PREWHERE 최적화는 어떻게 동작합니까?
PREWHERE 절은(는) ClickHouse에서 쿼리 실행 최적화 기능입니다. 이 기능은 불필요한 데이터 읽기를 피하고, 필터링에 사용되지 않는 컬럼을 디스크에서 읽기 전에 관련 없는 데이터를 먼저 걸러냄으로써 I/O를 줄이고 쿼리 속도를 향상합니다.
이 가이드에서는 PREWHERE가 어떻게 동작하는지, 그 영향도를 측정하는 방법, 그리고 최상의 성능을 위해 PREWHERE를 튜닝하는 방법을 설명합니다.
PREWHERE 최적화 없이 쿼리를 처리하는 방식
PREWHERE를 사용하지 않고 uk_price_paid_simple 테이블에 대한 쿼리가 어떻게 처리되는지부터 살펴보겠습니다:

① 쿼리에는 테이블 기본 키의 일부이자 프라이머리 인덱스(primary index)의 일부인 town 컬럼에 대한 필터가 포함됩니다.
② 쿼리를 가속하기 위해 ClickHouse는 테이블의 프라이머리 인덱스를 메모리에 로드합니다.
③ 그런 다음 인덱스 엔트리를 스캔하여 town 컬럼의 어떤 그래뉼이 조건과 일치하는 행을 포함하고 있을 수 있는지 식별합니다.
④ 이렇게 잠재적으로 관련 있는 그래뉼을 메모리에 로드하고, 쿼리에 필요한 다른 컬럼들에서 위치가 맞춰진 그래뉼도 함께 로드합니다.
⑤ 이후 쿼리 실행 중에 나머지 필터를 적용합니다.
보듯이 PREWHERE를 사용하지 않으면, 실제로 일치하는 행이 소수에 불과하더라도 관련 가능성이 있는 모든 컬럼이 필터링 전에 먼저 로드됩니다.
PREWHERE가 쿼리 효율성을 개선하는 방식
다음 애니메이션은 위에서 사용한 쿼리에 있는 모든 쿼리 조건에 PREWHERE 절을 적용했을 때 해당 쿼리가 어떻게 처리되는지 보여줍니다.
처음 세 단계의 처리 과정은 이전과 동일합니다:

① 쿼리에는 테이블의 기본 키에 포함되어 있고, 따라서 기본 인덱스에도 포함된 town 컬럼에 대한 필터가 있습니다.
② PREWHERE 절 없이 실행한 경우와 마찬가지로, 쿼리를 가속하기 위해 ClickHouse는 기본 인덱스를 메모리에 로드합니다.
③ 그런 다음 인덱스 엔트리를 스캔하여 town 컬럼에서 어떤 그래뉼에 조건과 일치하는 행이 포함되어 있을 수 있는지 식별합니다.
이제 PREWHERE 절 덕분에 다음 단계가 달라집니다. 관련된 모든 컬럼을 먼저 읽는 대신, ClickHouse는 컬럼별로 데이터를 필터링하면서 실제로 필요한 데이터만 로드합니다. 특히 컬럼이 많은 와이드 테이블에서 I/O가 크게 감소합니다.
각 단계마다 이전 필터를 통과, 즉 일치한 행이 최소 한 개 이상 포함된 그래뉼만 로드합니다. 그 결과 각 필터마다 로드하고 평가해야 하는 그래뉼의 수가 계속해서 줄어듭니다:
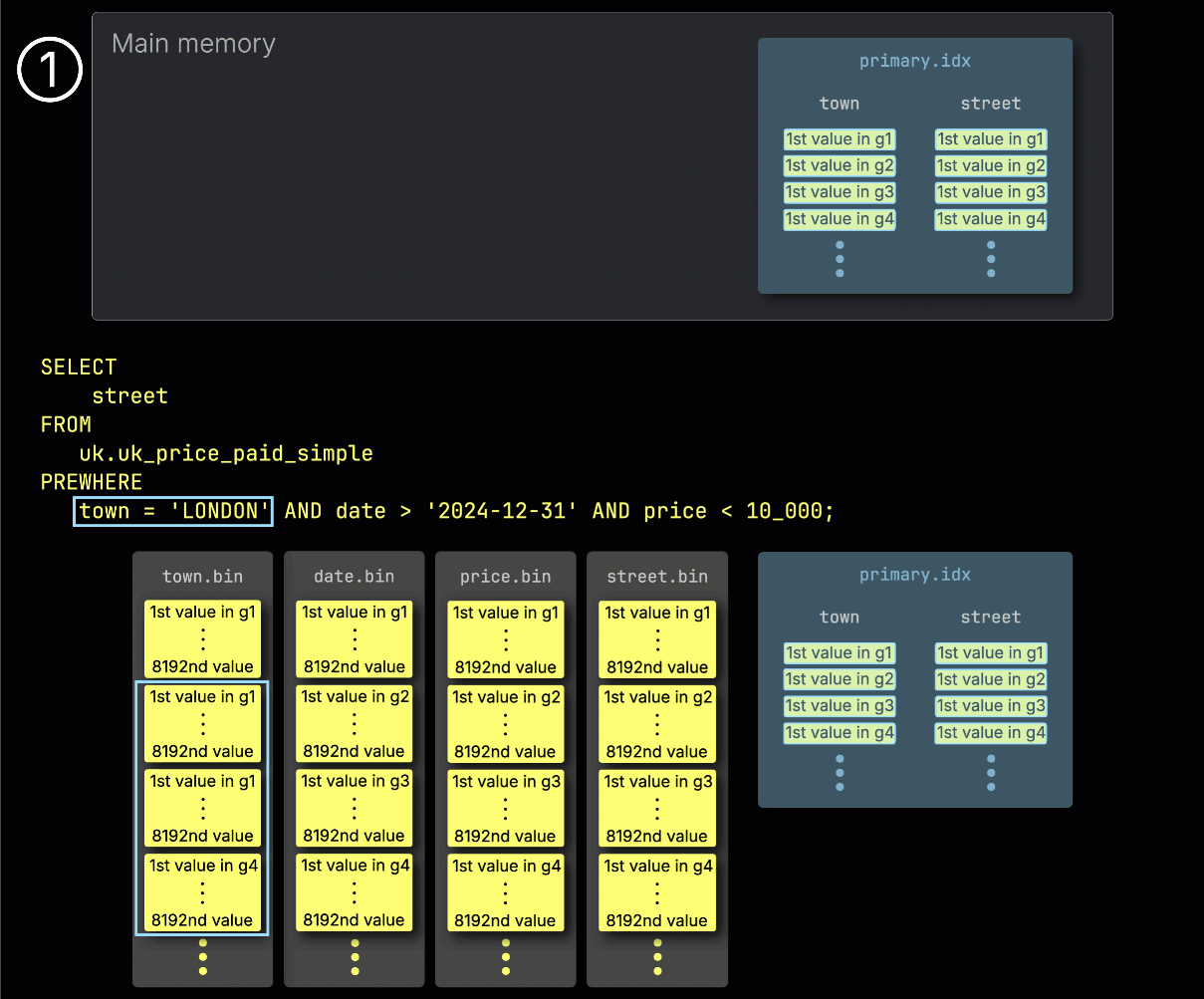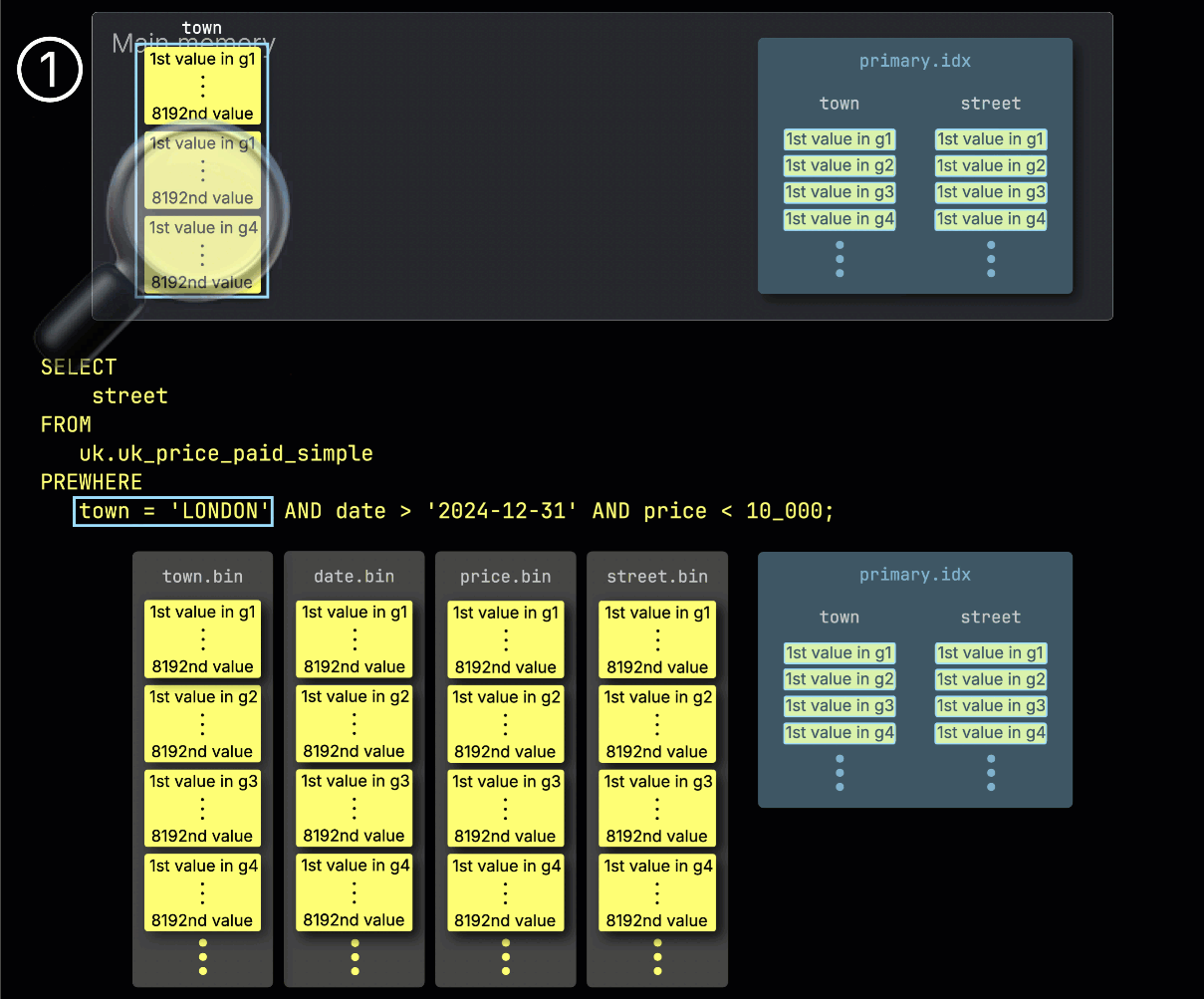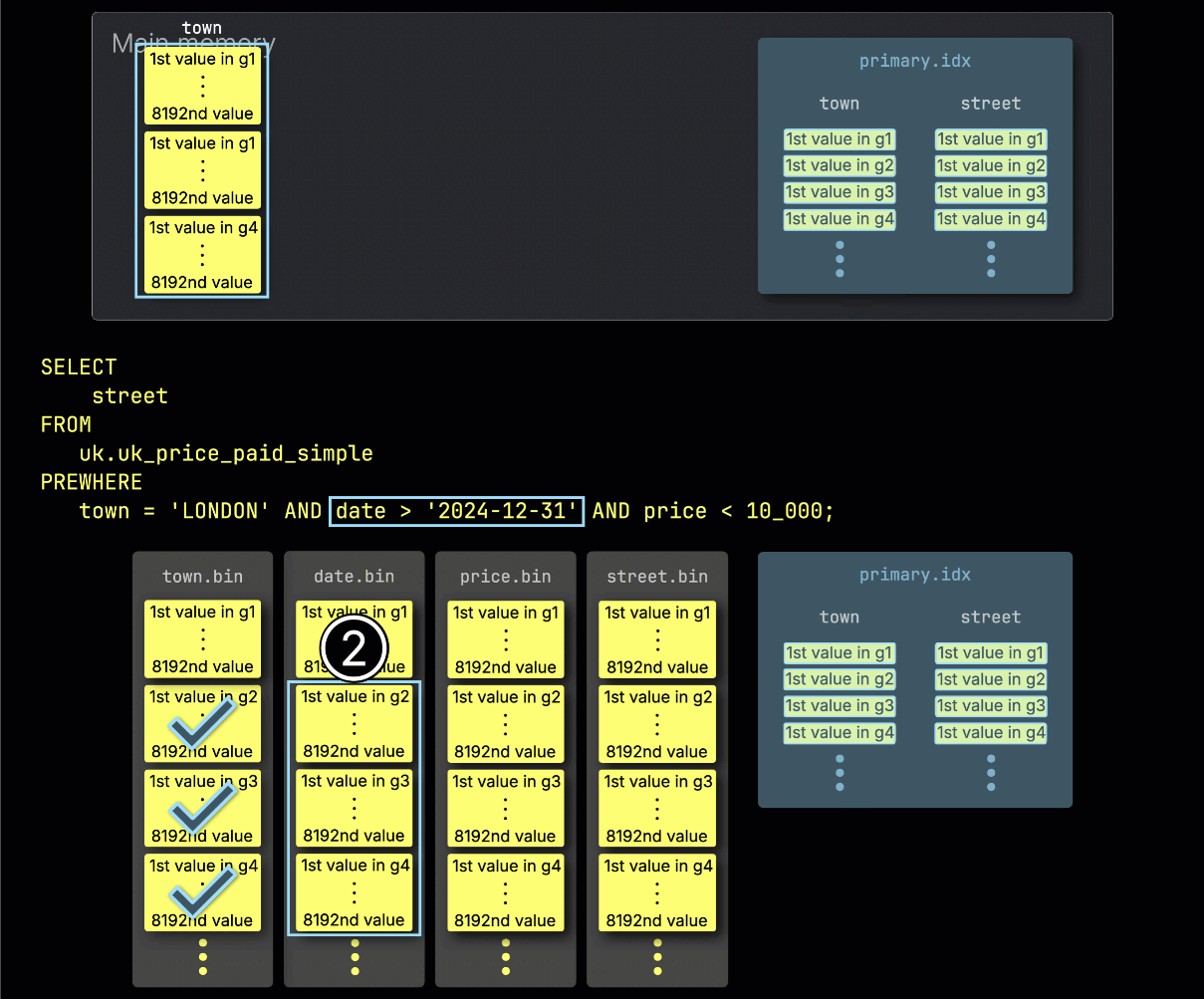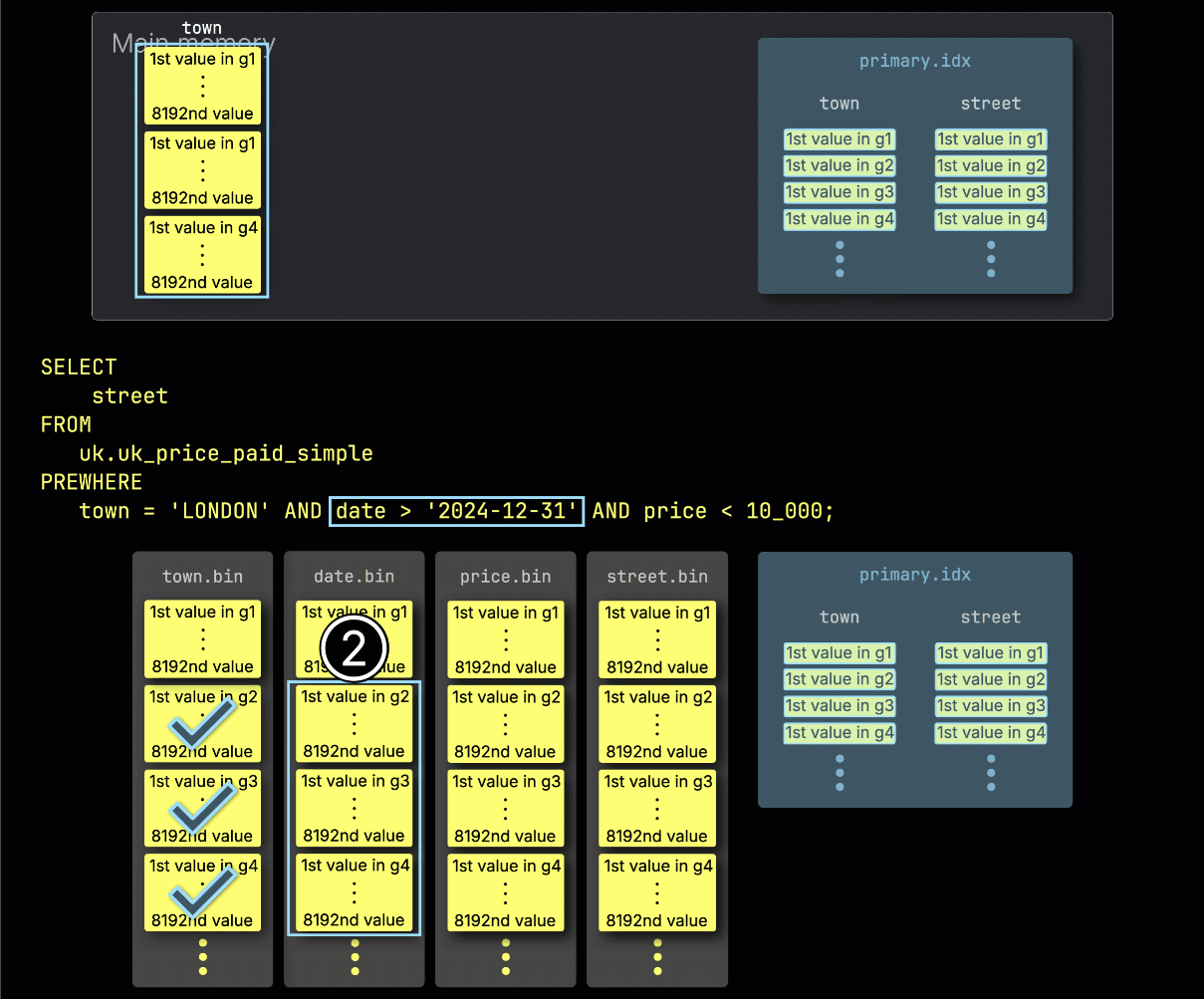
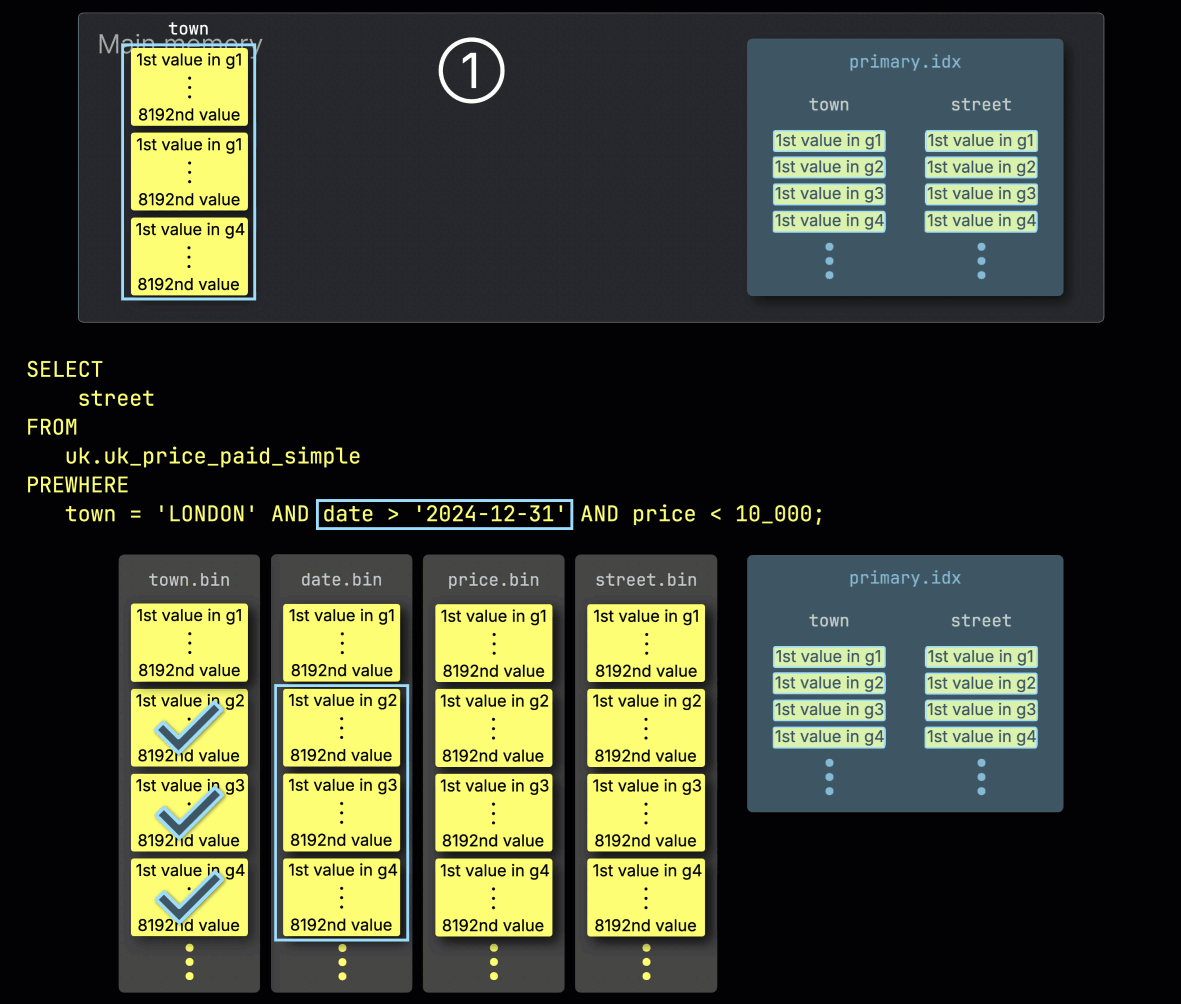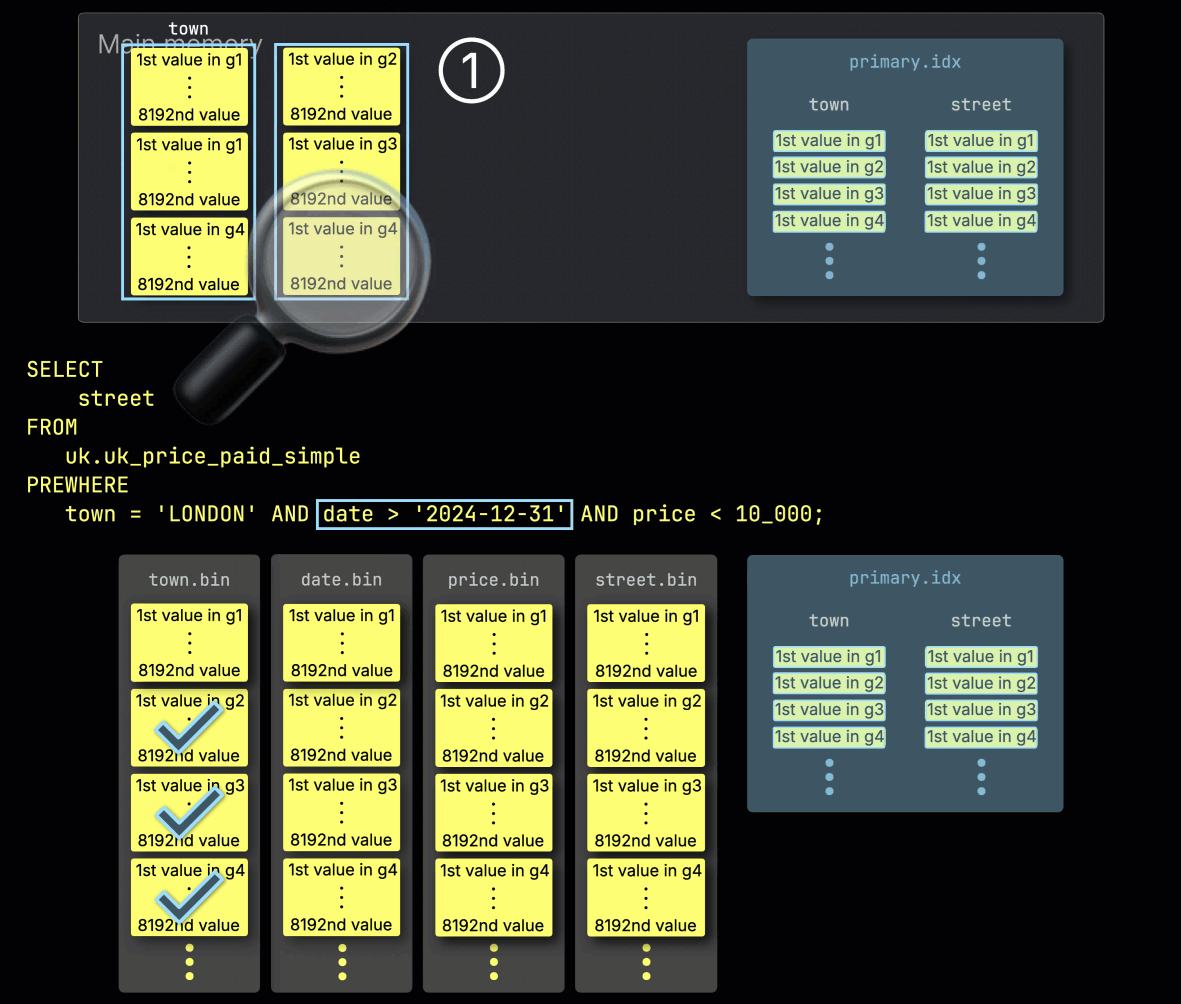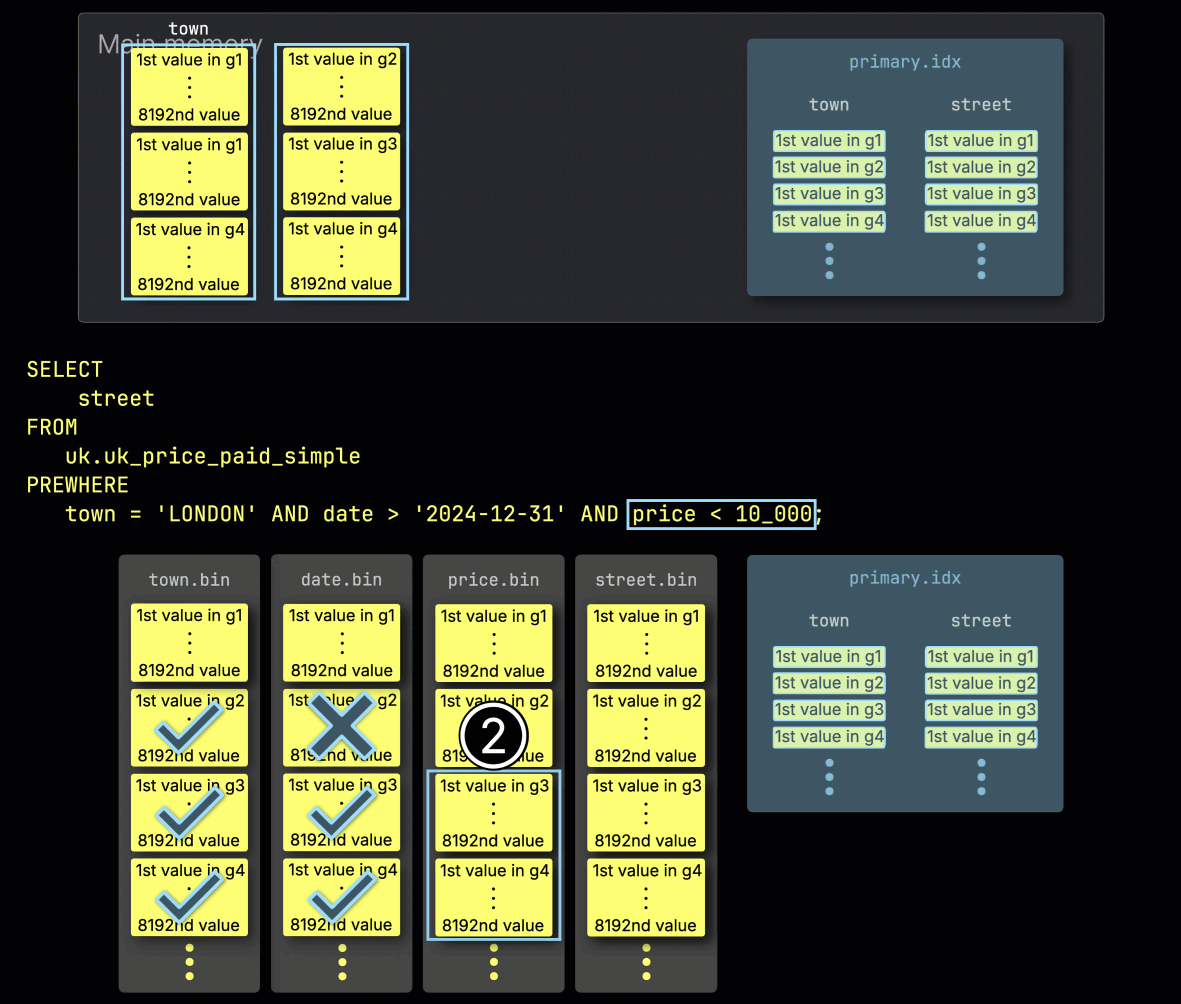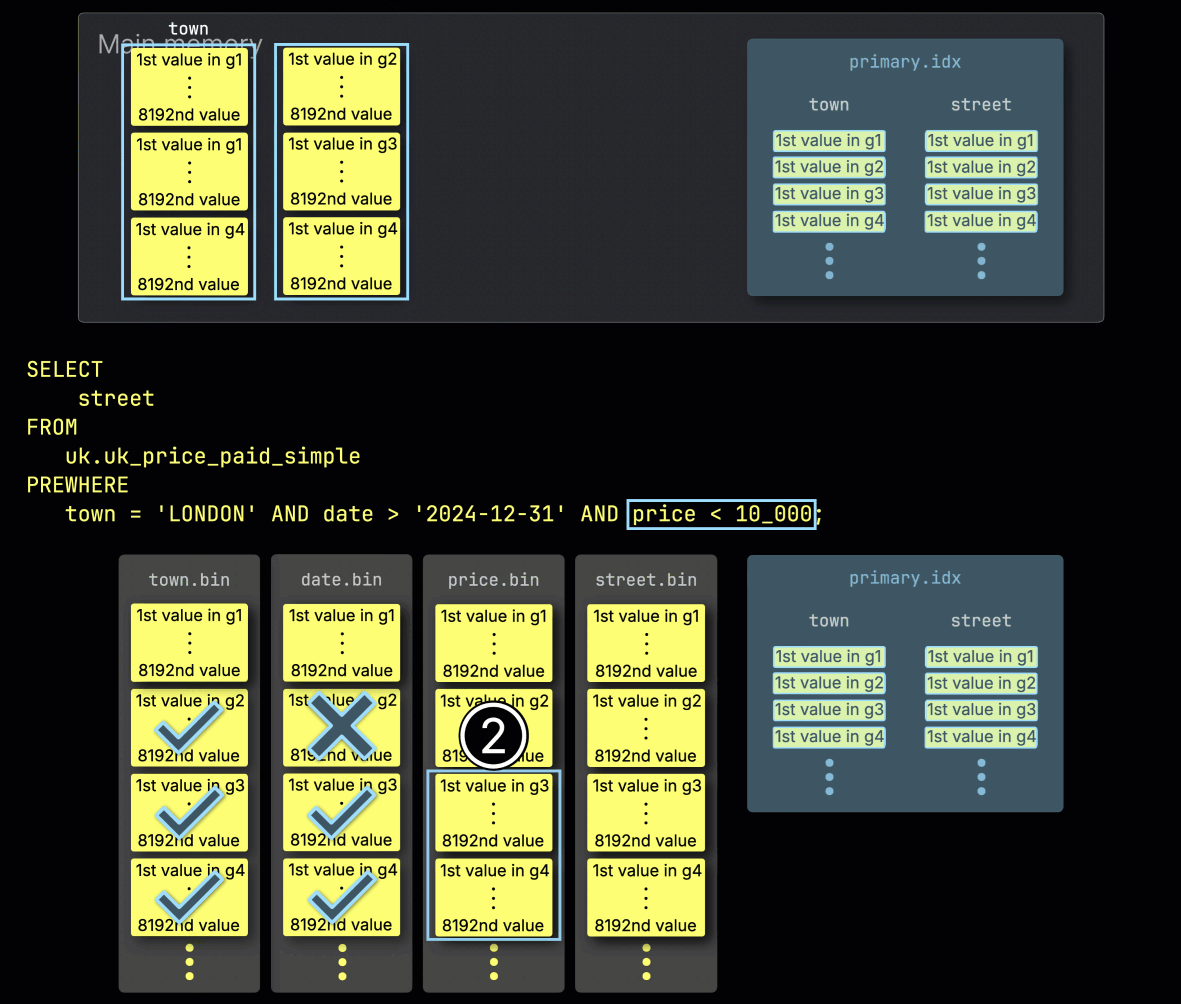
1단계: town으로 필터링
ClickHouse는 PREWHERE 처리를 시작할 때 ① town 컬럼에서 선택된 그래뉼을 읽고, 실제로 London과 일치하는 행을 포함하는지 확인합니다.
이 예제에서는 선택된 모든 그래뉼이 조건과 일치하므로, ② 다음 필터 컬럼인 date에 대해, 이와 위치가 일치하는 그래뉼들이 처리 대상으로 선택됩니다:
2단계: date로 필터링
다음으로 ClickHouse는 ① 선택된 date 컬럼 그래뉼을 읽어 date > '2024-12-31' 필터를 평가합니다.
이 경우 세 개의 그래뉼 중 두 개에 일치하는 행이 있으므로, ② 다음 필터 컬럼인 price에서 이 둘과 위치가 일치하는 그래뉼만 추가 처리 대상으로 선택됩니다:
3단계: price로 필터링
마지막으로 ClickHouse는 ① price 컬럼에서 선택된 두 개의 그래뉼을 읽어 마지막 필터 price > 10_000을 평가합니다.
두 그래뉼 중 하나만이 일치하는 행을 포함하므로, ② 그와 위치가 일치하는 SELECT 컬럼—street—의 그래뉼만 추가 처리를 위해 로드하면 됩니다:

마지막 단계에서는 일치하는 행을 포함하는 최소한의 컬럼 그래뉼만 로드됩니다. 이를 통해 메모리 사용량과 디스크 I/O가 줄어들고 쿼리 실행 속도가 빨라집니다.
PREWHERE를 사용한 쿼리와 사용하지 않은 쿼리 모두에서 ClickHouse가 처리하는 행 수는 동일하다는 점에 유의해야 합니다. 그러나 PREWHERE 최적화를 적용하면, 처리되는 모든 행에 대해 모든 컬럼 값을 로드할 필요는 없습니다.
PREWHERE 최적화는 자동으로 적용됩니다
PREWHERE 절은 위 예시처럼 수동으로 추가할 수 있습니다. 그러나 PREWHERE를 직접 작성할 필요는 없습니다. optimize_move_to_prewhere 설정이 활성화되어 있을 때(기본값은 true), ClickHouse는 읽기량을 가장 많이 줄일 수 있는 조건을 우선하여 WHERE의 필터 조건을 자동으로 PREWHERE로 이동합니다.
기본 아이디어는 작은 컬럼일수록 더 빠르게 스캔되며, 더 큰 컬럼을 처리할 시점에는 대부분의 그래뉼이 이미 필터링되어 있다는 것입니다. 모든 컬럼은 동일한 행 수를 가지므로, 컬럼의 크기는 주로 데이터 타입에 의해 결정됩니다. 예를 들어 UInt8 컬럼은 일반적으로 String 컬럼보다 훨씬 작습니다.
ClickHouse는 23.2 버전부터 기본적으로 이 전략을 따르며, 비압축 크기의 오름차순으로 PREWHERE 필터 컬럼을 정렬하여 다단계 처리에 사용합니다.
23.11 버전부터는 선택적으로 사용할 수 있는 컬럼 통계를 활용하여, 컬럼 크기뿐만 아니라 실제 데이터 선택도에 따라 필터 처리 순서를 결정함으로써 이를 더욱 개선할 수 있습니다.
PREWHERE 효과 측정 방법
PREWHERE가 쿼리에 도움이 되는지 검증하려면 optimize_move_to_prewhere setting을 활성화한 경우와 비활성화한 경우의 쿼리 성능을 비교합니다.
먼저 optimize_move_to_prewhere 설정을 비활성화한 상태에서 쿼리를 실행합니다:
ClickHouse는 해당 쿼리를 위해 231만 개의 행을 처리하면서 23.36 MB의 컬럼 데이터를 읽었습니다.
다음으로 optimize_move_to_prewhere SETTING을 활성화한 상태에서 쿼리를 실행합니다. (이 SETTING은 기본적으로 활성화되어 있으므로 선택 사항입니다.)
처리된 행 수는 동일하게 231만 개였지만, PREWHERE 덕분에 ClickHouse가 읽은 컬럼 데이터는 23.36 MB 대신 6.74 MB로 3배 이상 적어져 전체 실행 시간도 3배 단축되었습니다.
ClickHouse가 내부적으로 PREWHERE를 어떻게 적용하는지 더 깊이 이해하려면 EXPLAIN과 trace 로그를 사용합니다.
EXPLAIN 절을 사용하여 쿼리의 논리 실행 계획을 살펴봅니다.
여기서는 플랜 출력이 매우 장황하기 때문에 대부분을 생략합니다. 요점은 세 개의 컬럼 조건이 모두 자동으로 PREWHERE로 이동되었다는 것을 보여 준다는 점입니다.
직접 이를 재현해 보면, 쿼리 플랜에서 이러한 조건의 순서가 컬럼의 데이터 타입 크기를 기준으로 정해진 것을 확인할 수 있습니다. 컬럼 통계를 활성화하지 않았기 때문에 ClickHouse는 PREWHERE 처리 순서를 결정하기 위한 대체 기준으로 크기를 사용합니다.
내부 동작을 더 깊이 살펴보고 싶다면, 쿼리 실행 중에 모든 테스트 수준 로그 항목을 반환하도록 ClickHouse를 설정하여 각 PREWHERE 처리 단계를 개별적으로 관찰할 수 있습니다.
핵심 내용
- PREWHERE는 이후에 필터링되어 제거될 컬럼 데이터를 읽지 않도록 하여 I/O와 메모리를 절약합니다.
optimize_move_to_prewhere가 활성화되어 있을 때(기본값) 자동으로 동작합니다.- 필터링 순서가 중요하므로, 크기가 작고 선택도가 높은 컬럼을 먼저 사용해야 합니다.
- PREWHERE가 적용되었는지 확인하고 그 효과를 이해하려면
EXPLAIN과 로그를 사용하십시오. - PREWHERE는 선택도가 높은 필터가 있는 컬럼이 많은 테이블과 대규모 스캔에서 가장 큰 효과를 발휘합니다.
