Amazon Glue를 ClickHouse 및 Spark와 통합하기
ClickHouse Supported
Amazon Glue는 Amazon Web Services(AWS)에서 제공하는 완전 관리형 서버리스 데이터 통합 서비스입니다. 분석, 머신 러닝, 애플리케이션 개발을 위해 데이터를 탐색, 준비 및 변환하는 작업을 단순화합니다.
설치
Glue 코드를 ClickHouse와 통합하기 위해, 다음 방법 중 하나를 사용하여 Glue에서 공식 Spark 커넥터를 사용할 수 있습니다.
- AWS Marketplace에서 ClickHouse Glue 커넥터를 설치합니다(권장).
- Spark Connector의 JAR을 수동으로 Glue 잡에 추가합니다.
- AWS Marketplace
- 수동 설치
-
커넥터 구독
계정에서 커넥터를 사용하려면 AWS Marketplace에서 ClickHouse AWS Glue Connector를 구독합니다. -
필수 권한 부여
최소 권한 가이드에 설명된 대로, Glue 잡의 IAM 역할에 필요한 권한이 있는지 확인합니다. -
커넥터 활성화 및 커넥션 생성
이 링크를 클릭하여 커넥터를 활성화하고 바로 커넥션을 생성할 수 있습니다. 이 링크는 주요 필드가 미리 채워진 Glue 커넥션 생성 페이지를 엽니다. 커넥션 이름을 지정한 뒤 생성 버튼을 누릅니다(이 단계에서는 ClickHouse 커넥션 세부 정보를 제공할 필요가 없습니다). -
Glue 잡에서 사용
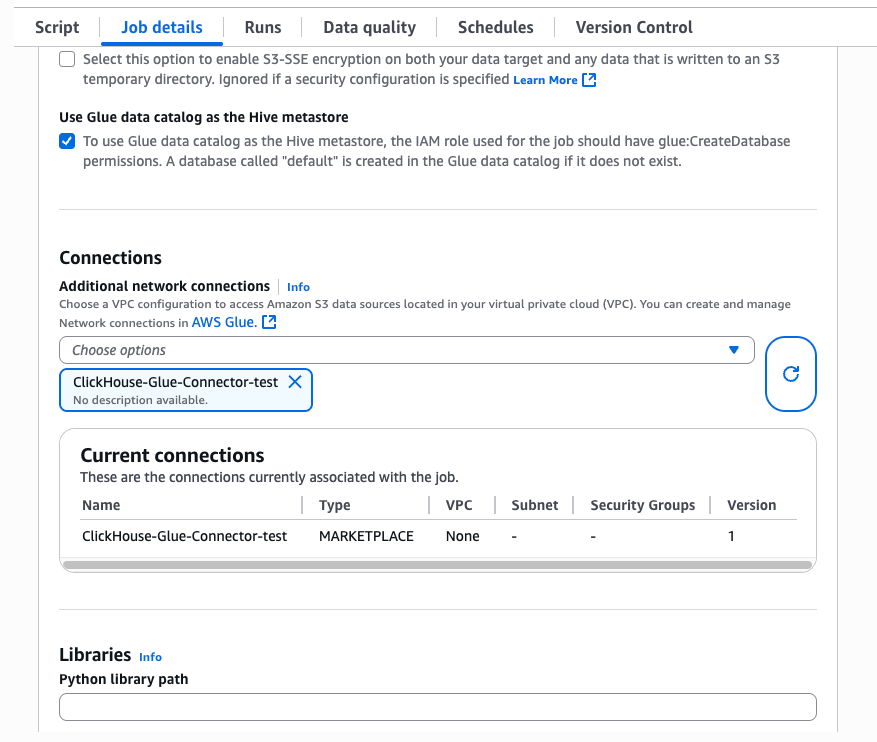
Glue 잡에서Job details탭을 선택한 다음Advanced properties창을 펼칩니다.Connections섹션에서 방금 생성한 커넥션을 선택합니다. 커넥터는 필요한 JAR을 잡 런타임에 자동으로 주입합니다.
참고
Glue 커넥터에서 사용하는 JAR은 Spark 3.3, Scala 2, Python 3용으로 빌드되어 있습니다. Glue 잡을 구성할 때 이 버전들을 선택해야 합니다.
필요한 JAR을 수동으로 추가하려면 다음 절차를 따르십시오.
- 다음 JAR을 S3 버킷에 업로드합니다:
clickhouse-jdbc-0.6.X-all.jar및clickhouse-spark-runtime-3.X_2.X-0.8.X.jar. - Glue 잡이 이 버킷에 접근할 수 있는지 확인합니다.
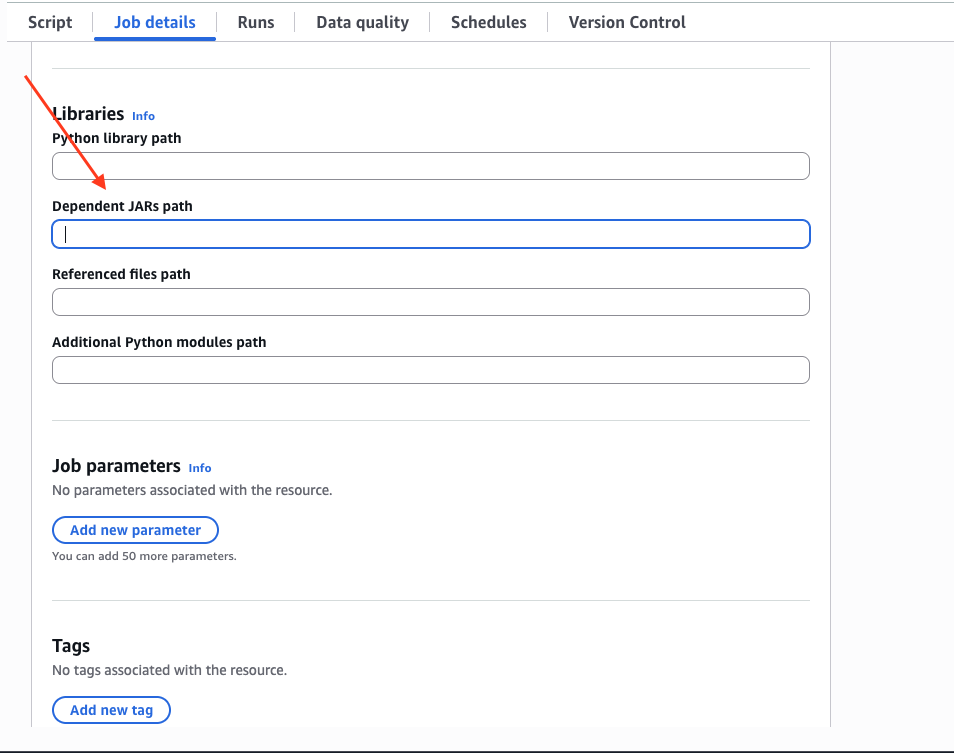
Job details탭에서 아래로 스크롤하여Advanced properties드롭다운을 펼치고,Dependent JARs path에 JAR 경로를 입력합니다:
예제
- Scala
- Python
자세한 내용은 Spark 문서를 참조하십시오.
