ClickHouse Cloud와 BigQuery 비교
리소스 구성
ClickHouse Cloud에서 리소스를 구성하는 방식은 BigQuery의 리소스 계층 구조와 유사합니다. 아래 다이어그램에 나와 있는 ClickHouse Cloud 리소스 계층 구조를 바탕으로 주요 차이점을 설명합니다.
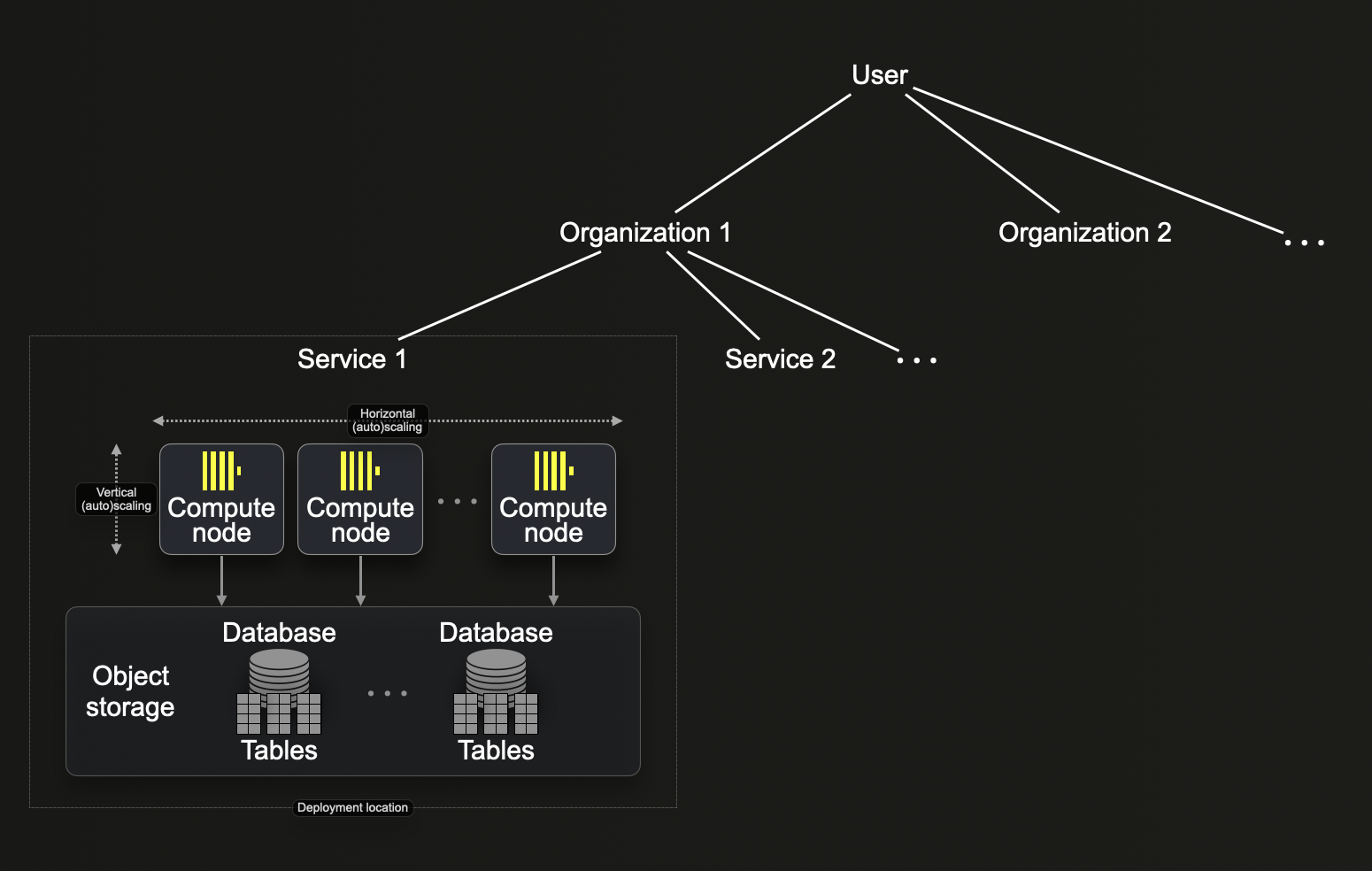
Organizations
BigQuery와 마찬가지로 Organization은 ClickHouse Cloud 리소스 계층 구조에서 루트 노드 역할을 합니다. ClickHouse Cloud 계정에서 처음 생성하는 사용자(USER)는 자동으로 해당 사용자가 소유한 Organization에 할당됩니다. 또한 이 사용자는 다른 사용자(USER)를 Organization에 초대할 수 있습니다.
BigQuery Projects vs ClickHouse Cloud Services
조직 내에서 저장된 데이터가 ClickHouse Cloud의 서비스와 연결되므로 BigQuery 프로젝트와 대략적으로 대응되는 서비스를 생성할 수 있습니다. ClickHouse Cloud에는 여러 서비스 유형이 제공됩니다. 각 ClickHouse Cloud 서비스는 특정 리전에 배포되며 다음을 포함합니다:
- 컴퓨트 노드 그룹(현재 Development 티어 서비스는 노드 2개, Production 티어 서비스는 노드 3개). 이 노드에 대해 ClickHouse Cloud는 수동 및 자동 모두에 대해 수직 및 수평 스케일링을 지원합니다.
- 서비스가 모든 데이터를 저장하는 객체 스토리지 폴더.
- 엔드포인트(또는 ClickHouse Cloud UI 콘솔을 통해 생성된 여러 엔드포인트) - 서비스에 연결하는 데 사용하는 서비스 URL(예:
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443)
BigQuery 데이터 세트 vs ClickHouse Cloud 데이터베이스
ClickHouse는 테이블을 데이터베이스 단위로 논리적으로 그룹화합니다. BigQuery 데이터 세트와 마찬가지로 ClickHouse 데이터베이스는 테이블 데이터를 구성하고 이에 대한 접근을 제어하는 논리적 컨테이너입니다.
BigQuery Folders
현재 ClickHouse Cloud에는 BigQuery 폴더와 동일한 개념이 없습니다.
BigQuery Slot reservations and Quotas
BigQuery slot reservations와 마찬가지로 ClickHouse Cloud에서도 수직 및 수평 자동 확장을 구성할 수 있습니다. 수직 자동 확장을 위해 서비스의 컴퓨트 노드에 대해 메모리와 CPU 코어의 최소 및 최대 크기를 설정할 수 있습니다. 그러면 서비스는 해당 범위 내에서 필요에 따라 자동으로 확장 또는 축소됩니다. 이러한 설정은 초기 서비스 생성 과정에서도 사용할 수 있습니다. 서비스의 각 컴퓨트 노드는 동일한 크기를 가집니다. 수평 확장을 사용하여 하나의 서비스 내에서 컴퓨트 노드 수를 변경할 수 있습니다.
또한 BigQuery quotas와 유사하게 ClickHouse Cloud는 동시성 제어, 메모리 사용량 제한, I/O 스케줄링을 제공하여 쿼리를 워크로드 클래스로 분리할 수 있도록 합니다. 특정 워크로드 클래스에 대해 공유 리소스(CPU 코어, DRAM, 디스크 및 네트워크 I/O)의 한도를 설정하면 해당 쿼리가 다른 중요 비즈니스 쿼리에 영향을 주지 않도록 보장합니다. 동시성 제어는 많은 수의 동시 쿼리가 존재하는 상황에서 스레드 오버서브스크립션(oversubscription), 즉 스레드 과다 할당을 방지합니다.
ClickHouse는 서버, 사용자, 쿼리 수준에서 메모리 할당의 바이트 단위 크기를 추적하여 메모리 사용량 한도를 유연하게 설정할 수 있도록 합니다. 메모리 오버커밋 기능을 사용하면 쿼리가 보장된 메모리를 넘어 사용 가능한 여유 메모리를 추가로 사용할 수 있으며, 동시에 다른 쿼리에 대한 메모리 한도는 보장됩니다. 또한 집계(aggregation), 정렬(sort), 조인(join) 절의 메모리 사용량도 제한할 수 있어, 메모리 한도를 초과하는 경우 외부 알고리즘으로 대체(fallback)하도록 할 수 있습니다.
마지막으로 I/O 스케줄링을 사용하면 워크로드 클래스에 대해 최대 대역폭, 진행 중인 요청 수, 정책을 기준으로 로컬 및 원격 디스크 접근을 제한할 수 있습니다.
권한
ClickHouse Cloud는 cloud console과 database 두 곳에서 사용자 접근을 제어합니다. 콘솔 접근은 clickhouse.cloud 사용자 인터페이스를 통해 관리됩니다. 데이터베이스 접근은 데이터베이스 사용자 계정과 역할을 통해 관리됩니다. 또한 콘솔 사용자에게 데이터베이스 내 역할을 부여하여, 해당 사용자가 SQL console을 통해 데이터베이스와 상호 작용할 수 있도록 할 수 있습니다.
데이터 타입
ClickHouse는 숫자형에 대해 보다 세분화된 정밀도를 제공합니다. 예를 들어, BigQuery는 INT64, NUMERIC, BIGNUMERIC, FLOAT64와 같은 숫자형 데이터 타입을 제공합니다. 이에 비해 ClickHouse는 10진수, 부동 소수점, 정수에 대해 여러 가지 정밀도의 타입을 제공합니다. 이러한 데이터 타입을 활용하면 저장 공간과 메모리 오버헤드를 최적화하여 더 빠른 쿼리와 더 낮은 리소스 사용량을 달성할 수 있습니다. 아래 표에서는 각 BigQuery 타입에 해당하는 ClickHouse 타입을 정리합니다:
ClickHouse 타입에 여러 옵션이 제공되는 경우 실제 데이터 범위를 고려하여 필요한 최소 범위를 선택해야 합니다. 또한 추가 압축을 위해 적절한 코덱을 활용하는 것이 좋습니다.
쿼리 가속화 기법
기본 키와 외래 키, 그리고 기본 인덱스
BigQuery에서는 테이블에 기본 키(primary key)와 외래 키(foreign key) 제약 조건을 둘 수 있습니다. 일반적으로 기본 키와 외래 키는 관계형 데이터베이스에서 데이터 무결성을 보장하기 위해 사용됩니다. 기본 키 값은 보통 각 행마다 고유하며 NULL이 아닙니다. 각 행의 외래 키 값은 기본 키 테이블의 기본 키 컬럼에 존재해야 하거나 NULL이어야 합니다. BigQuery에서는 이러한 제약 조건이 실제로 강제되지는 않지만, 쿼리 옵티마이저가 이 정보를 활용해 쿼리를 더 잘 최적화할 수 있습니다.
ClickHouse에서도 테이블은 기본 키를 가질 수 있습니다. BigQuery와 마찬가지로, ClickHouse는 테이블 기본 키 컬럼 값의 고유성을 강제하지 않습니다. BigQuery와 달리, 테이블 데이터는 디스크에 저장될 때 기본 키 컬럼을 기준으로 정렬된 순서로 저장됩니다. 쿼리 옵티마이저는 이 정렬 순서를 활용하여 재정렬 작업을 방지하고, 조인 시 메모리 사용량을 최소화하며, LIMIT 절에 대해 조기 종료(short-circuit)가 가능하도록 합니다. BigQuery와 달리, ClickHouse는 기본 키 컬럼 값을 기반으로 (희소) 기본 인덱스 를 자동으로 생성합니다. 이 인덱스는 기본 키 컬럼에 대한 필터가 포함된 모든 쿼리를 빠르게 처리하는 데 사용됩니다. 현재 ClickHouse는 외래 키 제약 조건을 지원하지 않습니다.
보조 인덱스(ClickHouse에서만 사용 가능)
테이블 기본 키 컬럼 값으로부터 생성되는 기본 인덱스 외에도 ClickHouse에서는 기본 키에 포함되지 않은 컬럼에 대해 보조 인덱스를 생성할 수 있습니다. ClickHouse는 쿼리 유형에 따라 적합한 여러 종류의 보조 인덱스를 제공합니다:
- Bloom Filter Index:
=또는IN과 같은 동등 조건이 포함된 쿼리를 빠르게 실행하는 데 사용됩니다.- 확률적 데이터 구조를 사용하여 데이터 블록에 특정 값이 존재하는지 여부를 판별합니다.
- Token Bloom Filter Index:
- Bloom Filter Index와 유사하지만 토큰화된 문자열에 사용되며, 전문 검색(full-text search) 쿼리에 적합합니다.
- Min-Max Index:
- 각 데이터 파트에 대해 컬럼의 최소값과 최대값을 유지합니다.
- 지정된 범위에 포함되지 않는 데이터 파트를 읽지 않고 건너뛸 수 있도록 합니다.
검색 인덱스
BigQuery의 검색 인덱스와 유사하게, ClickHouse 테이블의 문자열 유형 컬럼에 대해 전체 텍스트 인덱스를 생성할 수 있습니다.
벡터 인덱스
BigQuery는 최근 Pre-GA 기능으로 벡터 인덱스를 도입했습니다. 마찬가지로 ClickHouse에도 벡터 검색 사용 사례를 가속하기 위한 벡터 검색을 가속하는 인덱스에 대한 실험적 지원이 있습니다.
Partitioning
BigQuery와 마찬가지로 ClickHouse도 테이블을 더 작고 관리하기 쉬운 「파티션」 단위로 나누어 대규모 테이블의 성능과 관리 용이성을 향상시키는 테이블 파티션 기능을 사용합니다. ClickHouse 파티셔닝에 대해서는 여기에서 자세히 설명합니다.
클러스터링
클러스터링을 사용하면 BigQuery는 지정된 일부 컬럼 값을 기준으로 테이블 데이터를 자동으로 정렬하고, 최적 크기의 블록에 함께 배치합니다. 클러스터링은 쿼리 성능을 향상시키며, 이를 통해 BigQuery가 쿼리 실행 비용을 더 정확하게 추정할 수 있습니다. 또한 클러스터링된 컬럼을 사용하면 쿼리에서 불필요한 데이터 스캔을 피할 수 있습니다.
ClickHouse에서는 테이블의 기본 키 컬럼을 기준으로 디스크 상에서 데이터가 자동으로 클러스터링되며, 기본 인덱스 데이터 구조를 활용하는 쿼리가 블록을 빠르게 찾거나 건너뛸 수 있도록(prune) 논리적인 블록 단위로 구성됩니다.
구체화된 뷰(Materialized View)
BigQuery와 ClickHouse 모두 구체화된 뷰(Materialized View)를 지원합니다. 이는 성능과 효율성을 높이기 위해 기본 테이블에 대한 변환 쿼리 결과를 미리 계산해 저장하는 기능입니다.
구체화된 뷰(materialized view) 쿼리하기
BigQuery materialized view는 직접 쿼리할 수 있고, 옵티마이저가 기본 테이블에 대한 쿼리를 처리하는 데 사용할 수도 있습니다. 기본 테이블에 대한 변경 사항이 materialized view를 무효화할 수 있는 경우에는 데이터를 기본 테이블에서 직접 읽습니다. 기본 테이블에 대한 변경 사항이 materialized view를 무효화하지 않는 경우에는 나머지 데이터는 materialized view에서 읽고, 변경된 부분만 기본 테이블에서 읽습니다.
ClickHouse에서는 materialized view를 직접 쿼리하는 방식으로만 사용할 수 있습니다. 그러나 BigQuery(기본 테이블 변경 후 5분 이내에 materialized view를 자동으로 새로 고치지만, 30분마다보다 더 자주 새로 고치지는 않음)와 달리, materialized view는 항상 기본 테이블과 동기화되어 있습니다.
materialized view 업데이트
BigQuery는 기본 테이블에 대해 view의 변환 쿼리를 실행하여 materialized view를 주기적으로 전체 새로 고침합니다. 새로 고침 사이의 기간 동안 BigQuery는 materialized view의 데이터와 새로운 기본 테이블 데이터를 결합하여, materialized view를 계속 사용하면서도 일관된 쿼리 결과를 제공합니다.
ClickHouse에서는 materialized view가 증분 방식으로 업데이트됩니다. 이 증분 업데이트 메커니즘은 높은 확장성과 낮은 연산 비용을 제공합니다. 증분 업데이트되는 materialized view는 기본 테이블이 수십억 또는 수조 개의 행을 포함하는 시나리오에 특히 적합하도록 설계되었습니다. materialized view를 새로 고치기 위해 계속 증가하는 기본 테이블 전체를 반복적으로 쿼리하는 대신, ClickHouse는 새로 삽입된 기본 테이블 행의 값에서만 부분 결과를 계산합니다. 이 부분 결과는 백그라운드에서 이전에 계산된 부분 결과와 순차적으로 병합됩니다. 이러한 방식은 기본 테이블 전체에서 materialized view를 반복적으로 새로 고치는 것과 비교하여 연산 비용을 크게 절감합니다.
트랜잭션
ClickHouse와 달리 BigQuery는 단일 쿼리 내에서 또는 세션을 사용할 경우 여러 쿼리에 걸쳐 멀티 스테이트먼트 트랜잭션(다중 문 트랜잭션)을 지원합니다. 멀티 스테이트먼트 트랜잭션을 사용하면 하나 이상의 테이블에 행을 삽입하거나 삭제하는 등의 변경 연산을 수행한 뒤, 변경 사항을 원자적으로 커밋하거나 롤백할 수 있습니다. 멀티 스테이트먼트 트랜잭션은 ClickHouse의 2024년 로드맵에 포함되어 있습니다.
집계 함수
BigQuery와 비교하면, ClickHouse에는 훨씬 더 많은 기본 제공 집계 함수가 있습니다.
- BigQuery에는 18개의 집계 함수와 4개의 근사 집계 함수가 있습니다.
- ClickHouse에는 150개가 넘는 미리 구현된 집계 함수가 있으며, 미리 구현된 집계 함수의 동작을 확장하기 위한 강력한 aggregation combinator를 제공합니다. 예를 들어, 150개가 넘는 미리 구현된 집계 함수를 테이블 행 대신 배열에 적용하려면 -Array 접미사를 붙여 호출하기만 하면 됩니다. -Map 접미사를 사용하면 임의의 집계 함수를 맵에도 적용할 수 있습니다. 그리고 -ForEach 접미사를 사용하면 임의의 집계 함수를 중첩 배열에 적용할 수 있습니다.
데이터 소스 및 파일 포맷
BigQuery와 비교하면 ClickHouse는 훨씬 더 다양한 파일 포맷과 데이터 소스를 지원합니다:
- ClickHouse는 사실상 모든 데이터 소스에서 90개 이상의 파일 포맷의 데이터를 불러오는 기능을 네이티브로 지원합니다
- BigQuery는 5개의 파일 포맷과 19개의 데이터 소스를 지원합니다
SQL 언어 기능
ClickHouse는 분석 작업에 보다 적합하게 만들어 주는 다양한 확장과 개선 사항을 포함한 표준 SQL을 제공합니다. 예를 들어, ClickHouse SQL은 람다 함수와 고차 함수(higher order functions)를 지원하므로, 변환을 적용할 때 배열을 unnest/explode 연산으로 펼칠 필요가 없습니다. 이는 BigQuery와 같은 다른 시스템에 비해 큰 장점입니다.
배열(Arrays)
BigQuery의 배열 함수가 8개인 것과 비교하면, ClickHouse에는 다양한 문제를 우아하고 단순하게 모델링하고 해결하기 위한 80개가 넘는 내장 배열 함수가 있습니다.
ClickHouse에서 전형적인 설계 패턴은 groupArray 집계 함수를 사용하여 테이블의 특정 행의 값을 (일시적으로) 배열로 변환하는 것입니다. 이렇게 변환된 배열은 배열 함수를 통해 편리하게 처리할 수 있으며, 결과는 arrayJoin 집계 함수를 통해 다시 개별 테이블 행으로 변환할 수 있습니다.
ClickHouse SQL은 고차 람다 함수를 지원하므로, 많은 고급 배열 연산은 배열을 다시 테이블로 일시적으로 변환해야 하는 BigQuery에서 흔히 요구되는 작업(예: 필터링 또는 zipping 배열)을 대신해, 단순히 고차 내장 배열 함수 중 하나를 호출하는 것만으로도 달성할 수 있습니다. ClickHouse에서는 이러한 연산이 각각 arrayFilter 및 arrayZip과 같은 고차 함수 호출로 간단히 처리됩니다.
다음은 BigQuery의 배열 연산을 ClickHouse에 대응시킨 매핑입니다:
| BigQuery | ClickHouse |
|---|---|
| ARRAY_CONCAT | arrayConcat |
| ARRAY_LENGTH | length |
| ARRAY_REVERSE | arrayReverse |
| ARRAY_TO_STRING | arrayStringConcat |
| GENERATE_ARRAY | range |
| ARRAY | array |
서브쿼리의 각 행마다 하나의 요소를 가진 배열 생성
BigQuery
ClickHouse
groupArray 집계 함수
배열을 여러 행으로 변환
BigQuery
UNNEST 연산자
ClickHouse
날짜 배열을 반환
BigQuery
ClickHouse
타임스탬프 배열을 반환합니다
BigQuery
ClickHouse
배열 필터링
BigQuery
배열을 테이블로 일시적으로 되돌리기 위해 UNNEST 연산자를 사용해야 합니다
ClickHouse
arrayFilter 함수
배열 zip 하기
BigQuery
UNNEST 연산자를 사용하여 배열을 임시로 다시 테이블로 변환해야 합니다.
ClickHouse
arrayZip 함수
배열 집계
BigQuery
배열을 다시 테이블로 변환하기 위해 UNNEST 연산자를 사용해야 함
ClickHouse
arraySum, arrayAvg 등의 함수나 90개가 넘는 기존 집계 함수 이름을 arrayReduce 함수의 인자로 사용
