouse 서버 로그 파일에서 이를 확인할 수 있음을 보여 줍니다:
ClickHouse는 일반적인 제외 검색을 사용했을 때의 1076개 대신, 단 39개의 인덱스 마크만 선택했습니다.
추가된 테이블은 URL을 기준으로 필터링하는 예시 쿼리의 실행 속도를 높이도록 최적화되어 있습니다.
원래 테이블을 사용했을 때 해당 쿼리의 좋지 않은 성능과 마찬가지로, UserIDs로 필터링하는 예시 쿼리는 새로 추가한 테이블에서도 그다지 효율적으로 실행되지는 않습니다. 이제 UserID가 해당 테이블의 기본 인덱스에서 두 번째 키 컬럼이 되었기 때문에 ClickHouse는 그래뉼 선택에 일반적인 제외 검색을 사용하게 되며, 이는 UserID와 URL처럼 카디널리티가 비슷하게 높은 경우에는 그리 효과적이지 않습니다.
자세한 내용은 상세 정보 상자를 여십시오.
이제 두 개의 테이블이 있습니다. 각각 UserIDs로 필터링하는 쿼리를 빠르게 실행하도록 최적화된 테이블과, URL로 필터링하는 쿼리를 빠르게 실행하도록 최적화된 테이블입니다:
옵션 2: materialized view
기존 테이블을 기반으로 materialized view를 생성합니다.
응답은 다음과 같이 표시됩니다.
- 뷰의 프라이머리 키에서 키 컬럼의 순서를 (원본 테이블과 비교했을 때) 변경합니다.
- materialized view는 암시적으로 생성된 테이블을 기반으로 하며, 이 테이블의 행 순서와 프라이머리 인덱스는 지정된 프라이머리 키 정의를 기준으로 합니다.
- 암시적으로 생성된 테이블은
SHOW TABLES쿼리로 조회되며, 이름은.inner로 시작합니다. - 먼저 materialized view의 기반 테이블을 명시적으로 생성한 다음,
TO [db].[table]절을 통해 그 테이블을 대상으로 하도록 뷰를 생성할 수도 있습니다. POPULATE키워드를 사용하여 암시적으로 생성된 테이블을 소스 테이블 hits_UserID_URL의 887만 개 모든 행으로 즉시 채웁니다.- 새로운 행이 소스 테이블 hits_UserID_URL에 삽입되면, 해당 행들은 암시적으로 생성된 테이블에도 자동으로 삽입됩니다.
- 결과적으로 암시적으로 생성된 테이블은 명시적으로 생성한 보조 테이블과 동일한 행 순서와 프라이머리 인덱스를 갖게 됩니다.
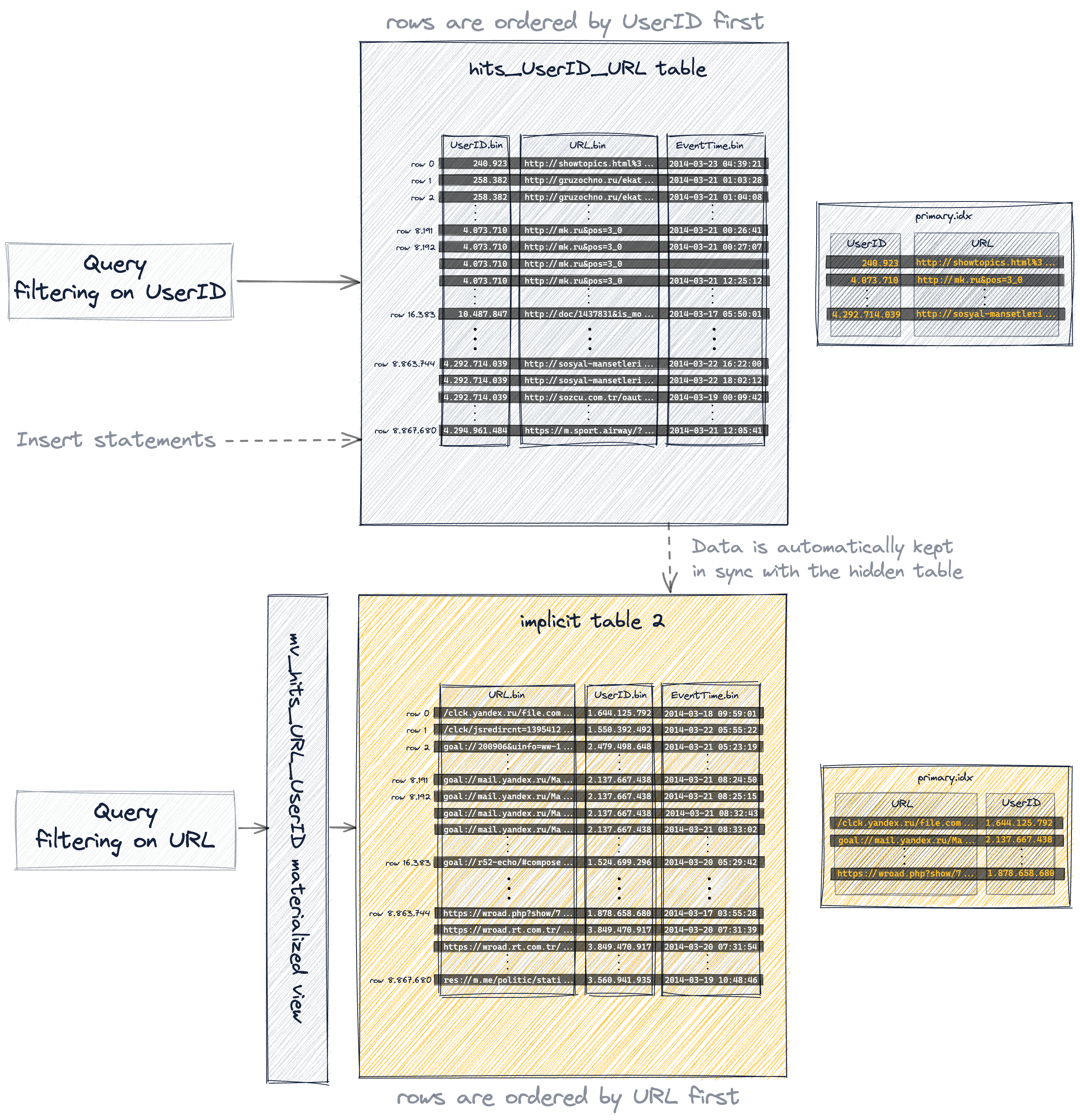
ClickHouse는 암시적으로 생성된 테이블의 컬럼 데이터 파일 (.bin), 마크 파일 (.mrk2), 프라이머리 인덱스 (primary.idx)를 ClickHouse 서버의 데이터 디렉터리 내 특수 폴더에 저장합니다:
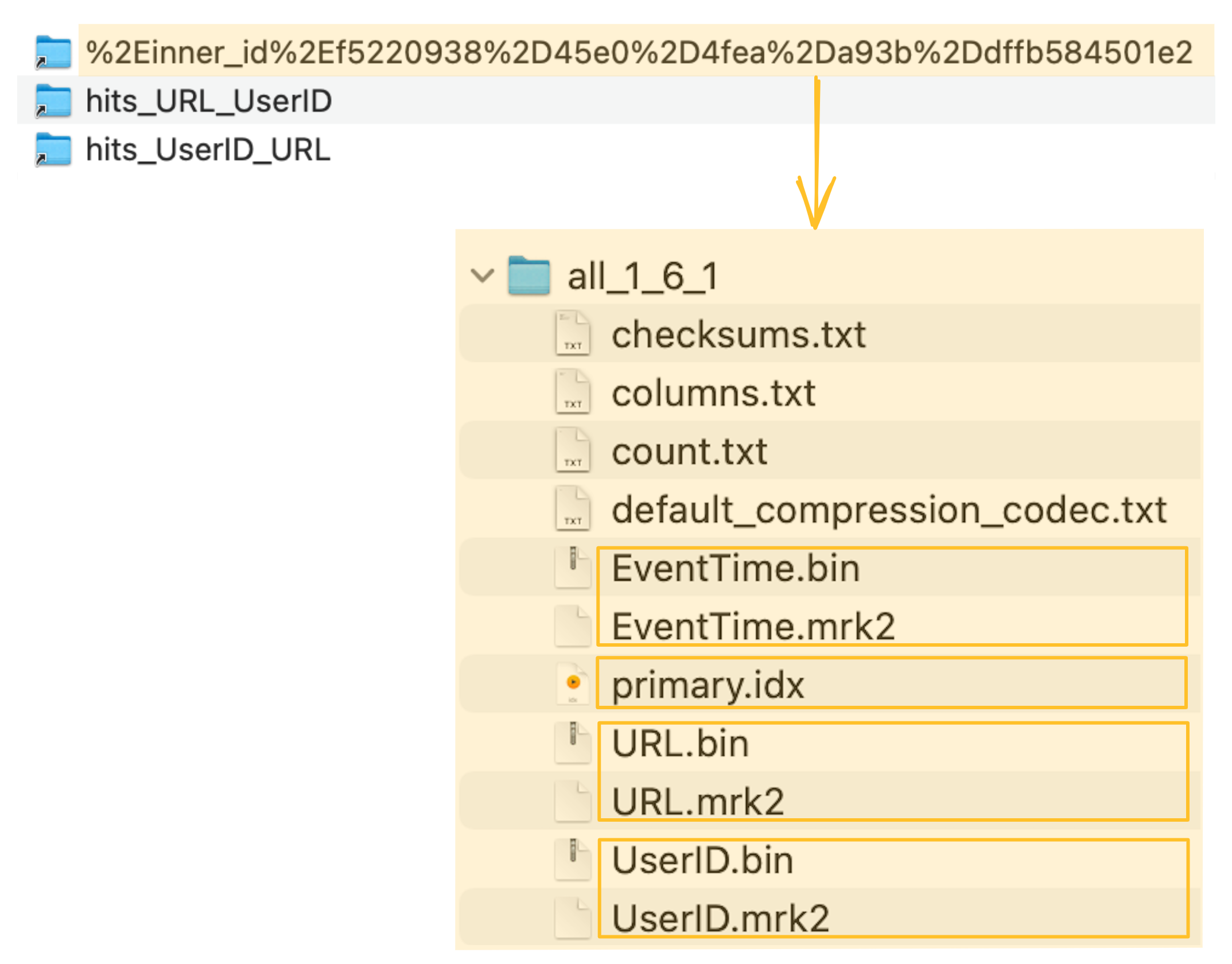
materialized view를 뒷받침하는 암시적으로 생성된 테이블(및 그 프라이머리 인덱스)은 이제 URL 컬럼을 기준으로 필터링하는 예제 쿼리의 실행 속도를 크게 높이는 데 사용할 수 있습니다.
응답은 다음과 같습니다:
materialized view를 뒷받침하는 암묵적으로 생성된 테이블(그리고 그 기본 키 인덱스)이 명시적으로 생성한 보조 테이블과 사실상 동일하기 때문에, 쿼리는 명시적으로 생성한 테이블을 사용할 때와 동일한 방식으로 실행됩니다.
ClickHouse 서버 로그 파일의 해당 트레이스 로그를 보면, ClickHouse가 인덱스 마크에 대해 이진 검색을 수행하고 있음을 확인할 수 있습니다:
옵션 3: 프로젝션
기존 테이블에 프로젝션을 생성하십시오:
그리고 PROJECTION을 구체화하십시오:
- 프로젝션은 지정된
ORDER BY절을 기반으로 행 순서와 프라이머리 인덱스를 가지는 숨겨진 테이블을 생성합니다. - 숨겨진 테이블은
SHOW TABLES쿼리 결과에 표시되지 않습니다. MATERIALIZE키워드를 사용하여 프로젝션의 숨겨진 테이블을 소스 테이블 hits_UserID_URL의 총 887만 개 행으로 즉시 채웁니다.- 소스 테이블 hits_UserID_URL에 새로운 행이 삽입되면, 해당 행은 자동으로 숨겨진 테이블에도 삽입됩니다.
- 쿼리는 항상 (구문상) 프로젝션의 소스 테이블인 hits_UserID_URL을 대상으로 하지만, 숨겨진 테이블의 행 순서와 프라이머리 인덱스가 더 효율적인 쿼리 실행을 가능하게 하는 경우에는 그 숨겨진 테이블이 대신 사용됩니다.
- 프로젝션의 ORDER BY가 쿼리의 ORDER BY와 일치하더라도, 프로젝션이 ORDER BY를 사용하는 쿼리를 더 효율적으로 만들어 주지는 않는다는 점에 유의하십시오 (https://github.com/ClickHouse/ClickHouse/issues/47333 참조).
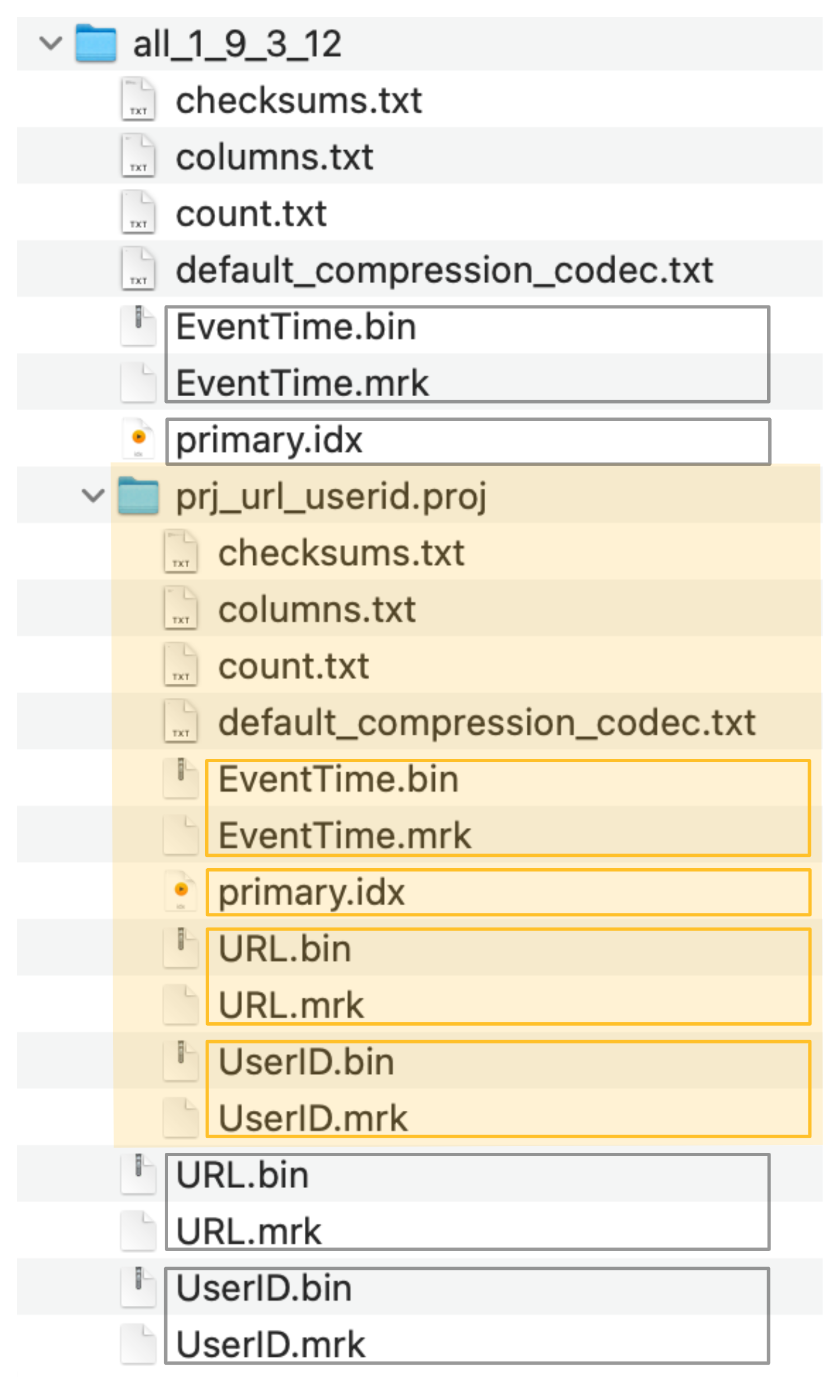
- 결과적으로 암묵적으로 생성된 숨겨진 테이블은 명시적으로 생성한 세컨더리 테이블과 동일한 행 순서와 프라이머리 인덱스를 가집니다:
ClickHouse는 숨겨진 테이블의 컬럼 데이터 파일 (.bin), 마크 파일 (.mrk2), 그리고 프라이머리 인덱스 (primary.idx)를, 아래 스크린샷에서 주황색으로 표시된 특수 폴더에 소스 테이블의 데이터 파일, 마크 파일, 프라이머리 인덱스 파일 옆에 저장합니다:
프로젝션에 의해 생성된 숨겨진 테이블(및 해당 프라이머리 인덱스)은 이제 URL 컬럼을 기준으로 필터링하는 예제 쿼리의 실행을 크게 가속하는 데 암묵적으로 사용될 수 있습니다. 이때 쿼리는 구문상으로는 프로젝션의 소스 테이블을 대상으로 한다는 점에 유의하십시오.
응답은 다음과 같습니다:
프로젝션에 의해 생성되는 숨겨진 테이블과 그 기본 인덱스는 직접 생성했던 보조 테이블과 실질적으로 동일하므로, 쿼리는 그 보조 테이블을 명시적으로 생성해 사용했을 때와 마찬가지 방식으로 실행됩니다.
ClickHouse 서버 로그 파일의 해당 trace 로그 항목은 ClickHouse가 인덱스 마크에 대해 이진 검색을 수행하고 있음을 보여 줍니다:
Summary
복합 프라이머리 키(UserID, URL)를 가진 테이블의 프라이머리 인덱스는 UserID로 필터링하는 쿼리의 속도를 높이는 데 매우 유용했습니다. 그러나 URL 컬럼이 복합 프라이머리 키의 일부임에도 불구하고, 해당 인덱스는 URL로 필터링하는 쿼리의 성능을 높이는 데에는 큰 도움이 되지 않았습니다.
반대로, 복합 프라이머리 키(URL, UserID)를 가진 테이블의 프라이머리 인덱스는 URL로 필터링하는 쿼리의 속도를 높였지만, UserID로 필터링하는 쿼리를 가속하는 데에는 큰 효과가 없었습니다.
프라이머리 키 컬럼인 UserID와 URL의 카디널리티가 비슷하게 높기 때문에, 두 번째 키 컬럼으로 필터링하는 쿼리는 두 번째 키 컬럼이 인덱스에 포함되어 있더라도 큰 이점을 얻지 못합니다.
따라서 프라이머리 인덱스에서 두 번째 키 컬럼을 제거하는 것이 타당하며(인덱스의 메모리 사용량 감소), 대신 여러 개의 프라이머리 인덱스를 사용하는 것이 더 합리적입니다.
그러나 복합 프라이머리 키의 키 컬럼들 사이에 카디널리티 차이가 큰 경우에는, 프라이머리 키 컬럼을 카디널리티 오름차순으로 정렬하는 것이 쿼리에 유리합니다.
키 컬럼들 사이의 카디널리티 차이가 클수록 키에서 해당 컬럼들의 순서가 더 중요해집니다. 다음 섹션에서 이를 보여 줍니다.
키 컬럼을 효율적으로 배치하기
복합 기본 키에서는 키 컬럼의 순서가 다음 두 가지 모두에 상당한 영향을 줄 수 있습니다.
- 쿼리에서 보조 키 컬럼을 필터링하는 효율성
- 테이블 데이터 파일의 압축률
이를 보여 주기 위해, 각 행이 인터넷 「user」(UserID 컬럼)가 어떤 URL(URL 컬럼)에 접근했을 때 그것이 봇 트래픽으로 표시되었는지 여부(IsRobot 컬럼)를 나타내는 세 개의 컬럼을 포함하는 웹 트래픽 샘플 데이터 세트의 한 버전을 사용합니다.
다음과 같은 전형적인 웹 분석 쿼리를 가속하는 데 사용할 수 있는, 위 세 컬럼 전체를 포함하는 복합 기본 키를 사용합니다.
- 특정 URL에 대한 트래픽 중 얼마나 많은 비율이 봇인지
- 특정 사용자가 봇(이 아닌지)에 대해 얼마나 확신할 수 있는지(해당 사용자로부터의 트래픽 중 어느 정도 비율이 봇 트래픽이라고 (아니라고) 가정되는지)
복합 기본 키를 구성하는 키 컬럼으로 사용하려는 세 컬럼의 카디널리티를 계산하기 위해 다음 쿼리를 사용합니다(로컬 테이블을 생성하지 않고 TSV 데이터를 즉석에서 쿼리하기 위해 URL table function을 사용한다는 점에 유의하십시오). 이 쿼리를 clickhouse client에서 실행합니다.
응답은 다음과 같습니다:
URL 컬럼과 IsRobot 컬럼 사이를 비롯해 카디널리티에 큰 차이가 있음을 알 수 있습니다. 따라서 복합 기본 키에서 이 컬럼들의 순서는 해당 컬럼을 기준으로 필터링하는 쿼리의 성능을 효율적으로 높이고, 테이블의 컬럼 데이터 파일에 대해 최적의 압축 비율을 달성하는 데 모두 중요합니다.
이를 보여 주기 위해 봇 트래픽 분석 데이터에 대해 두 가지 버전의 테이블을 생성합니다.
- 복합 기본 키
(URL, UserID, IsRobot)를 사용하고, 키 컬럼을 카디널리티 기준 내림차순으로 정렬한 테이블hits_URL_UserID_IsRobot - 복합 기본 키
(IsRobot, UserID, URL)를 사용하고, 키 컬럼을 카디널리티 기준 오름차순으로 정렬한 테이블hits_IsRobot_UserID_URL
복합 기본 키 (URL, UserID, IsRobot)를 사용하는 테이블 hits_URL_UserID_IsRobot을(를) 생성합니다.
그리고 여기에 887만 개의 행을 채워 넣습니다:
응답은 다음과 같습니다:
다음으로, (IsRobot, UserID, URL)를 복합 기본 키로 갖는 테이블 hits_IsRobot_UserID_URL을(를) 생성합니다:
그리고 이 테이블에도 이전 테이블과 마찬가지로 887만 개의 행을 채웁니다.
응답은 다음과 같습니다:
보조 키 컬럼에 대한 효율적인 필터링
쿼리가 복합 키를 구성하는 컬럼 중 적어도 하나를 조건으로 필터링하고, 그 컬럼이 첫 번째 키 컬럼인 경우, ClickHouse는 해당 키 컬럼의 인덱스 마크를 대상으로 이진 탐색 알고리즘을 실행합니다.
쿼리가 복합 키를 구성하는 컬럼만을 조건으로 필터링하지만, 그 컬럼이 첫 번째 키 컬럼이 아닌 경우, ClickHouse는 해당 키 컬럼의 인덱스 마크를 대상으로 일반적인 배제 탐색 알고리즘(generic exclusion search algorithm)을 사용합니다.
두 번째 경우에는 복합 기본 키에서 키 컬럼의 순서가 일반적인 배제 탐색 알고리즘의 효율성에 중요한 영향을 미칩니다.
다음은 키 컬럼을 카디널리티가 큰 순서대로 (URL, UserID, IsRobot)로 지정한 테이블에서 UserID 컬럼을 조건으로 필터링하는 쿼리입니다:
응답은 다음과 같습니다:
이는 키 컬럼 (IsRobot, UserID, URL)의 카디널리티를 기준으로 오름차순 정렬한 테이블에서 실행한 동일한 쿼리입니다:
응답은 다음과 같습니다:
키 컬럼을 카디널리티 오름차순으로 정렬한 테이블에서는 쿼리 실행이 훨씬 더 효율적이고 빠르다는 것을 확인할 수 있습니다.
그 이유는 generic exclusion search algorithm이 선행 키 컬럼의 카디널리티가 더 낮을 때 보조 키 컬럼을 통해 그래뉼을 선택하는 경우에 가장 효과적으로 동작하기 때문입니다. 이 점에 대해서는 이 가이드의 이전 섹션에서 자세히 설명했습니다.
데이터 파일의 최적 압축률
다음 쿼리는 위에서 생성한 두 테이블의 UserID 컬럼 압축률을 비교합니다.
다음과 같은 응답이 반환됩니다:
UserID 컬럼의 압축 비율이, 키 컬럼 (IsRobot, UserID, URL) 를 카디널리티 기준 오름차순으로 정렬한 테이블에서 훨씬 더 높다는 것을 확인할 수 있습니다.
두 테이블 모두 정확히 동일한 데이터(두 테이블에 동일한 8.87백만 개의 행을 삽입함)를 저장하고 있지만, 복합 프라이머리 키에서 키 컬럼의 순서는 테이블의 컬럼 데이터 파일에 들어 있는 압축된 데이터가 차지하는 디스크 공간에 상당한 영향을 줍니다.
- 복합 프라이머리 키
(URL, UserID, IsRobot)를 사용하고 키 컬럼을 카디널리티 기준 내림차순으로 정렬한 테이블hits_URL_UserID_IsRobot에서는,UserID.bin데이터 파일이 디스크 공간 11.24 MiB 를 사용합니다. - 복합 프라이머리 키
(IsRobot, UserID, URL)를 사용하고 키 컬럼을 카디널리티 기준 오름차순으로 정렬한 테이블hits_IsRobot_UserID_URL에서는,UserID.bin데이터 파일이 디스크 공간 877.47 KiB 만 사용합니다.
테이블 컬럼 데이터가 디스크에서 좋은 압축 비율을 가지면 디스크 공간을 절약할 뿐만 아니라, 해당 컬럼의 데이터를 읽어야 하는 쿼리(특히 분석용 쿼리)가 더 빠르게 실행되도록 합니다. 컬럼 데이터를 디스크에서 메인 메모리(운영 체제의 파일 캐시)로 옮기는 데 필요한 I/O가 줄어들기 때문입니다.
다음에서는 테이블 컬럼의 압축 비율 관점에서, 프라이머리 키 컬럼을 카디널리티 기준 오름차순으로 정렬하는 것이 왜 유리한지를 설명합니다.
아래 다이어그램은 키 컬럼이 카디널리티 기준 오름차순으로 정렬된 프라이머리 키에 대해, 디스크 상에서 행이 어떤 순서로 저장되는지를 개략적으로 보여줍니다.

테이블의 행 데이터는 프라이머리 키 컬럼 순서에 따라 디스크에 저장된다는 것을 앞에서 논의했습니다.
위 다이어그램에서, 테이블의 행(디스크에 저장된 컬럼 값)은 먼저 cl 값으로 정렬되고, 같은 cl 값을 가진 행들끼리는 ch 값으로 정렬됩니다. 그리고 첫 번째 키 컬럼 cl 의 카디널리티가 낮기 때문에, 같은 cl 값을 가진 행들이 존재할 가능성이 높습니다. 그렇기 때문에 ch 값 또한 정렬되어 있을 가능성이 큽니다(국소적으로, 동일한 cl 값을 가진 행 집합 내에서).
컬럼에서 유사한 데이터가 서로 가까이 배치되어 있으면, 예를 들어 정렬을 통해 배치된 경우, 그 데이터는 더 잘 압축됩니다. 일반적으로, 압축 알고리즘은 데이터의 연속 길이(더 많은 데이터를 연속으로 볼수록 압축에 유리함)와 지역성(데이터가 서로 더 비슷할수록 압축 비율이 좋아짐)에서 이점을 얻습니다.
위 다이어그램과 대조적으로, 아래 다이어그램은 키 컬럼이 카디널리티 기준 내림차순으로 정렬된 프라이머리 키에 대해, 디스크 상에서 행이 어떤 순서로 저장되는지를 개략적으로 보여줍니다.

이제 테이블의 행은 먼저 ch 값으로 정렬되고, 같은 ch 값을 가진 행들끼리는 cl 값으로 정렬됩니다.
그러나 첫 번째 키 컬럼인 ch의 카디널리티가 매우 높기 때문에, 같은 ch 값을 갖는 행이 존재할 가능성은 낮습니다. 그로 인해 cl 값이 (같은 ch 값을 가진 행들 사이에서 국소적으로) 정렬되어 있을 가능성도 낮습니다.
따라서 cl 값은 대부분 무작위 순서에 가깝기 때문에, 결과적으로 지역성(locality)과 압축률(compression ratio)이 모두 좋지 않게 됩니다.
요약
쿼리에서 보조 키 컬럼에 대한 효율적인 필터링과 테이블 컬럼 데이터 파일의 압축률을 모두 높이기 위해서는 기본 키의 컬럼들을 카디널리티가 낮은 순으로 정렬하는 것이 좋습니다.
단일 행을 효율적으로 식별하기
일반적으로는 ClickHouse의 최적의 사용 사례는 아니지만, ClickHouse 위에 구축된 애플리케이션이 ClickHouse 테이블의 단일 행을 식별해야 하는 경우가 있습니다.
이를 위한 직관적인 해결책은 행마다 고유한 값을 갖는 UUID 컬럼을 사용하고, 행을 빠르게 조회하기 위해 해당 컬럼을 기본 키 컬럼으로 사용하는 것입니다.
가장 빠른 조회를 위해서는 UUID 컬럼이 첫 번째 키 컬럼이어야 합니다.
앞에서 ClickHouse 테이블의 행 데이터는 기본 키 컬럼들을 기준으로 정렬된 상태로 디스크에 저장된다는 점을 설명했습니다. 따라서 기본 키에, 또는 더 낮은 카디널리티 컬럼들보다 앞에 오는 복합 기본 키에 매우 높은 카디널리티의 컬럼(예: UUID 컬럼)이 포함되면, 다른 테이블 컬럼들의 압축률에 불리하게 작용합니다.
가장 빠른 조회와 최적의 데이터 압축 간의 절충안으로, UUID를 마지막 키 컬럼으로 두고 그 앞에 일부 테이블 컬럼의 좋은 압축률을 유지하도록 돕는 낮은(또는 더 낮은) 카디널리티 키 컬럼들을 두는 복합 기본 키를 사용하는 방법이 있습니다.
구체적인 예시
구체적인 예시로, Alexey Milovidov가 개발하고 블로그에 소개한 평문(plaintext) 붙여넣기 서비스 https://pastila.nl이 있습니다.
텍스트 영역이 변경될 때마다 데이터는 자동으로 ClickHouse 테이블의 행(변경 1회당 행 1개)에 저장됩니다.
붙여넣은 콘텐츠의 (특정 버전을) 식별하고 조회하는 한 가지 방법은, 콘텐츠의 해시를 해당 콘텐츠를 포함하는 테이블 행의 UUID로 사용하는 것입니다.
다음 다이어그램은 다음을 보여줍니다.
- 콘텐츠가 변경될 때(예: 텍스트 영역에 키 입력으로 텍스트를 입력할 때) 행이 삽입되는 순서와
PRIMARY KEY (hash)를 사용할 때 삽입된 행들의 데이터가 디스크에 저장되는 순서를 보여줍니다:

hash 컬럼이 프라이머리 키 컬럼으로 사용되기 때문에
- 특정 행은 매우 빠르게 조회할 수 있지만,
- 테이블의 행들(각 행의 컬럼 데이터)은 (고유하며 랜덤한) hash 값 기준으로 오름차순 정렬된 상태로 디스크에 저장됩니다. 따라서 content 컬럼의 값들도 데이터 지역성 없이 랜덤한 순서로 저장되며, 그 결과 content 컬럼 데이터 파일의 압축 비율이 최적보다 떨어지게 됩니다.
특정 행의 빠른 조회를 유지하면서도 content 컬럼의 압축 비율을 크게 향상시키기 위해, pastila.nl은 특정 행을 식별하는 데 두 개의 해시(그리고 복합 프라이머리 키)를 사용합니다.
- 앞에서 설명한 대로 서로 다른 데이터에 대해 서로 다른 값을 갖는 콘텐츠의 해시와
- 작은 데이터 변경에서는 변하지 않는 locality-sensitive hash(지문, fingerprint)
다음 다이어그램은 다음을 보여줍니다.
- 콘텐츠가 변경될 때(예: 텍스트 영역에 키 입력으로 텍스트를 입력할 때) 행이 삽입되는 순서와
- 복합
PRIMARY KEY (fingerprint, hash)를 사용할 때 삽입된 행들의 데이터가 디스크에 저장되는 순서를 보여줍니다:

이제 디스크 상의 행들은 먼저 fingerprint 기준으로 정렬되고, 동일한 fingerprint 값을 가진 행들 사이에서는 hash 값이 최종 순서를 결정합니다.
작은 변경만 있는 데이터는 동일한 fingerprint 값을 갖기 때문에, 유사한 데이터가 content 컬럼 내에서 디스크 상에 서로 가까운 위치에 저장됩니다. 이는 content 컬럼의 압축 비율에 매우 유리한데, 일반적으로 압축 알고리즘은 데이터 지역성을 활용할수록(데이터가 서로 유사할수록) 더 좋은 압축 비율을 달성하기 때문입니다.
이때의 절충점은, 복합 PRIMARY KEY (fingerprint, hash)로부터 생성되는 프라이머리 인덱스를 최적으로 활용해 특정 행을 조회하려면 두 필드(fingerprint와 hash)가 모두 필요하다는 점입니다.
