Snowflake에서 ClickHouse로 마이그레이션
이 가이드는 Snowflake에서 ClickHouse로 데이터를 마이그레이션하는 방법을 설명합니다.
Snowflake와 ClickHouse 간에 데이터를 마이그레이션하려면 S3와 같은 오브젝트 스토어를
전송을 위한 중간 저장소로 사용해야 합니다. 마이그레이션 프로세스는 또한 Snowflake의 COPY INTO
명령과 ClickHouse의 INSERT INTO SELECT 명령을 사용하는 방식으로 이루어집니다.
Snowflake에서 데이터 내보내기
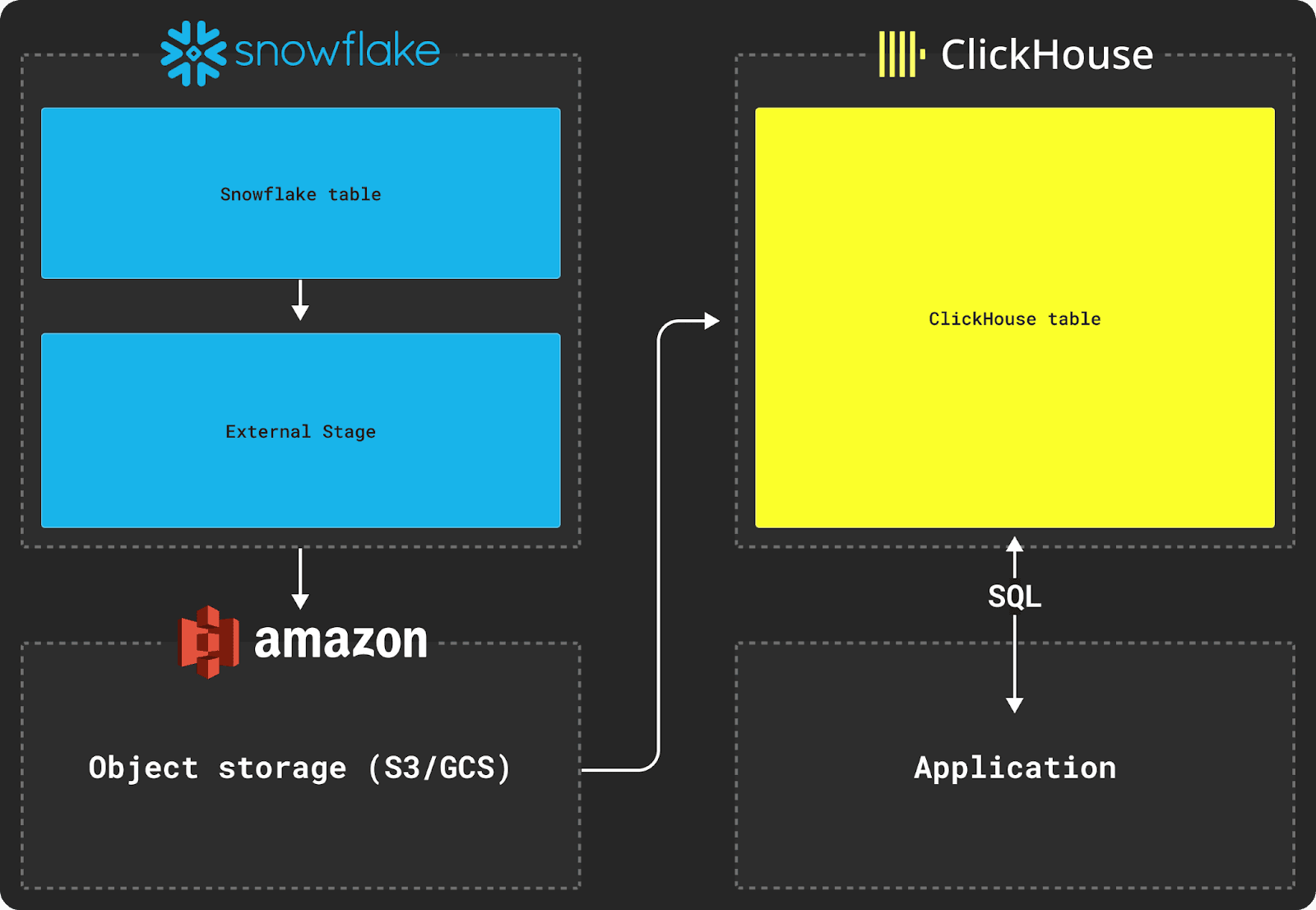
위 다이어그램과 같이 Snowflake에서 데이터를 내보내려면 외부 스테이지(external stage)를 사용해야 합니다.
다음과 같은 스키마를 가진 Snowflake 테이블을 내보내고자 한다고 가정합니다:
이 테이블의 데이터를 ClickHouse 데이터베이스로 옮기려면 먼저 이 데이터를 외부 스테이지로 복사해야 합니다. 데이터를 복사할 때는 중간 형식으로 Parquet을 사용할 것을 권장합니다. Parquet은 타입 정보를 공유할 수 있고, 정밀도를 유지하며, 압축 효율이 좋고, 분석 환경에서 일반적인 중첩 구조를 네이티브로 지원하기 때문입니다.
아래 예에서는 Parquet과 원하는 파일 옵션을 표현하는 Snowflake의 이름이 지정된 파일 형식(named file format)을 생성합니다. 그런 다음 복사된 데이터셋을 저장할 버킷을 지정합니다. 마지막으로 데이터셋을 해당 버킷으로 복사합니다.
약 5TB 규모의 데이터셋에 대해 최대 파일 크기를 150MB로 설정하고, 동일한 AWS us-east-1 리전에 위치한 2X-Large Snowflake warehouse를 사용할 경우, S3 버킷으로 데이터를 복사하는 데 약 30분이 소요됩니다.
ClickHouse로 가져오기
데이터가 중간 객체 스토리지에 스테이징된 후에는 아래와 같이 s3 테이블 함수와 같은 ClickHouse 함수를 사용하여 데이터를 테이블에 삽입할 수 있습니다.
이 예시는 AWS S3용 s3 테이블 함수를 사용하지만, Google Cloud Storage에는 gcs 테이블 함수를, Azure Blob Storage에는 azureBlobStorage 테이블 함수를 사용할 수 있습니다.
대상 테이블 스키마가 다음과 같다고 가정합니다:
이제 INSERT INTO SELECT 명령을 사용하여 S3에서 ClickHouse 테이블로 데이터를 삽입할 수 있습니다:
원래 Snowflake 테이블 스키마의 VARIANT 및 OBJECT 컬럼은 기본적으로 JSON 문자열로 출력되며, ClickHouse로 삽입할 때 이를 형 변환해 주어야 합니다.
some_file과 같은 중첩 구조는 Snowflake에서 복사 시 JSON 문자열로 변환됩니다. 이 데이터를 가져오려면, 위 예시처럼 ClickHouse에서 삽입 시점에 JSONExtract 함수를 사용하여 이러한 구조를 Tuple로 변환해야 합니다.
