ClickHouse Kafka Connect Sink
도움이 필요한 경우 저장소에 이슈를 등록하거나 ClickHouse public Slack에 질문을 남기십시오.
ClickHouse Kafka Connect Sink는 Kafka 토픽에서 ClickHouse 테이블로 데이터를 전송하는 Kafka 커넥터입니다.
라이선스
Kafka Connector Sink는 Apache 2.0 라이선스에 따라 배포됩니다.
환경 요구 사항
해당 환경에 Kafka Connect 프레임워크 v2.7 이상이 설치되어 있어야 합니다.
버전 호환성 매트릭스
| ClickHouse Kafka Connect 버전 | ClickHouse 버전 | Kafka Connect | Confluent Platform |
|---|---|---|---|
| 1.0.0 | > 23.3 | > 2.7 | > 6.1 |
주요 기능
- 기본적으로 exactly-once 처리 의미론을 제공합니다. 커넥터의 상태 저장소로 사용되는 새로운 ClickHouse 코어 기능인 KeeperMap을 기반으로 하며, 아키텍처를 최소화할 수 있습니다.
- 서드파티 상태 저장소 지원: 현재 기본값은 In-memory이며 KeeperMap을 사용할 수 있고, Redis는 곧 추가될 예정입니다.
- 코어 통합: ClickHouse에서 직접 빌드, 유지 관리 및 지원합니다.
- ClickHouse Cloud를 대상으로 지속적으로 테스트됩니다.
- 선언된 스키마 기반 및 스키마리스(schemaless) 모두에 대해 데이터 삽입을 지원합니다.
- ClickHouse의 모든 데이터 타입을 지원합니다.
설치 방법
연결 정보 준비
HTTP(S)로 ClickHouse에 연결하려면 다음 정보가 필요합니다:
| Parameter(s) | Description |
|---|---|
HOST and PORT | 일반적으로 TLS를 사용할 때는 포트가 8443이고, TLS를 사용하지 않을 때는 8123입니다. |
DATABASE NAME | 기본적으로 default라는 데이터베이스가 있으며, 연결하려는 데이터베이스의 이름을 사용합니다. |
USERNAME and PASSWORD | 기본값으로 사용자 이름은 default입니다. 사용하려는 용도에 적합한 사용자 이름을 사용합니다. |
ClickHouse Cloud 서비스에 대한 세부 정보는 ClickHouse Cloud 콘솔에서 확인할 수 있습니다. 서비스를 선택한 다음 Connect를 클릭하십시오:
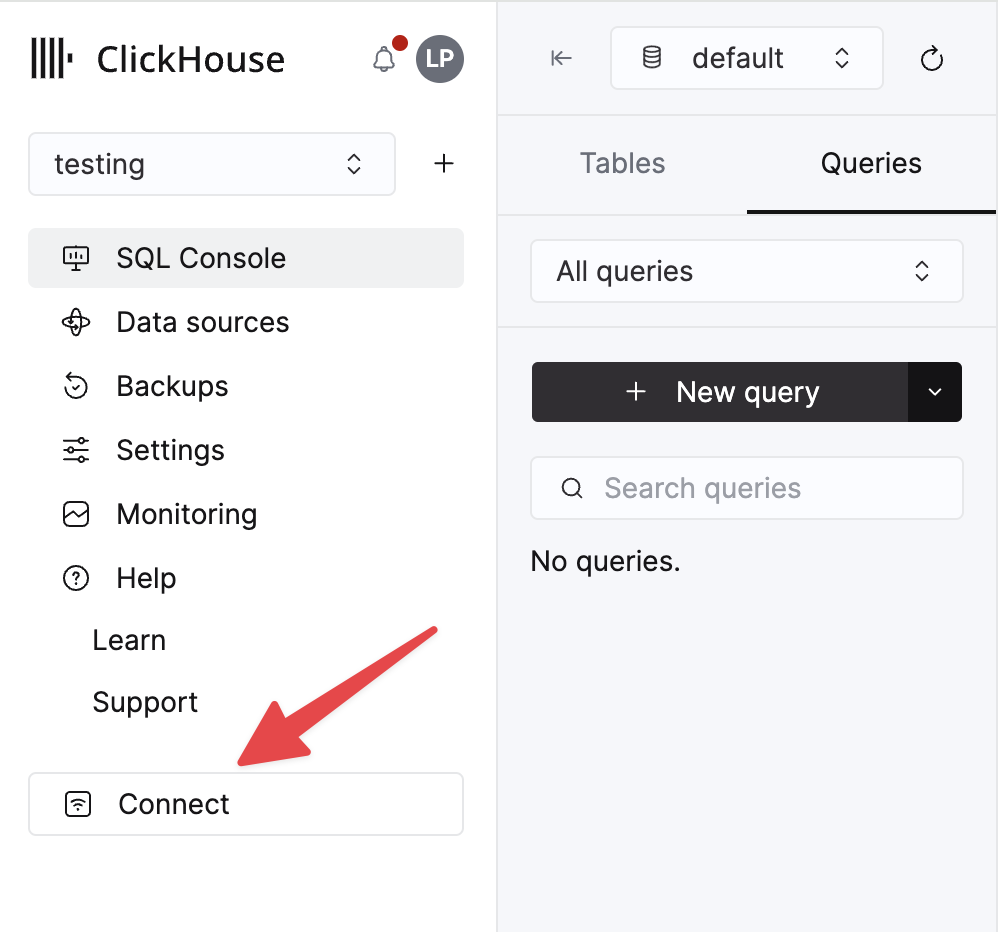
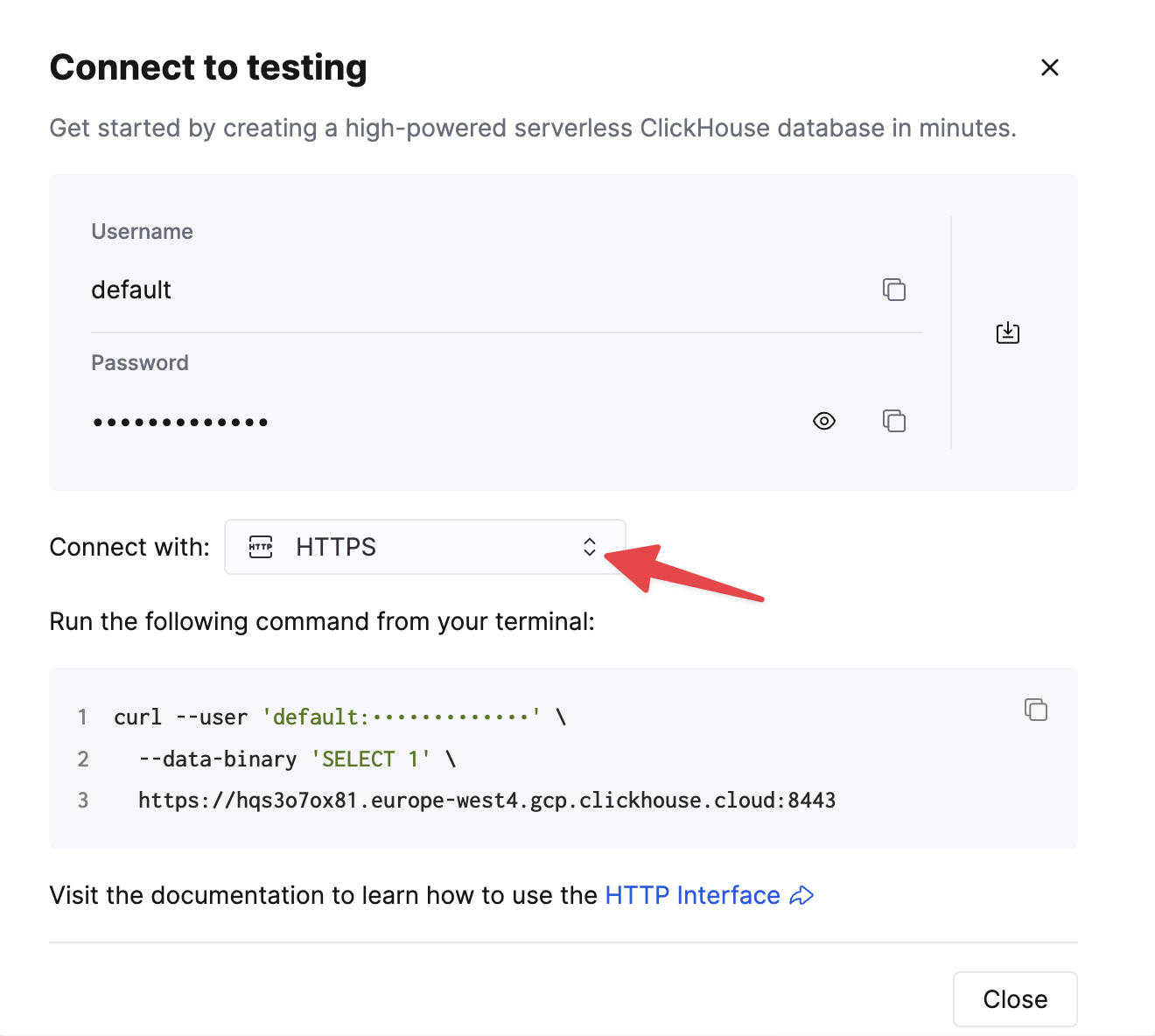
HTTPS를 선택하십시오. 연결 정보는 예제 curl 명령에 표시됩니다.
자가 관리형 ClickHouse를 사용하는 경우, 연결 정보는 ClickHouse 관리자가 설정합니다.
일반 설치 지침
커넥터는 플러그인 실행에 필요한 모든 클래스 파일을 포함하는 단일 JAR 파일로 배포됩니다.
플러그인을 설치하려면 다음 단계를 따르십시오:
- ClickHouse Kafka Connect Sink 저장소의 Releases 페이지에서 Connector JAR 파일이 포함된 ZIP 아카이브를 다운로드합니다.
- ZIP 파일의 압축을 해제한 뒤, 내용을 원하는 위치로 복사합니다.
- Confluent Platform이 플러그인을 찾을 수 있도록 Connect 속성 파일의 plugin.path 설정에 플러그인 디렉터리 경로를 추가합니다.
- 구성(config)에서 토픽 이름, ClickHouse 인스턴스 호스트 이름, 비밀번호를 설정합니다.
- Confluent Platform을 재시작합니다.
- Confluent Platform을 사용하는 경우 Confluent Control Center UI에 로그인하여 사용 가능한 커넥터 목록에 ClickHouse Sink가 표시되는지 확인합니다.
구성 옵션
ClickHouse Sink를 ClickHouse 서버에 연결하려면 다음을 제공해야 합니다.
- 연결 정보: 호스트명 (필수) 및 포트 (선택)
- 사용자 자격 증명: 비밀번호 (필수) 및 사용자 이름 (선택)
- 커넥터 클래스:
com.clickhouse.kafka.connect.ClickHouseSinkConnector(필수) - topics 또는 topics.regex: 폴링할 Kafka 토픽. 토픽 이름은 테이블 이름과 일치해야 합니다 (필수)
- key 및 value 컨버터: 토픽의 데이터 유형에 따라 설정합니다. 워커 구성에서 이미 정의되지 않은 경우 필수입니다.
전체 구성 옵션 표는 다음과 같습니다.
| Property Name | Description | Default Value |
|---|---|---|
hostname (Required) | 서버의 호스트 이름 또는 IP 주소 | N/A |
port | ClickHouse 포트입니다. 기본값은 Cloud 환경에서 HTTPS용 8443이며, HTTP(셀프 호스티드의 기본값)에서는 8123을 사용해야 합니다. | 8443 |
ssl | ClickHouse에 대한 SSL 연결을 활성화합니다. | true |
jdbcConnectionProperties | ClickHouse에 연결할 때 사용하는 연결 속성입니다. ?로 시작해야 하며, param=value 사이를 &로 연결해야 합니다. | "" |
username | ClickHouse 데이터베이스 사용자 이름 | default |
password (Required) | ClickHouse 데이터베이스 비밀번호 | N/A |
database | ClickHouse 데이터베이스 이름 | default |
connector.class (Required) | 커넥터 클래스입니다(명시적으로 설정하고 기본값으로 유지해야 합니다). | "com.clickhouse.kafka.connect.ClickHouseSinkConnector" |
tasks.max | 커넥터 태스크 수 | "1" |
errors.retry.timeout | ClickHouse JDBC 재시도 타임아웃(초) | "60" |
exactlyOnce | Exactly Once 기능 활성화 여부 | "false" |
topics (Required) | 폴링할 Kafka 토픽입니다. 토픽 이름은 테이블 이름과 일치해야 합니다. | "" |
key.converter (Required* - See Description) | 키의 타입에 따라 설정합니다. 키를 전달하는 경우(그리고 worker 설정에 정의되지 않은 경우) 여기에서 필수입니다. | "org.apache.kafka.connect.storage.StringConverter" |
value.converter (Required* - See Description) | 토픽의 데이터 타입에 따라 설정합니다. 지원 형식: JSON, String, Avro, Protobuf. worker 설정에 정의되지 않은 경우 여기에서 필수입니다. | "org.apache.kafka.connect.json.JsonConverter" |
value.converter.schemas.enable | 커넥터 value converter의 스키마 지원 여부 | "false" |
errors.tolerance | 커넥터 오류 허용 수준입니다. 지원 값: none, all | "none" |
errors.deadletterqueue.topic.name | 설정된 경우(errors.tolerance=all일 때), 실패한 배치에 대해 DLQ가 사용됩니다(Troubleshooting 참조). | "" |
errors.deadletterqueue.context.headers.enable | DLQ에 추가 헤더를 포함합니다. | "" |
clickhouseSettings | 콤마로 구분된 ClickHouse 설정 목록입니다(예: "insert_quorum=2, etc..."). | "" |
topic2TableMap | 토픽 이름을 테이블 이름에 매핑하는 콤마 구분 목록입니다(예: "topic1=table1, topic2=table2, etc..."). | "" |
tableRefreshInterval | 테이블 정의 캐시를 새로 고치는 시간(초 단위) | 0 |
keeperOnCluster | 셀프 호스티드 인스턴스에서 exactly-once connect_state 테이블에 대해 ON CLUSTER 파라미터를 설정할 수 있게 합니다(예: ON CLUSTER clusterNameInConfigFileDefinition. Distributed DDL Queries 참조). | "" |
bypassRowBinary | 스키마 기반 데이터(Avro, Protobuf 등)에 대해 RowBinary 및 RowBinaryWithDefaults 사용을 비활성화할 수 있게 합니다. 데이터에 누락된 컬럼이 있고 널 허용/기본값이 허용되지 않는 경우에만 사용해야 합니다. | "false" |
dateTimeFormats | ;로 구분된 DateTime64 스키마 필드를 파싱하기 위한 날짜-시간 형식입니다(예: someDateField=yyyy-MM-dd HH:mm:ss.SSSSSSSSS;someOtherDateField=yyyy-MM-dd HH:mm:ss). | "" |
tolerateStateMismatch | 커넥터가 AFTER_PROCESSING에 저장된 현재 오프셋보다 "이전"인 레코드를 드롭하도록 허용합니다(예: 오프셋 5가 전송되었으나, 마지막으로 기록된 오프셋이 250인 경우). | "false" |
ignorePartitionsWhenBatching | insert 수행을 위해 메시지를 수집할 때 파티션을 무시합니다(단, exactlyOnce가 false인 경우에만 해당). 성능 참고: 커넥터 태스크 수가 많을수록 태스크당 할당되는 Kafka 파티션 수가 줄어들며, 이는 성능 향상이 제한적일 수 있음을 의미합니다. | "false" |
대상 테이블
ClickHouse Connect Sink는 Kafka 토픽에서 메시지를 읽어 적절한 테이블에 기록합니다. ClickHouse Connect Sink는 기존 테이블에 데이터를 기록합니다. 데이터를 삽입하기 전에 ClickHouse에 적절한 스키마를 가진 대상 테이블이 미리 CREATE되어 있는지 확인하십시오.
각 토픽마다 ClickHouse에는 전용 대상 테이블이 필요합니다. 대상 테이블 이름은 소스 토픽 이름과 일치해야 합니다.
사전 처리
ClickHouse Kafka Connect Sink로 전송하기 전에 발신 메시지를 변환해야 하는 경우, Kafka Connect Transformations을 사용하십시오.
지원되는 데이터 타입
스키마가 선언된 경우:
| Kafka Connect Type | ClickHouse Type | 지원 여부 | 기본 타입 |
|---|---|---|---|
| STRING | String | ✅ | 예 |
| STRING | JSON. 아래 (1) 참조 | ✅ | 예 |
| INT8 | Int8 | ✅ | 예 |
| INT16 | Int16 | ✅ | 예 |
| INT32 | Int32 | ✅ | 예 |
| INT64 | Int64 | ✅ | 예 |
| FLOAT32 | Float32 | ✅ | 예 |
| FLOAT64 | Float64 | ✅ | 예 |
| BOOLEAN | Boolean | ✅ | 예 |
| ARRAY | Array(T) | ✅ | 아니오 |
| MAP | Map(Primitive, T) | ✅ | 아니오 |
| STRUCT | Variant(T1, T2, ...) | ✅ | 아니오 |
| STRUCT | Tuple(a T1, b T2, ...) | ✅ | 아니오 |
| STRUCT | Nested(a T1, b T2, ...) | ✅ | 아니오 |
| STRUCT | JSON. 아래 (1), (2) 참조 | ✅ | 아니오 |
| BYTES | String | ✅ | 아니오 |
| org.apache.kafka.connect.data.Time | Int64 / DateTime64 | ✅ | 아니오 |
| org.apache.kafka.connect.data.Timestamp | Int32 / Date32 | ✅ | 아니오 |
| org.apache.kafka.connect.data.Decimal | Decimal | ✅ | 아니오 |
-
(1) - JSON은 ClickHouse 설정에서
input_format_binary_read_json_as_string=1로 설정된 경우에만 지원됩니다. 이는 RowBinary 형식 계열에서만 동작하며, 이 설정은 INSERT 요청의 모든 컬럼에 영향을 주므로 모든 컬럼이 문자열이어야 합니다. 이 경우 커넥터는 STRUCT를 JSON 문자열로 변환합니다. -
(2) - struct에
oneof와 같은 union이 포함된 경우, 변환기는 필드 이름에 접두사/접미사를 추가하지 않도록 설정해야 합니다. 이를 위해ProtobufConverter에 대해generate.index.for.unions=false설정을 사용합니다.
스키마가 선언되지 않은 경우:
레코드는 JSON으로 변환된 후 JSONEachRow 형식의 값으로 ClickHouse에 전송됩니다.
Configuration recipes
빠르게 시작하는 데 도움이 되는 몇 가지 일반적인 구성 예시입니다.
기본 설정
시작할 때 사용할 수 있는 가장 기본적인 설정입니다. Kafka Connect를 분산 모드로 실행하고 있고, SSL이 활성화된 ClickHouse 서버가 localhost:8443에서 실행 중이며, 데이터는 스키마리스 JSON 형식이라고 가정합니다.
여러 토픽을 위한 기본 구성
커넥터는 여러 토픽에서 데이터를 소비할 수 있습니다.
DLQ를 포함한 기본 구성
서로 다른 데이터 형식 사용하기
Avro 스키마 지원
Protobuf 스키마 지원
주의: 클래스 누락 오류가 발생하는 경우, 모든 환경에 protobuf 컨버터가 포함되어 있는 것은 아니므로 종속성이 함께 포함된 다른 릴리스의 jar 파일이 필요할 수 있습니다.
JSON 스키마 지원
String 지원
커넥터는 여러 ClickHouse 포맷에서 String Converter를 지원합니다. 지원되는 포맷에는 JSON, CSV, TSV가 있습니다.
로깅(Logging)
로깅은 Kafka Connect Platform에서 자동으로 제공합니다. 로그의 대상(목적지)과 형식은 Kafka Connect 구성 파일에서 설정할 수 있습니다.
Confluent Platform을 사용하는 경우 CLI 명령을 실행하면 로그를 확인할 수 있습니다:
자세한 내용은 공식 튜토리얼을 참고하십시오.
모니터링
ClickHouse Kafka Connect는 Java Management Extensions (JMX)를 통해 런타임 메트릭을 노출합니다. JMX는 Kafka 커넥터에서 기본적으로 활성화되어 있습니다.
ClickHouse 관련 메트릭
커넥터는 다음 MBean 이름을 통해 사용자 정의 메트릭을 노출합니다:
| Metric Name | Type | Description |
|---|---|---|
receivedRecords | long | 수신된 레코드의 총 개수입니다. |
recordProcessingTime | long | 레코드를 그룹화하고 통합 구조로 변환하는 데 소요된 총 시간(나노초)입니다. |
taskProcessingTime | long | 데이터를 처리하고 ClickHouse에 삽입하는 데 소요된 총 시간(나노초)입니다. |
Kafka Producer/Consumer Metrics
커넥터는 데이터 흐름, 처리량, 성능에 대한 인사이트를 제공하는 표준 Kafka producer 및 consumer 메트릭을 제공합니다.
토픽 수준 메트릭:
records-sent-total: 토픽으로 전송된 레코드의 총 개수bytes-sent-total: 토픽으로 전송된 총 바이트 수record-send-rate: 초당 전송된 레코드의 평균 속도byte-rate: 초당 전송된 평균 바이트 수compression-rate: 달성된 압축 비율
파티션 수준 메트릭:
records-sent-total: 파티션으로 전송된 레코드의 총 개수bytes-sent-total: 파티션으로 전송된 총 바이트 수records-lag: 해당 파티션의 현재 레코드 지연(lag)records-lead: 해당 파티션의 현재 레코드 리드(lead)replica-fetch-lag: 레플리카에 대한 지연(lag) 정보
노드 수준 연결 메트릭:
connection-creation-total: Kafka 노드로 생성된 연결의 총 개수connection-close-total: 종료된 연결의 총 개수request-total: 노드로 전송된 요청의 총 개수response-total: 노드에서 수신한 응답의 총 개수request-rate: 초당 평균 요청 속도response-rate: 초당 평균 응답 속도
이러한 메트릭은 다음 항목을 모니터링하는 데 도움이 됩니다:
- 처리량(Throughput): 데이터 수집률 추적
- 지연(Lag): 병목 현상과 처리 지연 식별
- 압축(Compression): 데이터 압축 효율 측정
- 연결 상태(Connection Health): 네트워크 연결 상태 및 안정성 모니터링
Kafka Connect Framework Metrics
커넥터는 Kafka Connect 프레임워크와 통합되어 태스크 수명주기와 오류 추적을 위한 메트릭을 제공합니다.
태스크 상태 메트릭:
task-count: 커넥터에 있는 태스크의 총 개수running-task-count: 현재 실행 중인 태스크 개수paused-task-count: 현재 일시 중지된 태스크 개수failed-task-count: 실패한 태스크 개수destroyed-task-count: 제거된 태스크 개수unassigned-task-count: 할당되지 않은 태스크 개수
가능한 태스크 상태 값은 다음과 같습니다: running, paused, failed, destroyed, unassigned
오류 메트릭:
deadletterqueue-produce-failures: 실패한 DLQ 쓰기 횟수deadletterqueue-produce-requests: DLQ 쓰기 시도 총 횟수last-error-timestamp: 마지막 오류의 타임스탬프records-skip-total: 오류로 인해 건너뛴 레코드의 총 개수records-retry-total: 재시도된 레코드의 총 개수errors-total: 발생한 오류의 총 개수
성능 메트릭:
offset-commit-failures: 실패한 오프셋 커밋 횟수offset-commit-avg-time-ms: 오프셋 커밋의 평균 소요 시간offset-commit-max-time-ms: 오프셋 커밋의 최대 소요 시간put-batch-avg-time-ms: 배치를 처리하는 평균 시간put-batch-max-time-ms: 배치를 처리하는 최대 시간source-record-poll-total: 폴링된 레코드의 총 개수
모니터링 모범 사례
- Consumer 지연 모니터링: 파티션별
records-lag를 추적하여 처리 병목 현상을 파악합니다. - 오류율 추적:
errors-total및records-skip-total을 관찰하여 데이터 품질 문제를 탐지합니다. - 태스크 상태 모니터링: 태스크 상태 메트릭을 모니터링하여 태스크가 정상적으로 실행 중인지 확인합니다.
- 처리량 측정:
records-send-rate및byte-rate를 사용하여 수집 성능을 추적합니다. - 연결 상태 모니터링: 노드 수준의 연결 메트릭을 확인하여 네트워크 문제를 식별합니다.
- 압축 효율 추적:
compression-rate를 사용하여 데이터 전송을 최적화합니다.
자세한 JMX 메트릭 정의 및 Prometheus 통합 방법은 jmx-export-connector.yml 구성 파일을 참조하십시오.
제한 사항
- 삭제 작업은 지원되지 않습니다.
- 배치 크기는 Kafka Consumer 속성에서 결정됩니다.
- exactly-once를 위해 KeeperMap을 사용하고 있고 offset이 변경되거나 되돌려지는 경우, 해당 토픽의 KeeperMap 내용을 삭제해야 합니다. (자세한 내용은 아래 문제 해결 가이드를 참조하십시오)
성능 튜닝 및 처리량 최적화
이 섹션에서는 ClickHouse Kafka Connect Sink를 위한 성능 튜닝 전략을 다룹니다. 성능 튜닝은 고처리량 워크로드를 처리하거나 리소스 활용을 최적화하고 지연 시간을 최소화해야 할 때 필수적입니다.
언제 성능 튜닝이 필요합니까?
성능 튜닝은 일반적으로 다음과 같은 상황에서 필요합니다.
- 고처리량 워크로드: Kafka 토픽에서 초당 수백만 개의 이벤트를 처리해야 할 때
- Consumer 지연(consumer lag): 커넥터가 데이터 생성 속도를 따라가지 못해 지연이 점점 증가할 때
- 리소스 제약: CPU, 메모리 또는 네트워크 사용량을 최적화해야 할 때
- 여러 토픽: 여러 고용량 토픽을 동시에 소비할 때
- 작은 메시지 크기: 서버 측 배치 처리의 이점을 얻을 수 있는, 매우 작은 메시지를 대량으로 처리할 때
다음과 같은 경우에는 성능 튜닝이 일반적으로 필요하지 않습니다.
- 초당 10,000개 미만의 낮거나 중간 수준의 메시지 양을 처리하는 경우
- Consumer 지연이 안정적이고 사용 사례에서 허용 가능한 수준인 경우
- 기본 커넥터 설정만으로도 처리량 요구 사항을 이미 충족하는 경우
- ClickHouse 클러스터가 유입되는 부하를 무리 없이 처리할 수 있는 경우
데이터 흐름 이해하기
튜닝을 진행하기 전에 커넥터를 통해 데이터가 어떻게 흐르는지 이해하는 것이 중요합니다:
- Kafka Connect Framework가 백그라운드에서 Kafka 토픽으로부터 메시지를 가져옵니다.
- 커넥터가 폴링하여 프레임워크의 내부 버퍼에서 메시지를 가져옵니다.
- 커넥터가 배치 크기(poll 크기)에 따라 메시지를 묶습니다.
- ClickHouse가 HTTP/S를 통해 배치된 insert를 수신합니다.
- ClickHouse가 insert를 동기 또는 비동기 방식으로 처리합니다.
각 단계에서 성능을 최적화할 수 있습니다.
Kafka Connect 배치 크기 조정
첫 번째 최적화 단계에서는 Kafka에서 커넥터가 각 배치마다 수신하는 데이터 양을 제어합니다.
Fetch 설정
Kafka Connect(프레임워크)는 커넥터와는 독립적으로 백그라운드에서 Kafka 토픽의 메시지를 가져옵니다.
fetch.min.bytes: 프레임워크가 커넥터에 값을 전달하기 전에 필요한 최소 데이터 양 (기본값: 1바이트)fetch.max.bytes: 단일 요청에서 가져올 수 있는 최대 데이터 양 (기본값: 52428800 / 50 MB)fetch.max.wait.ms:fetch.min.bytes조건이 충족되지 않는 경우 데이터를 반환하기 전까지 대기할 최대 시간 (기본값: 500 ms)
Confluent Cloud에서는 이러한 설정을 조정하려면 Confluent Cloud를 통해 지원 요청을 생성해야 합니다.
폴링 설정
커넥터는 프레임워크의 버퍼에서 메시지를 폴링합니다.
max.poll.records: 한 번의 폴링에서 반환되는 레코드의 최대 개수 (기본값: 500)max.partition.fetch.bytes: 파티션당 최대 데이터 크기 (기본값: 1048576 / 1 MB)
Confluent Cloud에서는 이러한 설정을 조정하려면 Confluent Cloud를 통해 지원 요청을 생성해야 합니다.
높은 처리량을 위한 권장 설정
ClickHouse에서 최적의 성능을 얻으려면 더 큰 배치를 사용하는 것을 목표로 하십시오:
중요: Kafka Connect 페치 설정은 압축된 데이터를 기준으로 하지만, ClickHouse는 압축되지 않은 데이터를 받습니다. 사용하는 압축 비율을 고려하여 이 설정들을 균형 있게 조정하십시오.
트레이드오프:
- 배치 크기가 클수록 = ClickHouse 수집 성능 향상, 파트 수 감소, 오버헤드 감소
- 배치 크기가 클수록 = 메모리 사용량 증가, 종단 간 지연 시간 증가 가능성
- 배치가 너무 큰 경우 = 타임아웃, OutOfMemory 오류 발생,
max.poll.interval.ms초과 위험
자세한 내용: Confluent 문서 | Kafka 문서
비동기 insert
비동기 insert는 커넥터가 상대적으로 작은 배치를 전송하거나, 배치 처리 책임을 ClickHouse가 담당하도록 하여 수집을 한층 더 최적화하고자 할 때 유용한 기능입니다.
비동기 insert를 사용할 때
다음과 같은 경우 비동기 insert 활성화를 고려하십시오:
- 작은 배치가 많은 경우: 커넥터가 작은 배치(배치당 1,000행 미만)를 자주 전송하는 경우
- 높은 동시성: 여러 커넥터 태스크가 동일한 테이블에 쓰기 작업을 수행하는 경우
- 분산 배포: 서로 다른 호스트에서 많은 커넥터 인스턴스를 실행하는 경우
- 파트 생성 오버헤드: "too many parts" 오류가 발생하는 경우
- 혼합 워크로드: 실시간 수집과 쿼리 워크로드를 함께 처리하는 경우
다음과 같은 경우에는 비동기 insert를 사용하지 마십시오:
- 이미 큰 배치(배치당 10,000행 초과)를 일정한 빈도로 전송하고 있는 경우
- 데이터가 즉시 조회 가능해야 하는 경우(쿼리가 데이터를 바로 볼 수 있어야 하는 경우)
wait_for_async_insert=0인 정확히 한 번 처리(Exactly-once semantics) 요구 사항과 충돌하는 경우- 클라이언트 측 배치 방식을 개선하는 편이 더 유리한 사용 사례인 경우
비동기 insert 동작 방식
비동기 insert가 활성화되면 ClickHouse는 다음과 같이 동작합니다:
- 커넥터로부터 insert 쿼리를 수신합니다.
- 데이터를 디스크에 바로 기록하지 않고 메모리 버퍼에 기록합니다.
wait_for_async_insert=0인 경우 커넥터에 성공 응답을 반환합니다.- 다음 조건 중 하나를 만족하면 버퍼를 디스크로 플러시합니다:
- 버퍼가
async_insert_max_data_size에 도달한 경우 (기본값: 10 MB) - 최초 insert 이후
async_insert_busy_timeout_ms밀리초가 경과한 경우 (기본값: 1000 ms) - 누적된 쿼리 수가 최대값(
async_insert_max_query_number, 기본값: 100)에 도달한 경우
- 버퍼가
이는 생성되는 파트 수를 크게 줄이고 전체 처리량을 향상시킵니다.
비동기 insert 활성화
clickhouseSettings 구성 매개변수에 비동기 insert 설정을 추가합니다.
핵심 설정:
async_insert=1: 비동기 insert를 활성화합니다.wait_for_async_insert=1(권장): 커넥터가 데이터가 ClickHouse 스토리지에 플러시될 때까지 대기한 후에만 확인 응답을 보냅니다. 전달 보장(Delivery Guarantee)을 제공합니다.wait_for_async_insert=0: 커넥터가 버퍼링 직후 바로 확인 응답을 보냅니다. 성능은 더 좋지만, 플러시 전에 서버가 장애가 나면 데이터가 손실될 수 있습니다.
비동기 INSERT 동작 튜닝
비동기 INSERT 플러시 동작을 세밀하게 조정할 수 있습니다.
일반적인 튜닝 파라미터:
async_insert_max_data_size(기본값: 10485760 / 10 MB): 플러시 전 최대 버퍼 크기async_insert_busy_timeout_ms(기본값: 1000): 플러시까지의 최대 시간(ms)async_insert_stale_timeout_ms(기본값: 0): 마지막 insert 이후 플러시까지의 시간(ms)async_insert_max_query_number(기본값: 100): 플러시 전 최대 쿼리 수
트레이드오프:
- 장점: 파트 수 감소, 머지 성능 향상, CPU 오버헤드 감소, 높은 동시성 환경에서 처리량 개선
- 고려사항: 데이터가 즉시 쿼리되지 않음, 엔드 투 엔드 지연 시간이 소폭 증가
- 위험:
wait_for_async_insert=0인 경우 서버 크래시 시 데이터 손실 가능, 큰 버퍼로 인한 메모리 압박 가능성
정확히 한 번 의미론을 사용하는 비동기 insert
비동기 insert에서 exactlyOnce=true를 사용하는 경우:
중요: 데이터가 영구 저장된 이후에만 오프셋 커밋이 이루어지도록 하려면 exactly-once 처리 시 항상 wait_for_async_insert=1을 사용하십시오.
비동기 insert(async insert)에 대한 자세한 내용은 ClickHouse async inserts 문서를 참조하십시오.
커넥터 병렬성
처리량을 개선하려면 병렬도를 높이십시오:
커넥터별 작업 수
각 task는 토픽 파티션의 일부를 처리합니다. task 수가 많을수록 병렬성이 높아지지만 다음과 같은 점을 유의해야 합니다:
- 효과적으로 사용할 수 있는 task의 최대 개수 = 토픽 파티션 개수
- 각 task는 자체 ClickHouse 연결을 유지합니다
- task 수가 많을수록 오버헤드와 잠재적인 리소스 경합이 증가합니다
권장 사항: tasks.max 값을 토픽 파티션 개수와 같게 설정한 후, CPU 및 처리량(throughput) 메트릭을 기준으로 조정하십시오.
배치 시 파티션을 구분하지 않기
기본적으로 커넥터는 파티션별로 메시지를 배치합니다. 더 높은 처리량이 필요하면 여러 파티션에 걸쳐 배치할 수 있습니다:
** 경고**: exactlyOnce=false인 경우에만 사용하십시오. 이 설정은 더 큰 배치를 만들어 처리량을 높일 수 있지만, 파티션별 메시지 순서 보장이 사라집니다.
여러 개의 고처리량 토픽
커넥터가 여러 토픽을 구독하도록 설정되어 있고, topic2TableMap을 사용해 토픽을 테이블에 매핑하고 있으며, 데이터 삽입 단계에서 병목이 발생해 consumer lag이 생긴다면, 각 토픽마다 별도의 커넥터를 생성하는 방안을 고려하십시오.
이러한 현상이 발생하는 주된 이유는 현재 배치가 모든 테이블에 직렬로 삽입되기 때문입니다.
권장 사항: 처리량이 높은 여러 토픽을 사용하는 경우, 병렬 삽입 처리량을 최대화하기 위해 토픽당 하나의 커넥터 인스턴스를 배포하십시오.
ClickHouse 테이블 엔진 고려사항
사용 사례에 가장 적합한 ClickHouse 테이블 엔진을 선택하십시오:
MergeTree: 대부분의 사용 사례에 적합하며, 쿼리 및 INSERT 성능의 균형을 제공합니다ReplicatedMergeTree: 고가용성에 필요하며, 복제 오버헤드를 추가합니다*MergeTree와 적절한ORDER BY: 쿼리 패턴에 맞게 최적화합니다
고려할 설정(Settings):
커넥터 수준 Insert 설정:
커넥션 풀링과 타임아웃
커넥터는 ClickHouse에 대한 HTTP 연결을 유지합니다. 네트워크 지연(latency)이 큰 환경에서는 타임아웃 값을 조정하십시오.
socket_timeout(기본값: 30000 ms): 읽기 작업에 허용되는 최대 시간connection_timeout(기본값: 10000 ms): 연결을 설정하는 데 허용되는 최대 시간
대용량 배치 처리 시 타임아웃 오류가 발생하면 해당 값을 늘리십시오.
성능 모니터링 및 문제 해결
다음 핵심 메트릭을 모니터링해야 합니다:
- Consumer lag: Kafka 모니터링 도구를 사용하여 파티션별 lag을 추적합니다.
- Connector 메트릭: JMX를 통해
receivedRecords,recordProcessingTime,taskProcessingTime를 모니터링합니다(Monitoring 참고). - ClickHouse 메트릭:
system.asynchronous_inserts: 비동기 insert 버퍼 사용량을 모니터링합니다.system.parts: merge 문제를 감지하기 위해 파트 개수를 모니터링합니다.system.merges: 활성 merge 작업을 모니터링합니다.system.events:InsertedRows,InsertedBytes,FailedInsertQuery를 추적합니다.
일반적인 성능 문제:
| 증상 | 가능한 원인 | 해결 방법 |
|---|---|---|
| Consumer lag이 높음 | 배치 크기가 너무 작음 | max.poll.records를 증가시키고 비동기 insert를 활성화합니다. |
| "Too many parts" 오류 | 작고 빈번한 insert | 비동기 insert를 활성화하고 배치 크기를 늘립니다. |
| Timeout 오류 | 큰 배치 크기, 느린 네트워크 | 배치 크기를 줄이고 socket_timeout을 늘리며 네트워크를 점검합니다. |
| 높은 CPU 사용량 | 너무 많은 작은 파트 | 비동기 insert를 활성화하고 merge 관련 설정값을 높입니다. |
| OutOfMemory 오류 | 배치 크기가 너무 큼 | max.poll.records, max.partition.fetch.bytes 값을 줄입니다. |
| 작업(task) 간 부하 불균형 | 파티션 분배가 균일하지 않음 | 파티션을 재분배하거나 tasks.max를 조정합니다. |
모범 사례 요약
- 기본값부터 시작한 다음 실제 성능을 기준으로 측정하고 튜닝합니다.
- 더 큰 배치 크기를 사용합니다: 가능하면 한 번의 insert당 10,000–100,000행을 목표로 합니다.
- 많은 작은 배치를 전송하거나 높은 동시성 환경에서는 비동기 insert(async inserts)를 사용합니다.
- 정확히 한 번 처리(Exactly-once) 의미 체계를 위해서는 항상
wait_for_async_insert=1을 사용합니다. - 수평 확장: 파티션 수까지
tasks.max를 증가시킵니다. - 최대 처리량을 위해 고용량 토픽마다 커넥터를 하나씩 사용합니다.
- 지속적으로 모니터링합니다: consumer lag, part 수, merge 작업을 추적합니다.
- 충분히 테스트합니다: 프로덕션 배포 전에 현실적인 부하에서 구성 변경 사항을 항상 테스트합니다.
예시: 고처리량 구성
다음은 높은 처리량에 최적화된 전체 예시입니다.
이 구성은:
- poll 호출당 최대 10,000개의 레코드를 처리합니다
- 대량 INSERT를 위해 파티션 전체에 걸쳐 배치합니다
- 16 MB 버퍼를 사용하는 비동기 INSERT를 사용합니다
- 8개의 병렬 작업을 실행합니다(파티션 개수에 맞추는 것이 좋습니다)
- 엄격한 순서 보장보다는 처리량에 최적화되어 있습니다
문제 해결
"State mismatch for topic [someTopic] partition [0]"
이는 KeeperMap에 저장된 오프셋과 Kafka에 저장된 오프셋이 서로 다를 때 발생하며, 보통 토픽이 삭제되었거나 오프셋을 수동으로 조정했을 때 발생합니다. 이 문제를 해결하려면 해당 토픽과 파티션에 대해 저장된 이전 값을 삭제해야 합니다.
참고: 이 조정은 정확히 한 번(exactly-once) 처리 보장에 영향을 줄 수 있습니다.
"커넥터가 재시도하는 오류는 무엇인가요?"
현재는 재시도 가능한 일시적 오류를 식별하는 데 중점을 두고 있으며, 여기에는 다음이 포함됩니다:
ClickHouseException- ClickHouse에서 발생할 수 있는 일반적인 예외입니다. 보통 서버가 과부하 상태일 때 발생하며, 다음 오류 코드는 특히 일시적인 것으로 간주됩니다:- 3 - UNEXPECTED_END_OF_FILE
- 159 - TIMEOUT_EXCEEDED
- 164 - READONLY
- 202 - TOO_MANY_SIMULTANEOUS_QUERIES
- 203 - NO_FREE_CONNECTION
- 209 - SOCKET_TIMEOUT
- 210 - NETWORK_ERROR
- 242 - TABLE_IS_READ_ONLY
- 252 - TOO_MANY_PARTS
- 285 - TOO_FEW_LIVE_REPLICAS
- 319 - UNKNOWN_STATUS_OF_INSERT
- 425 - SYSTEM_ERROR
- 999 - KEEPER_EXCEPTION
- 1002 - UNKNOWN_EXCEPTION
SocketTimeoutException- 소켓이 시간 초과될 때 발생하는 예외입니다.UnknownHostException- 호스트를 확인할 수 없을 때 발생하는 예외입니다.IOException- 네트워크에 문제가 있을 때 발생하는 예외입니다.
"모든 데이터가 비어 있거나 0입니다"
데이터의 필드가 테이블의 필드와 일치하지 않는 경우일 가능성이 높습니다. 이는 특히 CDC(및 Debezium 형식)에서 자주 발생하는 문제입니다. 일반적인 해결 방법은 커넥터 설정에 flatten 변환을 추가하는 것입니다:
이 설정은 중첩된 JSON 데이터를 평탄화된 JSON으로 변환합니다(구분자는 _ 입니다). 이후 테이블의 필드 이름은 「field1_field2_field3」 형식(예: 「before_id」, 「after_id」 등)을 따르게 됩니다.
"Kafka 키를 ClickHouse에서 활용하고 싶습니다"
기본적으로 Kafka 키는 value 필드에 저장되지 않지만, KeyToValue 변환을 사용하여 키를 value 필드의 새 _key 필드로 이동할 수 있습니다:
